目次
1.4. JavaRestClient に基づいた集計の実装
1. データの集計
1.1. 基本概念
1.1.1. 集約の分類
集計はドキュメント データの統計分析と操作に使用されます。前に学習した mysql と同様に、集計関数もあります。たとえば、平均を見つけるには avg を、最大を見つけるには max を使用できます。グループ化には一致する group by が使用されますが、es も同様の機能があり、より豊富です。
es の集計には 3 つの主要なカテゴリがあります。
1. バケット集約:ドキュメントをグループ化するために使用されます。これは MySQL の group by に似ており、「バケット」という名前で、ゴミを分類するようなもので、さまざまなドキュメントを分類してグループ化する役割を果たします。
バケット集約グループ化には、最も一般的に使用される 2 つのタイプがあります。
TermAggregation: ドキュメントのフィールド値によるグループ化 (これは実際には、mysql のグループ化と同じ効果です)。
データ ヒストグラム: 週ごとに 1 つのグループ、月ごとに 1 つのグループなど、日付ラダーごとにグループ化します。
2. メトリック集計:最大値、最小値、平均値などの文書データのグループごとに計算します。
これは、avg、max、min などの mysql と同じです。
また、es には特別なメトリクス集計 (「統計」) もあり、これを使用して平均、最大、最小などを同時に計算できます。
3. パイプライン集計:他の集計の結果を集計するために使用されます。
たとえば、ホテル データをブランド別にグループ化し、バケット集計して、さまざまなブランドのホテルの平均価格を計算する場合は、この時点でメトリック集計を使用する必要があります。後で、ホテルの平均価格を計算する必要がある場合は、メトリック集計を使用する必要があります。異なるブランドのホテルを並べ替えた後、測定結果を再度集計する必要があります。
Ps: パイプライン集約手法はめったに使用されず、その後の学習の焦点ではありません。
1.1.2. 特徴
ここで、先ほど説明した集計が文字列を用語ごとにグループ化していることを理解するのは難しくありません。つまり、日付、値、ブール型はもちろんのこと、将来的には単語をセグメント化することはできません。
したがって、集計に参加するフィールドは単語で分割されてはなりません。
1.2. DSL はバケット集約を実装します
1.2.1. バケット集約の基本構文
バケット集約の構文は次のとおりです。
GET /索引库名/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"自定义聚合名": { //给聚合起个名字(自定义)
"terms": { // 聚合的类型,按照品牌值聚合,所以选择 terms
"field": "字段名", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量(值设置超过总数,也没有影响)
}
}
}
}
集計には、集計名、集計タイプ、集計フィールドの 3 つの要素があることがわかります。
たとえば、ホテルのブランドに従ってホテル情報を分類するとします。
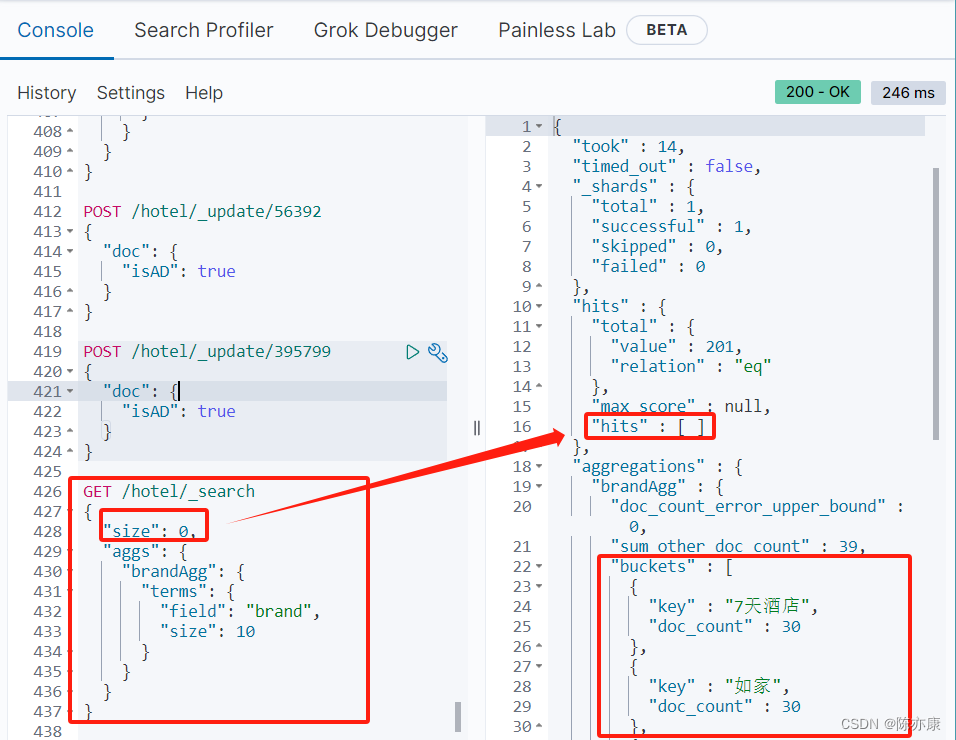
1.2.2. バケット集計結果のソート
デフォルトでは、バケット集計は、_count として記録されるバケット内のドキュメントの数をカウントし、_count の降順で並べ替えます。
たとえば、ホテル ブランドをグループ化し、ブランドごとのホテル数で昇順に並べ替えます。
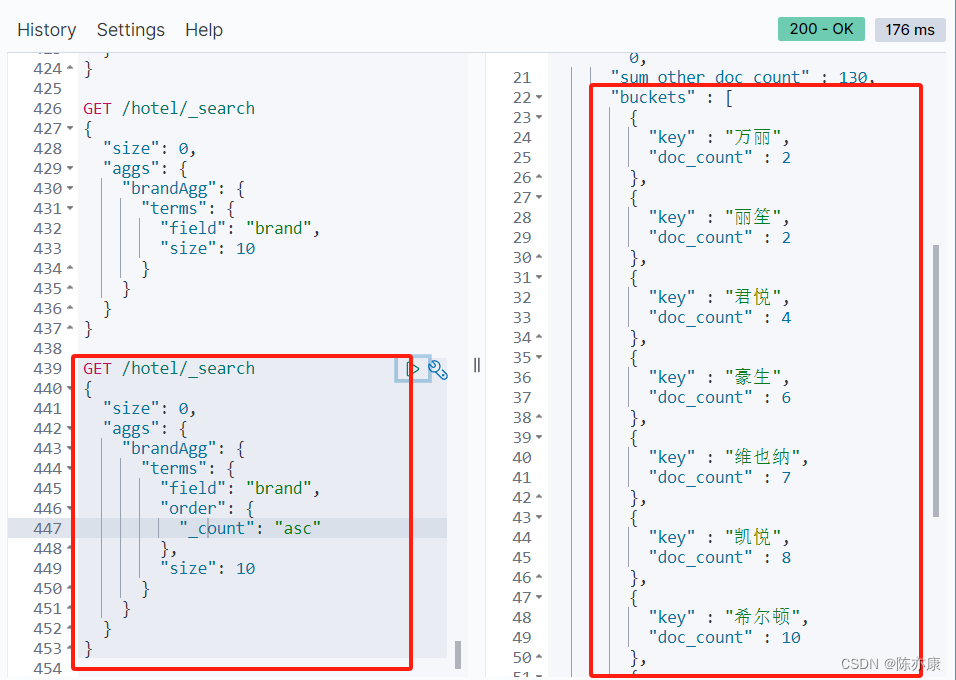
1.2.3. バケット集約の制限範囲
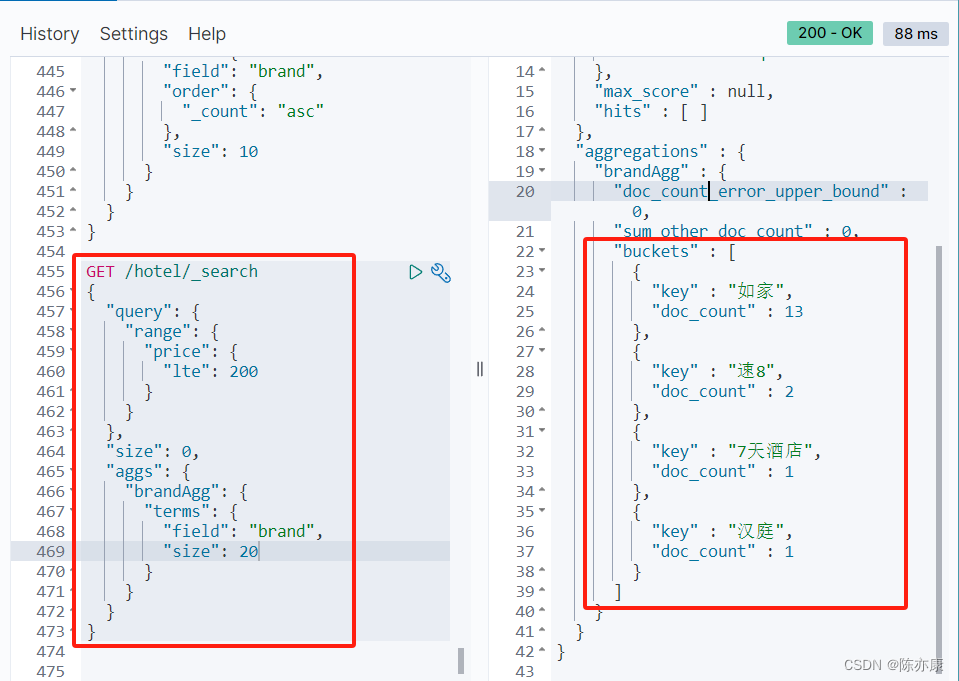
デフォルトでは、バケット集計はインデックス データベース内のすべてのドキュメントを集計します。ここでは、クエリ条件を追加するだけで、集計するドキュメントの範囲を制限できます。
追伸: バケット集計には利点があります: インデックス ライブラリに数億のデータがある場合でも、集計を見つけると大量のメモリが消費されます。そのため、クエリによる検索範囲を制限することで、メモリ使用量を大幅に削減できます。消費です。
たとえば、価格が 200 以下のホテルを検索し、ブランド別に分類します。
1.3. DSL はメトリクスの集約を実装します
メトリクスの集計では、グループ化後に各グループを個別に計算します (サブクエリを実行するには、aggs 内に aggs をネストする必要があります)。
たとえば、各ブランドのユーザー評価 (フィールドはスコア) の最小値、最大値、平均値などの値を検索します。
ここで統計の集計を使用できます

もちろん、次のように平均ユーザー評価に基づいて昇順に並べ替えることもできます。

1.4. JavaRestClient に基づいた集計の実装
1.4.1. 組み立て依頼
例: ホテルのブランドに従ってホテル情報を分類します。
@Test
public void testAggregation() throws IOException {
//1.准备 SearchRequest
SearchRequest request = new SearchRequest("hotel");
//2.准备参数
request.source().size(0);
request.source().aggregation(
AggregationBuilders
.terms("brandAgg") //自定义聚合名
.field("brand") //根据 brand 的字段聚合
.size(10) //展示 10 组数据
);
//3.发送请求,接收响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.解析
handlerResponse(response);
}
DSL ステートメントと比較できます

1.4.2. 応答の解析
//3.解析聚合查询
Aggregations aggregations = response.getAggregations();
Terms terms = aggregations.get("brandAgg");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
System.out.println(key);
}
ここで DSL 構文を比較して確認できます。

1.5. ダークホース観光業の事例
1.5.1. 需要
次の検索ページのブランド、都市、星の評価情報は、このページ用にハードコーディングされていませんが、インデックス データベース内のホテル データを集約することによって取得されます。
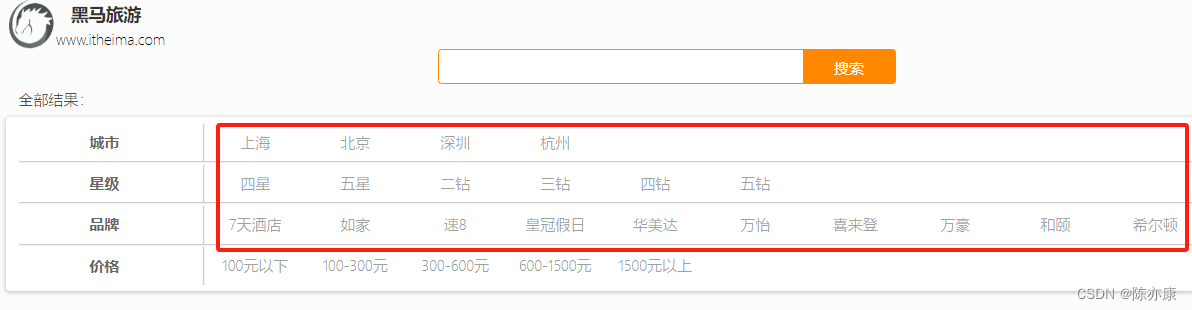
1.5.2. フロントエンドインターフェースへの接続
フロントエンド ページは、ブランド、都市、星の評価などのフィールドの集計結果をクエリするサーバーへのリクエストを開始します。

ここでのリクエスト パラメータは、前の検索の RequestParam とまったく同じです。

ここで返される応答の形式は次のとおりです。
{"都市": ["上海"、"北京"]、"ブランド": [....]...... }
Map<String, List<String>> の構造です。
1.5.3. 書き込みコントローラー
これはフロントエンドリクエストを受信するために使用されます。コードは次のとおりです。
@RequestMapping("/filters")
public Map<String, List<String>> filters(@RequestBody RequestParams params) {
return hotelService.filters(params);
}
1.5.4. フィルターインターフェースの追加
public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
Map<String, List<String>> filters(RequestParams params);
}
1.5.5. インターフェースの実装
ここでクエリ リクエストを作成するときは、最初に条件付きフィルタリング (フロント エンドから渡されるパラメータ) を通過し、次にブランド、都市、星の評価をそれぞれ集計します。
追伸:ここでブランド、星評価、都市、そしてインデックスデータベースを構築する際のタイプがキーワード、つまり切り離せない単語であるかどうかを確認しないと集計できません。
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
//1.构造请求
SearchRequest request = new SearchRequest("hotel");
//2.准备参数
// 1) 查询
handlerBoolQueryBuilder(request, params);
// 2) 设置 size
request.source().size(0);
// 3)聚合
buildAggregation(request);
//3.发送请求,接收响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4.处理响应
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
List<String> brandAgg = getAggListByName(aggregations, "brandAgg");
result.put("brand", brandAgg);
List<String> cityAgg = getAggListByName(aggregations, "cityAgg");
result.put("city", cityAgg);
List<String> starAgg = getAggListByName(aggregations, "starAgg");
result.put("starName", starAgg);
return result;
} catch (IOException e) {
System.out.println("[HotelService] 酒店数据聚合失败!");
e.printStackTrace();
return null;
}
}
private List<String> getAggListByName(Aggregations aggregations, String aggName) {
Terms terms = aggregations.get(aggName);
List<? extends Terms.Bucket> buckets = terms.getBuckets();
List<String> brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}
private void buildAggregation(SearchRequest request) {
// 1) 聚合品牌
request.source().aggregation(
AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
// 2) 聚合城市
request.source().aggregation(
AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
//3) 聚合星级
request.source().aggregation(
AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
