目次
1. リストの基本構造
リスト クラスをシミュレートして実装する場合は、まずその基礎となるアーキテクチャを理解する必要があります。前のブログで説明したように、リスト コンテナーの最下層は二重リンク リストであるため、ノード クラスをカスタマイズする必要があります。ノード クラスを使用すると、ノードを作成し、ノードの前後のポインタとデータ値を設定できます。次に、このクラス タイプを通じてリスト クラスのメンバー変数を作成できます。
template<class T>
struct list_node { //该类为内部类,是list的内部类
list_node(const T& val)
:_next(nullptr)
, _prev(nullptr)
, _data(val) {
}
//成员变量
list_node* _next; //后指针
list_node* _prev; //前指针
T _data; //值
};
template<class T>
class list {
public:
typedef list_node<T> node; //将节点类作为类类型
private:
node* _head; //指向堆区空间链表的指针
size_t _size; //计数
};
node* タイプは、node クラスのカプセル化のようなものです。
2. 次に、リスト クラス コンストラクターの設計です。
template<class T>
class list {
public:
typedef list_node<T> node; //将节点类作为类类型
//初始化操作
void empty_Init() {
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
list() //构造函数
:_head(nullptr)
,_size(0){
empty_Init();
}
private:
node* _head; //指向堆区空间链表的指针
size_t _size; //计数
};コンストラクターの初期化設計は、センチネル ヘッド ノードを作成し、リンク リスト ポインターがセンチネル ヘッド ノードを指すようにし、ノードの追加、削除、チェック、および変更をセンチネル ヘッド ノードに制御させ、次のような制御の必要性を回避します。リンク リスト ポインターの操作と形式の両方で、はるかに便利になりました。
注: センチネル ヘッダー ノードは empty_Init() 関数で作成されます。
3. リンクリストデータの追加:
template<class T>
class list{
public:
typedef Node<T> node;
//尾插
void push_back(const T& val) {
node* newnode = new node(val);
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
++_size;
}
//尾删
void pop_back() {
assert(!empty());
node* tail = _head->_prev;
node* last = tail->_prev;
last->_next = _head;
_head->_prev = last;
delete tail;
--_size;
}
//头插
void push_front(const T& val) {
node* newnode = new node(val);
node* first = _head->_next;
_head->_next = newnode;
newnode->_prev = _head->_next;
newnode->_next = first;
first->_prev = newnode;
++_size;
}
//头删
void pop_front() {
assert(!empty());
node* first = _head->_next;
node* second = first->_next;
_head->_next = second;
second->_prev = _head->_next;
delete first;
--_size;
}
//任意位置的插入
iterator insert(iterator pos, const T& val=T()) {
if (pos == this->begin()) {
push_front(val); //复用代码
}
else if (pos == this->end()) {
push_back(val); //复用代码
}
else {
node* newnode = new node(val);
node* cur = pos.phead;
node* last = cur->_prev;
last->_next = newnode;
newnode->_prev = last;
newnode->_next = cur;
cur->_prev = newnode;
++_size;
}
return pos;
}
//任意位置的删除
iterator erase(iterator pos) {
assert(!empty());
if (pos == this->begin()) {
pop_front();
}
else if (pos == this->end()) {
pop_back();
}
else {
node* cur = pos.phead;
node* tail = cur->_next;
node* last = cur->_prev;
last->_next = tail;
tail->_prev = last;
delete cur;
--_size;
}
return pos;
}
private:
node* _head; //指向堆区空间链表的指针
size_t _size; //计数
};データの追加と削除については、先頭プラグの削除と末尾プラグの削除が簡単です。焦点は挿入と消去関数の実装です。上記のコードに示すように、挿入と消去では、それぞれ 3 つの状況があり、先頭と末尾の操作は直接的です 関数を再利用するだけです 中間位置での挿入と削除の場合、私が言いたいのは、指定された pos パラメーターはイテレーター型 (ポインターであるカスタム イテレーター クラス) であるということです。!!これはノード要素の位置を指すだけなので、その位置にあるノードを取得したい場合は、ノードを取得するために pos.phead が必要です。ノードを取得するときにのみ、ノードの近くの前後のポインターを使用できます。 !
4. 次のステップでは、イテレータを作成します。
Vector コンテナと String コンテナのシミュレーション実装では、別々のイテレータを作成しませんでした。これは、これら 2 つのコンテナの最下位層が連続したアドレス空間である配列であるためです。イテレータ内のメンバーの開始と終了は、直接指定できます。ポインタ型バイト ++/-- 位置を決定するためにネイティブ ポインタを使用すると非常に便利です。
リスト コンテナの場合、その最下層はリンク リストであり、各ノードの位置は不連続かつランダムです。ネイティブ ポインターを使用しても、オブジェクトのすべての要素をトラバースすることはできません。したがって、リスト コンテナーの場合は、リンク リストを走査するためのカスタム型イテレーターを作成する必要があります。
template<class T>
struct list_iterator
{
typedef list_node<T> node;
node* _pnode; //成员变量
list_iterator(node* p) //构造函数
:_pnode(p){}
T& operator*(){ //指针解引用
return _pnode->_data;
}
list_iterator<T>& operator++(){ //指针++
_pnode = _pnode->_next;
return *this;
}
bool operator!=(const list_iterator<T>& it){ //!=运算符重载
return _pnode != it._pnode;
}
};
template<class T>
class list{
public:
typedef list_node<T> node;
typedef list_iterator<T> iterator;
iterator begin(){
return iterator(_head->_next);
}
iterator end(){
//iterator it(_head);
//return it;
return iterator(_head);
}
};
カスタム反復子クラスでは、私が普段練習しているベクトルと文字列の反復子コードに基づいて確実に使用されるいくつかの演算子オーバーロード関数を作成しました: dereference、pointer++、!=、および traversal で使用されるその他の関数。
カスタム反復子クラスを作成した後、リスト クラス内のクラスの名前を変更する必要があります。
イテレータを作成した後、それをテストできます。
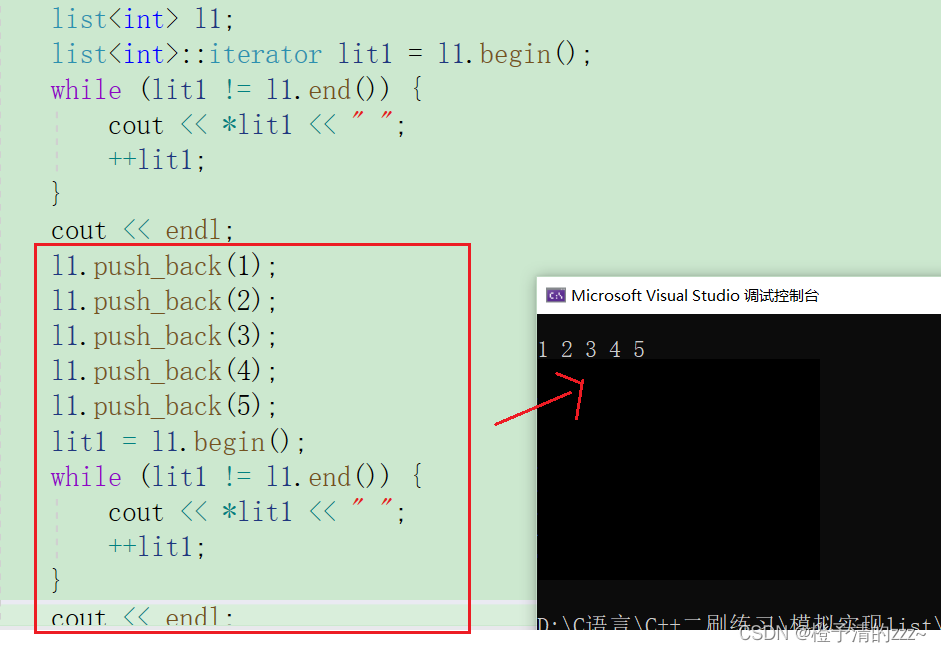
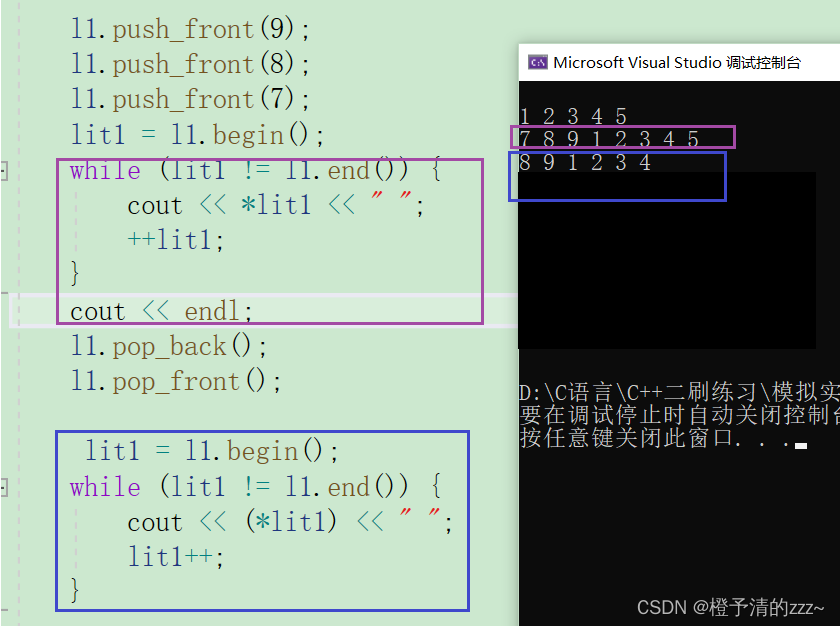
注: 上記のイテレータは通常のイテレータの実装に過ぎませんが、const イテレータとリバース イテレータも実装する必要があるため、さらに 2 つのイテレータ クラスを作成する必要があります。
4. 単純な関数の実装:
template<class T>
class list{
public:
size_t size()const {
return _size;
//方法2:利用指针遍历,每遍历一次记一次数
}
bool empty() const {
//方法1:
return _size == 0;
//方法2:return _head->next==_head;
}
void clear() {
node* cur = _head->_next;
while (cur != _head) {
node* del = cur;
cur = cur->_next;
delete del;
}
cur->_next = _head;
cur->_prev = _head;
_size = 0;
}
T& front() {
return this->begin().phead->_data;
}
T& back() {
return this->end().phead->_prev->_data;
}
private:
node* _head;
size_t _size;
};
5. 建設と破壊
イテレータを使用すると、リスト コンストラクターのイテレータ間隔構造を実装できます。
template<class T>
class list{
public:
//迭代器区间构造函数
template<class Inputiterator>
list(Inputiterator first, Inputiterator last) {
empty_Init();
while (first != last) {
push_back(*first);
++first;
}
}
void empty_Init() {
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
list() //无参构造
{
empty_Init();
}
//析构函数
~list() {
this->clear();
delete _head;
_head = nullptr;
_size = 0;
}
private:
node* _head;
size_t _size;
};デストラクターは、リンクされたリスト内の各ノードを走査して解放し、ポインターを null に設定し、変数を 0 に設定します。
6. コピー構築と代入のオーバーロード
伝統的な書き方:
//拷贝构造——传统写法
list(const list<T>& lt) {
empty_Init();
for (auto& e : lt) {
this->push_back(e);
}
}
//赋值重载函数——传统写法
list<T>& operator=(const list<T>& lt) {
if (this != <) {
this->clear();
}
for (const auto& e : lt) {
this->push_back(e);
}
return *this;
}コピーの構築と代入のオーバーロードは本質的に同じで、既存のリスト オブジェクトをコピーし、データをそれ自体にディープ コピーします。ディープ コピーは、独自のヘッド ノードを作成し、残りのデータはシャロー コピー (頭を使わずにデータを走査して、自身のヘッド ポインターにポインター リンクを実行させる) です。
現代文:
//调用std库中swap函数进行成员交换
void Swap(list<T>& lt) {
std::swap(this->_head, lt._head);
std::swap(this->_size, lt._size);
}
//拷贝构造——现代写法
list(const list<T>& lt) {
empty_Init();
list<T> tmp(lt.begin(), lt.end()); //调用迭代器区间构造函数
this->Swap(tmp);
}
//赋值重载——现代写法
list<T>& operator=(list<T> lt) {
this->Swap(lt); //值传递,形参的改变不影响实参
return *this;
}
7. イテレータテンプレートの種類
上記のイテレータの説明の最後で述べたように、イテレータには通常バージョン、const バージョン、逆バージョン、および逆 const バージョンがあります。つまり、4 つのイテレータ型を作成する必要がありますが、演算子は関数をオーバーロードしました。イテレータによって使用されるものは同じです。 、すべて逆参照、ポインタ++、!= 演算子です。
//自定义普通迭代器类
template<class T>
struct list_iterator{
typedef list_node<T> node;
node* _pnode;
list_iterator(node* p)
:_pnode(p){}
T& operator*(){
return _pnode->_data;
}
list_iterator<T>& operator++(){
_pnode = _pnode->_next;
return *this;
}
list_iterator<T>& operator--(){
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const list_iterator<T>& it){
return _pnode != it._pnode;
}
};
//const迭代器类
template<class T>
struct list_const_iterator{
typedef list_node<T> node;
node* _pnode;
list_const_iterator(node* p)
:_pnode(p){}
const T& operator*(){
return _pnode->_data;
}
list_const_iterator<T>& operator++(){
_pnode = _pnode->_next;
return *this;
}
list_const_iterator<T>& operator--(){
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const list_const_iterator<T>& it){
return _pnode != it._pnode;
}
};
template<class T>
class list{
typedef list_node<T> node;
public:
typedef list_iterator<T> iterator;
typedef list_const_iterator<T> const_iterator;
const_iterator begin() const{
return const_iterator(_head->_next);
}
const_iterator end() const{
return const_iterator(_head);
}
iterator begin(){
return iterator(_head->_next);
}
iterator end(){
return iterator(_head);
}上記のように、通常のイテレータ クラスと const イテレータ クラスの唯一の違いは、トラバーサルでは * const イテレータ クラスの逆参照演算子オーバーロード関数内のデータを変更するために使用できないため、これら 2 つのイテレータ クラスの他の関数の実装は同様に、これはコードの冗長性を大幅に引き起こし、可読性を低下させます。!!
したがって、1 つのイテレータ クラスでさまざまなタイプのイテレータを具体化するには、次のようにすることができます。
template<class T, class Ref, class Ptr>
struct _list_iterator {
typedef list_node<T> node;
typedef _list_iterator<T, Ref,Ptr> Self; //Self是T与ref,ptr 模板类型的另一种别称
//迭代器构造函数
_list_iterator(node* p)
:_pnode(p) {}
//解引用
Ref operator*() {
return _pnode->_data;
}
//箭头只有是结构体才可以用
Ptr operator->() {
return &_pnode->_data; //返回的是该结点的地址
}
Self& operator++() {
_pnode = _pnode->_next;
return *this;
}
//后置++,使用占位符int,与前置++以示区分
Self operator++(int) {
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
//前置--
Self& operator--() {
_pnode = _pnode->_prev;
return *this;
}
//后置--
Self operator--(int) {
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
bool operator!=(const Self& lt) const {
return _pnode != lt._pnode;
}
bool operator==(const Self& lt) const{
return _pnode == lt._pnode;
}
node* _pnode;
};
イテレータ クラスでは、3 つのテンプレート パラメータが取得されます。これら 3 つのテンプレート パラメータ: T はジェネリック値を表し、Ref はジェネリック参照を表し、Ptr はジェネリック ポインタを表します。これら 3 つのパラメータは主に関数の戻り値と、演算子オーバーロードされた関数の関数パラメータに使用されます。これらは非常に便利であり、機能します。複数の目的: 異なる実パラメータを渡すことで、異なるタイプの関数を呼び出すことができます。
template<class T>
class list {
public:
typedef list_node<T> node;
typedef _list_iterator<T, T&, T*> iterator;
//typedef list_const_iterator<T> const_iterator;
typedef _list_iterator<T, const T&, const T*> const_iterator;完全なシミュレーション実装コード .h ファイル:
#include<iostream>
#include<assert.h>
using std::cout;
using std::endl;
template<class T>
struct list_node { //该类为内部类,是list的内部类
list_node(const T& val)
:_next(nullptr)
, _prev(nullptr)
, _data(val) {
}
//成员变量
list_node* _next;
list_node* _prev;
T _data;
};
//typedef list_iterator<T, T&> iterator;
//typedef list_iterator<T, const T&> const_iterator;
//这种写法来源:vector<int>,vector<string>,vector<vector<int>>
template<class T, class Ref, class Ptr> //新增一个模板参数 ,T是一种类型,ref是一种类型
struct list_iterator {
typedef list_node<T> node;
typedef list_iterator<T, Ref, Ptr> Self; //Self是T与ref,ptr 模板类型的另一种别称
//迭代器构造函数
list_iterator(node* p)
:_pnode(p) {}
//在下面的运算符重载中,const版与非const版只有解引用运算符重载函数的类型不同,其他运算符重载都一样
//所以operator* 的类型需要使用ref,ref可以理解为constT&, 而非const对象也可以调用const函数,权限够
//const对象不可调用非const函数,权限不够,所以使用ref
//解引用
Ref operator*() {
return _pnode->_data;
}
//箭头只有是结构体才可以用
Ptr operator->() {
return &_pnode->_data; //返回的是该结点的地址
}
//前置++,
//为啥要用引用? 原因:return *this ,this(迭代器对象)出了该函数体,还存在(this的生命周期在该类中是全局的)
Self& operator++() {
_pnode = _pnode->_next;
return *this;
//既然this还在,那么直接用引用返回,栈帧中不开临时空间,减少拷贝次数,提高效率
//记住:使用引用返回的前提是,要返回的值出了函数体仍在才可以使用,否则会报错
}
//后置++,使用占位符int,与前置++以示区分
Self operator++(int) {
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
//返回tmp后,tmp为临时对象,出了函数就消失了,tmp对象不在,需要拷贝,那就得用传值返回,在栈帧中
//创建一个临时空间去接收返回的tmp对象数据。设置一个默认参数和前置++做区分,构成函数重载。
//若使用引用返回,那么该函数结束后,返回的tmp已经不存在了,引用返回返回野指针(随机值)就会报错!!!
}
Self& operator--() {
_pnode = _pnode->_prev;
return *this;
}
//后置--
Self operator--(int) {
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
bool operator!=(const Self& lt) const {
return _pnode != lt._pnode;
}
bool operator==(const Self& lt) const{
return _pnode == lt._pnode;
}
node* _pnode;
};
//--------------------------------------------------------------------------------
template<class T>
class list {
public:
typedef list_node<T> node;
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
void empty_Init() {
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
list(){
empty_Init();
}
//析构
~list() {
this->clear();
delete _head;
_head = nullptr;
_size = 0;
}
template<class Inputiterator>
list(Inputiterator first, Inputiterator last) { //拷贝构造的天选打工人
//先初始化,给头节点,否则没法继续
empty_Init();
while (first != last) {
push_back(*first);
++first;
}
}
void swap(list<T>& lt) {
std::swap(this->_head, lt._head);
std::swap(this->_size, lt._size);
}
void clear() {
iterator it = this->begin();
while (it != this->end()) {
it = this->erase(it);
}
}
//拷贝构造——传统写法
/*list(const list<T>& lt) {
empty_Init();
for (auto& e : lt) {
this->push_back(e);
}
}*/
//拷贝构造——现代写法
list(const list<T>& lt) {
empty_Init();
list<T> tmp(lt.begin(), lt.end()); //调用迭代器区间构造函数
this->swap(tmp);
}
//赋值重载——传统写法
/*list<T>& operator=(const list<T>& lt) {
if (this != <) {
this->clear();
}
for (const auto& e : lt) {
this->push_back(e);
}
return *this;
}*/
//赋值重载——现代写法
list<T>& operator=(list<T> lt) {
this->swap(lt);
return *this;
}
//迭代器
iterator begin() {
return iterator(_head->_next);
}
iterator end() {
return iterator(_head);
}
//const迭代器
const_iterator begin() const {
return const_iterator(_head->_next);
}
const_iterator end() const {
return const_iterator(_head);
}
//尾插
void push_back(const T& val) {
node* newnode = new node(T(val));
node* tail = _head->_prev;
tail->_next = newnode;
newnode->_prev = tail;
newnode->_next = _head;
_head->_prev = newnode;
}
//insert
iterator insert(iterator pos, const T& val) {
node* newnode = new node(T(val));
node* cur = pos._pnode;
node* first = cur->_prev;
first->_next = newnode;
newnode->_prev = first;
newnode->_next = cur;
cur->_prev = newnode;
_size++;
//insert后返回新节点的位置,那么下一次pos就会指向最近一次创建新节点的位置了
return iterator(newnode);
}
iterator erase(iterator pos) {
//pos不能指向哨兵位头节点,因为pos一旦指向哨兵位头,那么该链表一定为空,空链表是不能再删数据的
assert(pos != end());
node* first = pos._pnode->_prev;
node* last = pos._pnode->_next;
first->_next = last;
last->_prev = first;
delete pos._pnode;
pos._pnode = nullptr;
--_size;
return iterator(last);
}
void push_front(const T& val) {
insert(begin(), val);
}
void pop_back() {
erase(--end());
}
void pop_front() {
erase(begin());
}
size_t size() const{
/*size_t s = 0;
iterator it = this->begin();
while (it != this->end()) {
++it;
++s;
}
return s;*/
//复用insert和erase
//因为在链表中,一切的新增和减少都是复用的insert和erase,所以在insert和erase中size++,size--即可
return _size;
}
bool empty() const {
//return _head->_next == _head;
//也可以复用size()
return _size == 0;
}
private:
node* _head; //头节点
size_t _size;
};