より柔軟な動作設定着メロのAndroid携帯電話、あなたが好きな歌を聞く、我々はすぐにクリップに切断した後、この曲に合わせて、システム・インターフェースを介して可能なリングに(などの電話の着信音、アラーム音など)を設定されています。前提は、曲をカットする機能を提供する必要性を、この曲のAPPを再生していることです。
だから、どのようにオーディオファイルの傍受機能にそれを達成するために?
以前の報告に基づいて、あなたはそれのような、達成するためにFFmpegのコマンドを使用するのが自然だと思うかもしれません。
ffmpegの-ss 10 -i audio.mp3 -t 5 out.mp3
最初の10秒から出発して、上記のコマンド、抽出部5秒なので、その断片正常傍受。しかし、FFmpegのコマンドを簡単にPC上で使用することができますが、APPは、直接使用することはできません電話で(実際には、ことも可能であり、ffmpegのコマンドはAPPに直接呼び出すことができますが、これはここでのポイントはありません)。
ここでAndroidプラットフォームのため、オーディオファイルを切断する方法を紹介し、そして、元のオーディオファイルがM4A形式に包装されていると仮定。
この記事では、Androidプラットフォーム上でM4Aオーディオファイルをカットし、オーディオクリップを取得する方法について説明します。
この機能を達成するために、2つの基本的なオプションがあります。
- まず、元のオーディオファイルを復号化し、対応するセグメントを抽出し、この断片をコードします。
- 第二は、新しいオーディオファイルとして保存し、断片を抽出し、作物の先頭に直接位置しています。
対照的に、第1実施形態では、より顕著な消費性能を有しているが、この方式は取るオーディオでき(復号化、符号化、および最終的に固定されたフォーマットに限り)フォーマット。
2番目のオプションは、我々は、最初のオプションよりも少ない時間を達成するために(元の音声だけでなく、最終的に音声フォーマットを含む)異なるフォーマットを検討する必要がありますが、支配的なパフォーマンスインチ
ここで小さな第二の実施形態を実現する方法、およびのみ考慮取らM4A生成されたファイルです。2番目のオプションは、要約は、ある世代のプロセス分析とM4AのM4Aファイル形式。
(A)M4A紹介
M4Aファイル、実際にmp4ファイル(MP4A)は、一般的にオーディオストリームを保存します。名前からM4A Appleは、ビデオフレームとの一般的なMP4ファイルを区別します。
M4Aファイル形式の解析ライト・ファイルに対して同じ理由であるMP4ファイルフォーマットを、解析することです。
採取M4A断片には、M4Aファイル形式、等のサンプルレート、チャンネル数、サンプル数、総フレーム数、各フレームの長さ、オフセットフレーム毎、等の情報を(解析する必要があります)、ファイルフォーマットを解析中に、あなたはMP4ファイルフォーマットを理解する必要があります。
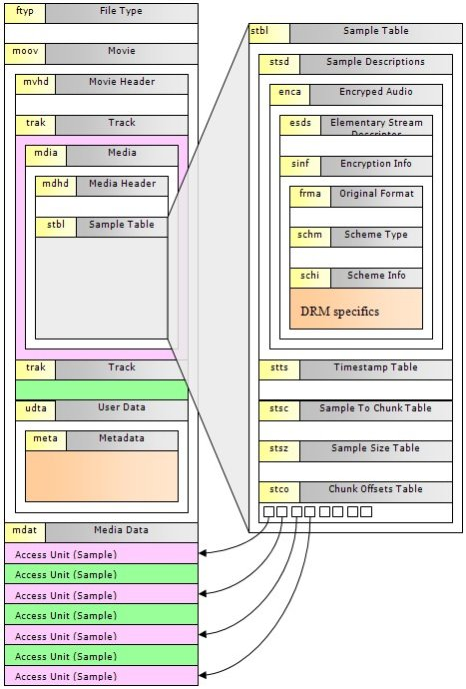
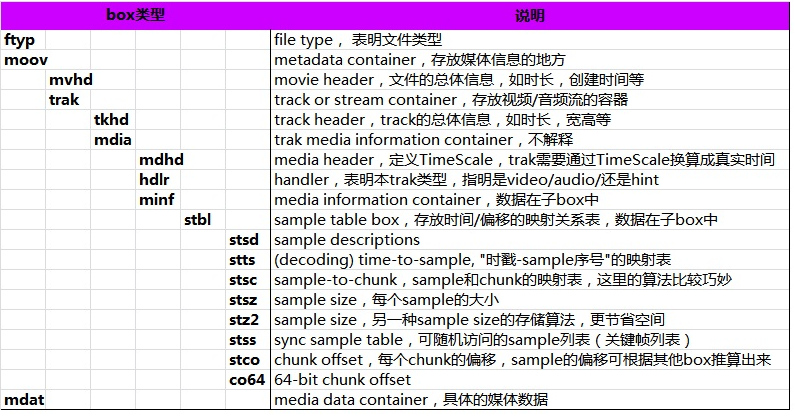
原子(または被呼ボックス)構成にMP4は、(音声データ情報と裸を含む)すべてのデータは、アトムに配置されます。
各原子は三つのフィールドで構成されています。
len(整个atom的长度,4Byte)、
type(atom的类型,4Byte)、
data(atom保存的数据)。原子は入れ子にすることができます。
すべてのタイプが有効なmp4ファイルを形成するために存在している必要がありません原子の多くの種類があります。しかし、原子のいくつかの種類があることは必須です。
ftyp(标识文件格式)、
stts(每一帧的样本数)、
stsz(每一帧的长度)、
stsc(帧与chunk的关系表)、
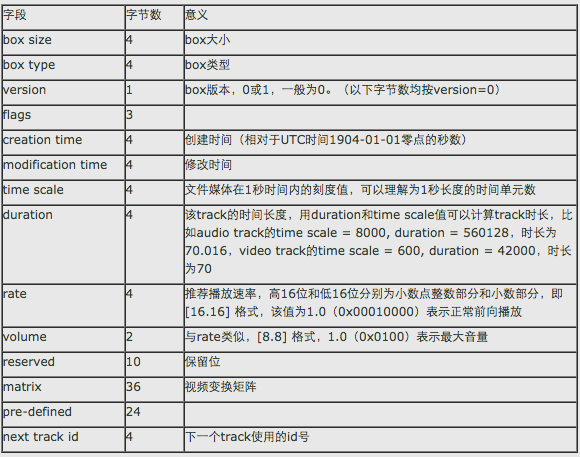
mvhd(时长等信息)、
mdat(裸数据)、
moov等。ネットワーク上のリソースを見ることができる(各原子の意味、および各フィールドのサイズの意味を含む)特定の構造は、(最良原子フォームフィールドを見て)。
例えば:
(B)を実現するためのプログラムを
第2のスキームを実現するには、このオープンソースプロジェクトをRingdroidでは使用することができます。
Gitのメンテナンス上のRingdroidでは、再符号化方式の最新バージョンをデコードするためにそれを使用して、このバージョンでは、この記事を必要としません。どのようにそれを行うには?Ringdroidでは、以前のバージョンを取得することができ、そこCheapAAC、CheapMP3など、さまざまなオーディオフォーマットとして扱われ、直接取られます。
CheapAACのReadFileは、新しい書き込みM4Aファイルを完成WRITEFILE、M4Aファイルの構文解析を完了します。
CheapAACは、図1のオーディオ波形を表示するために使用することができる達成ゲインを算出します。
傍受のために、いくつかの重要な情報があります長さ{すなわち、フレームのバイト数は}、{}これら二組によれば、フレームオフセットが取ら達成することができます。
フレーム長(とフレームの合計数)解析stszはMDATを解析するときにフレームオフセットを決定し、決定されたとき。
あなたは、傍受のプロセスを理解するためにCheapAACコードを読み取ることができます。ここだけの小さなCheapAACの問題を言及するための方法が、また、あなたが持つかもしれ質問があります。
(1)対応neroAacEncエンコードされたM4Aファイルではありません
neroAacEncアウトM4Aファイルのエンコーディングについて、CheapAACはparseMdat、データがneroAacEnc裸、8バイトの前に8バイトのデータフレームごとに計算されますオフセットするようにしているので、多くを支払う、適切に裸解決できない場合いいえ、各フレームのその後のWriteFileデータ中に記述された原因は右ではありません。
8バイト(ネロを符号化する際にM4Aが決定される)は、この問題を解決すると考えることができるスキップ。
if (mMdatOffset > 0 && mMdatLength > 0) {
final int neroAACFrom = 570;
int neroSkip = 0;
if (mMdatOffset - neroAACFrom > 0) {
FileInputStream cs = new FileInputStream(mInputFile);
cs.skip(mMdatOffset - neroAACFrom);
final int flagSize = 14;
byte[] buffer = new byte[flagSize];
cs.read(buffer, 0, flagSize);
if (buffer[0] == 'N' && buffer[1] == 'e' && buffer[2] == 'r' && buffer[3] == 'o' && buffer[5] == 'A'
&& buffer[6] == 'A' && buffer[7] == 'C' && buffer[9] == 'c' && buffer[10] == 'o'
&& buffer[11] == 'd' && buffer[12] == 'e' && buffer[13] == 'c') {
neroSkip = 8;
}
cs.close();
}
stream = new FileInputStream(mInputFile);
mMdatOffset += neroSkip; // slip 8 Bytes if need
stream.skip(mMdatOffset);
mOffset = mMdatOffset;
parseMdat(stream, mMdatLength);
} else {
throw new java.io.IOException("Didn't find mdat");
}(2)の長さの断片を取っていない場合
断片の期間傍受は長いまだ元のファイルを使用し、リセットされません。
最終用途がメディアプレーヤを再生する場合のフラグメントは長いWriteFile関数の内部再配置、それを注意してもよいし、次のコードは、添加されていないためなどのFFmpegと矛盾復号メディアプレーヤのプロセス。最終的にFFmpegは等を復号する場合、長いセグメントをリセットする必要があります。
// 在写完stco之后,增加:
long time = System.currentTimeMillis() / 1000;
time += (66 * 365 + 16) * 24 * 60 * 60; // number of seconds between 1904 and 1970
byte[] createTime = new byte[4];
createTime[0] = (byte)((time >> 24) & 0xFF);
createTime[1] = (byte)((time >> 16) & 0xFF);
createTime[2] = (byte)((time >> 8) & 0xFF);
createTime[3] = (byte)(time & 0xFF);
long numSamples = 1024 * numFrames;
long durationMS = (numSamples * 1000) / mSampleRate;
if ((numSamples * 1000) % mSampleRate > 0) { // round the duration up.
durationMS++;
}
byte[] numSaplesBytes = new byte[] {
(byte)((numSamples >> 26) & 0XFF),
(byte)((numSamples >> 16) & 0XFF),
(byte)((numSamples >> 8) & 0XFF),
(byte)(numSamples & 0XFF)
};
byte[] durationMSBytes = new byte[] {
(byte)((durationMS >> 26) & 0XFF),
(byte)((durationMS >> 16) & 0XFF),
(byte)((durationMS >> 8) & 0XFF),
(byte)(durationMS & 0XFF)
};
int type = kMDHD;
Atom atom = mAtomMap.get(type);
if (atom == null) {
atom = new Atom();
mAtomMap.put(type, atom);
}
atom.data = new byte[] {
0, // version, 0 or 1
0, 0, 0, // flag
createTime[0], createTime[1], createTime[2], createTime[3], // creation time.
createTime[0], createTime[1], createTime[2], createTime[3], // modification time.
0, 0, 0x03, (byte)0xE8, // timescale = 1000 => duration expressed in ms. 1000为单位
durationMSBytes[0], durationMSBytes[1], durationMSBytes[2], durationMSBytes[3], // duration in ms.
0, 0, // languages
0, 0 // pre-defined;
};
atom.len = atom.data.length + 8;
type = kMVHD;
atom = mAtomMap.get(type);
if (atom == null) {
atom = new Atom();
mAtomMap.put(type, atom);
}
atom.data = new byte[] {
0, // version, 0 or 1
0, 0, 0, // flag
createTime[0], createTime[1], createTime[2], createTime[3], // creation time.
createTime[0], createTime[1], createTime[2], createTime[3], // modification time.
0, 0, 0x03, (byte)0xE8, // timescale = 1000 => duration expressed in ms. 1000为单位
durationMSBytes[0], durationMSBytes[1], durationMSBytes[2], durationMSBytes[3], // duration in ms.
0, 1, 0, 0, // rate = 1.0
1, 0, // volume = 1.0
0, 0, // reserved
0, 0, 0, 0, // reserved
0, 0, 0, 0, // reserved
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // unity matrix for video, 36bytes
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0x40, 0, 0, 0,
0, 0, 0, 0, // pre-defined
0, 0, 0, 0, // pre-defined
0, 0, 0, 0, // pre-defined
0, 0, 0, 0, // pre-defined
0, 0, 0, 0, // pre-defined
0, 0, 0, 0, // pre-defined
0, 0, 0, 2 // next track ID, 4bytes
};
atom.len = atom.data.length + 8;(C)他の概念
CheapAACでは、一部のオーディオコンセプト、簡単に説明するための小さな道を関与。
track,即轨道(音频或视频),也叫流;
sample,理解为帧(跟样本的概念不同),对于aac来说一帧包括的样本数是固定的,都为1024个;
chunk,即块,是帧的集合。neroAccコマンド例:
ffmpeg -i "1.mp3" -f wav - | neroAacEnc -br 32000 -ignorelength -if - -of "1.m4a"
-br 码率
-lc/-he/-hev2 编码方式,默认是he
-if 输入文件
-of 输出文件
-ignorelength 在以其它输出(如ffmpeg)作为输入时使用このように、Androidプラットフォームの実現にM4Aが終了切断紹介します。
要約すると、本論文では達成M4AファイルのフラグメントアプローチをカットするCheapAACを使用して、Androidプラットフォーム上で説明するだけでなく、コンセプトM4A構造と可能性のある問題を紹介します。
