1. 質問
今日 codeblock を使用しているときに、codeblock ターミナルからの中国語出力がコンパイル中に文字化けしていることがわかりました。
コードブロックの右下に「データ損失を防ぐため、このファイルは UTF-8 として保存されました。」というメッセージが表示されると文字化けが発生します。
2. 理由を分析する
インターネット上には、「
コードが文字化けする原因は、システムのローカルエンコードとコードブロックコンパイラのデコード方法が異なるためです。GBKエンコード方法とUTF-8エンコード方法の競合です」という情報が多くあります。 。
最初はよく分かりませんでしたが、じっくり分析してみました。
意味不明なものには 2 種類あります。
- ファイルを開くと文字化けする
- ターミナル出力が文字化けする
ファイルを開くと文字化けする
次のように:
cout<<"±à¼Æ÷£ºÉèÖÃΪÁËĬ"<<endl;
cout<<"±àÒëÆ÷£ºÄ¬ÈÏ"<<endl;
cout << "Hello world!" << endl;
これはエディタのエンコード方法に関係します。
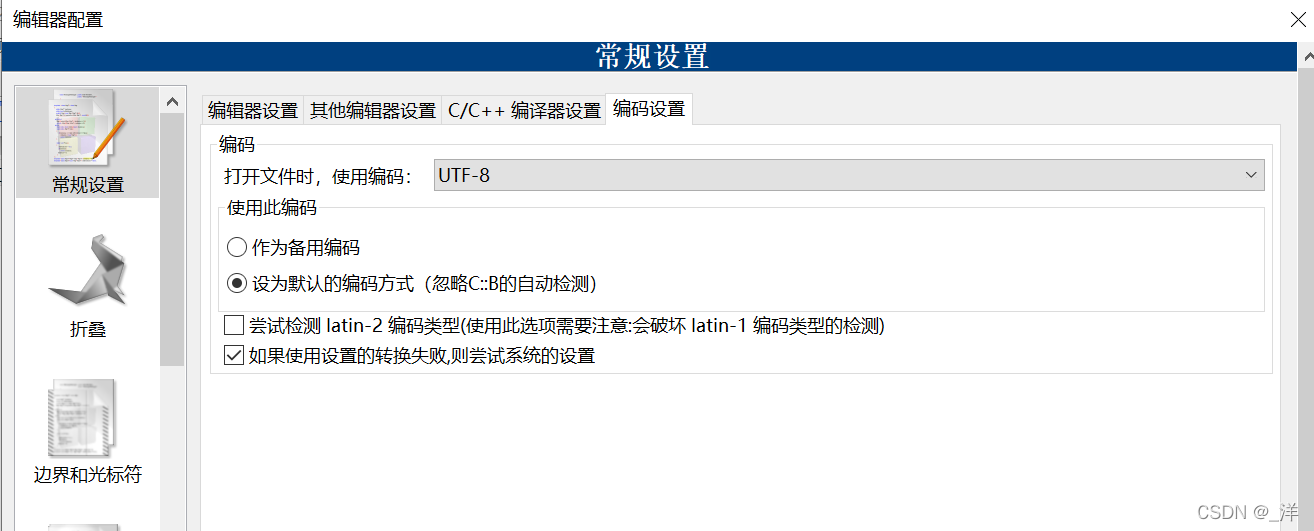
設定 -> エディタ -> エンコード設定
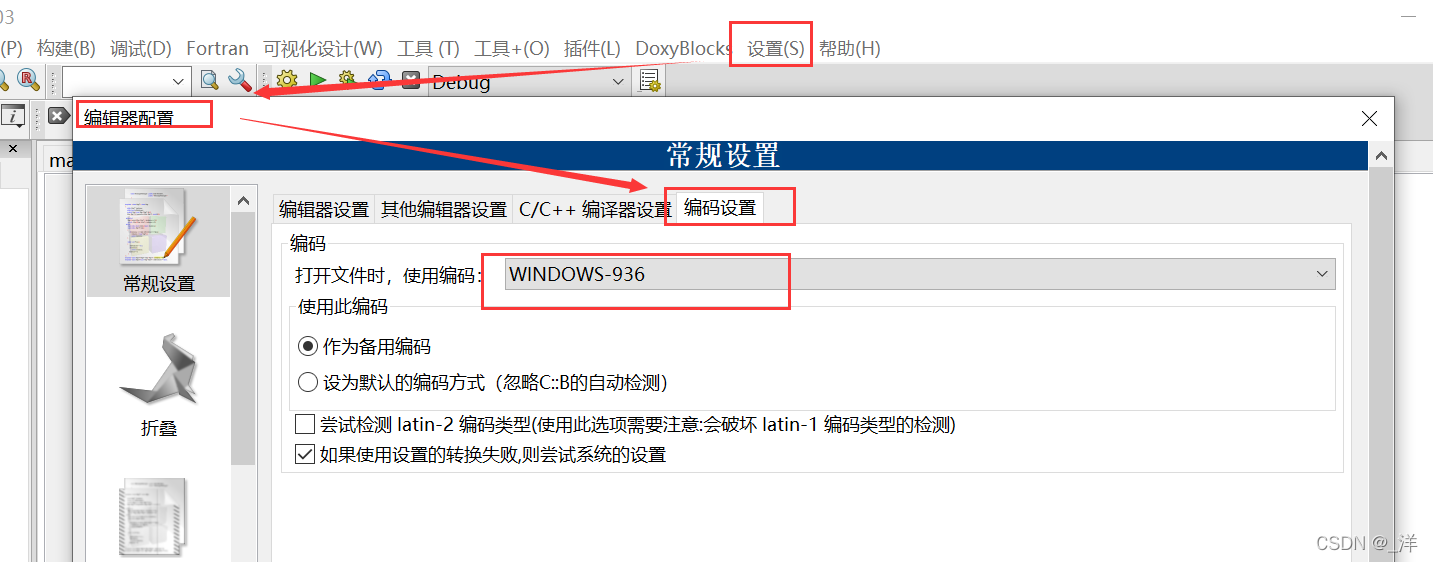
ここで 1 つを見つけました打开文件时,使用编码。これは、ファイルを保存したり開くときに使用するエンコード形式です。
一般的に使用するエンコード方法は 2 つあります: UTF-8 と GBK
WINDOWS-936 は GBK エンコード形式を表し、GBK はWindows で使用されるエンコード形式。UTF
-8 はコードブロックのデフォルトのエンコード形式で、UTF-8 は Linux のエンコード形式です。
余談:
これら 2 つの形式が競合するため、mingGW は Windows 上で GCC ベースのプログラム開発環境を提供し、Windows プラットフォーム上の Linux 上で GCC の開発環境をシミュレートします。
トピックに戻りますが、Windows システムでは依然として WINDOWS-936 エンコード形式が一般的に使用されていますが、これを“使用此编码”選択する必要があることに注意“设为默认的编码方式”してください。この場合、保存するファイルと開くファイルのエンコード形式は同じになります。 , ファイルを開いたときに文字化けすることはありません。もちろんUTF-8を選択することも可能ですが、その後のコンパイル時のエンコード方法も調整する必要があります。
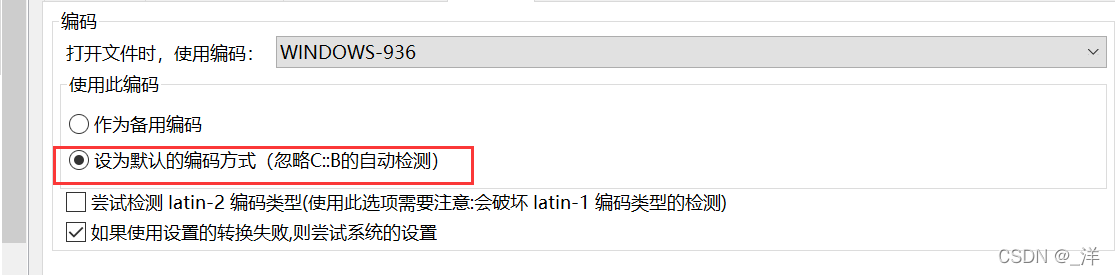
以前に私が選択したのは、“作为备用编码”コードブロックが最初にエンコード形式を検出し、検出されない場合は定義したエンコード形式を使用するというものでした。問題がないのは当然ですが、ファイルが GBK であっても、コードブロックがファイルを自動的に UTF-8 エンコーディングとして認識する理由がわかりません。もちろんGBKファイルをUTF-8解析で開くと上記の文字化けが発生します。
注: ファイルのエンコード形式は、保存時にコードブロック エディタで設定された形式と同じであり、保存後にエンコード形式を変更することはできません。
ターミナル出力が文字化けする
ターミナル出力の文字化けはコンパイラに関連しています:
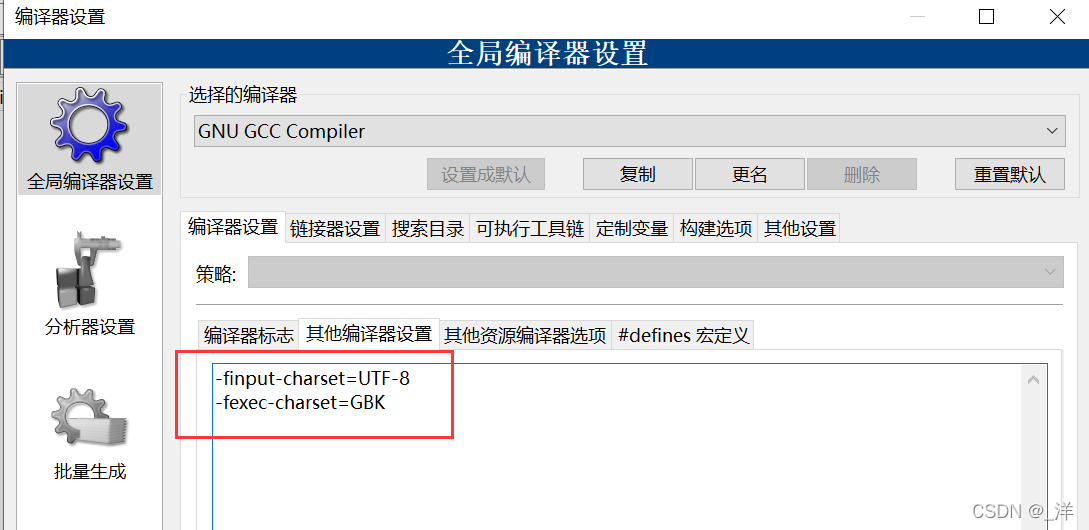
[設定] -> [コンパイラ]
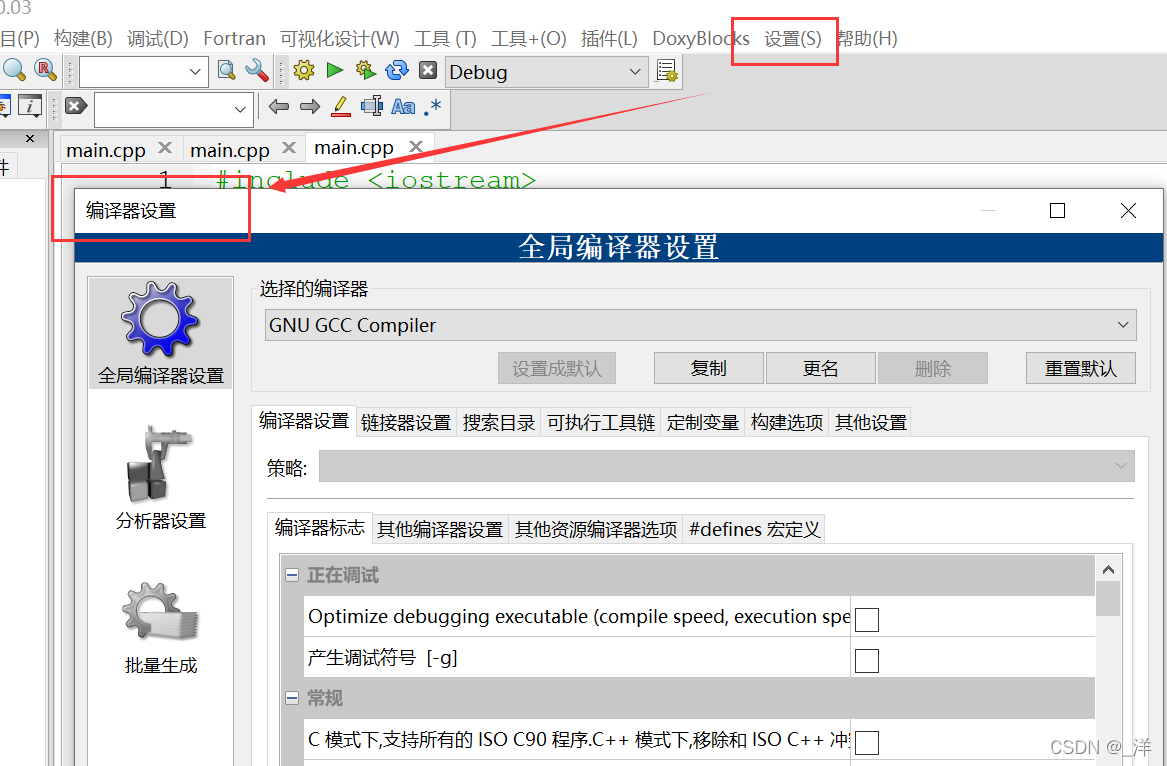
ここでは 2 つのコマンドが必要です:
-finput-charset=charset
-fexec-charset=charset
意味:
-finput-charset=charset は、コンパイラが入力ソース ファイルを解釈するために使用するエンコーディングを指定します。ソースファイルと同じエンコード形式では、形式が同じ場合にのみコンパイルが可能で、形式が異なる場合は、まったくコンパイルできないという
エラーが報告されます。-finput-charset=文字セットのデフォルト値は UTF-8 です。

-fexec-charset=charset はコンパイル時にターミナルに出力する際に使用するエンコード形式です。
-fexec-charset=charset はデフォルトでは UTF-8 ですが、Windows が認識できないため、文字化けを防ぐために GBK に変更する必要がありますは表示されません。
3. まとめ
要約すると、codeblock にはエンコーディングを設定するための 2 つの形式があります。
(1)GBK-GBK-GBK
[設定] -> [エディタ] -> [エンコーディングを使用] WINDOWS-936

[設定] -> [コンパイラ] -> [その他のコンパイラ設定]
次のステートメントを入力します。
-finput-charset=GBK
-fexec-charset=GBK
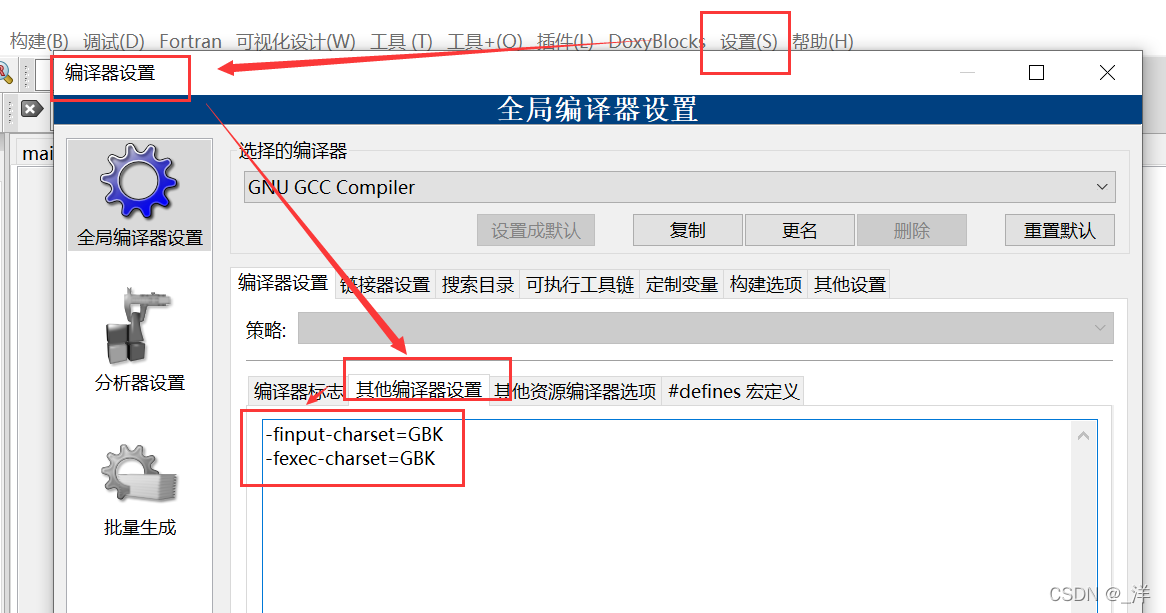
(2)UTF-8 - UTF-8 - GBK
[設定] -> [エディタ] -> [UTF-8 エンコーディングを使用]
[設定] -> [コンパイラ] -> [その他のコンパイラ設定]
次のステートメントを入力します。
-finput-charset=UTF-8
-fexec-charset=GBK
4.注意
両方の形式のファイルを、対応するエンコード形式で開くことが最善です。
つまり、UTF-8 - UTF-8 - GBK で作成されたファイルは、UTF-8 - UTF-8 - GBK 構成でも開く必要があり
、 GBK-GBK-GBK GBK-GBK-GBK 構成を使用して開くだけです。
ファイルが見つからない、コードが消えるなどの問題が発生する可能性があります。
(コードブロック:
UTF-8 - UTF-8 - GBK 構成は GBK-GBK-GBK ファイルを問題なく開き、コードの内容を表示できることがわかりました。GBK-GBK-GBK 構成は UTF-8 - UTF
-8 - GBK ファイルを開きます大丈夫、表示されない、当時は怖かった
)