自己教師あり表現学習法—DINO法
参考文献:《自己監視型ビジョントランスフォーマーにおける新たな特性》
DINO全称——a form of knowledge distillation with no labels.(一种没有标签的知识蒸馏的形式)

上に示す: 教師ありトレーニングなしの 8×8 パッチ上のビジュアル トランスフォーマーからのセルフ アテンション。最後の層ヘッダーの [CLS] トークンのセルフアテンションが観察されます。このトークンはいかなるレーベルや規制当局とも提携していません。これらのマップは、モデルがクラス固有の機能を自動的に学習し、教師なしオブジェクトのセグメンテーションを可能にすることを示しています。
1.概要
この記事では、自己教師学習が Vision Transformer (VIT) が畳み込みに関連する新しい機能を提供するかどうかについて疑問を呈します。ネットワークよりも目立ちます。特に効果的になるように自己教師あり手法をこのアーキテクチャに適応させることに加えて、次の観察を行います。 まず、自己教師あり ViT の特徴には、画像のセマンティック セグメンテーションに関する明示的な情報が含まれていますが、これは教師あり ViT ネットワークと畳み込みネットワークの両方では明らかではありません。 。第 2 に、これらの特徴は優れた k-NN 分類器でもあり、ImageNet では 78.3% のトップ 1 に達しています。私たちの研究では、運動量エンコーダー、複数作物トレーニング、vit を使用した小さなパッチの使用の重要性も強調しています。私たちは調査結果を DINO と呼ばれる単純な自己教師ありメソッドに実装します。これは、ラベルのない自己蒸留の形式として解釈されます。
個人的な要約:
①新しい自己教師あり学習法DINOを提案。
②自己教師あり学習は教師あり学習よりも有益な情報を得ることができます。ここでは主に画像のセグメンテーションに焦点を当てます。
③Vision Transformer は、畳み込みネットワークよりも有用な意味情報を取得します。
2.DINOメソッドの紹介
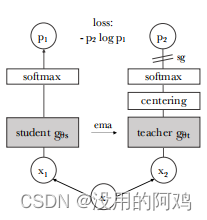
上に示すように、ラベルフリーの自己蒸留。
わかりやすくするために、DINO を 1 組のビュー (、
) のコンテキストで説明します。
①モデルは、入力画像の 2 つの異なるランダム変換を生徒と教師のネットワークに渡します。どちらのネットワークもアーキテクチャは同じですが、パラメータが異なります。教師ネットワークの出力は、バッチ全体で計算された平均を中心にしています。
②各ネットワークは、特徴次元の温度ソフトマックスで正規化された K 次元特徴を出力します。
③次に、クロスエントロピー損失を使用してそれらの類似性を測定します。
④ 教師に停止勾配 (sg) 演算子を適用して、生徒を介してのみ勾配を伝播します。教師パラメータは、生徒パラメータの指数移動平均 (EMA) で更新されます。
DINOアルゴリズムの擬似コード

ディノの詳細:
知識の蒸留は、特定の教師ネットワーク の出力にそれぞれ一致するように生徒ネットワーク をトレーニングする学習パラダイムです。 < a i=3> および パラメータ化されています。入力画像 が与えられると、 次元の 2 つのネットワークの確率分布は と で表されます。 < a i=8> を表します。確率 P は、 ネットワークの出力をソフトマックス関数で正規化することで取得されます。より正確には、
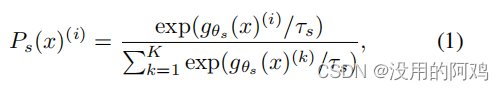
ここで、 は温度パラメータです。
固定の教師ネットワークを考慮すると、クロスエントロピー損失を最小限に抑えることで、分散した生徒ネットワークのパラメータに一致させる
ことを学習します。 /あ>
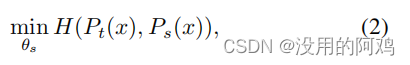
其中。
以下では、方程式 (2) のこの問題 (2) を自己教師あり学習に適応させる方法を詳しく説明します。まず、マルチスティック戦略を使用して、画像のさまざまな歪んだビューまたはトリミングを構築します。より正確には、指定された画像から、 2 つのグローバル ビュー ( と
) といくつかの解像度の詳細ビューを含むセット V を生成します。すべての作物は生徒を通じて伝えられますが、グローバルな視点のみが教師を通じて伝えられるため、「ローカルからグローバルへ」のコミュニケーションが促進されます。損失を最小限に抑えます:
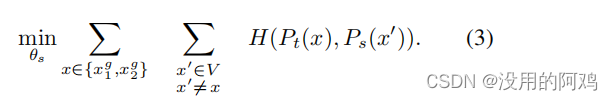
これら 2 つのネットワークは同じアーキテクチャを共有しており、異なるパラメータ セット
と
を備えています。確率的勾配降下法を使用して式 (3) を最小化することで、 パラメータ
を学習します。
特に興味深いのは、スチューデントの重みに対する指数移動平均 (EMA)、つまり運動量エンコーダの使用が、私たちのフレームワークに特に適していることです。更新ルールは で、トレーニング中、λ は 0.996 から 1 までのコサイン スケジュールに従います。
クラッシュを防ぎます。センタリングは 1 つの次元が支配するのを防ぎますが、均一な分布への崩壊を促進しますが、シャープ化は逆の効果をもたらします。両方の操作を適用すると効果のバランスが取れ、Momentum 教師の前でのメルトダウンを避けるのに十分です。クラッシュを回避するためにこのアプローチを選択すると、安定性と引き換えにバッチ依存性が低くなります。センタリング操作は 1 次バッチ統計にのみ依存します。これは、教師にバイアス項を追加すると解釈できます。: は指数移動平均で更新されるため、以下に示すように、このメソッドはさまざまなバッチ サイズでも適切に機能できます。
。中心

ここで、m > 0 はレート パラメータ、B はバッチ サイズです。出力の鮮明化は、教師ソフトマックス正規化で低い温度値を使用することで得られます。
3.実験結果
表 1: ImageNet での線形および k-NN 分類。さまざまな自己教師あり手法の ImageNet 検証セットにおける線形および k-NN 評価のトップ 1 の精度を報告します。私たちは ResNet-50 および vit-small アーキテクチャに焦点を当てていますが、アーキテクチャ全体で得られた最良の結果も報告します。 ※は当社が運営しております。公式に公開されている重みを使用してモデルに対して k-NN 評価を実行しました。スループット (im/s) は、NVIDIA V100 GPU で 1 アドバンスあたり 128 サンプルを使用して計算されます。パラメータ (M) は特徴抽出器です。
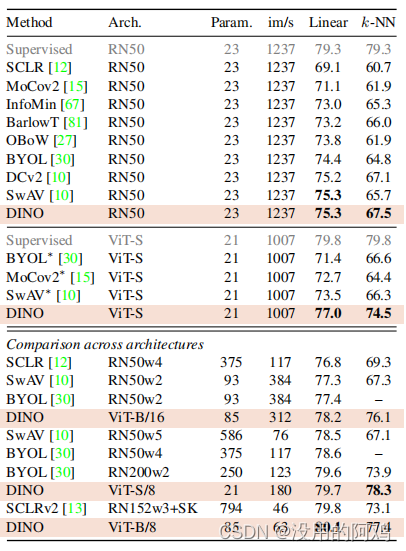
表 2: 画像の検索。教師付き機能または DINO で事前トレーニングされた既製の機能を使用して、ImageNet と Google Landmark v2 (GLDv2) データセットの検索パフォーマンスを比較します。オックスフォードとパリの地図について報告しました。ランドマーク データセットに対する DINO による事前トレーニングは特に良好なパフォーマンスを示しました。参考として、既製の機能を使用した最良の検索方法も報告します [57]。
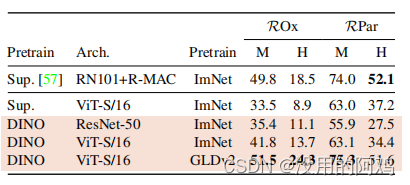
表 3: コピーの検出。我々は、複製日の「強力な」サブセットにおける複製検出における mAP のパフォーマンスを報告します [21]。参考として、特定のオブジェクトの取得用に特別にトレーニングされた多層モデル [5] のパフォーマンスも報告します。
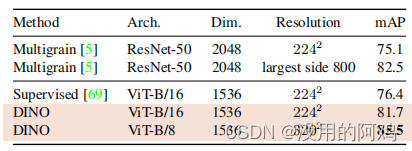
表 4: DAVIS 2017 ビデオ オブジェクトのセグメンテーション。ビデオ インスタンスの追跡で凍結された特徴の品質を評価します。平均領域類似度 Jm と輪郭ベースの精度 Fm を報告します。既存の自己教師あり手法と ImageNet でトレーニングされた教師あり ViT-S/8 を比較します。画像解像度は480pです。
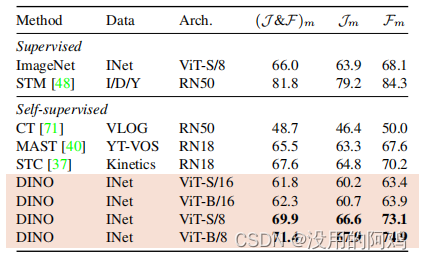
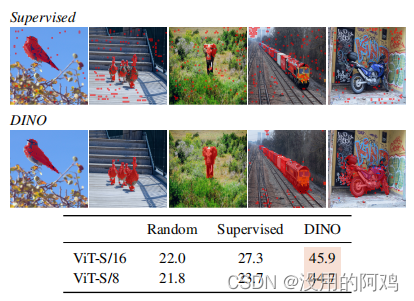
上:監修とDINOからのセグメンテーション。 60% の品質を維持するためにセルフ アテンション マップを閾値処理することで得られたマスクを視覚化します。上では、教師付きおよび DINO によってトレーニングされた ViT-S/8 マスクの結果を示しています。両モデルのベストヘッドをご紹介します。下の表は、グラウンド トゥルースと PASCAL VOC12 データセットの検証画像上のこれらのマスクの間の Jaccard 類似性を比較しています。
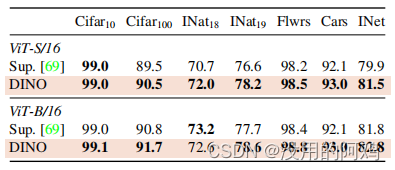
表 5: さまざまなデータセットで事前トレーニングされたモデルを微調整することによる転移学習。トップ 1 の精度をレポートします。 DINO の自己教師付き事前トレーニングは、教師付き事前トレーニングよりも優れています。
4 結論
この研究では、標準 ViT モデルの自己教師あり事前トレーニングの可能性を実証し、この設定用に設計された最良の凸ネットに匹敵するパフォーマンスを達成します。また、将来のアプリケーションで活用できる 2 つの特性も確認できます。k-NN 分類の特徴の品質には、画像検索の可能性があり、ViT は有望な結果を示しています。フィーチャ内にシーン レイアウト情報が存在すると、弱く教師された画像のセグメンテーションも容易になります。ただし、この論文の主な結果は、自己教師あり学習が ViT に基づいた BERT のようなモデルを開発する鍵となる可能性があるという証拠を得たことです。将来的には、キュレーションされていないランダムな画像に対して DINO を使用して大規模な ViT モデルを事前トレーニングすることで、視覚的特徴の限界を押し上げることができるかどうかを調査する予定です。
個人的な質問:
①トレーニングを長時間しすぎていませんか?
②構成が高すぎるようです、8GPUコンピュータ2台
表 8: 時間とメモリの要件。各 GPU の合計実行時間とピーク メモリ (「mem.」) を示します。 2 台の 8 GPU マシンで ViT-S/16 DINO モデルを実行する場合。それぞれ異なる計算要件を持つ複数の作物に対する ImageNetvalacc の上位 1 つの線形評価について報告します。
