少数pytorchの基本的な考え方
記事のディレクトリ
テンソル
人工知能のこのタイプの重要な概念である
、実際に多次元配列で、同様のnumpyのは内部ndarray

、ほとんど同じndarray numpyの持つ確かに非常に便利ないくつかのテンソル行列演算を使用します。
import torch
x = torch.rand(5,3)
y = torch.ones(5,3)
z = x + y
a = torch.rand(5,3)
print(x)
b = torch.zeros( 5,3,dtype=torch.long )
print(b)
c = torch.tensor([5.5,3])
print(c)
#下面是生成一个类型为double的5,3的矩阵张量,同时,还可以指定类型。
x = x.new_ones( 5,3,dtype=torch.double)
print(x)
y = torch.randn_like(x)
print(y)
x.size()
ある出力
テンソル([1.1943、1.7771、1.9026]、
[1.7972、1.5472、1.3902]、
[1.0869、1.4934、1.1207]、
[1.3406、1.0982、1.9051]、
[1.5109、1.0314、1.4367]])
ほとんどnumpyのように、見て。ビデオチュートリアルは、なぜ私たちは、このテンソルデータはそれをタイプ費やす必要があり、すべての操作は、テンソルのndarrayに使用することができますnumpyの、言いましたか?我々は、すべてのnumpyのは、CPUのマルチコア加速すること、することができます知って加速し、テンソルより強力な、それはCUDAやGPUすることができ

ますが、行列の加算を行うCUDAを使用することができます上記のステートメントで、私の実際の経験、少し遅い速度は、それは確かだ、それがあるべき時間のかかるにCUDAの初期化。
図は、動的に計算します
- 図は、動的(ダイナミック計算グラフ)を算出PyTorchの主な特徴であります
- それは、複雑な、より柔軟なモデルを計算するために私達を許可します
- これは、任意の時点でバックプロパゲーションアルゴリズムを可能に
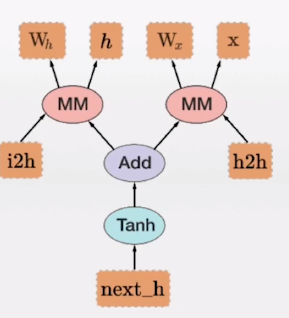
動的な計算モデルは、図のアルゴリズムです。上記のように、独自のアルゴリズムを構築するために私たちは非常に明確にしましょう、Pytorch楕円は、一連の計算を表し、四角は、変数を表し、矢印が依存関係を示します
定義された変数の自動微分
这个概念挺有趣的,这也是我之前看不大懂莫烦第一课教程的原因,网上查了一下,准备详细学习一下
在训练一个神经网络的时候,梯度的计算是一个关键的步骤,它为神经网络的优化提供了关键的数据。但是在面临复杂神经网络的时候,导数的计算就会成为一个难题,要求人们解出复杂的、高维的方程式不现实的。这就是自动微分出现的原因,当前最流行的深度学习框架如PyTorch、Tensorflow等都提供了自动微分的支持,让人们只需要少量的工作就能自动计算出复杂函数的梯度
PyTorch的autograd的简介
Tensor是PyTorch实现多维数组计算和自动微分的关键数据结构,一方面,它类似于numpy的ndarray,用户可以对Tensor进行各种数学计算;另一方面,当设置.requires_grad=True之后,在其上进行的各种操作就会被记录下来,用于后续的梯度计算,其内部实现的机制被称为动态计算图.
Variable变量:在pyTorch早期版本中,Tensor只负责多维数组的计算,自动微分的功能是由Variable来完成的。在现在的版本中,二者合二为一了
autograd机制能够记录作用于Tensor上的所有操作,生成一个动态计算图,图的叶子节点是输入的数据,根节点是输出的结果。当在根节点上调用.backward()的时候,就会从根到叶应用链式法则计算梯度。默认情况下,只有.require_grad和is_leaf两个属性都为True的节点才会被计算导数,并存储到grad中。
requires_grad属性
requires_grad属性默认为False,也就是Tensor变量默认是不需要求导的。如果一个节点的requires_grad是True,那么所有依赖它的节点requires_grad也会是True.换而言之,如果一个节点依赖的所有节点都不需要求导,那么它的requires_grad也会是FAlse。在反向传播的过程中,该节点所在的子图会被排除在外。
>>> x = torch.randn(5, 5) # requires_grad=False by default
>>> y = torch.randn(5, 5) # requires_grad=False by default
>>> z = torch.randn((5, 5), requires_grad=True)
>>> a = x + y
>>> a.requires_grad
False
>>> b = a + z
>>> b.requires_grad
True
Function类
我们已经知道PyTorch使用动态计算图(DAG)记录计算的全过程,那么DAG是怎么建立的呢?一些博客认为DAG的节点是Tensor(或说Variable),这其实是不正确的。DAG的节点是Function对象,表示数据依赖,从输出指向输入。因此,Function类在PyTorch自动微分中位居核心地位,但是用户通常不会直接去使用,导致人们对Function类了解并不多。
每当对Tensor施加一个运算的时候,就会产生一个Function对象,它产生运算的结果,记录运算的发生,并且记录运算的输入。Tensor使用.grad_fn属性记录这个计算图的入口。反向传播的过程中,autograd引擎会按照逆序,通过Function的backward依次计算梯度。

backward函数
backward函数是反向传播的入口点,在需要被求导的节点上调用backward函数会计算梯度值到相应的节点上。backward需要一个重要的参数grad_tensor,但如果节点只含有一个标量值,这个参数就可以省略(例如最普遍的loss.backward()与loss.backward(torch.tensor(1))等价),否则就会报如下的错误:
Backward should be called only on a scalar (i.e. 1-element tensor) or with gradient w.r.t. the variable
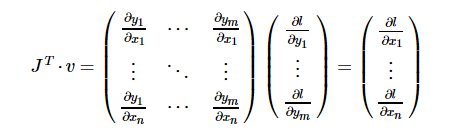
torch.autograd本质上应该是一个向量-雅克比乘积的计算引擎,计算vT⋅J,而所谓的参数
grad_tensor就是这里的v。由定义容易知道,参数grad_tensor需要与Tensor本身有相同的size。通过恰当地设置grad_tensor,容易计算任意的骗到组合。
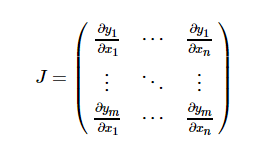
反向传播的过程一般用来传递上游传来的梯度,从而实现链式法则,简单的推导如下:
注意梯度是累加的
backward函数本身没有返回值,它计算出来的梯度存放在叶子节点的grad属性中。Pytorch文档中提到,如果grad属性不为空,新计算出来的梯度值会直接加到旧值上面。
为什么不直接覆盖旧的结果呢?这是因为 有些Tensor可能有多个输出,那么就需要调用多个backward。叠加的处理方式使得backward不需要考虑之前有没有被计算过导数,只需要加上去就行了,这使得设计变得更简单,因此我们用户在反向传播之前,常常需要用zero_grad函数对导数进行手动清零,确保计算出来的是正确的结果。
autograd的一些其他知识点
要阻止一个张亮被跟踪历史,可以调用.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。
为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad() :中。在评估模型时特别有用,因为模型可能具有requires_grad = True的可训练的参数,但是我们不需要在此过程中队他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。
Tensor和Function互相连接生成了一个非循环图,它编码了完整的计算历史。每个张量都有一个.grad_fn属性,它引用了一个创建这个Tensor的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是None),我的理解是每一个计算的过程都会生成一个新的张量,这个张量的Function就是跟该计算过程相关的.
如果需要计算导数,可以在Tensor上调用.backward()。如果Tensor是一个标量(即它包含一个元素的数据),则不需要为backward()指定任何参数,但是如果它有更多的元素,则需要指定一个gradient参数,它是形状(size)匹配的张量。
例子
x = torch.ones( 2,2,requires_grad=True )
print(x)
输出
tensor(
[[1.,1.],
[1.,1.]], requires_grad=True )
对这个张量做一次运算。
y = x + 2
print(y)
输出
tensor([[3., 3.],
[3., 3.]], grad_fn=)
y是计算的结果,所以它有grad_fn属性。
printf(y.grad_fn)
输出:
<AddBackward0 object at 0x7f1b248453c8>
猜想这个应该是一个关于加法的function
再对y进行更多的操作
z = y * y * 3
out = z.mean()
print( z,out )
输出:
tensor([[27., 27.],
[27., 27.]], grad_fn=) tensor(27., grad_fn=)
看看,从名字上看z这个张量的对应的grad_fn是一个关于乘法的function,而out是一个关于均值的grad_fn
.requires_grad_(...)は、既存の場所テンソルrequires_gradマークを変更することができます。指定されていない場合は、このフラグのデフォルトの入力はFalseです。
勾配
アウトがスカラーであるので、それでは逆伝搬、out.backward()を直接聞かせout.backward(torch.tensor(1.))と等価です
out.backward()
出力派生D(アウト)/ DX
プリント(x.grad)
#出力
テンソル([4.5000、4.5000]、
[4.5000、4.5000]])
、本質的に、偏導関数の各コンポーネントにスカラー関数を次のように計算しました。

Y = F値(x)関数場合は数学的に、Xに対する勾配は、yはヤコビ行列である:
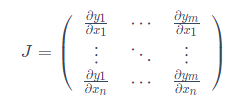
一般的に言えば、torch.autogradはベクトル積のヤコビ行列を計算することである「エンジン」。すなわち、任意のベクトルv所与=

コンピューティング製品Jvを。vはスカラー関数であることを起こる場合 = Vで
= Vで
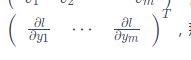
のxの鎖ルールヤコビ行列ベクトル積べきL誘導体
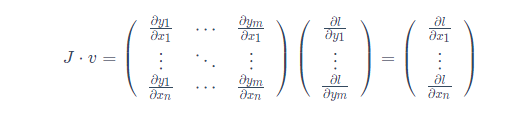
、この機能のヤコビ行列ベクトル積外側傾斜が出力非スカラとなる有するモデルに入力されるように便利
x =torch.randn(3,requires_grad=True)
y = x*2
while y.data.norm() < 1000:
y = y * 2
print(y)
#上面的y函数是一个标量函数,autograd不能直接计算完整的雅克比矩阵,但是只想要雅克比向量积,只
#需要将这个向量作为参数传给backward
v = torch.tensor( [0.1,1.0,0.001],dtype =torch.float )
y.backward(v)
print(x.grad)