いくつかの音楽サイトで一般的な、クールな犬間違いなく最高のクロールの問題では、良くなって暗号化されませんでした、何を曲げなかったので、エントリーホワイト爬虫類のために最も適しました
白爬虫類ゼロベースに対するBenpianは、私はスクリーンショットや詳細な説明は、実際には、私自身が最終的な分析では、長ったらしいを見てきましたしているすべてのステップは、2つのステップを依頼することですが、ギャング回り道をスプレーしないでください。
1.クールGouguanネットワーク、検索ボックスを見ることができ、我々は、曲を検索した後、戻ってクールな犬は曲ごとに曲と曲の情報のリストを返すようにされたデータをクロールする必要がある(歌詞、作者、URL等)
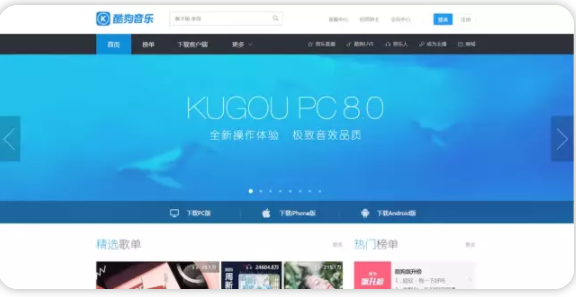
(これはすべてのクールな犬のフォアグラウンドであると要求リストを相互作用)すべて - 2は、開発者モードで、[ネットワーク]を入力するためにF12キーを押します
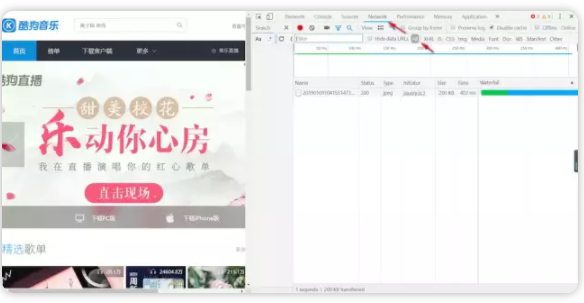
3、コンテンツを検索するための検索ボックス、そしてあなたは、リストの多くがあるだろう見ることができる権利、これで事実内部の検索データのリストに、私はあなたがその名前に応じて、このsong_searchを見つけることができますマーク赤いボックスを(持っている、そうではありません彼らはコンテンツを探しているかどうかを確認するために一つ一つを開くためのポイント)
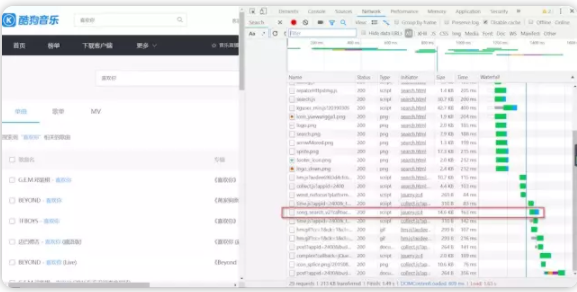
図4に示すように、ラインを開く、スイッチングがプレビューJSONデータ関連する結果の上に発見され、データリストの一覧を示しています
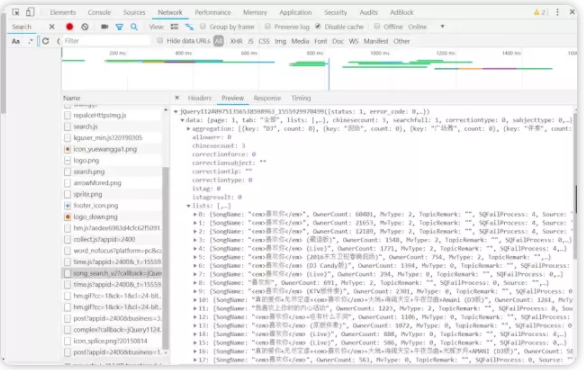
5など、ソング名、作者、ALBUMID、ファイルハッシュの曲情報が含まれている曲を、開きます

6、私たちは上記のヘッダに切り替え、その後、あなたはRequestURL(つまり、リクエストURLである)を参照することができ、矢印の下にGETリクエストを見ることができます
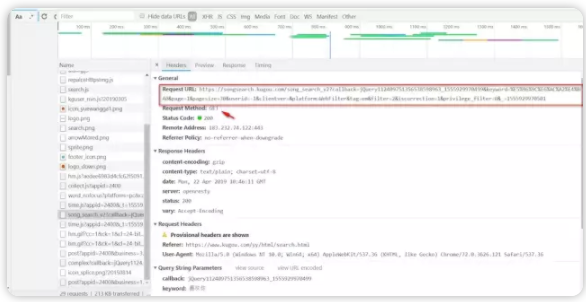
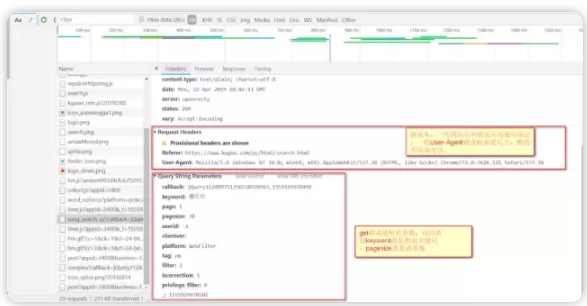
7、滑落、あなたはRequsetヘッダを(headesを検証します。このバックエンド、一般のユーザーエージェントがリクエストを書くために必要であり、いくつかのより多くの部分の検証は、あなたが、クールな犬はヘッダを書いていない、検証をしなかった場合の処理を見てする必要があります見ることができますリクエストすることもできます)とリクエストパラメータ(要求されたパラメータ、キーワード検索、リクエスト数やその他の情報)
8は、我々が直接要求のPythonライブラリを構築要求(直接Baiduはライン上に設置)を使用し、あまり話をしなかった、私の環境ではpython2.7、ノートバージョン違いののpython3です
#coding=utf-8import requestssearch = '喜欢你' #搜索内容pagesize = '10' #请求数目url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery11240251602301830425_1548735800928&keyword=%s&page=1&pagesize=%s&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1548735800930' % (search,pagesize)res = requests.get(url) #requests发起get请求print res.text #输出响应内容
-
出力は、戻りJSONはすべてのコンテンツ、情報を印刷見ることができるようなものである、とこれは同じを参照するには、単にブラウザの開発者向けツールであります

10、私たちはそれぞれの曲の特定の情報の一覧を取得するには、ブラウザに、リストを取得し、その後、左は詳細ページに最初のクリックを選択
11、ページへのジャンプを演奏見ることができ、ページを更新し、再びそれをリロード
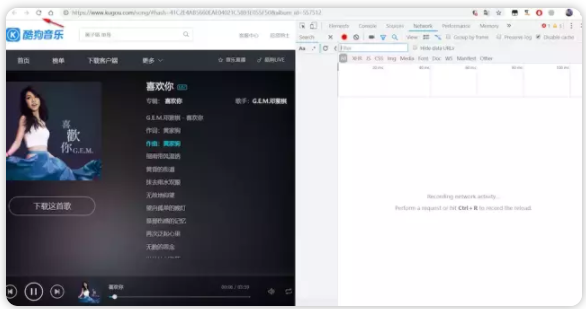
12、可以看到右侧红色框圈起来的就是歌曲信息(你可能问我怎么知道哪个才是包含歌曲信息的,当然是观察法了,写多了就有经验了,实在不会一个个点进去看)
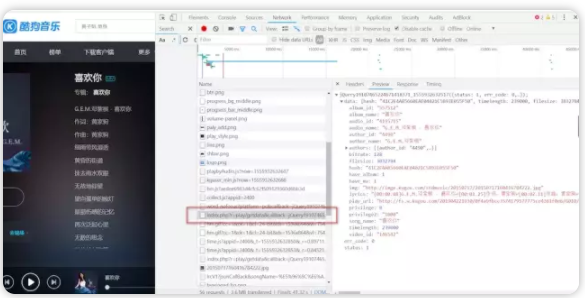
13、我用箭头标注的都是一般需要爬取的有用信息,可以看到作者,歌曲名,歌词,专辑图片,id,play_url都在里面,不信你把play_url复制到地址栏回车播放的肯定是这个歌曲,拿到这个url我们就可以直接下载歌曲了
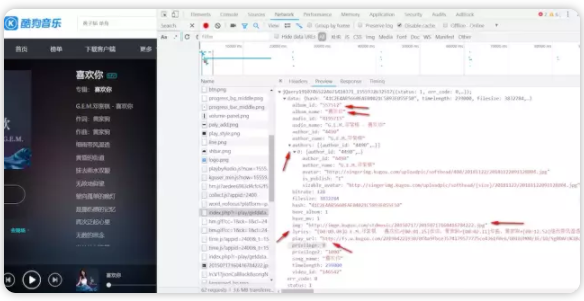
14、接着我们再从上方从Preview切换到Headers,可以看到和请求歌曲列表差不多,还是GET请求
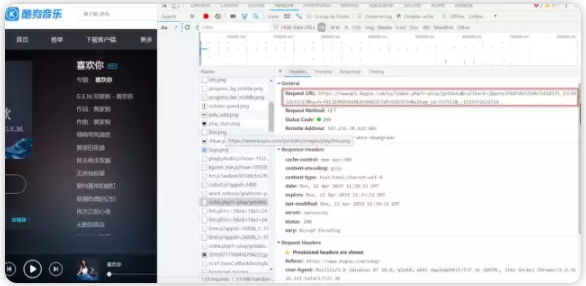
15、这里的query同样还是GET请求的参数,其中hash和album_id就是一首歌曲的信息,我们只需要请求不同歌曲时改这两个参数就行了(第一步请求搜索列表每一行单曲数据包含这个参数了)
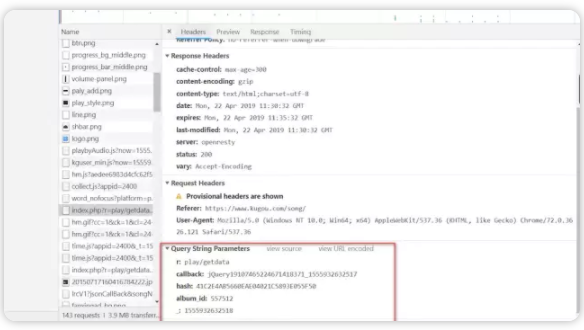
16、直接刚才根据开发者模式里面的RequestURL,构造get请求,请求每首歌曲时换上每首歌对应的id和hash值就行
#coding=utf-8import requests#在这里,为了分步演示,直接用刚才第一步搜索时开发者模式获取到的搜索列表第一条的id和hash#文章最后有整个连贯的代码id = '557512' #单曲idhash = '41C2E4AB5660EAE04021C5893E055F50' #单曲hash值url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19107465224671418371_1555932632517&hash=%s&album_id=%s&_=1555932632518' % (hash,id)res = requests.get(url)print res.text
-
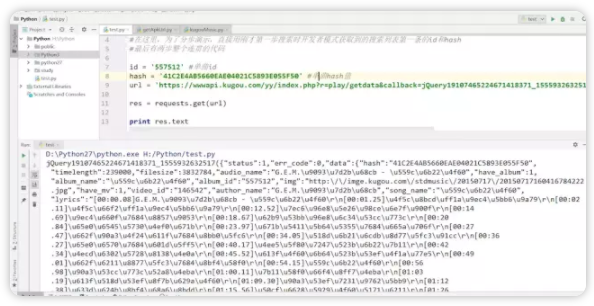
可以看到控制台打印了单曲信息,因为是json数据没有转换,直接输出打印现在看起来有点乱
-
注意,酷狗返回数据并不直接就是json格式,两端有一些无用字符串,需用正则表达式去除,只保留大括号{}里面(包括大括号)内容,19步骤代码里有说明
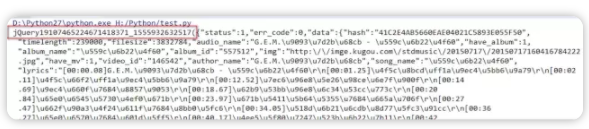
19、我们已经熟悉了上面的两步,最后进行汇总写一个完整的python爬虫,输入搜索歌曲,拿到搜索列表并包括单曲信息
# coding=utf-8import requestsimport jsonimport re# 请求搜索列表数据search = raw_input('音乐名:') # 控制台输入搜索关键词pagesize = "10" # 请求数目url = 'https://songsearch.kugou.com/song_search_v2?callback=jQuery11240251602301830425_1548735800928&keyword=%s&page=1&pagesize=%s&userid=-1&clientver=&platform=WebFilter&tag=em&filter=2&iscorrection=1&privilege_filter=0&_=1548735800930' % (search, pagesize)res = requests.get(url) # 进行get请求# 需要注意一点,返回的数据并不是真正的json格式,前后有那个多余字符串需要用正则表达式去掉,只要大括号{}包着的内容# json.loads就是将json数据转为python字典的函数res = json.loads(re.match(".*?({.*}).*", res.text, re.S).group(1))list = res['data']['lists'] # 这个就是歌曲列表#建立List存放歌曲列表信息,将这个歌曲列表输出,别的程序就可以直接调用musicList = []#for循环遍历列表得到每首单曲的信息for item in list:#将列表每项的item['FileHash'],item['AlnbumID']拼接请求url2url2 = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191010559973368921649_1548736071852&hash=%s&album_id=%s&_=1548736071853' % (item['FileHash'], item['AlbumID'])res2 = requests.get(url2)res2 = json.loads(re.match(".*?({.*}).*", res2.text).group(1))['data']#同样需要用正则处理一下才为json格式,再转为字典#打印一下print res2['song_name']+' - '+res2['author_name']print res2['play_url']print ''#将单曲信息存在一个字典里dict = {'author': res2['author_name'],'title': res2['song_name'],'id': str(res2['album_id']),'type': 'kugou','pic': res2['img'],'url': res2['play_url'],'lrc': res2['lyrics']}#将字典添加到歌曲列表musicList.append(dict)
-
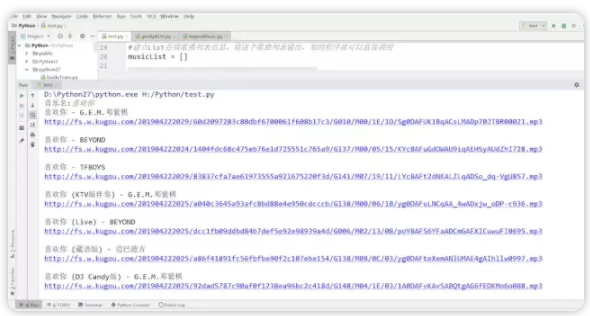
最后控制台输出结果
学习python过程中有不懂的可以加入我的python零基础系统学习交流秋秋qun:934109170,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容
学习python有不懂的(学习方法,学习路线,如何学习有效率的问题),可以随时来咨询我,或者缺少系统学习资料