VCED プロジェクトの実践 2 – Jina の使用を開始する
名前
- jina は、クロスモーダル/マルチモーダル アプリケーションをクラウドで構築できるようにする MLOp フレームワークです。POC プロトタイプを準運用レベルのサービスに高めます。Jina の非構造化データの処理能力により、高度なソリューション エンジンとなり、すべての開発者がアクセスできるようになりますクラウドネイティブテクノロジー。

基本的な考え方
書類
Documentこれは、Jina の基本的なマルチモーダルおよびクロスモーダル データであり、Jina の IO の基本要素です。- これは、テキスト、画像、ビデオ、オーディオ、3D グリッドなどを統一されたデータ構造に抽象化するものとして理解できます。
- 公式ドキュメント
属性
id: 固有の文書番号blob:バイナリ生データtensor:ndarray のビデオ、画像、オーディオtext:文章modality: このドキュメントに対応するモダリティを示します。検索時に使用されます。embedding:このドキュメントの埋め込み- その他の属性については、公式ドキュメントを参照してください。
例
-
さまざまなパラメータを使用したインスタンス化
-
from docarray import Document import numpy d1 = Document(text='hello') d2 = Document(blob=b'\f1') d3 = Document(tensor=numpy.array([1, 2, 3])) d4 = Document( uri='https://jina.ai', mime_type='text/plain', granularity=1, adjacency=3, tags={ 'foo': 'bar'}, )
-
-
最も近い埋め込みを見つける
-
顔認識、類似画像検索、およびマルチモーダル検索の本質は、クエリの圧縮された埋め込みに対して最も類似または近い埋め込みを見つけるプロセスです。
-
ループを使用する場合と比較して、
Document.matchメソッドはより便利な API を提供します.embed使用前にメソッドを使用するか、.embeddingsドキュメントの埋め込みを設定する必要があることに注意してください。
-
from docarray import DocumentArray, Document import numpy as np da = DocumentArray.empty(10) #创建一个长度为10的DocumentArray,元素为空的Document da.embeddings = np.random.random([10, 256]) #设置每个Document的embedding字段为随机数 q = Document(embedding=np.random.random([256])) # query q.match(da) q.summary() -
結果は、候補セット DocumentArray 内の要素との類似度を返し、類似度によって大きい順に並べ替えます。
- デフォルトの距離メトリックはコサイン距離、つまり1 − a ⋅ b / ( ∣ ∣ a ∣ ∣ ⋅ ∣ ∣ b ∣ ∣ ) 1-a\cdot b /(||a||\cdot||b) であることに注意してください。 || )1−ある⋅b / ( ∣ ∣ a ∣ ∣⋅∣ ∣ b ∣ ∣ )、つまり、値が小さいほど類似しています。
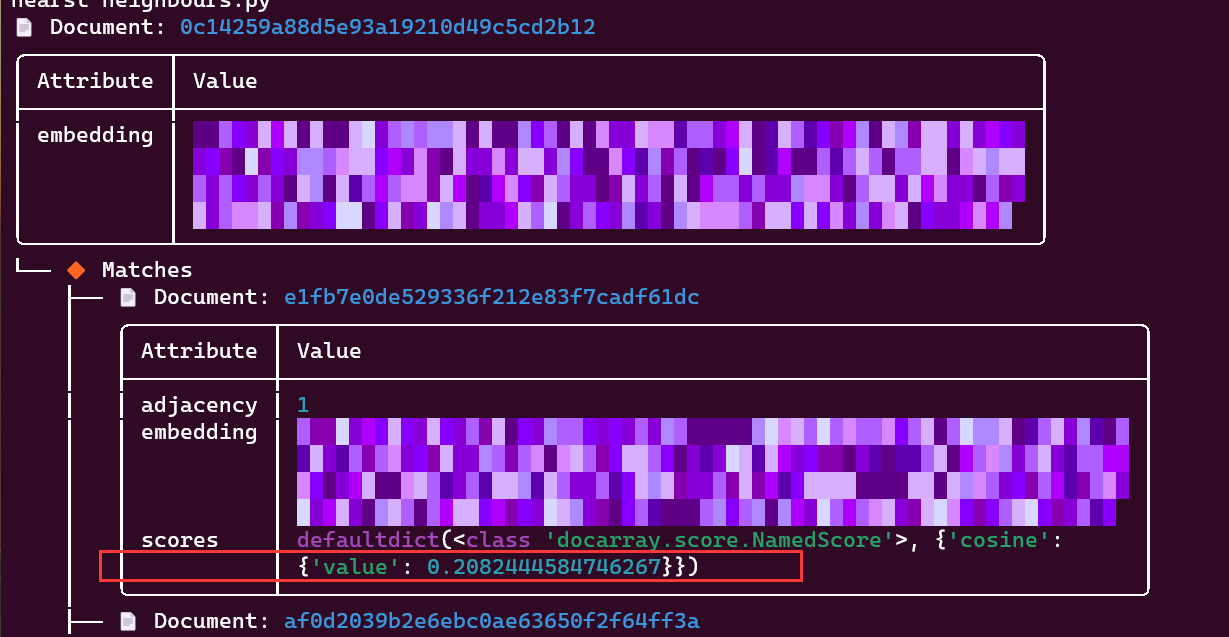
-
ドキュメント配列
DocumentArrayDocumentPythonのリストに似た複数のコンテナです。
執行者
ExecutorDocumentArrayIOとして使用できる一連のメソッドを備えたPythonクラスであり、Executorマイクロサービスとみなすことができます。
流れ
Flowこれは一連の論理パイプラインでありExecuter、エンドツーエンドのサービスとみなすことができます。
ゲートウェイ
GatawayそうFlow、社内連絡経路に相当する入り口です。
フローチャート
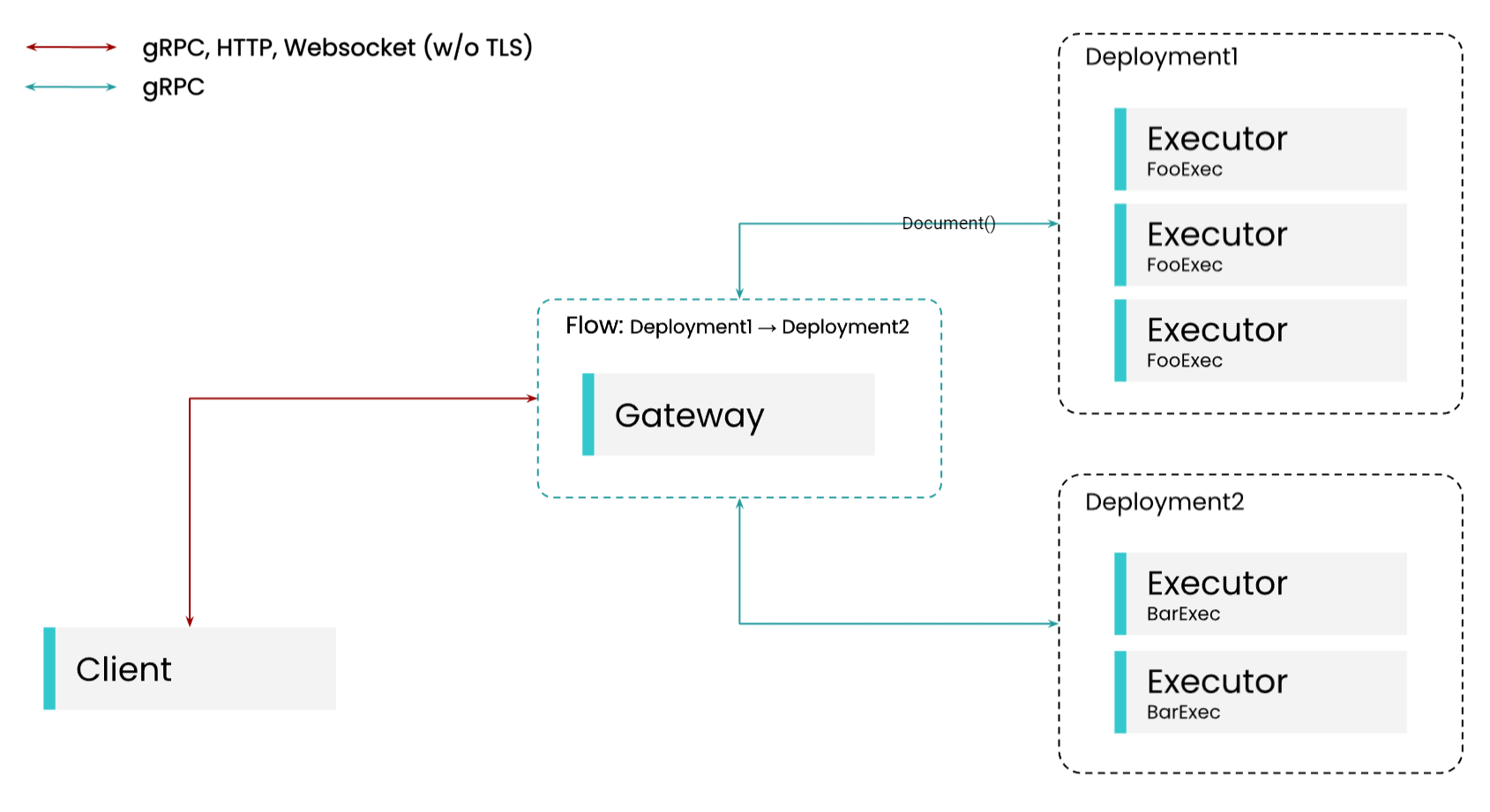
コーディングスタイル
-
Jina プロジェクトは 2 つのスタイルのコードをサポートしています
-
パイソン的な
-
from jina import DocumentArray, Executor, Flow, requests class FooExec(Executor): @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += 'hello, world!' class BarExec(Executor): @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += 'goodbye!' f = Flow(port=12345).add(uses=FooExec, replicas=3).add(uses=BarExec, replicas=2) with f: f.block()
-
-
ヤムリッシュ
-
# executor.py from jina import DocumentArray, Executor, requests class FooExec(Executor): @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += 'hello, world!' class BarExec(Executor): @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += 'goodbye!' -
#flow.yaml jtype: Flow with: port: 12345 executors: - uses: FooExec replicas: 3 py_modules: executor.py - uses: BarExec replicas: 2 py_modules: executor.py -
jina flow --uses flow.yml
-
-
-
Python コードは、実行プログラムとフローを Python ファイルにパッケージ化することと同等です。
-
yaml スタイルのコードは、実行プログラムを Python ファイルに書き込み、フロー構成を別の yaml に書き込みます。フローのロジックは分離できます。このスタイルは、運用環境の複雑なプロジェクトに使用する必要があります。
準備
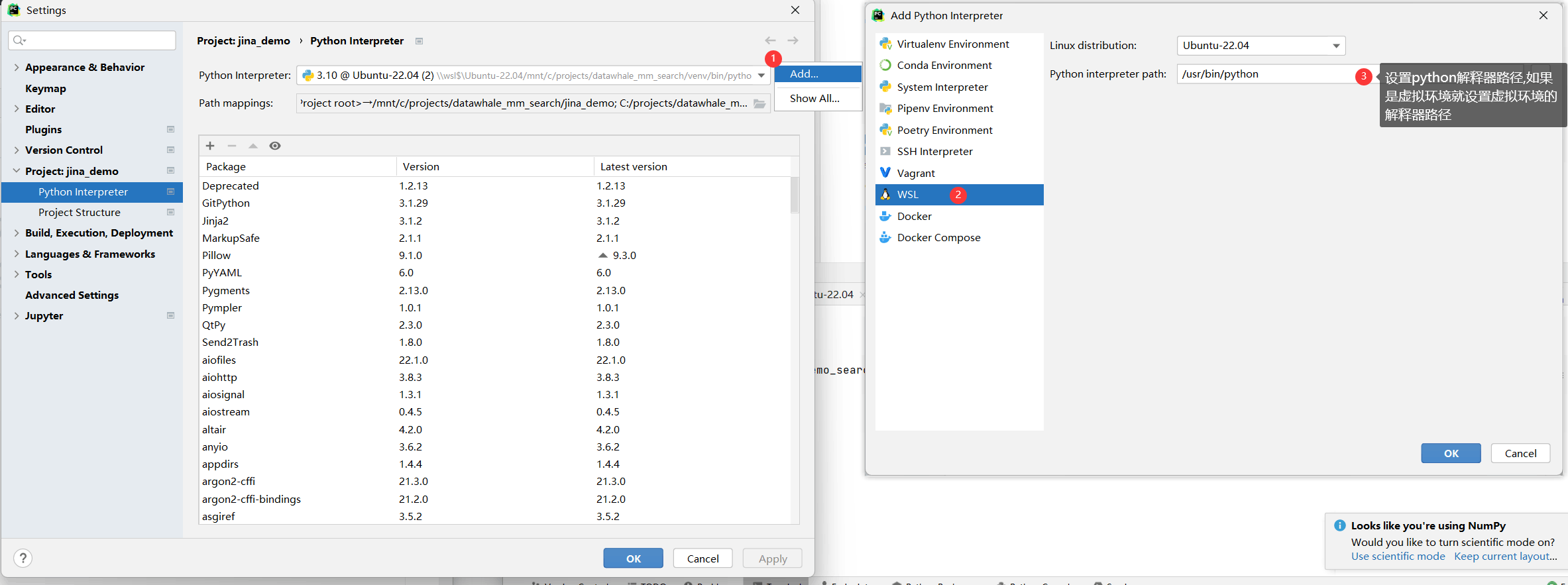
wsl インタープリターを使用するように pycharm を構成する
- ファイル > 設定 > プロジェクト:xxx >Python インタープリター
ジュピターを構成する
-
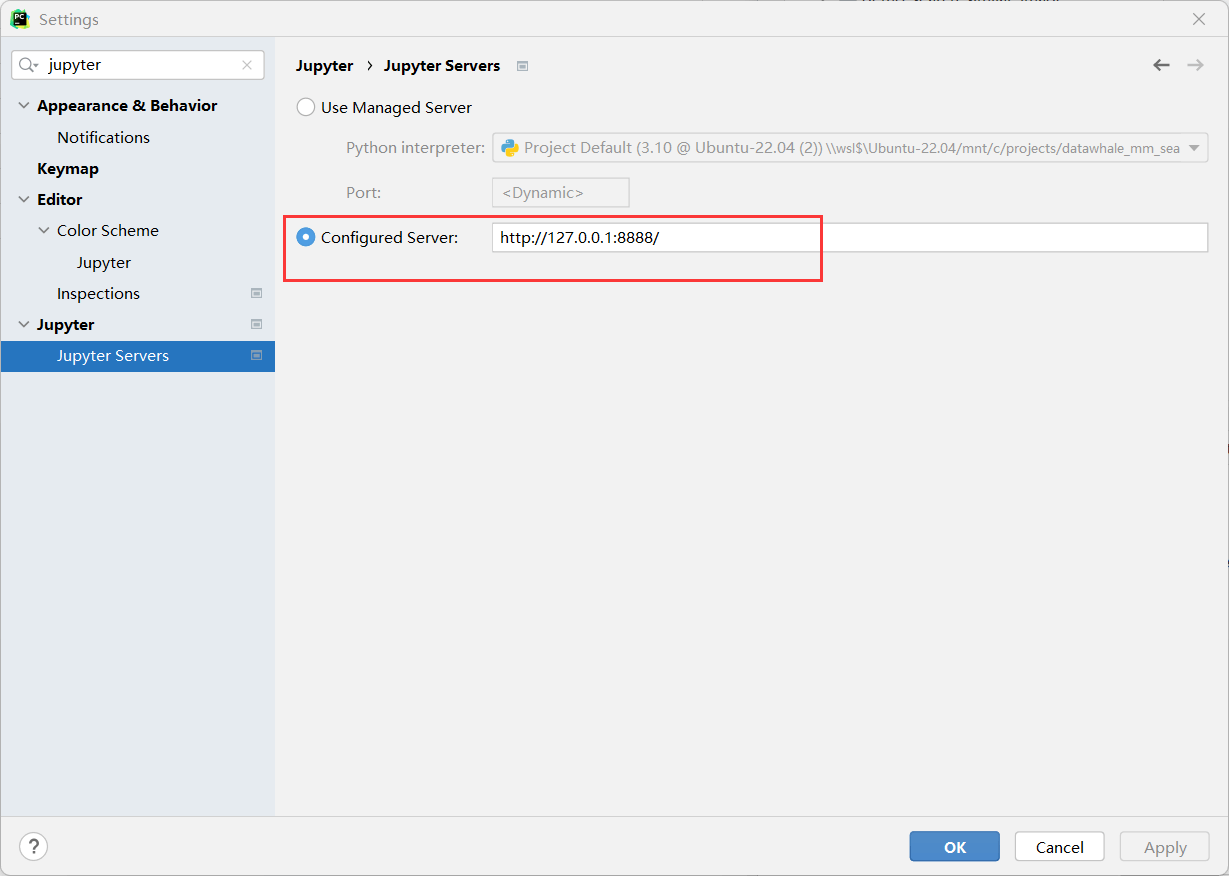
pycharmのjupyterの起動に問題があるため、WLS端末でjupyterサービスを起動する必要があります。
-
jupyter notebook -
jupyter リンクをコピーし、ブラウザまたは pycharm で開きます。

デモ: Hello world
-
次の例は、基本的な helloworld デモを示しています。
- ドキュメントのテキスト属性に「hello, world!」を追加する Excutor が定義されています。
- メソッドを使用して
Flow.send空をストリームに送信しますDocumentArray
-
# demo_hello_world/main.py from jina import DocumentArray, Executor, Flow, requests class MyExec(Executor): """ 定义了一个executor,包含一个异步方法, 其从网络请求中获取输入一个DocumentArray, 并在其中的每一个Document的text属性加入"hello, world!" """ @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += "hello, world!" # Flow流中中接着连续两次的MyExec,会在text字段加入两遍 "hello, world!" f = Flow().add(uses=MyExec).add(uses=MyExec) # with控制流的打开与关闭,会在结束时自动关闭 with f: r = f.post('/', DocumentArray.empty(2)) print(r.texts) -
# run python demo_hello_world/main.py -
結果

gRPC サーバー
-
なお、Pythonファイルに記述したフローは
with f:コードブロックが完成した時点で終了するためデバッグに適していますが、サーバーとしてデプロイする場合はyamlの記述方法を使用する必要があります。 -
この書き方はスケーラブルでクラウドネイティブです
-
MyExecクラスを別のファイルに配置しexecutor.py、対応する yaml を記述します。-
# executor.py from jina import DocumentArray, Executor, requests class MyExec(Executor): @requests async def add_text(self, docs: DocumentArray, **kwargs): for d in docs: d.text += 'hello, world!' -
# toy.yml jtype: Flow with: port: 51000 protocol: grpc executors: - uses: MyExec name: foo py_modules: - executor.py - uses: MyExec name: bar py_modules: - executor.py -
# 启动项目 jina flow --uses toy.yml -
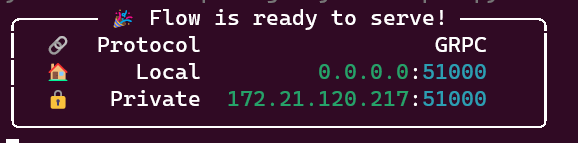
-
この時点で、 GPRC プロトコルサービスが開始されます。ブラウザを介して直接アクセスすることはできません。アクセスするクライアントを作成するか、テストのために Postman を使用する必要があります。
-
クライアントアクセス
-
クライアントコード
-
from jina import Client, Document c = Client(host='grpc://0.0.0.0:51000') #创建一个客户端 result = c.post('/', Document()) #客户端post一个空的Document print(result.texts) -
結果
-
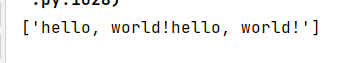
{kind=link}
郵便配達員のテスト
-
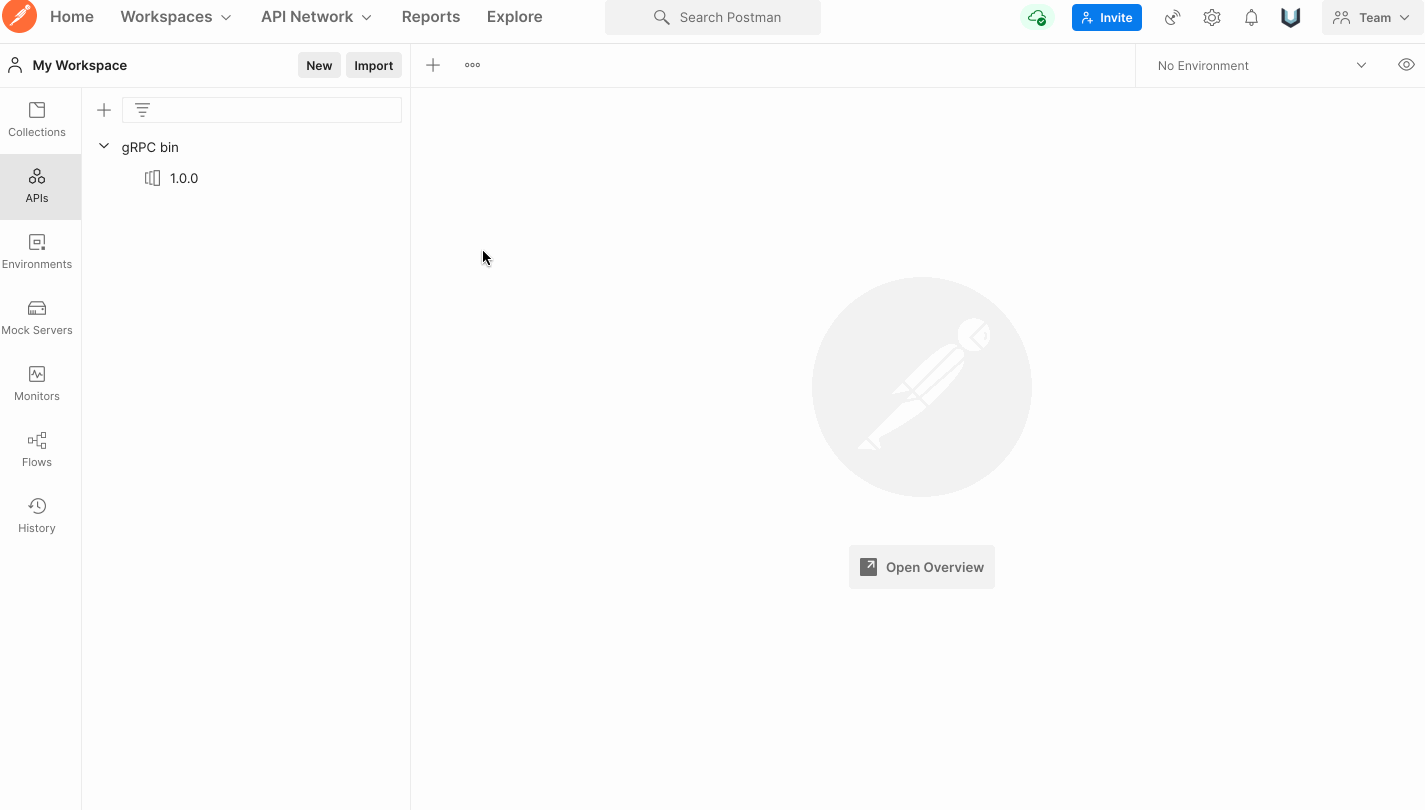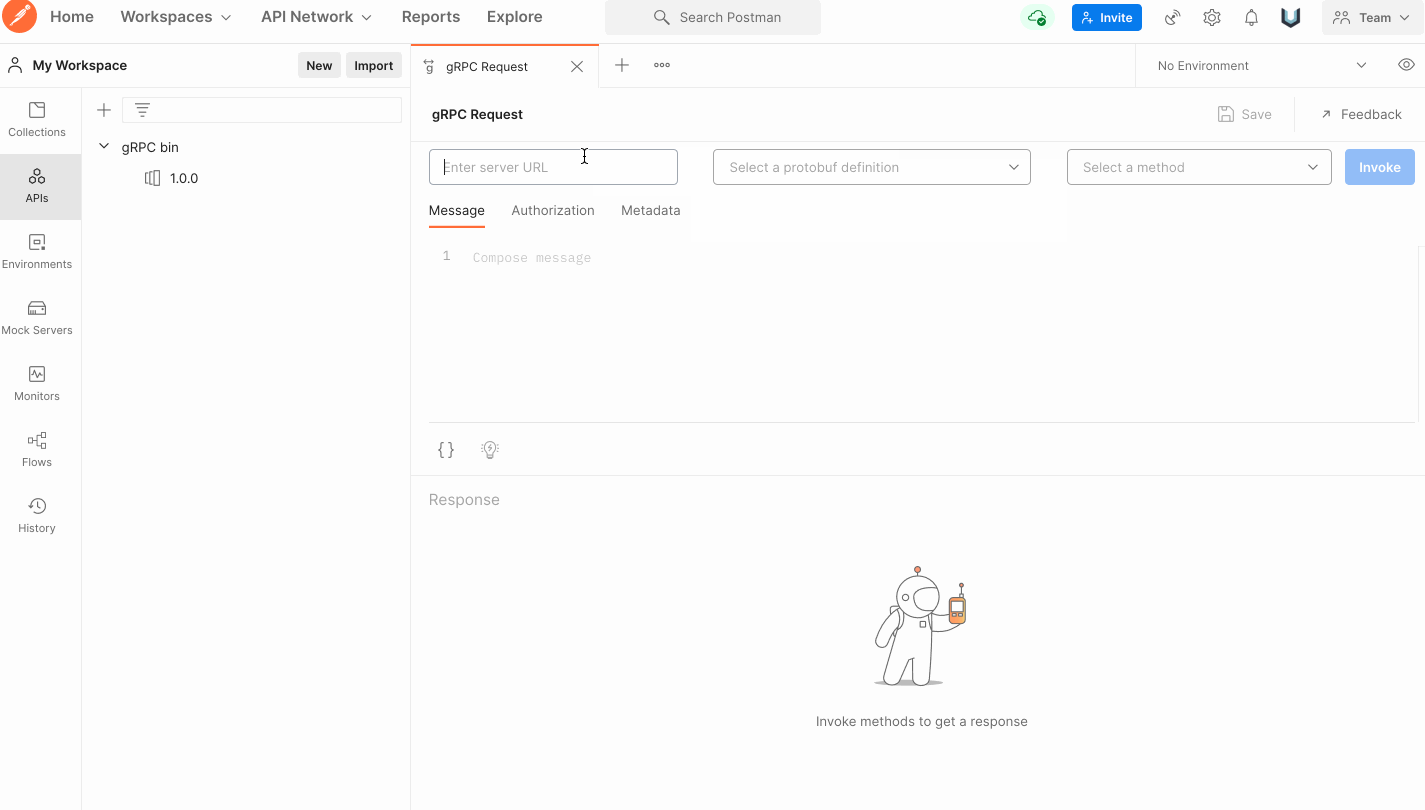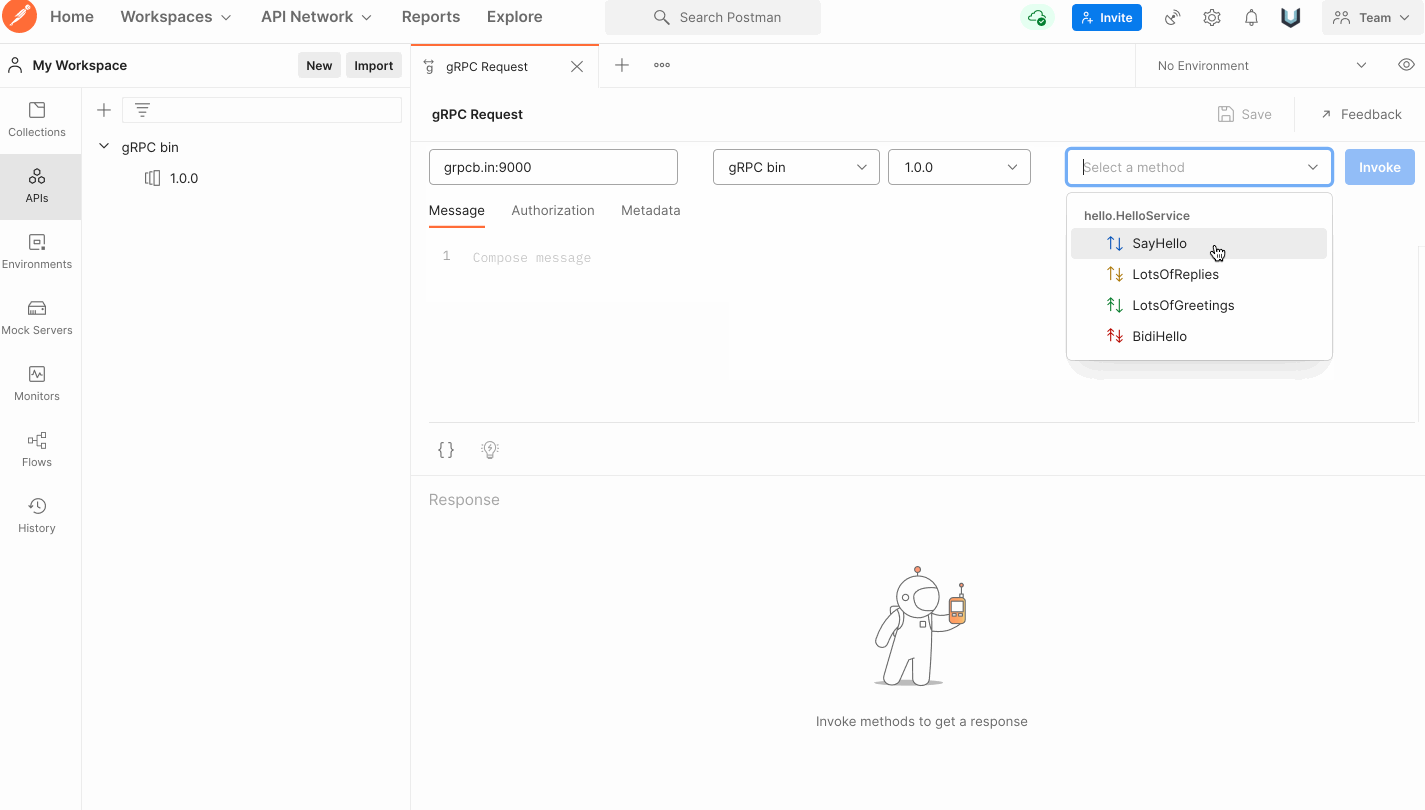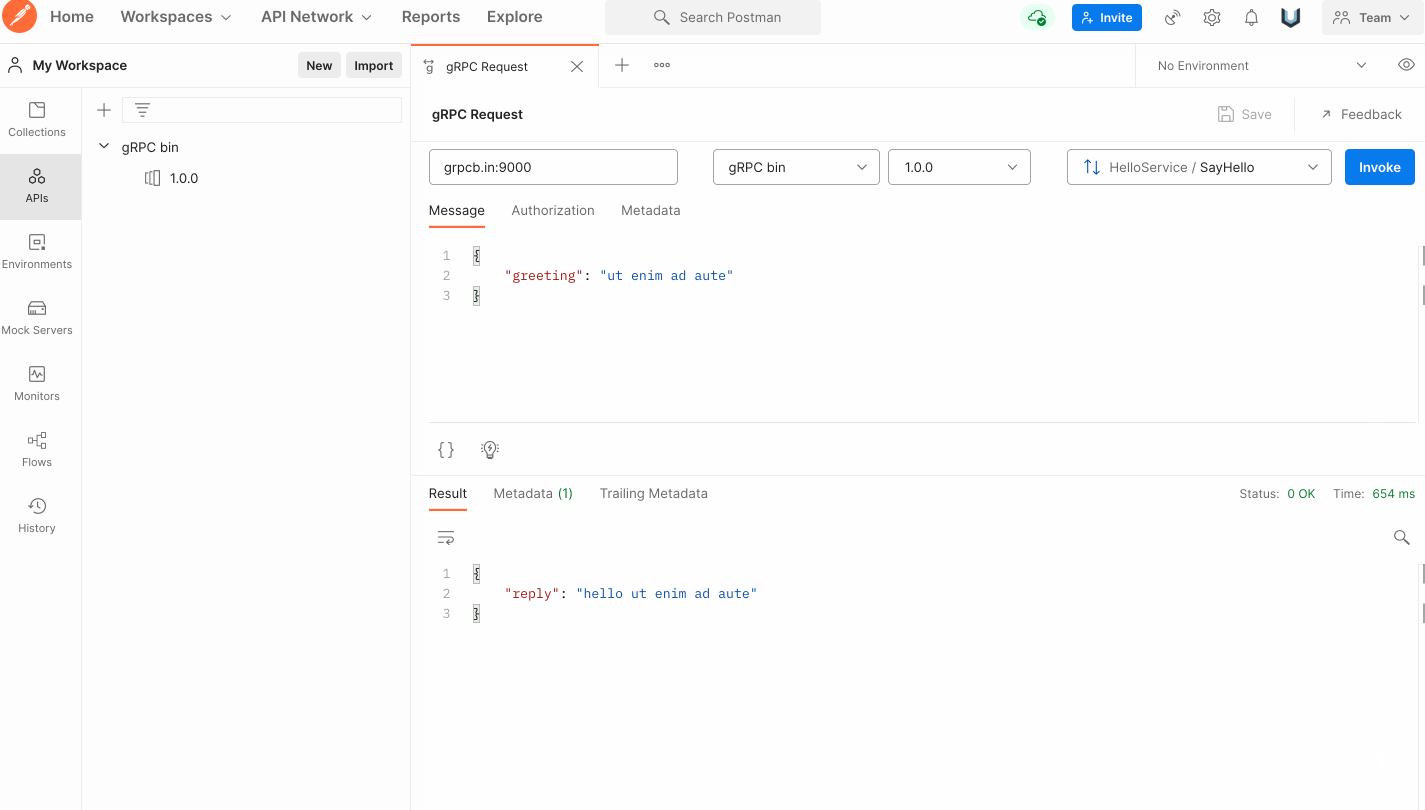
-
protoファイルをインポートすることも、郵便配達員のリフレクションを使用することもできます -
サービスが正常であれば、サーバーの URL を入力すると呼び出し構造のドロップダウン メニューが表示されるので、[呼び出し] をクリックしてテストします。
-
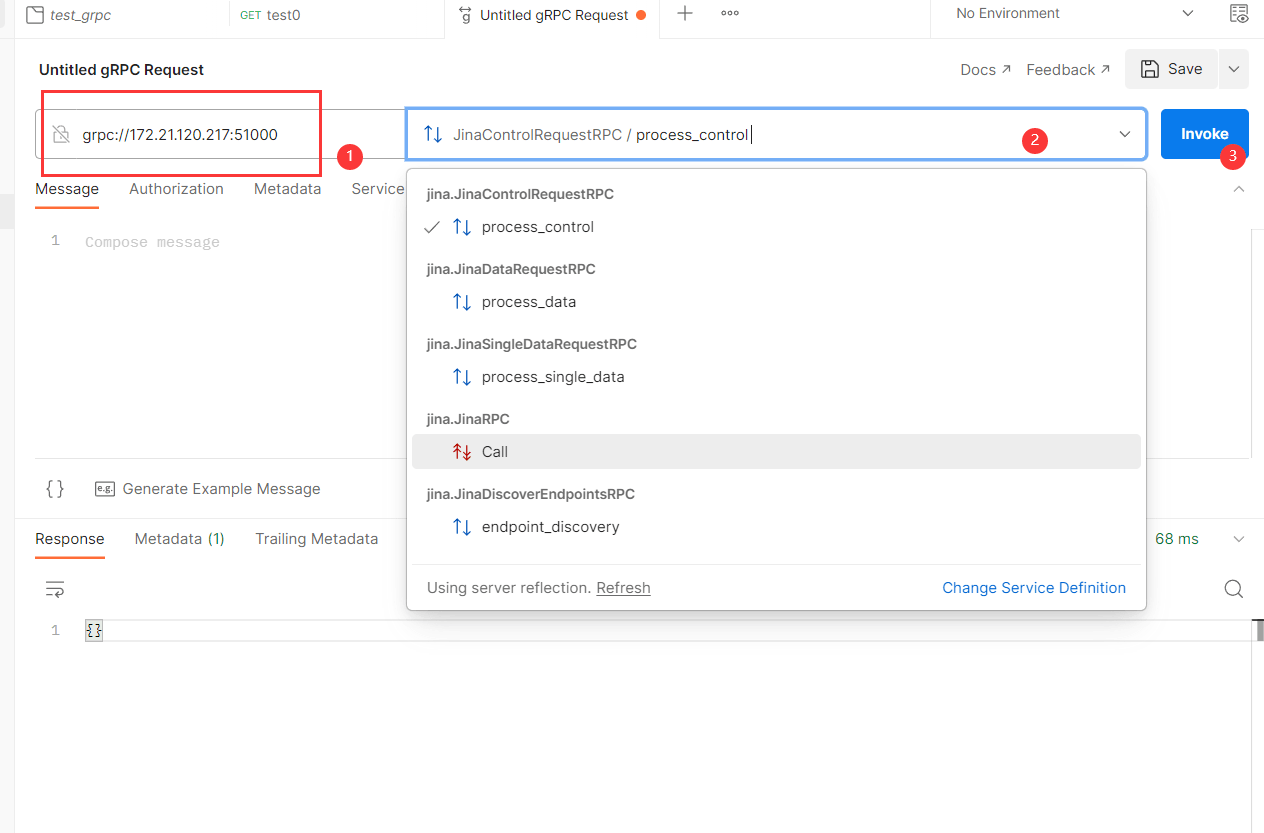
デモ: resnet を使用して類似した画像を検索する
import jina
import urllib
from jina import DocumentArray, Executor, requests, Document
from docarray.array.mixins.plot import PlotMixin
from docarray import DocumentArray
import matplotlib.pyplot as plt
import os
plt.rcParams['font.family'] = 'SimHei'
ローカル画像からミニ検索データセットを構築する
img_path_list = [os.path.join('./test_img', i) for i in os.listdir('./test_img')]
img_path_list
for idx, img_path in enumerate(img_path_list):
# f = urllib.request.urlopen(img_uri)
plt.subplot(2, 3, idx + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.xlabel(img_path.split('/')[-1])
img = plt.imread(img_path)
plt.imshow(img)

前処理
- パラメータから画像を渡し、画像を に変換し、正規化して同じサイズにサイズ変更し、最後にチャネルを最初の次元に配置します。これは と同等
Documentです。uritorch.tensortorch.permute
def get_doc_from_img(img_path):
return Document(uri=img_path).load_uri_to_image_tensor().set_image_tensor_normalization().set_image_tensor_shape(
(300, 300)).set_image_tensor_channel_axis(-1, 0)
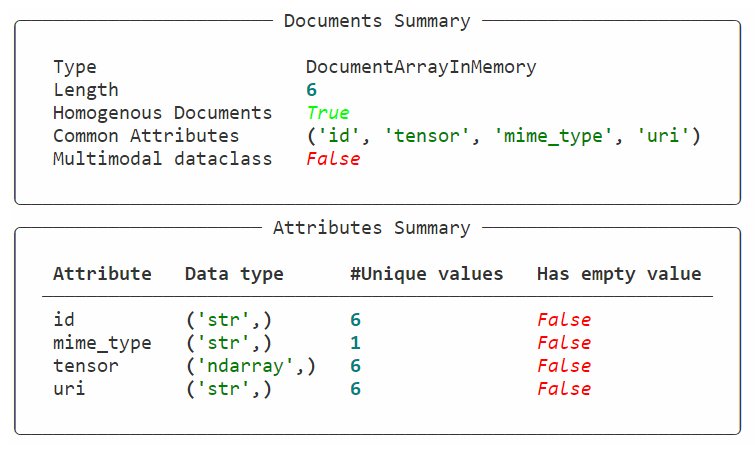
検索画像データベースの定義
DocumentArray複数保存する場合に使用しますDocument
docs = DocumentArray([get_doc_from_img(i) for i in img_path_list])
docs
resnet の事前トレーニング済みモデルをインポートし、埋め込みを生成する
- ネットワーク上の理由により、このステップでエラーが報告された場合は、まず事前トレーニングの重みを設定し、エラー メッセージに従って指定されたパスにそれらを配置できます。
- メソッドを使用して
DocumentArray.embed画像の埋め込みを取得します
import torchvision
model = torchvision.models.resnet50(pretrained=True)
docs.embed(model).embeddings
埋め込みテンソル
tensor([[-1.8643, 1.8063, -2.5505, ..., 0.3757, 1.5515, -0.1677],
[-1.0711, 1.8354, -2.3960, ..., 0.4941, 1.7618, -0.4173],
[-1.6836, 1.7230, -2.4809, ..., 0.8211, 5.2785, -0.2270],
[-0.9699, 1.8454, -2.8017, ..., 4.9436, 3.8553, 0.9916],
[ 2.9779, 1.3210, -4.4595, ..., 3.3578, 1.9920, -1.8143],
[ 3.9424, 0.8940, -3.4237, ..., 4.5399, 2.4077, -1.0326]])
視覚化
# docs.plot_embeddings() #进行可视化
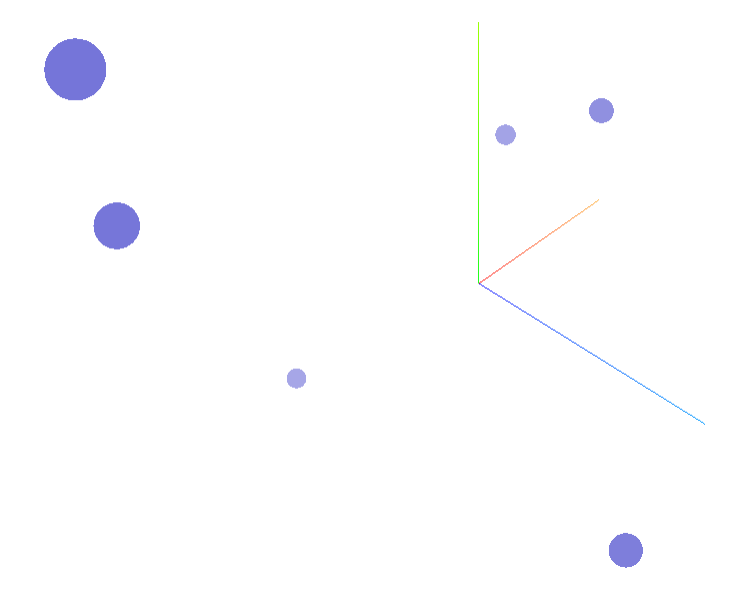
画像の類似性を比較する
- クエリ画像は、まずモデルを通じて埋め込みを取得し、次に
Document.matchメソッドを使用してデータベースの各埋め込みとの類似性を計算する必要があります。
# query
d_query = get_doc_from_img(img_path_list[0])
d_query.embed(model) #也要先通过模型得到embedding
d_query.match(docs)
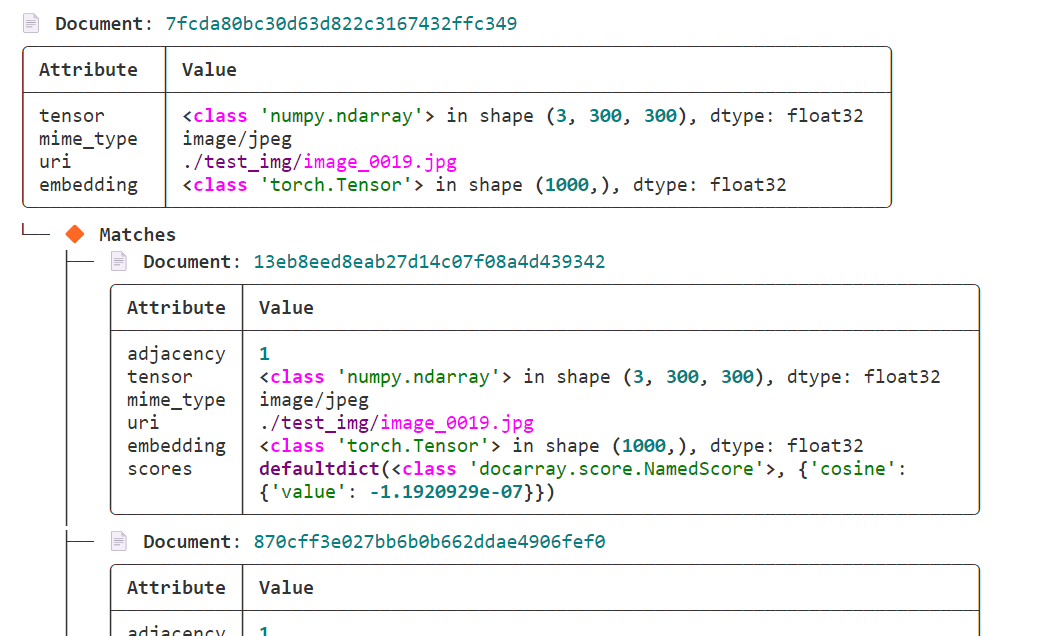
query_result = [(m.scores['cosine'].value, m.uri) for m in d_query.matches]
query_result.sort()# 距离从小到大排序
plt.subplot(3, 3, 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.xlabel(f'query image')
plt.imshow(plt.imread(img_path_list[0]))
for idx, (dis,img_path) in enumerate(query_result):
# f = urllib.request.urlopen(img_uri)
plt.subplot(3, 3, idx + 4)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.xlabel(f'emb distance {
dis:.2f}')
img = plt.imread(img_path)
plt.imshow(img)
plt.tight_layout()
plt.show()

フローを使用してサービスとしてデプロイする
- 操作をカプセル化し
executor、クライアントを使用してクエリを実行する
# executor.py
from jina import DocumentArray, Executor, requests, Document
import torchvision, os
def get_doc_from_img(img_path):
return Document(uri=img_path).load_uri_to_image_tensor().set_image_tensor_normalization().set_image_tensor_shape(
(300, 300)).set_image_tensor_channel_axis(-1, 0)
class MyExec(Executor):
@requests
async def get_similar_img(self, docs: DocumentArray, **kwargs):
docs.embed(model)
docs.match(img_database)
model = torchvision.models.resnet50(pretrained=True)
img_path_list = [os.path.join('./test_img', i) for i in os.listdir('./test_img')]
img_database = DocumentArray([get_doc_from_img(i) for i in img_path_list])
img_database.embed(model) #一定要提前将检索图片embed
# toy.yml
jtype: Flow
with:
port: 51000
protocol: grpc
executors:
- uses: MyExec
name: img_query
py_modules:
- executor.py
# client 测试
from jina import Client, Document
c = Client(host='grpc://0.0.0.0:51000') #创建一个客户端
d_query=get_doc_from_img(img_path_list[0])
# d_query.embed(model) #改为服务端进行模型embed
result = c.post('/',d_query) #结果是一个DocumentArray
print(result[0])
query_result = [(m.scores['cosine'].value, m.uri) for m in result[0].matches]
query_result.sort()# 距离从小到大排序
plt.subplot(3, 3, 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.xlabel(f'query image')
plt.imshow(plt.imread(img_path_list[0]))
for idx, (dis,img_path) in enumerate(query_result):
# f = urllib.request.urlopen(img_uri)
plt.subplot(3, 3, idx + 4)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.xlabel(f'emb distance {
dis:.2f}')
img = plt.imread(img_path)
plt.imshow(img)
plt.tight_layout()
plt.show()