

著者 | 武南
導入
ログ センターによって毎日送信されるログ PV レベルは、数千億に達する場合があります。レポート プロセス中に冗長なログ データを削減できるため、下流のデータ処理の困難さとコストが軽減され、データの精度と品質が向上し、サポートが向上します。業務システムの運用と最適化。この記事では、ログ重複パッケージ化のための UBC SDK の最適化実践を紹介しますデータベース、プロセス、管理メカニズムを最適化することで、ログ レベルの重複率を 3,000 分の 1 から 10,000 分の 1 に効果的に削減します。
全文は 8525 ワード、推定読了時間は 22 分です。
01 はじめに
この記事では、まずログ プラットフォームの重複排除の背景と UBC SDK の管理メカニズムを紹介し、次に重複問題を特定する難しさと方法を説明し、最後に重複問題の分析と解決策の実践に焦点を当てます。
1.1 ログ重複排除の背景
ログセンターは、データの完全なライフサイクル管理を実現し、次のような問題を解決するために、ログデータの収集、送信、管理、クエリと分析などの機能を含む、エンドログのライフサイクル全体の能力構築に焦点を当てています。ログの標準化と新旧製品の統合を行い、プラットフォームのリソース使用率を向上させてログのアプリケーション価値を最大化します。
下流側でデータを効率的かつ正確に受信できるようにするために、ログ センターはエンドツーエンドのデータ送信の適時性と信頼性に関して長期的な最適化を実施し、顕著な成果を上げてきましたが、これらの最適化によって問題も徐々に浮き彫りになってきました。データ重複の可能性があります。
重複した問題とは、同じログが SDK によってサーバーに複数回報告されることを意味します。サーバーの QPS を削減するために、SDK は複数のログをパッケージ化してレポートするため、繰り返される問題は 2 つのカテゴリに分類できます。
1. パッケージの重複: SDK はデータを送信しましたが、結果を受信しませんでした。サーバーはディスク上に配置されましたが、末端のパッケージは削除されていませんでした。パッケージ内のログ全体が繰り返し報告されます。
2. ログの複製: 単一のログが複数のパッケージに入力され、各パッケージとともにサーバーに報告されます。
ログ センター サーバーは、ダウンストリーム データにパケットの詳細な重複がないことを保証するストリーミング重複排除ソリューションを開始しました。サーバーは md5 パッケージを通じて重複排除を実行しますが、同じログが異なるパッケージに入力されると異なる md5 が生成され、この場合サーバーはそれを識別できません。したがって、サーバー側の重複排除の前提条件は、レポートされたログが繰り返しパッケージ化されないことを SDK が保証することです。
1.2 UBC SDK の概要
UBC (User Behavior Collection) SDK、つまりユーザー行動収集 SDK は、端末管理ログの収集、パッケージ化、レポート作成などの機能を担当し、ユーザー行動データを記録し、ログ センター サーバーにアップロードします。ログセンターのデータ送信リンクのソース。
1.2.1 ドットの種類
管理が表現する内容に応じてイベント管理とフロー管理に分けられ、それぞれ単独行動と滞在行動を記録します。
ポイント レポートの適時性に対する要件はビジネス パーティごとに異なります。遅いものから速いものまで、非リアルタイム レポート、リアルタイム レポート、直接レポート、リアルログ レポートに分類できます。実行プロセスには違いがあります。さまざまな種類のレポート。
1.2.2 管理メカニズム
UBC SDK は、工場内のほとんどのデータの記録と送信を行います。両端で 1 日に数千億のログが報告される可能性があります。メイン スレッドの実行に影響を与えることなく、迅速かつ正確に報告される必要があります。この目標を達成するために、UBC は次の措置を講じました。
1. 段階的な非同期処理: レポートの効率と安定性を確保するために、SDK は内部でプロセス全体を複数のステージに分割し、それらをタスク スレッドと送信スレッドに渡して非同期のスケジューリングと実行を行います。
2. ログとパッケージの永続的ストレージ: ログが失われないようにするために、SDK はログを SQLite に永続化し、送信時にログをファイルに永続化し、成功するまで繰り返し送信を試行します。
3. 複数のレポート トリガー タイミング: レポートのスループットと適時性を考慮するために、SDK は、リアルタイム管理が発生したときにすぐにトリガーする、非リアルタイム管理がレポートに達したときにトリガーするなど、さまざまなタイミングでログ レポートをトリガーします。期間、フロントエンドとバックエンド間の切り替え、またはネットワークが回復したときのバックログ データのレポートなど。
UBC SDK コア モジュールのアーキテクチャを次の図に示します。
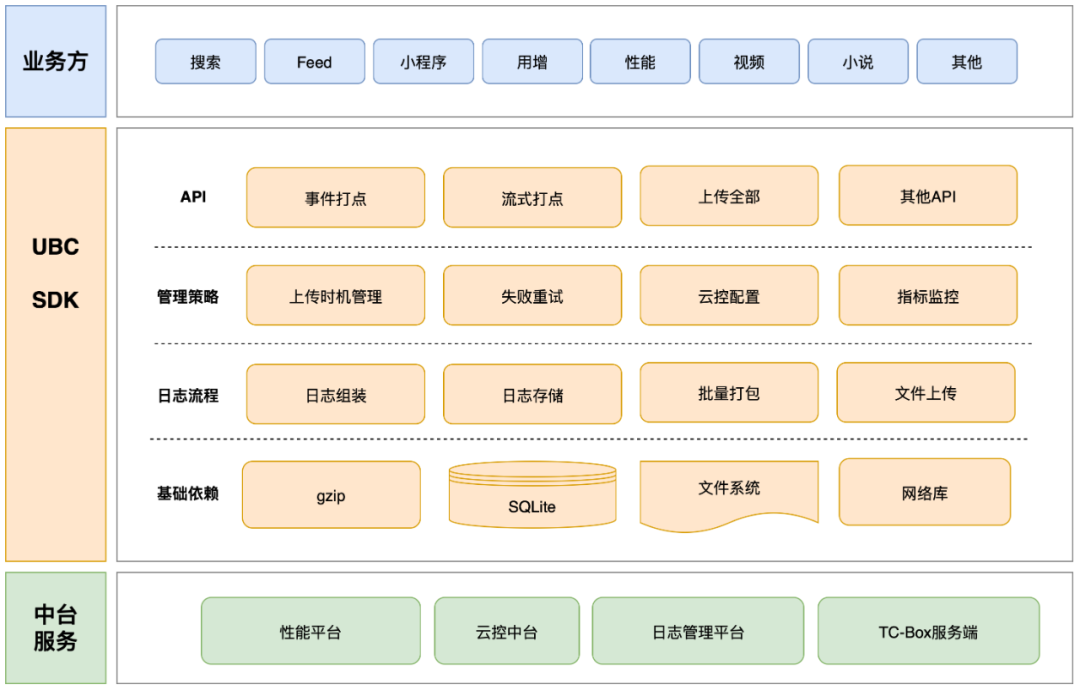
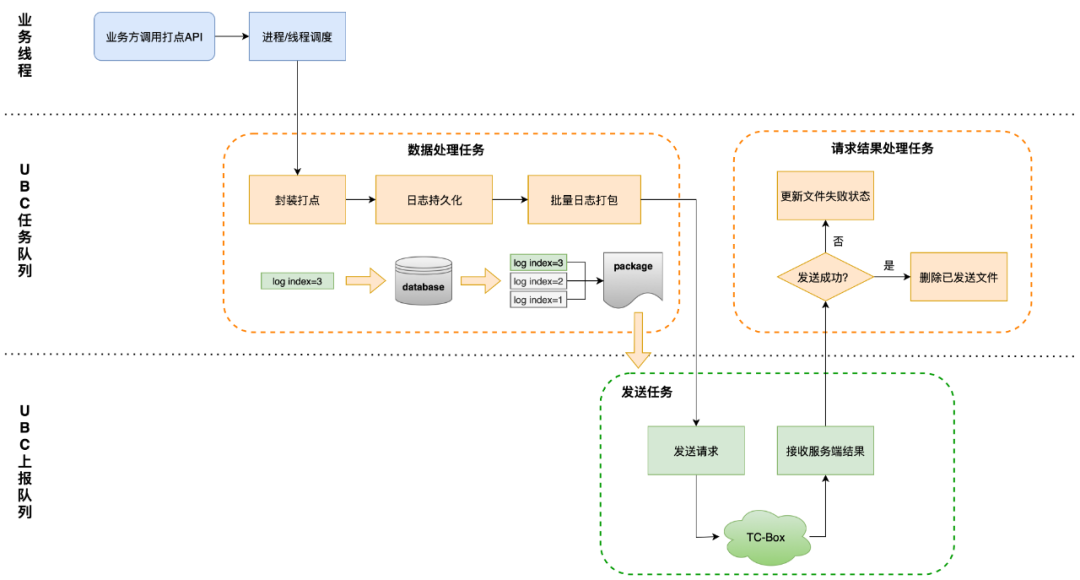
UBC ログの管理、保存、送信の基本プロセスを次の図に示します。
02 位置決め手段
2.1 位置付けの難しさと方法論
エンドサイドのログ重複の問題のトラブルシューティングには次のような問題があります。
1. UBC を利用する取引先は多数あり、トリガーのシナリオもその時点で異なり、発生する問題も異なり、すべてのサービスの呼び出し方法を理解することは不可能です。
2. ログの重複は、ほとんどの場合、ユーザーのローカル環境、システムのバージョン、製造元に密接に関係する低確率の潜在的な異常イベントによって引き起こされ、問題を再現するのは困難です。
3. UBC SDK はデータの入り口であり、システム全体に影響を与えるため、レポート プロセスに変更を加えると、既存のデータに変動が生じ、ビジネス統計に影響を与える可能性があります。
したがって、この種の問題は、一般的な手段でトラブルシューティングや最適化することが困難であり、UBC は、次のような処理の過程で一連の方法論を徐々に形成してきました。
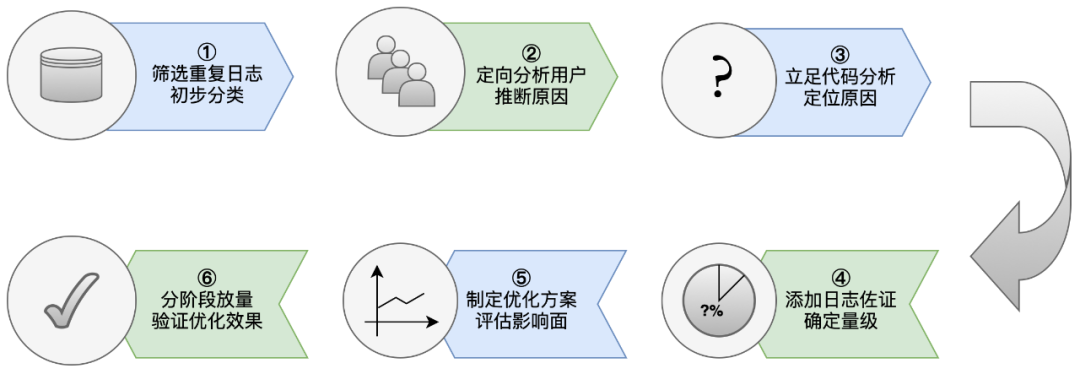
2.2 位置決めツール
2.2.1 オンラインログの識別
オンライン ログは、重複率などの指標を監視する最も直接的な方法ですが、数千億のデータの中から重複してパッケージ化されたログを見つけるのは、干し草の山から針を見つけるようなものです。
したがって、重複した問題を特定するときは、さまざまな種類のフラグが重要であり、これらを使用して、さまざまなログ エントリを識別して関連付けることができ、どの問題が重複しているかを判断するのに役立ちます。データ統計とアラーム監視を通じて、T+1 時間制限内で問題を発見でき、統計に含まれる生データを通じて問題を直接分析できます。
重複したログを見つけるには、まずログを一意に識別する必要があります。
ログ uuid : UUID (Universally Unique Identifier) は、オブジェクトまたはイベントがグローバルに一意に識別されることを保証できる 128 ビット文字列です。つまり、ロギングと追跡のために同じデバイス上でログを一意に識別できます。変更により既存のデータに変動が生じ、ビジネス統計に影響を与える可能性があります。
TC-Box に繰り返し報告されるログは、ログ uuid で確認できますが、重複パッケージか重複ログかを判断するには、パッケージ情報に基づいて判断する必要があります。パッケージの識別情報は主に 2 つあります。 :
1. パッケージ md5 : MD5 (メッセージ ダイジェスト アルゴリズム 5) は、任意の長さのデータを受信して固定長のハッシュ値を生成できる、広く使用されている暗号化ハッシュ関数です。UBC は、パッケージの内容をパッケージ識別子として使用して md5 値を計算します。
2. Package createtime : ミリ秒レベルのパッケージ化タイムスタンプ。パッケージ内容が同じであれば md5 の値は同じであるため、同じバッチのデータを複数回パッケージ化すると md5 で識別できないため、繰り返しパッケージ化する場合の識別識別子として md5+createtime を使用する必要があります。
識別情報に加えて、判断を支援するために次のような他の情報も必要です。
1. timestamp : 管理時のタイムスタンプ。管理前後の繰り返しログと組み合わせてユーザーの操作を推測できます。
2.appv : 管理時のアプリのバージョン番号 最適化効果を評価する際には、古いバージョンの報告遅延による影響を軽減する必要があります。
3.process : パッケージ化されたプロセスIDとプロセス名を実行します UBCインスタンス内に複数のプロセスが同時に存在する場合、プロセスの安全性の確保により重複が発生する可能性があります。
4.trigger : トリガー タイミングのパッケージ化。通常の状況では、レポート タイミングの頻度は異なります。レポート タイミングの異常な頻度は、問題の特定にも役立ちます。
5.db_sync : SQLite 同期モード。ユーザー データベース ライトバック メソッドによって引き起こされる例外の検証を支援するために使用できます。
2.2.2 異常監視
UBC の実行中にはさまざまな異常が発生する可能性があり、これらの異常をタイムリーに検出するには、レポートと管理を通じて UBC を監視する必要があります。
さまざまな種類の異常の監視と管理には、特別なリンク、例外スタック、その他のコンテンツの実行ステータスが含まれており、繰り返される問題のトラブルシューティング、例外規模の統計、修復効果の分析に役立ちます。
UBC の通常のプロセスが実行できなくなる異常な状況を回避するために、監視は UBC ストレージをバイパスし、バイパスを通じて保存およびレポートを実行します。
2.2.3 経営管理
UBCはサービス層のSDKとして業務から切り離されているため、SDK自体の動作を監視することしかできず、ユーザーの操作経路やデバイス情報を直接取得することはできません。
ビジネス側の管理は、ユーザー操作のさまざまなシナリオで発生し、ユーザーの行動を復元するのに役立ちます。たとえば、関連するポイントを手動でアクティブ化することでユーザーのフロントエンドとバックエンドの切り替えとコールド スタートの動作を判断したり、スプラッシュ スクリーンを通じてポイントを表示したり、ユーザーの電源を取得してユーザーのデバイスの電源がオフになっているかどうかを判断したりできます。再起動、その他のポイントを介してネットワークの各種状態やディスクなどの情報を記録します。
03 繰り返される問題の原因特定と解決
3.1 データベース関連の問題
管理実行プロセスに基づいて、単一ログの繰り返しパッケージ化の問題をトラブルシューティングするには、最初に思いつくのは、バッチ ログ パッケージ化段階のトラブルシューティングです。

このリンクには多くの論理分岐があり、リアルタイムと非リアルタイムの管理実行戦略は異なります。
-
非リアルタイム RBI がトリガーされた後、最初にキャッシュが書き込まれ、次にデータベースが書き込まれます。レポート時間に達すると、データベースがバッチでクエリされ、レポートがトリガーされます。
-
リアルタイム管理は、レポートをトリガーするために最初にファイルに書き込まれます。ファイルの書き込みに失敗した場合は、データベースに書き込まれます。ファイルの書き込み時に、データベースにクエリが実行され、非リアルタイムのバッチが追加されます。管理。
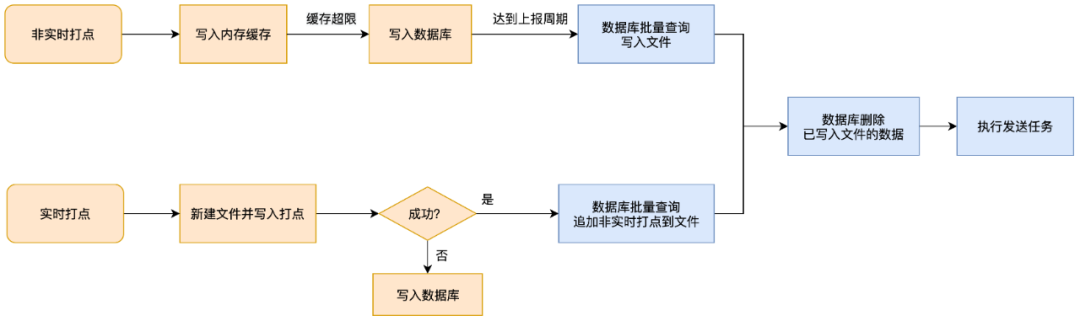
繰り返しデータの初期分析では、リアルタイム管理ポイントはほとんどなく、そのほとんどはデータベースに保存する必要がある非リアルタイム管理とストリーミング管理でした。したがって、重複問題のトラブルシューティングの最初の段階では、データベース関連の問題のトラブルシューティングに重点を置きました。
パッケージング処理とは「データベースからログを一括してファイルに転送する」処理で、青枠で示した手順の詳細は下図のとおりです。
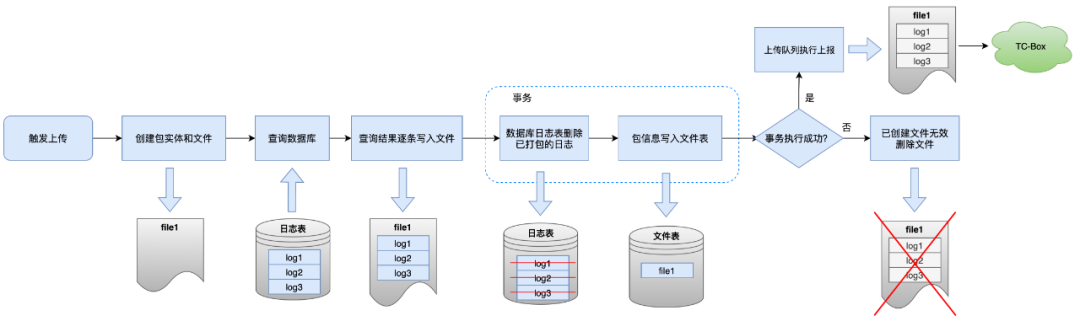
通常の状況では、ファイルの書き込み後にデータベース内のパッケージ化されたログの削除に失敗した場合、SDK はレポート プロセスを終了して生成されたファイルを削除し、パッケージ化の繰り返しを避けるために送信プロセスを中断します。
このリンクの本来の目的は、レポート時にデータベースを直接読み取ることによって引き起こされる繰り返し送信の問題を解決することですが、プロセス中に SDK が認識しない例外が発生した場合、現在のファイルが直接送信されることになります。このログのバッチは次のとおりです。初めて報告されると、再度クエリとパッケージ化が行われるため、重複が発生します。
3.1.1 データベースの破損
セクション 2.1 で述べた問題特定方法論に従って、重複ユーザーをデータの特性に従って分類し、重複の原因を 1 つずつ特定し、大部分の重複問題をデータベース破損として特定します。
(1)問題の帰属
データの特性
-
ユーザーが 1 日に報告する PV は膨大で、深刻なケースでは数百万件に達します (1 人のユーザーが 1 日に報告する平均 PV 数は約 2,000)。
-
ユーザーによって報告されるログのほとんどは重複ログであり、同じログが複数回パッケージ化されます。
-
複数のパッケージングの間隔は非常に短く、コールド スタートは発生しません。
-
ほとんどの重複パッケージの md5 は同じですが、createtime が異なり、トリガー条件は項目数が制限を超えることです。
理由の推測
パッケージ化されたログ トランザクションを削除すると成功結果が返されて報告されますが、実際の削除結果は失敗です。
さらなる分析
私たちは報告されたデータを削除するためのコードをレビューし、最初に影響を与えるいくつかの要因を除外しました。
-
他のスレッドの影響を排除するために、ロジック全体に同期ロックが追加されます。
-
SQL 実行例外が捕捉され、失敗が返され、現在のファイルは削除され、レポートされません。
-
delete メソッドによって削除されたアイテムの数が予想どおりにならない状況を監視しましたが、問題の規模は小さく、繰り返し率への影響はほとんどありませんでした。
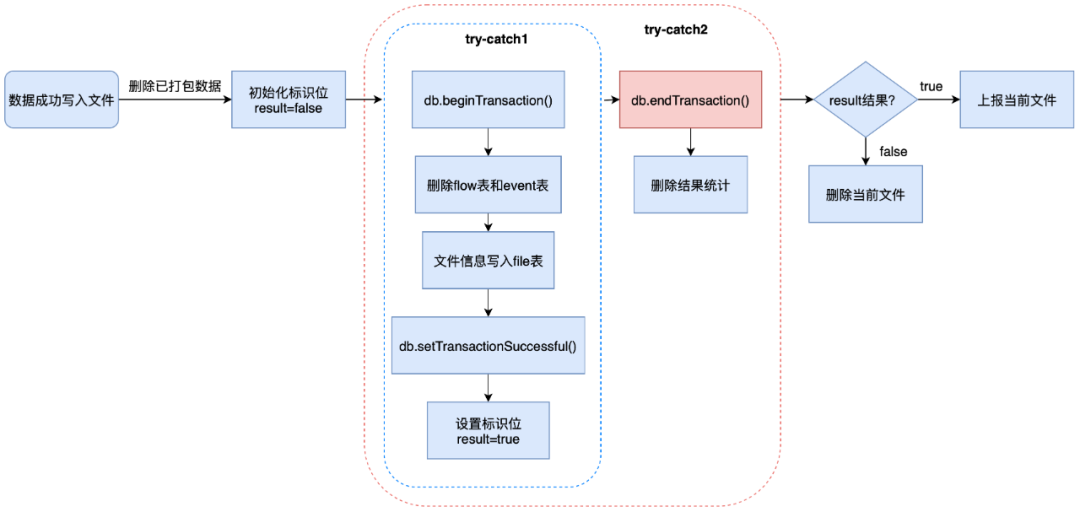
コード内の try-catch の 2 つの層をさらに分析すると、次の問題が明らかになりました。
-
内層の try-catch: 複数の SQL を実行し、成功後にトランザクション成功フラグを設定し、結果フラグを true に設定します。
-
外層の try-catch: トランザクションを送信し、削除結果をカウントします。
外層に入るとき、フラグ ビットは true に設定されていますが、送信されたトランザクションの結果は処理されていません。このリンクでハンドルされない例外が発生し、トランザクションがロールバックされたものと推測されます。
帰属をサポートする
-
例外の原因を特定するために、SQL 例外監視が改良され、DatabaseHelper クラスでキャプチャされたすべての例外スタックが記録されます。
-
重複ユーザーの異常監視データを取得したところ、大量のSQL例外が発生していることが判明しました。スタックは次のとおりです。db.endTransaction 中にデータベース破損例外 SQLiteDatabaseCorruptException が発生しました。これは、コード分析結果を裏付けます。
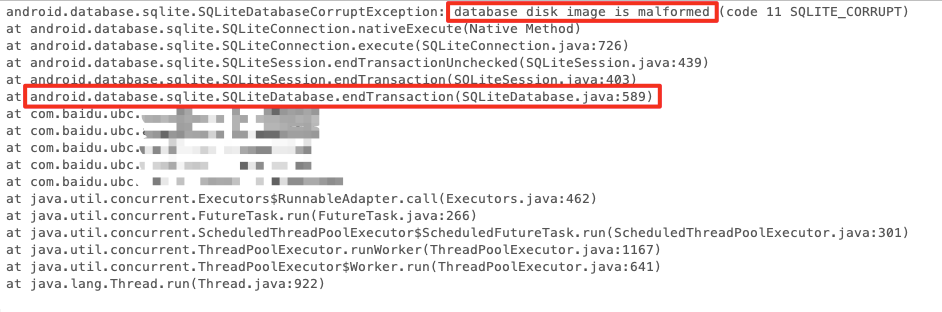
クラッシュスタック
-
SQLite の公式 Web サイトでは、データベースの損傷の問題についても説明しています。ファイルの fsync の失敗、ディスクの損傷、異常なデータ書き込み、およびデータベースの読み取りおよび書き込みプロセス中のその他の問題により、データベースが損傷する可能性があります。

最終的な帰属
-
データベースが破損すると、ログの一部が読み取り可能でも書き込み不可になる場合があります。
-
トランザクションがコミットされる前にデータ削除の実行結果が更新され、成功結果に応じてレポートが処理されましたが、データベースの破損によりトランザクションがロールバックされ、データが正常に削除されませんでした。
-
各アップロードが成功すると、データベース エントリの数がチェックされます。しきい値を超えた場合、アップロードが再度トリガーされます。単一のパッケージが制限を超えると書き込みが停止するため、短期間に大量のレポートが生成されます。パッケージの同じ md5 での時間。
(2)最適化計画
この問題に対処するには、両端で 2 段階の最適化が必要です。
1. トランザクションの送信中に例外が発生した場合は、データベース トランザクションの実行結果を修正し、結果をリセットします。
2. データベースが破損した場合は、データベースを再構築します。データベース ファイルとそれに添付されている -journal、-shm、-wal ファイルを削除します。データベースを再度開くと、データベース ファイルが再作成されます。
リスクアセスメント
1. UBC はレポートの適時性が高く、ほとんどのデータは 1 分以内にレポートされ、データベースから消去されます。そのため、通常、データベースに保持されるデータは少数のみです。失われたデータの直接削除は許容範囲内です。
2. ファイルの削除と再構築の操作は頻繁に実行しないでください。データベースの修復の頻度を制限し、修復操作とその結果ごとに統計を収集する必要があります。
3. データベース再構築のリスクが比較的高いため、AB 実験的対象分散手法を使用して、効果があり、他に影響がないことを確認してから、徐々に量を増やします。
最適化効果
1. 実験の初期段階で、実験用スイッチは多数の繰り返しレポートを持つユーザーに向けられましたが、すべて正常に修復され、修復後に繰り返し率は 0 に戻りました。
2. 実験が完全に展開された後、監視統計によると、毎日 40 件以上のデータベース損傷が正常に修復され、多数の問題が繰り返されることはなくなります。
3. データベース破損問題を最適化した後、市場の重複率は約 0.07 パーセントポイント減少して 1,000 分の 2 未満に低下し、最適化前のレベルの約 35% を占めました。
3.1.2 WALファイルの書き込み失敗
(1)問題の帰属
データの特性
-
重複するユーザーがいる場合、パッケージのバッチは 2 回パッケージ化されます。
-
2梱包ではコールドスタートがあり、間隔が長いです。
-
最後のパッケージはコールド スタート後の最初のパッケージであり、パッケージ化のトリガー条件はリアルタイム レポートまたはネットワーク回復レポートです。
理由の推測
ユーザーのデバイスでのシステムレベルのクラッシュにより、データベース操作は成功しましたが、ライトバックは失敗しました。
さらなる分析
-
Android 9.0 以降、SQLite の WAL (Write-Ahead Logging) モードがデフォルトで有効になっています。WAL モードでは、SQLite は変更操作を WAL ファイルに記録します。システムがアイドル状態であるか、トランザクションがコミットされているとき、チェックポイント操作が実行され、WAL ファイルがディスク上のデータベース ファイルに書き戻されます。 。SQLite はこのメカニズムを使用して、頻繁なディスク書き込み操作を回避し、データベースの書き込みパフォーマンスと同時実行性を向上させます。
-
変更操作が WAL ファイルに書き込まれ、WAL ファイルがデータベース ファイルに書き戻されるとき、最初にディスク バッファーに書き込まれ、次に fsync 操作を実行してディスクにフラッシュするプロセスが実行されます。システム例外後にトランザクションを回復できるかどうかの鍵は、WAL ファイルが fsync を正常に実行するかどうかにあります。
-
PRAGMA schema.synchronous = NORMAL | FULL. 2 つの主な違いは、NORMAL は WAL ファイルの書き込み時に fsync が実行される前にコミット結果を返すのに対し、FULL モードは実際にコミット結果を書き込むことです。 WAL ファイルをディスクにコピーし、結果は後で返されます。
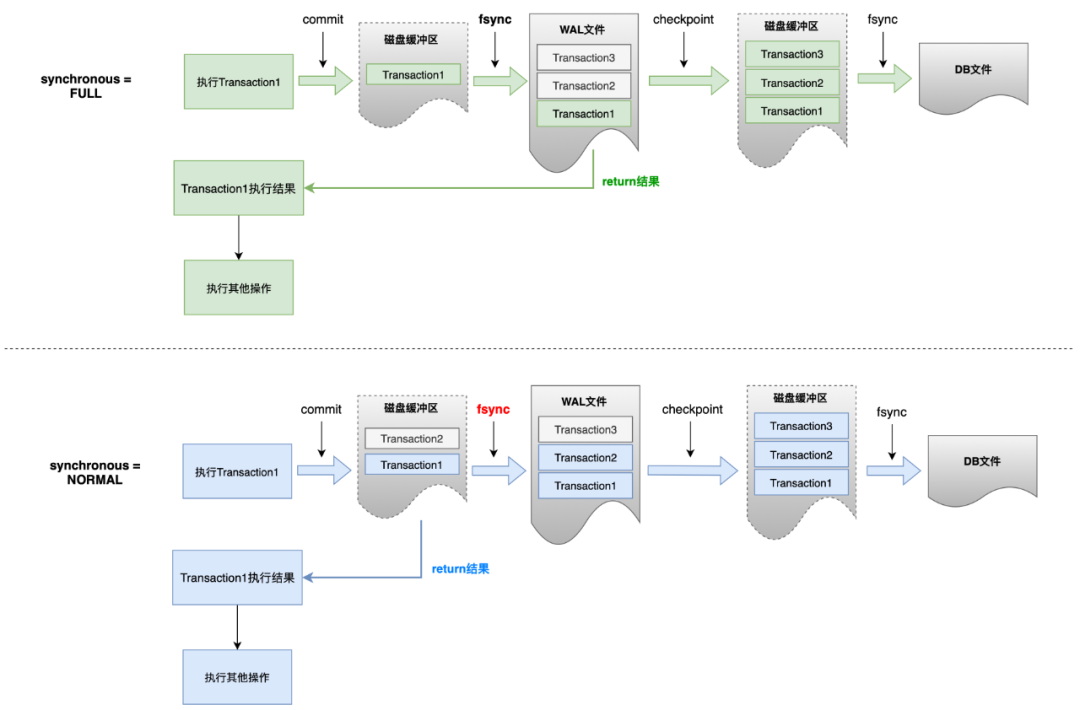
- SQLite の公式ドキュメントには次のように記載されています。 NORMAL モードでは、電源が失われたりシステムがクラッシュしたりすると、トランザクションの送信がロールバックされる可能性があります。

帰属をサポートする
1. ユーザーの電力を記録するための関連管理を開始します。一部のユーザーについては、前回のパッケージング中に電力が 10% 未満でしたが、2 回目のパッケージング中に電力が回復しました。これは、期間中に停電の問題があったことを示しています。
2. データベース同期モード情報を取得して報告する このような問題が繰り返されるユーザーのデータベース モードはすべて NORMAL であることが確認されています。
最終的な帰属
1. ユーザー デバイスの SQLite は WAL の NORMAL モードを使用しており、削除トランザクションが WAL ディスク バッファに書き込まれた後、バッファがディスクに同期される前に、停電またはシステム クラッシュが発生します。
2. トランザクションは成功と判定され報告されましたが、WAL ファイルへの書き込みが行われていないため、ディスクファイル内のデータは削除されず、システム復旧後も再度削除することはできず、報告されたデータは残っています。
(2)最適化計画
重複の理由に応じて、この問題の解決策は、データベース操作が完了した後、できるだけ早く操作をディスクに書き込むことを推測できます。実行方法は 3 つあります。オフ WAL モード; (2) 同期モードを FULL に設定します;(3) チェックポイントを手動で実行します。
Android 側で複数のソリューションを比較およびテストした結果、最終的に妥協案が得られました: データベース トランザクション「パッケージ化されたデータの削除」の信頼性のみが保証されます。同期モードが NORMAL の場合、データの削除後にチェックポイントが手動でトリガーされ、 WAL ファイルの書き込み: DB ファイルを入力し、SQLite が少なくとも WAL ファイルの fsync 操作を完了していることを確認します。チェックポイントの実行にかかる時間は、トランザクションの実行にかかる時間と基本的に同じであり、パフォーマンスの低下は許容範囲内です。
iOS 側でトランザクションが完全に WAL モードで書き込まれるようにするには、同期モードを NORMAL に設定するだけでなく、fullfsync オプションを有効にして、書き込み順序が送信順序と一致することを厳密に保証する必要もあります。テストと評価の結果、繰り返し率の最適化による利点よりもパフォーマンスの低下が大きかったため、最終的にこの最適化を実行しないことにしました。
最適化効果
-
WAL 書き込みエラーは、新バージョンにおけるロングテール重複の問題の約 70% を占めています。
-
Android 側の実験データによると、1 時間以内に、実験グループはコントロール グループと比較してパッケージングの繰り返しを 200 倍以上削減しました。
3.2 プロセス関連
データベースの損傷によって引き起こされる繰り返しパッケージングの問題を最適化した後、市場データを照会したところ、Android 側に依然として問題があり、ログが 2 つのパッケージに短い間隔で繰り返し入力され、ユーザーはデータベースの例外情報を持っていないことがわかりました。 。
短期間に同時にパッケージングをトリガーするというこの問題は、必然的に、UBC スレッドが安全かどうかという別の疑問につながります。ただし、セクション 1.2.2 で示すように、UBC 内にはキューが 2 つしかありません。データベースの読み取りとパッケージ化はどちらもシングルスレッド操作です。理論的には、スレッドの同時実行の問題は発生しません。
したがって、私たちは Android 側のプロセスのセキュリティ問題に注目しました。
1. Baidu APP にはメインプロセスに加えて、小さなプログラムやメディアなどの複数のサブプロセスがあり、異なるプロセスが管理 API を呼び出します。
2. 起動速度を確保するために、UBC は遅延読み込み初期化方式を採用しており、現在のプロセスに UBC インスタンスがない場合にのみ UBC シングルトンが初期化されます。
3. ビジネス パーティが非メイン プロセスで API を呼び出す場合、UBC は実行のためにメイン スレッドに IPC を実行し、ライフ サイクル内でメイン プロセスのみが UBC シングルトンを持つようにします。このプロセスに問題がある場合、子プロセスで別の UBC インスタンスが初期化される可能性があります。
2 つのプロセスが同時に UBC シングルトンを持つ場合、次の図に示すように、プロセスのセキュリティが確保されない可能性があります。
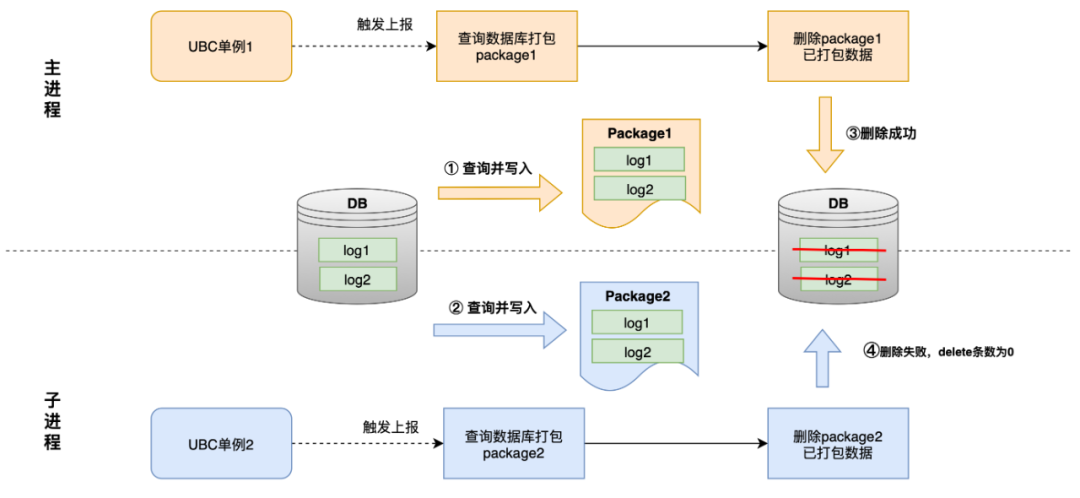
1. 2 つのプロセスがデータベースを同時にパッケージ化して操作するため、一方のプロセスがデータを削除する前に他方のプロセスがクエリを実行すると、同じデータのバッチが 2 つのファイルに書き込まれます。
2. 削除操作の実行順序により、後続の削除操作ではデータが存在しないため削除番号 0 が返されますが、レポートは例外をスローして終了しません。
マルチプロセスの問題により 2 つの UBC シングルトンが初期化される原因としては、IPC 障害とプロセス判定失敗の 2 種類があり、それぞれ症状の現れ方やパッケージ化が繰り返される理由が異なりますので、以下に順番に紹介します。
3.2.1 IPC 障害により複数の UBC インスタンスが発生する
(1)問題の帰属
データの特性
-
ユーザーが重複している場合、ポイントは 2 回パッケージ化されます。
-
2 つのパッケージ間の時間は短い (1 秒未満)。
-
パッケージングのトリガー条件のうち、ネットワーク復旧とバックグラウンド切り替えが頻繁に発生します。
-
重複したデータを2つパッケージ化した場合、プロセスIDとプロセス名が異なります。
理由の推測
2 つのプロセスにはそれぞれ UBC インスタンスがあり、システム イベントを同時に監視し、データベース パッケージを読み取ります。
さらなる帰属
マルチプロセス フレームワークのビジネス側と連絡を取り、UBC の単一ケースが 2 件発生し、パッケージ化が繰り返された理由を整理しました。
1. マルチプロセスフレームワークが子プロセスからメインプロセスへ IPC を実行するときにエラーが発生した場合、子プロセスで IPC 障害管理がトリガーされます。
2. この管理は、UBC の放棄されたマルチプロセス管理の古いインターフェイスを呼び出します。古いインターフェイスを使用すると、子プロセスで UBC シングルトンを初期化し、フロントエンドとバックエンドのスイッチングとネットワーク ステータスの監視を追加できます。
3. フロントエンドとバックエンドのスイッチングとネットワーク回復が監視をトリガーし、2 つの UBC インスタンスが同時にパッケージ化を実行します。
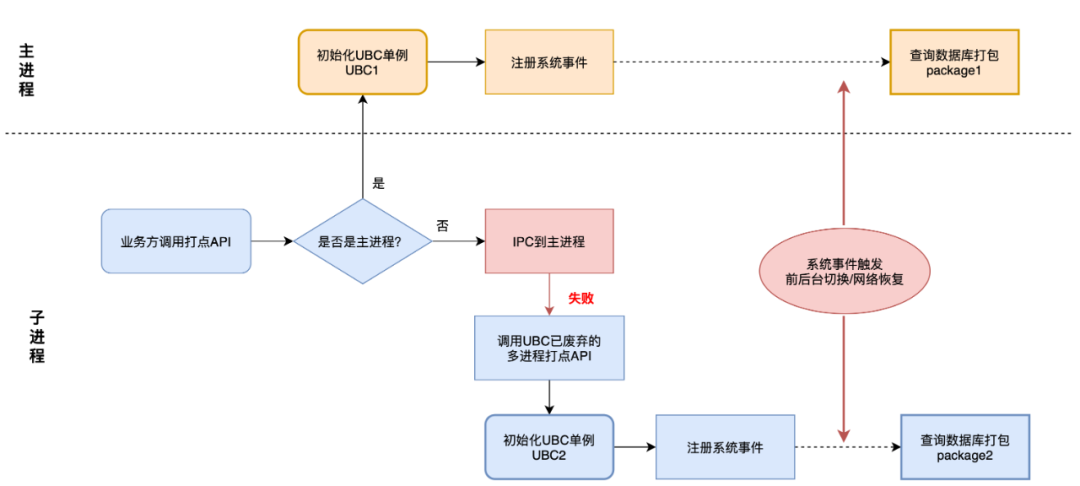
帰属をサポートする
問題が繰り返し発生した 2 つのパッケージのうち 1 つに IPC 障害ポイントがあり、これは分析の結論と一致しています。
(2)最適化計画
この問題に対応して、影響評価の後、最終的に 2 段階の最適化が実行されました。
1. サブプロセスがパッケージングを制限し、フロントエンドスイッチングとネットワークリカバリがトリガーされると、非メインプロセスはパッケージングプロセスを実行しません。
2. マルチプロセス管理インターフェイスを最適化し、メイン以外のプロセスで UBC スケジュール ロジックをバイパスし、インスタンスの初期化を回避し、レポート用に管理ポイントをファイルに直接書き込みます。
最適化効果
この問題を最適化した後、市場の重複率は 1,000 分の 1 以下に低下し、約 0.04 パーセントポイント減少し、最適化前の重複率の約 33% を占めました。
3.2.3 プロセス判断の失敗により複数の UBC インスタンスが発生する
(1)問題の帰属
データの特性
-
ユーザーが重複している場合、ポイントは 2 回パッケージ化されます。
-
2 つのパッケージ間の時間は短い (1 秒未満)。
-
リアルタイム トリガーはパッケージング トリガー条件の大部分を占めますが、両方が非リアルタイム トリガーである場合もあります。通常の状況では、非リアルタイム パッケージングは少なくとも 1 分離す必要があります。
-
2 つのパッケージのうち 1 つは、サブプロセス (ミニ プログラム ページ ビューなど) によってトリガーされる管理を備えていますが、IPC 障害の管理はありません。
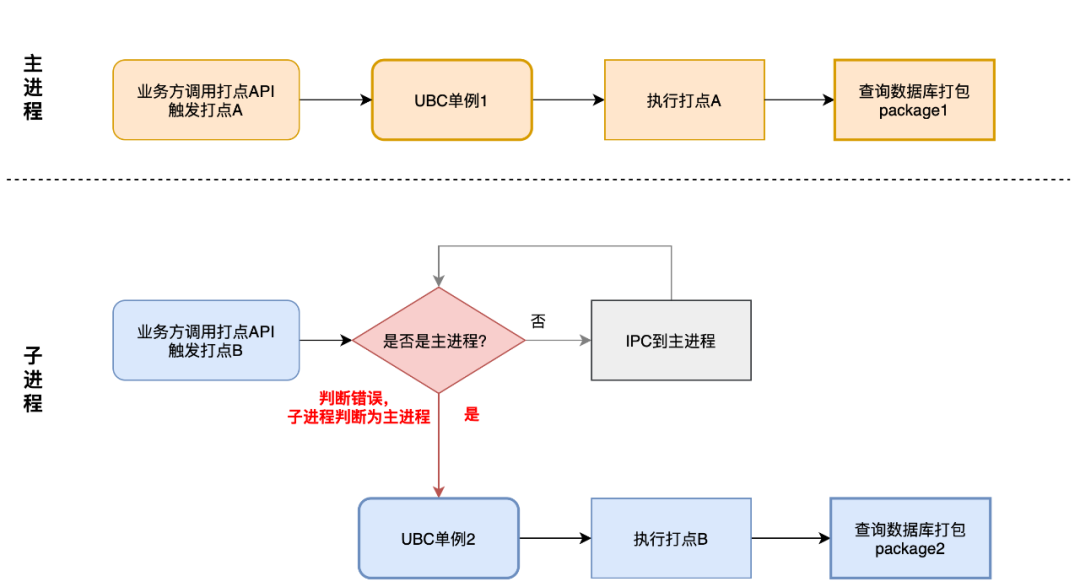
理由の推測
2 つの UBC インスタンスがあり、RBI A と B が同時に入力され、パッケージ化をトリガーします。2 つの UBC インスタンスは同時に行われ、データベース内の両方の RBI C がクエリされ、レポート用にパッケージ化されます。
さらなる帰属
- データのパフォーマンスと IPC 障害問題の最適化結果を組み合わせると、問題は IPC 障害によるバックログ データの同時レポートではなく、RBI によって引き起こされる複数のプロセスの同時実行であるため、主な疑い点はプロセスの判断です。
-
メインプロセスの決定にはマルチプロセスフレームワークが提供するメソッドが使用され、現在のプロセス名がパッケージ名と等しいかどうかを判断し、現在のプロセス名を取得するロジックが以下のようになります。
-
メモリレコードの読み取り → システムファイル /proc/self/cmdline から取得 → ActivityManager から取得
-
前の方法で取得できなかった場合は、パッケージ名をプロセス名として使用します。
-
通常、パッケージ名はメインプロセスと同じですが、子プロセスでパッケージ名をプロセス名として使用すると判定エラーとなり、子プロセスで別のUBCシングルトンが初期化されてしまい、パッケージ化問題が繰り返し発生します。
帰属をサポートする
ユーザーは、同じ名前で異なるプロセス ID を使用してプロセスを 2 回パッケージ化しました。これは、コード分析の結論と一致しています。
(2)最適化計画
UBC は管理 SDK としてプロセスの判定ロジックをあまり重視すべきではないため、マルチプロセス フレームワークのアップグレードを促進し、プロセス名の取得方法を増やす必要があります。
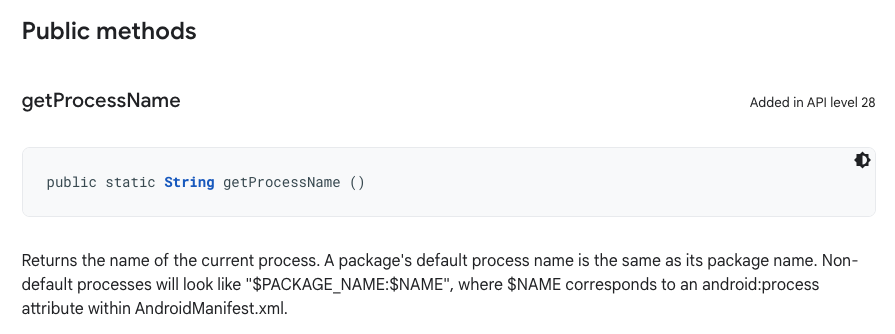
Android API 28では、リフレクションやIPCを必要とせず、プロセス名の冗長判定メソッドとして利用できるプロセス名取得メソッドApplication.getProcessName()を新たに追加しました。
最適化効果
-
プロセスの判断ミスに起因する重複問題は、新バージョンにおける重複パッケージングのロングテール問題の約 20% を占めます。
-
処理判定方法の最適化により、1秒以内に2回パッケージを繰り返す回数が約半分に減少しました 新バージョンログの重複問題は、本APIをサポートしていない低バージョン端末のみで発生しました。
3.3 管理メカニズムに関する事項
3.3.1 リアルログ
(1)問題の帰属
Reallog は特別なタイプの管理です。管理後にキャッシュは行いません。クエリ I/O 操作のみを実行します。履歴エラー データを保持し、メモリに直接レポートします。レポートが失敗すると、レポートはデータベースに書き込まれます。 。
このメカニズムは、究極のデータ報告の適時性を確保するために設定されていますが、異常な状況では、リアルログのパッケージ化が繰り返されることになります。ログは正常に報告され、ディスクに配置されていますが、サーバーの結果が時間内に返されず、UBC に保存されます。障害ロジックに従ってログを作成し、データベースにアクセスすると、次のリアルログ管理がトリガーされたときにクエリが実行され、レポートされます。
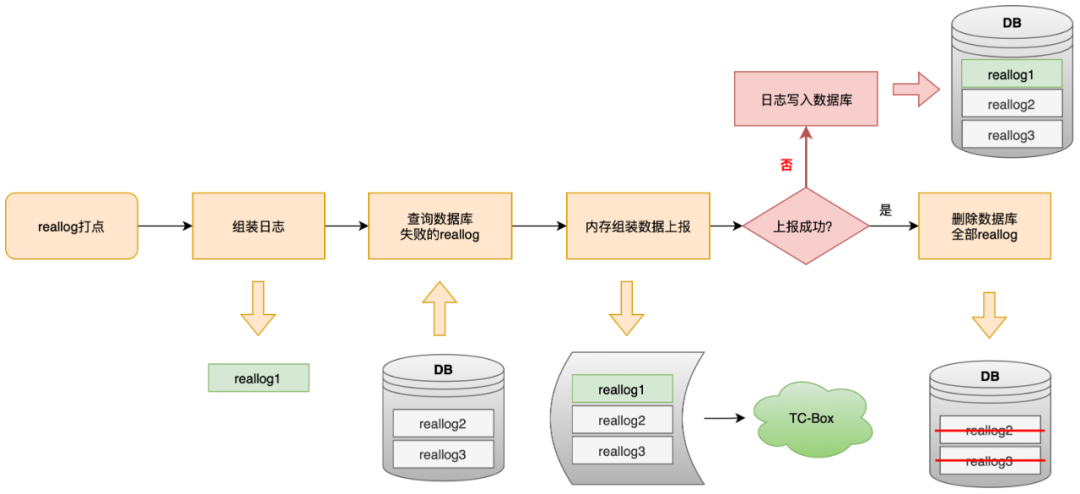
上の図に示すように、reallog タイプ管理は個別にパッケージ化されてレポートされ、reallog=1 フラグが URL に含まれます。この識別子を使用して重複データを検証し、reallog によって引き起こされた重複の問題を証明します。
(2) 最適化計画
リアルログ問題を最適化するには、ログの複製をパケットの複製に変換するか、リアルログ管理をリアルタイム管理に低下させるという 2 つの解決策を採用できます。

事例の評価:
-
リアルログは特殊な管理のため、ログセンターからの設定ができず、ごく一部の企業のみが利用しており、センターの基準に準拠していない管理です。
-
適時性の最適化を複数回行った結果、通常のリアルタイム管理の現在の 97 パーセンタイルの適時性は約 0.5 分となり、ビジネス パーティのニーズを満たすのに十分です。
2 つのオプションのコストと利点を評価し、関係するビジネス パーティに確認した後、最終的に実験を通じてオフライン リアログを段階的に最適化し、同時に UBC ポイント タイプの収束を達成することが決定されました。
最適化効果
-
新しいバージョンにおけるロングテール重複の問題の約 10% は、reallog が原因で発生します。
-
reallog がオフラインになると、両端でこのタイプの重複はなくなり、関連するビジネス パーティの使用に影響はありません。
04 概要と展望
ログを正確かつ効率的にレポートすることは、ログ データのソースとしての UBC SDK の本来の目的であり、目標です。長期的な取り組みの結果、UBC は適時性と到着率を大幅に向上させました。今回は、繰り返し報告されていた問題を調査して最適化し、SDK 管理プロセスにおけるさまざまな問題と隠れた危険性を発見して解決しました。は 3,000 分の 1 から 1,000 分の 1 未満に減少し、ダウンストリーム データにより信頼性の高いデータが提供されます。
同時に、さまざまな最終管理の問題のトラブルシューティングにおける貴重な経験を蓄積し、ローカル ログを最適化し、より詳細な SDK 実行プロセスの監視を構築して、将来的に問題を迅速に発見して特定するための強固なデータ基盤を構築しました。
- 終わり -
推奨読書
文生図の大規模実践: 百度による AIGC ペイント ツール探索の裏話が明らかに!
Python スクリプトによる OC コード再構築の実践のサポート (2): データ項目はモジュール アクセス データ パスのコード生成を提供します
Baidu のオープンソース高性能検索エンジン Puck について InfoQ に相談してください
Alibaba Cloudが深刻な障害に見舞われ、全製品が影響(復旧) Tumblr がロシアのオペレーティングシステムAurora OS 5.0 を冷却新しいUIが公開 Delphi 12とC++ Builder 12、RAD Studio 12多くのインターネット企業がHongmengプログラマーを緊急採用UNIX時間17 億時代に突入しようとしている (すでに突入している) Meituan が兵力を募集し、Hongmeng システム アプリの開発を計画Amazon が Linux 上の .NET 8 への Android の依存を取り除くために Linux ベースのオペレーティング システムを開発独立した規模はFFmpeg 6.1「Heaviside」がリリースされました