LLM アプリケーションの新しいアーキテクチャ
大規模な言語モデルは、ソフトウェアを構築するための強力な新しいプリミティブです。しかし、これらは非常に新しく、通常のコンピューティング リソースとは動作が大きく異なるため、その使用方法が必ずしも明らかであるとは限りません。
このペーパーでは、新たな大規模言語モデル アプリケーション スタックのリファレンス アーキテクチャを共有します。AI スタートアップや先端テクノロジー企業でよく見られる最も一般的なシステム、ツール、設計パターンを紹介します。このスタックはまだ非常に初期段階にあり、基盤となるテクノロジーの進歩に伴って大幅に変更される可能性がありますが、現在大規模な言語モデルを扱う開発者にとって有益な参考資料となることを願っています。
LLM アプリケーション スタック
LLM アプリケーション スタックの現在のビューは次のとおりです。
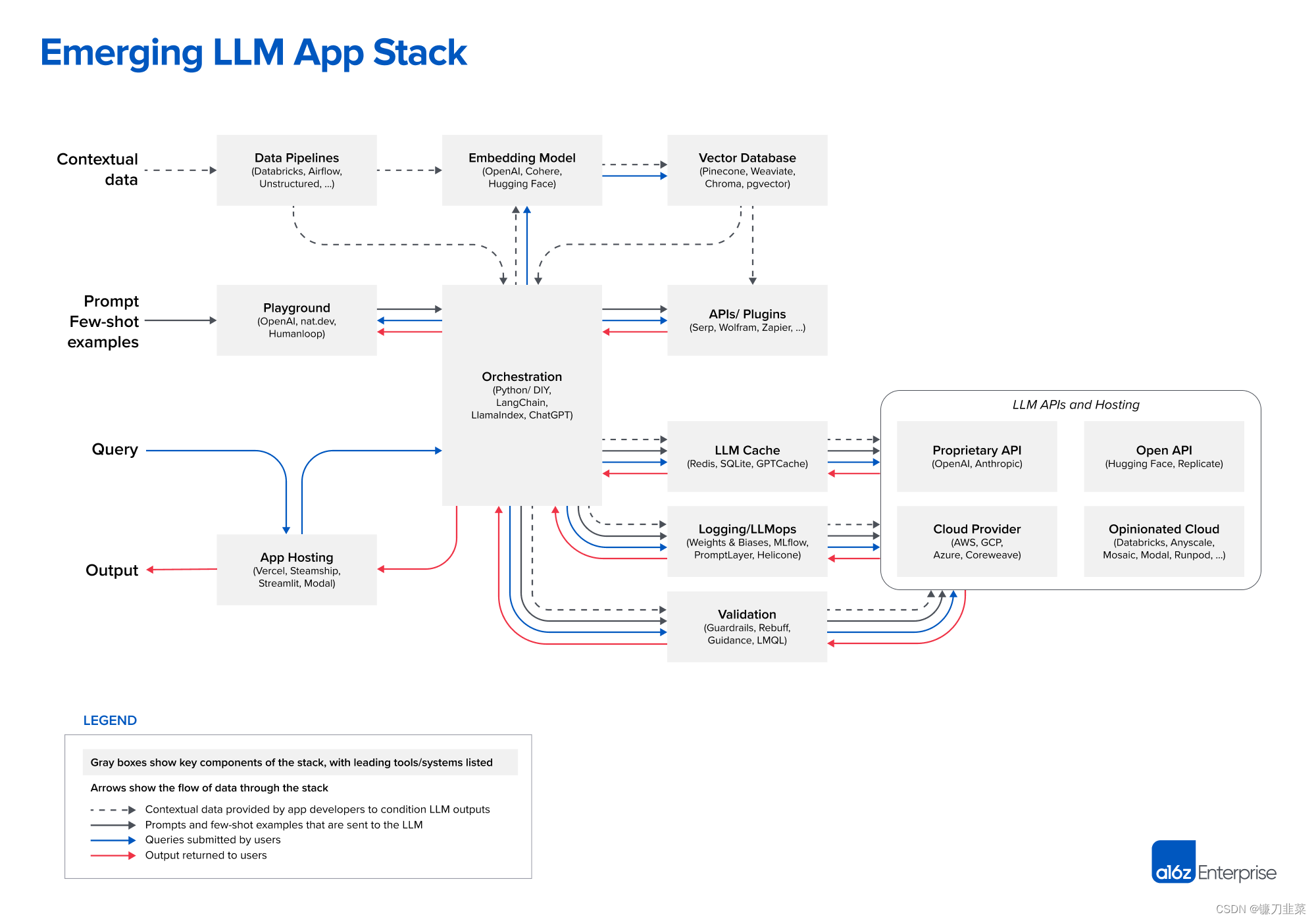
以下は、クイック リファレンスとして各プロジェクトへのリンクのリストです。
| データパイプライン | 埋め込みモデル | ベクトルデータベース | 遊び場 | オーケストレーション | API/プラグイン | LLM キャッシュ |
|---|---|---|---|---|---|---|
| データブリック | OpenAI | 松ぼっくり | OpenAI | ラングチェーン | セルプ | レディス |
| 気流 | 密着 | ウィアビエイト | nat.dev | ラマインデックス | ヴォルフラム | SQLite |
| 非構造化 | ハグフェイス | クロマDB | ヒューマンループ | チャットGPT | ザピエル | GPTCache |
| ベクター |
| ロギング/LLMops | 検証 | アプリのホスティング | LLM API (独自仕様) | LLM API (オープン) | クラウドプロバイダー | 意見の多い雲 |
|---|---|---|---|---|---|---|
| 重みとバイアス | ガードレール | ヴェルセル | OpenAI | ハグフェイス | AWS | データブリック |
| MLフロー | 拒絶 | 汽船 | 人間的 | 複製する | GCP | エニースケール |
| プロンプトレイヤー | マイクロソフトのガイダンス | ストリームライト | アズール | モザイク | ||
| ヘリコン | LMQL | モーダル | コアウィーブ | モーダル | ||
| ランポッド |
LLM を使用して構築するには、モデルを最初からトレーニングする、オープンソース モデルを微調整する、マネージド API を使用するなど、さまざまな方法があります。ここで紹介するテクノロジー スタックは、ほとんどの開発者が最初に使用する設計パターンであるコンテキスト学習 に基づいています (現在は基本モデルでのみ可能です)。
このパターンについては次のセクションで簡単に説明しますが、経験豊富な LLM 開発者はこのセクションをスキップしてください。
デザインパターン: コンテキスト内学習
コンテキスト学習の中心的な考え方は、既製の LLM を(つまり、微調整なしで) 使用し、プライベートな「コンテキスト」データに対する賢い手がかりと条件付けを通じてその動作を制御することです。
たとえば、一連の法的文書に関する質問に答えるチャットボットを構築しているとします。すべてのドキュメントを ChatGPT または GPT-4 プロンプトに貼り付け、最後にドキュメントについて質問するネイティブ アプローチを採用します。これは非常に小さなデータセットでは機能する可能性がありますが、拡張できません。最大の GPT-4 モデルは、約 50 ページの入力テキストしか処理できず、この制限 (コンテキスト ウィンドウと呼ばれる) に近づくと、パフォーマンス (推論時間と精度で測定) が大幅に低下します。
コンテキスト学習は、LLM プロンプトごとにすべてのドキュメントを送信するのではなく、最も関連性の高い少数のドキュメントのみを送信するという賢明なトリックでこの問題を解決します。**最も関連性の高いファイルは、次の助けを借りて特定されました... ご想像のとおり、LLM です。
大まかに言うと、ワークフローは次の 3 つのフェーズに分類できます。
- データの前処理/埋め込み: このフェーズには、後で取得するためにプライベート データ (この例では法的文書) を保存することが含まれます。通常、ドキュメントはチャンクに分割され、埋め込みモデルを通過して、 と
向量数据库呼ばれる特殊なデータベースに保存されます。 - プロンプトの構築/取得: ユーザーがクエリ (この場合は法的な質問) を送信すると、アプリケーションは言語モデルに送信する一連のプロンプトを構築します。コンパイルされたヒントは通常、開発者によってハードコーディングされたヒント テンプレート、少数のショー例と呼ばれる有効な出力の例、外部 API から取得された必要な情報、およびベクトル データベースから取得された一連の関連ドキュメントを組み合わせたものです。
- プロンプトの実行/推論: プロンプトがコンパイルされると、独自のモデル API やオープンソースまたは自己トレーニングされたモデルを含む、推論のために事前トレーニングされた LLM に送信されます。一部の開発者は、この段階でロギング、キャッシュ、検証などのオペレーティング システムを追加します。
これは大変な作業のように思えるかもしれませんが、通常は他のオプション ( LLM 自体のトレーニングや微調整)よりも簡単です。コンテキスト学習を行うために ML エンジニアの専任チームは必要ありません。また、独自のインフラストラクチャをホストしたり、OpenAI から高価な専用インスタンスを購入したりする必要もありません。このモデルは、AI の問題を、ほとんどの新興企業や大企業がすでに解決方法を知っているデータ エンジニアリングの問題に効果的に還元します。また、LLM が微調整を通じて記憶し、新しいデータをほぼ実際に組み込むことができるようにするには、特定の情報がトレーニング セット内に少なくとも 10 回以上出現する必要があるため、比較的小さなデータセットの微調整よりも優れたパフォーマンスを発揮する傾向があります。時間。
コンテキスト学習における最大の疑問の 1 つは、基礎となるモデルを変更してコンテキスト ウィンドウを増やすとどうなるかということです。これは実際に可能であり、活発な研究分野です (たとえば、ハイエナの論文やこの最近の投稿を参照してください)。ただし、これにはいくつかのトレードオフが伴います。主に、推論のコストと時間がヒントの長さに応じて二次関数的に増加することです。現在、線形スケーリング (最良の理論的結果) であっても、多くのアプリケーションではコストが非常に高くなります。現在の API 価格では、10,000 ページを超える GPT-4 クエリには数百ドルの費用がかかります。したがって、展開されたコンテキスト ウィンドウに基づいたスタックへの大規模な変更は予想されませんが、これについては記事の本文で詳しく説明します。
コンテキスト学習をさらに深く掘り下げたい場合は、AI の規範に多くの優れたリソースがあります(特に「 LLM 構築の実践ガイド」セクション)。この記事の残りの部分では、上記のワークフローをガイドとして使用して、リファレンス スタックについて説明します。
データの前処理/埋め込み
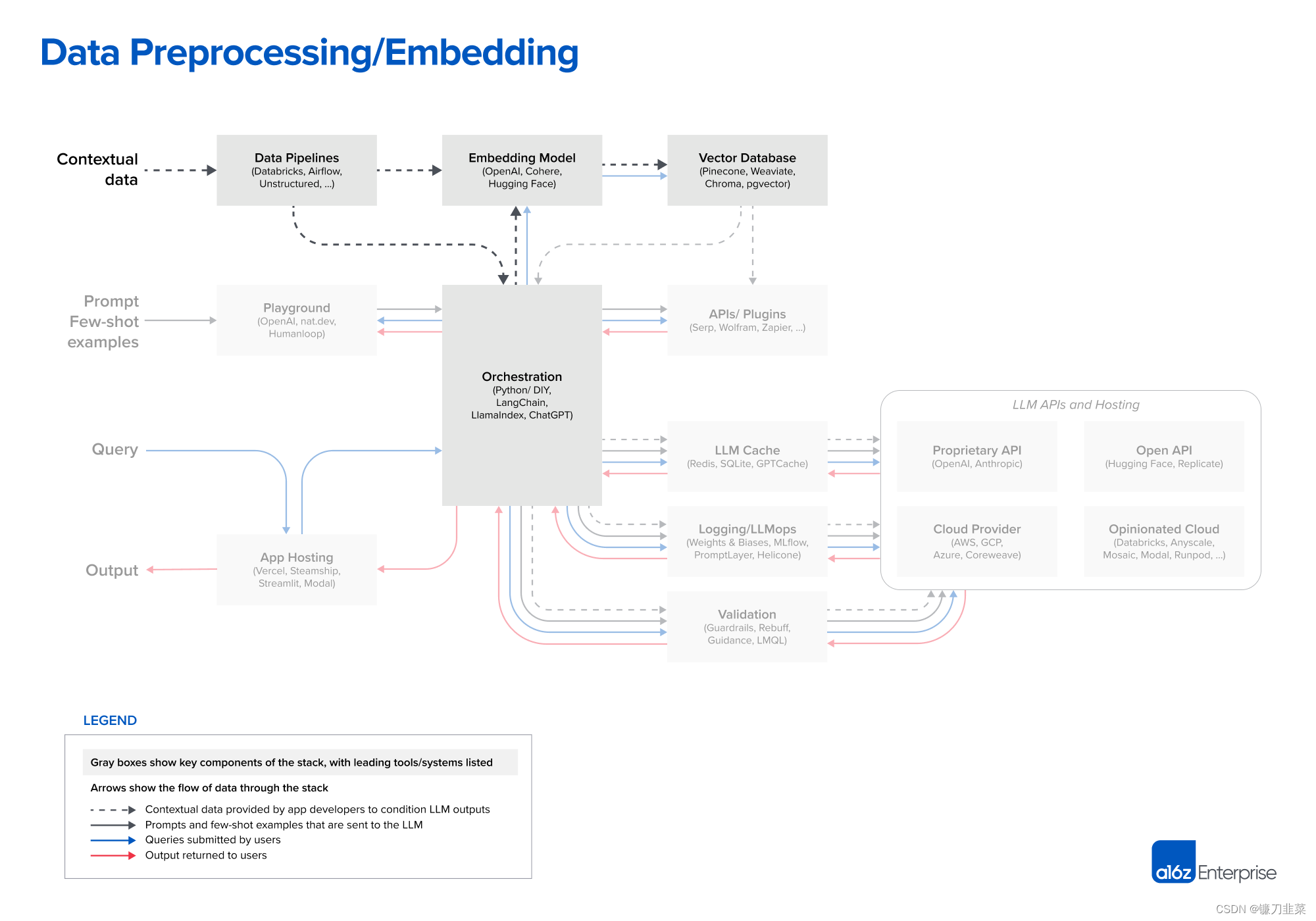
LLM アプリケーションのコンテキスト データには、テキスト ドキュメント、PDF、さらには CSV や SQL テーブルなどの構造化フォーマットが含まれます。このデータのデータ読み込みおよび変換ソリューションは、インタビューした開発者によって大きく異なりました。ほとんどは、Databricks や Airflow などの従来の ETL ツールを使用します。LangChain (Un Structured を利用) や LlamaIndex (Llama Hub を利用) など、オーケストレーション フレームワークに組み込まれたドキュメント ローダーを使用する場合もあります。ただし、このセグメントは比較的未成熟であり、LLM アプリケーション専用のデータ レプリケーション ソリューションを構築する機会があると考えています。
埋め込みの場合、ほとんどの開発者は OpenAI API、特にtext-embedding-ada-002モデルを使用します。使いやすく (特に他の OpenAI API をすでに使用している場合)、かなりうまく機能し、価格もどんどん安くなっています。一部の大企業も、埋め込みと特定のシナリオでのパフォーマンス向上に重点を置いた製品を提供する Cohere を検討しています。オープンソースを好む開発者にとって、Hugging Face の文コンバータ ライブラリは標準です。さまざまなユースケースに応じてさまざまなタイプの埋め込みを作成することもできます。これは今日ではニッチな実践ですが、有望な研究分野です。
システムの観点から見ると、前処理パイプラインの最も重要な部分はベクトル データベースです。これは、最大数十億のエンベディング (ベクトルなど) を効率的に保存、比較、取得する役割を果たします。市場で最も一般的なオプションは松ぼっくりです。これはデフォルトであり、完全にクラウドでホストされており、大企業が実稼働環境で必要とする多くの機能 (大規模なパフォーマンス、SSO、稼働時間 SLA など) を備えているため、簡単に始めることができます。
ただし、利用可能なベクトル データベースは多数あります。次の点に注意してください。
- Weaviate、Vespa、Qdrant などのオープンソース システム: 多くの場合、優れた単一ノード パフォーマンスを備え、特定のアプリケーションに合わせてカスタマイズできるため、カスタム プラットフォームを構築したい経験豊富な AI チームに人気があります。
- Chroma や Faiss などのネイティブ ベクター管理ライブラリ: 経験豊富な開発者が多く、小規模なアプリケーションや開発実験での開発が容易です。しかし、それらは必ずしも本格的なデータベースを大規模に置き換えるわけではありません。
- pgvector のような OLTP 拡張機能: データベースの形をした穴をすべて見つけて Postgres に接続しようとしたり、データ インフラストラクチャのほとんどを単一のクラウド プロバイダーから購入しようとする開発者にとって優れたベクトル サポート ソリューションです。ベクトルとスカラーのワークロードを密結合することが長期的には意味があるかどうかは不明です。
今後、ほとんどのオープンソース ベクトル データベース企業がクラウド製品を開発しています。調査によると、クラウドで堅牢なパフォーマンスを達成することは、想定されるユースケースの広大な設計空間では非常に困難な問題です。したがって、一連のオプションは短期的には劇的に変化しないかもしれませんが、長期的には変化する可能性があります。重要な問題は、OLTP や OLAP と同様に、ベクトル データベースが 1 つまたは 2 つの一般的なシステムを中心に統合されるかどうかです。
もう 1 つの未解決の問題は、ほとんどのモデルで利用できるコンテキストのウィンドウが拡大するにつれて、埋め込みデータベースとベクトル データベースがどのように進化するかということです。コンテキスト データをプロンプトに直接ドロップできるため、埋め込みの関連性が薄れると主張するのは簡単です。ただし、このトピックに関する専門家のフィードバックは、埋め込みパイプラインが時間の経過とともにより重要になる可能性があることを示唆しています。大きなコンテキスト ウィンドウは強力なツールですが、かなりの計算コストも必要になります。したがって、それらを有効に活用することが不可欠です。さまざまなタイプの埋め込みモデルが普及し、モデルの関連性を直接トレーニングして、これを可能にして活用するように設計されたベクトル データベースが普及し始めるかもしれません。
迅速な構築/回収
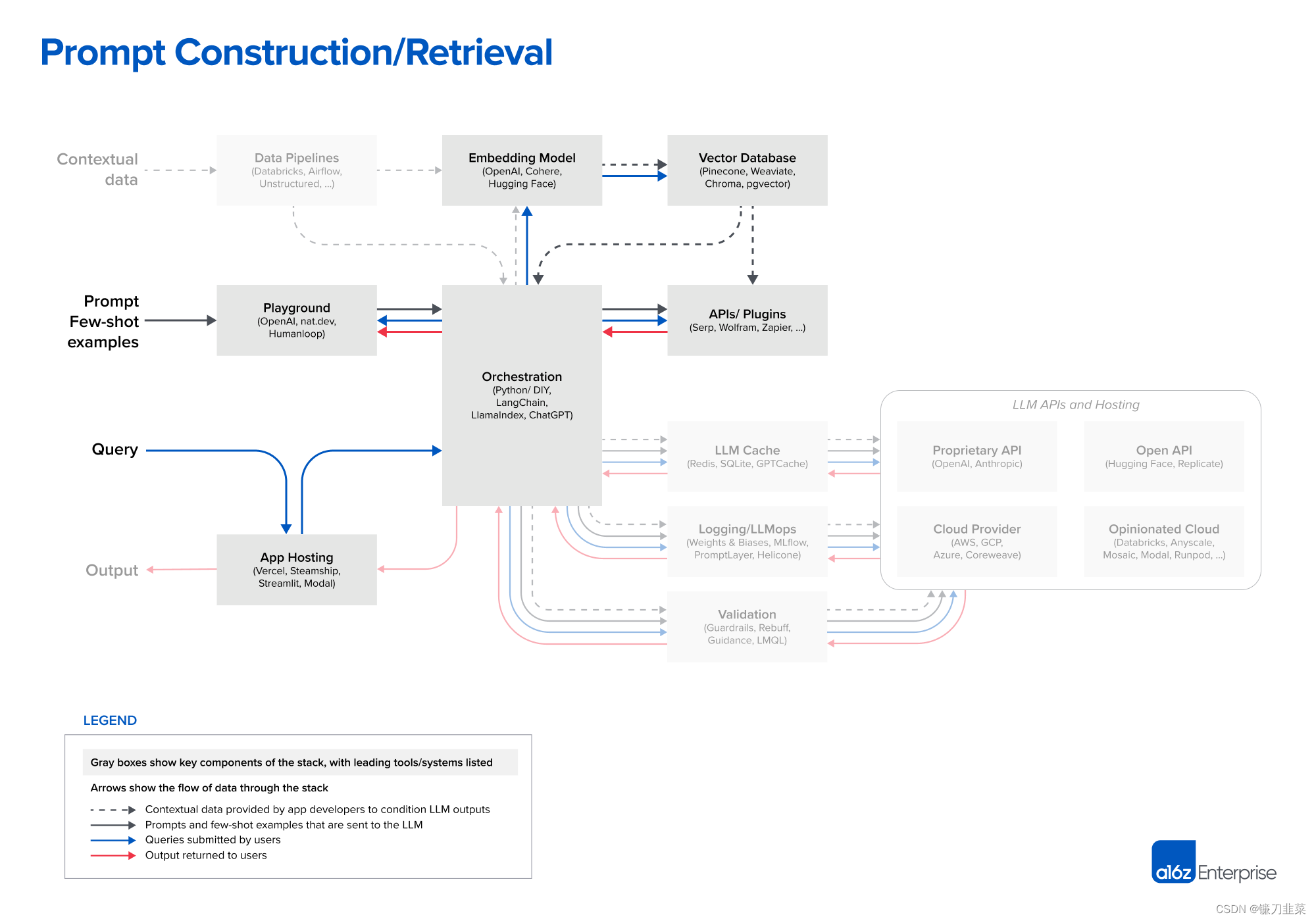
LLM を促進し、製品差別化のソースとしてコンテキスト データを統合する戦略は、ますます洗練され、重要になっています。ほとんどの開発者は、直接的な命令 (ゼロショット ヒント) または場合によってはサンプル出力 (少数ショット ヒント) のいずれかである、単純なヒントを試して新しいプロジェクトを開始します。これらのヒントは通常、良好な結果をもたらしますが、運用環境の展開に必要な精度レベルには達しません。
ヒントの次のレベルである柔術は、モデルの応答を何らかの真実の情報源に基づいて行い、モデルがトレーニングされていない外部環境を提供することを目的としています。『プロンプト エンジニアリング ガイド』には、思考の連鎖、自己一貫性、生成された知識、思考ツリー、方向性刺激などを含む 12 個以上の高度なプロンプト戦略がリストされています。これらの戦略は、ドキュメント Q&A、チャットボットなど、さまざまな LLM ユースケースをサポートするために使用することもできます。
ここで、 LangChain や LlamaIndex などのオーケストレーション フレームワークが威力を発揮します。これらは、ヒントのリンク、外部 API とのインターフェイス (API 呼び出しが必要なタイミングの決定を含む)、ベクトル データベースからのコンテキスト データの取得、複数の LLM 呼び出しにわたるメモリの維持の多くの詳細を抽象化します。また、上記の一般的なアプリケーションの多く用のテンプレートも提供します。それらの出力は、言語モデルに送信されたヒントまたはヒントのシーケンスです。これらのフレームワークは、愛好家やアプリケーションの立ち上げを検討している新興企業の間で広く使用されており、LangChain はそのリーダーです。
LangChain はまだ比較的新しいプロジェクト (現在バージョン 0.0.201) ですが、LangChain を使用して構築されたアプリケーションがすでに運用され始めています。一部の開発者、特に LLM の初期導入者は、追加の依存関係を削除するために実稼働環境で生の Python に切り替えることを好みます。しかし、この DIY アプローチは、従来の Web アプリケーション スタックと同様に、ほとんどのユースケースで時間の経過とともに減少すると予想されます。
鋭い読者は、オーケストレーション ボックスに一見奇妙なエントリである ChatGPT があることに気づくでしょう。通常の形態では、ChatGPT は開発ツールではなくアプリケーションです。ただし、API としてアクセスすることもできます。さらに、よく見ると、カスタム ヒントの必要性の抽象化、状態の維持、プラグイン、API、またはその他のソースを介したコンテキスト データの取得など、他のオーケストレーション フレームワークと同じ機能の一部を実行します。ChatGPT は、ここにリストされている他のツールの直接の競合相手ではありませんが、インスタント ビルドに代わる実行可能で簡単な代替ソリューションとなる可能性がある代替ソリューションと考えることができます。
即時実行/推論
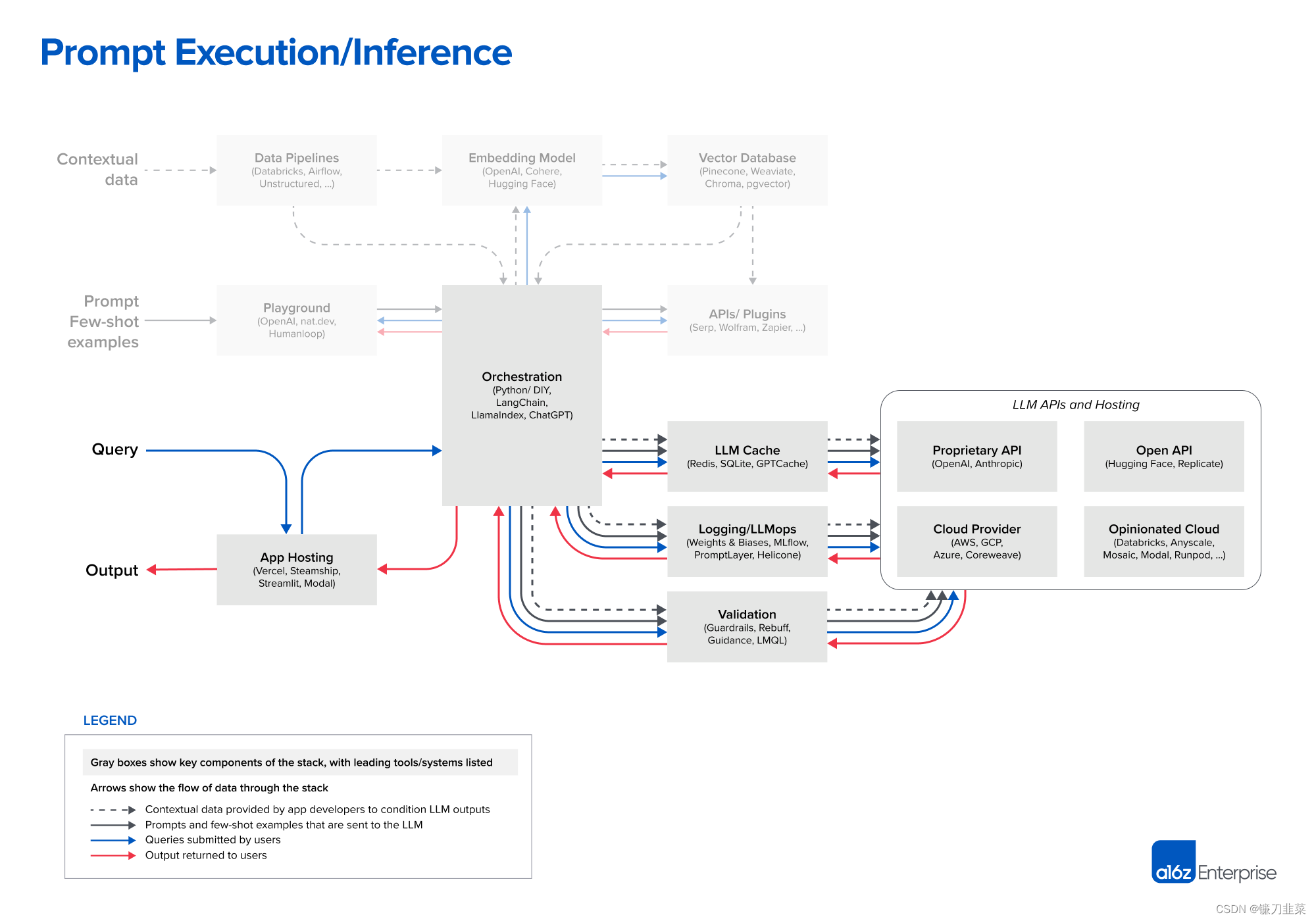 現在、OpenAI は言語モデルの先頭に立っている。私たちがインタビューしたほぼすべての開発者は、OpenAI API を使用して新しい LLM アプリケーションを開始しており、通常は
現在、OpenAI は言語モデルの先頭に立っている。私たちがインタビューしたほぼすべての開発者は、OpenAI API を使用して新しい LLM アプリケーションを開始しており、通常はgpt-4またはgpt-4-32kモデルを使用しています。これにより、アプリケーションのパフォーマンスにスイート スポットが提供され、幅広い入力ドメインで動作し、通常は微調整や自己ホスティングが必要ないため、使いやすくなります。
プロジェクトが実稼働に入り、スケールし始めると、より幅広いオプションが必要になります。よく聞かれる質問には次のようなものがあります。
- gpt-3.5-turbo に切り替えます。GPT-4 よりも約 50 倍安く、大幅に高速です。多くのアプリケーションは GPT-4 レベルの精度を必要としませんが、低遅延の推論と無料ユーザー向けのコスト効率の高いサポートを必要とします。
- 他の独自のベンダー (特に Anthropic の Claude モデル) で実験してください。Claude は、高速推論、GPT-3.5 レベルの精度、より大規模なカスタム オプション、および最大 100k のコンテキスト ウィンドウを提供します (ただし、精度は入力に応じてスケールし、長さが増加すると減少することがわかりました)。
- 一部のリクエストをオープンソース モデルにオフロードする: これは、クエリの複雑さが大きく異なり、無料ユーザーに安価にサービスを提供する必要がある、検索やチャットなどの大量の B2C ユースケースで特に効果的です。
- 多くの場合、これは、オープンソースの基本モデルを微調整することと組み合わせて行うのが最も効果的です。この記事では、ツール スタックについては詳しく説明しませんでしたが、Databricks、Anyscale、Mosaic、Modal、RunPod などのプラットフォームを使用するエンジニアリング チームが増えています。
- オープンソース モデルには、Hugging Face および Replicate 用のシンプルな API インターフェイス、主要なクラウド プロバイダーの生のコンピューティング リソース、上記のような独自のクラウド製品など、さまざまな推論オプションがあります。
オープンソース モデルは現在、プロプライエタリな製品に比べて遅れをとっていますが、その差は縮まり始めています。Meta の LLaMa モデルは、オープンソースの精度の新たな基準を設定し、一連の亜種を生み出しました。LLaMa は研究用途のみにライセンスされているため、多くの新しいベンダーが代替ベース モデル (Togetter、Mosaic、Falcon、Mistral など) をトレーニングするために参入しています。Meta は、LLaMa 2 の真のオープンソース バージョンについても議論しています。
オープンソース LLM が GPT-3.5 に匹敵する精度レベルに到達すると (そうでない場合ではなく)、大規模な実験、共有、微調整されたモデルの製品化など、テキストが着実に普及する同様の瞬間が訪れると予想されます。Replicate のようなホスティング会社は、ソフトウェア開発者がこれらのモデルをより利用しやすくするためのツールをすでに追加しています。開発者は、より小型で微調整されたモデルが狭い使用例で最先端の精度を達成できると信じています。
私たちがインタビューした開発者のほとんどは、 LLM の運用ツールをまだ詳しく調べていません。キャッシュはアプリケーションの応答時間とコストを改善するため、通常は Redis に基づいており、比較的一般的です。Weights & Biases や MLflow (従来の機械学習から移植)、PromptLayer や Helicone (LLM 専用に構築) などのツールもかなり広く使用されています。LLM 出力を記録、追跡、評価でき、オンザフライ ビルドの改善、パイプラインの調整、モデルの選択によく使用されます。また、LLM 出力 (ガードレールなど) を検証したり、インスタント インジェクション攻撃 (Rebuff など) を検出したりするための新しいツールも多数開発されています。これらの運用ツールのほとんどは、LLM 呼び出しに独自の Python クライアントの使用を推奨しているため、これらのソリューションが時間の経過とともにどのように共存するかを見るのは興味深いでしょう。
最後に、LLM アプリケーションの静的な部分 (つまり、モデル以外のすべて) もどこかにホストする必要があります。私たちがこれまでに見た中で最も一般的なソリューションは、Vercel や大手クラウド プロバイダーなどの標準オプションです。ただし、2 つの新しいカテゴリが出現しています。Steamship などのスタートアップは、オーケストレーション (LangChain)、マルチテナント データ コンテキスト、非同期タスク、ベクトル ストレージ、キー管理などの LLM アプリケーションのエンドツーエンド ホスティングを提供します。Anyscale や Modal などの企業では、開発者がモデルと Python コードを 1 か所でホストできるようにしています。
エージェントについてはどうですか?
このリファレンス アーキテクチャに欠けている最も重要なコンポーネントは、AI エージェント フレームワークです。「GPT-4 を完全に自律化するための実験的なオープンソースの試み」と説明されている AutoGPT は、この春史上最も急速に成長している Github リポジトリであり、今日のほぼすべての AI プロジェクトまたはスタートアップには何らかの形式のプロキシが含まれています。
ほとんどの開発者はエージェントの可能性に興奮しています。この論文で説明されているコンテキスト学習モデルは、幻覚やデータの鮮度の問題に対処し、コンテンツ生成タスクをより適切にサポートするのに効果的です。一方、エージェントは、AI アプリケーションに、複雑な問題の解決、外部世界への作用、展開後の経験からの学習など、まったく新しい機能セットを提供します。彼らは、高度な推論/計画、ツールの使用、記憶/再帰/内省の組み合わせを通じてこれを行います。
そのため、エージェントは LLM アプリケーション アーキテクチャの中心部分になる可能性があります(再帰的な自己改善を信じている場合は、スタック全体を引き継ぐことさえできます)。LangChain などの既存のフレームワークには、すでにいくつかのプロキシの概念が含まれています。問題が 1 つだけあります。プロキシがまだ実際には機能していないことです。現在、ほとんどのエージェント フレームワークは概念実証の段階にあり、驚くべきデモンストレーションが可能ですが、まだ信頼性と再現性を持って実行することはできません。**私たちは、それらが近い将来どのように発展するかを注意深く見守っています。
展望
事前トレーニングされた AI モデルは、インターネット以来、ソフトウェアにおける最も重要なアーキテクチャの変化を表しています。これらにより、個人の開発者は数日で驚異的な AI アプリケーションを構築できるようになり、大規模チームが構築するのに数か月かかる教師あり機械学習プロジェクトを上回ります。
ここにリストされているツールとパターンは、統合 LLM の終点ではなく、開始点である可能性があります。重大な変更 (モデル トレーニングへの移行など) があった場合はこれを更新し、意味のある場合は新しいリファレンス アーキテクチャを公開します。