1. プレフィックスツリーの導入と定義
プレフィックス ツリーは、高速検索の一致、機密性の高い単語の一致と置換、記事の複数の単語の一致検索と強調表示などのシナリオでよく使用されるマルチツリー構造です。
1. プレフィックスツリーの定義
(1). プレフィックス ツリーのルート ノードには文字が含まれません。
(2). リーフ ノードを除き、プレフィックス ツリー内のどのノードにも文字が含まれており、どのノードにも n 個の子ノードが含まれる場合があります。
(3). ルート ノードを除く接頭辞ツリー内の各ノードは、それが単語の終わりであるかどうかを示す識別子を持つ必要があります。
(4).接頭辞ツリーの葉ノードは単語の終わりでなければなりません。
2. プレフィックスツリーの構造
次の 14 個の単語があるとします。
"張三峰"、"張三峰"、"張三峰"、"張三峰は犬です"、"張泉"、"張李"、"張三峰"、"張三峰"、"ファック・ザ・キング"、
"ファック・ザ・キング・シックス」、「ファック・オフ」、「ファック・オフ」
各単語を分割して接頭辞ツリーに配置すると、接頭辞ツリーは次のようになります。
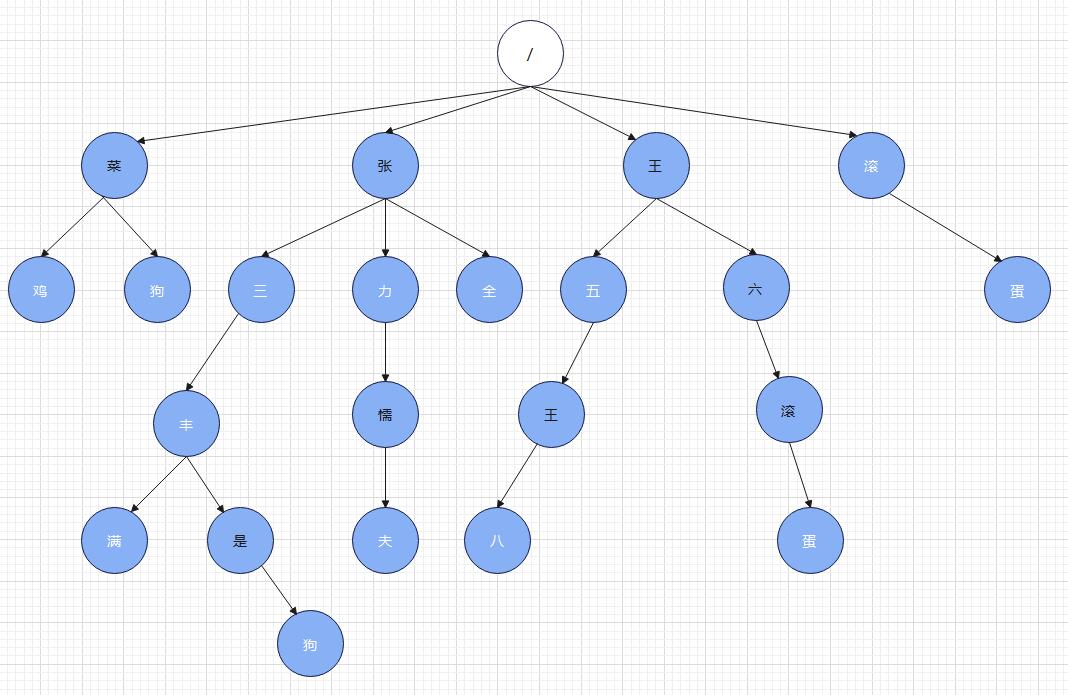
このプレフィックスツリーでは、ノードの文字が語尾である場合、それを示すために白いフォントを使用します。つまり、ノードの文字色が白の場合、ルートノードからノードまでのすべてのノードが、ノードは単語に接続されます。
例:
ルート ノードから開始すると、「ニワトリ」ノードの文字は白になります。これは、ルート ノードからこのノードまでが単語、つまり「ルーキー」が単語であることを意味します。同様に、「ファイブ」は、白の
場合は「王五」が単語、
「八」が白の場合は「王五王八」が単語になります。
したがって、上記のような接頭辞ツリーを与えると、その接頭辞ツリーに「新人」、「張三」、「張三峰」、「張三豊満」、「出て行け」、「」などの単語が含まれていることを簡単に推測できます。出て行け」などの言葉。
2. プレフィックスツリーの実装
一般にノードの子ノードを格納するには配列やHashMapを使うことが多いですが、ここでは子ノードを素早く検索できるようにHashMapを使用してノードの子ノードを格納します。
1. 接頭辞ツリーに単語を追加する
(1) 単語の各文字ノードが接頭辞ツリーに存在しない場合は、ルート ノードから単語の各文字ノードを追加し、最後の文字ノードの単語識別子を true に設定します。
(2) 単語の先頭の文字が接頭辞ツリー上にある場合は、接頭辞ツリー上でそのノードを見つけ、その単語の残りの文字ノードをそのノードに追加し、最後の文字ノードの単語識別子を true に設定します。
(3) その単語が接頭辞ツリー上の別の単語の始まりである場合、接頭辞ツリー上で追加される単語の最後の文字ノードを見つけて、その単語識別子を true に設定します。
2. 接頭辞ツリーから単語を削除します。
削除する単語が接頭辞ツリーにあるかどうかを判断する必要がある状況は数多くあります。削除する単語が接頭辞ツリーにある場合は、次のようになります。
(1) 削除する単語の最後の文字の子ノードの下にノードがなく、単語の他の子ノードの下に子ノードが 1 つだけある場合、単語をルート ノードから削除できます。または、単語は 1 つの単語のみで、他の子ノードはその下に子ノードがない場合は、ルート ノードからこの単語を削除することもできます。
例如:前缀树上张开头的词语只有一个 "张力懦夫" ,如果要删除该词语可以从根节点直接删除。
(2) 最後の文字ノードの下に子ノードがある場合は、最後の文字ノードの単語識別子を false に設定します。
例如:前缀树上张开头的词语只有两个 "张力懦夫" 和 "张力懦夫啊" ,如果要删除词语 "张力懦夫" 只能将 "夫" 这个节点下的词语标识设置为 false,不能删除任何节点,否则会影响另一个词。
(3) 単語の最後の文字ノードの下に子ノードがなく、最後の文字ノードに最も近い他のノードの子ノードの数が 1 より大きいか、単語フラグが true の場合、単語は削除されます。残りの文字ノードはプレフィックス ツリーから削除されます。
例如:前缀树上张开头的词语只有两个 "张力" 和 "张力懦夫啊" ,要删除"张力懦夫啊",只能删除 "力" 这个字符节点下的 "懦夫啊" ;
前缀树上张开头的词语只有两个 "张力懦夫吗" 和 "张力懦夫啊" ,要删除"张力懦夫啊",只能删除 "啊" 这个字符节点;
3. 接頭辞ツリーを使用した単語識別の場合:
単語に別の単語が含まれているかどうかを区別する必要があり、含まれている場合は、マークする最長の単語を見つける必要があります。
如:前缀树上有 "张力" 、 "张力懦夫啊"、"王五" 三个词,需要标记的文本是 "王五张力是谁?王五张力懦夫啊",最终标记的结果是 "【王五】【张力】是谁?【王五】【张力懦夫】啊" ,而不能是 "【王五】【张力】是谁?【王五】【张力】懦夫啊"
他の接頭辞ツリー内の機密単語を置き換えたり、単語が接頭辞ツリーに含まれるかどうかを判断したりすることは比較的簡単ですが、ここでは説明しません。
4. プレフィックスツリーの実装コード
import java.util.*;
/**
* 前缀树
*/
public class TrieTree {
/**
* 前缀树总的词语数
*/
private int size;
/**
* 根节点
*/
private Node root = new Node(new HashMap<>(), false);
private static class Node {
private Map<Character, Node> childNodeMap;
private boolean isWord;
private Node(Map<Character, Node> childNodeMap, boolean isWord) {
this.childNodeMap = childNodeMap;
this.isWord = isWord;
}
public void setIsWord(boolean isWord) {
this.isWord = isWord;
}
public boolean getIsWord() {
return isWord;
}
public Map<Character, Node> getChildNodeMap() {
return childNodeMap;
}
public void setChildNodeMap(Map<Character, Node> childNodeMap) {
this.childNodeMap = childNodeMap;
}
}
/**
* 清空前缀树
*/
public void clear() {
root = new Node(new HashMap<>(), false);
size = 0;
}
/**
* 获取前缀树的词语数
*/
public int size() {
return size;
}
/**
* 向前缀树中增加节点
*/
public void add(String[] addValues) {
if (addValues != null) {
Arrays.stream(addValues).forEach(this::add);
}
}
/**
* 向前缀树中增加节点
*/
public void add(List<String> addValues) {
if (addValues != null) {
addValues.forEach(this::add);
}
}
/**
* 向前缀树中增加节点
*/
public void add(String str) {
if (str == null || str.trim().isEmpty()) {
return;
}
Map<Character, Node> fatherNodeMap = root.childNodeMap;
int index = 0;
int addValueLength = str.length();
while (index != addValueLength) {
char ch = str.charAt(index);
if (fatherNodeMap.containsKey(ch)) {
Node node = fatherNodeMap.get(ch);
if (index != addValueLength - 1) {
if (node.childNodeMap == null) {
node.childNodeMap = new HashMap<>();
}
fatherNodeMap = node.childNodeMap;
} else {
if (!node.isWord) {
node.setIsWord(true);
size++;
}
}
} else {
if (index != addValueLength - 1) {
Node nodeNew = new Node(new HashMap<>(), false);
fatherNodeMap.put(ch, nodeNew);
fatherNodeMap = nodeNew.childNodeMap;
} else {
Node nodeNew = new Node(null, true);
fatherNodeMap.put(ch, nodeNew);
size++;
}
}
index++;
}
}
/**
* 返回前缀树上以 inputStr 开头的词语
*/
public List<String> matchStartWord(String inputStr) {
List<String> matches = new ArrayList<>();
if (root.childNodeMap.size() == 0) {
return matches;
}
Node node = havaWord(inputStr, root, matches);
if (node != null) {
getMatchStr(new StringBuilder(inputStr), new StringBuilder(""), matches, node.childNodeMap);
}
return matches;
}
private void getMatchStr(StringBuilder inputStr, StringBuilder afterStr, List<String> matches, Map<Character, Node> childNodeMap) {
if (childNodeMap != null) {
for (Map.Entry<Character, Node> m : childNodeMap.entrySet()) {
Character key = m.getKey();
StringBuilder afterStr1 = new StringBuilder(afterStr);
afterStr1.append(key);
Node node = m.getValue();
boolean isWord = node.getIsWord();
StringBuilder inputStrOriginl = new StringBuilder(inputStr);
if (isWord) {
matches.add(inputStrOriginl.append(afterStr1).toString());
}
if (node.childNodeMap != null) {
if (!isWord) {
getMatchStr(inputStrOriginl.append(afterStr1), new StringBuilder(""), matches, node.childNodeMap);
} else {
getMatchStr(inputStrOriginl, new StringBuilder(""), matches, node.childNodeMap);
}
}
}
}
}
/**
* 从前缀树中删除词语 str
* 如果 str 每个字符节点下都只有其下一个字符节点,并且最后一个字符节点下没有节点则可以从根节点删除这个词语,否则将词语的最后一个字符的词语标识设置为false
*/
public void deleteWord(String str) {
//判断前缀树上是否有该词语
if (null != str && haveWord(str)) {
int index = 0;
Node deleteNode = null;
Node startNode = root;
char[] charArray = str.toCharArray();
for (int i = 0; i < charArray.length; i++) {
char ch = charArray[i];
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (i != charArray.length - 1) {
Node node = childNodeMap.get(ch);
if (node.childNodeMap.size() > 1 || node.isWord) {
deleteNode = node;
index = i;
}
startNode = node;
} else {
Node node = childNodeMap.get(ch);
Map<Character, Node> childNodeMap1 = node.childNodeMap;
node.isWord = false;
if (null != childNodeMap1 && childNodeMap1.size() > 0) {
//如果该最后一个字符不是叶子节点,即它还有子节点
deleteNode = null;
} else {
//如果该最后一个字符是叶子节点
if (deleteNode == null) {
deleteNode = root;
} else {
index++;
}
}
}
}
if (deleteNode != null) {
Map<Character, Node> childNodeMap = deleteNode.childNodeMap;
if (childNodeMap.size() > 1) {
childNodeMap.remove(str.charAt(index));
} else {
deleteNode.childNodeMap = null;
}
}
size--;
}
}
/**
* 判断前缀树上的所有词语,词语 str
*/
public boolean haveWord(String str) {
if (null == str) {
return false;
}
List<String> list = new ArrayList<>();
havaWord(str, root, list);
return list.size() > 0 && str.equals(list.get(0));
}
/**
* 判断前缀树上的所有词语,是否有 str 开头的
*/
public boolean startWordWith(String str) {
if (null == str) {
return false;
}
List<String> list = new ArrayList<>();
Node node = havaWord(str, root, list);
if (list.size() == 0) {
return node != null;
}
return list.size() == 1 && str.equals(list.get(0));
}
/**
* 判断前缀树上是否有 以 inputStr 开头的词语,
* -有,则返回 inputStr 最后一个字符的子节点,若最后一个节点没有子节点则返回最后一个字符的节点
* 若返回的节点不为 null,且 matches 的大小为 0,则返回的是最后一个字符的子节点(即表明 inputStr 是前缀树上的一个词语的开头,如:前缀树上有 “一生一世” 这个词,但 inputStr 是 “一生一”)
* 若返回的节点不为 null,且 matches 的大小为 1,则返回的是 inputStr 倒数第二个字符的节点(即表明 inputStr 是前缀树上的一个词语,如:前缀树上有 “一生一世” 这个词,但 inputStr 是 “一生一世”)
* -没有,则返回 null
*/
private Node havaWord(String inputStr, Node startNode, List<String> matches) {
char[] charArray = inputStr.toCharArray();
for (int i = 0; i < charArray.length; i++) {
char ch = charArray[i];
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (childNodeMap.containsKey(ch)) {
Node node = childNodeMap.get(ch);
if (node.childNodeMap == null && i != charArray.length - 1) {
return null;
}
if (node.childNodeMap != null || charArray.length == 1) {
startNode = node;
}
if (null != matches && i == charArray.length - 1 && node.isWord) {
matches.add(inputStr);
}
if (i == charArray.length - 1 && node.isWord && node.childNodeMap == null) {
return null;
}
} else {
return null;
}
}
return startNode;
}
/**
* 字符串敏感词替换,若 text 文本中的的词语有在前缀树上的,将其替换为 *
*/
public String sensitiveWordReplace(String text) {
return text != null ? markWordAndWordReplace(text, null, null) : text;
}
/**
* 字符串敏感词标记,若 text 文本中的的词语有在前缀树上的,用 strartSymbol和 endSymbol 将其标记
* 如:
* 例1:
* 假如 "张三"、"今天" 这两个词语在前缀树上
* 当调用 markWord("张三你好,你今天过得怎么样", "【", "】");
* 得到的结果是 "【张三】你好,你【今天】过得怎么样"
*/
public String markWord(String text, String strartSymbol, String endSymbol) {
if (text != null && strartSymbol != null && endSymbol != null) {
return markWordAndWordReplace(text, strartSymbol, endSymbol);
}
return text;
}
//敏感词替换、敏感词标记通用方法
private String markWordAndWordReplace(String text, String strartSymbol, String endSymbol) {
Node startNode = root;
//isMarkWord 为 true 则为敏感词标记,false 为敏感词替换
boolean isMarkWord = strartSymbol != null && endSymbol != null;
//存储最终的结果
StringBuilder result = new StringBuilder();
//若为敏感词替换(也就是isMarkWord为false)starOrCh用于存放* ,即匹配到一个字符就存入* 。若为敏感词标记,则starOrCh用于存放匹配的词
StringBuilder starOrCh = new StringBuilder();
//存放匹配到的字符,即匹配到一个字符就存入
StringBuilder matchCh = new StringBuilder();
int index = 0;
while (index != text.length()) {
char ch = text.charAt(index);
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (childNodeMap.containsKey(ch)) {
starOrCh.append(isMarkWord ? ch : "*");
Node node = childNodeMap.get(ch);
if (node.childNodeMap != null) {
startNode = node;
}
if (node.isWord) {
StringBuilder saveTemp = new StringBuilder(starOrCh);
//判断该字符后的字符在前缀树上是否在该词语的后面(如:text是"张力懦夫",当前字符ch是"张",匹配到"张力"这个词语,但是"张力懦夫"也是个词语,需要向后再判断其是否在前缀树上,并判断其是否是一个词语)
int nextWordEndIndex = nextCh(text, index + 1, index, node);
if (nextWordEndIndex > index) {
int nextStart = index + 1;
StringBuilder temp = new StringBuilder();
temp.append(saveTemp);
for (int i = nextStart; i <= nextWordEndIndex; i++) {
char nextCh = text.charAt(i);
temp.append(isMarkWord ? nextCh : "*");
index++;
}
appendResuleClearTemp(result, temp, matchCh, starOrCh, strartSymbol, endSymbol);
} else {
//将该词语用*号替换拼接到result , 并清空 starOrCh、temMatch
appendResuleClearTemp(result, starOrCh, matchCh, starOrCh, strartSymbol, endSymbol);
}
//重新设置根节点为开始遍历的节点,方便下一个字符匹配
startNode = root;
} else {
matchCh.append(ch);
}
} else {
if (matchCh.length() > 0) {
appendResuleClearTemp(result, matchCh, matchCh, starOrCh);
}
Map<Character, Node> rootChildNodeMap = root.childNodeMap;
if (rootChildNodeMap.containsKey(ch)) {
matchCh.append(ch);
starOrCh.append(isMarkWord ? ch : "*");
startNode = rootChildNodeMap.get(ch);
} else {
result.append(ch);
}
}
index++;
}
return result.toString();
}
private void appendResuleClearTemp(StringBuilder result, StringBuilder joinBuilder, StringBuilder matchCh, StringBuilder starOrCh, String strartSymbol, String endSymbol) {
if (strartSymbol != null) {
result.append(strartSymbol);
}
result.append(joinBuilder);
if (endSymbol != null) {
result.append(endSymbol);
}
matchCh.setLength(0);
starOrCh.setLength(0);
}
private void appendResuleClearTemp(StringBuilder result, StringBuilder joinBuilder, StringBuilder matchCh, StringBuilder starOrCh) {
result.append(joinBuilder);
matchCh.setLength(0);
starOrCh.setLength(0);
}
//返回从text 的 index 下标开始,node 节点下匹配到的最长词语,返回最长的词语的最后一个字符在 text 的下标,即 wordIndex
private int nextCh(String text, int index, int wordIndex, Node node) {
if (index <= text.length() - 1) {
char nextCh = text.charAt(index);
Map<Character, Node> childNodeMap = node.childNodeMap;
if (childNodeMap != null) {
if (childNodeMap.containsKey(nextCh)) {
Node nextNode = childNodeMap.get(nextCh);
if (nextNode.isWord) {
wordIndex = index;
}
return nextCh(text, index + 1, wordIndex, childNodeMap.get(nextCh));
} else {
return wordIndex;
}
}
}
return wordIndex;
}
}
3. プレフィックスツリーの使用とテスト
1. 接頭辞ツリーに単語を追加する
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
TrieTree trieTree = new TrieTree();
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
2. 入力に従って接頭辞ツリー内の単語を照合します。
一般に、Baidu などの検索エンジンは、ユーザーが頻繁に検索するテキストをプレフィックス ツリーに追加します。この方法では、ユーザーは検索ボックスに 1 つまたは 2 つの単語を入力するだけで、検索エンジンは関連する単語を含む一致する単語を返します。プレフィックス ツリーからプレフィックスを選択し、次のリストに追加します。ユーザーが選択しやすいように、プルダウン ボックスの形式で表示されます。
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//匹配前缀树上 "张" 开头的词语有哪些
List<String> matchResult = trieTree.matchStartWord("张");
//输出:[张全, 张三, 张三丰, 张三丰满, 张三丰是狗, 张力, 张力懦夫]
System.out.println(matchResult);
3. 接頭辞ツリーに特定の単語があるかどうかを判断します
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//判断前缀树上是否有 "张三" 这个词语
boolean existWord = trieTree.haveWord("张三");
System.out.println(existWord); //true
//判断前缀树上是否有 "张三四" 这个词语
boolean existWord1 = trieTree.haveWord("张三四");
System.out.println(existWord1); //false
4. 入力文字列が接頭辞ツリーの単語の先頭であるかどうかを判断します。
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//判断前缀树上是否有 "王六滚" 开头的词语
boolean haveStar = trieTree.startWordWith("王六滚");
System.out.println(haveStar); //true
//判断前缀树上是否有 "王六滚蛋" 开头的词语
boolean haveStar = trieTree.startWordWith("王六滚蛋");
System.out.println(haveStar); //true
5. 接頭辞ツリーから単語を削除します。
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
System.out.println("没删除前前缀树含有"+trieTree.size()+"个词语");
trieTree.deleteWord("张三");
System.out.println("删除后前缀树含有"+trieTree.size()+"个词语");
System.out.println("删除后前缀树是否含有词语 \"张三\" :"+trieTree.haveWord("张三"));
出力:
没删除前前缀树含有14个词语
删除后前缀树含有13个词语
前缀树是否含有词语 "张三" :false
6. 機密ワードのフィルタリングにプレフィックス ツリーを使用する
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
trieTree.add(array);
String text = "小张打游戏很厉害,但是张三打游戏真菜鸡。上次我在游戏里说张三菜狗他就生气了。他说滚,我就滚滚蛋了。\n"+
"王五斗地主很厉害,上次王五王炸,张三丰就骂他,我们是队友你炸我干嘛,然后骂王五王八,王五听错了以为张三丰骂的,于是回骂张三丰是狗。\n"+
"然后场面一度失控,旁边的张力也被波及,什么张力懦夫张力滚蛋王五王八王五滚蛋都被乱七八糟的骂!";
//过滤后的文本
String textFilter = trieTree.sensitiveWordReplace(text);
System.out.println(textFilter);
出力:
小张打游戏很厉害,但是**打游戏真**。上次我在游戏里说****他就生气了。他说*,我就***了。
**斗地主很厉害,上次**王炸,***就骂他,我们是队友你炸我干嘛,然后骂****,**听错了以为***骂的,于是回骂*****。
然后场面一度失控,旁边的**也被波及,什么****************都被乱七八糟的骂!
7. プレフィックス ツリーを使用して、デリケートな単語を含む記事やメッセージにマークを付ける
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
trieTree.add(array);
String text = "小张打游戏很厉害,但是张三打游戏真菜鸡。上次我在游戏里说张三菜狗他就生气了。他说滚,我就滚滚蛋了。\n"+
"王五斗地主很厉害,上次王五王炸,张三丰就骂他,我们是队友你炸我干嘛,然后骂王五王八,王五听错了以为张三丰骂的,于是回骂张三丰是狗。\n"+
"然后场面一度失控,旁边的张力也被波及,什么张力懦夫张力滚蛋王五王八王五滚蛋都被乱七八糟的骂!";
//标记后的文本
String mark = trieTree.markWord(text, "【", "】");
System.out.println(mark);
出力:
小张打游戏很厉害,但是【张三】打游戏真【菜鸡】。上次我在游戏里说【张三】【菜狗】他就生气了。他说【滚】,我就【滚】【滚蛋】了。
【王五】斗地主很厉害,上次【王五】王炸,【张三丰】就骂他,我们是队友你炸我干嘛,然后骂【王五王八】,【王五】听错了以为【张三丰】骂的,于是回骂【张三丰是狗】。
然后场面一度失控,旁边的【张力】也被波及,什么【张力懦夫】【张力】【滚蛋】【王五王八】【王五】【滚蛋】都被乱七八糟的骂!