

記事のソース | ByteDance インテリジェント作成チーム
前例のない速度と品質を実現し、コミュニティで利用できるようになった最新の Vincentian グラフ モデル SDXL-Lightning を皆さんと共有できることを嬉しく思います。
モデル: https://huggingface.co/ByteDance/SDXL-Lightning
論文: https://arxiv.org/abs/2402.13929

超高速の画像生成
生成 AI は、テキスト プロンプトに基づいて見事な画像やビデオさえも作成できる機能で世界的な注目を集めています。ただし、現在の最先端の生成モデルは、ノイズを徐々に画像サンプルに変換する反復プロセスである拡散に依存しています。このプロセスには膨大なコンピューティング リソースが必要であり、高品質の画像サンプルを生成するプロセスでは時間がかかりますが、1 つの画像の処理時間は約 5 秒で、通常、巨大なニューラル ネットワークへの複数回の呼び出し (20 ~ 40 回) が必要になります。 。この速度は、高速なリアルタイム生成を必要とするアプリケーション シナリオを制限します。品質を向上させながら生成を高速化する方法は、現在の研究の注目分野であり、私たちの仕事の中核目標です。
SDXL-Lightning は、革新的なテクノロジーであるProgressive Adversarial Distillationによってこの障壁を突破し、前例のない生成速度を実現します。このモデルは、わずか 2 または 4 ステップで非常に高品質で解像度の高い画像を生成することができ、計算コストと時間を 10 分の 1 に削減します。私たちの方法では、タイムアウトに敏感なアプリケーション向けに 1 ステップで画像を生成することもできますが、品質が若干犠牲になる可能性があります。
SDXL-Lightning は、速度の利点に加えて、画質においても優れたパフォーマンスを実現し、評価において以前の高速化テクノロジを上回っています。良好な多様性と画像とテキストの一致を維持しながら、より高い解像度とより優れた詳細を実現します。
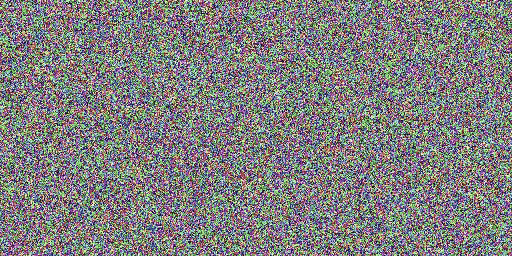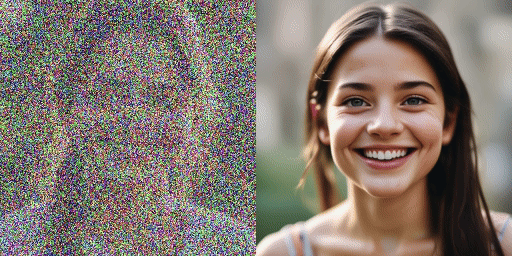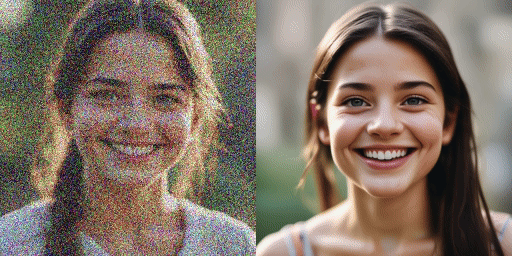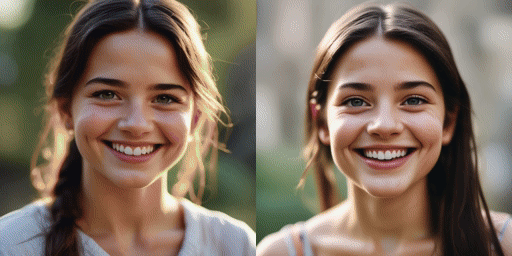 速度比較
速度比較
オリジナルモデル(20ステップ)、弊社モデル(2ステップ)
モデル効果
私たちのモデルは、1 ステップ、2 ステップ、4 ステップ、および 8 ステップで画像を生成できます。推論ステップが多いほど、画質は向上します。
4 段階のプロセスの結果は次のとおりです。
2 ステップのビルドの結果は次のとおりです。
以前の方法 (Turbo および LCM) と比較して、私たちの方法は詳細が大幅に改善され、元の生成モデルのスタイルとレイアウトにより忠実な画像を生成します。

コミュニティへの還元、オープンモデル
オープンソースの波は、人工知能の急速な発展を促進する重要な力となっており、ByteDance はこの波に加わっていることを誇りに思っています。私たちのモデルは SDXL に基づいています。SDXL は現在、テキスト生成画像の最も人気のあるオープン モデルであり、すでに盛んなエコシステムを持っています。今回、私たちは SDXL-Lightning を世界中の開発者、研究者、クリエイティブな実践者に公開し、彼らがこのモデルにアクセスして適用し、業界全体のイノベーションとコラボレーションをさらに促進できるようにすることを決定しました。
SDXL-Lightning を設計する際、オープン モデル コミュニティとの互換性を考慮しました。コミュニティの多くのアーティストや開発者が、漫画やアニメのスタイルなど、さまざまな様式化された画像生成モデルを作成しています。これらのモデルをサポートするために、SDXL-Lightning を高速化プラグインとして提供します。これは、これらのさまざまなスタイルの SDXL モデルにシームレスに統合して、さまざまなモデルの画像生成を高速化できます。
 私たちのモデルは、現在非常に人気のある制御プラグイン ControlNet と組み合わせて、非常に高速で制御可能な画像生成を実現することもできます。
私たちのモデルは、現在非常に人気のある制御プラグイン ControlNet と組み合わせて、非常に高速で制御可能な画像生成を実現することもできます。
 私たちのモデルは、現在オープンソース コミュニティで最も人気のある生成ソフトウェアである ComfyUI もサポートしており、モデルを直接ロードして使用することができます。
私たちのモデルは、現在オープンソース コミュニティで最も人気のある生成ソフトウェアである ComfyUI もサポートしており、モデルを直接ロードして使用することができます。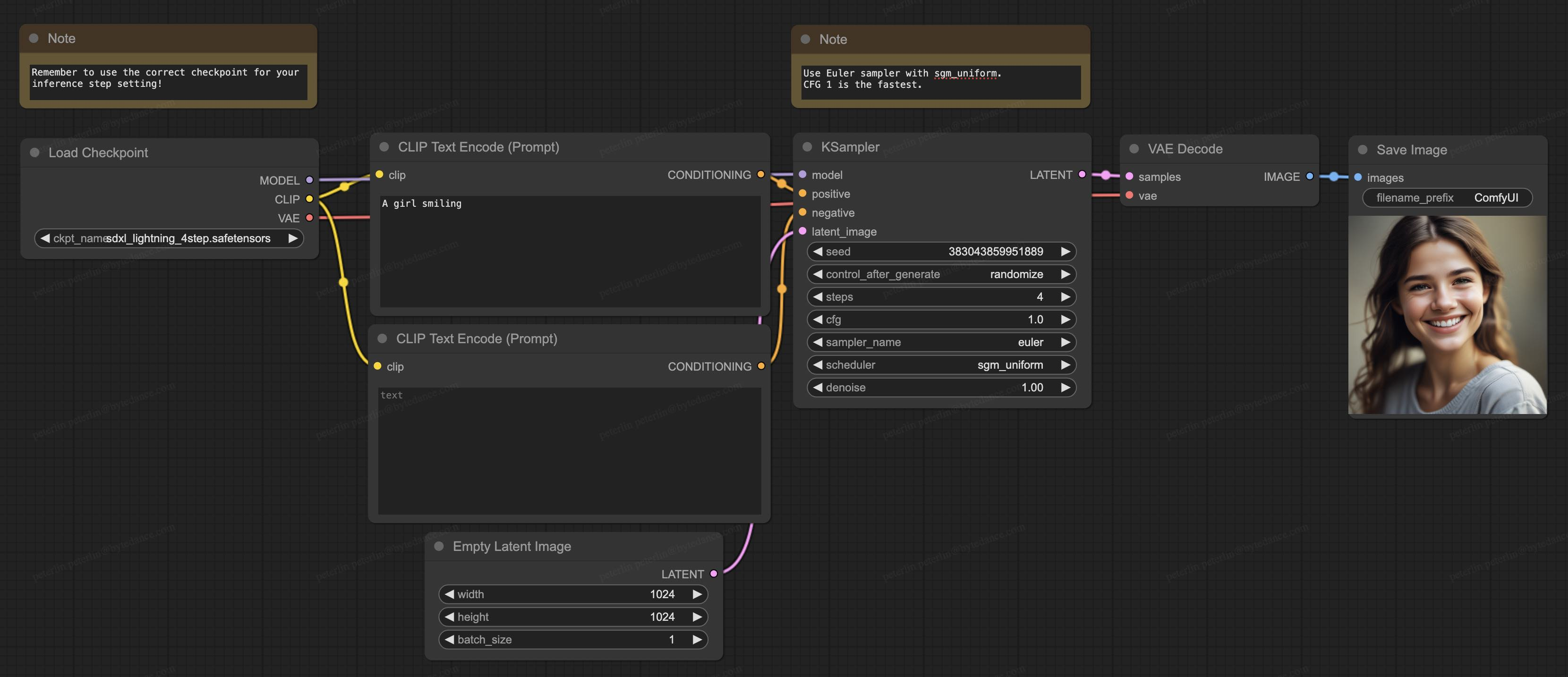
技術的な詳細について
理論的には、画像生成はノイズから鮮明な画像への段階的な変換プロセスです。このプロセスでは、ニューラル ネットワークは変換フローのさまざまな位置での勾配を学習します。
画像を生成する具体的な手順は次のとおりです。まず、ストリームの開始点でノイズ サンプルをランダムにサンプリングし、次にニューラル ネットワークを使用して勾配を計算します。現在の位置の勾配に基づいてサンプルに微調整を加え、このプロセスを繰り返します。反復するたびに、鮮明な画像が得られるまで、サンプルは最終的な画像分布に近づきます。
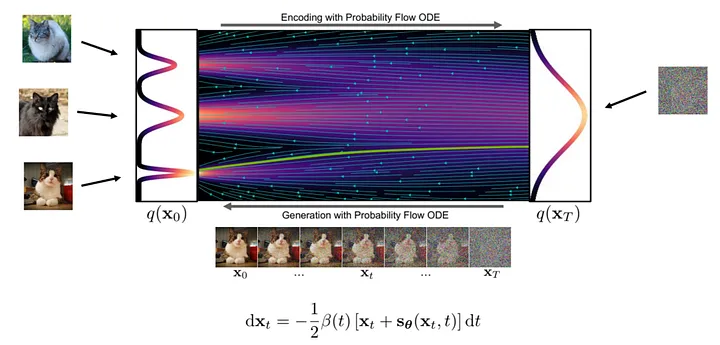 図: 生成プロセス ( 画像 は https://arxiv.org/abs/2011.13456 より)
図: 生成プロセス ( 画像 は https://arxiv.org/abs/2011.13456 より)
生成フローは複雑かつ非線形であるため、勾配誤差の蓄積を減らすために一度に小さなステップで生成する必要があるため、ニューラルネットワークの頻繁な計算が必要となり、計算量が大きくなります。
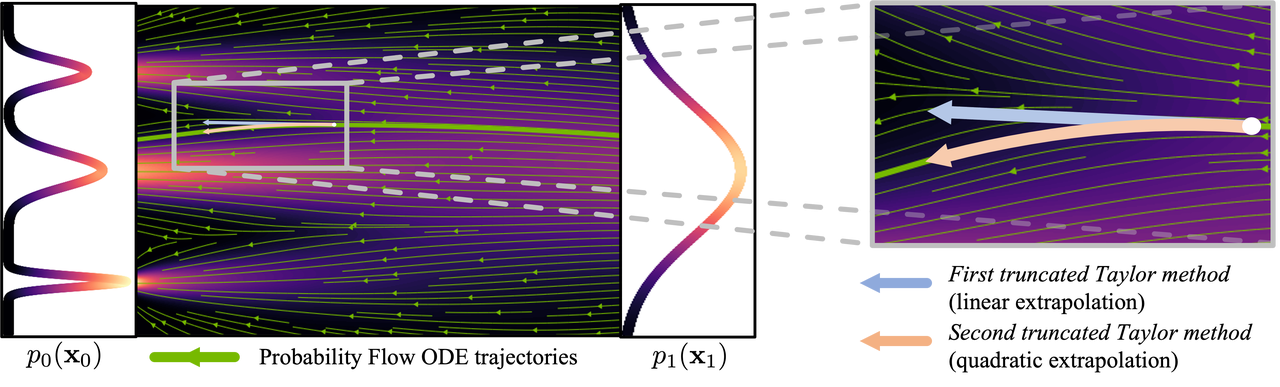 図: 曲線プロセス ( 画像 は https://arxiv.org/abs/2210.05475 から)
図: 曲線プロセス ( 画像 は https://arxiv.org/abs/2210.05475 から)
画像の生成に必要な手順の数を減らすために、解決策を見つけるために多くの研究が行われてきました。誤差を減らすサンプリング方法を提案する研究もあれば、生成された流れをより線形にしようとする研究もあります。これらの方法は進歩していますが、画像を生成するには依然として 10 を超える推論ステップが必要です。
もう 1 つの方法はモデル蒸留であり、10 未満の推論ステップで高品質の画像を生成できます。現在の流れ位置での勾配を計算する代わりに、モデル蒸留はモデル予測のターゲットを変更して、次に遠い流れ位置を直接予測します。具体的には、複数ステップの推論を完了した後、教師ネットワークの結果を直接予測するように生徒ネットワークをトレーニングします。このような戦略により、必要な推論ステップの数を大幅に削減できます。このプロセスを繰り返し適用することで、推論ステップの数をさらに減らすことができます。このアプローチは、以前の研究では漸進蒸留と呼ばれていました。
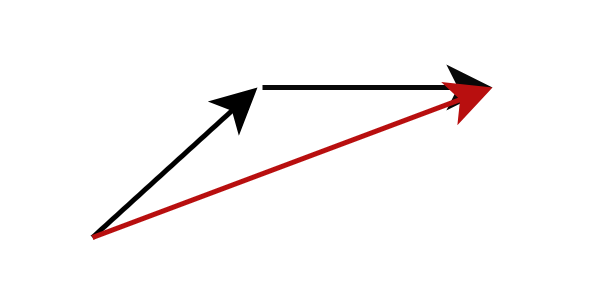 図: 漸進的蒸留 、複数のステップを経て生徒ネットワークが教師ネットワークの結果を予測
図: 漸進的蒸留 、複数のステップを経て生徒ネットワークが教師ネットワークの結果を予測
実際には、学生ネットワークは将来の流れの位置を正確に予測することが難しいことがよくあります。各ステップが累積するにつれて誤差が増幅し、推論の 8 ステップ未満でモデルによって生成された画像がぼやけ始めます。
この問題を解決するための私たちの戦略は、生徒のネットワークを教師のネットワークの予測と完全に一致させることではなく、確率分布の観点から生徒のネットワークを教師のネットワークと一致させることです。言い換えれば、学生ネットワークは確率的に考えられる位置を予測するように訓練されており、たとえその位置が完全に正確でなくても、ペナルティを課すことはありません。この目標は、生徒と教師のネットワーク出力の分布一致を達成するのに役立つ追加の識別ネットワークを導入する敵対的トレーニングを通じて達成されます。
これは私たちの研究方法の簡単な概要です。弊社の技術文書 ( https://arxiv.org/abs/2402.13929 ) では、より詳細な理論分析、トレーニング戦略、モデルの具体的な定式化の詳細を提供しています。
SDXL ライトニングを超えて
この研究では主に画像生成に SDXL-Lightning テクノロジーを使用する方法を検討していますが、私たちが提案するプログレッシブ敵対的蒸留法の応用可能性は静止画像に限定されません。この革新的なテクノロジーは、ビデオ、オーディオ、その他のマルチモーダル コンテンツを迅速かつ高品質で生成するために使用することもできます。ぜひ、HuggingFace プラットフォームで SDXL-Lightning を体験していただき、貴重なご意見やフィードバックをお待ちしております。
モデル: https://huggingface.co/ByteDance/SDXL-Lightning
論文: https://arxiv.org/abs/2402.13929
仲間のニワトリがDeepin-IDE を 「オープンソース」化し、ついにブートストラップを達成しました。 いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた Tencent Cloud の 4 月 8 日の障害レビューと状況説明 RustDesk リモート デスクトップ起動の再構築 Web クライアント WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始 TIOBE 4 月リスト: PHPは史上最低値に落ち、 FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし 、Google は大規模なコード モデル CodeGemma をリリースしました 。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツール