機械学習における最近の研究チームは、機械学習は、パッチリリースの評価、異常検知システムを通じて達成したいと考えています。ビジネスシナリオ要約したものです。
- 収集されたデータ(リリース関連の例外ログには、アラームデータ)は、パッチがリリースされた状況を(成功、失敗)を識別する
- 鉄道模型の行動の訓練を学習マシンを選択
- (高精度)ベースの訓練を受けた最新のパッチ・リリースの予測モデルでした
典型的な機械学習 - 学習シーンを監督しました。ネットの忠実なユーザー、アプリケーションを試してみてください最近のホットML.NETとして。誰もが共有するためのエントリとしてTodayの記事、。
まずその概要を引きます:
1. ML.Netモデルビルダは、インストールの展開について説明し
2.一般的なシナリオ例
、ML.Netモデルビルダーは、インストールの展開について説明し
まず、どのようなML.Netモデルビルダーのことを?それは何をしますか?
https://marketplace.visualstudio.com/items?itemName=MLNET.07
モデルビルダーは、開発者がアプリケーションで構築、およびカスタムトレーニング機械学習モデルを公開するためのシンプルなUIツールです。
いいえ、開発者MLの専門知識は、ファイルまたはSQL Serverに格納されたデータ、トレーニングモデルに接続し、モデルのトレーニングと消費のためのコードを生成するには、このシンプルなビジュアルインターフェイスを使用することはできません。
一つの文は要約する:機械学習、モデリングツール、可視化をVSデザイナーによる機械学習モデルを構築します。サンプルコードを生成しながらガイドを再利用することができます。
1.展開をインストールします。
公式の勧告は次のとおりです。Visual Studioの2017 15.9.12以降
私はから直接VS2019とVS2017 Enterprise Editionをインストールしていたhttps://marketplace.visualstudio.com/items?itemName=MLNET.07 拡張MLNET_Model_Builder.vsix VS組立ラインオフ。インストールをダブルクリックします。
VSIXInstaller.NoApplicableSKUsException:この拡張機能は、任意の現在インストールされている製品にはインストールできません。
VSは、この拡張機能をインストールすることはできません現在インストールされている、食事グーグル、https://github.com/dotnet/machinelearning-samples/issues/451は まだ解決されていません。再インストールVS2017とVS2019自然と卵。
:最後に、VSの公式勧告見つけるのVisual Studio 2017 15.9.12以降 vs_community__425161747.1541050689にインストールVS2017を
最後に正常にインストール。
2.新しい.NET Core Consoleのプロジェクトを作成し、機械学習プロジェクトを追加
ML.Netモデルビルダーデザイナーポップ、説明は機械学習のモデリングを開始することができます。
3.機械学習モデルを開始
マイクロソフトは、主に以下の3通りの方法で、抽象的分類の機械学習とモデリングの典型的なシナリオです。
回帰:回帰クラス機械学習モデル:典型的なシナリオは、次のとおり等の価格の予測、販売予測を、
バイナリ分類:ユーザーコメント(負または正)評判分析、取引のリスク予測(またはではありません):バイナリの分類機械学習モデル、典型的なシナリオがあります
マルチ分類:多次元分類機械学習モデル。典型的なシナリオは次のとおりです。ユーザーの肖像画を、データ分類
また、ML.Netは、カスタムモデリングをサポートしています。

列車の4.サンプルデータ準備機械学習と研修ニーズ
マイクロソフトが提供する例サンプルデータとシナリオは、現在、トレーニング機械学習サンプルデータは、寸法値を決定するために、データを構造化されています。同時に、次元データの必要性は、行動ラベルの識別とラベルを予測します。
概要の概要について:
- 样本数据必须是结构化的数据,确定的列和值
- 样本数据由各个维度列和一个预测维度列组成
- 样本数据中预测维度列的值需要手工标注,以便进行机器学习训练
从上面的总结可以看出,ML.NET 属于监督学习这一类。
样本数据的格式:支持CSV(逗号间隔)、TSV(Tab间隔)和SQL Server。
至于怎么另存为TSV文件,其实很简单,Copy示例数据到文本编辑器,另存为**.tsv文件即可。https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/wikipedia-detox-250-line-data.tsv
选择输入结构化的样本数据后,要指定一个机器学习要预测的列。
5. Train训练、评估
指定输入的数据和要预测的列,进行训练。训练的过程会评估AutoML中提供的各种算法的准确度。
Train训练的时间,随数据量的不同而不同
训练完成后,会输出一个最佳准确度的算法,同时生产一个模型文件,MLModel.zip, 供后续预测使用。
6. 生成可重复执行的代码
即将ML.NET Model Builder 设计器向导的配置,生成可重复执行的代码:两个C# Project,一个Model的Project,一个Console的Project。
二、典型场景示例
第一大章节,我们将整个ML.NET的建模过程做了梳理,现在我们以微软的示例代码,做一个实践应用。
这次我们选择用户反馈情感分析这个场景,这几天我想了一下,这个场景的实际价值是:线上爬取指定产品的用户评论和反馈,通过机器学习预测出产品的热度、问题,后续进行产品完善和市场活动。
话不多说,开始吧。
1. 准备TSV数据
这个非常简单:https://raw.githubusercontent.com/dotnet/machinelearning/master/test/data/wikipedia-detox-250-line-data.tsv,这个文本拷贝到Sublime Text中,另存为data.tsv文件
2. 新建.Net Core Console 应用,右键添加 Machine Learning项目
在选择场景步骤中,我们选择第一个,“情感分析”
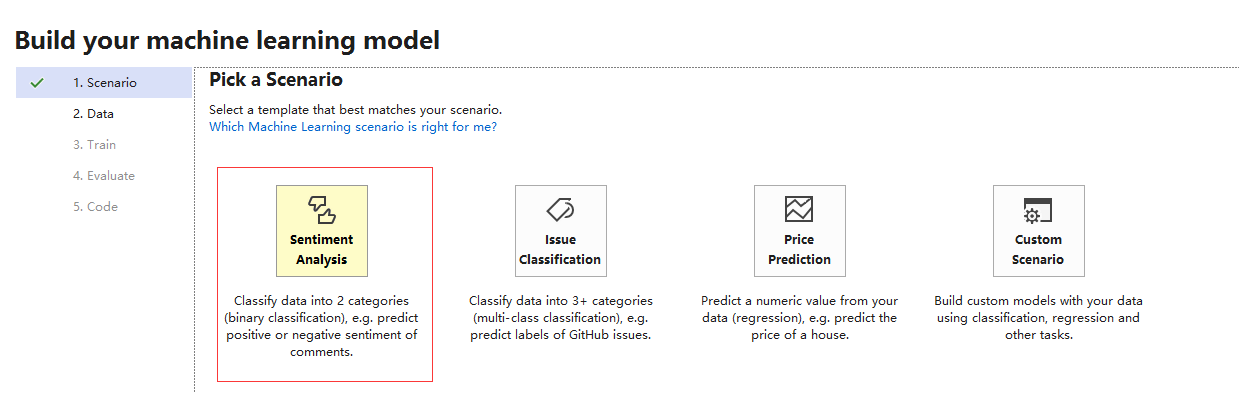
2. 选择样本数据,进行训练,预测
选择第一步我们准备好的data.tsv文件,指定一个要预测的列Sentiment
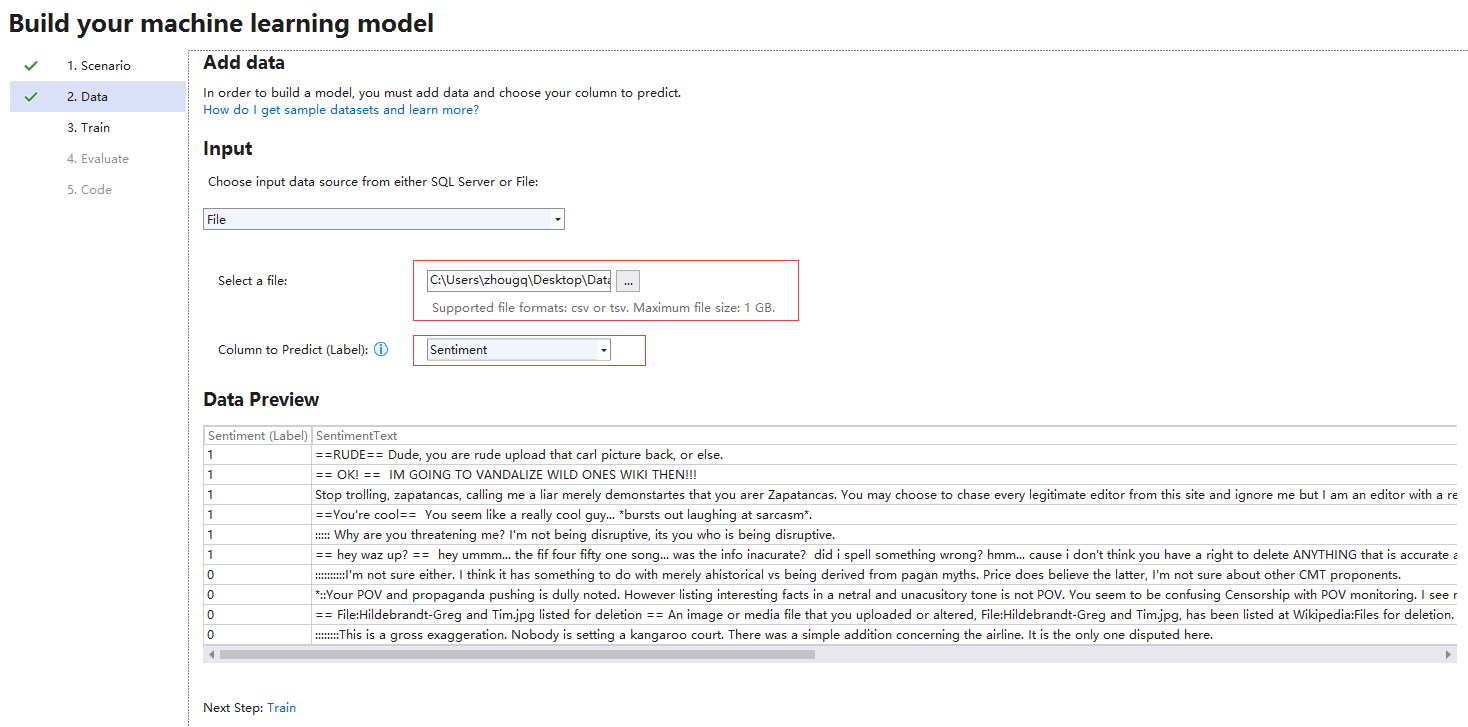
3. 开始样本数据的训练
训练的时间和数据量有关系,一般的:
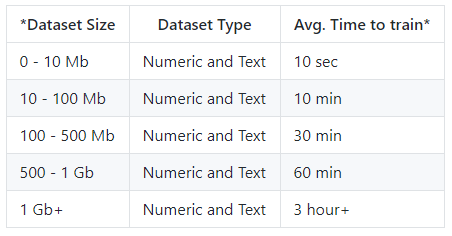
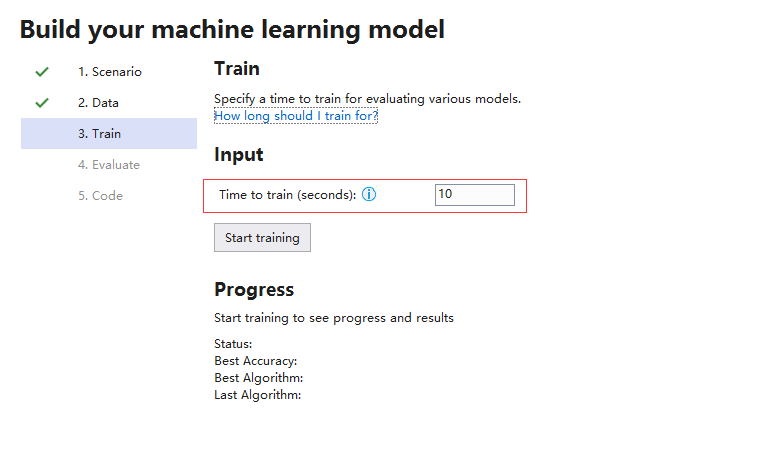
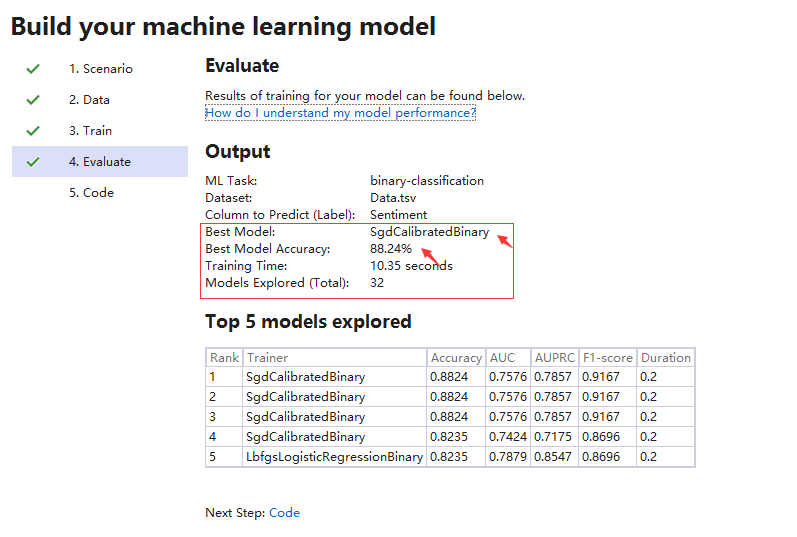
这里我们尝试了10s和30s,最近算法和准确度没有变化,只是尝试机器学习训练的算法要多:
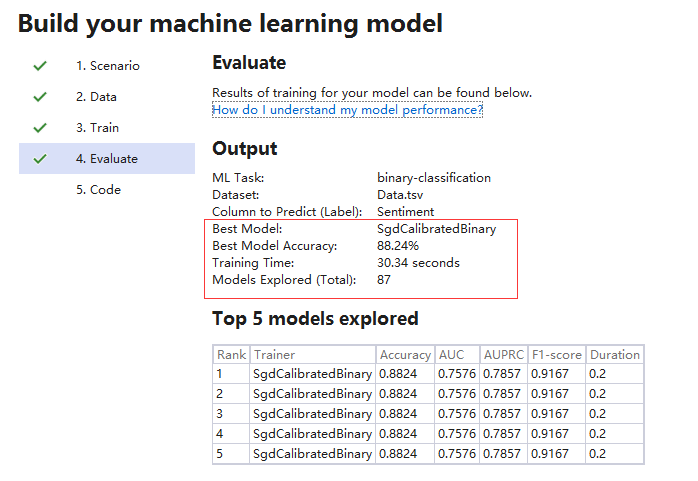
5. 生成可重复执行的代码工程

生成代码后,会在当前解决方案中多了两个Project,一个是Model的Project,一个Console的Project,我们深入看一下
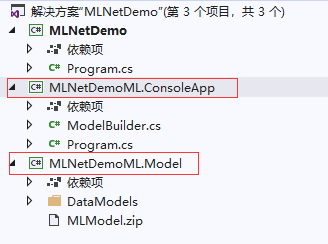
其中Model Project中主要包含:
模型的输入类和输出类,其中:
- 输入类ModelInput是对我们输入数据的结构化描述
- 输出类ModelOutput是包含预测列和评估准确度
还有一个机器学习样本数据训练完成后的MLModel.zip文件,供后续数据预测用。
Console Project中,主要形成了一个可重复执行的代码:重点看Main函数的代码:
1 //Machine Learning model to load and use for predictions 2 private const string MODEL_FILEPATH = @"MLModel.zip"; 3 4 //Dataset to use for predictions 5 private const string DATA_FILEPATH = @"C:\Users\zhougq\Desktop\Data.tsv"; 6 7 static void Main(string[] args) 8 { 9 MLContext mlContext = new MLContext(); 10 11 // Training code used by ML.NET CLI and AutoML to generate the model 12 //ModelBuilder.CreateModel(); 13 14 ITransformer mlModel = mlContext.Model.Load(GetAbsolutePath(MODEL_FILEPATH), out DataViewSchema inputSchema); 15 var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel); 16 17 // Create sample data to do a single prediction with it 18 ModelInput sampleData = CreateSingleDataSample(mlContext, DATA_FILEPATH); 19 20 // Try a single prediction 21 ModelOutput predictionResult = predEngine.Predict(sampleData); 22 23 Console.WriteLine($"Single Prediction --> Actual value: {sampleData.Sentiment} | Predicted value: {predictionResult.Prediction}"); 24 25 Console.WriteLine("=============== End of process, hit any key to finish ==============="); 26 Console.ReadKey(); 27 }
上面的代码解读一下:
- 构建一个MLContext
- MLContext上加载训练好的模型(MLModel.zip)
- 输入要预测的数据
- 预测,输出结果(ModelOutput)
上面的代码是一个点睛之笔,我们可以想象一下:
1. 每天正常的机器学习、训练,优化模型
2. 线上数据,通过Kafka、文本等数据源,实时接入数据,进行预测
3. 对预测的结果进行评估、对样本数据再纠正和标注,直至模型的准确率更高
4. 作用与线上业务决策
5. Loop
是不是很赞,很简单,很容易理解,简化了我们对机器学习的建模、算法选择和评估。生产力工具,技术普惠。
给ML.NET 点赞。
后续我们将基于ML.NET实现更多的业务场景,逐步分享给大家。
周国庆
2019/6/23