
01
背景
02
Venus ログプラットフォームの紹介
Venus は、iQiyi が開発したログ サービス プラットフォームで、ログの収集、処理、保存、分析などの機能を提供しており、主に社内のログのトラブルシューティング、ビッグ データの分析、監視、警報に使用されます。 1.示されています。
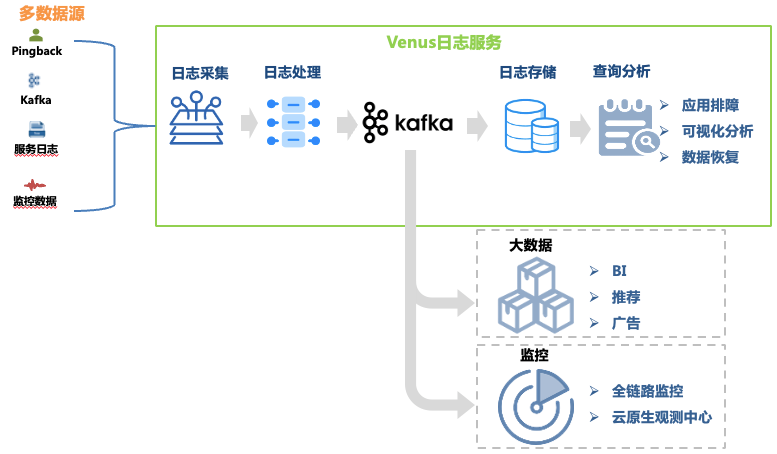 図 1 金星リンク
図 1 金星リンク
この記事では、ログのトラブルシューティング リンクのアーキテクチャの進化に焦点を当てています。そのデータ リンクには次のものが含まれます。
ログ収集:マシンやコンテナホストに収集エージェントを導入することで、フロントエンド、バックエンド、監視など各業務のログを収集し、フォーマット要件に合わせたログの自己配信にも対応。 30,000 を超えるエージェントがデプロイされ、Kafka、MySQL、K8、ゲートウェイなど 10 のデータ ソースをサポートしています。
ログ処理: ログ収集後、定期的な抽出や組み込みパーサー抽出などの標準化された処理が行われ、JSON 形式で Kafka に均一に書き込まれ、ダンプ プログラムによってストレージ システムに書き込まれます。
ログ ストレージ: Venus は 10,000 近くのビジネス ログ ストリームを保存し、書き込みピークは 1,000 万 QPS を超え、毎日の新しいログは 500 TB を超えます。ストレージ規模の変化に伴い、ストレージ システムの選択も ElasticSearch からデータ レイクまで多くの変化を遂げてきました。
クエリ分析: Venus は、ビジュアル クエリ分析、コンテキスト クエリ、ログ ディスク、パターン認識、ログ ダウンロードなどの機能を提供します。
大量のログ データのストレージと迅速な分析に対応するために、Venus ログ プラットフォームは 3 つの主要なアーキテクチャ アップグレードを経て、古典的な ELK アーキテクチャからデータ レイクに基づく自社開発システムに徐々に進化しました。この記事では、遭遇した問題について紹介します。 Venus のアーキテクチャとソリューションの変革中。
03
Venus 1.0: ELK アーキテクチャに基づく
Venus 1.0 は 2015 年に開始され、図 2 に示すように、当時人気のあった ElasticSearch+Kibana に基づいて構築されました。 ElasticSearch はログのストレージと分析機能を担当し、Kibana は視覚的なクエリと分析機能を提供します。ログ サービスを提供するには、Kafka を使用して ElasticSearch にログを書き込むだけです。
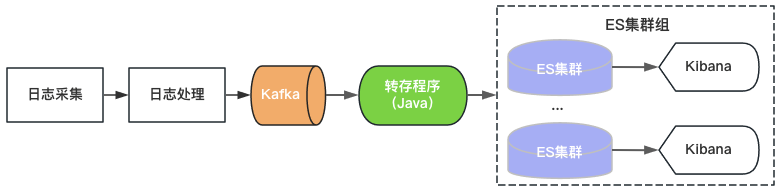 図 2 Venus 1.0 アーキテクチャ
図 2 Venus 1.0 アーキテクチャ
単一の ElasticSearch クラスターのスループット、ストレージ容量、インデックス シャードの数には上限があるため、Venus は増大するログ需要に対応するために新しい ElasticSearch クラスターを追加し続けています。コストを制御するために、各 ElasticSearch の負荷は高レベルになり、インデックスは 0 コピーで構成され、突然のトラフィック書き込み、大規模なデータ クエリ、クラスターの使用不能につながるマシン障害などの問題が頻繁に発生します。同時に、クラスター上の多数のインデックス、大量のデータ、および長い回復時間により、ログが長期間利用できなくなり、Venus の使用エクスペリエンスはますます悪化します。
04
Venus 2.0: ElasticSearch + Hive ベース
クラスターの分類: ElasticSearch クラスターは、高品質と低品質の 2 つのカテゴリに分類されます。主要なビジネスは高品質のクラスターを使用し、クラスターの負荷は低レベルで制御され、インデックスは 1 コピー構成で有効になり、単一ノードの障害を許容します。非主要なビジネスは低品質のクラスターを使用します。は高レベルで制御されており、インデックスは引き続き 0 コピー構成を使用します。
ストレージ分類:長期保存ログの場合は、ElasticSearch と Hive を二重書き込みします。 ElasticSearch は過去 7 日間のログを保存し、Hive はより長期間のログを保存します。これにより、ElasticSearch のストレージ負荷が軽減され、大規模なデータ クエリによって ElasticSearch がハングアップするリスクも軽減されます。ただし、Hive は対話型のクエリを実行できないため、Hive のログはオフライン コンピューティング プラットフォームを介してクエリする必要があり、クエリ エクスペリエンスが低下します。
統合クエリ ポータル: Kibana に似た統合ビジュアル クエリおよび分析ポータルを提供し、基盤となる ElasticSearch クラスターを保護します。クラスターに障害が発生した場合、新しいログのクエリと分析に影響を与えることなく、新しく書き込まれるログが他のクラスターにスケジュールされます。クラスターの負荷が不均衡な場合、クラスター間のトラフィックを透過的にスケジュールします。
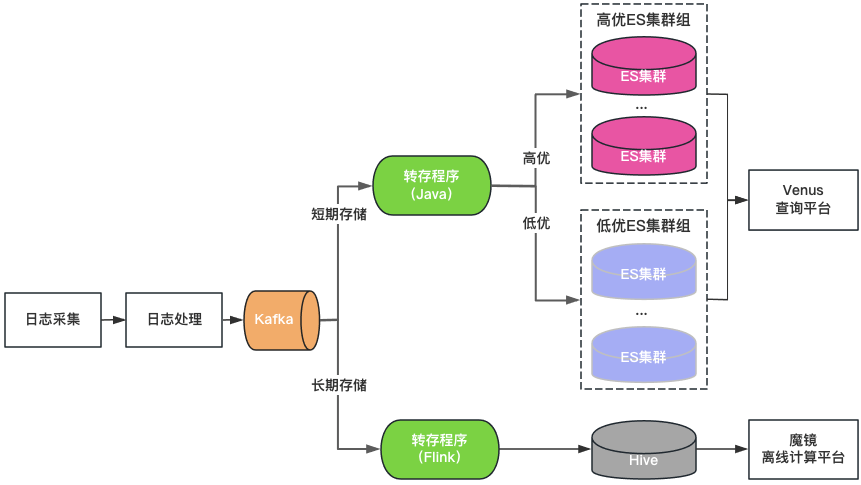
図 3 Venus 2.0 アーキテクチャ
Venus 2.0 は、主要なビジネスを保護し、障害のリスクと影響を軽減するための妥協的なソリューションです。コストが高く、安定性が低いという問題がまだあります。
ElasticSearch の保存期間は短い:大量のログのため、ElasticSearch は 7 日間しか保存できず、毎日のビジネス ニーズを満たすことができません。
多くの入り口とデータの断片化があります: 20 以上の ElasticSearch クラスター + 1 つの Hive クラスター、多くのクエリ入り口があり、クエリと管理にとって非常に不便です。
高コスト: ElasticSearch はログを 7 日間しか保存しませんが、それでも 500 台を超えるマシンを消費します。
統合された読み取りと書き込み: ElasticSearch サーバーは読み取りと書き込みを同時に処理し、相互に影響を与えます。
多くの障害: ElasticSearch 障害は、Venus の障害全体の 80% を占めます。障害が発生すると、読み取りと書き込みがブロックされ、ログが失われやすくなり、処理が困難になります。
05
Venus 3.0: データレイクに基づく新しいアーキテクチャ
データレイクの導入を検討中
金星のログシナリオを詳細に分析した後、その特徴を次のように要約します。
大量のデータ: 10,000 万 QPS のピーク書き込み容量と PB レベルのデータ ストレージを備えた約 10,000 のビジネス ログ ストリーム。
書き込み量を増やし、チェック量を減らす: 通常、企業はトラブルシューティングが必要な場合にのみログをクエリします。ほとんどのログには 1 日以内のクエリ要件がなく、全体的なクエリ QPS も非常に低くなります。
インタラクティブ クエリ: ログは主に、複数の連続したクエリを必要とし、第 2 レベルのインタラクティブ クエリ エクスペリエンスを必要とする緊急のシナリオのトラブルシューティングに使用されます。
ElasticSearch を使用してログを保存および分析するときに発生する問題については、次の理由により、Venus ログのシナリオと完全には一致していないと考えられます。
単一クラスターの書き込み QPS とストレージ スケールには制限があるため、複数のクラスターでトラフィックを共有する必要があります。クラスター サイズ、書き込みトラフィック、ストレージ スペース、インデックスの数などの複雑なスケジューリング戦略の問題を考慮する必要があるため、管理がさらに困難になります。ビジネス ログのトラフィックは大きく変動し、予測できないため、クラスターの安定性に対する突然のトラフィックの影響を解決するには、多くの場合、より多くのアイドル リソースを予約する必要があり、結果としてクラスター リソースが大量に浪費されます。
書き込み中の全文インデックス作成は CPU を大量に消費し、データの拡張とコンピューティングおよびストレージのコストの大幅な増加につながります。多くのシナリオでは、分析ログの保存にはバックグラウンド サービスのリソースよりも多くのリソースが必要です。書き込みが多くクエリが少ないログなどのシナリオでは、フルテキスト インデックスを事前計算する方がより贅沢です。
ストレージ データと計算は同じマシン上にあり、大量のデータのクエリや集計分析は書き込みに影響を与えやすく、書き込みの遅延やクラスター障害の原因となる場合があります。
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
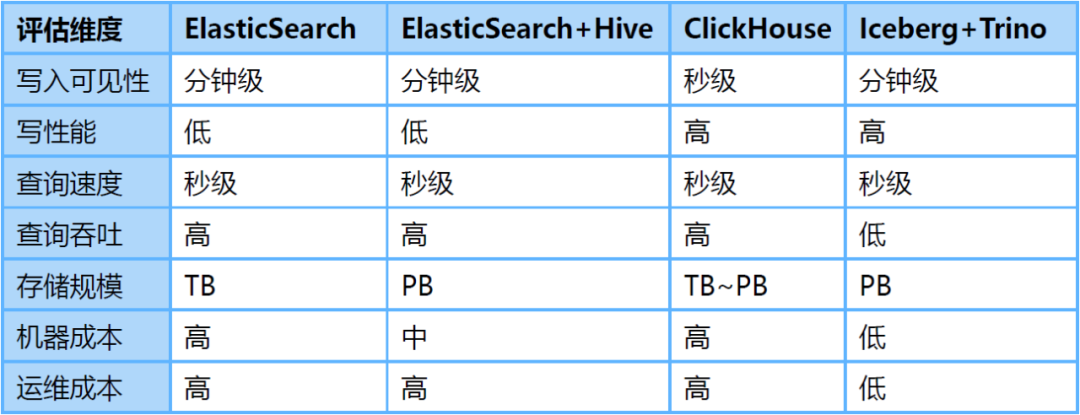
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
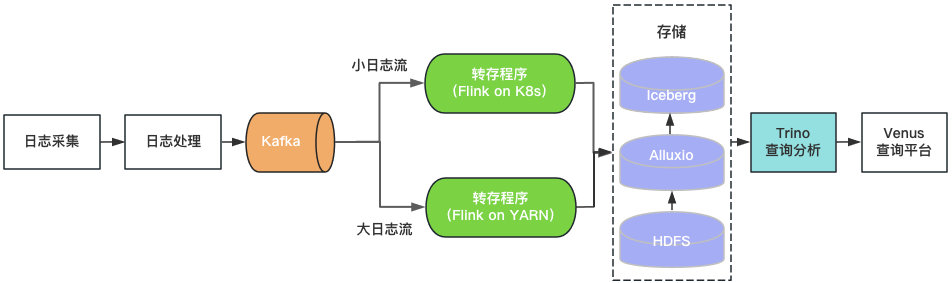 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
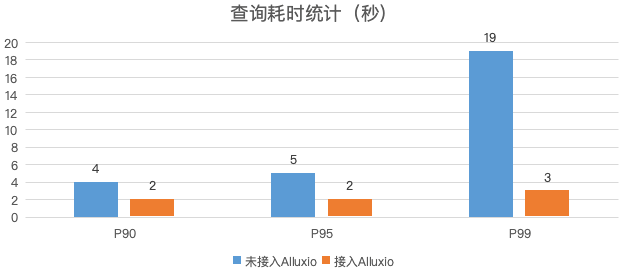
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。