この記事は合計 1,310 文字で構成されており、推定読了時間は 5 分です。
目次
探す
ソートされた配列があるとします。以下を参照してください。現在のタスクは、要素が配列内に存在するかどうかを確認することです。

この配列内で値 57 の要素を見つける必要があります。
方法 1: 線形探索
名前が示すように、線形検索ではリストを最初から最後までたどって、各項目の値が探しているものであるかどうかを比較する必要があります。一致する値が見つかると、走査は終了します。
値 57 を見つけます

現在探している値より大きい値が見つかった場合、検索を終了できます (後続の値は探している値よりも大きいだけであるため)。
たとえば、値 35 を見つけるには、

これは良いアプローチでしょうか?
この解決策は可能です。しかし、もう少し注意を払ってみると、配列の順序付けのプロパティが最大限に活用されていないことがわかります。最悪の場合、このアルゴリズムの時間計算量は O(N) になります。探している要素が配列内に存在しない場合、探している値を配列内のすべての要素と比較する必要があります。 。
メソッドをより良く設計できるでしょうか?
もちろん二分探索も使ってみてください
方法 2: 二分探索
二分探索の概念は単純です。あなたが普段どのように英語辞書で単語を調べているかを考えてみましょう。たとえば、辞書で「風変わり」という単語を見つけたい場合、辞書にはそれぞれの単語がすでに配置されているため、辞書の最初のページから最後のページまで順番にめくって単語を見つける必要はありません。単語をアルファベット順に並べ替えます。文字 q の前後のページ番号をすばやくスキップできます。
例に戻って、まず配列の中央にある値 48 を見てみましょう。この値がターゲット値と一致する場合は、検索を直接終了できます。

しかし、値 48 を探していない場合はどうなるでしょうか? 次に、中央の値を使用して、ターゲット値と比較します。ターゲット値がこれより小さい場合は、これより小さい値を見つける必要があります。つまり、48 から開始して、右側の値を考慮せずに左側に向かって検索します。
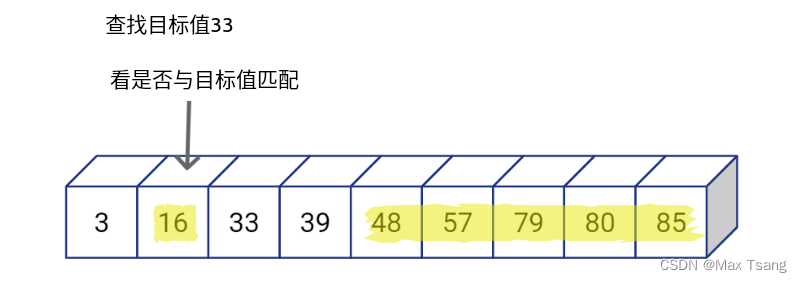
値 33 を見つけます


二分探索を使用すると、検索順序を短縮でき、比較する値の数を半分に減らすことができます。また、「中間値」を選択し続け、目標値と比較して一致するかどうかを判断し、一致しない場合は左に探索するか右に探索するかを決定し続けるという処理を繰り返し続けることができます。検索する配列を継続的に絞り込み、クエリ数を減らすことができます。


現在の時間計算量はどれくらいですか?
アルゴリズムの時間計算量は、比較の数によって決まります。このアルゴリズムを理解していれば、このアルゴリズムの時間計算量は であることがわかるはずです。具体的な導出公式については、「 big O - どのような要素が時間計算量に影響を与えるのか?」を参照してください。
このアルゴリズムは、配列の順序付け特性を最大限に利用します。このアルゴリズムは、多数の値が配列に連続して格納される場合にパフォーマンスを最大限に活用できます。
それで、これは完璧な解決策なのでしょうか?
明らかに、この方法は検索時に非常に労力を節約します。ただし、要素を挿入または削除する場合、シーケンシャル配列はこの状況には適していません。
例えば:
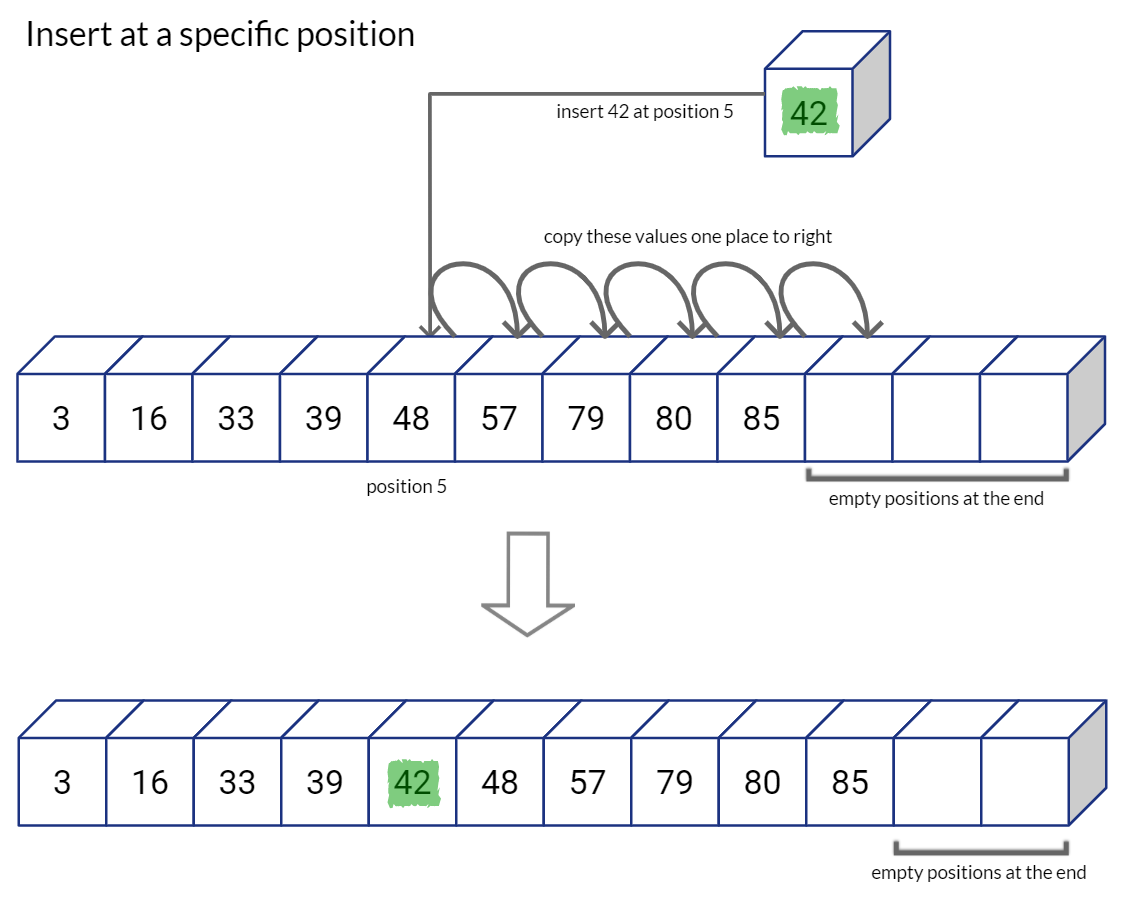
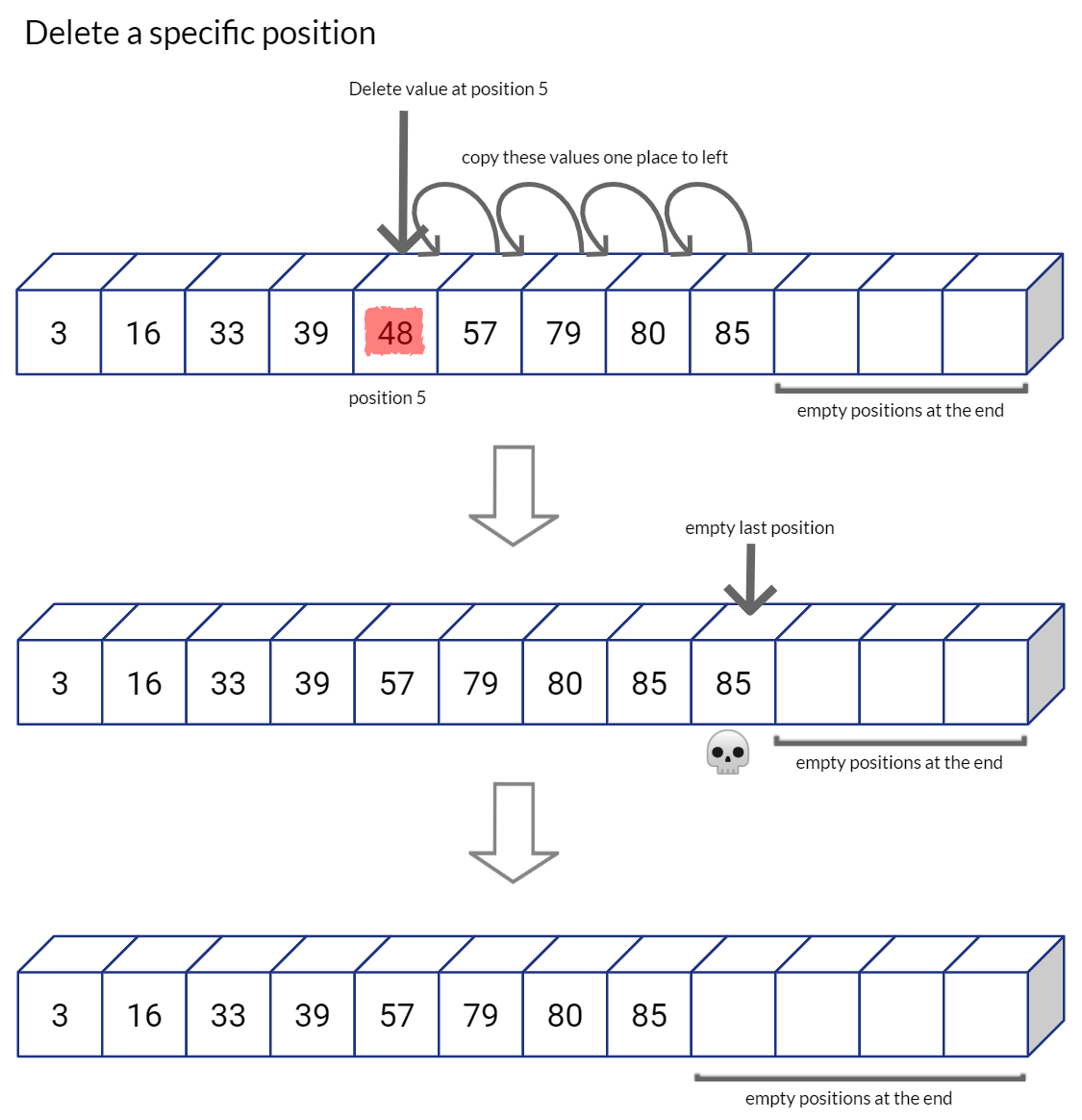
ご想像のとおり、配列の右側に余分なスペースがある場合は、挿入と削除の操作が便利です。そうでない場合は、挿入のたびに動的メモリ割り当てを呼び出し、新しく割り当てられた配列に配列全体をコピーする必要があります。Python の List データ構造は、同様の方法で List を割り当て、将来の拡張に備えてシーケンスの最後に容量を残します。リスト内のスペースが不足すると、Python は新しいより大きなリストを割り当て、古いリストのすべての値を新しいリストにコピーしてから、古いリストを削除します。(これが、Python リストへの挿入の時間計算量がO(1)である理由です)
挿入および削除時のパフォーマンスが向上するデータ構造を構築する、より良い方法はあるでしょうか?
もちろん、それはリンクされたリストです。
翻訳中…