1つ、CPUの使用
各CPUモードの1秒あたりのレートを計算することから始めます。PromQLには、距離ベクトルの時系列の1秒あたりの瞬間成長率を計算するために使用されるirateと呼ばれる関数があります。`` node_cpu_seconds_total`メトリックでirate関数を使用してみましょう。クエリボックスに入力します。
irate(node_cpu_seconds_total {job = "node"} [5m])
avg(irate(node_cpu_seconds_total {job = "node"} [5m]))by(インスタンス)
ここで、irate関数を平均集計にカプセル化し、インスタンスタグによって集計されるby句を追加します。これにより、すべてのCPUとすべてのモードからの値を使用して、ホストのCPU使用率を平均する、3つの新しいメトリックが生成されます。
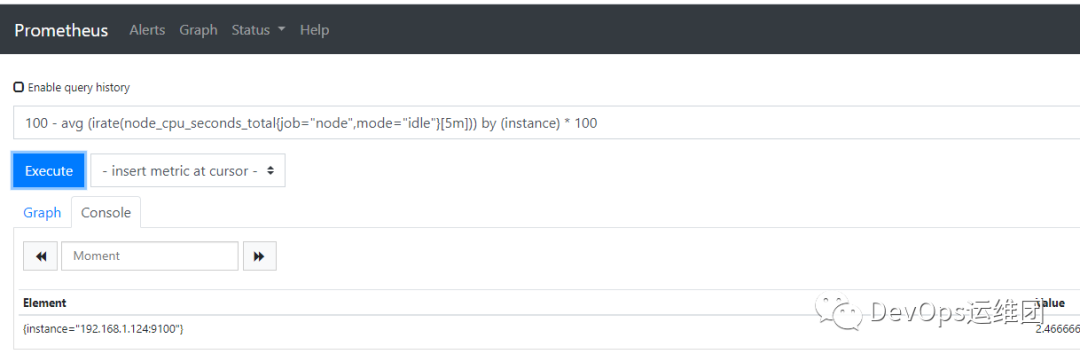
avg(irate(node_cpu_seconds_total {job = "node"、mode = "idle"} [5m]))by(インスタンス)* 100
ここでは、idleの値を持つmodeタグをクエリに追加します。これはアイドルデータのみをクエリします。例を通して結果の平均を見つけ、それを100で乗算します。これで、各ホストで5分間のアイドル使用率の平均パーセンテージが得られました。これをパーセンテージに変換し、次のようにこの値から100を引くことができます。
100-平均(irate(node_cpu_seconds_total {job = "node"、mode = "idle"} [5m]))by(インスタンス)* 100
これで、3つのインジケーターがあります。各ホストに1つのインジケーターがあり、5分間のウィンドウで使用された平均CPUパーセンテージを示しています。
第二に、メモリ使用量
node_memoryのプレフィックスが付いたインジケーターのリストでそれらを見つけます。
node_memoryメトリックのサブセットに焦点を当てて、使用率メトリックを提供します。
•node_memory_MemTotal_bytes-ホストの合計メモリ
•node_memory_MemFree_bytes-ホストのメモリを解放します
•node_memory_Buffers_bytes_bytes-バッファキャッシュ内のメモリ
•node_memory_Cached_bytes_bytes–ページキャッシュ内のメモリ。
これらのインジケータはすべてバイトで表されます。
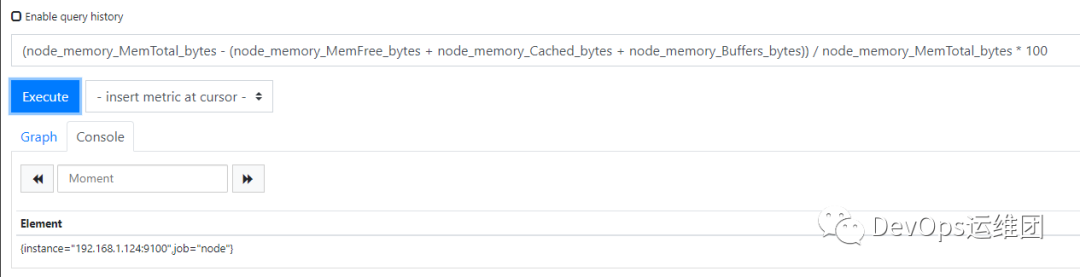
(node_memory_MemTotal_bytes-(node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes))
/ node_memory_MemTotal_bytes * 100
3.ディスク使用量
ディスクの場合、ディスク使用量のみを測定し、使用量、飽和度、またはエラーは測定しません。これは、ほとんどの場合、視覚化とアラートに最も役立つデータであるためです。Node Exporterのディスク使用状況インジケーターは、node_filesystemというプレフィックスが付いたインジケーターのリストにあります。
たとえば、node_filesystem_size_bytesインジケータは、監視されている各ファイルシステムのサイズを示します。メモリメトリックと同様のクエリを使用して、ホストで使用されているディスク領域の割合を生成できます。ただし、メモリメトリックとは異なり、すべてのホストのすべてのマウントポイントにファイルシステムメトリックがあります。そこで、マウントポイントタグ、特にルートファイルシステムの「/」マウントを追加しました。これにより、各ホスト上のファイルシステムのディスク使用量メトリックが返されます。
(node_filesystem_size_bytes {mountpoint = "/"}-node_filesystem_free_bytes {mountpoint = "/"})
/ node_filesystem_size_bytes {mountpoint = "/"} * 100

Grafanaをローカライズでき、mysqlやredisなどの監視テンプレートを同時にインポートできます
↓↓「元のテキストを読む」をクリックします[ DevOps運用および保守チームに参加します]
関連資料:
2. Prometheus + Grafanaをデプロイします
3. Prometheus + Alertmanagerが電子メールアラームを構成します
友達のサークルに共有し、コードをスキャンしてフォローしてください
