自動機械学習AutoML
AutoML
機械学習アルゴリズムの開発者にとって、モデルの選択やハイパーパラメータの調整などのタスクは面倒な作業ですが、機械がモデルを自動的に設計および調整できるようにするために、自動機械学習 AutoML が登場しました。
自動化された機械学習は、自動化された ML または AutoML とも呼ばれ、機械学習モデルの開発における時間のかかる反復的なタスクを自動化するプロセスです。AutoML の主な機能は、機械学習モデルの構築とデプロイのしきい値を下げることであり、機能の選択、モデルの選択、ハイパーパラメーターの調整などの一連のタスクを自動化することで、手動介入の必要性を効果的に減らし、精度を向上させることができます。モデルの性能です。
AutoML は主に Neural Architecture Search (NAS) に基づいており、このアルゴリズムは主に検索空間と検索戦略を含むモデルの自動生成を実現し、生成されたモデルのパフォーマンスを自動的に評価します。現在、NAS は画像分類、ターゲット検出、音声認識、自然言語処理のさまざまなモデルで広く使用されています。
- サーチ スペースの定義: NAS はまず、考えられるすべてのニューラル ネットワーク構造を含むサーチ スペースを定義します。これには、さまざまなタイプのレイヤー、レイヤー間の接続方法、各レイヤーの幅と深さなどが含まれます。
- 検索戦略: NAS は、通常はヒューリスティックまたは最適化手法に基づく検索アルゴリズムを使用して、検索スペース内で最適なネットワーク構造を見つけます。これらのアルゴリズムは、遺伝的アルゴリズム、強化学習、進化的アルゴリズム、ベイズ最適化などに基づくことができます。
- 評価と更新: 検索されたネットワーク構造ごとに、そのパフォーマンスを評価する必要があります。これは通常、ニューラル ネットワークをトレーニングし、検証セットで評価することによって行われます。パフォーマンス評価後、次のラウンドの検索を最適化するために、評価結果に基づいて検索アルゴリズムの重みが更新されます。
- 検索の高速化: NAS の検索スペースは大きいため、検索プロセスに非常にコストがかかる場合があります。したがって、研究者は、パラメータの共有、モデルのスケーリングの採用、代理モデルの使用などによって、検索を高速化するいくつかの方法を提案しています。
AutoML を使用するには、通常、次の手順が必要です。
- データの準備: トレーニングと評価用にデータ セットを準備します。
- AutoML ツールを選択する: タスクに適した AutoML ツールまたはプラットフォームを選択します。一般的な AutoML ツールには、Auto-Sklearn、AutoKeras、AutoGluon、Google AutoML、Azure、Auto-PyTorch などが含まれます。
- 検索スペースの構成: モデルとハイパーパラメーターの検索スペースを定義します。これには、適切なモデル タイプの選択、ハイパーパラメータの範囲の設定などが含まれる場合があります。
- AutoML を実行する: AutoML ツールを起動すると、定義された検索スペースで最適なモデルとハイパーパラメーターの組み合わせが自動的に検索されます。
- モデルの評価: AutoML によって取得されたモデルを評価して、そのパフォーマンスを理解します。これには通常、検証セットまたは相互検証を使用して、モデルの一般化能力をチェックすることが含まれます。
- モデルをデプロイする: 満足したら、実際の予測のために AutoML で生成されたモデルを運用環境にデプロイします。
以下は、Auto-Sklearn、AutoKeras、AutoGluon、Google AutoML、Azure 自動機械学習を含む 5 つの AutoML ツールの紹介です。
自動Sklearn
Auto-Sklearn は、Scikit-Learn ライブラリに基づいて構築され、自動モデル選択とチューニングを提供する人気の AutoML ツールです。実際の使用では、データの特性に基づいて、異なるメトリクスの選択、モデルの探索空間の調整など、より詳細な設定が必要になる場合があります。Auto-Sklearn には多くの構成オプションが用意されており、ユーザーは自動化プロセスをより柔軟にカスタマイズできます。さらに、Auto-Sklearn の API を介してモデルの詳細にアクセスし、選択する最適なモデルをより深く理解することができます。詳細については、Github の公式Web サイトを参照してください。

Python コードの例: Auto-Sklearn を使用して手書き数字 (Digits) のデータセットを分類します。これは、タスクに基づいて独自のデータセットに置き換えることができます。time_left_for_this_task および per_run_time_limit パラメータは、Auto-Sklearn の実行時間を制限するために使用されることに注意してください。
# 安装Auto-Sklearn
!pip install auto-sklearn
# 导入必要的库
import autosklearn.classification
from sklearn.model_selection import train_test_split
from sklearn import datasets
# 加载示例数据集(如果没有,可以替换为自己的数据集)
X, y = datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 创建并训练Auto-Sklearn分类器
automl_classifier = autosklearn.classification.AutoSklearnClassifier(time_left_for_this_task=120, per_run_time_limit=30)
automl_classifier.fit(X_train, y_train)
# 在测试集上评估模型性能
accuracy = automl_classifier.score(X_test, y_test)
print(f"Accuracy: {
accuracy}")
# 获取Auto-Sklearn所选用的模型信息
print(automl_classifier.show_models())
AutoKeras
AutoKeras は、テキサス A&M 大学によって開発された、Keras をベースとしたオープンソースの AutoML フレームワークで、簡単に始めることができ、さまざまなニューラル ネットワーク構造を試すことができます。詳細については、Github の公式Web サイトを参照してください。
Python コードの簡単な例:
# 安装autokeras
pip install autokeras
# 导入autokeras库
import autokeras as ak
# 创建模型
clf = ak.ImageClassifier()
# 模型训练
clf.fit(x_train, y_train)
# 模型测试
results = clf.predict(x_test)
オートグルーオン
AutoGluon は、Apache MXNet コミュニティ (Amazon) によって開発されたもう 1 つのオープン ソース AutoML フレームワークで、非常に簡単に始めることができ、強力な機能を備えています。機械学習モデルのトレーニングと導入プロセスを簡素化するように設計されており、ユーザーは深い専門知識を必要とせずに高性能モデルを簡単に構築できます。モデルとハイパーパラメーターの選択に重点を置く他の AutoML フレームワークとは異なり、AutoGluon は複数のモデルを統合し、それらを複数のレイヤーに積み重ねることによって、より優れたパフォーマンスを実現できます。詳細については、Github の公式Web サイトを参照してください。
Python コードの例: クラス列がターゲット ラベルである、バイナリ分類用の表形式のデータ セットがあるとします。AutoGluon は、適切なモデルを自動的に選択してハイパーパラメーターを最適化し、テスト セットのパフォーマンス メトリックと予測結果を返します。
# 安装AutoGluon
!pip install autogluon
# 导入AutoGluon相关模块
from autogluon import TabularPrediction as task
# 加载示例数据集(如果没有,可以替换为自己的数据集)
train_data = task.Dataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
test_data = task.Dataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
# 定义任务类型为二分类
predictor = task.fit(train_data=train_data, label='class', problem_type='binary')
# 在测试集上评估模型性能
performance = predictor.evaluate(test_data)
# 打印性能指标
print(performance)
# 进行预测
predictions = predictor.predict(test_data)
print(predictions)
Google AutoML
Google Cloud AutoML は、強力な自動機械学習機能を提供する Google Cloud プラットフォーム上のサービスです。Google AutoML を使用するには Google Cloud アカウントが必要であり、料金がかかる場合があることに注意してください。開発手順は次のとおりです。
- Google Cloud プロジェクトを作成する: 必ず Google Cloud 上でプロジェクトを作成し、AutoML API を有効にしてください。
- データをアップロードする: Google Cloud Console で、AutoML Vision ページに移動し、画像とラベルを含むデータセットをアップロードします。指示に従って画像をアップロードし、タグ付けします。
- モデルをトレーニングする: データをアップロードした後、モデル構成とハイパーパラメーターを選択して、モデルのトレーニングを開始します。
- モデルのトレーニングが完了するまで待ちます: データ セットのサイズによっては、モデルのトレーニングに時間がかかる場合があります。トレーニングの進行状況は Google Cloud Console で追跡できます。
- モデルを評価する: トレーニングが完了したら、AutoML Vision ページでモデルのパフォーマンスを評価し、混同行列や精度などの指標を表示できます。
- モデルを使用して予測を行う: 満足したら、トレーニングされたモデルを使用して予測を行うことができます。オンライン API は Google Cloud Console で利用できます。また、モデルをダウンロードしてローカルにデプロイすることもできます。
以下は、画像分類タスクに Google AutoML Vision を使用する方法を示す、簡略化された Python の例です。
from google.cloud import automl_v1beta1
from google.cloud.automl_v1beta1.proto import service_pb2
# 替换为你的项目ID、模型ID和文件路径
project_id = "your-project-id"
model_id = "your-model-id"
file_path = "path/to/your/image.jpg"
# 创建AutoML客户端
client = automl_v1beta1.AutoMlClient()
# 构建模型路径
model_full_id = f"projects/{
project_id}/locations/us-central1/models/{
model_id}"
# 读取图像文件
with open(file_path, "rb") as content_file:
content = content_file.read()
# 构建图像内容
image = automl_v1beta1.Image(image_bytes=content)
# 构建预测请求
payload = service_pb2.PredictRequest.Params()
payload.image.image_bytes = content
payload = {
"image": payload}
request = automl_v1beta1.PredictRequest(name=model_full_id, payload=payload)
# 发送预测请求
response = client.predict(request=request)
# 解析预测结果
for result in response.payload:
print(f"Predicted class: {
result.display_name}")
print(f"Confidence: {
result.classification.score}")
Azure の自動機械学習
Azure 自動機械学習は、Microsoft によって開発された AutoML フレームワークです。図に示すように、Azure Automated Machine Learning はトレーニング中に、さまざまなアルゴリズムとパラメーターを試す複数の並列パイプラインを作成します。このサービスは、特徴選択と組み合わせた ML アルゴリズムを反復し、反復ごとにトレーニング スコアを持つモデルを生成します。最適化されているメトリクスのスコアが高いほど、モデルはデータに「適合」していると見なされます。機械学習は、実験で定義された終了条件に達すると停止します。
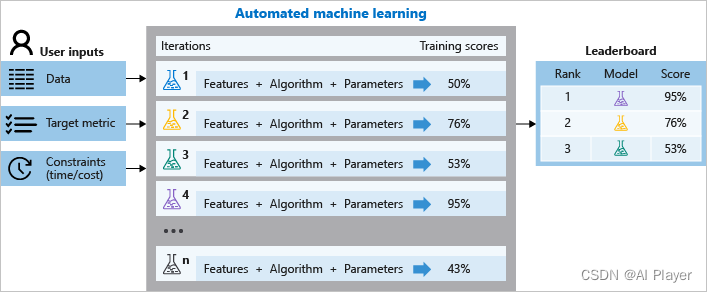
Azure の自動機械学習フレームワークは、分類、回帰、時系列予測、コンピューター ビジョン、自然言語処理に適用できます。で:
- 分類モデルの主な目的は、トレーニング データから得られた経験に基づいて、新しいデータがどのカテゴリに属するかを予測することです。一般的な分類の例には、不正検出、手書き認識、オブジェクト検出などがあります。
- 回帰モデルは、独立した予測子に基づいて出力数値を予測します。回帰の目的は、ある変数が他の変数に及ぼす影響を推定することによって、これらの独立した予測変数間の関係を確立することを支援することです。たとえば、1 マイルあたりの燃料消費量や安全性評価などの特性に基づいて車の価格を予測します。
- 時系列予測は重回帰問題として考慮されます。過去の時系列値は、回帰変数やその他の予測変数の追加ディメンションに「ピボット」されます。従来の逐次的手法とは異なり、この手法の利点は、複数のコンテキスト変数とその相互関係がトレーニング プロセスに自然に含まれることです。自動 ML は、データセットと予測期間内のすべてのプロジェクトについて、多くの場合内部ブランチを含む単一のモデルを学習します。これにより、より多くのデータをモデル パラメーターの推定に使用できるようになり、未知の系列への一般化が可能になります。高度な予測構成には以下が含まれます:
(1) 休日の検出と特性評価
(2) タイミングおよび DNN トレーナー (Auto-ARIMA、Prophet、ForecastTCN)
(3) グループ化によるマルチモデルのサポート
(4) ローリング原点相互検証
(5) 構成可能なヒステリシス
(6) ローリングウィンドウ集計機能 - コンピュータ ビジョンは、マルチクラス画像分類、マルチラベル画像分類、オブジェクト検出、およびインスタンス セグメンテーション タスクをサポートできます。また、Azure Machine Learning MLOps と ML パイプライン機能を活用して大規模に動作します。
- 自然言語処理のための自動 MLを使用すると、テキスト分類および固有表現認識シナリオ用にテキスト データでトレーニングされたモデルを簡単に生成できます。104 言語の多言語サポートを提供し、分散トレーニング用の Horovod をサポートします。
自動機械学習はアンサンブル モデルをサポートしており、デフォルトで有効になっています。アンサンブル学習では、単一のモデルを使用するのではなく、複数のモデルを組み合わせることで、機械学習の結果と予測パフォーマンスが向上します。アンサンブルの反復は、 の最後の反復として表示されます。自動機械学習では、投票法とスタックドアンサンブル法を使用してモデルを結合します。
- 投票: 予測クラス確率 (分類タスクの場合) または予測回帰ターゲット (回帰タスクの場合) の加重平均に基づいて予測を行います。
- スタッキング: スタッキング方法では、異種モデルを結合し、各モデルの出力に基づいてメタモデルをトレーニングします。現在のデフォルトのメタモデルは、LogisticRegression (分類タスク用) と ElasticNet (回帰/予測タスク用) です。
さらに、Azure Automated Machine Learning では、スケーリングと正規化の手法を適用して、特徴エンジニアリングを簡素化します (特徴エンジニアリングとは、データ ドメインの知識を使用して、機械学習アルゴリズムの学習効果の最適化に役立つ特徴を作成するプロセスです)。
Azure 自動機械学習に関する上記の内容は、公式 Web サイトを参照しています。ここでは、関連する原理と機能のみを紹介します。Azure のインストール方法、データの前処理、モデルのトレーニングとテストなどの詳細については、公式 Web サイトにアクセスしてください。モデルのデプロイメント、視覚化および監視モデルなど、詳細なコード例が提供されます。