ズーム機能はどのようなものです:
これは、同じスケールにすべてのデータをマッピングすることです。以下のような:
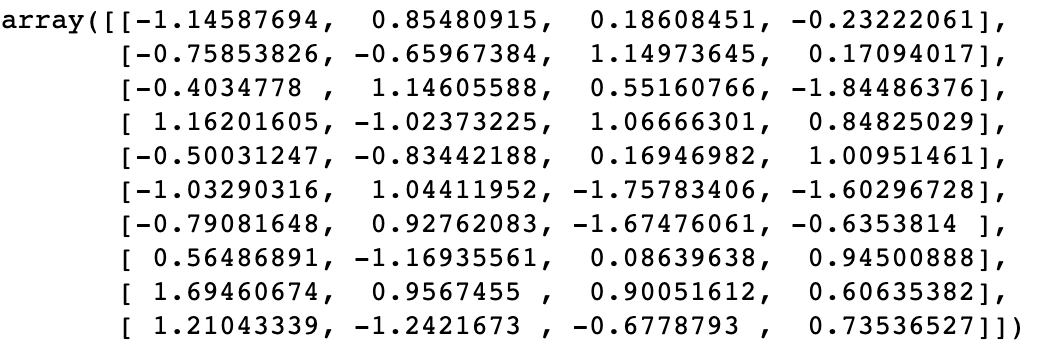
次のように設定し、トレーニングをX_train:

(x_trian)
特定の機能のスケーリングされた後、新しい値が得られ:
明らかな特徴をスケーリングした後、特徴値が小さく
なぜそれをスケーリングしていますでしょうか?
例えば、年齢、体重などの値間隔の制限を、持っている一部の機能。値の一部の機能は、カウント値として、無制限に増加させることができます。
そこで、数値モデルとの間のギャップは、特性を特色にすると悪影響を受けます。以下のような:

このサンプルセットにおいて、により異なる寸法、「番号」ドミナント機能によってモデル。したがって、データ・ワードのない前処理が存在しない場合
優れた応答特性が困難な重要度の間の偏差がもたらす可能性があります。実際には、賛成の最適化では、他の理由があります
機能のスケーリングの分類:
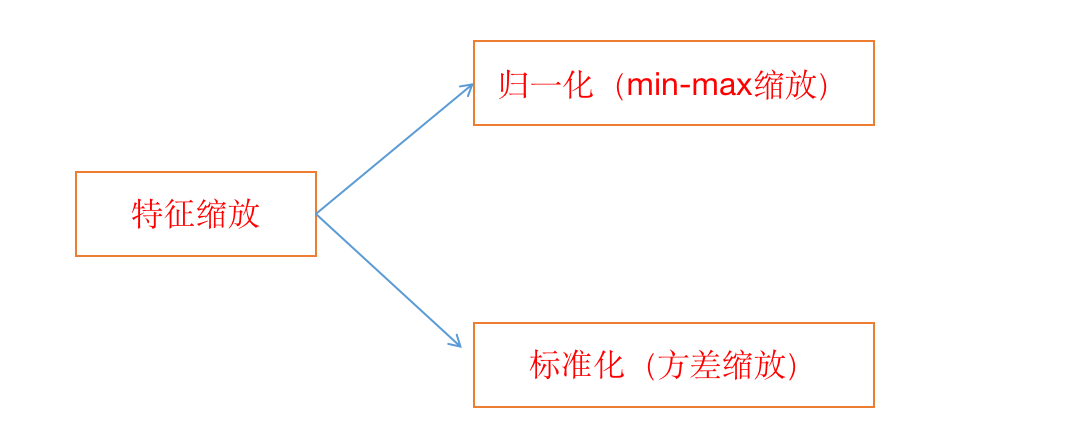
(つ以上の、しかし一般的に標準化された使用)
正規で1ルック(MIN-MAXは、スケーリングされました)
0~1の間の値にマッピングされた値を正規化することによって。
公式:
![]()
特性値の最小値X(i)の機能はすべて、この機能のX(分)、X(最大)、この機能のために
すべての固有値の最大値
すなわち、(特徴値マイナス最小値の差)(最大マイナス最小特性特徴の差)で割った値であります
これにより正規化値後の特性値。

Pythonは達成することは簡単です:
import numpy as np def min_max_scaler(X): '''归一化''' assert X.ndim == 2,'必须为二维数组' X = np.array(X,dtype=float) n_feature = X.shape[1] for n in range(n_feature): min_feature = np.min(X[:,n]) max_feature = np.max(X[:,n]) X[:, n] = (X[:,n] - min_feature) / (max_feature - min_feature) return X x = np.random.randint(0,100,(25,4)) print(min_max_scaler(x))
'''
[[0.89247312 0.11494253 0.17857143 0.29347826]
[0.09677419 0.74712644 0.10714286 0.63043478]
[0. 0.87356322 0.95238095 0.67391304]
.......
[0.2688172 0.4137931 0.33333333 0.89130435]
[0.11827957 0.7816092 0.55952381 0.15217391]
[1. 0.57471264 0.70238095 0.45652174]
[0.16129032 1. 0.75 0.23913043]]
'''
sklearn中对应API: from sklearn.preprocessing import MinMaxScaler
