01
バックグラウンド
iQIYIの海外バックエンド研究開発チームは、iQIYIの海外のPHONE/PCW/TV 3端末バックエンド関連ビジネスをサポートしています。3つの端末のバックエンドサービスを担うほか、海外ポイント事業やポップアップウィンドウ、各種プログラムの予約システムなども担当する。さらに、プロダクトのさまざまな運用形態や実験的要求を迅速にサポートするIQバックグラウンド、プロダクト運用の洗練された運用を支援する戦略エンジン、トラフィックの再生とプレッシャーを実現する品質保証プラットフォームなどの一連のインフラストラクチャも備えています。テスト待ち。
さまざまなビジネスの安定した運用は完全なログ システムに依存しているため、ビジネス コードは多くの場合、ビジネス コードの運用上の問題の監視とトラブルシューティングに役立つように多くのログを出力します。ただし、ログの印刷はプロジェクトのパフォーマンスに一定の影響を与えます。私たちは多くの情報を読み、さまざまなフレームワークのログ パフォーマンスの比較をたくさん見つけることができますが、エンジニアリングの実践に必要な洗練されたログ出力 SOP が不足しています。また、現在は分散システムが主流となっており、ログ出力の際にはステートレスで各ノードが同じリクエストの情報を独立して出力するため、情報の重複が多くリソースの無駄が発生し、サービスパフォーマンスも良くありません。
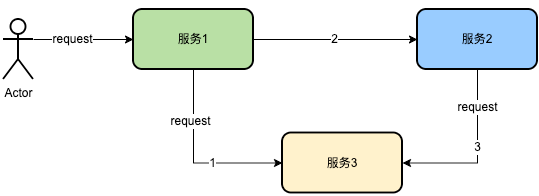
上に示すように、サービス 1 はサービス 3 を呼び出し、次にサービス 2 を連続的に呼び出します。サービス 2 は内部的にサービス 3 に依存します。上記の場合、サービス 1 は要求されたサービス 3 の詳細情報を記録し、サービス 2 は要求されたサービス 3 の詳細情報を記録し、サービス 3 は要求されたすべての情報を記録します。つまり、リンクには同じログが 4 回含まれています。
上記の問題を解決するために、私たちは分散システムのログ出力最適化スキームの特別な構築を実行しました。これは主に 2 つの部分で構成されます。
(1) ログ記録によって引き起こされるプロジェクトのパフォーマンスの実際の損失に関する定量的なデータを取得し、プロジェクトのパフォーマンスを向上させ、将来のログ印刷の参考となるようにログ印刷 SOP を改良します。
(2) ログ印刷のリンクグローバル性を考慮し、分散サービスノード間のステートフルなログ記録を実現します。
上記 2 つの部分の構築により、分散リンク下でのログ印刷のリソースとパフォーマンスの消費を削減できます。システムのパフォーマンスを向上させ、システムの損失を削減します。
この記事では主に、分散システムのログ印刷最適化スキームにおける探索、思考、実践のプロセスを共有します。
02
単一システム最適化ログ出力の検討と実践
現在、最も人気のあるフレームワークは、log4j、log4j2、logback です。一般に、log4j2 は log4j のアップグレードであると考えられています。そのため、最も主流の log4j2 フレームワークと logback 1.3.0 フレームワークの間で実験的な比較を実施し、パフォーマンス データを取得し、ビジネス システムがログを出力するためのプロセス仕様を提供するためのベスト プラクティスを要約します。
2.1 ログ出力のベストプラクティス計画を取得するための複数のディメンションの比較
コンテナー デプロイメント、リソース: 2c4g、独立したデプロイメント プロジェクトを選択しました。プロジェクトには、入力パラメーターに従ってさまざまなサイズのログを制御および出力する機能を持つ API が含まれています。
2.1.1 log4j2の印刷性能の定量的調査
log4j2非同期
ログサイズ: 2KB、非同期
 log4j2同期
log4j2同期
 Log4j2 圧力テストの結論
Log4j2 圧力テストの結論
上記のデータから、次のグラフを簡単に生成できます。
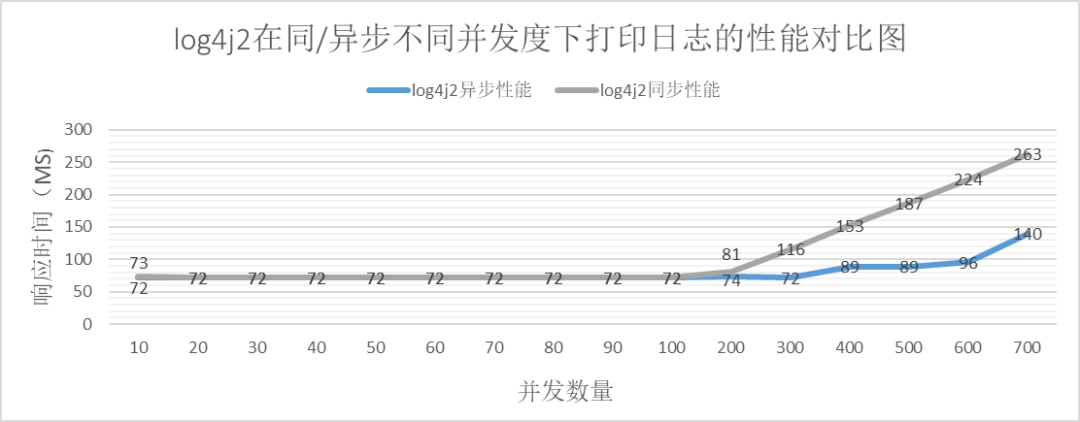
上の図から次のことがわかります。
同時実行数が少ない場合、log4j2 のパフォーマンスは安定していますが、同時実行数が一定の数に増加すると、明らかに非同期印刷のパフォーマンスが同期印刷よりも優れています。
Log4j2 非同期印刷にもパフォーマンスのボトルネックがあります。
log4j2 の同期印刷のパフォーマンスのボトルネックは IO ボトルネックにあり、1 秒あたりの IO サイズは約 2635 ✖️ 2kb = 5.15MB です。
2.1.2 logbackの印刷性能の定量的調査
非同期ログバック

ログバック同期印刷

ログバック圧力テストの結論
logbackの圧力計測データから以下のようなグラフを簡単に生成できます。
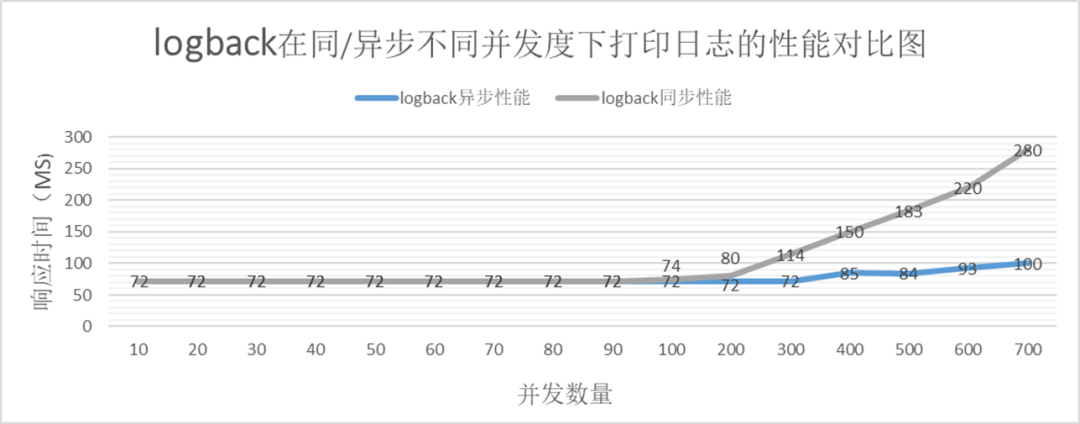
上の図から次のことがわかります。
同時実行数が少ない場合、log4j2 のパフォーマンスは安定していますが、同時実行数が一定の数に増加すると、明らかに非同期印刷のパフォーマンスが同期印刷よりも優れています。
ログバック非同期印刷にもパフォーマンスのボトルネックがある
log4j2 の同期印刷のパフォーマンスのボトルネックは IO ボトルネックにあり、1 秒あたりの IO サイズは約 2650 ✖️ 2kb = 5.2MB であり、log4j2 とほぼ同じ IO サイズです。
2.1.3 logback と log4j2 の比較
同期比較

上記の表データから、次の比較表が得られます。
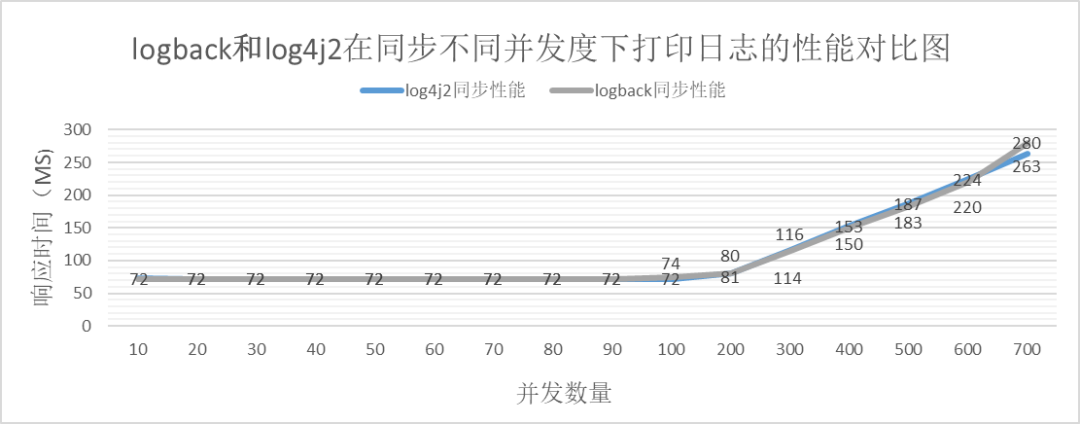
非同期比較

上記の表データから、次の比較表が得られます。
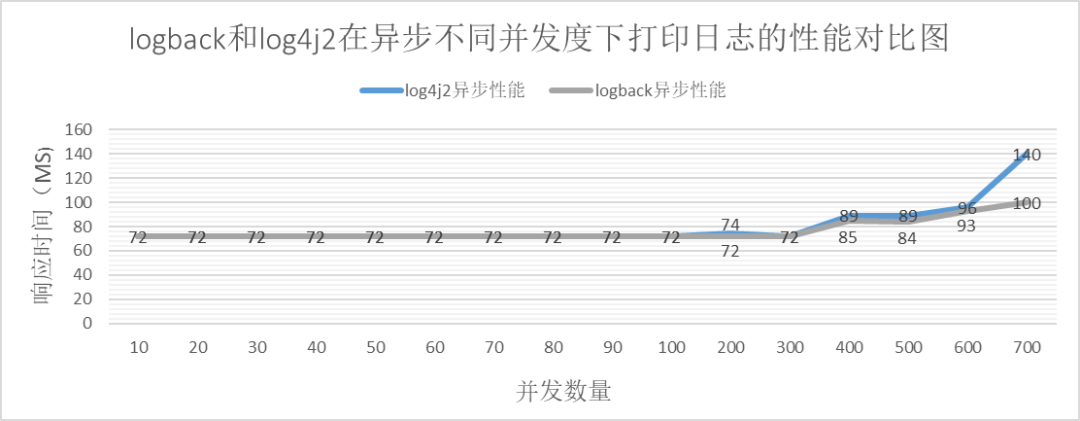
上記のことから、次のことがわかります。
同期か非同期か。同時実行性が特定のしきい値を超えると、logback のパフォーマンスが log4j2 よりも高くなります。
一定の同時実行性の範囲内では、logback のパフォーマンスは log4j2 のパフォーマンスと同等です。
2.1.4 さまざまなシナリオでのログバックのパフォーマンスの定量的比較
セクション 2.1.3 の結論から、同期か非同期かは関係ないことがわかります。同時実行数がしきい値未満になる前は、logback と log4j2 のパフォーマンスは同等ですが、同時実行数が一定のしきい値を超えると、logback のパフォーマンスが log4j2 よりも優れています。したがって、以下では、さまざまなシナリオでのログバックのパフォーマンスを詳しく調べます。
Logback は、同じ数の同時実行インターフェイスのパフォーマンス データの下で、異なるサイズのログを同期的に出力します。
同時実行 = 100、同期

Logback は、同じ数の同時実行インターフェイスのパフォーマンス データの下で、異なるサイズのログを非同期的に出力します。
同時実行数 = 100、非同期

上記のデータから、次のような関係図を描くことができます。
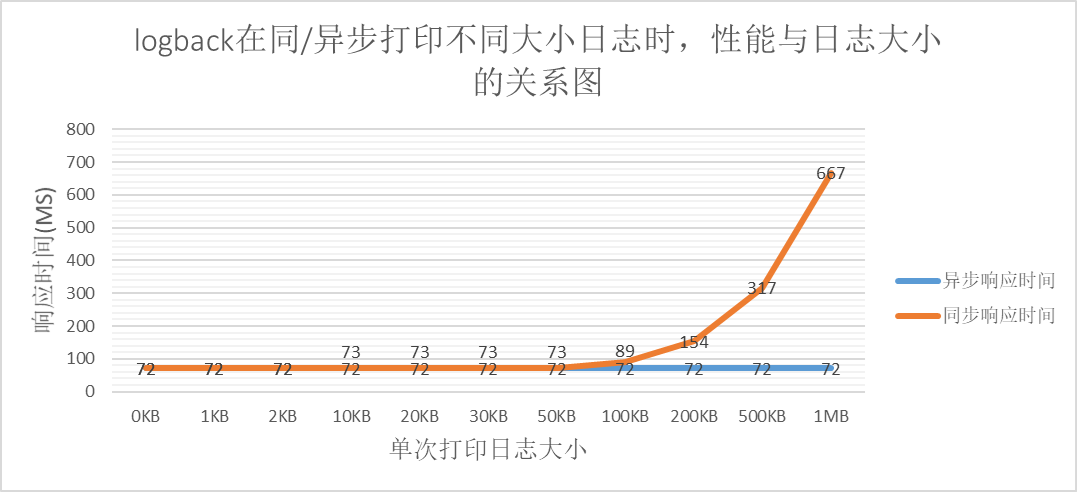
上の図から次のことがわかります。
ログサイズが一定の範囲内であればパフォーマンスに影響はありませんが、一定の制限を超えるとパフォーマンスが大幅に低下します。
同期的に出力されたログのデータから、同時実行数が一定の場合、IO 数にボトルネックがあることがわかります。つまり、単位時間あたりの IO のサイズは、同時実行数の増加に比例して増加しません。各IO。実験データのボトルネックは約 160MB です。
ログバック非同期印刷は、非同期印刷キューがいっぱいになった後、ビジネス ログを破棄する戦略を採用できるため、ログ サイズの影響を受けにくくなります。
2.2 ベストプラクティスの概要
プロジェクトのパフォーマンスに対するログ出力の影響を軽減するために、ログ出力のフレームワークとしてログバックの使用を優先します。
同時実行性が高く、ビジネス ログが必要ない場合は、logback を使用して非同期に印刷します。
ビジネス ログが強く依存していると判断したため、logback は、ログを非同期に出力するために神経ブロック = true を設定することに特別な注意を払う必要があります。このとき、プロジェクトの 1 リクエストの印刷ログ サイズが 2KB 未満の場合、プロジェクトの 1 秒あたりの IO データは 5MB を超えてはなりません。
2.3 エンジニアリングプロジェクトの最適化
上記のベストプラクティスに基づいて、パイロット変革のために iQIYI の海外バックエンド R&D チームのプロジェクトを選択し、パフォーマンスの変化を分析しました。
2.3.1 プロジェクトの紹介
iQIYIの海外バックエンド研究開発チームは、主にページビジネスデータの安定した出力のためのTOCサービスと、柔軟で効率的かつスケーラブルなIQ運用背景を含む、PHONE/PCW/TVの対応する海外iQIYIバックエンドビジネスを担当しています。きめ細かな運用を実現する戦略エンジンと、プログラムデータを同期するデータセンターサービス。
プロジェクトには多数の API が含まれており、ログ出力のシナリオも多数あるため、パイロットとして非カード構造の TOC サービスを選択します。このプロジェクトはシンガポールに展開され、4C8G コンテナ化された展開で、スタンドアロンのピーク時の QPS は約 120 です。
2.3.2 パフォーマンスの最適化の結果

非同期変換後、P99 は 78.8 ミリ秒から 74 ミリ秒に低下し、P999 は 180 ミリ秒から 164.5 ミリ秒に低下しました。
プロジェクトによって状況は異なりますが、単一マシンのトラフィックが多いプロジェクトや、大量のログが出力されるプロジェクトの場合は、非同期変換の方がパフォーマンスが向上すると考えられます。
2.4 概要
スタンドアロン ログのパフォーマンス最適化の主な作業は、さまざまなログ フレームワークのパフォーマンスを取得し、さまざまなシナリオで同じログ フレームワークのパフォーマンスを取得することです。データのこの部分が、同じジレンマに直面している同僚の助けになれば幸いです。また、ログの出力方法も標準化しており、ビジネスSLAを格付けすることで、なぜここにログが出るのかをログレベルで説明でき、例外であればどのレベルの例外なのかをすべて説明できるようになりました。ビジネスを学ぶ学生は、さまざまなアラームについてタイムリーに学ぶことができ、緊急度によって優先順位の判断やプロセスに基づいた対応が可能になります。
03
ログ印刷における分散型変数共有の応用
上記の章では、スタンドアロン システムのログ印刷の最適化について紹介しましたが、現在のシステムは基本的に分散システムです。分散システムにおけるログ印刷の問題点と解決策は何でしょうか。分散システムにおけるログリンク印刷の最適化手法を考えたので、以下に分散システムにおけるログ印刷最適化の考え方と実践を示す。
3.1 はじめに
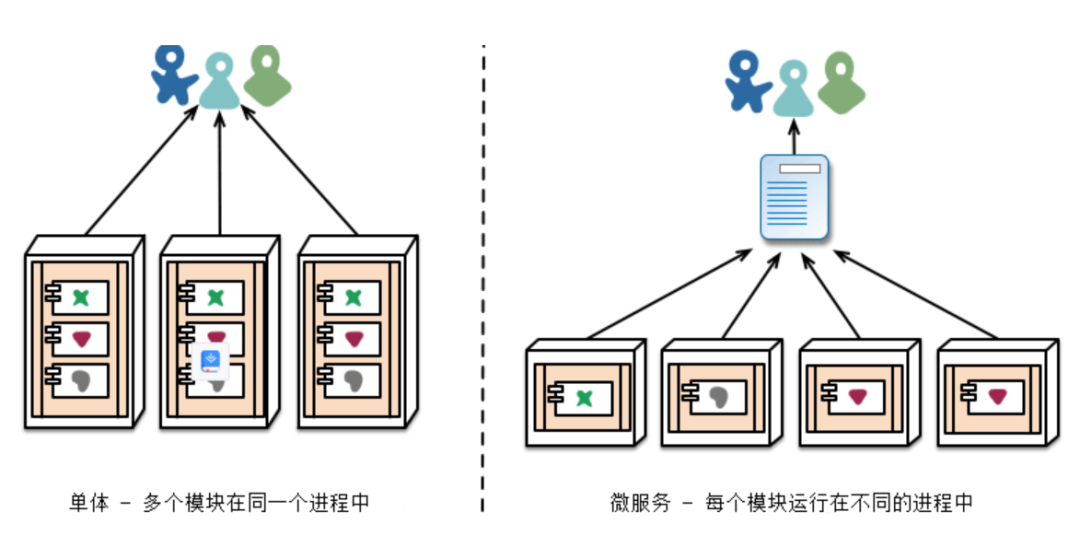
インターネット技術の進化の過程を見ると、単一システムから分散システムへの進化は非常に重要な特徴です。しかし、一般的に物事を変える方が有利であることは否定できませんが、支店では常に新しい課題に遭遇します。モノリシック システムには、ローカル トランザクション、共有コード、共有変数など、分散システムにはない利点もあります。ログを出力するという観点から見ると、モノリシック システムは同じサービスへの呼び出しをシンクできます。ログ レコードは同じプロジェクト内にあるため、表示したり同意したりすることもできます。分散システムでは通常、機能モジュールが分割され、異なる開発チームに所属しているため、異なるサービスノードのログ出力は通信できないことが多いため、基本的にはすべての開発チームが全力で取り組むことになります リンク全体のログ非常に冗長になるため、リソースの無駄が発生し、分散システムのパフォーマンスが低下します。
3.2 完全なリンク追跡システムの概要
分散システムでは、外部リクエストを完了するには、複数の内部モジュール、複数のミドルウェア、および複数のマシンが相互に呼び出しを行う必要があることがよくあります。この一連の呼び出しでは、一部はシリアルであり、一部は並列である可能性があります。この場合、このリクエスト全体によってどのアプリケーションが呼び出されたかをどのように判断できるでしょうか? どのモジュールですか? どのノードですか? そしてそれらの順序と各パートのパフォーマンスは何ですか?リンクトラッキングの目的は、上記の問題を解決すること、つまり、分散リクエストを通話リンクに復元し、分散リクエストの通話ステータスを一元的に表示することです。各サービス ノードの特定のリクエスト、どのマシンに到達するか、各サービス ノードのリクエスト ステータスなど。たとえば、フルリンク システムの 1 つである zipkin のアーキテクチャ図は次のとおりです。
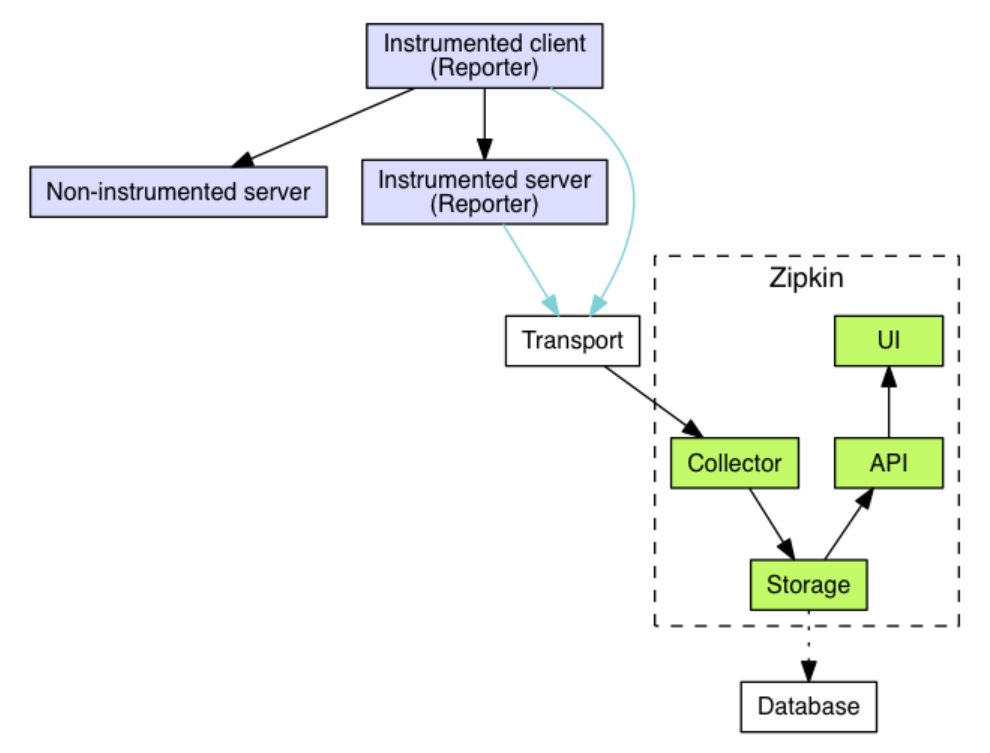
フル リンク トラッキング システムは、リンク ログ サンプリングと可変透過伝送をサポートしており、分散システムを最適化するためにフル リンク設計アイデアを参照します。
3.3 ログサンプリングのための共有変数の使用
3.3.1 背景の紹介
この問題は、当社の戦略エンジン システムに集中しています。戦略エンジン システムは、洗練された運用を実現するために設計および実装されたシステムです。主に、さまざまな人々のグループのポートレートを識別して識別し、それに応じてさまざまな戦略を展開することができます。システムの導入により、アクセスビジネスは急速に成長しました。現在、iQIYIの海外ページデータのCARD事業、ポップアップウィンドウ事業、広告事業、インタラクティブマーケティング事業、レコメンド事業、ナビゲーション・ジャーニー事業が連携されている。ただし、上記のさまざまなシステムには特定の依存関係があり、相互に呼び出します。また、ビジネス ニーズにより、ポリシー エンジンのリクエストは投稿リクエストに依存しており、ゲートウェイ ログは投稿のリクエスト パラメーターを解析できないため、ビジネスは各リクエストの詳細を記録する必要があります。さらに、ポリシー エンジンは、BI サービスと Facebook サービスにそれぞれ保存されているユーザーのポートレート データに大きく依存しています。過去の経験によると、ポリシー ヒットの失敗の原因の約 90% は、ユーザーのポートレート データが時間内に更新されていないことが原因です。トラブルシューティングを容易にするために、問題を特定するために、ポリシー エンジンは各ユーザーが要求したユーザーのポートレート データを記録します。ポリシー エンジンの QPS は非常に高いため、1 日あたりのログ量は約 150G です。ログのこの部分をエレガントに最適化する方法は、私たちが直面した課題です。
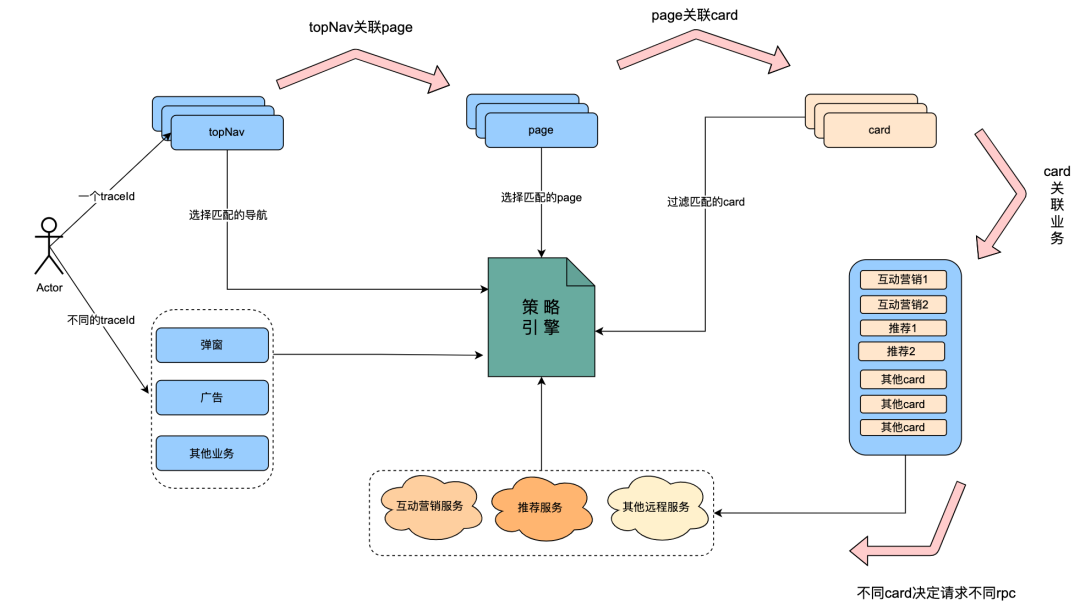
戦略エンジンのトラフィックには、主にポップアップ ウィンドウ、広告、トップ ナビゲーション、iq、レコメンデーション、インタラクティブ マーケティングが含まれます。
ただし、一部のトラフィックには明らかなリンク特性があることがわかりました。クライアントリクエストによってトップナビゲーションが決定されると、関連するページが取得されます。
ページに関連付けられた一連のデータが存在する場合、ユーザー プロファイルに一致するページを取得するようにポリシー エンジンに要求する必要があります。
ページには複数のカードが関連付けられているため、このとき、ユーザーの肖像画と一致するカードを取得するようにポリシー エンジンに要求する必要があります。
このカードは実際には、インタラクティブなマーケティング サービスや推奨サービスなどのさまざまなビジネス データに関連付けられています。また、インタラクティブなマーケティングとレコメンデーションは、戦略エンジンに群衆のポートレートと一致するデータを取得するよう要求します。
分析の結果、ユーザーがリクエストすると、含まれるマイクロサービスがそれぞれポリシー エンジンをリクエストすると結論付けることができます。リクエストのライフサイクルにおいて、ユーザーのリクエストデータは必ず同じであり、ユーザーのポートレートデータも必ず同じです。
3.3.2 解決策
上記の分析によれば、ポリシー エンジンによって一律に記録されていると考えるのが簡単です。ポリシー エンジンは、リクエストのライフ サイクルにレコードがあるかどうか、レコードがある場合は記録されず、レコードがない場合は記録されることを示す識別子を TraceContext に追加します。
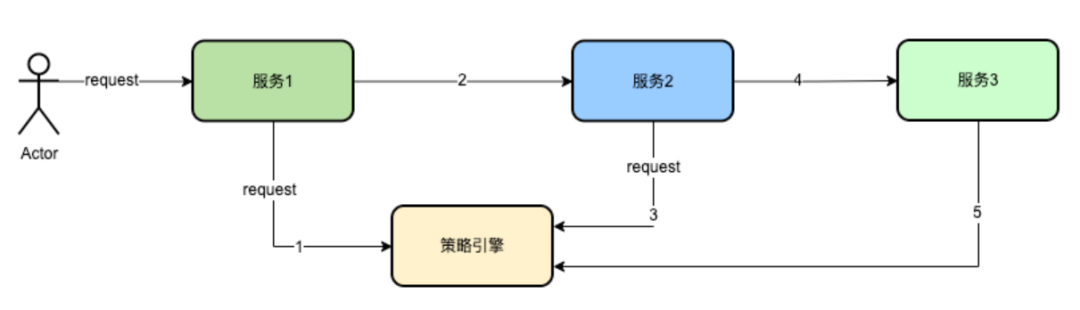
上の図に示すように、サービス 1 がポリシー エンジンを要求した後、TraecContext に識別子が追加され、要求 Trace が記録されたことを示します。後続のノード、つまりサービス 2 とサービス 3 がポリシー エンジンを再度要求する場合、レコードを繰り返す必要はありません。そうすることで、大量のロギングを削減できます。
ただし、次の問題が発生します。5xx エラーがある場合、ポリシー エンジン サービスが失敗し、対応するリクエストが記録されず、リクエスト レコードが失われるため、トラブルシューティング エージェントは非常に困難になります。
比較分析の結果、分散システムで変数を共有することで上記 2 つの問題をうまく解決できることが最終的に判明しました。
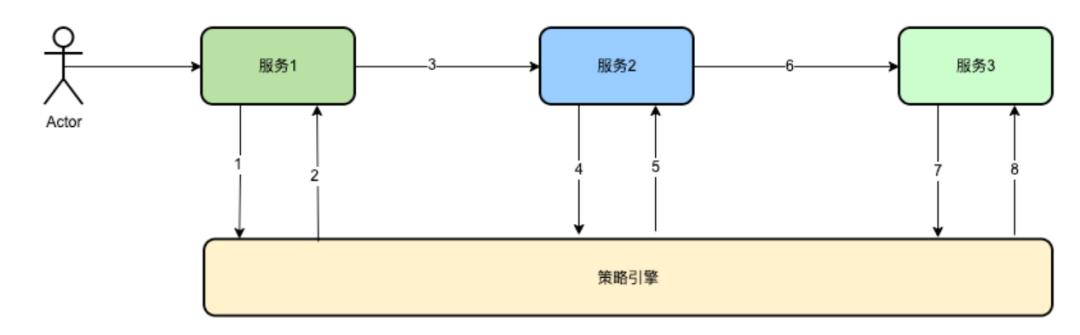
上記リクエスト1、2、4、5、7、8はいずれもtraceContextコンテキストのlogBusinessフィールドを判定する必要があり、存在する場合は記録する必要はなく、存在しない場合はログを記録しますそしてlogBusinessをtrueに設定します。
たとえば、これは合計 200 件のリクエストで、1 件のリクエストがポリシー エンジンに到着し、traceContext コンテキストの logBusiness フィールドが false であると判断された後、そのリクエストが記録され、logBusiness が true に設定され、その後の 4 件では、リクエストが記録されます。 、5、7、8、再度ログを記録する必要はありません。4、5、7、8 に例外があった場合でも、1 で記録された TraceId とリクエストを通じてリクエスト ポリシー エンジンのシーンを復元できます。
もう 1 つの例は、1 つのリクエストが失敗した場合です。499 タイムアウト リクエストの場合、タイムアウトはサーバーに対して透過的であり、ポリシー エンジンは実行を継続するため、ポリシー エンジンはログを出力し、traceContext コンテキストの logBusiness フィールドを true に設定します。 。ただし、サービス 1 については、タイムアウトにより、データのコピーが重複して記録されます。4 回目のリクエストでは、traceContext コンテキストの logBusiness が false のままであるため、再記録され、logBusiness は true に設定され、後続の 7 回目のリクエストでは記録されません。
たとえば、1 つのリクエストが失敗し、それが 5xx リクエストだった場合、1 が記録され、4 が再度記録されます。
したがって、この方法は、復元ログリンクの整合性を確保することを前提として、リンクログを最小限に抑えることができる。
3.3.3 概要
ポリシーエンジンサービスを最適化し、ログを従来の150G/日から30G/日まで削減できます。それに応じて、flink タスクの収集とログ処理のためのキュー リソースの消費も削減されます。
04
概要の見通し
本稿では主に分散システムのログ印刷最適化スキームの探索と実践プロセスを単一ログ最適化と分散システムログ最適化の側面から紹介する。現在主流のログ フレームワークのパフォーマンスを比較し、データを取得し、ベスト プラクティスを形成し、ビジネス プロジェクトのログ印刷方法の標準アクセス ソリューションを提供し、ログ印刷方法を改善することでチーム プロジェクトで得られる利点を紹介します。特定のシナリオでは、分散システムのログ印刷のステートレス問題に対する革新的な解決策が提供され、異なるまたは同じ分散ノードの繰り返しログの問題が解決されます。ここでもう 1 つ言及しておきます。一連の検討の結果、分散シェア変数には幅広い応用の可能性があります。この記事で紹介したステートフルに最適化されたログ出力に加えて、この方法は、データの不整合に対する許容度がゼロまたは弱いシナリオにも使用できます。ボトルネック サービスのトラフィック プレッシャーを軽減し、リンク パフォーマンスを向上させることは良いことですが、当然、これにはデータ圧縮アルゴリズムと解凍アルゴリズムの連携が必要です。今後の練習では、自分たちの考え方や練習のプロセスを仲間と共有する機会を設けます。

たぶんあなたは見たいでしょう