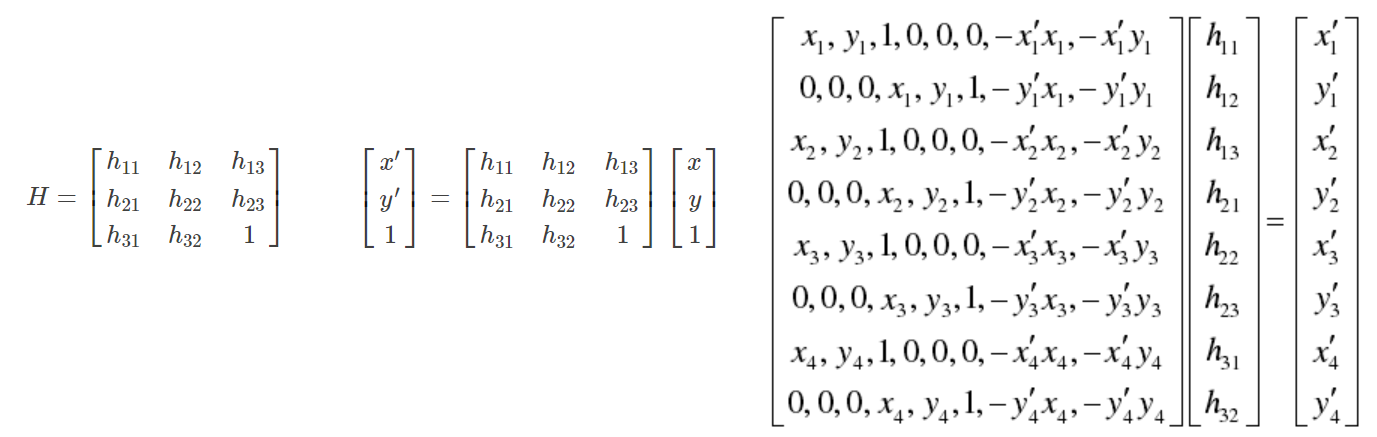opencv 研究ノート 6 -- 画像特徴 [harris+SIFT]+特徴マッチング
画像特徴 (SIFT スケールの不変特徴変換)
画像スケール空間
一定の範囲内であれば、物体が大きいか小さいかに関係なく、人間の目では区別することができますが、コンピュータが同じ能力を持つことは困難であるため、機械が物体を統一的に理解するためには、異なるスケールで存在する画像の特性を考慮する必要があります。
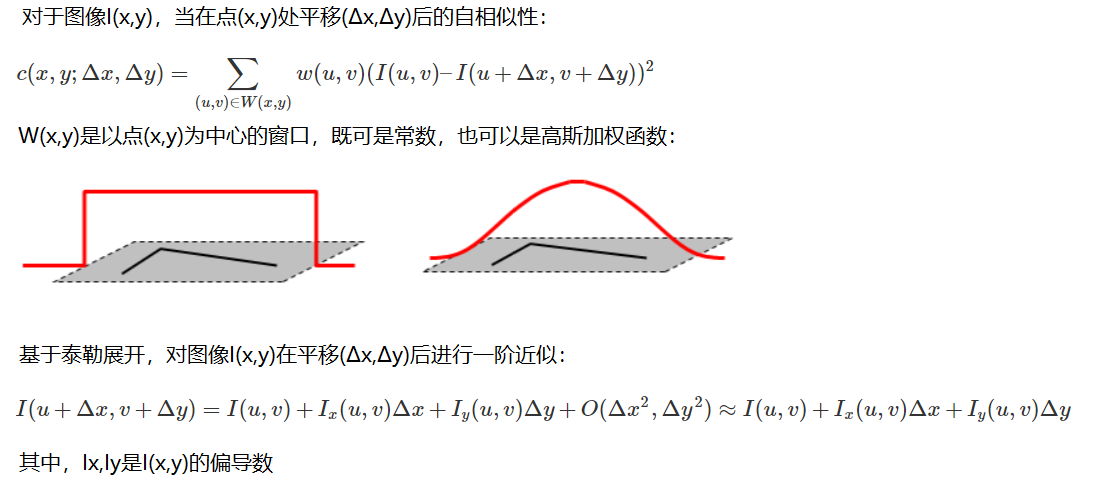
スケール空間の取得は、通常、ガウスぼかしを使用して実現されます。
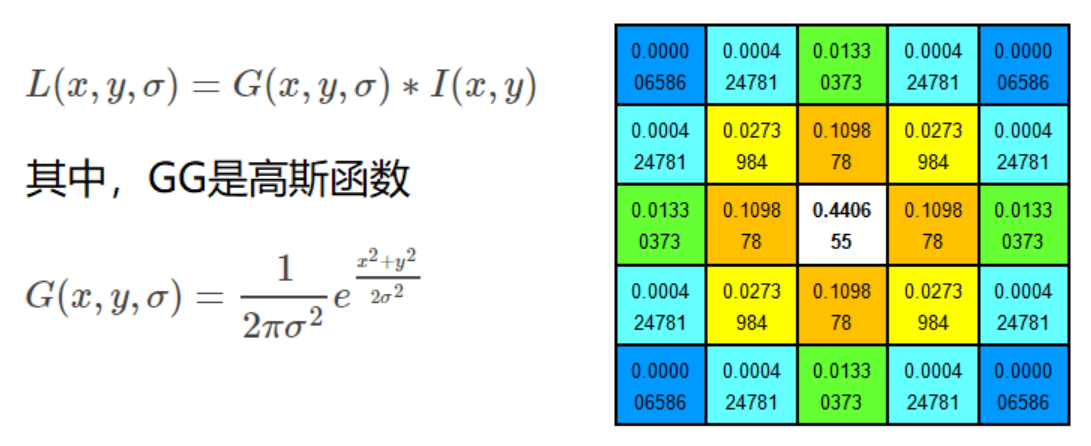

異なる σ を持つガウス関数は画像の滑らかさを決定し、σ 値が大きいほど画像がぼやけます。
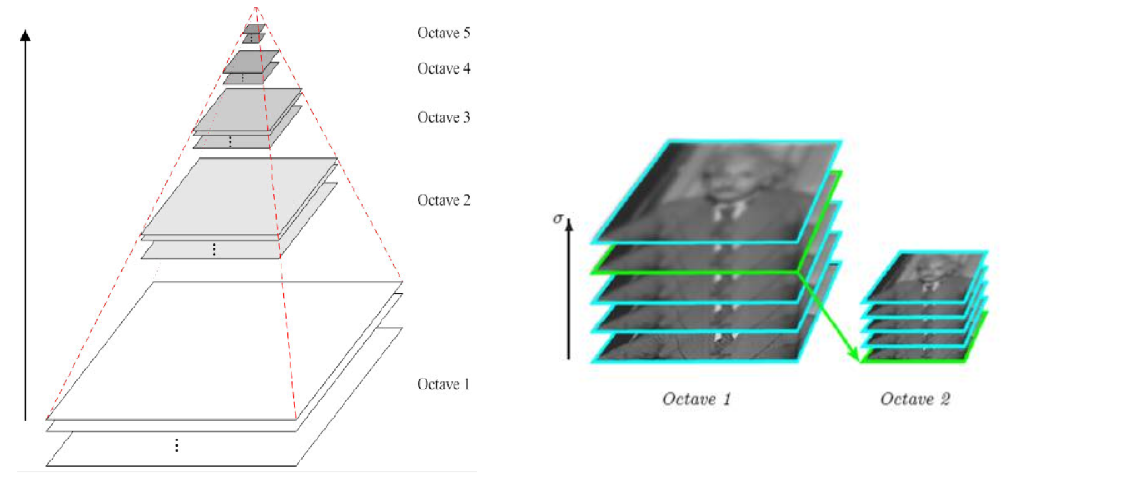
多重解像度ピラミッド
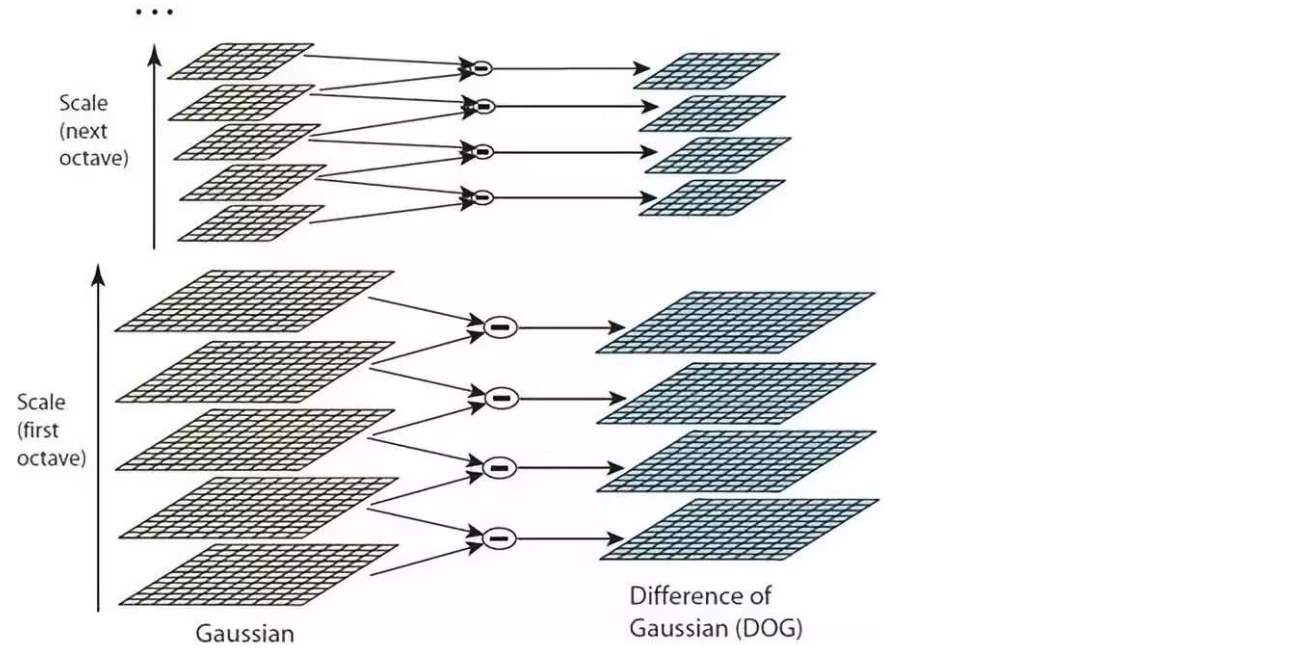
ガウスピラミッド(DOG)の違い
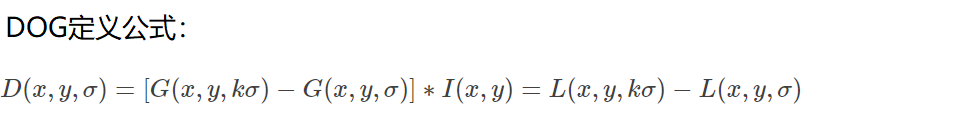
DoG空間極値検出
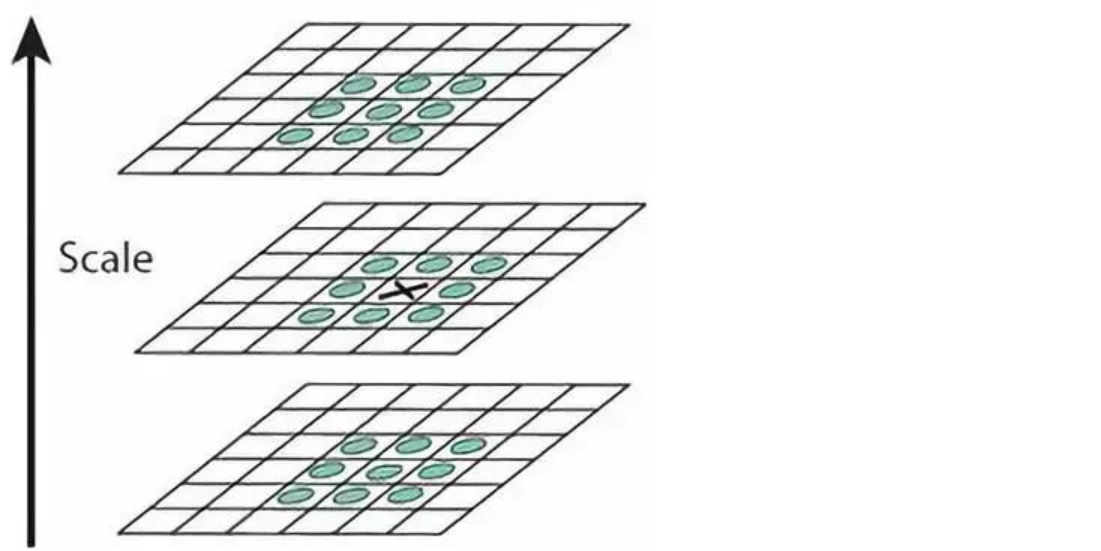
スケール空間の極点を見つけるために、各ピクセル点は、その画像領域 (同じスケール空間) およびスケール領域 (隣接するスケール空間) 内のすべての隣接点と比較されます。対応する点が隣接する点である場合、その点は極点となります。以下の図に示すように、中央の検出ポイントは、それが位置する画像の 3×3 近傍の 8 ピクセルと、隣接する上下のレイヤーの 3×3 エリアの 18 ピクセルと比較する必要があります。合計 26 ピクセル。
重要なポイントの正確な位置決め
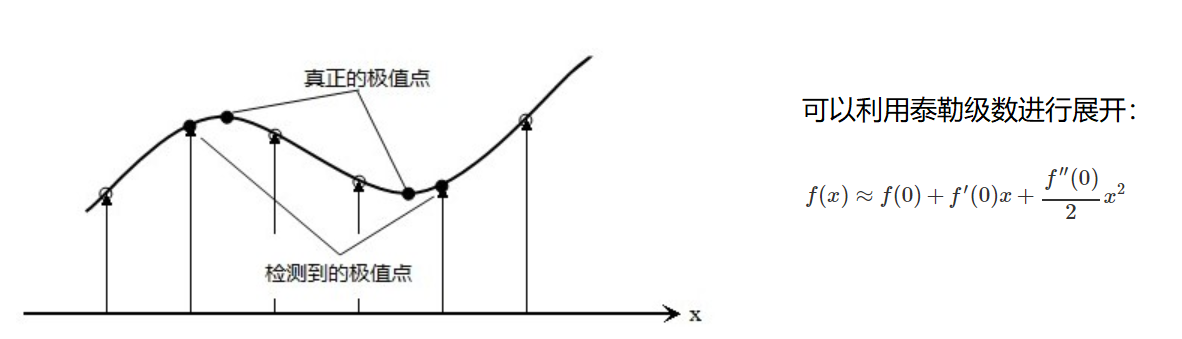
これらの候補キー ポイントは DOG 空間内の局所的な極値点であり、これらの極値点は離散点です。極値点を正確に特定する 1 つの方法は、スケール空間 DoG 関数で曲線フィッティングを実行し、その極値点を計算することにより、正確な値を実現します。重要なポイントの位置決め。
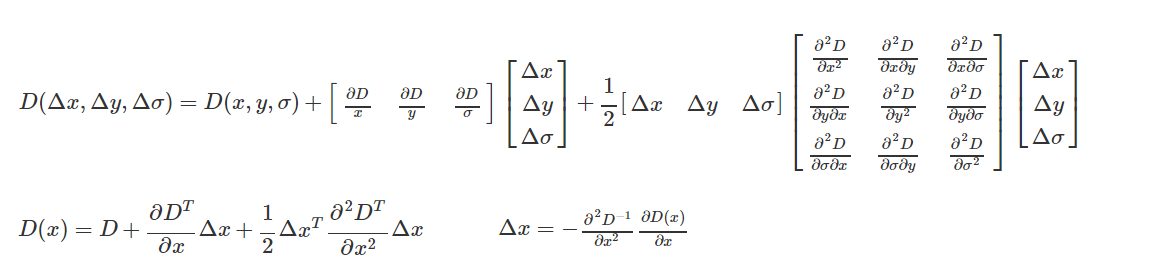
境界線の反応を排除する

特徴点の主な方向

各特徴点は、位置、スケール、方向の3つの情報(x、y、σ、θ)を得ることができます。複数の方向を持つキーポイントを複数のコピーにコピーすると、コピーされた特徴点にそれぞれ方向値が割り当てられ、1 つの特徴点から同じ座標とスケールで方向が異なる複数の特徴点が生成されます。
機能の説明を生成する
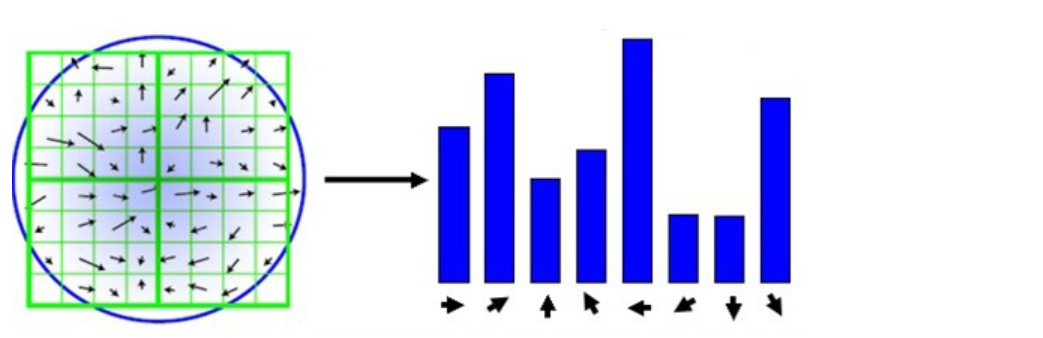
キーポイントの勾配計算が完了したら、ヒストグラムを使用して近傍のピクセルの勾配と方向をカウントします。
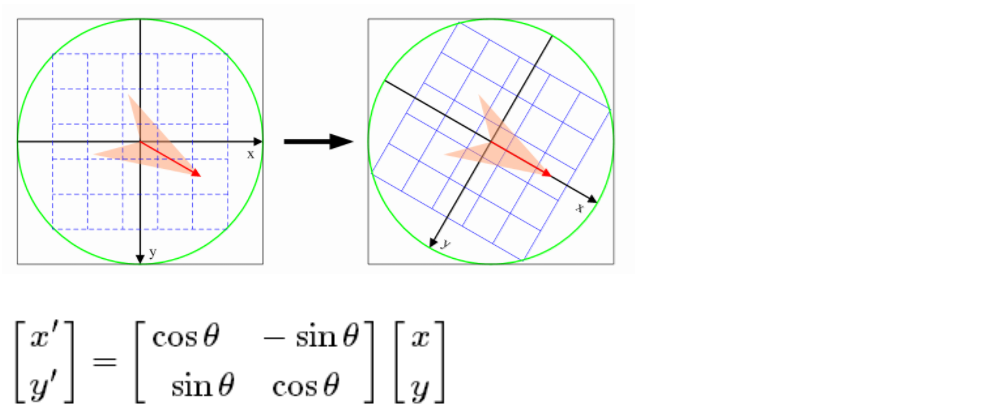
特徴ベクトルの回転不変性を確保するには、特徴点を中心とし、その近傍で座標軸を角度θだけ回転させる、つまり、座標軸を主方向に回転させる必要があります。特徴点の。
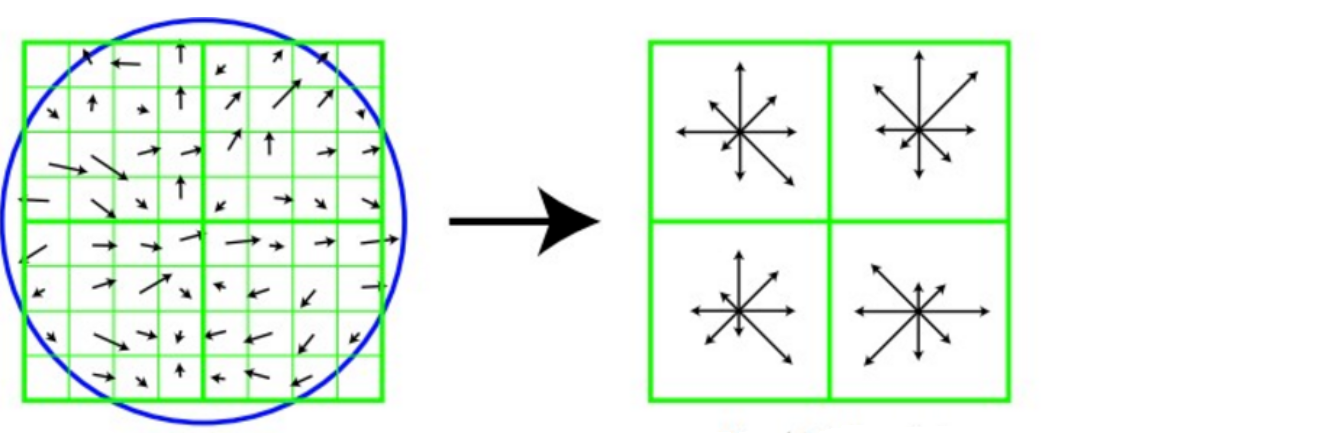
回転後の主方向を中心とした 8x8 ウィンドウを取得し、各ピクセルの勾配の振幅と方向を求めます。矢印の方向は勾配の方向を表し、長さは勾配の振幅を表します。その後、ガウス ウィンドウを使用して重み付けを行いますそれを、最後に各 4x4 で小さなパッチ上に 8 方向の勾配ヒストグラムを描画し、各勾配方向の累積値を計算してシード ポイントを形成します。つまり、各特徴は 4 つのシード ポイントで構成され、各シード ポイントは8 方向のベクトル情報を持ちます。
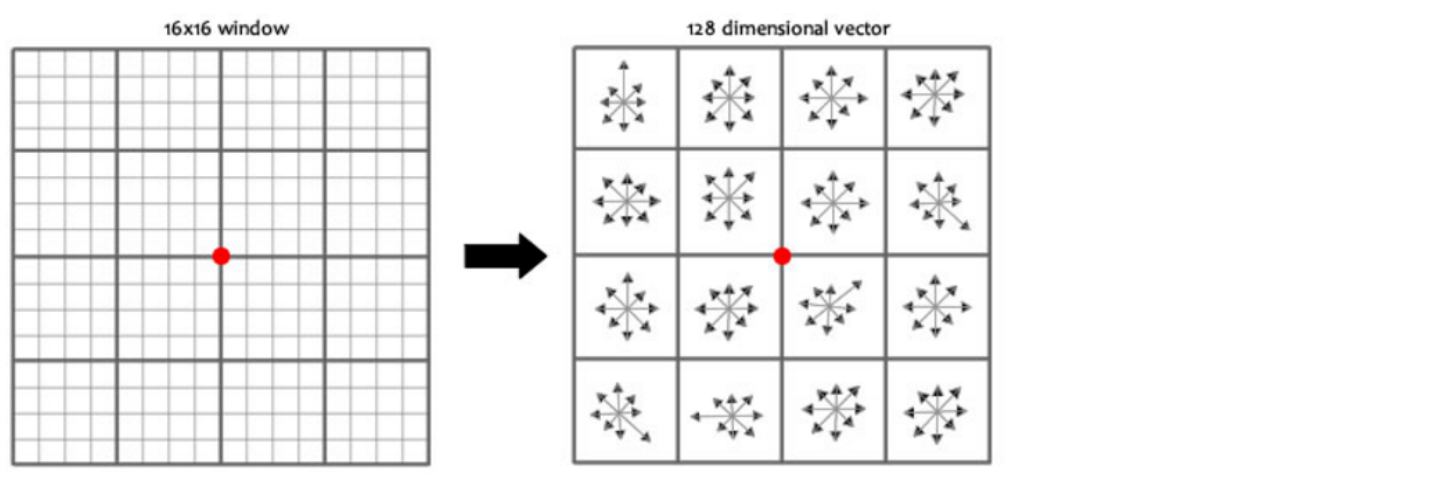
この論文では、キー ポイントが 128 次元の SIFT 特徴ベクトルを生成するように、4x4 合計 16 個のシード ポイントを使用して各キー ポイントを記述することを推奨しています。
opencv SIFT関数
import cv2
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
cv2.__version__ #3.4.1.15 pip install opencv-python==3.4.1.15 pip install opencv-contrib-python==3.4.1.15
'3.4.1'
特徴点を取得する
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
img = cv2.drawKeypoints(gray, kp, img)
cv_show(img,'drawKeypoints')
# cv2.imshow('drawKeypoints', img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()

コンピューティング機能
kp, des = sift.compute(gray, kp)
print (np.array(kp).shape)
(6827,)
des.shape
(6827, 128)
des[0]
array([ 0., 0., 0., 0., 0., 0., 0., 0., 21., 8., 0.,
0., 0., 0., 0., 0., 157., 31., 3., 1., 0., 0.,
2., 63., 75., 7., 20., 35., 31., 74., 23., 66., 0.,
0., 1., 3., 4., 1., 0., 0., 76., 15., 13., 27.,
8., 1., 0., 2., 157., 112., 50., 31., 2., 0., 0.,
9., 49., 42., 157., 157., 12., 4., 1., 5., 1., 13.,
7., 12., 41., 5., 0., 0., 104., 8., 5., 19., 53.,
5., 1., 21., 157., 55., 35., 90., 22., 0., 0., 18.,
3., 6., 68., 157., 52., 0., 0., 0., 7., 34., 10.,
10., 11., 0., 2., 6., 44., 9., 4., 7., 19., 5.,
14., 26., 37., 28., 32., 92., 16., 2., 3., 4., 0.,
0., 6., 92., 23., 0., 0., 0.], dtype=float32)
画像の特徴 - ハリスコーナー検出
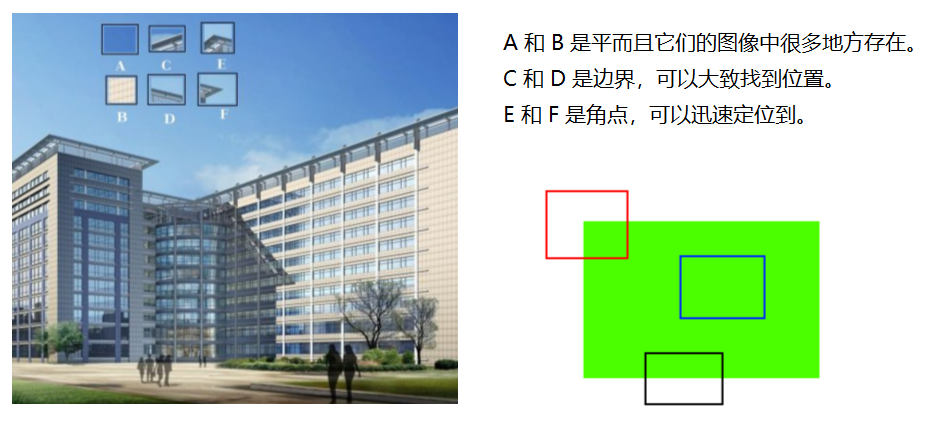
基本的
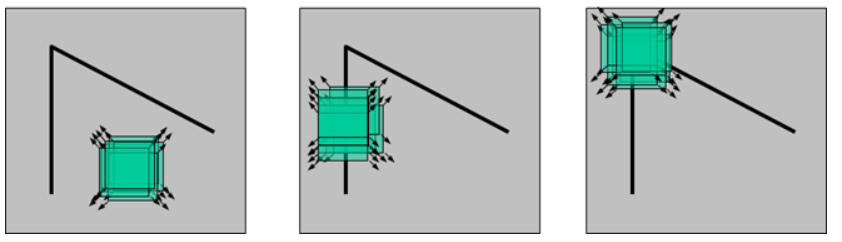
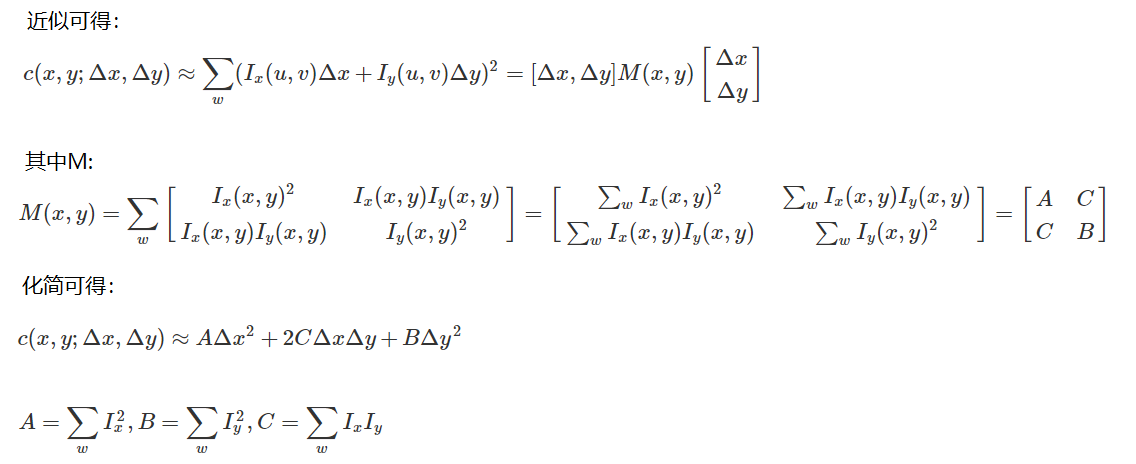
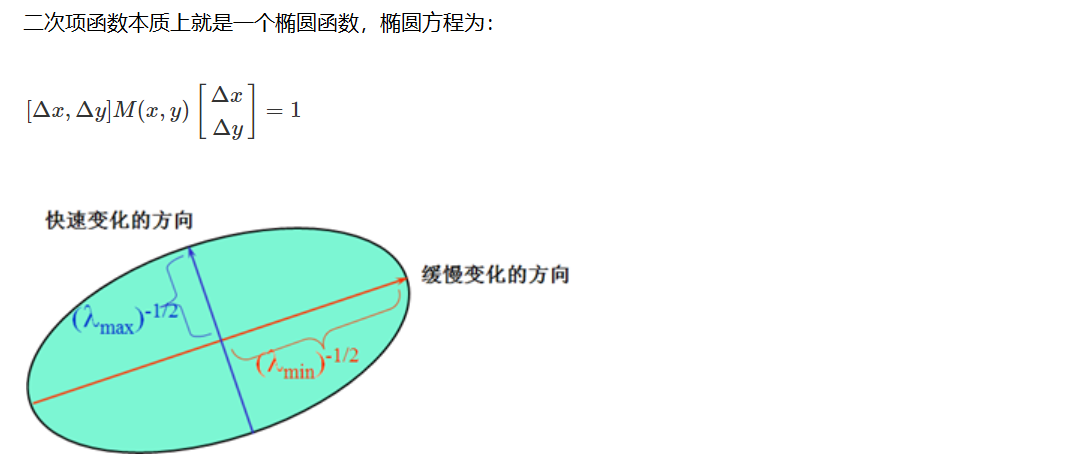
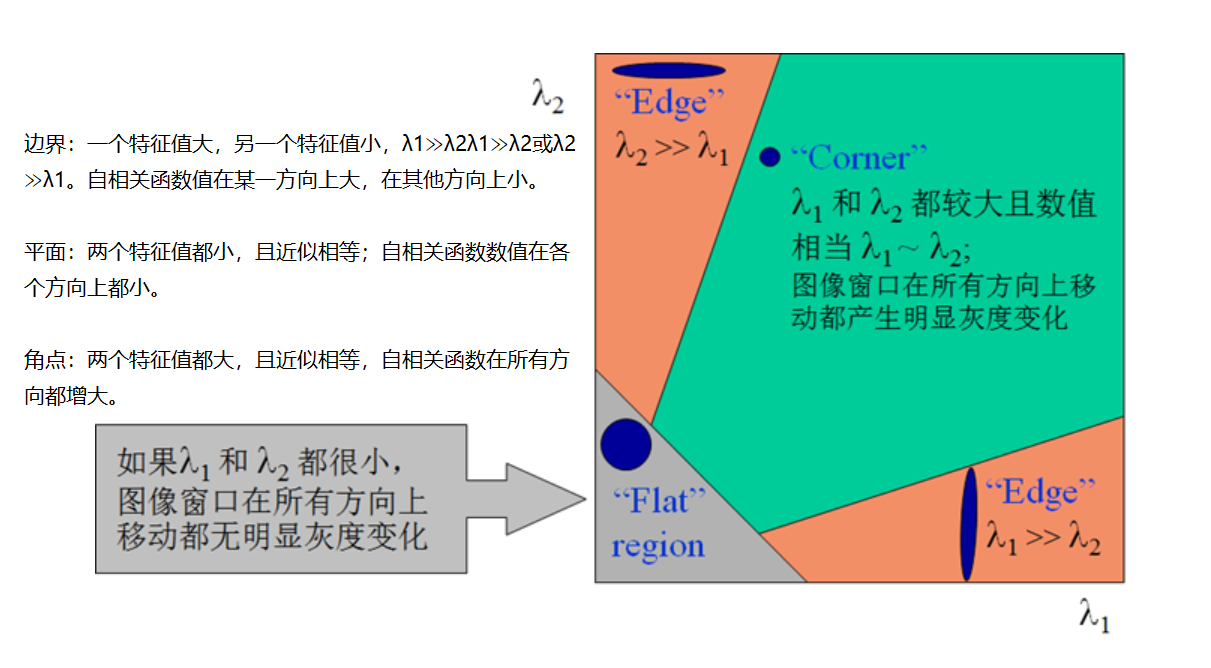

cv2.cornerHarris()
- img: データ型 float32 の入力画像
- blockSize: コーナー検出時の指定領域のサイズ
- ksize: ソーベル導出で使用されるウィンドウ サイズ
- k: 値パラメータは [0,04,0.06]
import cv2
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
img = cv2.imread('chessboard.jpg')
print ('img.shape:',img.shape)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray)
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print ('dst.shape:',dst.shape)
img.shape: (512, 512, 3)
dst.shape: (512, 512)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
img[dst>0.01*dst.max()]=[255,255,255]
cv_show(img,'dst')
# cv2.imshow('dst',img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()

特徴マッチング
ブルートフォースブルートフォースマッチング
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
def cv_show(img,name):
b,g,r = cv2.split(img)
img_rgb = cv2.merge((r,g,b))
plt.imshow(img_rgb)
plt.show()
def cv_show1(img,name):
plt.imshow(img)
plt.show()
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
cv_show1(img1,'img1')

cv_show1(img2,'img2')

sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True) #蛮力匹配
1対1の試合
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)#排序
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
cv_show(img3,'img3')

k 個のベストマッチ
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)#1对K匹配
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
cv_show(img3,'img3')

操作をより速く完了する必要がある場合は、 cv2.FlannBasedMatcher を使用してみてください。
ランダム サンプル コンセンサス アルゴリズム (RANSAC)
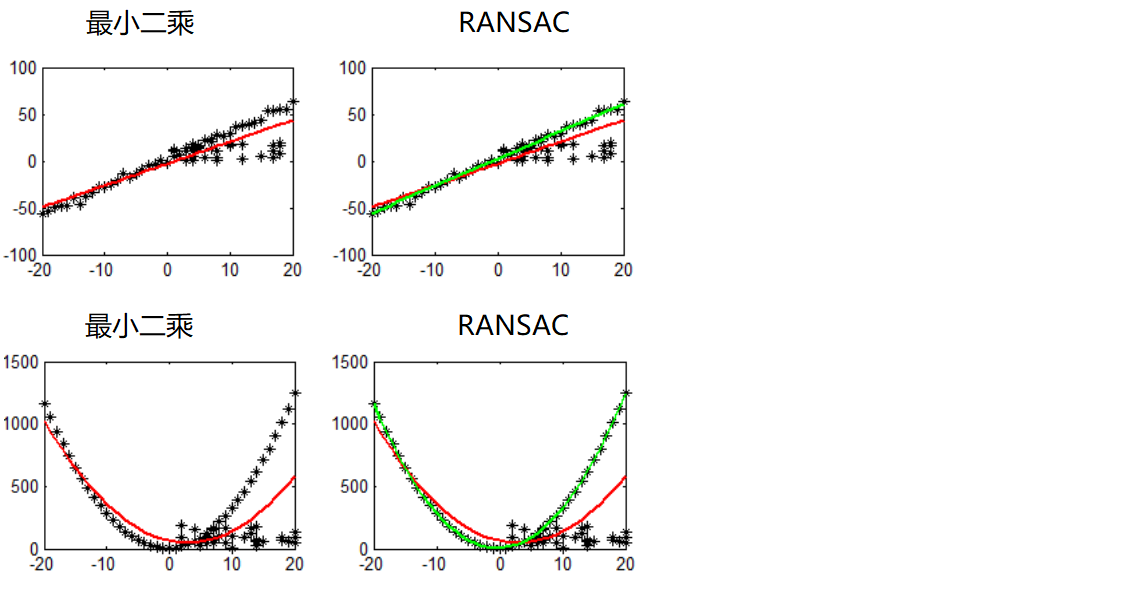
フィッティングのための最初のサンプル点を選択し、許容範囲を指定して、反復を続けます
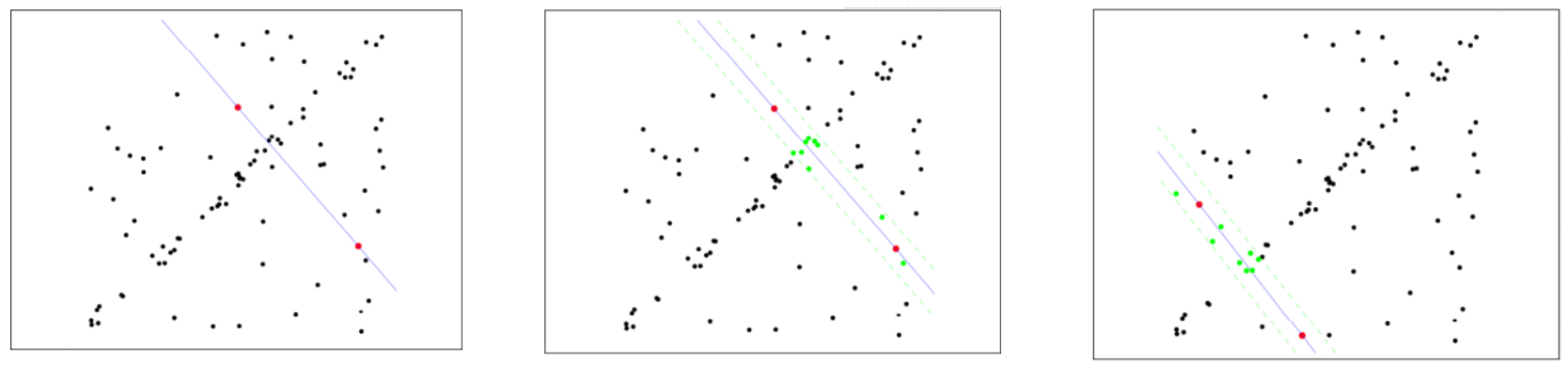
各フィッティングの後、許容範囲内に対応する数のデータ ポイントが存在します。データ ポイントの数が最大となる状況を見つけます。これが最終的なフィッティング結果です。
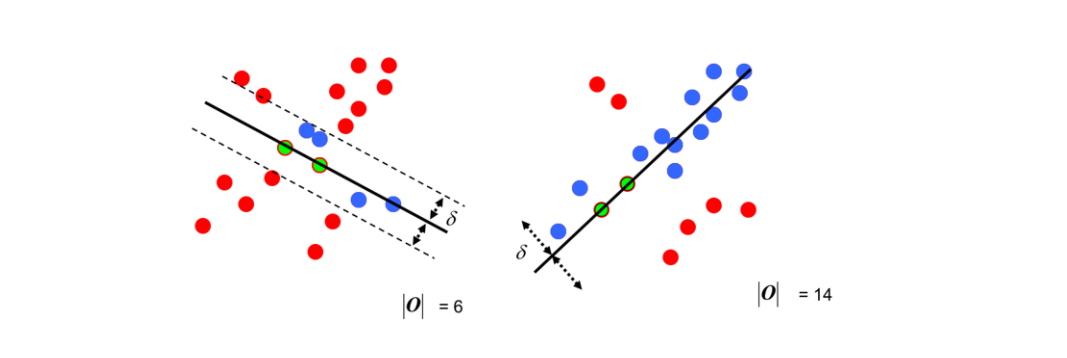
ホモグラフィー行列