作者: ウェイウェイ
SQL Server の概要
SQLサーバーとは何ですか?
Microsoft SQL Server は、エンタープライズ IT 環境におけるさまざまなトランザクション処理、ビジネス インテリジェンス、分析アプリケーションをサポートする Microsoft のリレーショナル データベース ソリューションです。Microsoft SQL Server は、市場をリードするデータベース テクノロジの 1 つです。
SQL サーバーの機能
- 安定性: 企業のアプリケーションのニーズに応じて、環境に適応するソリューションを開発し、データのセキュリティと企業の円滑な運営を確保します。
- 使いやすさ: ユーザーがデータベース システムを迅速に構築できるよう、豊富なグラフィカル管理ツールを提供します。
- 互換性: Windows システムにネイティブに適合し、豊富な API アクセスを提供します。
- パフォーマンス: 複数のデータベース エンジン最適化アルゴリズムにより、大量のデータ クエリとストレージがサポートされます。
SQL Server のコア概念
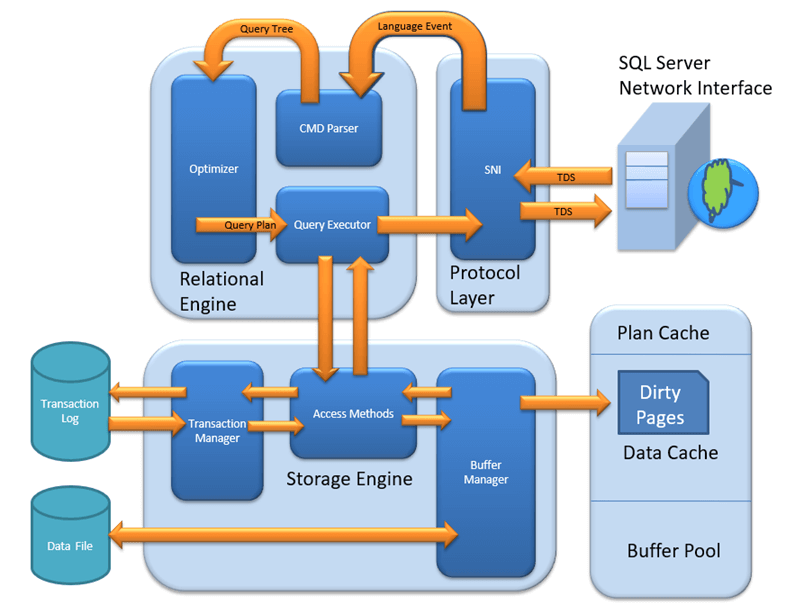
リレーショナル エンジン:リレーショナル エンジンは、ストレージ エンジンのデータ処理を制御し、クエリの実行方法を正確に決定する SQL Server コンポーネントを提供します。リレーショナル エンジンは 3 つの主要な部分で構成されます。CMD パーサー (パーサー) は主に、意味論的および文法上のエラーを特定して除去し、クエリ ツリーを生成する役割を果たします。オプティマイザーは、冗長なタスクを排除し、最適なプランを見つけることで、要求されたクエリの応答が可能な限り効率的になるようにします。Query Executoe は、データ取得ロジックの動作を生成します。
ストレージ エンジン:データがストレージ エンジンによって保存される場合、データは SAN やディスクなどのストレージ システムから取得されます。ストレージ エンジンには、プライマリ ファイル、補助ファイル、ログ ファイルの 3 種類のファイルがあります。アクセス メソッドは、キャッシュ マネージャーとトランザクション ログの間でデータを交換する役割を果たします。バッファ マネージャーは、現在の実行プランとページをキャッシュします。トランザクション マネージャーは、ログ マネージャーとロック マネージャーを使用してトランザクションを管理します。
プロトコル層:この層は、クライアント/サーバー アーキテクチャとストリーミングをサポートします。プロトコル層は、共有メモリ、TCP/IP、名前付きパイプの 3 種類のクライアント/サーバー アーキテクチャをサポートします。
主な適用シナリオ
Microsoft SQL Server は、そのビジュアル インターフェイスとそのオプションとツールを備えており、必要な情報をすべてリレーショナル データベースに保存し、そのようなデータを簡単に管理するのに最適です。
- トランザクション処理: SQL Server はトランザクション処理をサポートしています。トランザクションを使用すると、ユーザーは一連のデータベース操作をグループ化し、すべてが正常に実行されるか、すべてが元の状態にロールバックされることを確認できます。これは、銀行取引、オンライン ショッピング、在庫管理など、データの一貫性が必要なアプリケーションにとって重要です。
- ビッグ データ クラスターによるすべてのデータのインテリジェントな分析: SQL Server は、強力なデータ ウェアハウジング機能とビジネス インテリジェンス機能を提供します。ユーザーは SSIS を使用して、さまざまなデータ ソースからデータを抽出、変換し、データ ウェアハウスに読み込むことができます。その後、SSAS を使用して多次元データ モデルとキューブを作成し、複雑なデータ分析とレポートのニーズをサポートできます。さらに、SQL Server は、組織がデータの隠れたパターンや傾向を発見できるようにするデータ マイニング機能と予測分析機能も提供します。
- スケーラビリティ: SQL Server は、アプリケーション開発者をサポートする幅広い開発およびプログラミング機能を提供します。SQL Server は水平方向および垂直方向の拡張もサポートしており、ユーザーは必要に応じてサーバー ハードウェア リソースを増やしたり、データを複数のサーバーに分割して分散したりして、大規模なデータや高い同時負荷を処理することができます。SQL Server を使用すると、ユーザーはデータベース管理システムを任意のデバイスおよび Azure サービスと簡単に統合して、データ パフォーマンスと分析機能を向上させることができます。
メインバージョンの紹介
SQL Server 2022: セキュリティ、パフォーマンス、可用性、その他の機能強化、クエリ ストレージとインテリジェントなクエリ処理
SQL Server 2019: データ仮想化とビッグ データ クラスター、スマート データベース、スマート クエリ、インメモリ データベース
SQL Server 2017: グラフ データベース機能、動的管理ビュー、メモリ最適化など
SQL Server 2016: インメモリ OLTP、Stretch Database、統合 Hadoop など。
主要な指標を監視する
ここでは、SQL Server サービスの監視における一般的な主要な指標を紹介します。
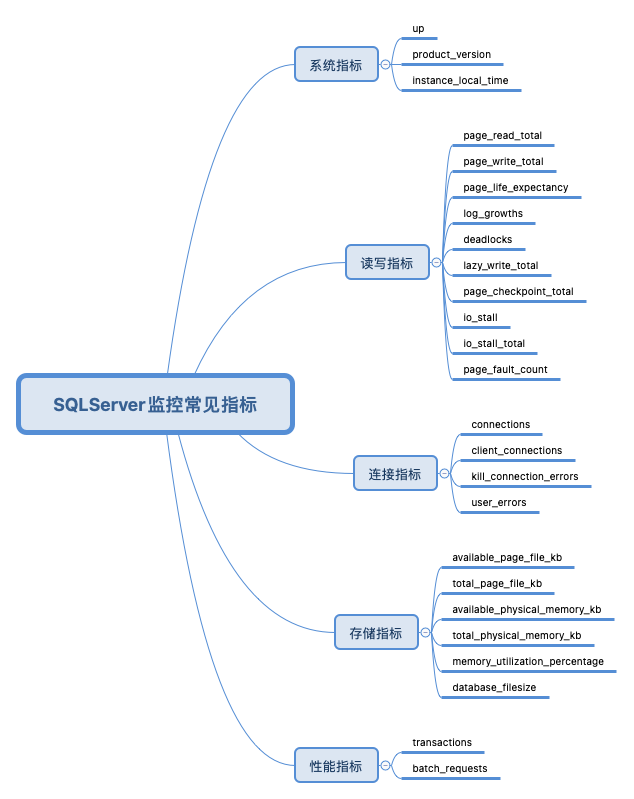
システムインジケーター
稼働状況
起動ステータスは SQL Server を監視するための最も基本的な指標であり、SQL Server インスタンスが正常に実行されているかどうか、または再起動されているかどうかを示します。SQL Server を再起動すると、コミットされていないデータが失われ、低い確率でエラーが発生する可能性があります。
バージョン/インスタンス時間
開始された SQL Server インスタンスが期待どおりであるかどうか、またビジネスに必要な SQL Server バージョンであるかどうかを監視します。SQL Server のローカル時刻がクライアントのローカル時刻と一致していることを確認してください。一致していない場合、データベースから返される時刻が不正確になる可能性があります。
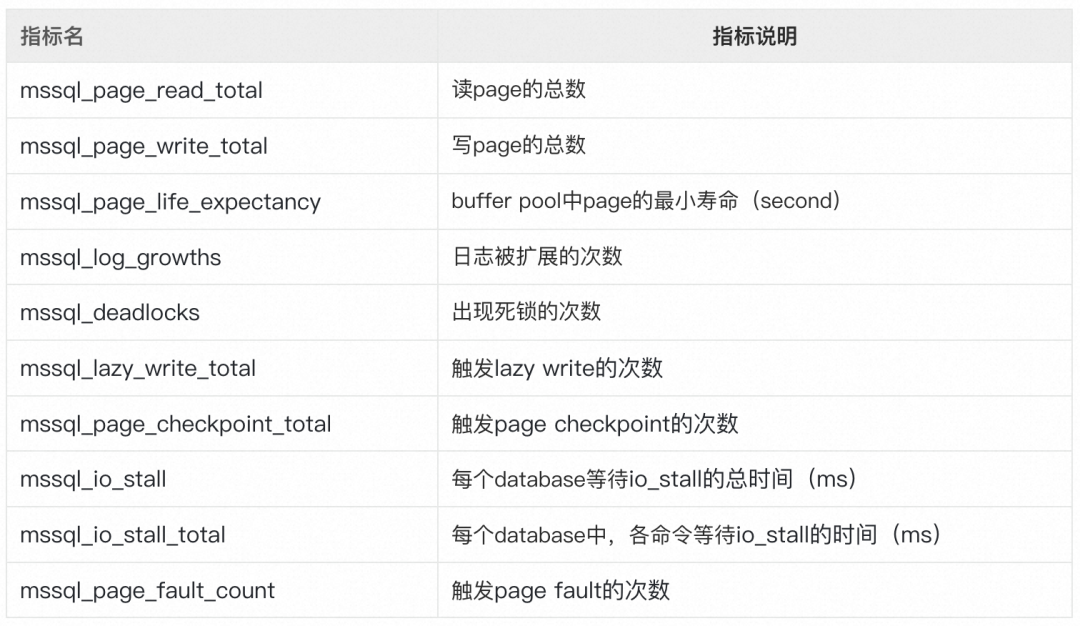
読み書き能力の指標
ページインデックス
ページの読み取りと書き込み:ページは、SQL Server ストレージ エンジンのディスク管理の最小単位です。データベース内のデータ ファイル (.mdf または .ndf) に割り当てられるディスク領域は、論理的にページ (0 から n までの連続番号) に分割できます。 。ディスク I/O 操作はページ レベルで実行されます。つまり、SQL Server はすべてのデータ ページの読み取りまたは書き込みを行います。したがって、ページの読み取りおよび書き込みの監視は特に重要です。読み書きされたページ数のインジケーターを通じて、ページの読み書き速度を計算し、SQL Server の実行パフォーマンスを判断できます。
キャッシュ内のページ滞留時間:ディスクの読み取りおよび書き込み操作はリソースを大量に消費するため、すべてのデータベース ソフトウェアの主な設計目標の 1 つは、ディスク I/O を最小限に抑えることです。SQL Server は、データベースから読み取ったページを保持するためにメモリ内にバッファ プールを生成します。キャッシュ プール内のページの存続期間を監視する必要があります。ページがキャッシュ プールに長く存在するほど、ヒットする可能性が高くなります。これは、ページへのアクセスにディスクへのアクセスが必要ないことを意味します。
遅延書き込み:バッファ キャッシュ内でページが変更された後、そのページはすぐにディスクに書き戻されず、代わりに「ダーティ」としてマークされます。これは、ページがディスクに物理的に書き込まれる前に、論理的に複数回書き込むことができることを意味します。通常の動作では、ダーティ ページは定期的にディスクにフラッシュされます。新しいデータが常に SQL Server に書き込まれ、キャッシュが十分ではない場合、大量のダーティ ページがキャッシュから移動されます。
チェックポイント:チェックポイントが発生すると、SQL Server ではすべてのダーティ ページをディスクにフラッシュする必要があり、このとき、SQL Server のパフォーマンスにある程度の影響があります。チェックポイントが期待どおりの速さで更新されるように、チェックポイントの速度を監視する必要があります。
ページ フォールト:ページ フォールトが発生すると、必要なページが SQL Server が管理できるメモリ領域の外にあることを意味します。ページフォールトが発生すると、プログラムの実行が停止され、待機状態に設定されます。オペレーティング システムは、要求されたアドレスをディスク内で検索します。ページが見つかると、オペレーティング システムはそのページをディスクから空き RAM ページにコピーします。オペレーティング システムにより、プログラムは実行を継続できます。
成長時間を記録する
SQL Server データベース エンジンは、データ変更プロセスの実行時、データベース テーブルまたはインデックスの作成または削除時、ページの割り当てまたは削除時、SQL トランザクションの開始時など、データベース内のすべての操作のログ レコードを書き込みます。または終了しました。ログは、システムまたはハードウェア障害が発生した場合に、データベースを特定の時点に復元するのに役立ちます。過剰なログ操作を伴う高度なトランザクション システムでは、SQL Server トランザクション ログ ファイルが最大サイズに達するまで急速に増大し、エラー番号 9002 が生成されます。自動拡張オプションが有効になっている場合、基盤となるディスク ドライブの空き領域が不足します。
I/O待ち時間(ストール)時間
I/O 待機時間は、I/O 問題を検出するために使用できるメトリックです。SQL Server がファイルにデータを書き込むとき、またはファイルからデータを読み取るとき、I/O 待機時間として表される長時間待機する必要があります。長い一時停止時間は、I/O の問題とビジーなディスク アクティビティを示します。ファイル I/O はデータベースのクリティカル パスに属しており、待ち時間は SQL Server の読み取りおよび書き込みにおけるクライアントの遅延を直接反映します。
各データベースには異なるファイルが保存され、異なる記憶メディアが使用される場合があります。そのため、全体のI/O待ち時間を監視するだけでなく、データベースごとのI/O待ち時間も監視し、運用保守を目的とした最適化を行う必要があります。
接続メトリクス
SQL Server では、クエリの実行はクライアント接続の確立と維持に依存します。SQL Server の可用性と高いパフォーマンスを維持する必要がある場合、接続の監視は運用および保守作業の優れたエントリ ポイントです。SQL Server への同時接続が多すぎると、サーバーが過負荷になる可能性があります。接続が正常に確立されると、接続が使用されているかどうかに関係なく、各接続でオーバーヘッドが発生します。
ストレージメトリクス
前述したように、SQL Server はデータをディスクに保存しますが、キャッシュ プールの存在により、SQL Server のメモリ使用量にも注意する必要があります。デフォルトでは、SQL Server は利用可能なシステム リソースに基づいてメモリ要件を動的に管理します。SQL Server がより多くのメモリを必要とする場合、SQL Server はオペレーティング システムにクエリを実行して空き物理メモリが利用可能かどうかを確認し、利用可能なメモリを使用します。オペレーティング システムの使用可能なメモリが不足している場合、SQL Server は、メモリ不足状態が緩和されるか、SQL Server がサーバー メモリの最小制限に達するまで、メモリをオペレーティング システムに解放します。
パフォーマンス
トランザクション処理速度(TPS)
トランザクションとは、クライアントが SQL Server に要求を送信し、SQL Server が応答するプロセスを指します。クライアントは、クエリ要求の送信時に計測を開始し、SQL Server からの応答を受信した後に終了して、使用時間と完了したトランザクションの数を計算します。一般に、SQL Server のパフォーマンスは、1 秒あたりに完了するクライアント リクエストの数によって測定されます。
バッチ処理 (T-SQL) 速度
T-SQL (Transact-SQL) は、Sybase と Microsoft が提供するプログラミング拡張機能のセットで、トランザクション制御、例外およびエラー処理、行処理、宣言された変数などのさまざまな機能を構造化照会言語 (SQL) に追加します。SQL Server と通信するすべてのアプリケーションは、T-SQL ステートメントをサーバーに送信することによって通信を行います。
指標の詳細な定義
システムインジケーター
読み書き能力の指標
接続メトリクス
ストレージメトリクス
パフォーマンス

市場を監視する
デフォルトで SQL Server の概要が提供されます。
概要
このパネルでは、SQL Server の稼働時に注目すべき指標が表示されます。SQL Server の状態を確認する場合は、まず概要で異常な状態がないかを確認し、次に特定の指標を確認します。
- 起動ステータス: 緑色は正常な動作を示し、赤色は異常な動作を示します
- メモリ使用量: 赤、黄、緑の色のプロンプトを使用します。メモリ使用量が 80% 未満の場合は緑色、メモリ使用量が 80% ~ 90% の場合は黄色、メモリ使用量が 90% を超える場合は黄色になります。 、 それは赤いです。

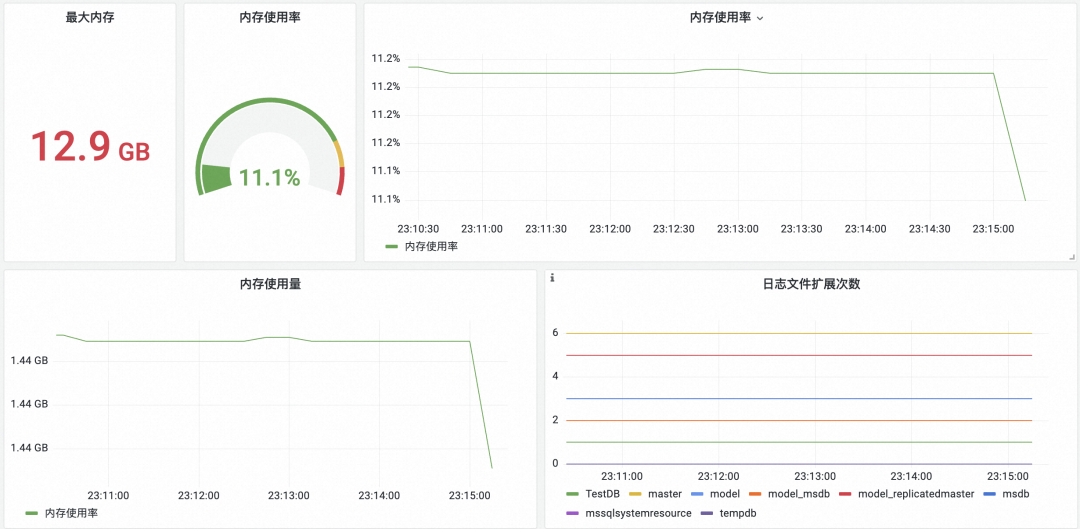
リソース
メモリは SQL Server の主要なハードウェア リソースです。このパネルを通じて、SQL Server のメモリ使用量を理解できます。
- 最大メモリ: メモリの全体的なステータスを提供します。
- メモリ使用量/使用量: メモリ使用量の傾向を分析します。
- ファイル拡張子数:稼働データ量の傾向を分析
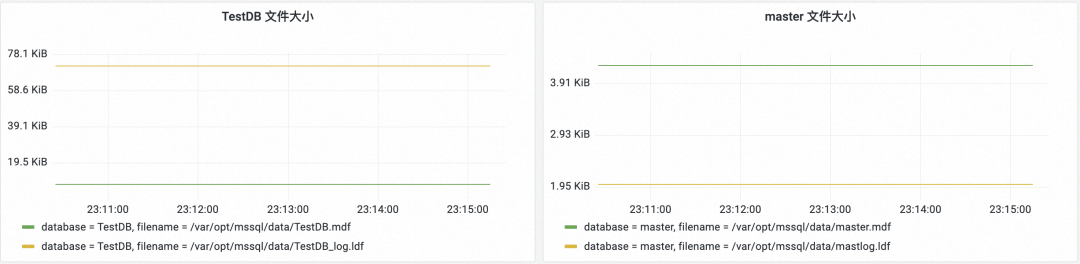
- データベースファイルサイズ:データベースに保存されているデータ量の傾向とログ保存量の傾向を表示します。
パフォーマンス
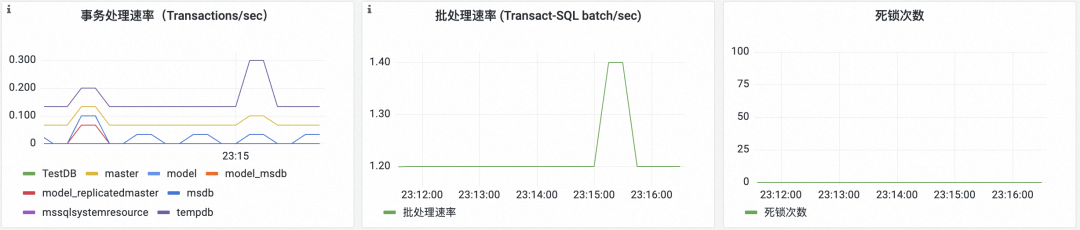
次のパネルでは、SQL Server の運用効率が次の 3 つのカテゴリに分類されて表示されます。
- トランザクション処理速度: SQL Server によって 1 秒あたりに処理されるトランザクションの数を示します。これは、クライアント クエリ要求の遅延に直接影響します。
- バッチ処理速度: SQL Server が 1 秒あたりに処理できる Transact-SQL の数を示します。
- デッドロックの数: パフォーマンスに重大な影響を与える、データベースの競合によってデッドロックが発生したかどうかを検出します。
読み書き
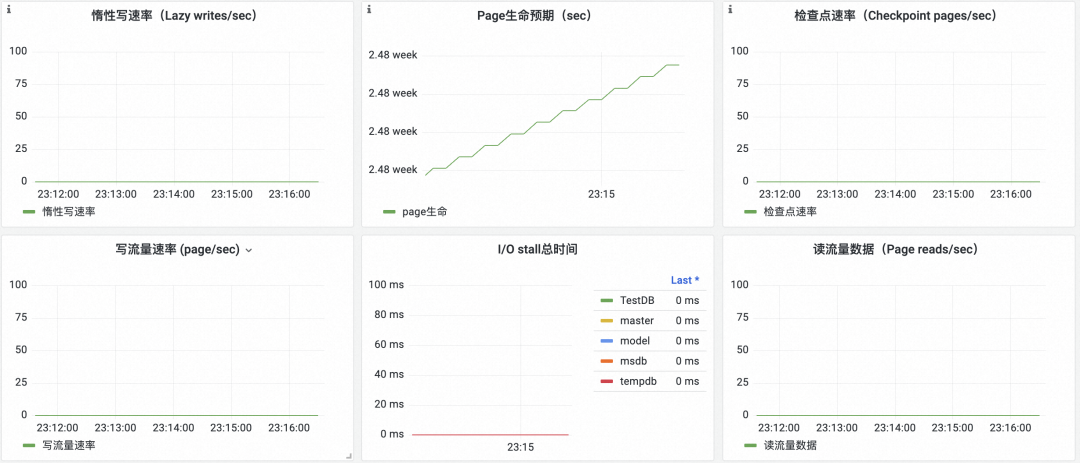
次のパネルで SQL Server の動作効率を確認できます。
- 読み取りおよび書き込みページのレート: 読み取りおよび書き込みページのレート傾向、予想レートに達しているかどうか、ピークと谷が発生しているかどうかなどを監視します。
- 遅延書き込み速度: ダーティ ページの速度傾向を定期的に入力し、安定しているかどうかを監視します。
- ページの平均寿命: ページの平均寿命は長いほど良いです。
- I/O 待機時間: SQL Server のファイルの読み取りおよび書き込みの待機時間の傾向
- チェックポイント レート: チェックポイントが発生すると、実行レートを監視する必要があります。
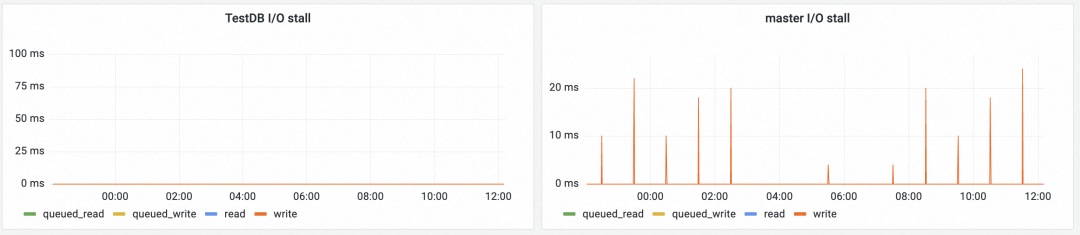
データベース I/O ストール
SQL Server 全体の I/O 待機時間の監視に加えて、データベースの I/O 待機時間も個別に監視する必要があります。各データベースには異なるファイルが保存され、異なるディスクに保存される可能性があるため、対象を絞った最適化ソリューションを作成する必要があります。
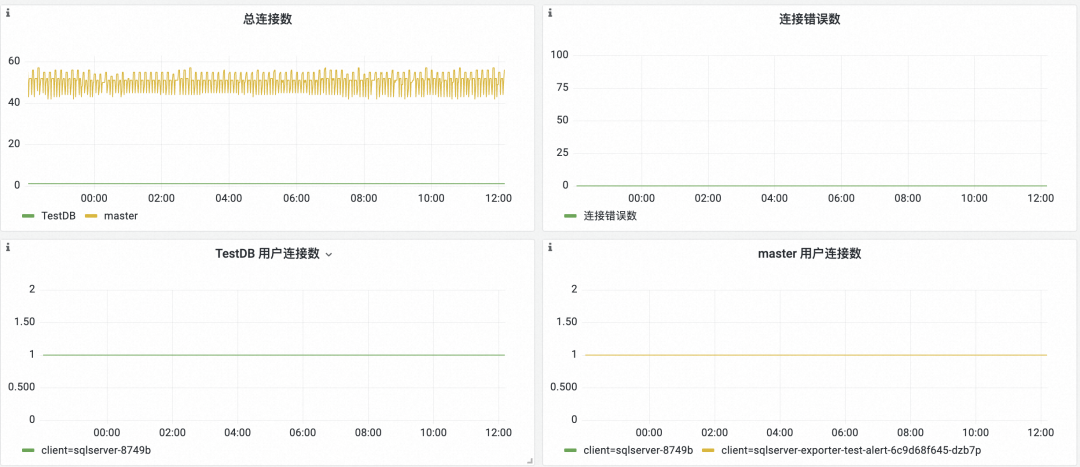
接続する
過剰な同時実行によるパフォーマンスへの影響を防ぐために、SQL Server の接続ステータスを常に確認する必要があります。
- 合計接続数: 全体的な接続数の傾向を監視します
- 接続エラーの数: クライアントに接続エラーがあるかどうかを監視して、システムが正常に動作していることを確認します。
- 各データベースの接続ユーザー: 各データベースに接続しているクライアントを個別に監視し、各クライアントによって開始された接続の数を監視します。
データベースのステータス
各データベースが正常に動作しているかどうかを監視します。次の表にデータベースの状態を定義します。
| 州 | 意味 |
|---|---|
| オンライン | データベースにアクセスできるようになります。リカバリの元に戻すフェーズがまだ完了していない場合でも、プライマリ ファイル グループはオンラインのままです。 |
| オフライン | データベースが使用できません。データベースは明示的なユーザー操作によりオフラインになり、追加のユーザー操作が実行されるまでオフラインのままです。たとえば、ファイルを新しいディスクに移動できるようにデータベースをオフラインにすることができます。次に、移動操作が完了したら、データベースをオンラインに戻します。 |
| 復元中 | プライマリ ファイル グループの 1 つ以上のファイルが復元されているか、1 つ以上のセカンダリ ファイルがオフラインで復元されています。データベースが利用できません。 |
| 回復 | データベースを回復しています。回復プロセスは一時的な状態であり、回復が成功するとデータベースは自動的にオンラインになります。リカバリが失敗した場合、データベースは疑わしい状態になります。データベースが利用できません。 |
| 回復保留中 | SQL Server はリカバリ中にリソース関連のエラーを検出しました。データベースは破損していませんが、ファイルが見つからないか、システム リソースの制限によりデータベースが起動できない可能性があります。データベースが利用できません。問題を解決し、回復プロセスを完了するには、追加のユーザー操作が必要です。 |
| 容疑者 | 少なくともプライマリ ファイル グループが疑わしいか、破損している可能性があります。SQL Server の起動中はデータベースを回復できません。データベースが利用できません。問題を解決するには、追加のユーザー操作が必要です。 |
| 緊急 | ユーザーはデータベースに変更を加え、そのステータスを緊急に設定しました。データベースはシングルユーザー モードであり、修復または復元できます。データベースには READ_ONLY のマークが付けられ、ログ記録は無効になり、アクセスは sysadmin 固定サーバー ロールのメンバーに制限されます。EMERGENCY は主にトラブルシューティングに使用されます。たとえば、「不審」としてマークされたデータベースを EMERGENCY 状態に設定できます。これにより、システム管理者はデータベースへの読み取り専用アクセスが許可されます。sysadmin 固定サーバー ロールのメンバーのみがデータベースを EMERGENCY 状態に設定できます。 |

主要なアラート ルール
SQL Server のアラーム ルールを構成する場合は、上記で収集したインジケーター (実行ステータス、リソース使用量、接続使用量) に基づいて次の側面からアラーム ルールを構成することをお勧めします。一般に、SQL Server の通常の使用に影響を与えるアラーム ルールは、デフォルトで優先度が高く生成されます。読み取り速度や書き込み速度などのビジネス関連のアラームは、ユーザーによってカスタマイズされます。以下に、推奨されるアラート ルールをいくつか示します。
稼働状況
SQLサーバーがダウンしている
SQL Server のダウンタイムは、しきい値が 0/1 のアラーム ルールです。一般に、Alibaba Cloud 環境に展開される ACK などの SQL Server サービスには高可用性機能があり、1 つの SQL Server インスタンスが停止しても、他のインスタンスは動作し続けます。このアラームは、すべての SQL Server が正常に起動できないか、エクスポーター エラーが発生してデータを取得できないことが原因で発生する可能性があります。デフォルトでは、SQL Server が 5 分以内に回復できないというアラームが設定されています。
SQLサーバーの再起動
SQL Server の再起動は、しきい値 0/1 のアラーム ルールです。ほとんどの場合、ログが存在するため、SQL Server でのデータ損失はありません。ただし、SQL Server が再起動されると、キャッシュ プールの内容がクリアされるため、クエリが一時的に遅くなります。実行中のトランザクションをクライアントにロールバックする必要があるため、一連の一時エラーが発生し、クライアントはリクエストを再度開始する必要があります。
リソースの使用量
メモリ使用量が多すぎる
SQL Server のサーバー メモリの使用ポリシーは、使用するメモリと同じ量のメモリを占有することになっており、制限がなければ、ノードのすべてのメモリ リソースを占有する可能性があります。メモリ使用量が高すぎると、SQL Server が適切に実行できなくなります。設定したメモリ使用量のしきい値は、危険値 80%、警告値 90% です。メモリ使用率が 80% の場合、ノードは高負荷で動作しますが、通常の使用には影響しません。メモリ使用率が90%を超える状態が長時間続くと、運用保守リソースの不足を示すアラームが発行されますので、早急に対処する必要があります。
デッドロックが発生する
SQL Server でのデッドロックの発生は、デッドロックの数に関係なく、しきい値が 0/1 のアラーム ルールです。通常、システムで発生するデッドロックの数は非常に少ないですが、デッドロックが発生すると、スレッドによって実行されている現在のバッチを終了し、デッドロックの対象となったトランザクションをロールバックし、クライアントにエラー メッセージをロールバックする必要があります。 。
接続の使用状況
接続エラーが発生しました
SQL Server 接続エラーは、しきい値 0/1 のアラーム ルールです。このエラーは、リモート ホストが既存の接続を強制的に閉じたり、タイムアウトが経過したりするなど、さまざまな理由で発生する可能性があります。操作が完了する前にタイムアウト期間が経過したか、サーバーが応答していない、SSPI コンテキストを生成できないなどです。エラーの原因を確認するには、データベースにログインしてログを確認する必要があります。
典型的な問題のシナリオとそのトラブルシューティング/解決策
SQL Server のパフォーマンスが低い
SQL Server のパフォーマンスの低下は、トランザクション処理速度 (TPS) とバッチ処理 (T-SQL) 速度の低さの指標に反映されています。パフォーマンスの低下にはさまざまな理由が考えられます。トラブルシューティングには複数の指標に問い合わせる必要があります。
メモリ使用量を確認する
- 理由: メモリが不十分な場合、キャッシュ プールはすべてのホットスポット データをキャッシュできず、その結果、複数のデータ アクセス リクエストがディスクに送信されます。
- トラブルシューティング方法: ディスクのメモリ使用量パネルを調べて、メモリ使用量が常に高いかどうかを確認します。アラーム履歴を確認し、メモリリソースが不足していないか確認してください。
- 解決策: 対応するノードのディスク リソースを最適化します。
I/O待ち時間を確認する
- 原因: 長い I/O 待機時間は、I/O 問題と重いディスク アクティビティを示しています。
- トラブルシューティング方法: マーケットの I/O 待ち時間パネルを確認し、I/O 待ち時間が常に長いかどうかを確認します。アラーム履歴を確認し、メモリリソースが不足していないか確認してください。
- 解決策: 多数のピーク アクセスとディスク アクセスの突然の増加が発生する可能性があります。SQL Server アーキテクチャの最適化を検討し、ノードのファイル システムに I/O 問題があるかどうかをさらに確認し、対応するノードのディスク リソースを最適化します。
ログの成長時間を確認する
- 原因: データベースで変更が実行されると、SQL Server は変更をログ バッファに書き込み、バッファ データをディスクに書き込みます。書き込まれるデータが多すぎると、ログの内容を時間内にディスクにフラッシュできなくなります。
- トラブルシューティング方法: マーケットのログ増加時間のパネルを確認し、一定期間内にログ増加時間が急激に増加していないかどうかを確認します。
- 回避策: ログ ファイル用に選択したディスクは、シーケンシャルな読み取りおよび書き込みのスループットと最小限の遅延という点で優れたパフォーマンスを発揮する必要があります。
チェックポイントを確認する
- 理由: チェックポイントを実行すると、SQL Server はメモリ内のすべてのダーティ ページをディスクにフラッシュします。これにより、データベース全体のパフォーマンスが影響を受け、ディスクへの負担が大きくなります。
- トラブルシューティング方法: チェックポイント パネルをチェックして、この期間中にチェックポイント操作が実行されたことを示すチェックポイント レート データがあるかどうかを確認します。
- 解決策: ピーク時間を避けるためにチェックポイントのタイミングを設計します。
監視システム構築
SQL Server を監視する独自の Prometheus を構築する際の問題点
通常、現在の SQL Server は ECS 上にデプロイされているため、SQL Server を監視するために独自の Prometheus を構築する場合、直面する典型的な問題は次のとおりです。
-
セキュリティや組織管理などの理由により、ユーザー サービスは通常、複数の分離された VPC にデプロイされますが、Prometheus は複数の VPC に独立して繰り返しデプロイする必要があるため、デプロイメントおよび運用保守コストが高くなります。
-
完全な自己構築監視システムには、Prometheus、Grafana、AlertManager などのインストールと構成が必要です。プロセスは複雑で、実装サイクルは長くなります。
-
Alibaba Cloud ECS とシームレスに統合されるサービス検出 (ServiceDiscovery) メカニズムが欠如しており、ECS タグに基づいてクロール ターゲットを柔軟に定義できません。同様の機能を自分で実装する場合、Golang 言語を使用してコードを開発し (Alibaba Cloud ECS POP インターフェイスを呼び出し)、それをオープンソースの Prometheus コードに統合し、コンパイルおよびパッケージ化してデプロイする必要があり、実装の敷居が高くなります。 、プロセスが複雑で、バージョンアップが困難です。
-
一般的に使用されているオープン ソースの Grafana SQL Server は、十分に専門的ではなく、SQL Server の原則/機能およびベスト プラクティスに基づいた詳細な最適化が欠けています。
-
SQL Server アラーム インジケーター テンプレートが不足しているため、ユーザーがアラーム項目を自分で調べて設定する必要があり、大きな作業負荷となります。
Alibaba Cloud Prometheus を使用して自作の SQL Server を監視する
- ARMS コンソールにログインします[ 1]。
- 左側のナビゲーション バーで [Prometheus Monitoring] > [Prometheus Instance List] を選択し、監視可能な Prometheus バージョンのインスタンス リスト ページに入ります。
- ターゲットの Prometheus インスタンス名をクリックして、統合センターのページに移動します。
- SQL Server カードの「インストール」をクリックします。

- 関連するパラメータを設定し、「OK」をクリックしてコンポーネントへのアクセスを完了します。

接続されたコンポーネントは、統合センター ページのインストール領域に表示されます。コンポーネント カードをクリックすると、ポップアップ パネルでターゲット、インジケーター、マーケット、アラーム、サービス ディスカバリ設定、エクスポーター、およびその他の情報を表示できます。

以下の図に示すように、監視可能な Prometheus バージョンによって現在提供されている主要なアラーム インジケーターを確認できます。
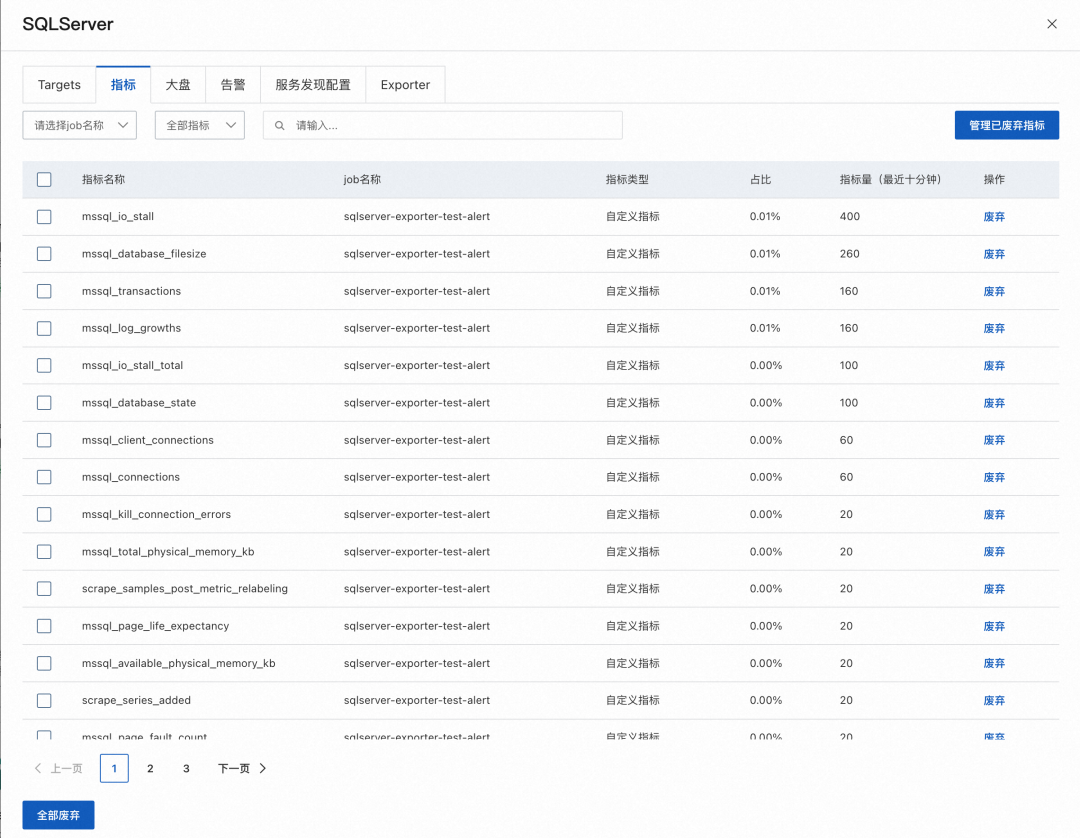
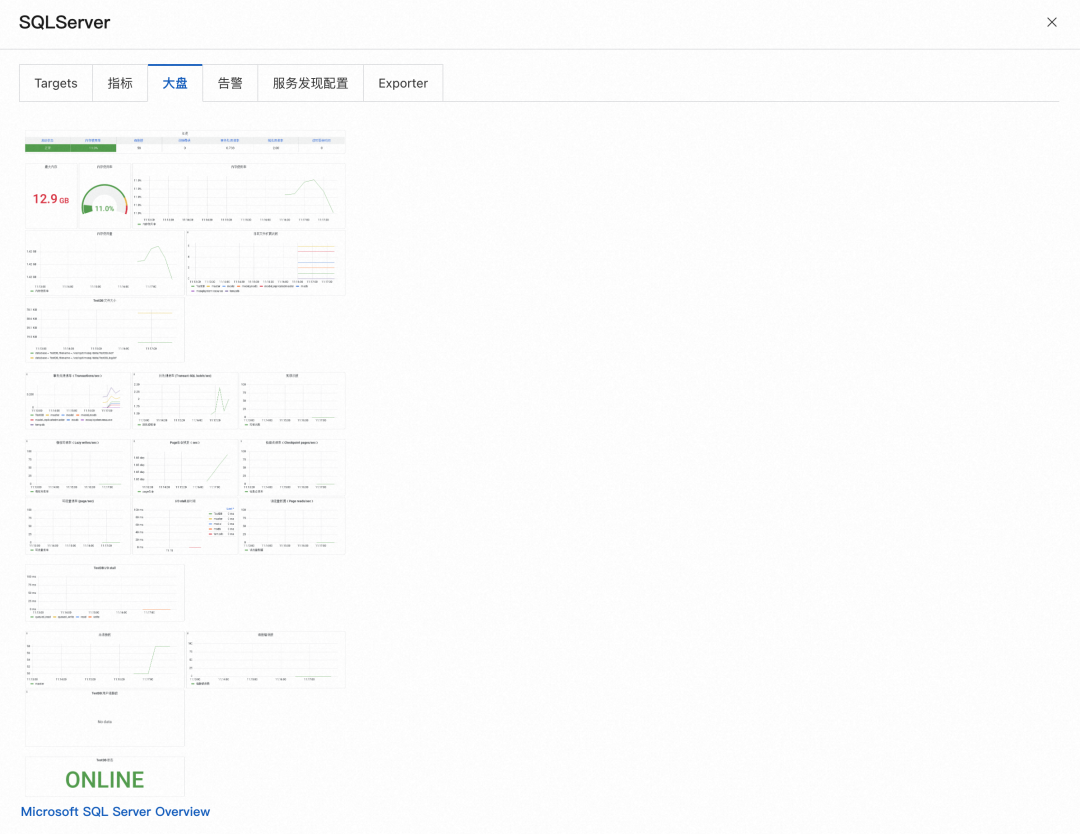
「マーケット」タブのマーケットのサムネイルをクリックすると、対応する Grafana マーケットを表示できます。
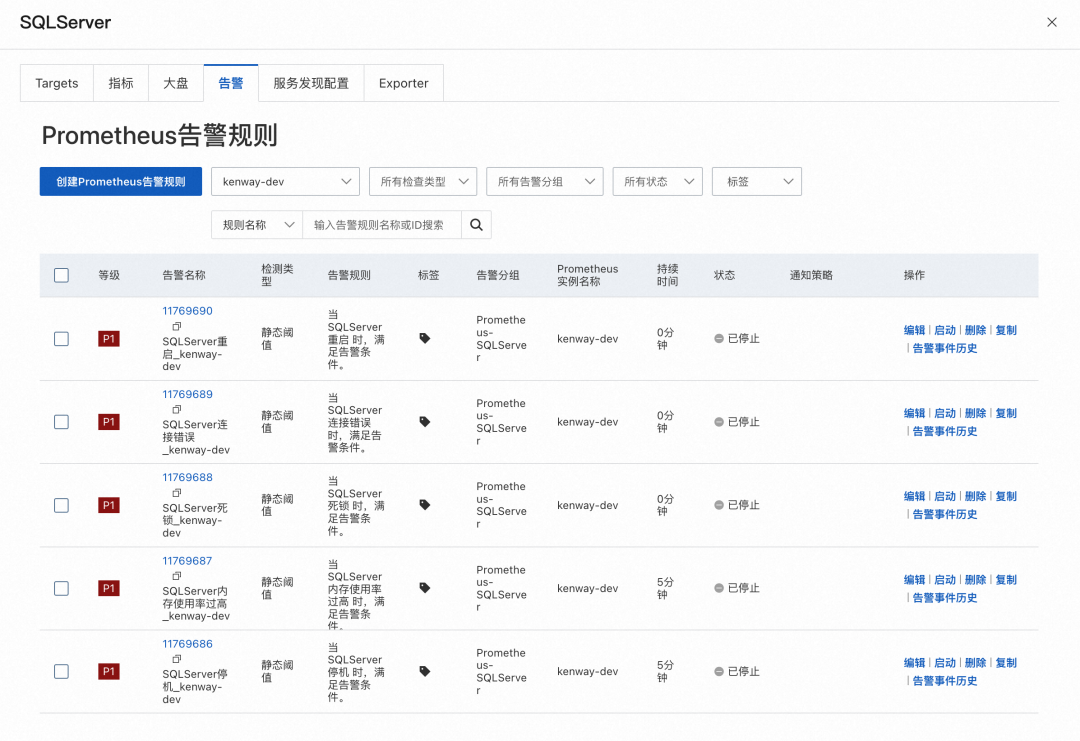
パネルの[アラーム]タブをクリックすると、SQL Server Prometheus アラームを表示できます。ビジネス ニーズに基づいてアラーム ルールを追加することもできます。Prometheus アラーム ルールの作成に関する具体的な操作については、「Prometheus アラーム ルール[ 2] 」を参照してください。
自作 Prometheus と Alibaba Cloud のオブザーバブル監視の長所と短所の比較 Prometheus のバージョン監視 SQL Server

監視可能なモニタリング Prometheus バージョンでは、製品の新規ユーザーに、3 か月間 2,000 万の毎日のカスタム インジケーター レポートの割り当てが提供されます。今すぐ無料で試したい場合は、ここをクリックしてください。
参考リンク:
[2] https://www.sqlshack.com/sql-server-troubleshooting-disk-io-problems/
[8] https://www.sqlshack.com/sql-server-transaction-log-growth-monitoring-and-management/
[9] https://blog.csdn.net/Superman7658/article/details/130799559
関連リンク:
[1] ARMSコンソール
[2] Prometheus アラート ルールhttps://help.aliyun.com/zh/arms/prometheus-monitoring/create-alert-rules-for-prometheus-instances#task-2121615
オープンソース フレームワーク NanUI の作者がスチールの販売に切り替えたため、プロジェクトは中断されました。Apple App Store の無料リストのナンバー 1 はポルノ ソフトウェア TypeScript です。人気が出てきたばかりなのに、なぜ大手はそれを放棄し始めるのでしょうか。 ? TIOBE 10月リスト:Javaが最大の下落、C#はJavaに迫る Rust 1.73.0リリース AIガールフレンドにイギリス女王暗殺を勧められた男性に懲役9年の実刑判決 Qt 6.6正式リリース ロイター:RISC-Vテクノロジーが中米テクノロジー戦争の鍵となる 新たな戦場 RISC-V: 単一の企業や国に支配されない レノボ、Android PC の発売を計画