https://www.cnblogs.com/zlslch/p/6785207.html?utm_source=itdadao&utm_medium=referralからの振替
インパラとの関係ハイブ
インパラは、リアルタイムビッグデータ分析ハイブクエリエンジンに基づいているにハイブメタストアに保存されたインパラのメタデータを意味し、メタハイブデータベースのメタデータを直接使用。そして、SQLセマンティクス機能のハイブのサブセットを達成するためのインパラSQL決意の互換性のハイブを継続的に完成されます。
ハイブとの関係
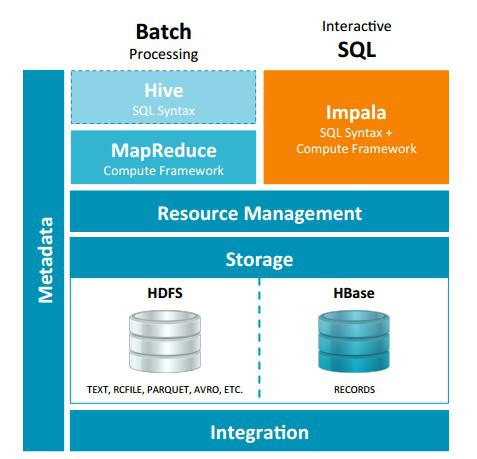
ハイブインパラとデータクエリーツールは、Hadoopの上に構築されている焦点に適応するために異なりますが、クライアントはインパラビューハイブは、ODBC / JDBCドライバ、データテーブルのメタデータを、共通の多くを持って使用していますSQL構文、柔軟なファイル形式、ストレージ・リソース・プール。ハイブインパラと次の図のHadoopとの関係です。長いバッチ分析に適したハイブ、およびインパラは、リアルタイムの対話型SQLクエリに適しており、データアナリストインパラは、ビッグデータ分析ツールのアイデアをテストするために迅速な実験を提供します。ハイブは、第一ハイブ処理をデータセットの結果に使用インパラ迅速なデータ分析の後、データ変換プロセスを使用することができます。
ハイブを使用インパラに関して最適化技術
- 1は、それが非常に良好なMapReduceの並列コンピューティングフレームワークであるが、MapReduceは、並列コンピューティングのために使用されていないが、それがなく、対話式SQLの実行のために、より多くのバッチ指向モードです。MapReduceのと比較すると:木ではなく、MapReduceのタスクのシリーズへのインパラ全体のクエリ実行プラン、配布計画の実施後、インパラは、データ取得結果のプル取得モードを使用して、実行ツリーコレクションストリーミングによって結果のデータ転送の構成、ディスクに書き込まれた中間結果を還元する工程、及び、ディスクのオーバーヘッドからデータを読み出します。MapReduceの開始時間ではありませんあなたは、すべてのクエリの実行のオーバーヘッドを開始するために必要なサービスを使用しないようにするインパラ方法、比較ハイブ。
- 図2は、実行効率をスピードアップするためにインラインの方法を使用して、関数呼び出しのオーバーヘッドを低減しながら、特定のクエリのための固有のコードを生成するために、LLVMを使用して生成されたコードを実行します。
- 図3に示すように、利用可能なハードウェア命令(SSE4.2)をフルに活用。
- 4、IOよりよいスケジューリング、ディスクインパラは、読み出しデータブロックインパラは、ローカルコードとチェックサムの直接計算をサポートしながら、データブロックは、複数のディスクのより良い利点を利用することができる位置を知っています。
- 図5に示すように、最良の性能は、適切なデータ格納形式(インパラは、複数の記憶フォーマットをサポート)を選択することによって得ることができます。
- 図6は、メモリの最大使用、中間結果は、ネットワーク経由でストリーミングするタイムリーな配信方法をディスクに書き込みません。
インパラとの類似点と相違点ハイブ
- データストレージ:HDFS、HBaseの中に格納されたデータをサポートし、同じストレージ・プール・データを使用しています。
- メタデータ:両方が同じメタデータを使用しています。
- SQLは、治療の説明:より多くの同様の実行計画は、字句解析によって生成されます。
実施計画:
- ハイブは:のMapReduceフレームワークの実装に依存し、実施計画は、MAP-> shuffle-> reduce-> MAP-> shuffle-> ...削減モデルに分かれています。クエリは、MapReduceの数回にコンパイルされている場合は、中間結果を書き込むために多くのがあるでしょう。フレーム自体の特性のMapReduceを行うため、過度の中間処理は、クエリの全体的な実行時間を増加させます。
- インパラは:完全な実装計画ツリーのパフォーマンスの実施計画は、クエリを実行するために、様々なImpalad実施計画に配布する方が自然なことができますが、それは、パイプライン型MAP->インパラを確保するために、モデルを減らすにまとめとして、ハイブを好きではありませんより良い並行処理、不要な中間ソートやシャッフルを避けます。
データフロー:
- ハイブは:プッシュ方式を使用して、各計算ノードは、積極的に、後続のノードに演算データが終了した後に押しました。
- インパラ:この方法でデータが戻ってクライアントにストリーミングすることができ、そして限り、処理すべきデータがあると、すぐに表示することができ、のを待つことなく、フロントgetNextをアクティブノードへのデータのノードに後続する、プルモードを使用しますすべての処理は、対話型SQLクエリに沿って、より多くの、完了です。
メモリ使用量:
- ハイブ:メモリは、すべてのデータに適合しない場合は、実行時に、外部メモリは、完全なクエリを順次実行することができることを確認するために使用されます。各ラウンドのMapReduceの端部は、中間結果もHDFSに書き込まれ、MapReduceのも実行アーキテクチャの特性によるもので、シャッフル処理は、ローカルディスク書き込み操作が存在することになります。
- インパラ:それはメモリにデータが収まらない遭遇したとき、現在のバージョン1.0.1は、外部メモリを使用せず、将来のバージョンでは改善されなければならない、直接のリターンエラーです。このプロセスは、現在、それは最高のハイブと一緒に使用され、クエリインパラは、一定の制限の対象とした使用しています。実行中に、複数段の間にはディスク書き込み操作のデータを転送しないようにネットワークのインパラ使用(インサートを除きます)。
スケジュール:
- ハイブ:タスクのスケジューリングは、Hadoopののスケジューリングポリシーに依存します。
- インパラ:自分で行われたスケジューリング、一つだけのスケジューラの単純なスケジュールがあり、それはデータ自体の物理マシンの近くにスキャンしたデータをローカル、プロセスデータを満たすためにしようとします。スケジューラは何ら考慮負荷、ネットワークの状態IOスケジューリングはありません、でSimpleScheduler :: GetBackendで見ることができ、まだ比較的簡単です。しかし、インパラは、実装プロセスのパフォーマンスの統計分析を持って、我々は、後でそれをスケジュールするためにこれらの統計を使用しますする必要があります。
フォールトトレランス:
- ハイブは:Hadoopのフォールトトレランスに依存しています。
- インパラ:障害が実行中に発生した場合、クエリ処理では、過失のロジックは、エラーがその後、リアルタイムクエリで位置決め、クエリが失敗したので、インパラ、インパラの設計に関連している(直接返され、その後、一度だけチェックされており、コストが非常に低いたら)確認してください。しかし、全体として、インパラがよくフォールトトレランスされ、Impaladのすべてのクエリを実行しているすべてがImpalad障害が、失敗した場合と同等の構造は、ユーザーが、任意のImpaladにクエリーを送信することができますが、ユーザー他のImpaladクエリの実行に置き換える再送信することができ、サービスには影響しません。状態ストアは現在、一つだけを持っていますが、状態ストアが失敗したとき、それがサービスには影響しませんのために、各Impaladは、状態ストアの情報をキャッシュしているが、クラスタのステータスを更新することはできません、それはImpaladに割り当てられたタスクを実行することが可能である失敗しただろう実行、このクエリにつながる失敗しました。
適用表面:
- ハイブ:複雑なバッチクエリタスク、データ変換タスク。
- インパラ:リアルタイムのデータ分析、問題がUDFをサポートしていないため、ドメインを扱うことができるがハイブ、リアルタイム分析でハイブデータセットの結果と併せて、一定の制限があります。
インパラとハイブが上に構築されたHadoop上のデータのクエリツールが、異なる強調を持って、我々は、なぜこれらの2つのツール、それを使用しますか?ハイブインパラは、単独で使用したりできないのですか?
I.はじめインパラとハイブ
(1)インパラとハイブHDFS /上に設けられているHBaseの HDFSへのアクセスを可能にする手段糸スケジューリングデータによって、MapReduceのハイブに変換し、データのSQLクエリツール、およびインパラ直接データクエリをHDFS。しかし、彼らは、胴体に実行し、標準のSQL文として提供されています。

(2)Apache Hive是MapReduce的高级抽象,使用HiveQL,Hive可以生成运行在Hadoop集群的MapReduce或Spark作业。Hive最初由Facebook大约在2007年开发,现在是Apache的开源项目。
Apache Impala是高性能的专用SQL引擎,使用Impala SQL,因为Impala无需借助任何的框架,直接实现对数据块的查询,所以查询延迟毫秒级。Impala受到Google的Dremel项目启发,2012年由Cloudera开发,现在是Apache开源项目。
二、Impala和Hive有什么不同?
(1)Hive有很多的特性:
1、对复杂数据类型(比如arrays和maps)和窗口分析更广泛的支持
2、高扩展性
3、通常用于批处理
(2)Impala更快
1、专业的SQL引擎,提供了5x到50x更好的性能
2、理想的交互式查询和数据分析工具
3、更多的特性正在添加进来
三、高级概述:

四、为什么要使用Hive和Impala?
1、为数据分析人员带来了海量数据分析能力,不需要软件开发经验,运用已掌握的SQL知识进行数据的分析。
2、比直接写MapReduce或Spark具有更好的生产力,5行HiveQL/Impala SQL等同于200行或更多的Java代码。
3、提供了与其他系统良好的互操作性,比如通过Java和外部脚本扩展,而且很多商业智能工具支持Hive和Impala。
五、Hive和Impala使用案例
(1)日志文件分析
ログは、現在は、一般的なデータ型である大規模なデータの重要な年齢データソース構造は、ログ収集カフカ水路でとHDFSに固定されておらず、その後、その後、区切り文字に応じてログテーブルを確立するために、ログの構造を分析しますインパラダウンやデータを分析するためにハイブを使用しています。例えば:

(2)感情分析
多くの組織では、ソーシャルメディアの報道を分析するためにハイブやインパラを使用しています。例えば:

(3)ビジネスインテリジェンス
多くの大手BIツールは、ハイブとインパラをサポート

エディタ: