本章では、最適化される前のセクションで説明した技術を使用する方法を示すために、いくつかの例を使用します。単にコードのいくつかの小さな断片を表示することに加えて、そのセクションの前に2つのよく知られた画像フィルタリング処理、フィルタリングおよびイプシロンソーベルフィルタ処理ステップの最適化により工程を説明するあります。
コードサンプル9.1アプリケーション
9.1.1リフティングスキーム
この例では、パフォーマンスを向上させるためのコードを簡素化する方法を示しています。絵を考えると、それはボックスの8×8ぼかしフィルタを行いました。
オリジナルのカーネルの最適化前のコードの:
__kernelボイドImageBoxFilter(__ READ_ONLY image2d_tソース、
__write_only image2d_t DEST、
sampler_tサンプラー)
{
... //変数宣言
以下のために(; iは8 <; I = 0 int型私は++)
{
(int型J = 0; jの<8; J ++)について
{
COOR = inCoord +(INT2)(I - 4、J - 4)。
// !! read_imagefは、作業項目ごとに64回呼び出されます
和+ = read_imagef(ソース、サンプラー、COOR)。
}
}
//平均を計算
float4 avgColor =合計/ 64.0f;
... //結果を書き出します
}
上記の二つのステップのテクスチャアクセスカーネル関数を減らすために。最初の2×2の各作業項目の平均値を算出するステップと、一時的な画像に結果を格納します。第二のステップは、最終的な計算のための一時的な画像を使用します。
カーネルが変更され
//最初のパス:2x2のピクセルの平均
__kernelボイドImageBoxFilter(__ READ_ONLY image2d_tソース、
__write_only image2d_t DEST、
sampler_tサンプラー)
{
... //変数宣言
// 2x2の領域をサンプリングし、結果を平均
以下のために(; iは2 <; I = 0 int型私は++)
{
(INT J = 0であり、j <2、J ++)のために
{
COOR = inCoord - (INT2)(i、j)は、
作業項目ごとに// 4 read_imagef
和+ = read_imagef(ソース、サンプラー、inCoord-(INT2)(I、J))。
}
}
//場合コンパイラは、4分周の等価物は//最適化しません
float4 avgColor =合計* 0.25F。
... //結果を書き出します
}
// 2番目のパス:最終平均
__kernel無効ImageBoxFilter16NSampling(__read_only image2d_tソース、
__write_only image2d_t DEST、
sampler_tサンプラー)
{
... //変数宣言
INT2は、=は、outCoordオフセット - (INT2)(3,3)。
// 2x2の隣人の16サンプリング
以下のために(; iは4 <; I = 0 int型私は++)
{
(INT J = 0; J <4; J ++)のために
{
COORD = mad24((INT2)(i、j)は、(INT2)2、オフセット)。
作業項目ごとに// 16 read_imagef
和+ = read_imagef(ソース、サンプラー、COORD)。}
}
//ケースコンパイラには、16で割ったのと同等の//最適化しません。
float4 avgColor =合計* 0.0625;
... //結果を書き出します
}
唯一の修飾各作業項目アルゴリズムは、元の取得64 read_imagefよりも明らかに多くの倍少ない画像バッファ、第20(16 + 4)を得ました。
量子化9.1.2ロードとストア
この例では、副腎のGPUにおける帯域幅の量子化と活用をロードして保存する方法を示しています。
事前最適化されたソースコード:
__kernelボイドMatrixMatrixAddSimple(のconst int型matrixRows、
constのint型matrixCols、
__globalフロート*行列A、
__globalフロート* matrixB、
__globalフロート* MatrixSum)
{
int型I = get_global_id(0)。
INT J = get_global_id(1)。
//唯一の行列AとmatrixBから4バイトを取得します。
//次にMatrixSumに4つのバイトを保存します。
MatrixSum [私は+ jのmatrixColsを*] =
行列Aは+ matrixB [私はmatrixCols + jは*] [私はmatrixCols + jは*]。
}
改訂されたコード
__kernel無効MatrixMatrixAddOptimized2(のconst int型の列、
constのint型COLS、
__globalフロート*行列A、
__globalフロート* matrixB、
__globalフロート* MatrixSum)
{
int型I = get_global_id(0)。
INT J = get_global_id(1)。
//オフセット指数を計算する組み込み関数を利用
int型のオフセット= mul24(J、colsの);
INTインデックス= mad24(I、4、オフセット)。
// //ベクタライズ性能向上のためのメモリ帯域幅の利用に。
//今では行列AとmatrixBから16のバイトをretieves。
//次にMatrixSumに16のバイトを保存します
float4 TMPA =(*((__グローバルのfloat4 *)&行列A [インデックス])); // //代わりに
VLOADとVSTOREは、ここで使用することができます
float4 TMPB =(*((__グローバルのfloat4 *)&matrixB [インデックス]));
(*((__グローバルするfloat4 *)&MatrixSum [インデックス]))=(TMPA + TMPB)。
// ALUがスカラー基づいているので、ALUの動作には影響。
}
新しいカーネルは、量子化のfloat4ロード/ストアを達成するために使用されます。ベクトル化するので、グローバルワークサイズの前に新しいカーネルが1/4のカーネルです。
9.1.3使用イメージ置換バッファ
この例では、所定のベクトル演算500万対ベクトルの各対のドット積です。元のコードは、頻繁に使用されるデータのアクセス性能を向上させるために、テクスチャオブジェクト(read_imagef)を使用して、変更後、オブジェクトバッファの使用です。これは単純な例ですが、技術を使用すると、このような状況下で、アクセスバッファオブジェクトは、有効なより良いテクスチャオブジェクトアクセスされ、多くの似たようなケースにも適用することができます。
| オリジナルのカーネル関数の最適化の前に |
最適化されたカーネル関数 |
| __kernelボイドドット積(__グローバルのconst float4 *、constの__globalのfloat4 * B、__グローバルフロート*結果){// aとbの 500万ベクトルそれぞれが含まれています //配列は、線形バッファとして格納されています グローバルメモリ内の 結果[GID] =ドット([GID]、B [GID])。 } |
__kernelボイドドット積(__ READ_ONLY image2d_tのC、__read_only image2d_t dを、 __globalフロート*結果){ //画像c、dはデータを保持するために使用されています 代わりに、リニアバッファの // read_imagefは、テクスチャを通過します エンジン INT2 GID =(get_global_id(0)、 get_global_id(1))。 結果[gid.y * W + gid.x] = ドット(read_imagef(C、サンプラー、GID)、 read_imagef(D、サンプラー、GID))。 } |
9.2イプシロンフィルタ
イプシロンフィルタは広く欠陥の一種である(例えば、サイド画像のような)高周波数領域で発生するモスキートノイズを低減するために画像処理に使用されます。これは、空間的変動の支持点に基づいて、非線形フィルタリング及びローパスフィルタリングされ、そして、特定の画素の閾値を濾過します。
ノイズは、しばしば、このチャンネルで見ることができるので、この例では、それだけは、イプシロンフィルタYUV Yチャネル画像に使用されます。Yチャネルは、(NV12形式で)連続的に記憶されたUVチャンネルから別々に記憶されているものとします。図9-1は、フィルタリングアルゴリズムの二つの基本的な手順を示しています。
nはフィルタリングされる画素について、全ての画素の画素差分絶対値の中心に9×9の範囲で計算されます。
nが閾値の絶対値よりも小さい場合、隣接する画素の平均値を使用します。しきい値は、事前に定義されたプログラムで、通常は一定であることに注意してください。

図9-1イプシロンフィルタリングアルゴリズム。
最初の実装を9.2.1
プログラムは、各画素は8ビットのデータ幅である(3264、幅、高さ2448である)3264x2448のYUV画像分解能を算出します。本明細書に基づいてパフォーマンスデータSnadragon 810(MSM8994、副腎430)は、高パフォーマンスモードの装置。
ここで初めて実装されたパラメータおよびポリシーは、次のとおりです。
- 使用OpenCL的image对象替代buffer对象。
- 使用image替代buffer能够避免边界检测和充分利用Adreno GPUs中的L1 cache。
- 使用CL_R | CL_UNORM_INT8图片格式/数据类型
- 单个通道,比如这里的Y通道,而且读取到SP的像素点,都被Adreno GPUs内建的texture管道归一化到[0,1]。
- 每个work item 处理一个输出的元素。
- 使用2D的kernel,global 的worksize大小被设置为[3264,2448].
在这个实现中,每个work item需要获取81个浮点类型的像素点。在Adreno A430上这个实现的性能数据作为进一步优化的基准。
9.2.2数据包优化
通过比较计算量和数据装载量,这个例子明显是内存瓶颈。因此,主要的优化是如何提升数据的装载效率。
首先需要注意到,使用32位的浮点来表示像素点是对内存的浪费。对许多图像处理算法来说,8位或者16位的数据类型就够用了。因为Adreno GPUs对16位浮点类型有内嵌的硬件支持,比如half或者fp16,所以可以使用下面的优化方法:
- 使用16位浮点数据类型来替换32位浮点
- 现在每个work item获取81个half 数据
- 使用CL_RGBA| CL_UNORM_INT8图像类型或者数据类型
- 使用CL_RGBA 去装载4个通道能更好的的利用TP的带宽。
- 使用read_imagef 替代read_imageh。TP会将数据自动转换成16位half数据。
- 每个work item
- 每行使用3个half4向量
- 输出一个已经被处理的像素点
- 对于每一个输出的像素点,访问的内存数是3x9 = 27 (half4)
- 性能提升1.4x
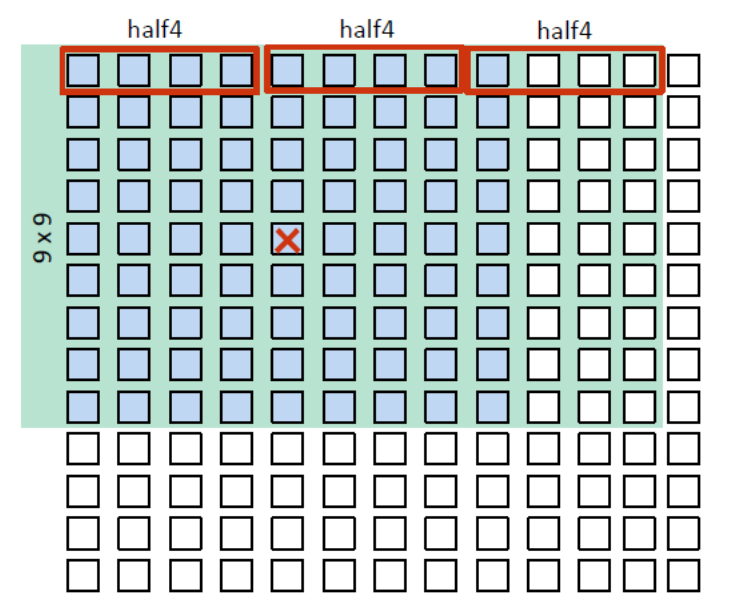
图9-2 使用16位 half类型(fp16)打包数据
9.2.3 向量化装载/存储优化
在之前的步骤中,只要计算一个输出像素,就有很多邻居像素点需要装载。可以通过额外装载一些像素点,那么久可以滤波更多的像素点,如下所示:
- 每个work item
- 每一行读3个half4的向量
- 输出4个像素
- 每个输出像素点需要获取的内存数量是:3x9/4 = 6.75(half4)
- 全局的work size:(width/4)x height
- 对每一行循环展开。
- 在每一行内,使用活动窗口的方法。

图9-3 每一个work item滤波更多的像素点
图9-3 阐述了通过装载额外的像素点,处理多个像素的方法。以下是几个具体的步骤:
Read center pixel c;//读取中心像素点c
For row = 1 to 9, do://从行1到行9,执行以下操作
read data p1;//读取数据p1
Perform 4 computation with pixel c;//对c执行1次计算
read data p2;//读取数据p2
Perform 4 computations with pixel c; //对c执行4次计算
read data p3;//读取数据p3
Perform 4 computations with pixel c; //与c执行4次计算
end for//结束循环
write results back to pixel c.//将结果写回中心像素点
通过这些步骤,性能比基准性能提高了3.4x。
9.2.4 进一步提升每个work item的工作量
提升每个work item的工作量,性能可能会有所提升。下面是一些可选的操作:
- 读取多个half4向量,提升输出的像素个数到8个。
n 全局的work size : width/8 xheight
n 每个work item
- 每一行读4个half4 向量。
- 输出8个像素
- 每个输出像素点需要访问的内存次数为:4x9/8 = 4.5 (half4)
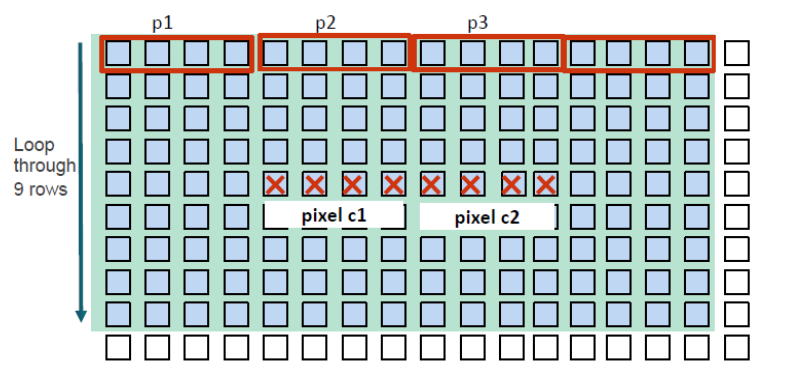
图9-4 每个work item 处理8个像素点
这些改变仅提升了很少的性能(仅提升0.1x),下面是为什么这么做不起作用的原因:
- 在cache命中率上没有很大的改变,这个在之前的步骤上已经做的很好了。
- 更多的寄存器被使用,导致了更少的wave,这将会损失平行性和延迟的隐藏性。
为了实验的目的,下面的方法可以装载更多的像素点:
- 读取更多的half4的向量,提升输出像素点的个数到16.
- 全局的work size: width/16 xheight
图9-5 表示了每个work item 会执行以下几个步骤:
- 每行读6个half4个向量。
- 输出16个像素点
- 每个输出像素点需要访问的内存次数为:6x9/16 = 3.375(half4)
经过这些改变后,性能从3.4x退化到0.5x。装载更多的像素点进入kernel中会引起寄存器溢出,这将会严重地损害性能。
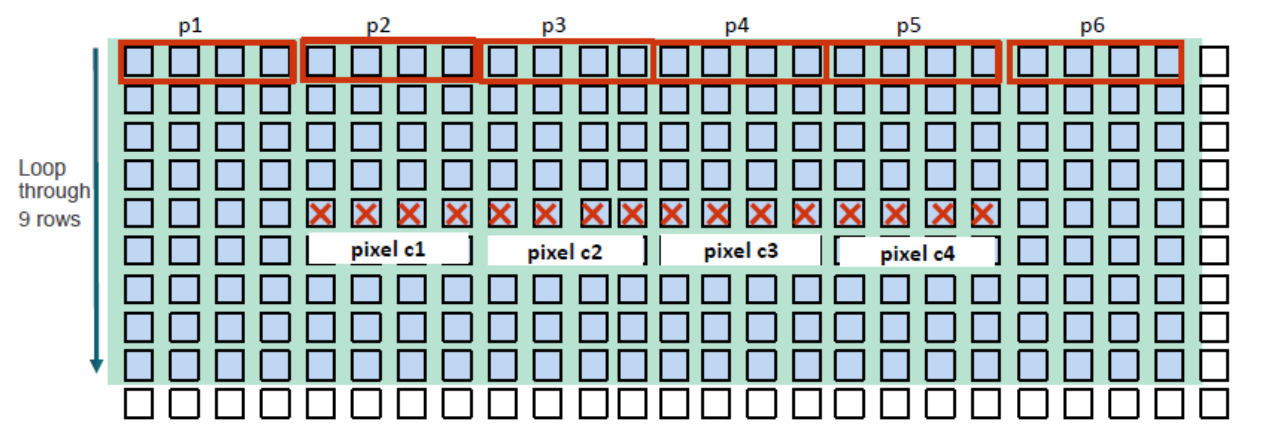
图9-5 每个work item处理16个像素
9.2.5 使用本地内存优化
本地内存比全局内存有更短的延迟,因为本地内存是片上内存。一个选择是,将像素点装载进本地内存,避免重复从全局内存中加载。而且,对于要处理的中心元素,由于9x9范围的滤波,所以它周围的元素也需要,所以如图9-6所示,装载进内存。

图9-6 使用本地内存进行Epsilon 滤波
表9-1 列出了两种情况的设置和他们的性能。整体性能比原始的要更好,然而从9.3.4节中可以看出,并没有获得最好的性能。
表9-1 使用本地内存的性能
|
|
情况1 |
情况2 |
| workgroup |
8x16 |
8x24 |
| 本地内存大小(byte) |
10x18x8=1440 |
10x26x8 = 2080 |
| 性能 |
2.4x |
2.8x |
如7.1.1节所讨论的,本地内存使用时,通常需要使用barrier进行workgroup中work item之间的同步,这样会导致性能不比使用全局内存时的好。而且,如果同步导致许多开销的话,它可能会有更差的性能。在这种情况下,如果全局内存有高cache命中率的话,那么全局内存可能是一个更好的选择。
9.2.6 分支操作的优化
Epsilon滤波需要进行像素之间的比较,如下:
Cond = fabs(c -p) <= (half4)(T);
sum += cond ? p : consth0;
cnt += cond ? consth1 : consth0;
三元素符 ?: 是发生在硬件上的分支,因为同一个wave中的不是所有的fiber都会执行相同的分支。分支操作可以被ALU 操作替代,如下所示:
Cond = convert_half4(-(fabs(c -p) <= (half4)(T)));
sum += cond * p;
cnt += cond;
这种优化方法之前就应用在9.2.2章中描述过的一个例子中,性能从3.4x提升到5.4x。
这个操作的关键差异是,新代码是在高度并行的ALU下执行,而且在同一个wave中所有的fiber基本上执行的是同一块代码,尽管变量Cond可能有不同的值,而原来的代码会使用非常耗时的硬件逻辑来处理分支。
9.2.7 总结
表9-2总结了优化的步骤和性能数据。最初,算法是内存瓶颈的。通过数据打包,向量化装载,它变成ALU瓶颈。总的来说,对于这个例子的关键是优化装载数据的方式。许多其他的内存瓶颈的用例可以使用相似的技术来加速。
表9-2 优化和性能的总结
| 步骤 |
优化方法 |
imag类型 |
kernel中的数据类型 |
向量化操作 |
速度提升 |
| 1 |
最初的GPU实现 |
CL_R | CL_UNORM_INT8 |
float |
1-pixlel/work item |
|
| 2 |
在kernel中使用half类型 |
CL_R | CL_UNORM_INT8 |
half |
1.0x |
|
| 3 |
数据打包 |
CL_RGBA| CL_UNORM_INT8 |
1.4x |
||
| 4 |
向量化处理 循环展开 |
4-pixel/work item (halt4 output) |
3.4x |
||
| 5 |
每个work item处理更多的像素 |
8-pixel/work item |
3.5x |
||
| 6 |
每个work item处理更多的像素 |
16-pixel/work item |
0.5x |
||
| 4-1 |
使用LM (workgroup 大小为8x16) |
4-pixel/work item
|
2.4x |
||
| 4-1-1 |
使用LM (workgroup 大小为8x24) |
2.8x |
|||
| 4-1-2 |
使用LM移除分支操作,workgroup大小为8x24 |
2.9x |
|||
| 4-2 |
移除分支操作 |
5.4x |
表9-3中展示了在三种分辨率的图片上使用Epsilon滤波后的OpenCL性能。从图中可以看出,越大的图像,性能提升越大。对于一个3264x2448的图像,可以看到有5.4x的性能提升,相比之言,在512x512的图像上,优化后的代码性能比最初的OpenCL代码的性能,只有4.3x的提升。这是很容易理解的,因为在不考虑任务量的情况下,消耗的时间与kernel的执行时间是正相关的,而且任务量越大,他在整个性能数据中的权重越小。
表9-3 不同分辨率的图片的性能统计
| 图片的分辨率 |
512x512 |
1920x1080 |
3245x2448 |
|
| 像素点的个数 |
0.26MP |
2MP |
8MP |
|
| 设备(A430) |
GPU的最初实现结果 |
1x |
1x |
1x |
| GPU优化后的结果 |
4.3x |
5.2x |
5.4x |
|
9.3 Sobel 滤波
Sobel滤波,也被称作Sobel操作,用在很多图像处理和计算机视觉算法的边界检测中。它使用两个3x3的kernels与原始图片结合,近似得出导数。这里有两个kernel:一个负责水平方向,一个负责垂直方向,如图9-7所示:
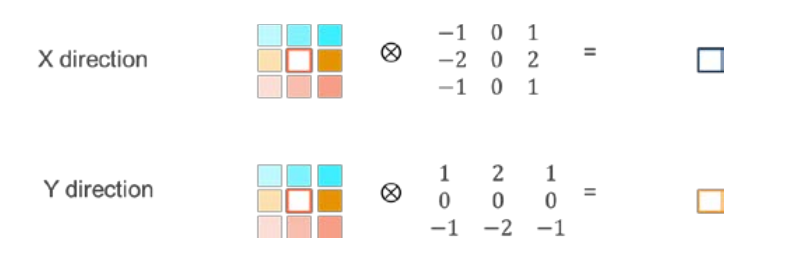
图9-7 Sobel滤波的两个方向操作
9.3.1 算法优化
Sobel的滤波是一个可分离的滤波器,可以如下分解:
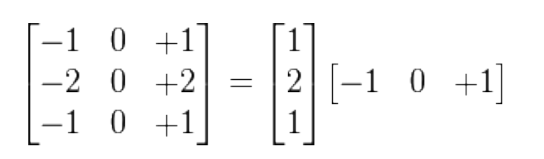
图9-8 Sobel 滤波分离
相比于不可分离的2D滤波,一个可分离的2D滤波器可能将复杂度从O(n2)降低到O(n)。由于2D的高复杂性和计算的耗时,理想的情况就是使用可分离的滤波器。
9.3.2 数据打包的优化
尽管可分离的滤波,已经减少了很多计算,但是每一个要被滤波的像素点所需要的像素点个数是一样的,比如对3x3kernel来说,需要8个邻居像素点加上中心像素点。可以明显地看出来,这个一个内存瓶颈的问题。所以,如果有效的将像素点装载进GPU是性能优化的关键。下面的图片中阐述了3种可以使用的选择:

图9-9 每个work item处理一个像素点,每个kernel装载3x3个像素点
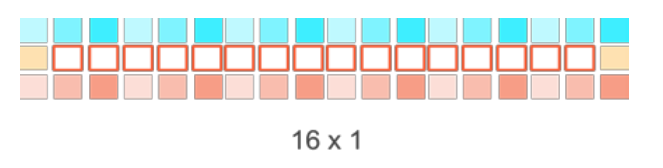
图9-10 处理16x1 个像素点,装载18x3个像素点
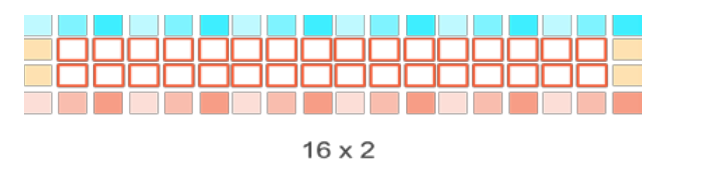
图9-11 处理16x2个像素点,装载18x4个像素点
下面的表格中总结了每种情况下总的字节数和平均字节数。对于表9-9所述的第一个种情况,每个work item只对一个像素点进行Sobel滤波。随着每个工作项处理的像素点的个数的增加,需要装载的数据数量将会减少,如9-10和9-11所示。这将会减少全局内存到GPU的数据量,从而提升性能。
表9-4 3种情况下数据装载/存储的数量
|
|
1 pixel/work item |
16x1 pixels/work item |
16x2 pixels/work item |
| 总的输入字节数 |
9 |
54 |
72 |
| 平均输入字节数 |
9 |
3.375 |
2.25 |
| 平均存储字节数 |
2 |
2 |
2 |
9.3.3 向量化的装载/存储优化
对于16x1 和16x2 这两种情况,装载/存储的次数可以通过使用OpenCL中的向量化装载存储函数进行进一步的减少,比如float4,Int4和char4等。表9-5表示了使用了向量化的情况下,需要的装载/存储的次数(假设像素的数据类型是8-bit)。
表9-5 使用向量化的装载/存储方法需要的装载和存储次数
|
|
16x1 向量化 |
16x2 向量化 |
| 装载 |
6/16=1.375 |
8/32=0.374 |
| 存储 |
2/16=0.125 |
4/32 = 0.125 |
下面是一小段向量化装载的代码:
short16 line_a = convert_short16(as_uchar16(*((__global uint4
*)(inputImage+offset))));
如下,在边界处,需要装载两个像素
short2 line_b = convert_short2(*((__global uchar2 *)(inputImage + offset +16)));
注意:每个工作项处理像素点的数量提升可能会导致严重的寄存器使用空间的压力,从而导致寄存器溢出到私有内存和性能下降。
9.3.4 性能统计和总结
在使用了两种优化步骤之后,可以看到性能的显著提升,如图9-12所示,图中在MSM8994(Adreno418)上的原始算法性能(每个work item处理单个像素点)被归一化为1.

图9-12 通过使用数据打包和向量化装载/存储带来的性能提升
为了总结,下面是这个用例优化的几个关键点:
- 数据打包提升了内存访问效率
- 向量化装载/存储是减少内存繁忙的关键点。
- 在这种情况下,优先选择更短的数据类型比如整型或者char型。
在这种情况下,没有使用本地内存。数据打包和向量化的装载/存储已经最小化了可复用数据的重叠。因此,使用本地内存并不能提升性能。
可能还存在其他的提升性能的选项,比如使用texture来替换global buffer。
9.4 总结
在这一章节中提供了一些简单的例子和代码片段来证实了前几章说明的优化规则,并且指出了性能是如何改变的。开发者可以尝试在真实的设备上使用这些步骤。由于编译器和驱动的升级,这些结果可能不会被准确的重现。但是,一般地,通过这些优化步骤,肯定会实现同样的性能提升。