記事ディレクトリ
パート 1: スタック
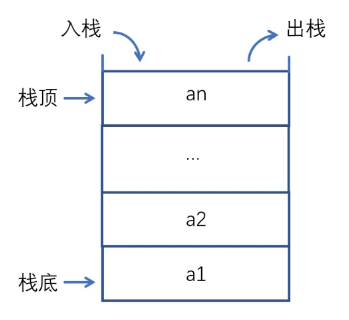
1. スタックの定義
一方の端でのみ挿入または削除操作を許可する線形リスト、4 つの単語:「後入れ先出し」
要素を挿入するスタック これはプッシュと呼ばれ、スタックからの要素の削除はポップ
2. スタック操作
| 空栈状态 | 入栈操作 | フルスタックステータス | 出栈操作 |
|---|---|---|---|
 |
 |
 |
 |
| 上部 = -1 | ① トップ = トップ+1; ② A[トップ] = a; |
上 = 最大サイズ-1 | ① e = A[トップ]; ② トップ = トップ-1; |
- 「オーバーフロー」 現象 - スタックがいっぱいになると、別の スタックへのプッシュ 操作が発生します。スペースオーバーフロー現象;
- 「アンダーフロー」 現象 - スタックが空の場合、ポップ操作が再度実行されると発生します 空間オーバーフロー現象。
パート 1 演習
-
スタックのプッシュ シーケンスが 1、2、3...、n であることがわかっている場合、その出力シーケンスは p1、p2、p3...、pn、p1=n の場合は pi になります。は (C) です。
A.i
B.n=i
C.n-i+1 (代数的手法により p2 が得られます)が n-1 で、p3 が n-2 である場合、帰納法では n-i+1) が得られます)
D. 不確実 -
要素 a1、a2、a3、a4 がシーケンス スタックに順番に入力され、次の不可能なポップアウト シーケンスは (D) です。 。
A.a4、a3、a2、a1 (すべてスタックにプッシュされ、1 つずつポップアウトされます)
B.a3, a2 , a4, a1 (最初に a1 ~ a3 をスタックにプッシュし、次に a3 と a2 をスタックからポップし、次に a4 をスタックにプッシュし、最後にスタックからポップします順)
C.a3、a4、a2、a1 (最初に a1 ~ a3 をスタックにプッシュし、次に a3 をスタックからポップし、次に a4 をプッシュします
D. a3、a1 、a4、a2 (明らかに、a2 がポップされた後に a1 をポップする必要があります)ポップ) -
連続したスタック S があるとします。要素 s1、s2、s3、s4、s5、s6 が順番にスタックにプッシュされます。スタックから取り出される 6 つの要素の順序が s2、s3 であるとします。 、s4、s6、s5、s1、次にスタック 容量は少なくとも (3) である必要があります。 - 空白を埋める
[分析]: スタックには同時に最大 s6、s5、s1 を保存できます
パート 2: 共有スタック
1. 共有スタックの定義
共有スタックはデュアル スタックとも呼ばれます。
2 つのスタックが共同してストレージ スペースを作成します。一方のスタックの底部がスペースの始まり (添字 0)、もう一方のスタックの底部がスペースの終わり (添字 Maxsize-1) となります。要素がスタックにプッシュされると、要素は両端から中央まで拡張され、残りのスペースをどちらのスタックでも使用できるようになります。
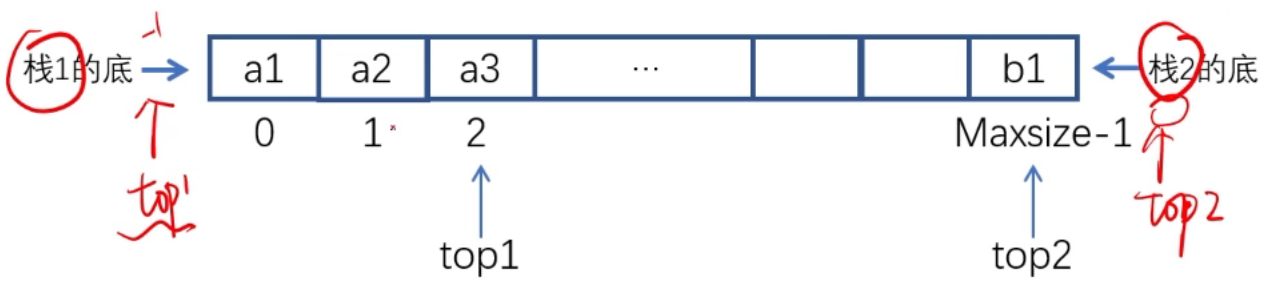
2. 共有スタックの運用
- 栈空: トップ 1 = -1; トップ 2 = 最大サイズ;
- スタックがいっぱいです。top1 = top2-1 (top1+1 = top2 も許容されます) の場合。
- スタック 1 の動作:
- 入栈:① top1 = top1+1(向栈1顶移动);② A[top1] = val;
- 出栈:① e = A[top1]; ② top1 = top1-1(向栈1底移动);
- スタック 2 の動作:
- 入栈:① top2 = top2-1(向栈2顶移动);② A[top2] = val;
- 出栈:① e = A[top2];② top2 = top2+1(向栈2底移动);
パート 2 演習
-
スタック オーバーフローの可能性を減らすために、2 つのスタックは連続したストレージ スペースを共有でき、2 つのスタックのスタック底部はこのスペースの両端に設定されます。 < a i=1>A) はオーバーフローを引き起こす可能性があります。 A. 2 つのスタックの上部がスタック スペース内の特定の位置で出会う B. いずれかのスタックの上部がスタックの中心点に達するスタック スペース a> (不可能状況、またはこの時点ですでにオーバーフローしています) (もう一方のスタックは空ではないため、スタックは C) と同様に、最大で一番下の前の位置に到達できます) D. どちらのスタックも空ではなく、一方のスタックの上部がもう一方のスタックの下部に達しています C. 2 つのスタックの上部が同時にスタック スペースの中心点に到達する
-
スタックがシーケンシャル ストレージに格納されている場合、2 つのスタックはスペースを共有します。V[1,...,m]、top[1]、top[2] はそれぞれ 1 番目と 2 番目のスタックの上部を表します。 1 の底部は V[1] にあり、スタック 2 の底部は V[m] にあります。スタックがいっぱいになる条件は (B
< a i=2>)。 A. ∣ | ∣トップ[2]-トップ[1] ∣ | ∣ = 0
B.top[1]+1 = top[2](共享栈栈满的定义)
C.top[1]+top[2] = m
D.top[1] = top[2]
パート 3: チェーンスタック
1. チェーンスタックの定義
上記のスタックと共有スタックはすべて、シーケンシャル ストレージを使用して実装されています。スタックが実装されている場合チェーンストレージによるものをチェーンスタックと呼びます。
実際、リンク リストによって実装されたスタックは、リンクされたリストに 「後入れ先出し」 制約を課します。リストの構造は一般的なリストと同じであり、リンクされたリストもまったく同じです。

2. チェーンスタックの操作
前の順次スタックでは、top は配列の添字を参照しますが、チェーン スタックでは、top はポインタを参照することに注意してください。
- スタックが空です: トップ = null;
- スタックがいっぱい: 存在しません!
- スタックへのプッシュ: (実際にはリンク リストの先頭挿入メソッド)
① p->next = top; a>
② トップ = p; - 出栈:
① e = トップ->データ;(p = トップ;)
② トップ = トップ->次; (無料(p);)
パート 3 演習
-
最上位ポインタが top であるリンク スタックに x ノードを挿入し、実行します (C)。
A.top->next=x
B.x->next=top->next; top->next=x
C.x->next=top;top=x
D.x->next=top;top=top->next -
リンク リストがスタックのストレージ構造として使用される場合、スタック操作中 (D)。
A. スタックがいっぱいかどうかを判断する必要があります。 (物理的なストレージ容量が著しく不足しない限り、チェーン スタックはいっぱいになりません。プッシュ操作中にスタックがいっぱいです。判定)
B. スタックに対して判定を行わない (判定を行わないことは十分に堅牢ではありません) D. スタックが空かどうかを判断する必要がある (意味不明)
C. スタック要素の種類を判断する
第 1 部から第 3 部までのまとめ
1. シーケンススタックとチェーンスタックの比較
(1) 時間性能の比較
シーケンシャルスタックとチェーンスタックの基本演算アルゴリズムの時間計算量はO(1) スタックがいっぱいになる問題はありません。スタックがいっぱいになるのは、メモリに空き領域がない場合のみですが、各要素にはポインタ フィールドが必要です。結果として構造的なオーバーヘッドが発生します。 チェーン スタック は固定値を決定する必要があります。そのため、保存する要素の数に制限があり、無駄なスペースが発生するという問題があります。 シーケンス スタック 最初に
(2) スペース パフォーマンスの比較。
- 一般的な結論: スタックの要素数が使用中に大きく変化する場合(つまり、固定長を決定することが困難な場合) )、チェーン スタックを使用することをお勧めします。それ以外の場合は、順次スタックを使用する必要があります。
- 典型的な例: シーケンシャル スタックと比較すると、チェーン スタックには明らかな利点があります (A)。
A. 通常、スタックはいっぱいではありません。
B. スタックは通常、空です。
C. 挿入 操作は次のとおりです。実装が簡単
D. 削除操作の実装が簡単
2. スタックの適用
- スタックの適用: 主にブラケット マッチング、式の評価、再帰プレフィックス式 および サフィックス式。
- 典型的な例: 中置式 A − ( B + C / D ) ∗ E A-(B+C/D)*E あ−(B+C/D)∗E的后缀形式是(D)。
A. A B − C + D / E ∗ AB-C+D/E* AB−C+D/E∗
B. A B C + D / − E ∗ ABC+D/-E* ABC+D/−E∗
C. A B C D / E ∗ + − ABCD/E*+- あ>ABCD/E∗+−
D. A B C D / + E ∗ − ABCD/+E*- ABCD/+そして∗−
[分析]中置式は、式の途中にある一般的な演算記号です。 a> の算術式、さらに難しいのは、それを 接頭辞式 と 、つまり、 演算子記号が式の前端または後端にある算術式: a>
① 括弧を追加: 演算子の優先順位に従って各演算を括弧で囲みます。元の括弧>乗算と除算>加算、つまり減算です。 、 ( A − ( ( B + ( C / D ) ) ∗ E ) ) (A-((B+(C/D))*E)) となります。あ>(A−((B+(C/D))∗E));
② 移符号:将运算符移到括号前或括号后,即继续变为: − ( A ∗ ( + ( B / ( C D ) ) E ) ) -(A*(+(B/(CD))E)) −(A∗(+(B/(CD))E))或 ( A ( ( B ( C D ) / ) + E ) ∗ ) − (A((B(CD)/)+E)*)- (A((B()/)DC+E)∗)−;
③ 去括号:把括号去除得到前缀表达式: − A ∗ + B / C D E -A*+B/CDE −A∗+B/CDE,或后缀表达式: A B C D / + E ∗ − ABCD/+E*- ABCD/+そして∗−。
3. スタック適用に関する演習
-
再帰的アルゴリズムを対応する非再帰的アルゴリズムに変更する場合、通常は (A) (通常はスタックが使用されますが、他の方法も使用できます) B. キュー C. 循環キュー D. 優先キュー
-
算術式 A + B ∗ C − D / E A+B*C-D/E あ+B∗C−D/E转为前缀表达式后为(D) 。
A. − A + B ∗ C / D E -A+B*C/DE −A+B∗C/DE
B. − A + B ∗ C D / E -A+B*CD/E −A+B∗CD/E
C. − + ∗ A B C / D E -+*ABC/DE −+∗ABC/D E
D. − + A ∗ B C / D E -+A*BC/DE −+あ∗BC/DE
【分析】① < /span> ( ( A + ( B ∗ C ) ) − ( D / E ) ) ((A+(B*C))-(D/E)) ((A+(B∗C))−(D/E)) − ( + ( A ∗ ( B C ) ) / ( D E ) ) -(+(A*(BC))/(DE)) ;② −(+(A∗(BC))/( − + A ∗ B C / D E -+A*BC/DE ;③ ))ED−+あ∗BC/DE; -
中缀表达式 A ∗ ( B + C ) / ( D − E + F ) A*(B+C)/(D-E+F) あ∗(B+C)/(D−そして+F)的后缀表达式是(C) 。
A. A ∗ B + C / D − E + F A*B+C/D-E+F あ∗B+C/D−そして+F
B. A B + C + D / E − F + AB+C+D/E-F+ AB+C+D/E−F+
C. A B C + ∗ D E − F + / ABC+*DE-F+/ ABC+∗DE−F+/
D. A B C D E F ∗ + / − + ABCDEF*+/-+ ABCDEF∗+/−+
【分析】① ( ( A ∗ ( B + C ) ) / ( ( D − E ) + F ) ) ( (A*(B+C))/((D-E)+F)) ((A∗(B+C))/((D−E)+F));② ( ( A ( B C ) + ) ∗ ( ( D E ) − F ) + ) / ((A(BC)+)*((DE)-F)+)/ ((A(BC))+∗((DE)−F)+)/;③ A B C + ∗ D E − F + / ABC+*DE-F+/ ABC+∗DE−F+/;
パート 4: キュー
1. キューの定義
では、テーブルの一端での挿入とテーブルの他端での削除のみが許可されます。 4 つの単語: 「先入れ先出し」
要素をキューに挿入することを エンキュー<と呼びます。 a i=4>、キューから要素を削除することをデキューと呼びます。
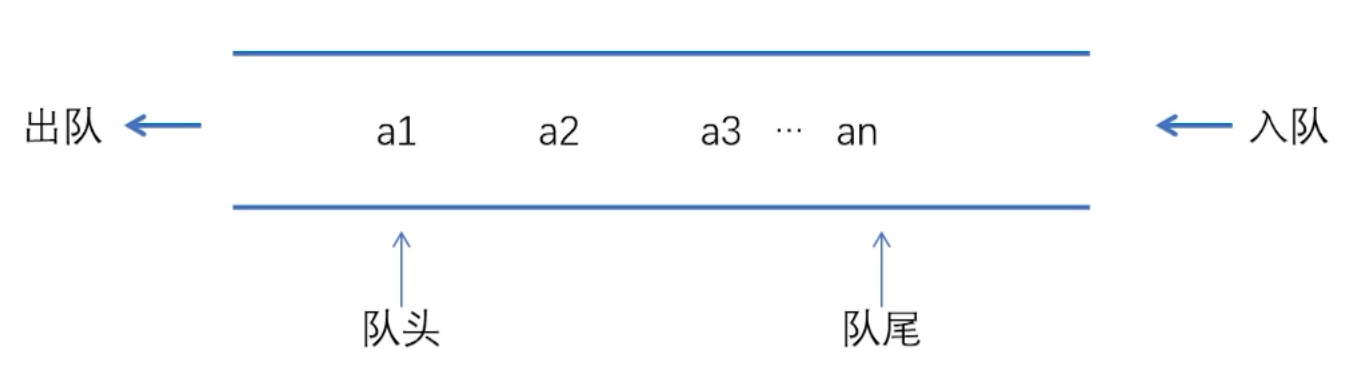
[注] 単純なキューには、 false オーバーフロー または false full< が発生する場合があります。 /span> a> 問題、つまり、満杯のキューの先頭要素がキューから取り出されるとき、先頭ポインタの前に空きがあるにもかかわらず、エントリは最後尾からでなければなりません。最後にキューを戻すことはできず(キューがいっぱいであると判断され)、キューに参加できなくなります。
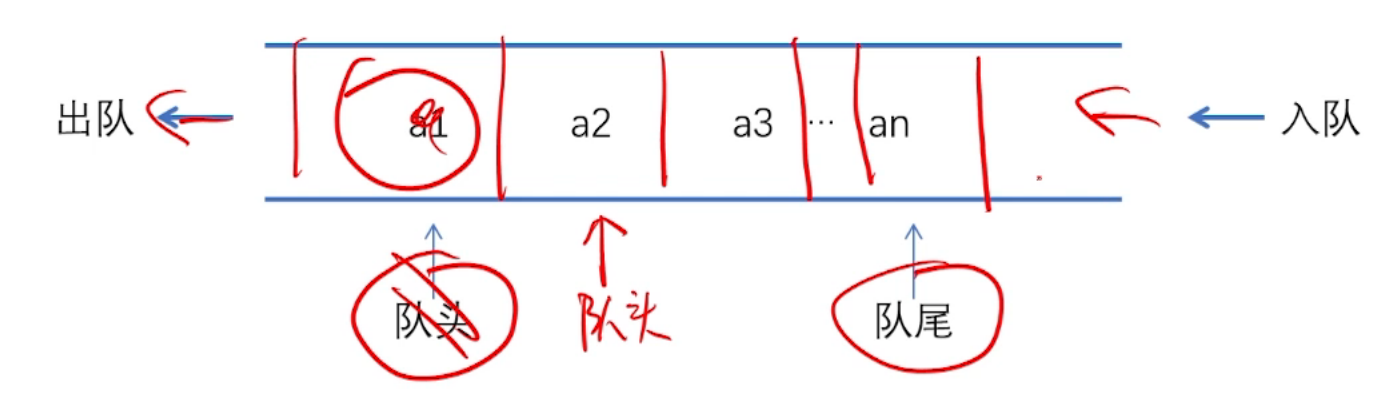
2. 循環キュー
偽のオーバーフローや偽のフルの問題を解決するために、通常、シーケンシャル キューは循環キューで構成されます。循環キューはキューの先頭と末尾を接続します。もちろん、これは単なる論理構造ですが、 =5>シーケンシャルストレージの実装方法は、キュー末尾ポインタがキューの最大位置に達したときに、前進するとキューの開始位置に戻るというものです。
3. 循環キューの運用
| 空队状态 | 入队操作 | チーム全体ステータス | 出队操作 |
|---|---|---|---|
 |
 |
 |
 |
| フロント=リア | ① キュー[リア] = A; ② リア = (リア+1)%Maxsize; |
(リア+1)%最大サイズ = フロント | ① e = キュー[フロント]; ② フロント = (フロント+1)%Maxsize; |
- 上記の操作では、Maxsize の残りは、キューの最後に達したときにキューの先頭に +1 を返すために使用されます。
パート 4 演習
-
循環キューの要素が配列 A[m] に格納されており、その先頭ポインタと末尾ポインタがそれぞれ前と後であると仮定すると、現在のキューの要素の数は ( A[分析] リアがフロントを超えることはできないので、2 つの最大の差は次のとおりです。 m; 2 つの差に m を加算します。差が正の場合、剰余演算により加算された m が削除されます。差が負の場合、剰余演算は有効になりません。この式は D.(rear-front)%m C.(前- Rear+m)%m B.後-前+1
A.(後-前+m)%m)。
(m+rear)−front。 -
スタック S とキュー Q の初期状態が空であると仮定します。要素 a、b、c、d、e、f は順番にスタック S を通過します。1 つの要素がスタックからポップされた後、要素はキュー Q に入ります。6 つの要素がキューから取り出される場合、シーケンスが a、c、f、e、d、b である場合、スタック S の容量は少なくとも (C< /span> D.3[分析] スタックに b、d、e、f が最も多く含まれる場合 C.4 B.5
A.6)。
-
サイズ 6 の配列を使用して循環キューを実装し、リアとフロントの現在の値がそれぞれ 0 と 3 である場合、キューから要素が削除され、さらに 2 つの要素が追加されると、リアとフロントの値 値は (B) です。
A.1 および 5
B.2 および 4
C.4 および 2
D.5 および 1
パート 5: デク
1. 両端キューの定義
両端がエンキュー操作とデキュー操作を実行できるキューを指します (両端は制限されていません)。
- 出力制限された両端キュー: 一方の端では挿入と削除が許可されますが、もう一方の端では挿入のみが許可されます。 は、出力制限された両端キューと呼ばれます。
- 入力制限された両端子: 一方の端では挿入と削除が許可されますが、もう一方の端では削除のみが許可されます。 は入力制限された両端キューと呼ばれます。
2. 両端キューの動作
通常のキューと同様に、両端を制限なくキューに入れたり、キューから取り出したりできます。
- 両端がキューに入れられた場合、最初にキューに入れられた要素は両端のキューの中央に囲まれることに注意してください。このとき、キューは特定の端からデキューされ、出口端の入口部分「後入れ先出し」になります。 。入口端でキューに入る部分は「先入れ先出し」です。 (出力制限あり)
- 同様に、一方の端からのみキューに入り、両端からデキューする場合、入口側でキューから出る部分になります 「後入れ先出し」、キューの出口端で出る部分は「先入れ先出し」 >。 (入力制限あり)
[古典的な例] 両端キューの入力系列として 1234 を使用した場合、入力限定両端キューでも出力限定両端キューでも取得できない出力系列は (B) です。
A.4213
B.4231
C.4132
D.1234

パート 6: チェーン チーム
1. チェーンチームの定義
は実際には、先頭ポインタと末尾ポインタの両方を持つ単一リンク リストです。これは、リンク リストに 「先入れ先出し」 を適用することと同じです< a i=2> 制約。
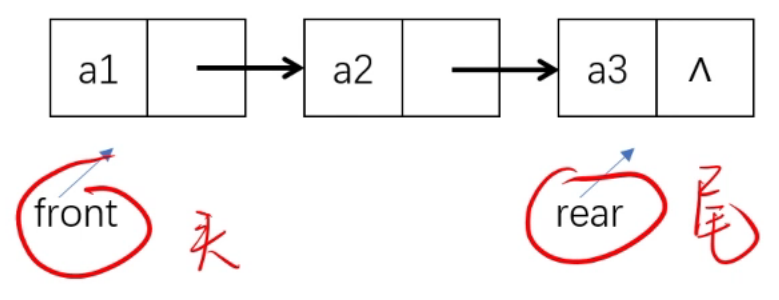
2. チェーンチームの運営
前の順次ストレージ キューでは、フロントとリアが配列添字を参照しますが、チェーン キューでは両方ともポインタであることに注意してください。
- 空队:前 = null; 後 = null;
- チーム全員:そんなものは存在しません!
- キューに入る: (実際にはリンク リストの末尾挿入方法)
① Rear->next = p;
② 後 = 後->次; - 出队:
① e = フロント->データ;(p = フロント;)
② フロント = フロント->次; (無料(p);)
パート 6 演習
-
単一リンク リストを使用してキューを表す場合は、(B) を使用する必要があります。
A. 末尾ポインタを持つ非巡回リンク リスト (デキュー操作を実装するためにキューの先頭に戻るのは時間がかかりすぎる ×) (キューの最後まで行ってキューに参加するのは時間がかかりすぎる ×) D. ヘッド ポインタを持つ循環リンク リスト (二重循環リンク リスト × でない限り、同様にノードを 1 つずつキューの最後に移動する必要があります) -
「先頭ノードのチェーンキューが空である」と判断する条件は(A)である。
A.Q.front == NULL (ヘッド ポインタはデキューに使用され、通常はチームのヘッド要素を指します)
B.Q.rear == NULL (末尾ポインタはキューに入れるために使用され、元々は null を指します)
D.Q.front == Q.rear< a i=8> (おそらく 1 つのノードが含まれます) D.Q.front != Q.rear
第 4 部から第 6 部までのまとめ
1. 循環キューとチェーンキューの比較
(1) 時間パフォーマンスの比較
循環キューとチェーン キューの基本操作のアルゴリズムはどちらも一定の時間を必要としますO(1)、
- 循環キュースペースは事前に申請され、使用中に解放されることはありません。
- 連鎖キューノードの申請と解放を行うたびに、ある程度の時間オーバーヘッドが発生します。
頻繁に出入りする場合、両者の間にはまだ若干の違いがあります - 最良の選択循環キューを使用すると、ノードの申請と解放にかかる時間のオーバーヘッドを節約できます。
(2) スペース性能の比較
循環キューは固定長(シーケンシャルストレージ)である必要があるため、ストレージ要素の数と無駄なスペースが問題になります。
2. アプリケーションをキューに入れる
- キューの用途: 主に階層トラバーサルに使用されますが、コンピュータ システムでキューを使用して問題を解決することもできます。ホストと外部デバイス間の速度の不一致<複数のユーザーによって引き起こされる a i=2 >問題とリソース競合問題。
- 典型的な例: コンピュータ ホストとプリンタの間の速度の不一致の問題を解決する場合、通常は印刷データ バッファが設定され、ホストが出力するデータをバッファに順番に書き込みます。プリンタがバッファからデータを読み出し、データを取り出して印刷します。バッファは (B) 構造である必要があります。
A. スタック
B. キュー
C. 配列
D. 線形テーブル< /span>
スタックとキューの概要
- スタックはデータ構造の大部分を占め、キューはオペレーティング システムの大部分を占めます。
