
ソースチーム|Bytedance ライブオペレーションプラットフォームES に基づくクロスドメイン データ集約サービスの継続的な構築において、ES の多くの機能が MySQL などの一般的に使用されるデータベースとは大きく異なることがわかりました。この記事では、ES の実装原則とライブ ブロードキャスト プラットフォームにおけるビジネス選択の提案について説明します。 、実際に遭遇した問題と思考。
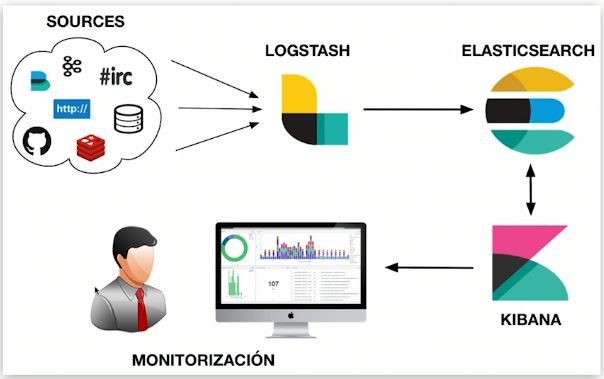
ESの導入と適用シナリオ
Elasticsearch は、分散型のほぼリアルタイムの大規模データ ストレージ、取得、分析エンジンです。私たちがよく「ELK」と呼ぶものは、Elasticsearch、Logstash/Beats、Kibana で構成され、収集、保存、取得、視覚化が可能なデータ システムを指します。 ES は、同様のデータ システムにおけるデータの保存とインデックス付け、データの取得、およびデータ分析において役割を果たします。
ESの特徴
各テクノロジの選択には独自の特性があり、ES の全体的な特性は、基礎となる実装によっても影響を受けます。この記事の第 2 部では、次の特性の根本原因について詳しく説明します。
長所:
-
分散: シャーディングを通じて、最大 PB レベルのデータをサポートし、シャーディングの詳細を外部から保護できます。ユーザーは読み取りおよび書き込みルーティングを意識する必要がありません。
-
スケーラブル: 水平方向に拡張するのが簡単で、MySQL のようにデータベースやテーブルを手動で分割したり、サードパーティのコンポーネントを使用したりする必要はありません。
-
高速: 各シャードの並列計算、高速な取得速度。
-
全文検索: さまざまな単語分割プラグインによる多言語の全文検索のサポートや、セマンティック処理による精度の向上など、複数の対象を絞った最適化。
-
豊富なデータ分析機能。
短所:
-
トランザクションはサポートされていません。各シャードの計算プロセスは並列かつ独立しています。
-
ほぼリアルタイム: データが書き込まれてからデータをクエリできるようになるまでに数秒の遅延があります。
-
ネイティブ DSL 言語は比較的複雑であり、ある程度の学習コストがかかります。
一般的な用途
機能はコンポーネントのアプリケーション シナリオに影響を与えます。ライブ ブロードキャスト操作プラットフォームは ES を使用して数億のアンカーのさまざまな情報を集約し、対応するプラットフォームでさまざまなリストを表示します。 Argos エラーを検出するために使用されます。
ESの実装とアーキテクチャ
次に、上記の ES の利点がどのように実現されるか、またその欠点がどのように生じるかを理解します。ES について語るとき、Lucene はすべてを実装するための基礎となるコンポーネントとして使用されます。 Lucene の機能を中心に紹介します。Lucene と比較して、ES にはどのような機能と新しい機能がありますか?
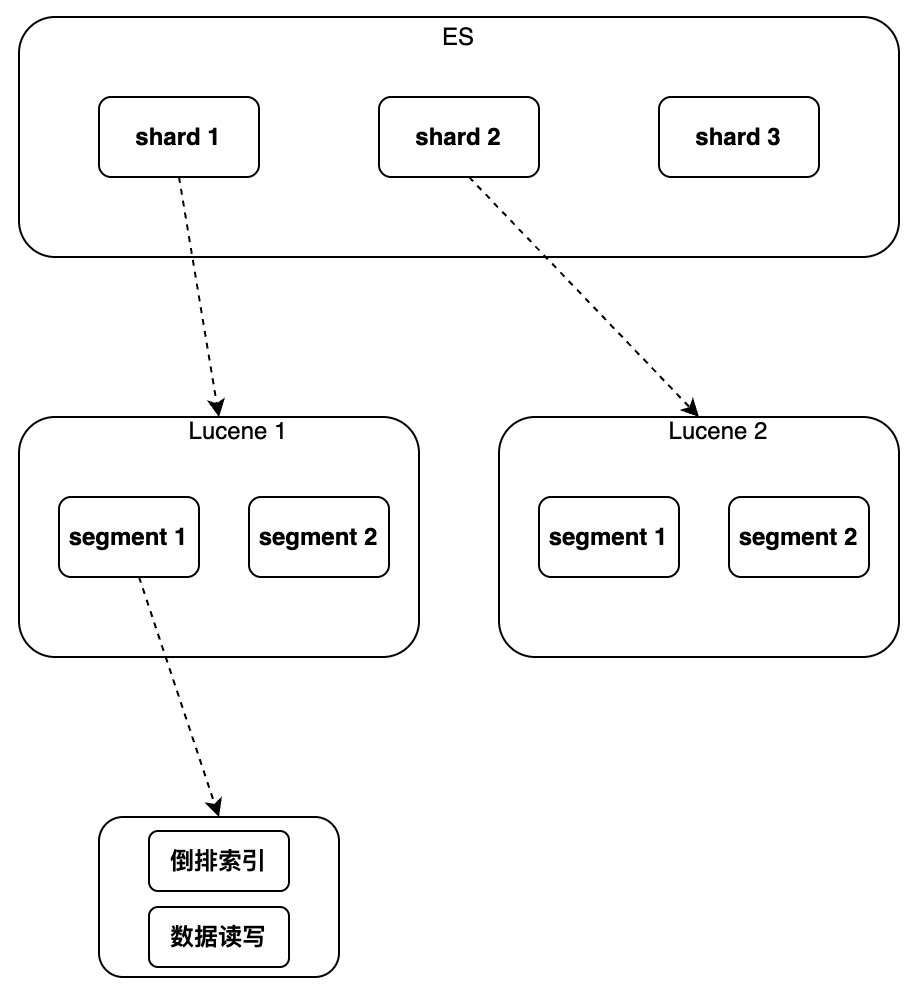
Lucene は単一インスタンスでデータのインデックス作成と取得を実装しますが、データの逆インデックスと順次書き込みをサポートしますが、グローバル主キーの概念はなく、ドキュメントとデータを識別するための統一された方法は使用できません。配信をサポートすることはできません。
したがって、ES には Lucene と比較していくつかの新機能が追加されています
。
主に、データの変更/削除とシャード ルーティングを可能にする新しいグローバル主キー フィールド「_id」や、削除されたドキュメントを「新規に書き込む」というマークを付ける別のファイルの使用などです。更新操作は「ドキュメント、古いドキュメントを削除済みとしてマークする」によって実装されます。ドキュメントに新しいバージョン番号を追加することで、同時実行がサポートされます。分散を実現するプロセスは、複数の Lucene インスタンスを実行して読み取りとルートを実行します。主キー ID に基づいてリクエストを書き込み、クエリ結果をマージします。クエリ結果の並べ替え、統計などの分析を実装できる集計分析も追加されました。以下、シングルインスタンスからクラスターの順に具体的な実装内容を紹介していきます。
単一インスタンス
索引
インデックス作成の目的は、検索プロセスを高速化することです。インデックスの選択は、すべてのデータベースにとって避けられない問題です。ES 設計の最初のターゲット シナリオは、「逆インデックス」をサポートし、これに向けて多くの最適化が行われています。さらに、Block Kd Tree などの他のインデックスもサポートしており、ES はフィールド タイプに応じて対応するインデックス タイプを自動的に照合し、インデックス付けが必要なフィールドのインデックスを構築します。
逆インデックスとブロック Kd ツリーも、分析によく使用されるインデックス タイプです。文字列の場合、一般的な状況が 2 つあります。テキストでは単語の分割 + 逆索引が使用され、キーワードでは非単語の分割 + 逆索引が使用されます。 Long/Float などの数値型の場合、通常は Block Kd Tree が使用されます。
転置インデックス
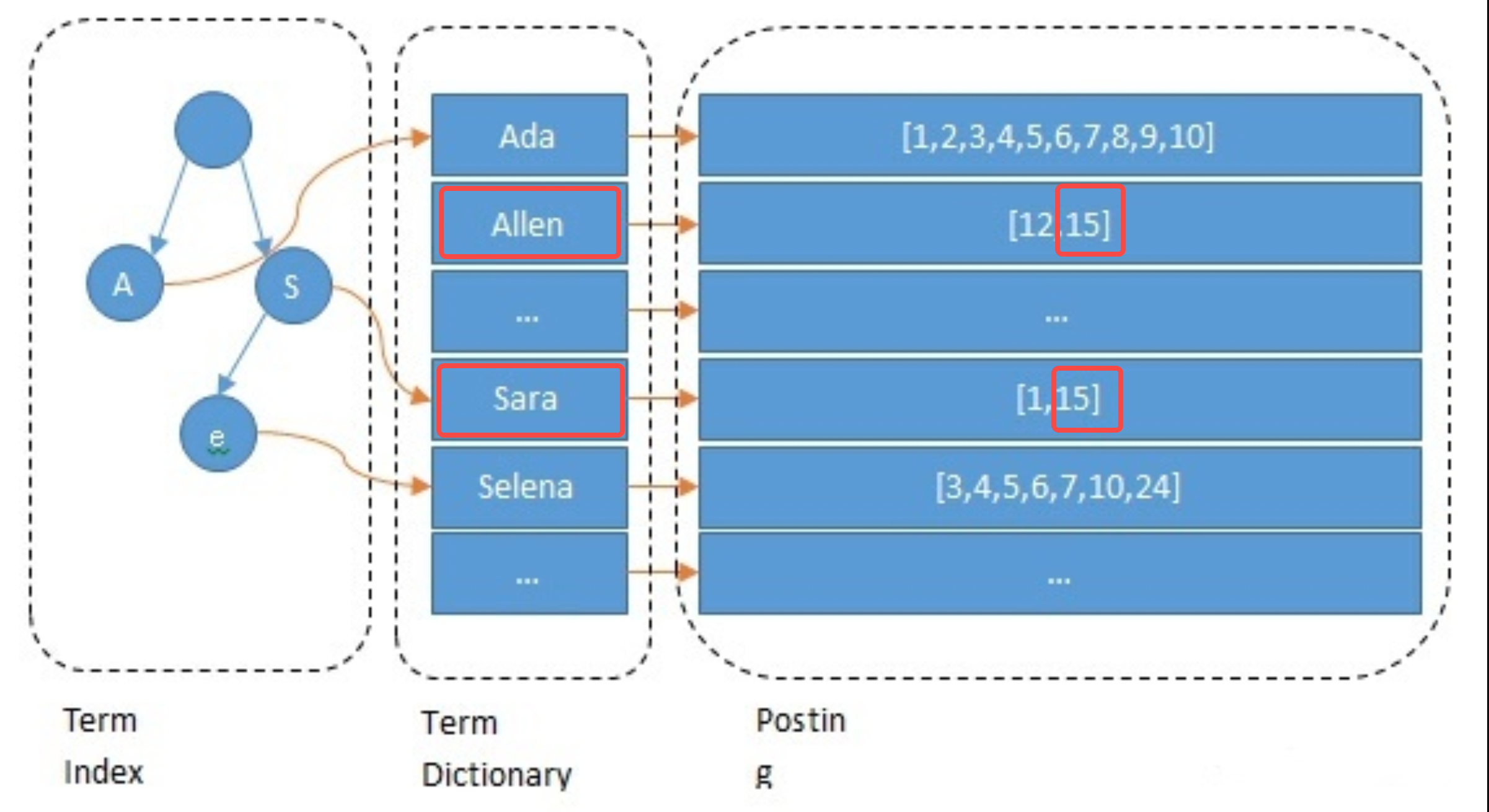
インデックスを構築するとき、ES はデフォルトで各フィールドにインデックスを付けます。このプロセスには、単語の分割、意味処理、マッピング テーブルの構築が含まれます。まず、テキストを単語に分割します。単語の分割方法は、英語のスペースによる切り取りなど、言語に関連します。次に、意味のない単語が削除され、意味の正規化が実行されます。最後にマッピングテーブルを作成します。次の例は、アンカー 15 の Name フィールドの処理プロセスを簡単に示しています。これは、allen と sara に分割され、小文字およびその他の演算に変換され、allen->15 と sara->15 のマッピングが構築されます。
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
クエリプロセス
例として、「allen sara」という名前のアンカーのクエリを考えます。単語の分割結果によれば、2 つのリスト [12, 15] と [1, 15] がそれぞれ見つかります (実際のアプリケーションでは、クエリもそれに基づいています)。同義語); リストとスコアをマージするには、 を押します。優先順位は結果 [15、12、1] を取得することです (これは検索の呼び出しステップであり、アルゴリズムに従って調整されます)。
最適化項目
検索を高速化し、メモリ/ハードディスクの負荷を軽減するために、ES は転置インデックスに対して次の最適化を実行します。これは、他のコンポーネントに対する ES の利点でもあります。ここで注意する必要があるのは、ストレージ領域の最終的な利用がすべてのデータベースに共通する機能である可能性があることです。Redis も同様にメモリ領域を節約します。つまり、データは可能な限り少ないビットで保存され、小さなセットと大きなセットはすべて保存されます。さまざまな方法で保存されます。
-
用語インデックス: 接頭辞ツリーを使用して、「用語」単語の配置を高速化し、単語が多すぎることによって引き起こされる検索速度の低下の問題を解決します。
-
用語辞書: 同じ接頭辞を持つ単語をデータ ブロックに入れ、[hello, head] -> [lo, ad] のように接尾辞のみを保持します。
-
ポスト: 順序付け + インクリメンタル コーディング + ブロック ストレージ ([9、10、15、32、37] -> [9、1、5、17、5] など)。各要素は 5 ビット ストレージを使用できます。
-
Posting マージの最適化: スペースを節約するには、Roaring Bitmap を使用します。複数条件のクエリを使用する場合は、複数の Posting をマージする必要があります。
-
セマンティック処理: 同様のセマンティックを持つコンテンツをクエリできます。
転置インデックスの特徴:
-
全文検索のサポート: 中国語の全文検索を実装する IK 単語分割プラグインなど、さまざまな単語分割プラグインで複数の言語をサポートします。
-
小さいインデックス サイズ: プレフィックス ツリーによりスペースが大幅に圧縮され、インデックスをメモリに配置して検索を高速化できます。
-
範囲検索のサポートが不十分: プレフィックス ツリーの選択によって制限されます。
-
適用可能なシナリオ: 単語による検索、非範囲検索。 ES の非数値フィールドはこのタイプのインデックスを使用します。
ブロック
K dツリーインデックス
Block Kd Tree インデックスは範囲検索に非常に適しており、ES 値、地域、範囲などのフィールド タイプはすべてこのインデックス タイプを使用します。ビジネス選択では、範囲検索が必要な数値フィールドには Long などの数値タイプを使用する必要があります。転置インデックスの場合、全文検索を必要としないフィールドにはキーワード タイプを使用する必要があります。
スペースが限られているため、この記事ではあまり紹介しません。BKd Tree に興味のある方は、次のコンテンツを参照してください。
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
データストレージ
このパートでは、単一インスタンスのデータがメモリとハードディスクにどのように保存されるかを主に説明します。
セグメント化されたストレージ セグメント
1 つのインスタンスのデータは最大数百 GB に達するため、それをファイルに保存するのは明らかに不適切です。 Kafka、Pulsar、および追加専用データを保存する必要があるその他のコンポーネントと同様に、ES はデータをストレージ用のセグメントに分割することを選択します。
-
セグメント: 各セグメントには独自のインデックス ファイルがあり、結果は並列クエリの後にマージされます。
-
セグメント生成のタイミング: スケジュールされた生成またはファイル サイズに基づいて、期間は構成可能です (通常は数秒)。
-
セグメントのマージ: セグメントは定期的に生成され、通常は比較的小さいため、大きなセグメントにマージする必要があります。
遅延とデータ損失のリスク
-
取得遅延: 条件付き取得はインデックスに依存し、インデックスはセグメントの生成時にのみ使用できるため、通常、書き込みから取得までに数秒の遅延が発生します。
-
データ損失のリスク: デフォルトでは、新しく生成されたセグメントのフラッシュには数十分かかり、データ損失のリスクがあります。
-
データ損失のリスクを軽減する: デフォルトでは、書き込みイベントを記録するために Translog が追加で使用されますが、それでも数秒間のデータが失われるリスクはあります。
削除/更新の実装方法
-
削除: 各セグメントは削除された ID を記録する del ファイルに対応しており、検索結果をフィルターで除外する必要があります。
-
更新: 新しいドキュメントを作成し、古いドキュメントを削除します。
集まる
単一マシンのデータベースには、容量とスループットが限られている、災害復旧機能が弱いなどの問題があります。これらの問題は通常、シャーディングとデータの冗長化によって解決されます。まず、ES がデータをシャード化してバックアップする方法を見てから、次の 3 つの質問を解決する方法を見てみましょう: 読み取りおよび書き込みリクエストはどのように各シャードにルーティングされるのですか?各シャードの検索結果を結合するにはどうすればよいですか?アクティブ インスタンスとスタンバイ インスタンスの間でマスターを選択するにはどうすればよいですか?
分散シャード
次の図では、3 つのシャードを持つインデックスを例として、各インデックスのシャードの数を構成できます。水平方向の拡張によって全体のストレージ容量が増加し、各シャードの並列計算によって取得速度が向上します。
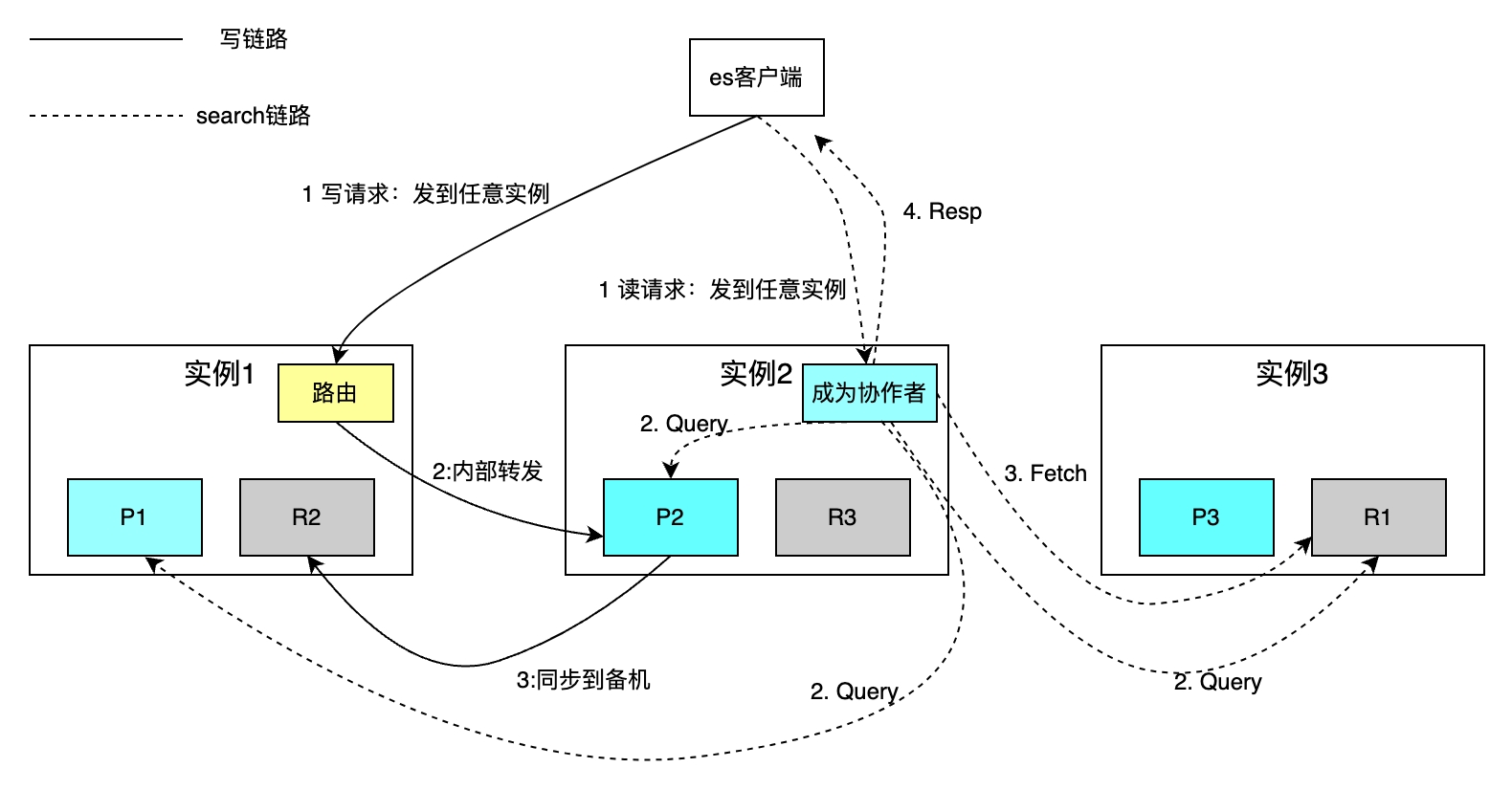
ルーティング ポリシーは、主キーに基づいて単一のドキュメントの読み取りと書き込みを行います。ハッシュ ルーティングでは、書き込み操作の場合、デフォルトで ID が主キーとして使用されます。ビジネス パーティが主キー ID を指定しない場合、ES は Guid アルゴリズムを使用して ID を自動的に生成します。ルーティング ポリシーの制限により、シャード数の増減にはすべてのデータの移行が必要になります。条件付き取得に基づく検索リクエストは、コラボレーターの座標フェーズとクエリ フェーズのクエリ フェーズと、フェッチ フェーズの取得フェーズの 2 つのステップを通じて実装されます。コラボレーターは任意のインスタンスに読み取りリクエストを送信し、インスタンスはそのリクエストを各シャードに並行して送信し、各シャードがローカル SQL を実行して、ID と UID を含む 2000+100 個のデータをコラボレーターに返します。共同作業者は、シャード化されたすべてのデータをソートし、100 件のドキュメントの ID を取得し、ID ごとにデータを取得してクライアントに返します。
欠点は、上記の取得方法ではシャーディングの概念がクライアントから保護されるため、読み取りおよび書き込み操作が大幅に容易になることです。ただし、各インスタンスを開く必要もあります。 from+limit サイズのスペース 深いページめくりが発生すると、共同作業者はシャード* (from+limit) ドキュメントやその他の問題をソートする必要があります。
上記の問題に対応して、実際には、リクエストごとに変更される uid>2200 などのパラメータを Search After の条件項目に追加します。これにより、別の形式の Scroll のソート数を from+limit から Limit に減らすことができます。 Search After、各リクエストの条件項目をES内部で保持し、同時実行をサポートします。
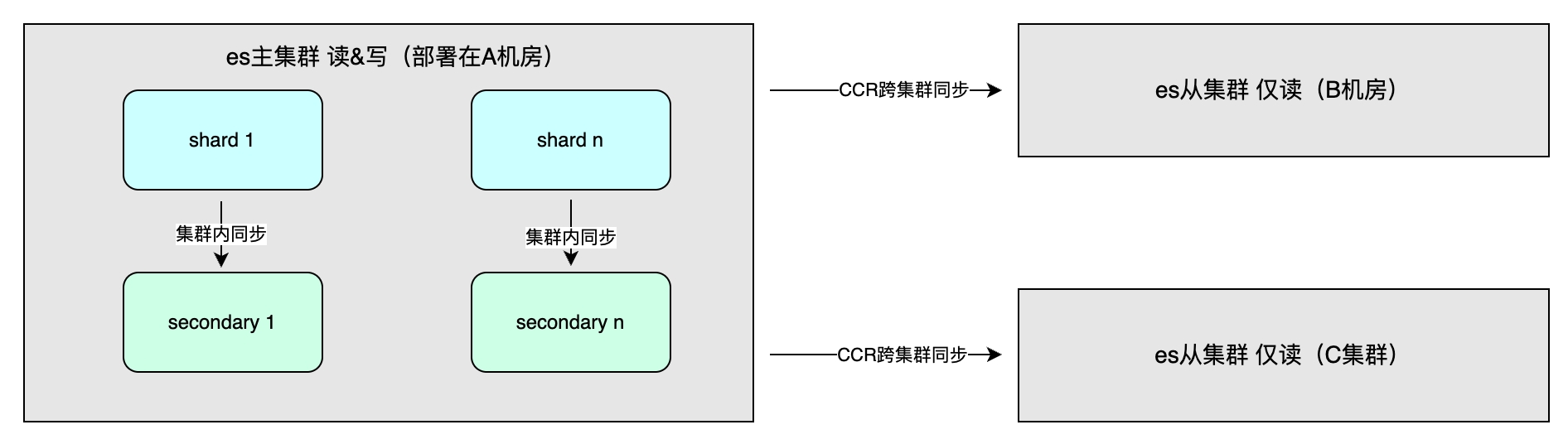
マスタスレーブ同期収入
主な利点には、データの冗長性による高可用性とシステム スループットの向上が含まれます。データ同期方法には、クラスター内のマスター/スレーブ同期が含まれます。これは通常、書き込み操作を高速化するために同じリージョン内の異なるコンピューター ルームに展開されます。整合性は 1 つ、すべて、またはクォーラムから選択できます。さらに、マルチクラスターの災害復旧や異なるリージョンでの近隣アクセスに使用されるクラスター間同期 (CCR) があり、非同期方式が採用されており、インデックス レベルはデータの一方向または双方向のレプリケーションが可能です。 。
該当シーン
ES の実装の詳細によってその全体的な特性が決まり、適用可能なシナリオに影響を与えます。該当するシナリオには、PB レベル未満の大量のデータ、複数フィールドの柔軟なインデックス作成と並べ替えが必要、トランザクションの要件がない、書き込み後のクエリ遅延の要件が低い、などがあります。ただし、ES を重要なデータの唯一のストレージとして使用することはお勧めできません。数秒の遅延とデータ損失のリスクがあり、MySQL とは異なり、高可用性は細部にわたって慎重に最適化されています。
ライブ放送運用基盤向けクロスドメインデータ集約システムの実践
アプリケーションシナリオ
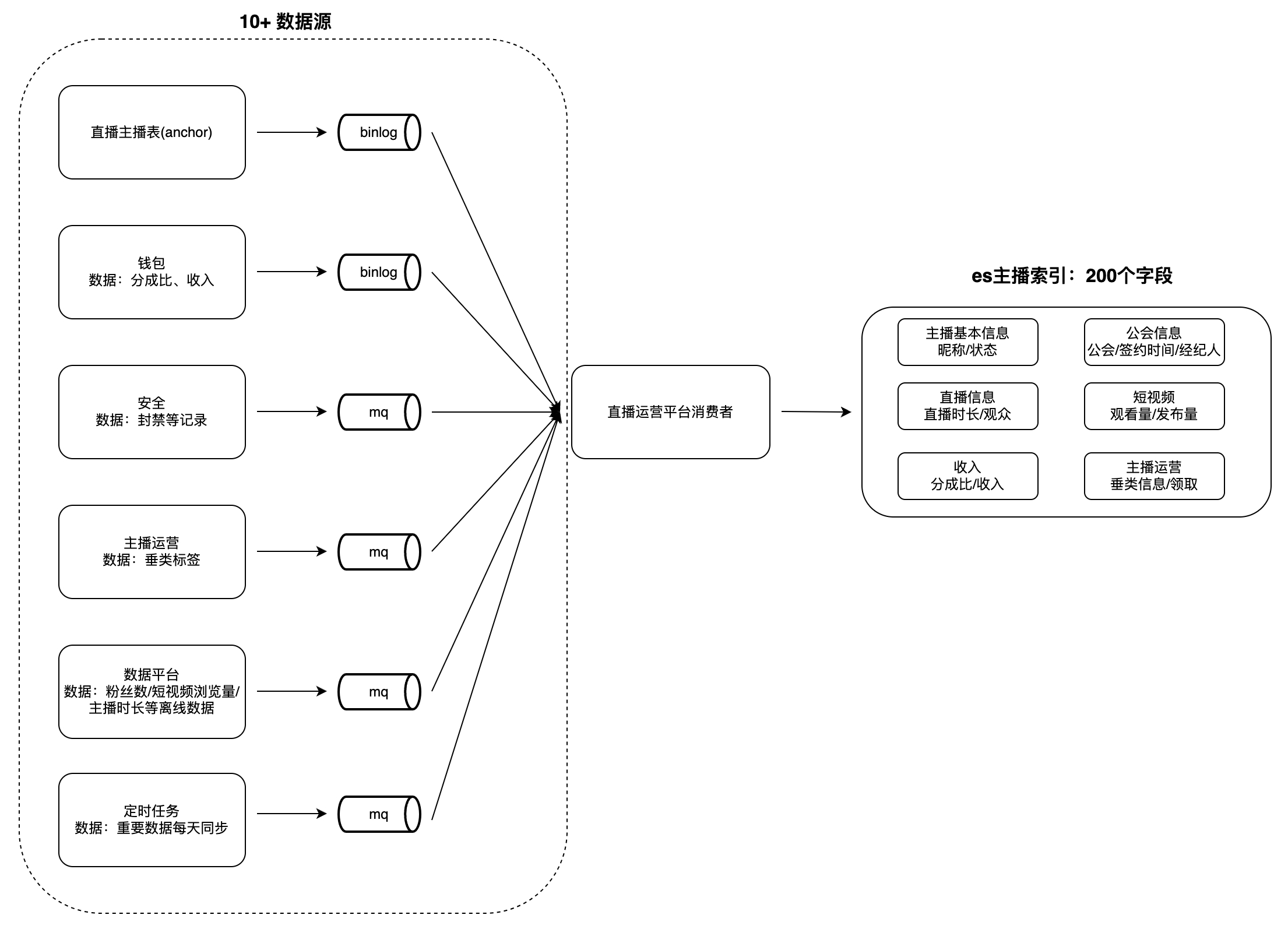
ライブブロードキャストギルドとアンカーの運用プラットフォームには、アンカーリスト、アンカー、ギルドタスクなど、データの閲覧と分析のための多くのシナリオがあります。このタイプのデータは一般に次のような特徴を持っています: データ量が多く、フィールドが多く、データ量が多い。たとえば、アンカーのインデックス フィールドの数は 200 近く、データ ソースは 10 以上あり (データ プラットフォーム、セキュリティ プラットフォーム、ウォレットなど)、検索や並べ替えなどの操作が必要です。複数のフィールドによるサポートがサポートされています。
ユーザーがデータを閲覧する際、各取引先からリアルタイムにデータを取得するには時間がかかり、条件検索や複数項目によるソートが難しいため、事前にデータを1つのデータベースに集約する必要がある。 MySQL や Redis などのデータベースでは上記の特性を満たすことが困難であるため、ES をベースにクロスドメイン データ集約サービス システムを構築しました。つまり、上流のデータ ソースでの変更を消費し、それらをデータ ソースに書き込むことになります。クエリのニーズを満たす ES の大きなインデックス。データ集約モードを説明するために、「アンカー インデックス」を例に挙げます。
チャレンジ
最初のバージョンの実装では、単一の PSM をコンシューマとして使用して、アップストリーム データを読み取り、ES に書き込みました。書き込みが分離されていなかったため、多くの問題がありました。まず、すべてのアクセス パーティが同じ PSM にデータ消費ロジックを書き込むため、データ処理ロジックの結合度が高く、メンテナンスが困難になります。第 2 に、複数のビジネス パーティが同じフィールドに書き込む可能性があり、ビジネス例外が発生する可能性があります。さらに、フルカバレッジ ES データ書き込みモードでは、データ処理速度が遅くなり、MQ 消費速度も低くなります。同時に、リソースの競合や、特定のアップストリームに関連付けることができないクエリの遅さなどの問題も依然として存在します。隔月ごとに約 5 つの新しいフィールドが追加され、データは増加し続けているため、これらの問題が解決されない場合、将来的にはさらに大きな課題が発生することになります。
上記の問題は 3 つのカテゴリに分類できます。各データ ソースの処理ロジックが高度に結合しており、データ処理速度が遅く、リソースの競争が激化している。書き込みガバナンス機能: 書き込み分離、低速クエリ統計。
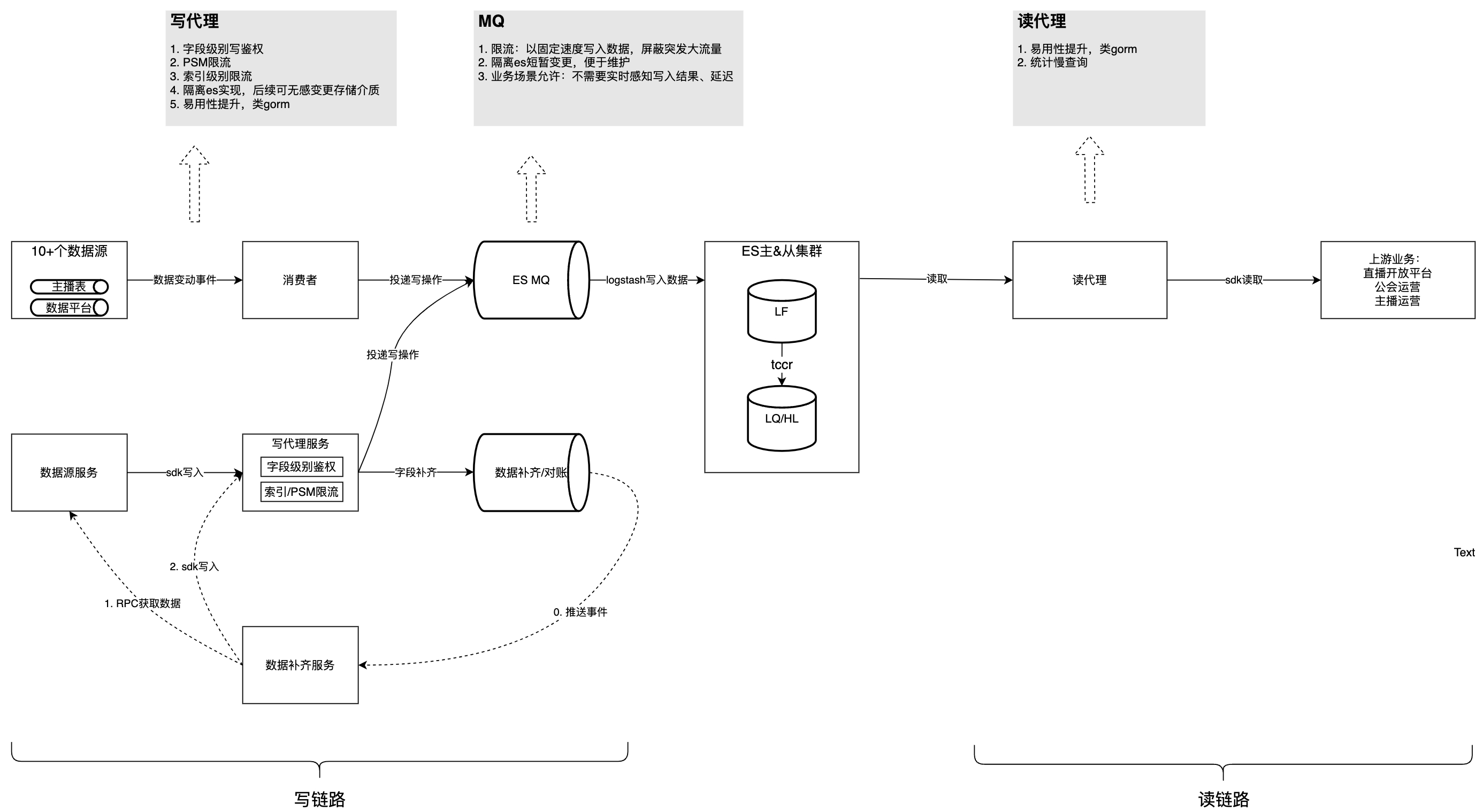
解決
以下の図はガバナンス後の全体構造を紹介したものであり、これを踏まえてガバナンスプロセスにおける課題や考慮事項を一つずつ分析していきます。
現時点では、このコンテンツはフェイシュ文書以外には表示できません。
問題 1: 各データ ソースの消費ロジックは強く結合されており、保守が難しく、相互に影響を及ぼし、リソースを占有します。
この問題の具体的な兆候は、10 を超える MQ データ消費ロジックが同じ PSM に実装されているため、共有データ処理ロジックと小さな変更が他の MQ 処理に影響を及ぼし、サービスが複数の MQ イベントを監視することが不便になる可能性があることです。リソースの競合と単一 MQ イベントのパーティションの不均等な分散により、単一マシン上のリソース使用率が不均等になります。これは、マシンの水平拡張では解決できません。したがって、単一の MQ のコードの不安定性はすべての MQ トピックの消費に影響し、個々の MQ トピックのパーティションの分散が不均一になると、個々のコンシューマ インスタンスの CPU が急増し、他のトピックの消費に影響を及ぼします。
最適化戦略:
-
単一イベントの消費速度を改善します。ES の部分的な更新。すべてのトピックの現在の制限構成を見直します。
-
より多くのデータ書き込みメソッドを構築し、非コア フィールドの書き込みをさまざまなビジネス サイドに分散します。たとえば、書き込み SDK の提供や Dsyncer の導入などです。
問題 2:
MQ
データの消費が遅く、ビジネス データの更新が遅れる
フルカバレッジ ES データ書き込みモードを例にとると、1 つのフィールドを更新するには、更新する必要のない残りのフィールドをまとめて書き込む必要があります。これは、200 近くのフィールド データを取得する必要があるためです。全体的に時間がかかり、MQ の消費速度が遅くなります。一部の MQ トピックは 1 つのインスタンスで 1 つのワーカーを消費します。主な影響は、データ更新の遅延が大きく、変更後にユーザー情報が下流プラットフォームに表示されるまでに時間がかかることです。また、更新ごとに、複数のビジネス パーティから 200 近くのフィールドを取得する必要があります。単一のデータ ソースに異常があると、MQ イベントの消費全体が失敗し、再試行されます。
最適化戦略:
-
ES クラスターのデータ書き込みモードをフル カバレッジから部分更新に変更します。単一のフィールドをオンデマンドで更新できるため、コンシューマーは複数のビジネス パーティから 200 近くのフィールドを取得する必要がなくなり、データ処理時間が短縮されるだけでなく、コードも削減され、メンテナンスが困難になります。
-
すべての MQ トピックを複数のワーカーを持つように構成し、連続した使用が必要なトピックは、主キー ID に基づいて同じワーカーにルーティングされるように構成します。
問題 3: 書き込みが分離/認証/制限されていない
フィールド書き込みには分離と認証が不足しており、複数のビジネス パーティが同じフィールドに書き込みを行うリスクがあり、これによりビジネス異常が発生する可能性があります。主な理由は、書き込み当事者がリソースを共有するため、一方の当事者があまりにも早く書き込むと、他の当事者のリソースを占有し、書き込み遅延が増加することです。したがって、ユーザーからの大量のフィードバックを引き起こすことを避けるために、ES ストレージのコア フィールドの更新を厳密に制御する必要があります。
最適化戦略:
-
フィールドレベルの書き込み認証を追加し、許可された PSM のみが特定のフィールド データを書き込むことができるようにしました。
-
PSM とインデックスの 2 つの次元でトラフィック制限戦略を実行するには、一般的なトラフィック管理プラットフォーム上の動的に構成可能なコンポーネントが使用されます。
問題 4: 遅いクエリの統計情報と最適化方法が不足している
MySQL や他のデータベースと同様、非標準 SQL は不必要なスキャンやクエリの大幅な遅延につながります。 ES は時間のかかる SQL をクエリする機能を提供しますが、アップストリームの PSM、Logid、およびその他の情報を関連付けることができないため、トラブルシューティングが困難になります。
最適化戦略: 読み取りエージェントは、SQL、アップストリーム PSM、Logid、およびしきい値を超えるその他のメッセージを中間層の形式で ES に記録し、低速クエリ条件を毎日報告します。
質問5: 使いやすさ
最適化戦略:
-
ES クラスターで ES SQL プラグインを有効にします。ES SQL 構文は MySQL SQL とは若干異なるため、読み取りエージェント サービスを通じて追加のサポートが提供されます。ユーザー側は MySQL 構文を使用し、読み取りエージェントは正規表現を使用して書き換えます。 SQL から ES SQL 標準。ScrollID を ES SQL に挿入するため、ユーザー側は SQL で Scroll クエリを表現する方法を気にする必要がありません。
-
ユーザーがクエリ データを構造体に逆シリアル化できるようにします。
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
ガバナンスの実績
上記のガバナンスにより、書き込みリンクの蓄積が完全に排除され、消費容量が 150% 増加しました。これは、システム パフォーマンスの上限に達することなく、ビジネスの QPS が 4k から 10k に増加することに具体的に反映されています。ピーク読み取り値 QPS は 1500 で、SLA は長期的に 99.99% で安定しています。現在、複数のビジネス パーティが SDK を使用しており、アクセス時間が当初の 2 日から 0.5 日に短縮されたとビジネス パーティが報告しています。
フォローアップ計画
フォローアップ計画には主に、MVP 調整機能を個別のシナリオからすべてのシナリオに拡張すること、低速クエリの統計に基づいて SQL の上流のビジネス最適化を促進すること、および FaaS などのより多くのデータ書き込み方法を提供することが含まれます。
ByteDance の内部の大規模ベスト プラクティスの経験に基づいて、Volcano Engine は外部的に一貫した
ES
製品
、つまり
クラウド検索サービスの
エンタープライズ レベルのクラウド製品を提供します。クラウド検索サービスは、Elasticsearch、Kibana、その他のソフトウェアおよび一般的に使用されるオープンソース プラグインと互換性があり、構造化テキストと非構造化テキストの複数条件の取得、統計、レポートを提供し、ワンクリックの展開、柔軟なスケーリング、運用とメンテナンスが簡素化され、ログ分析、情報の検索と分析、その他のビジネス機能を迅速に構築できます。
{{名前}}
{{名前}}