この記事では、データ視覚化手法を使用して、4 つのサポート ベクター マシン カーネル関数とパラメーターの違いを説明します。
簡単に言えば、サポート ベクター マシン (SVM) は、分類に使用される教師あり機械学習手法です。これは、最大のマージンでクラスを最適に分離する超平面を計算することによって機能します。

サポート ベクター マシンは、単純な線形分離を提供するだけでなく、さまざまなカーネル メソッドを適用することで非線形分類を実行することもできます。パラメータ設定も、SVM がより適切に動作するためのもう 1 つの重要な要素です。適切な選択を行うことで、サポート ベクター マシンを使用して高次元データを処理できます。

この記事の目的は、Scikit-learn ライブラリを使用して、各カーネル関数とさまざまなパラメーター設定の使用方法を示すことです。データの視覚化を通じて解釈および比較します。
アイリスの花やタイタニックなどの一般的なデータセット以外の別のデータセットを探している場合は、poksammon データセットが別のオプションになります。これらのポケットモンスターのファンではないかもしれませんが、その特性は理解しやすく、さまざまな特性が用意されています。

HP、攻撃、素早さなどのポケモンの属性を連続変数として使用できます。カテゴリ変数には、タイプ (草、火、水など)、レベル (通常、伝説) などがあります。さらに、将来的に新しい世代やポケモンが登場した場合、データセットは更新されます。
免責事項:ポケモンおよびすべての関連名称は、任天堂株式会社の著作権および商標です。
データとライブラリをインポートする
各 SVM カーネルがカテゴリをどのように区別するかを視覚的に示すために、赤ちゃん、伝説的、神話的なもののみを選択します。データとライブラリをインポートすることから始めましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('pokemons.csv', index_col=0)
df.reset_index(drop=True, inplace=True)
df = df[df['rank'].isin(['baby', 'legendary'])]
df.reset_index(drop=True, inplace=True)
df.head()

エダ
ポケモンにはHP、攻撃、防御、特攻、特防、素早さ、高さの7つの基本属性があります。次の手順では、選択した統計を使用して簡単な EDA を実行します。
select_col = ['hp','atk', 'def', 'spatk', 'spdef', 'speed', 'height']
df_s = df[select_col]
df_s.info()

幸いなことに、NULL 値はありません。次に、箱ひげ図を描いてこれらの変数の分布を見てみましょう。
sns.set_style('darkgrid')
df_s.iloc[:,].boxplot(figsize=(11,5))
plt.show()
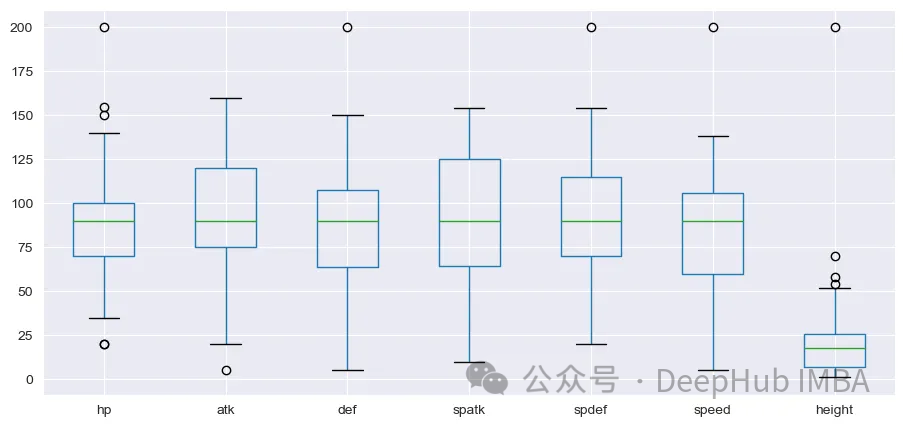
高さ変数の分布は他の変数とは大きく異なります。続行する前に標準化を実行する必要があります。sklearnから処理までStandardScalerを使用します
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
array_s = scaler.fit_transform(df_s)
df_scal = pd.DataFrame(array_s, columns=[i+'_std' for i in select_col])
df_scal.boxplot(figsize=(11,5))
plt.show()
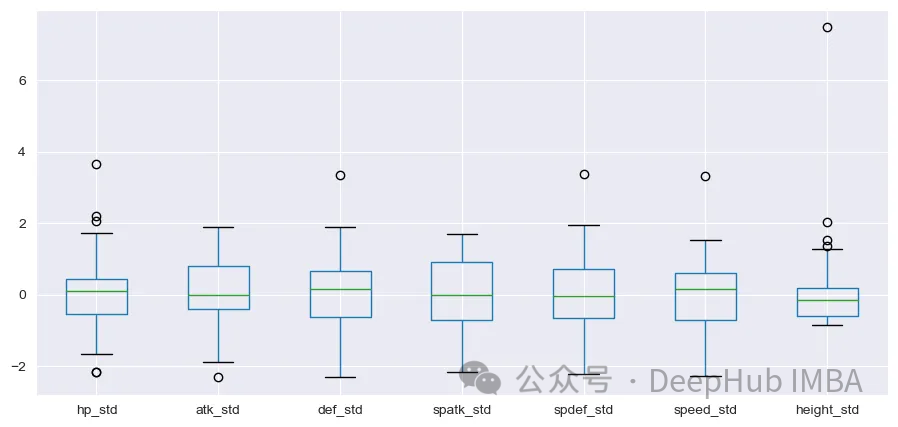
正規化後、分布はより良く見えます。
データセットには複数の特徴があるため、次元削減プロットを実行する必要があります。sklearn.decomposition のクラス PCA を使用して次元を 2 に削減します。結果は、Plotly の散布図を使用して表示されます。
from sklearn.decomposition import PCA
import plotly.express as px
#encoding
dict_y = {'baby':1, 'legendary':2}
df['s_code'] = [dict_y.get(i) for i in df['rank']]
df.head()
pca = PCA(n_components=2)
pca_result = pca.fit_transform(array_s)
df_pca = pd.DataFrame(pca_result, columns=['PCA_1','PCA_2'])
df = pd.concat([df, df_pca], axis=1)
fig = px.scatter(df, x='PCA_1', y='PCA_2', hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False)
fig.show()
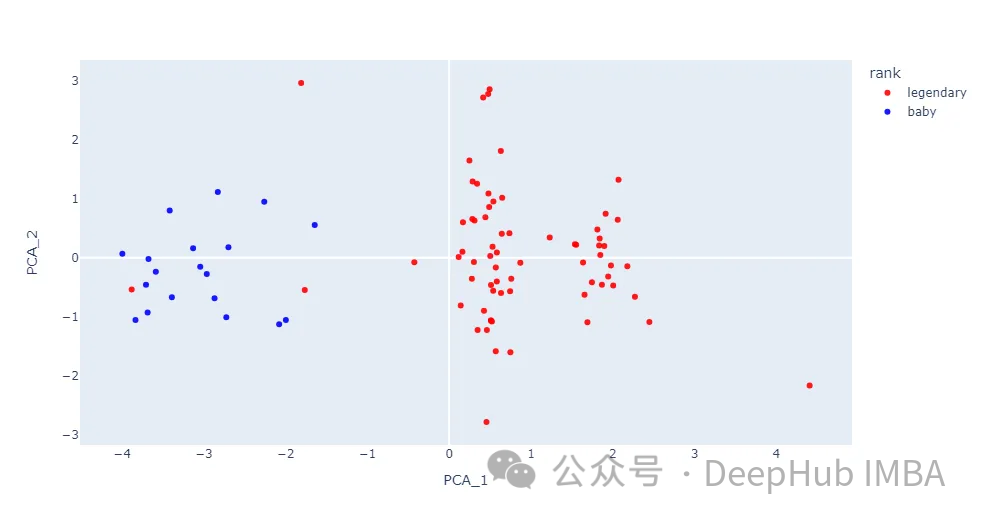
ポケモンの画像を散布図に取り込みます。

再度免責事項: ポケモンおよび関連するすべての名前は、任天堂株式会社の著作権および商標です。
ほとんどのデータ ポイントは、ベイビーと凡例の 2 つのカテゴリに分かれています。2 つのクラスは完全に分離されているわけではありませんが、この記事で各カーネル関数を試してみると役に立ちます。
次のステップは、3 次元で詳細を取得することです。PCA コンポーネントの数を 3 に変更してみましょう。これは、3D 散布図で表示できる最大数です。
pcaz = PCA(n_components=3)
pcaz_result = pcaz.fit_transform(array_s)
df_pcaz = pd.DataFrame(pcaz_result, columns=['PCAz_1', 'PCAz_2', 'PCAz_3'])
df = pd.concat([df, df_pcaz], axis=1)
fig = px.scatter_3d(df, x='PCAz_1', y='PCAz_2', z='PCAz_3', hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_traces(marker=dict(size=4))
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0))
fig.show()
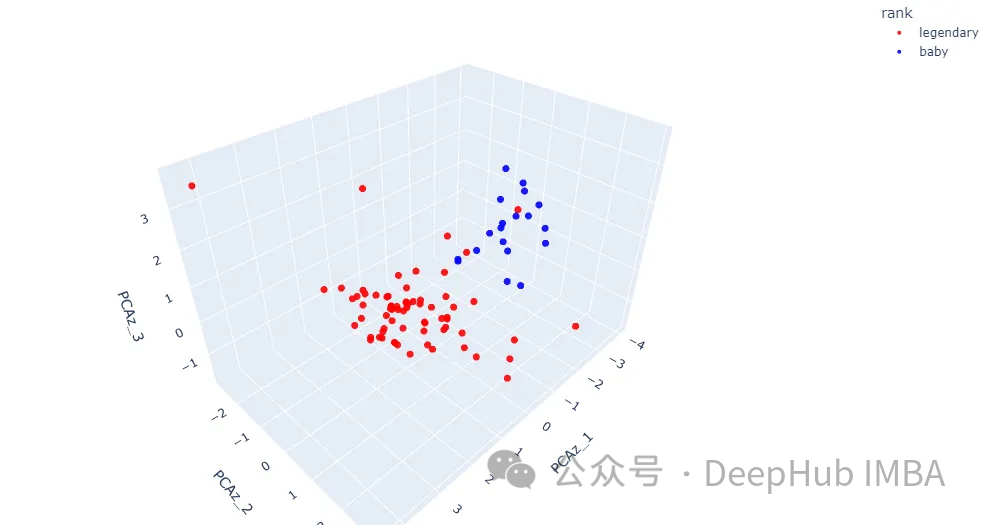
結果には、データ ポイントが 3 次元空間にどのように配置されているかがさらに詳細に示されます。一部の地域では、2 つのクラスがまだ混在しています。次にカーネルメソッドについて説明します。
カーネルメソッド
サポート ベクター マシンは、Scikit-learn ライブラリの sklearn.svm.SVC クラスを使用するだけで実装できます。カーネル関数は、カーネルパラメータを変更することで選択できます。合計 5 つの方法が利用可能です。
Linear
Poly
RBF (Radial Basis Function)
Sigmoid
Precomputed
この記事では主に最初の 4 つのカーネル メソッドに焦点を当てます。最後のメソッドは事前計算されており、入力行列が正方行列である必要があり、データセットには適していません。
カーネル関数に加えて、後で結果を比較するために 3 つの主要なパラメーターも調整します。
C: 正則化パラメータ
ガンマ(γ): rbf、ポリ、シグモイド関数のカーネル係数
Coef0: カーネル関数内の独立した項。ポリ関数およびシグモイド関数でのみ意味を持ちます。
以下のコードでは、predict_proba() がグリッド上で起こり得る結果の確率を計算します。最終結果は等高線図として表示されます。
from sklearn import svm
import plotly.graph_objects as go
y = df['s_code'] # y values
h = 0.2 # step in meshgrid
x_min, x_max = df_pca.iloc[:, 0].min(), df_pca.iloc[:, 0].max()
y_min, y_max = df_pca.iloc[:, 1].min(), df_pca.iloc[:, 1].max()
xx, yy = np.meshgrid(np.arange(x_min-0.5, x_max+0.5, h), #create meshgrid
np.arange(y_min-0.5, y_max+0.5, h))
def plot_svm(kernel, df_input, y, C, gamma, coef):
svc_model = svm.SVC(kernel=kernel, C=C, gamma=gamma, coef0=coef,
random_state=11, probability=True).fit(df_input, y)
Z = svc_model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 0]
Z = Z.reshape(xx.shape)
fig = px.scatter_3d(df, x='PCAz_1', y='PCAz_2', z='PCAz_3', #3D Scatter plot
hover_name='name',
color='rank', opacity=0.9,
color_discrete_sequence=['red', 'blue'])
fig.update_traces(marker=dict(size=4))
fig.add_traces(go.Surface(x=xx, y=yy, # prediction probability contour plot
z=Z+round(df.PCAz_3.min(),3), # adjust the contour plot position
name='SVM Prediction',
colorscale='viridis', showscale=False,
contours = {"z": {"show": True, "start": x_min, "end": x_max,
"size": 0.1}}))
title = kernel.capitalize() + ' C=' + str(i) + ', γ=' + str(j) + ', coef0=' + str(coef)
fig.update_layout(margin=dict(l=0, r=0, t=0, b=0), showlegend=False,
title={'text': title,
'font':dict(size=39),
'y':0.95,'x':0.5,'xanchor': 'center','yanchor': 'top'})
return fig.show()
最後に、比較する 3 つのパラメーターのリストを作成します。ここでは、0.01 から 100 までの値を比較します。別の値を試したい場合は、この数値を調整できます。
from itertools import product
C_list = [0.01, 100]
gamma_list = [0.01, 100]
coef_list = [0.01, 100]
param = [(r) for r in product(C_list, gamma_list, coef_list)]
print(param)

すべての準備が整ったので、さまざまな種類のカーネル関数を使用して結果をプロットしてみましょう。
1. 線形カーネル
これは、最も一般的で単純な SVM カーネル関数です。このカーネル関数は、クラスを分離するための決定境界として使用される線形超平面を返します。超平面は、特徴空間内の 2 つの入力ベクトルの内積を計算することによって取得されます。
for i,j,k in param:
plot_svm('linear', df_pca, y, i, j, k)

結果の平面 (等高線図) は超平面ではありません。これらは、predict_proba() の予測確率の結果であり、0 から 1 までの値を持ちます。
確率平面は、データ ポイントが分類される確率を表します。黄色の部分はベビーになる可能性が高いことを、青色の部分はレジェンドになる可能性が高いことを意味します。
SVM の結果を変更する唯一のパラメータは、正則化パラメータ © です。理論的には、C の数が増加すると、超平面のマージンは小さくなります。異なるカテゴリのデータ ポイントが混在する場合は、高い C を使用するとよいでしょう。正則化が高すぎると、過剰適合が発生する可能性があります。
2. 放射基底関数 (RBF) カーネル
RBF (放射基底関数)。このカーネル関数は、ユークリッド距離の二乗を計算して、2 つの特徴ベクトル間の類似性を測定します。
カーネル名を変更するだけで、同じ for ループ処理を使用できます。
for i,j,k in param:
plot_svm('rbf', df_pca, y, i, j, k)

結果は、正則化パラメータ © に加えて、γ (γ) も RBF カーネルの結果に影響を及ぼし、coef0 は RBF カーネル関数に影響を及ぼさないことを示しています。
ガンマ パラメーターは、超平面上のデータ ポイントの影響を決定します。ガンマ値が高い場合、超平面に近いデータ ポイントの方が、遠いデータ ポイントよりも大きな影響を及ぼします。
低いガンマ値の確率プレーンは、高いガンマ値の確率プレーンよりも滑らかです。結果は、高いガンマ値での最後の 4 つの散布図でより明らかであり、各データ ポイントは予測確率に大きな影響を与えます。
3. 多項式カーネル
多項式カーネルは、データを高次元空間にマッピングすることによって機能します。変換された高次元空間と元の空間のデータ点の内積を計算します。このカーネルは高次元データを処理できるため、非線形分離の実行に推奨されます。
多項式カーネルは、他のカーネルと比較して最も長い処理時間を要します。これは、データを高次元空間にマッピングした結果である可能性があります。
for i,j,k in param:
plot_svm('poly', df_pca, y, i, j, k)

これら 3 つのパラメータが SVM の分類効果に影響を与えることがわかります。正則化パラメータ © および γ (γ) に加えて、coef0 パラメータはモデルに対する高次多項式の影響の度合いを制御します。coef0 値が高くなるほど、予測確率の等高線はより湾曲する傾向があります。
4、Sigmoid核
理論的には、シグモイド関数は入力値をマッピングして 0 から 1 までの値を返すのが得意です。この関数はニューラル ネットワークで一般的に使用され、シグモイド関数は分類の活性化関数として機能します。
SVM タスクに適用できて便利そうですが、結果が複雑すぎて解釈できない可能性があるとの記事もあります。ここではデータ視覚化を使用してこの問題を検討します。
for i,j,k in param:
plot_svm('sigmoid', df_pca, y, i, j, k)
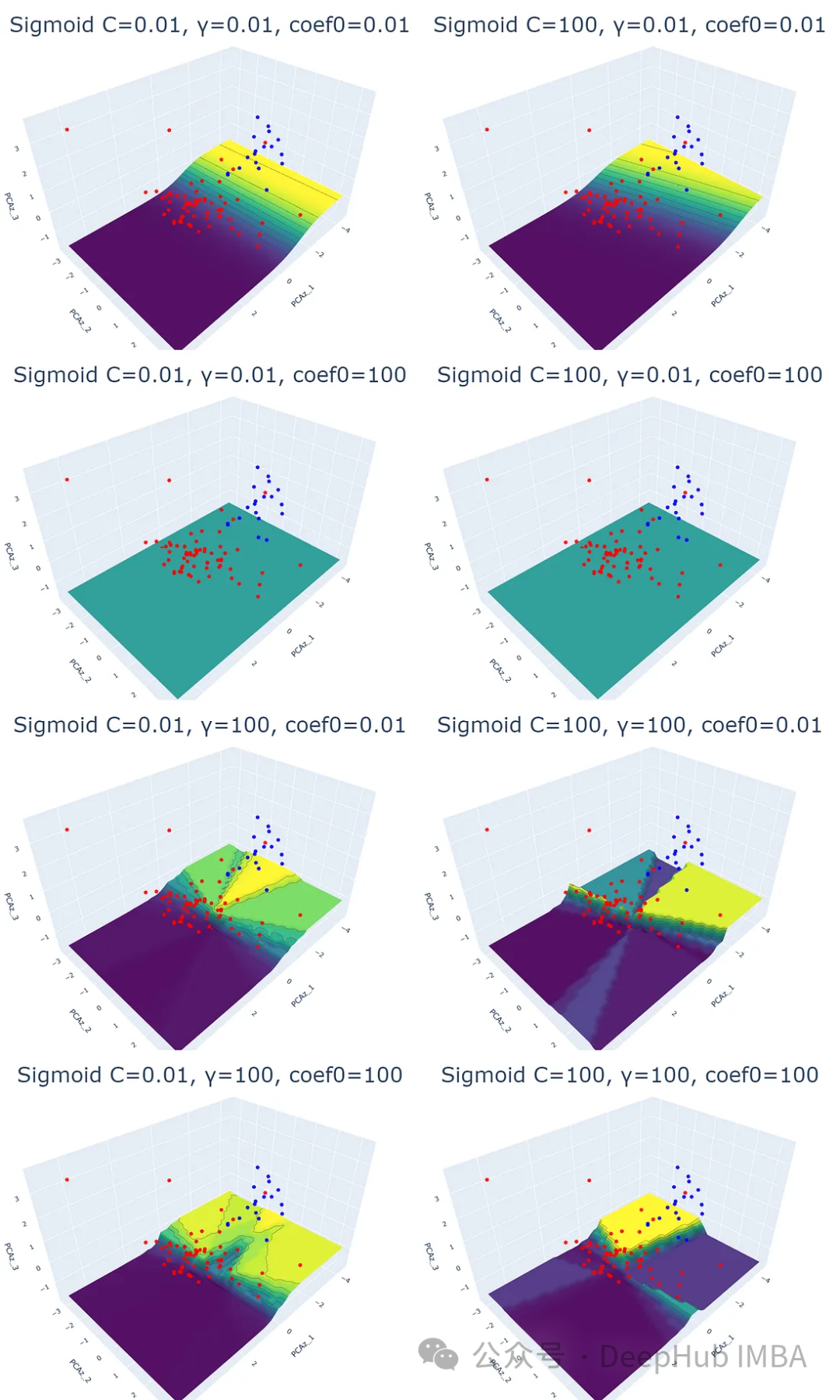
シグモイドカーネルから得られるグラフは非常に複雑で説明できないことがわかります。予測確率等高線プロットは、他のカーネルのものとは完全に異なります。また、等高線プロットの色は、対応するデータ ポイントを下回っていません。重要なことは、パラメーター値を変更しても、結果にパターンが存在しないことです。
しかし、私の個人的な意見では、これはこのカーネルが悪いとか、避けるべきだという意味ではありません。おそらく彼は、私たちが気づいていなかったデータの特徴を発見したので、シグモイドが適した分類タスクがいくつかあるかもしれません。
要約する
サポート ベクター マシンは、単純な線形および非線形分類を提供できるため、効果的な機械学習分類手法です。
データセットごとに異なる特性があるため、特効薬はありません。サポートベクターマシンを有効に機能させるためには、カーネルとパラメータを適切に選択し、オーバーフィッティングを避ける必要があります。
https://avoid.overfit.cn/post/96c405b7aecf40c5a324ac8a2718f019
著者: ボリハーン K