1.5拡張例:Tic-Tac-Toe
強化学習の一般的な考え方を説明し、それを他の方法と比較するために、次に別の例を考えてみましょう。
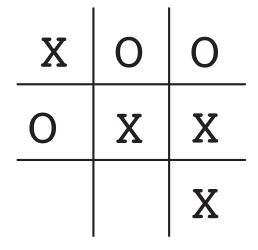
例として、おなじみの子供向けゲームTic TacToeを取り上げます。2人のプレーヤーが交代で3行3列のボードでプレイします。プレーヤーXがゲームで行うのと同じように、3つのマーカーを水平、垂直、または斜めに配置して1人のプレーヤーが勝つまで、1人のプレーヤーがXと他のOをプレイします。ボード上のプレーヤーが3連勝しない場合、ゲームは引き分けになります。熟練したプレーヤーは決して負けることはないので、ゲームが間違っていることもあるが勝つことができる不完全なプレーヤーと対戦していると仮定しましょう。実際、引き出しと補償を私たちにとって悪いものとして扱いましょう。対戦相手のゲームの欠陥を見つけ、勝つチャンスを最大化することを学ぶことができるプレーヤーをどのように訓練しますか?
これは単純な問題ですが、従来の手法では簡単に解決することはできません。たとえば、ゲーム理論の古典的な「最大-最小」ソリューションは、対戦相手の特別なゲームプレイを想定しているため、ここでは正しくありません。たとえば、ミニマックスプレーヤーは、たとえ実際には対戦相手の間違ったゲームのために負ける可能性があるゲーム状態に達することは決してなく、常に勝ちます。動的プログラミングなどの順次決定問題の従来の最適化方法では、任意の対戦相手の最適解を計算できますが、各ボード状態での対戦相手の各移動の確率を含む、対戦相手の完全な説明を入力する必要があります。この情報は、最も実用的に興味深い問題ではないため、この問題の事前情報ではないと仮定します。一方、この情報は、この場合、対戦相手と多くのゲームをプレイすることによる経験から推定することができます。この問題に関しては、最初に対戦相手の行動モデルを学習してある程度の信頼度を達成し、次に動的プログラミングを適用して、特定の近似対戦相手モデルの最適なソリューションを計算するのが最善の方法です。最後に、これは、この本の後半で学習するいくつかの強化学習方法とそれほど違いはありません。
この問題に適用される進化的方法は、可能な戦略空間で対戦相手に勝つ可能性が高い戦略を直接見つけます。ここで、戦略とは、ゲームの各状態に対してどのアクションを実行する必要があるかをプレーヤーに指示するルールです。3×3ボード上のXとOのすべての可能な構成です。検討した戦略ごとに、対戦相手と一定数のゲームをプレイすることで、勝率の見積もりが得られます。この評価は、次に検討する1つまたは複数のポリシーをガイドします。典型的な進化的方法は、ポリシースペースの丘を登り、ポリシーを生成および評価して、段階的な改善を取得することです。あるいは、全体的な戦略を維持および評価するために遺伝的アルゴリズムを使用することが可能かもしれません。何百もの異なる最適化方法を適用できます。
値関数を使用してTicTacToeの問題に対処する方法は次のとおりです。まず、数字の表を作成します。各数字は、ゲームの可能な状態を表します。各数値は、その州で勝つ確率の最新の見積もりになります。この推定値を状態値として扱い、表全体が学習値関数です。状態値が状態Bよりも高いか、状態Bよりも「優れている」と見なされます。現在の確率の推定値がBよりも高い場合、常にxを再生すると、すべての状態に3つの連続したXがあり、勝つ確率があります。勝ったので1です。同様に、3つの連続したOを持つすべての状態、または満たされたすべての状態の場合、勝つことができないため、正しい確率は0です。他のすべての状態の初期値を0.5に設定しました。これは、推測に勝つ可能性が50%あることを意味します。
その後、対戦相手とたくさんのゲームをしました。ステップを選択するために、可能な各ステップ(チェスボード上のすべてのスペース)の可能な状態を確認し、テーブルでそれらの現在の値を調べます。ほとんどの場合、私たちは貪欲で、最も価値のある動き、つまり勝つ可能性が最も高い動きを選択します。ただし、他の動きからランダムに選択する場合があります。これらは、これまでに見たことのない状態を体験できるため、探索的移動と呼ばれます。ゲームで実行される一連のアクションを図1.1に示します。
ゲームをプレイしているときは、ゲーム内の状態の値を変更します。私たちは、彼らに勝つ確率をより正確に推定させるように努めています。この目的のために、図1.1の矢印で示すように、各貪欲な移動後の状態値を移動前の状態に「バックアップ」します。より正確には、前の状態の現在の値は、後の状態に近い値に更新されます。これは、前の状態の値を後の状態の値に少しシフトすることで実現できます。stが貪欲な動きの前の状態を示し、St + 1が貪欲な動きの後の状態を示し、次にSt V(St)の推定値に更新するとします。
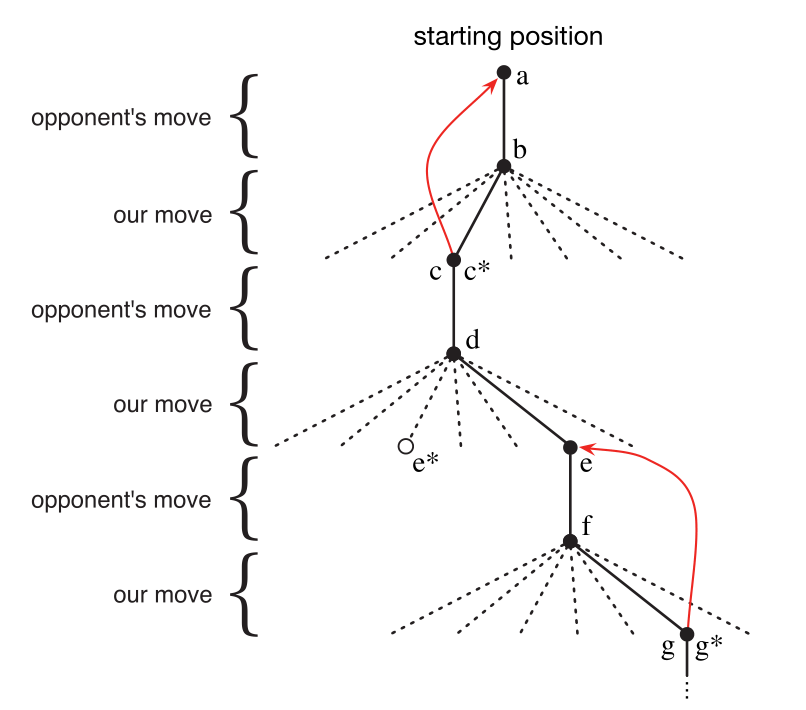
図1.1:tic-tac-toeアクションシーケンス。黒の実線はゲーム内の動きを表し、点線は私たち(強化学習プレイヤー)が考慮したが実行しなかった動きを表します。*現在推定されている最良の動きを示します。2番目のステップは探索的な動きです。つまり、別の兄弟会社の動きでさえ、e *ランキングが高くなります。探索的な移動は学習につながりませんが、赤い矢印で示されているように、他のすべての移動は更新につながります。この記事で説明されているように、推定値はツリー上の後のノードから前のノードに移動します。
次のように書くことができます
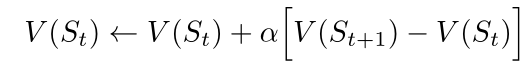 、
、
その中で、aはステップサイズパラメータと呼ばれる小さな正のスコアであり、学習速度に影響を与えます。この更新ルールは時差学習方法の一例であり、2つの連続する時間推定値の差V(St + 1)-V(St)に基づいて変化するため、このように呼ばれます。
上記の方法は、このタスクでうまく機能します。たとえば、ステップサイズパラメータが時間の経過とともに適切に減少した場合、固定された対戦相手の場合、メソッドは、最高のパフォーマンスを得るためにプレーヤーによって与えられた各状態で勝つ真の確率に収束します。さらに、後続の動き(暫定的な動きを除く)は、実際にはこの(不完全な)対戦相手に対する最良の動きです。言い換えれば、この方法は、この対戦相手とのゲームに最適な戦略に収束します。ステップサイズパラメータが時間の経過とともにゼロに減少しない場合、プレーヤーは、プレイスタイルをゆっくりと変更する対戦相手ともうまく戦うことができます。
この例は、進化法と価値関数の学習法の違いを示しています。戦略を評価するために、進化的手法は戦略を変更せずに対戦相手と複数のゲームをプレイするか、対戦相手のモデルを使用して複数のゲームをシミュレートします。勝率は、戦略の勝率の偏りのない見積もりを提供し、次の戦略の選択を導くために使用できます。ただし、各ポリシーの変更は複数のゲームの後に行われ、各ゲームの最終結果のみが使用されます。ゲーム中に発生したことは無視されます。たとえば、プレーヤーが勝った場合、特定のアクションが勝利にとってどれほど重要であっても、ゲーム内のすべてのアクションが信頼されます。一度も起こったことのない行動にもクレジットが与えられます!対照的に、値関数法では、個々の状態を評価できます。最後に、進化法と価値関数法の両方が検索戦略空間にありますが、価値関数を学習すると、ゲーム中に利用可能な情報が使用されます。
Tic-tac-toeには比較的小さい有限の状態セットがあり、状態セットが非常に大きい場合、または無限の場合でも、強化学習を使用できます。たとえば、Gerry Tesauro(1992、1995)は、上記のアルゴリズムを人工ニューラルネットワークと組み合わせて、約10 ^ 20の状態でバックギャモンを再生することを学習しました。非常に多くの州があるため、それらのごく一部を体験することは不可能です。テサウロのプロジェクトは、これまでのどのプロジェクトよりもはるかに優れたゲームを学び、最終的には世界最高の人間プレイヤーよりも優れていました(セクション16.1を参照)。人工ニューラルネットワークは、プログラムに経験から要約する機能を提供するため、新しい状態では、ネットワークが過去に決定したのと同様の状態で保存された情報に基づいてアクションを選択します。このような大規模な状態セットの問題における強化学習システムの役割は、過去の経験から適切に要約する能力と密接に関連しています。強化学習において私たちが最も必要とするのはこの役割です。人工神経回路網と深層学習(セクション9.7)は、唯一または最良の方法ではありません。
このtic-tac-toeの例では、学習開始時にゲームのルールを超える事前知識はありませんが、強化学習は表形式の学習とインテリジェンスを意味するものではありません。逆に、以前の情報はさまざまな方法で強化学習に組み込むことができ、これらの方法は早期学習に不可欠です(たとえば、セクション9.5、17.4、および13.1を参照)。tic-tac-toeの例では実際の状態にアクセスすることもできます。また、状態の一部が非表示になっている場合や、学習者の状態が異なる場合にも、強化学習を適用できます。
最後に、tic-tac-toeプレーヤーは、それぞれの可能なアクションがどのような状態を生み出すかを楽しみにして知ることができます。これを行うには、実行できないアクションに応じて環境がどのように変化するかを予測できるゲームモデルが必要です。多くの問題はこのようなものですが、他の問題では、短期的なアクション要素モデルの欠如さえあります。強化学習はどのような状況でも適用できます。モデルは必須ではありませんが、モデルが利用可能または学習可能であれば、簡単に使用できます(第8章)。
一方、一部の強化学習方法では、環境モデルをまったく必要としません。モデルフリーシステムは、単一のアクションに応答して環境がどのように変化するかを考慮することさえできません。この意味で、Tic-Tac-Toeゲーム機は、対戦相手に比べてモデルがありません。対戦相手のモデルはありません。モデルが有用であるためには非常に正確でなければならないため、問題を解決する本当のボトルネックが高精度の環境モデルを構築することである場合、モデルフリーの方法はより複雑な方法よりも利点があります。モデルフリーの方法も、モデルベースの方法の重要な部分です。この本では、より複雑なモデルベースのメソッドのコンポーネントとしてモデルフリーメソッドを使用する方法を説明する前に、いくつかの章でモデルフリーメソッドについて説明します。
強化学習は、システムの高レベルと低レベルの両方で使用できます。tic-tac-toeプレイヤーはゲームの基本的な動きを学ぶだけですが、すべての「アクション」自体が複雑な問題解決方法のアプリケーションである可能性があるため、強化学習がより高いレベルで機能することを妨げるものはありません。階層型学習システムでは、強化学習は複数のレベルで同時に機能します。演習1.1:セルフプレイ上記の強化学習アルゴリズムは、ランダムな対戦相手と対戦するのではなく、双方が学習している間に自分自身と対戦するとします。この状況で何が起こると思いますか?さまざまな動きの選択戦略を学びますか?
演習1.2:対称性多くのtic-tac-toeの位置は異なって見えますが、対称性があるため、実際には同じです。これを利用するには、上記の学習プロセスをどのように変更する必要がありますか?この過程で、学習方法にどのような改善が加えられますか?今考えてみてください。対戦相手が対称性を使用していないと仮定します。その場合、私たちはすべきですか?したがって、対称的に等しい位置は同じ値でなければなりません。これは本当ですか?
演習1.3:貪欲なゲームは、強化学習プレーヤーが貪欲であることを前提としています。つまり、常に最善と思われる場所にそれを取ります。貪欲でない人よりも上手く、または下手にプレーすることを学ぶことができますか?何がうまくいかないのでしょうか?
演習1.4:探索からの学習学習の更新は、探索アクションを含むすべてのアクションの後に発生すると想定します。ステップサイズパラメータが時間の経過とともに適切に減少する場合(ただし、探索の傾向ではない)、状態値は異なる確率のセットに収束します。概念的には、探索的行動から学ぶときに、(概念的に)2セットの確率が計算されますか?探索的アクションを継続して実行するとします。学習に適した確率のセットはどれですか。それはより多くの勝利につながるでしょうか?
演習1.5:その他の改善強化学習の能力を向上させる他の方法を考えられますか?ポーズをとるときのチックタックトゥの問題を解決するためのより良い方法を考えられますか?