大規模な言語モデルのサイズについて話すとき、パラメーターからはニューラル ネットワークの構造がどれほど複雑であるかがわかり、トークン サイズからはパラメーターのトレーニングにどれだけのデータが使用されたかがわかります。
Lu Qi 博士が述べたように、大規模言語モデルは、テキスト生成から質問応答まで、さまざまなタスクに優れた機能を提供し、自然言語処理 (NLP) の分野に革命をもたらすだけでなく、基本モデルとしても機能し、ソフトウェア エコシステム全体を変えます。
これらのモデルで見落とされがちな重要な点は、モデルによって処理される情報の個々の単位である「トークン」の役割です。大規模言語モデル (LLM) は生のテキストを真に理解することはできず、テキストはトークンと呼ばれる数値表現に変換され、これらのトークンが処理のためにモデルに供給されます。

トークンはブロックチェーン内のパスまたはトークンを表します。では、LLM ではトークンは何を表すのでしょうか?
1. トークンとは何ですか?
LLM では、トークンはモデルが理解および生成できる意味の最小単位を表し、モデルの基本単位となります。使用される特定のトークン化スキームに応じて、トークンは単語、単語の一部、または文字だけを表すことができます。トークンには数値または識別子が割り当てられ、シーケンスまたはベクトルに配置され、モデルの入力または出力として使用されます。これはモデルの言語コンポーネントです。
一般に、トークンは、単語の先頭または末尾から正確に分割されていない単語の断片として見なすことができ、末尾のスペースやサブワード、さらにはより大きな言語単位を含むことができます。トークンは、生のテキスト データと LLM が使用できる数値表現の間のブリッジとして機能します。 LLM はトークンを使用してテキストの一貫性と一貫性を確保し、書き込み、翻訳、クエリへの回答などのさまざまなタスクを効果的に処理します。
トークンの長さを理解するのに役立つ経験則をいくつか示します。
1 token ~= 4 chars in English
1 token ~= ¾ words
100 tokens ~= 75 words
或者
1-2 句子 ~= 30 tokens
1 段落 ~= 100 tokens
1,500 单词 ~= 2048 tokens
OpenAI の API パラメーターの max_tokens パラメーターは、モデルが最大長 60 トークンの応答を生成することを指定します。 https://platform.openai.com/tokenizer を通じてトークン関連の情報を確認できます。
2. トークンの特徴
まず、OpenAI プレイグラウンドを使用して、「1993 年 12 月 31 日。事態はおかしくなっている」という例を見てみましょう。

GPT-3 トークナイザーを使用して、同じ単語をトークンに変換します。

2.1 トークンから数値表現へのマッピング
語彙はトークンを一意の数値表現にマップします。 LLM は数値入力を使用するため、語彙内の各トークンには一意の識別子またはインデックスが与えられます。このマッピングにより、LLM はテキスト データを一連の数値として処理および操作できるようになり、効率的な計算とモデリングが可能になります。
トークン間の意味とセマンティックな関係を把握するために、LLM はトークン エンコーディング テクノロジを採用しています。これらの技術は、トークンをエンベディングと呼ばれる高密度のデジタル表現に変換します。セマンティック情報とコンテキスト情報のエンコーディングが埋め込まれているため、LLM は一貫したコンテキスト テキストを理解して生成できます。トランスフォーマーのようなアーキテクチャは、セルフアテンション メカニズムを使用してトークン間の依存関係を学習し、高品質の埋め込みを生成します。
2.2 トークンレベルの操作: テキストを正確に操作する
トークンレベルの操作により、テキスト データに対するきめ細かい操作が可能になります。 LLM は、トークン、置換トークン、またはマスク トークンを生成して、意味のある方法でテキストを変更できます。これらのトークンレベルの操作は、機械翻訳、感情分析、テキスト要約などのさまざまな自然言語処理タスクに応用できます。
2.3 トークン設計の制限
テキストは生成のために LLM に送信される前にトークン化されます。トークンは、モデルが入力 (単一の文字、単語、単語の一部、またはテキストやコードの他の部分) を表示する方法です。各モデルはこのステップを異なる方法で実行します。たとえば、GPT モデルはバイト ペア エンコーディング (BPE) を使用します。
トークンには、トークナイザー ジェネレーターの語彙内の ID が割り当てられます。ID は、数値を対応する文字列にバインドする数値識別子です。たとえば、「Matt」は GPT ではトークン番号 [13448] としてエンコードされますが、「Rickard」は ID [8759,446] の 2 つのトークン「Rick」、「ard」としてエンコードされます。GPT-3 には 1,400 万の語彙があります。文字列の。
トークンの設計には、おそらく次の制限があります。
大文字と小文字の区別: 大文字と小文字が異なる単語は、異なるトークンとして扱われます。 「hello」はトークン[31373]、「Hello」は[15496]、「HELLO」には 3 つのトークン[13909,3069,46]があります。
数値のチャンク化に一貫性がありません。値「380」は、GPT で単一の「380」トークンでタグ付けされます。ただし、「381」は 2 つのトークン ["38", "1"] で表されます。 「382」も 2 つのトークンですが、「383」は 1 つのトークン [「383」] です。 4 桁のトークンには、["3000"]、["3"、"100"]、["35"、"00"]、["4"、"500"] があります。これが、GPT ベースのモデルが必ずしも数学に優れているわけではない理由である可能性があります。
末尾のスペース。一部のトークンにはスペースが含まれており、単語プロンプトや単語補完で興味深い動作を引き起こす可能性があります。たとえば、末尾にスペースがある「once Upon a」は、["once", "Upon", "a", " "] としてエンコードされます。ただし、「once on a time」は ["once", "Upon", "a", "time"] としてエンコードされます。 「time」はスペースを含む単一のトークンであるため、プロンプト単語にスペースを追加すると、「time」が次のトークンになる確率に影響します。
3. LLM に対するトークンの影響
トークンの数がモデルの応答にどのように影響するかについては、多くの場合、トークンの数がモデルをより詳細かつ具体的にするかどうかが混乱されます。個人的には、大規模モデルに対するトークンの影響は次の 2 つの側面に焦点を当てていると思います。
コンテキスト ウィンドウ: これは、モデルが一度に処理できるトークンの最大数です。モデルがコンテキスト ウィンドウよりも多くのトークンを生成するように要求された場合、モデルはブロック内で生成するため、ブロック間の一貫性が失われる可能性があります。
トレーニング データ トークン: モデルのトレーニング データ内のトークンの数は、モデルが学習した情報量の尺度です。ただし、モデルがより「一般的」であるか「詳細」であるかは、これらの象徴的な尺度に直接関係しません。
モデルの応答の一般性または特異性は、応答の生成に使用されるトレーニング データ、微調整、およびデコード戦略に大きく依存します。大規模な言語モデルにおけるトークンの概念は、これらのモデルがどのように機能し、それらを効果的に使用する方法を理解するための基礎となります。モデルが処理できるトークンの数、またはモデルがトレーニングされたトークンの数はパフォーマンスに影響しますが、その応答の一般性または詳細は、使用されるトレーニング データ、微調整、およびデコード戦略の成果です。
さまざまなデータでトレーニングされたモデルは一般的な応答を生成する傾向がありますが、特定のデータでトレーニングされたモデルはより詳細な状況固有の応答を生成する傾向があります。たとえば、医療テキストに基づいてモデルを微調整すると、医療上の合図に対してより詳細な応答が生成される可能性があります。
デコード戦略も重要な役割を果たします。モデルの出力層で使用される SoftMax 関数の「温度」を変更すると、モデルの出力をより多様にしたり (温度を高く)、より決定的にしたり (温度を低く) したりできます。 OpenAI API で温度値を設定すると、決定性とさまざまな出力の間のバランスを調整できます。
すべての言語モデルは、そのサイズやトレーニング対象のデータ量に関係なく、トレーニング対象のデータ、微調整、およびデコード戦略に対してのみ最も効果的である可能性が高いことを覚えておくことが重要です。使用中に使用します。
LLM の限界を押し上げるには、さまざまなトレーニングおよび微調整方法を試し、さまざまなデコード戦略を使用できます。これらのモデルの長所と短所を認識し、ユースケースが使用しているモデルの機能と一貫していることを常に確認してください。
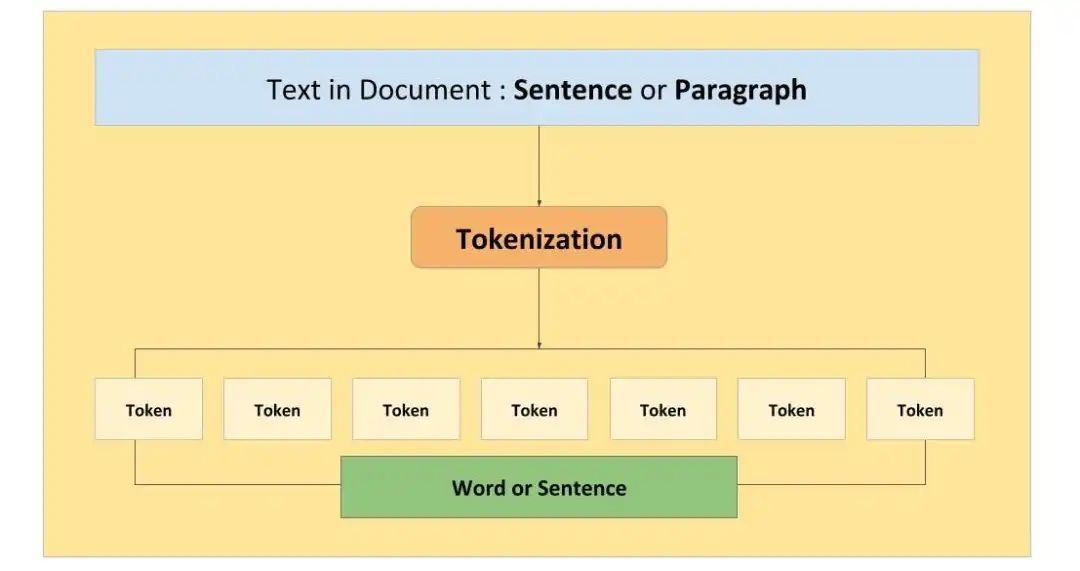
4. トークン適用メカニズム - トークン化
テキストをさまざまなトークンに分割する正式なプロセスは、トークン化と呼ばれます。トークン化はテキストの意味と文法構造を捕捉するため、テキストを重要なコンポーネントに分割する必要があります。
トークン化は、入力テキストと出力テキストをより小さな単位に分割するプロセスであり、LLM AI モデルによって処理されます。トークン化は、モデルがさまざまな言語、語彙、形式を処理し、計算コストとメモリ コストを削減するのに役立ちます。また、トークンの意味とコンテキストに影響を与えることで、生成されるテキストの品質と多様性にも影響を与える可能性があります。テキストの複雑さと変動性に応じて、ルールベースの方法、統計的方法、ニューラルな方法など、さまざまな方法をトークン化に使用できます。
OpenAI と Azure OpenAI は、GPT ベースのモデルに「バイト ペア エンコーディング (BPE)」と呼ばれるサブワード トークン化方法を使用します。 BPE は、特定のトークン数または語彙サイズに達するまで、最も頻繁に発生する文字またはバイトのペアを 1 つのトークンに結合する方法です。 BPE は、モデルがまれな単語や目に見えない単語を処理し、よりコンパクトで一貫性のあるテキスト表現を作成するのに役立ちます。 BPE を使用すると、モデルは既存の単語またはトークンを組み合わせて新しい単語またはトークンを生成することもできます。語彙が多いほど、モデルによって生成されるテキストはより多様で表現力豊かになります。ただし、語彙が増えるほど、モデルに必要なメモリとコンピューティング リソースが増加します。したがって、語彙の選択は、モデルの品質と効率の間のトレードオフに依存します。
大規模なモデルの使用コストは、モデルとの対話に使用されるトークンの数と、モデルごとに異なるレートに基づいて大きく異なります。たとえば、2023 年 2 月の時点で、Davinci の使用料金は 1,000 トークンあたり 0.06 ドルですが、Ada の使用料金は 1,000 トークンあたり 0.0008 ドルです。この比率は、遊び場や検索などの使用の種類によっても変化します。したがって、トークン化は、大規模なモデルを実行するコストとパフォーマンスに影響を与える重要な要素です。
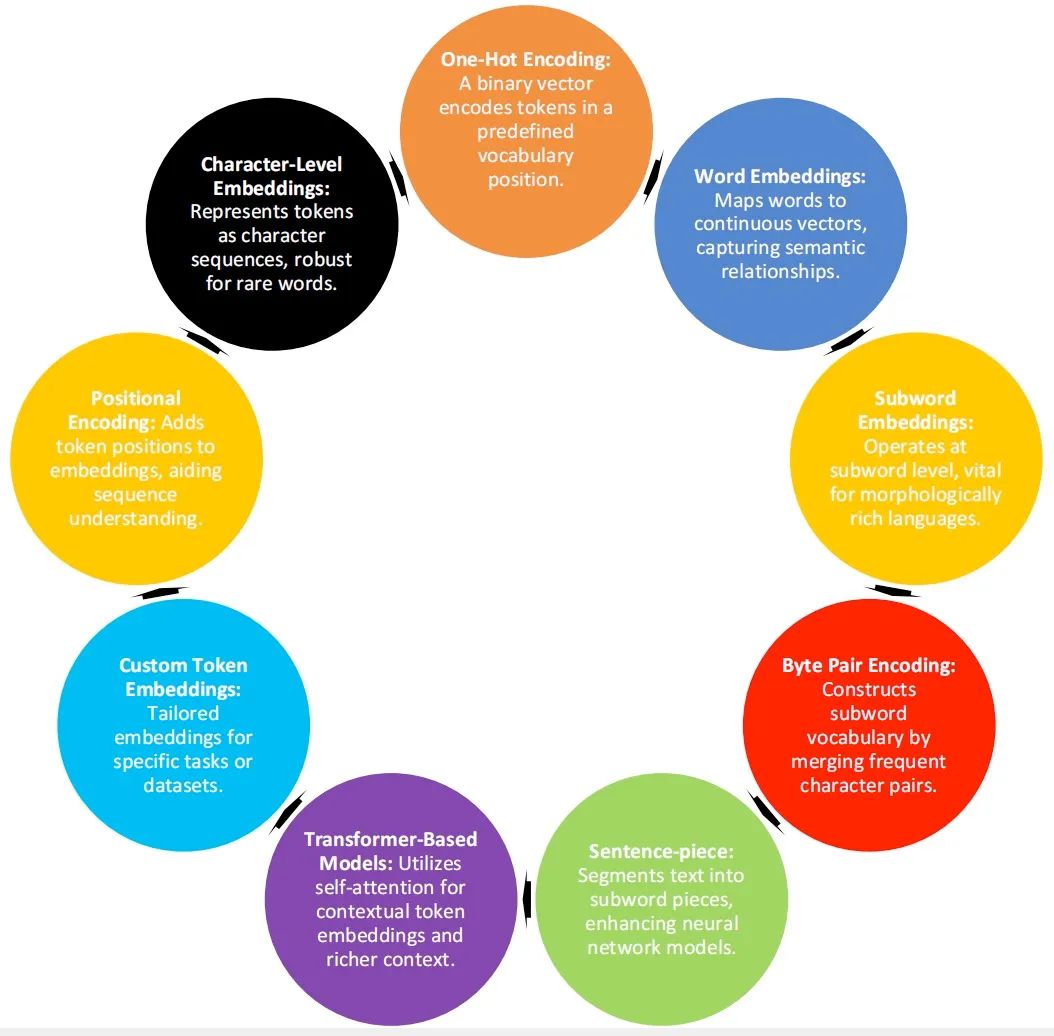
4.1 7 種類のトークン化
トークン化には、テキストを意味のある単位にセグメント化して、その意味論的および構文構造をキャプチャすることが含まれます。単語レベル、サブワード レベル (バイト ペア エンコードや WordPiece を使用するなど)、文字レベルなど、さまざまなトークン化手法を使用できます。各手法には、特定の言語と特定のタスクのニーズに応じて、独自の利点とトレードオフがあります。
バイト ペア エンコーディング (BPE): AI モデルのサブワード語彙を構築し、頻繁に発生する文字/サブワードのペアをマージするために使用されます。
サブワードレベルのトークン化: 単語を複雑な言語と語彙に分割します。複雑な言語では、単語をより小さな単位に分割することが重要です。
単語レベルのトークン化: 言語処理のための基本的なテキストのトークン化。各単語は異なるトークンとして使用され、シンプルですが制限されています。
文の断片化: 学習したサブワード断片を使用したテキストのセグメント化、学習したサブワード断片に基づくセグメント化。
単語セグメンテーションのトークン化: さまざまな結合方法を使用したサブワード単位。
バイトレベルのトークン化: バイトレベルのトークン化を使用してテキストの多様性を処理し、各バイトをトークンとして扱います。これは多言語タスクにとって非常に重要です。
ハイブリッド トークン化: 単語レベルとサブ単語レベルのトークン化を組み合わせて、詳細と解釈可能性のバランスをとります。
LLM は、多言語およびマルチモーダル入力を処理できるように拡張されました。これらのデータの多様性に対応するために、特殊なトークン化方法が開発されました。多言語マークアップは、言語固有のトークンまたはサブワード テクノロジーを活用して、単一モデルで複数の言語を処理します。マルチモーダル マークアップは、融合や連結などの技術を使用して、テキストを画像や音声などの他のモダリティと組み合わせて、異種のデータ ソースを効果的に表現します。
4.2 トークン化の重要性
トークン化は、LLM の効率、柔軟性、一般化機能において重要な役割を果たします。テキストをより小さく管理しやすい単位に分割することで、LLM はテキストをより効率的に処理および生成できるようになり、計算の複雑さとメモリ要件が軽減されます。さらに、トークン化により、さまざまな言語、ドメイン固有の用語、さらにはインターネットスラングや顔文字などの新たなテキスト形式に適応することで柔軟性が得られます。この柔軟性により、LLM は幅広いテキスト入力を処理できるようになり、さまざまなドメインやユーザー コンテキストでの適用性が向上します。
トークン化テクノロジーの選択には、粒度と意味の理解の間のトレードオフが関係します。単語レベルのタグは個々の単語の意味を捕捉しますが、語彙外 (OOV) 用語や形態学的に豊富な言語に遭遇する可能性があります。サブワード レベルのトークン化により、柔軟性が向上し、単語をサブワード単位に分割することで OOV 用語が処理されます。ただし、文全体の文脈におけるサブワード マーカーの意味を正しく理解することは困難です。トークン化手法の選択は、特定のタスク、言語特性、利用可能なコンピューティング リソースによって異なります。
4.3 トークン化が直面する課題: ノイズの多い、または不規則なテキスト データの処理
現実世界のテキスト データには、ノイズ、不規則性、または不一致が含まれることがよくあります。トークン化は、スペルミス、略語、スラング、または文法上の誤りのある文を扱うときに課題に直面します。このノイズの多いデータを処理するには、堅牢な前処理技術とドメイン固有のトークン化ルールの調整が必要です。さらに、トークン スクリプトや明確な単語境界のない言語など、複雑なオーサリング システムを備えた言語を扱う場合、トークン化で問題が発生する可能性があります。これらの課題を解決するには、多くの場合、特殊なトークン化方法や既存のトークナイザーの適応が必要になります。
トークン化はモデル固有です。モデルの語彙とトークン化スキームに応じて、トークンのサイズと意味が異なる場合があります。たとえば、「running」や「ran」などの単語は異なるトークンで表すことができ、これはモデルの時制や動詞の形式の理解に影響します。さまざまなモデルが独自のトークナイザーをトレーニングします。LLaMa も BPE を使用しますが、トークンは ChatGPT とも異なるため、前処理とマルチモーダル モデリングがより複雑になります。
5. LLM アプリケーションでのトークンの使用
現在のタスクのトークンの使用状況を知る必要があるため、大規模モデルのトークン長の制限に直面して、いくつかの解決策を試すことができます。
5.1 トークンの使用状況
ここでは OpenAI の API を使用し、langchain アプリケーション フレームワークを使用して簡単なアプリケーションを構築し、現在のテキスト入力のトークン使用状況を記述します。
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
with get_openai_callback() as cb:
result = llm("给我讲个笑话吧")
print(cb)エージェント タイプのアプリケーションの場合、同様の方法を使用して、それぞれのトークンの統計データを取得できます。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
with get_openai_callback() as cb:
response = agent.run(
"Who is Olivia Wilde's boyfriend? What is his current age raised to the 2023?"
)
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")5.2 LLM におけるトークンの長さ制限と応答
GPT-3/4、LLaMA などの大規模モデルにはトークンの最大数があり、それを超えると入力を受け入れたり出力を生成したりできません。
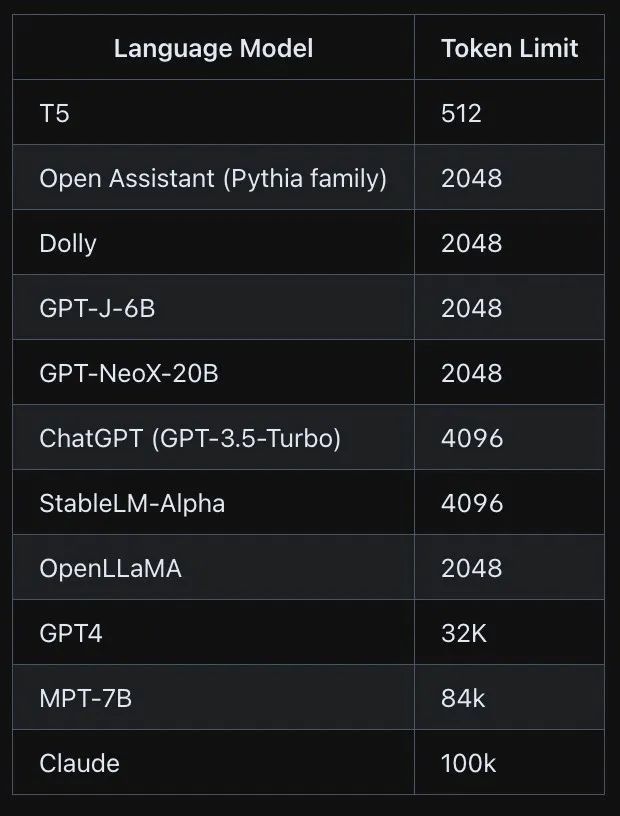
一般に、トークンの長さ制限の問題を解決するには、次の方法を試すことができます。
切り詰める
切り捨てには、トークン制約内に収まるように入力テキストの一部を削除することが含まれます。これは、テキストの先頭または末尾、あるいはその両方の組み合わせを削除することで実行できます。ただし、切り詰めると重要な情報が失われる可能性があり、生成される出力の品質と一貫性に影響を与える可能性があります。
サンプリング
サンプリングは、入力テキストからトークンのサブセットをランダムに選択する手法です。これにより、入力の多様性をある程度保つことができ、異なる出力を生成するのに役立ちます。ただし、このアプローチ (切り捨てと同様) では、コンテキスト情報が失われ、生成される出力の品質が低下する可能性があります。
再編
もう 1 つのアプローチは、入力テキストをシンボルの制限内で小さなチャンクまたはセグメントに分割し、それらを順番に処理することです。このようにして、各ブロックを独立して処理し、出力を連結して最終結果を得ることができます。
コーデック
エンコードとデコードは、テキスト データを数値表現に変換したり、その逆に変換したりする一般的な自然言語処理技術です。これらの手法を使用すると、言語モデルのマークアップ制約に合わせてテキストを圧縮、解凍、切り詰め、または拡張することができます。このアプローチでは追加の前処理手順が必要となり、生成された出力の読みやすさに影響を与える可能性があります。
微調整
微調整により、タスク固有のデータをあまり使用せずに、事前トレーニングされた言語モデルを特定のタスクまたはドメインに適応させることができます。微調整を利用して、チャンク化またはより小さな部分に分割されたテキストのシーケンス内の次のトークンを予測するようにモデルをトレーニングすることで、言語モデルのトークン制限に対処できます。各テキストはモデルのトークン制限内に収まります。
6. トークン関連技術の展望
トークンは伝統的にテキスト単位を表していましたが、トークンの概念は言語要素を超えています。最近の進歩により、画像、音声、ビデオなどの他のモダリティのラベル付けが検討され、LLM がこれらのモダリティと並行してテキストを処理および生成できるようになりました。このマルチモーダルなアプローチは、豊富で多様なデータ ソースのコンテキストでテキストを理解して生成するための新しい機会を提供します。これにより、LLM は画像のキャプションを分析し、テキストの説明を生成し、詳細な音声転写を提供することもできます。
トークン化の分野は、ダイナミックかつ進化する研究分野です。将来の進歩は、トークン化の制限への対処、OOV 処理の改善、新興言語とテキスト形式のニーズへの適応に焦点を当てる可能性があります。さらに、トークン化テクノロジーは引き続き改良され、ドメイン固有の知識を組み込み、コンテキスト情報を利用して意味の理解を強化します。トークン化の継続的な開発により、LLM はより高い精度、効率、適応性でテキストを処理および生成できるようになります。
7. まとめ
トークンは、LLM 言語処理機能をサポートする基本コンポーネントです。 LLM におけるトークンの役割、およびトークン化における課題と進歩を理解することで、これらのモデルの可能性を最大限に理解できるようになります。私たちはトークンの世界の探求を続ける中で、機械がテキストを理解して生成する方法に革命を起こし、自然言語処理の限界を押し広げ、さまざまな分野で革新的なアプリケーションを推進していきます。
PS. もう 1 つ、大規模なモデル アプリケーションを開発するときに知っておくべき数値は次のとおりです。

【参考資料と関連書籍】
https://python.langchain.com/docs
https://blog.langchain.dev/
OpenAI: トークンとは何ですか?、その数え方は?、 https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
マルチスケールトランスフォーマーによる百万バイトシーケンスの予測、https://arxiv.org/pdf/2305.07185.pdf
https://learn.microsoft.com/en-us/semantic-kernel/prompt-engineering/tokens
https://www.anyscale.com/blog/num-every-llm-developer-Should-know