免責事項:この記事はブロガーのオリジナルの記事、再現され、ソースhttps://blog.csdn.net/C2681595858/article/details/85687836を明記してください
記事のディレクトリ
テストコード(GitHubの)
まず、実験の内容
1、ダイクストラ最短パスアルゴリズム。
- テストチャート
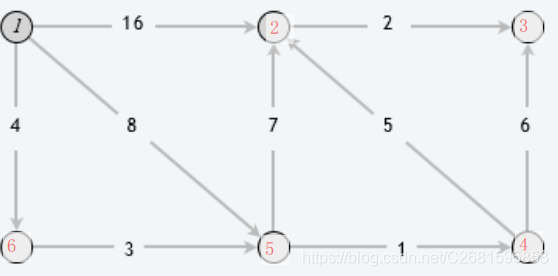
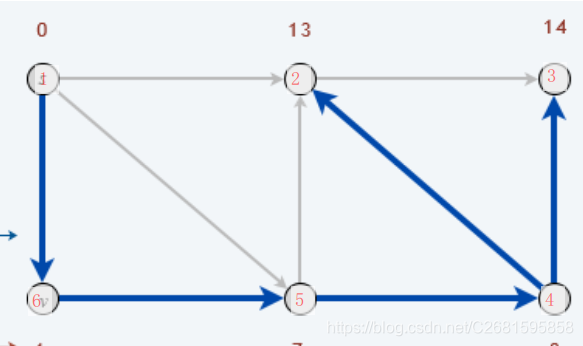
- 期待される結果:
2、ベルマン - フォード最短経路アルゴリズム
- テストチャート
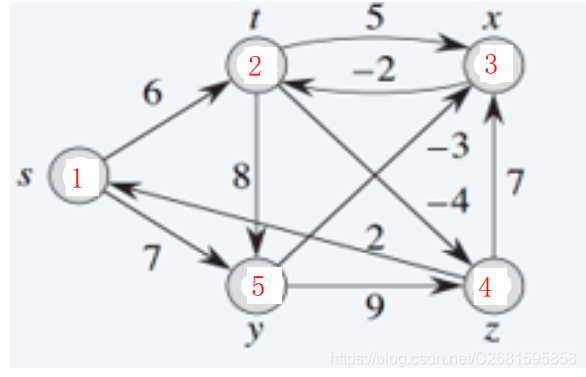
- 期待される結果

第二に、理論的な準備
1、ダイクストラアルゴリズム
- 最大の特徴は、各頂点のための安全装置であります の値は、最短経路長が既に知られているを通して、原点からその点にあります。そして、頂点を選択されていないミックスに追加 最小の頂点の値はミックスに追加し、次いで変性頂点に隣接する頂点と直ちに混合物に加えます のすべての頂点がミックスに追加されるまで値は、循環してきました。
- それは2つのステップを持っている限り、頂点は未定更新されます 値、及び他の更新の頂点から選択されます 一つの頂点の最小値は、ミックスに追加する、つまり、それは頂点決意なります。そして、狙いを更新することを選択したことにあります
- 擬似コードは次のよう:

- ここで減少キー()は、キュー内の頂点vキーの値を小さくすると述べました。
- 特別な注意、各更新プライオリティキュー [V]の時間であります 。学过最小生成树的同学知道有一个prim算法与dijkstra算法非常相似,但是注意他们并不相同,prim算法每次用定点u到v之间的权重去更新优先队列中v的key值,不需要加上 .
2、bellman-ford算法
- 算法思路:
核心思想是:首先对距离进行松弛,然后随着迭代次数的增加,距离越来越接近最短路径,直到最后得出最短路径。
更具体一点说就是每一次检查每一条边(u,v),看是否有 情况,如果有就更新d[v]的值,这样一来每一遍大的循环就把源点的情况全局推进一步,然后最多推进n-1步也就把原点的情况推到了每一个节点。 - 伪码:

- 伪码解读:
- 在内部的两层循环中看似是两层循环应该有 的复杂度,但是它真正是m的复杂度,这是为什么呢?
- 首先思考bellman-ford算法最初的想法,他是每次查看一条边是否满足 情况。所以那两层内层循环实质上是在便利所有的边,所以它的复杂度只是边的条数m,而不是 .
3、 两个算法的使用环境。
- ダイクストラ法は、右の負の側面を描くには適していません。
- 補題1:リングがsの負〜vを含んでいる場合、それは最短経路ではありません。
- 補助定理2:負ラップがない場合、それは最短経路と最短経路までのn-1個のエッジを含む、n個の頂点の数でなければなりません。
- ベルマン・フォードは負の側面を有していてもよく、しかし、負の側面がある場合、我々は負の円を持っていなければなりません。
- 負の円:円と負のそれぞれの側に。ここでは、負極側と負側がリングであることを注意してください、しかし、リングは必ずしも否定円ではありません。
第三に、実験環境
- オペレーティングシステムとバージョン:windows10
- コンパイラソフトウェアとバージョン:G ++ 6.3.0
- 使用されるコンピュータ言語:C言語
第四に、実験
- 実験であった以前の実験に基づいて完成します。
1、ダイクストラアルゴリズム
- アルゴリズムと理論的な製造方法は次のようにコアコードは、同じです。
void Graph::dijkstra(int startId)
{//先把它从队列中删除,然后找到它的邻居顶点并更新节点的值直到队列为空
Pritree<Vertex> pritree;
initialForDij(pritree, startId);
while(pritree.getSize() != 0)
{
Vertex temp = pritree.popHead();//找到discovery最小的值
Vertex* vertexp = findVerAccId(temp.getVertexId());
Node* neighbor = vertexp->getHeadNode();//找到邻居节点
// cout<<temp.getVertexId()<<"-> ";
while(neighbor != NULL)//对每一个邻居节点进行循环中的操作
{
Vertex* tempNe = neighbor->getVertex();//与弹出来的顶点相邻的顶点
if(tempNe->getDiscovery() > temp.getDiscovery() + neighbor->getWeight())
{
tempNe->setDiscovery(temp.getDiscovery() + neighbor->getWeight());
tempNe->setParent(vertexp);//记住其父节点
pritree.delete_ele(*tempNe, equal);//从优先队列中删除
pritree.insert(*tempNe);//然后插入新的更新后的顶点
}
neighbor = neighbor->getNextNode();
}
}
//打印出最后的结果
Vertex* for_out_ver = this->headVertex;
cout<<"dijkstra:"<<endl;
while(for_out_ver != NULL)
{
for_out_ver = for_out_ver->getNextVertex();
if(for_out_ver != NULL)
cout<<(for_out_ver->getParent())->getVertexId()<<"->"<<for_out_ver->getVertexId()<<endl;
}
}
2、ベルマン - フォード法
- 擬似コードの理論的準備と実施が同じである、それは言葉のダイクストラアルゴリズムよりもアイデアの実現は簡単であるべきだが、その複雑さが高くなっています。
void Graph::bellmanFord(int startId)
{
//初始化
Vertex* vptr = this->headVertex;
while(vptr != NULL)
{
if(vptr->getVertexId() == startId)
vptr->setDiscovery(0);
else
vptr->setDiscovery(INT_MAX);
vptr->setParent(NULL);
vptr = vptr->getNextVertex();
}
//最外层迭代顶点数目减一次
for(int counter0 = 1; counter0 < this->vertexNumber; counter0++)
{
vptr = this->headVertex;
while(vptr != NULL)//遍历每一个顶点
{
Node* eptr = vptr->getHeadNode();
while(eptr != NULL)//遍历每一条边
{
Vertex* vtoptr = eptr->getVertex();
if( vtoptr->getDiscovery()> vptr->getDiscovery()+eptr->getWeight())
{
vtoptr->setDiscovery(vptr->getDiscovery()+eptr->getWeight());
vtoptr->setParent(vptr);
}
eptr = eptr->getNextNode();
}
vptr = vptr->getNextVertex();
}
}
Vertex* for_out_ver = this->headVertex;
cout<<"bellman-ford:"<<endl;
while(for_out_ver != NULL)
{
for_out_ver = for_out_ver->getNextVertex();
if(for_out_ver != NULL)
cout<<(for_out_ver->getParent())->getVertexId()<<"->"<<for_out_ver->getVertexId()<<endl;
}
}
第五に、実験結果
- 実験で内容によって与えられた図のテストは、次のアルゴリズムの実行の結果であり、一方のエッジの数を表すの一対。
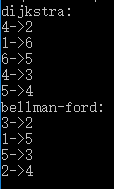
- これらの二つの異なるアルゴリズムの結果は、図試験は、もちろん、また、アルゴリズムをテストするために、図のベルマン・フォードの負側なく、同じ使用されないことに留意されたいです。
シックス・実験概要
- ダイクストラアルゴリズムを記述するためのアイデアは非常に明確であるが、常にバグが記述されている場合は、バグが本当に長い時間のために、デバッグを書くために半分の時間を要し、最終的な理由は、十分に気をつけませんでした一時オブジェクトは、内に堆積間違わアドレスリスト、最後のアクセス時のエラー。達成するために、動的優先度キュー・アレイ、長いチェックもたらす最初のものを格納することなく、対応する添字及びPPT、ダイナミックアレイの位置のためのように疑似コード、書き込み機能delete_eleは無視最後の時間、。