文字列ディレクトリ
目次
3. String クラスのテンプレート (えっ? String は実際にテンプレートを使用するのですか??)
4.1 [ ] + 添え字 (operator[ ] のオーバーロード関数)
4.2 範囲ベースの for ループ (C++11 構文糖衣)
5. 文字列イテレータ (イテレータはポインタをカプセル化し、ポインタの動作をシミュレートするクラスです)
6.2予約スペースの確保(通常は拡張に使用)(サイズは変更されません)
8.2append (最後にデータを追加しますが、+= はありません)
8.3insert (任意の位置に挿入) (通常は使用しません、時間の無駄です)
8.5 swap (パラメータであり、一般的なものとは異なります)
9. 文字列演算演算関数(c_str、find、、substr)
9.1c_str (C++とC言語間のインターフェースを作るため、大使館とみなされます)
9.3rfind (rfind はファイルの接尾辞を見つけるのに非常に快適です)
9.4find_first_of (文字サブセットの最初の出現を検索)
10. 非メンバー関数のオーバーロードされた関数 (getline)

お急ぎの場合は、このタイトルで私の内容を読んでください。!
もちろん、次のリストを参照してください。このリストには、C++ の `std::string` クラスの一般的なメンバー関数と演算子、および各関数と演算子の簡単な説明と使用例が含まれています。
1. `begin`: 文字列の先頭を指すイテレータを取得します。
std::string::iterator it = str.begin();
2. `end`: 文字列の末尾を指すイテレータを取得します。
std::string::iterator it_end = str.end();
3. `size` (または `length`): 文字列のサイズを取得します (capacity は文字列によって開かれたスペースのサイズを返します)
std::string str = "Hello";
std::cout << "Size: " << str.size() << std::endl;
4. `empty`: 空かどうかを判断します。
if (str.empty()) {
std::cout << "String is empty." << std::endl;
}
5. `operator[]`: 配列に相当する n 番目の要素を受け取ります
char firstChar = str[0];
6. `c_str`: C スタイルの const char* 文字列を取得します
const char* cString = str.c_str();
7. `data`: 文字列コンテンツのアドレスを取得します。
const char* data = str.data();
8. `operator+=`: 文字列末尾挿入演算子
str1 += str2;
9. `find`: 文字列内の部分文字列の位置を検索します。
size_t found = str.find("World");
10. `substr`: 部分文字列を取得します
std::string sub = str.substr(6, 5);
11. `compare`: 文字列を比較します
int result = str1.compare(str2);
if (result == 0) {
std::cout << "Strings are equal." << std::endl;
}
12. `operator+`: 文字列の連結
std::string result = str1 + str2;
13. `operator==`: それらが等しいかどうかを判断します
if (str1 == str2) {
std::cout << "Strings are equal." << std::endl;
}
14. `operator!=`: に等しくないかどうかを判断します。
if (str1 != str2) {
std::cout << "Strings are not equal." << std::endl;
}
15. `operator<`: より小さいかどうかを判断します
if (str1 < str2) {
std::cout << "str1 is less than str2." << std::endl;
}
16. `insert`: 文字を挿入します
str.insert(3, " inserted");
17. `resize`: スペースの再割り当て
- 説明: `resize` 関数は文字列のサイズを変更するために使用され、文字列の長さを増減できます。新しいサイズが現在のサイズより大きい場合、新しい要素はデフォルトで初期化されます。(3つの条件)
std::string str = "Hello";
str.resize(8); // 增加字符串大小
std::cout << str << std::endl; // 输出 "Hello\0\0\0"
str.resize(3); // 缩小字符串大小
std::cout << str << std::endl; // 输出 "Hel"18. `reserve`: スペースの予約
- 説明: `reserve` 関数は、後続の操作でのメモリの再割り当てを避けるために、文字列用のストレージ スペースを予約するために使用されます。これは、動的メモリ割り当てのオーバーヘッドを軽減するのに役立ちます。
std::string str;
str.reserve(100); // 预留至少能容纳100个字符的空间
str = "Hello, World!"; // 不会触发重新分配内存上記の例は参考用です。
1. STL の概要
1.1STLとは
STL (標準テンプレート ライブラリ): C++ 標準ライブラリの重要な部分であり、再利用可能なコンポーネント ライブラリであるだけでなく、データ構造とアルゴリズムを含むソフトウェア フレームワークでもあります。
1.2STL版
1.3STL 6 つのコンポーネント
STL には、コンテナ、アダプタ、イテレータ、スペース アセンブラ、アルゴリズム、ファンクタの 6 つの主要なコンポーネントがあり、具体的な内容は次のとおりです。
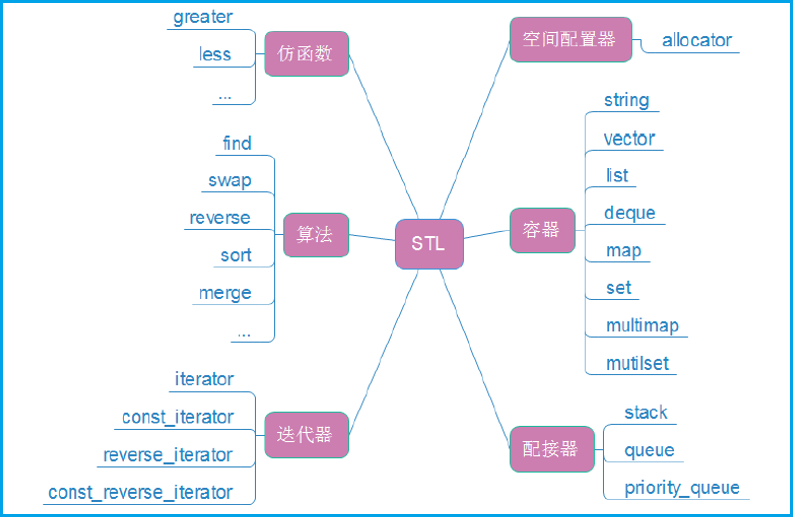
1.4 STLの重要性
インターネットには、「STL を理解していないのに、C++ を知っているとは言わないでください」という格言があります。STL は C++ の優れた作品です。STL との連携により、基礎となる多くのデータ構造とアルゴリズムを再発明する必要がなく、直接使用できるため、問題解決と開発の効率が大幅に向上します。そのため、STL は筆記試験で広く使用されています。面接や職場での重要な検査対象です。
1.5 STLの学習方法
英語のドキュメント クエリ インターフェイス Web サイトについて説明します: cplusplus.com - The C++ Resources Network
(注: cplusplus は、更新後に使用する前に登録する必要があります。右上隅の [レガシー バージョン] をクリックして古いバージョンに戻すことができます。個人的には、古いバージョンの方がエクスペリエンスが優れていると思います)新しいバージョン)、cplusplus の方が初心者に適しているため、STL を学習する過程で遭遇しました。関数インターフェイス、関数パラメーターなどは、cplusplus で検索することで解決できます。
優れた C++ の本を読む: C++ は詳細が多く難しい言語ですが、現在は時々 STL ソース コード分析を読んでいます。

電子版が必要な場合は、私に個別にメッセージを送ってください。!
2.文字列とは何ですか? ? (基本的にはクラスです)
C 言語では、文字列は '\0' で終わる文字の集合です。操作の便宜上、C 言語の string.h ヘッダー ファイルには一連のライブラリ関数が用意されていますが、これらのライブラリ関数は文字列から分離されています。オブジェクト指向の考え方に準拠しており、その下にある空間はユーザー自身が管理する必要があり、注意しないと範囲外にアクセスされてしまう可能性もあります。
上記の理由に基づいて、C++ 標準ライブラリは string クラスを提供します。string クラスは、クラスの 6 つのデフォルトのメンバー関数、文字列の挿入と削除、演算子のオーバーロードなどのさまざまな関数インターフェイスを提供します。オブジェクトを作成し、文字列のさまざまなインターフェイスを通じてオブジェクトに対するさまざまな操作を完了します。
string クラスの実装枠組みは大まかに以下のとおりです。
namespace std {
template<class T>
class string {
public:
// string 的各种成员函数
private:
T* _str;
size_t _size;
size_t _capacity;
//string 的其他成员变量,比如npos
};
}
注: 厳密に言えば、文字列は STL よりも前に登場したため (これが、長さを計算するために .length() と .size() が登場した理由です)、文字列は実際には STL に属しません。しかし、文字列の異なる特性により、このインターフェイスは非常に複雑です。 STL の他のコンテナのインターフェースと似ているので、文字列を STL の一種とみなして一緒に学習することができます。
3. String クラスのテンプレート (えっ? String は実際にテンプレートを使用するのですか??)
ドキュメントの URL を開いて string を検索すると、string が実際には文字型 char を使用して、basic_string クラス テンプレートによってインスタンス化されたクラスであることがわかります(以下は忍耐強く英語で読む必要があります)。
実際、これは動的に増加する文字配列です

では、basic_string とは何でしょうか? ?
Basic_string は、任意の文字タイプでインスタンス化できるクラス テンプレートです。
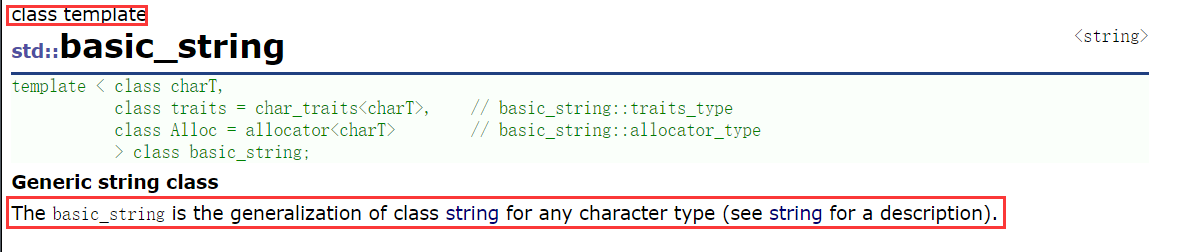
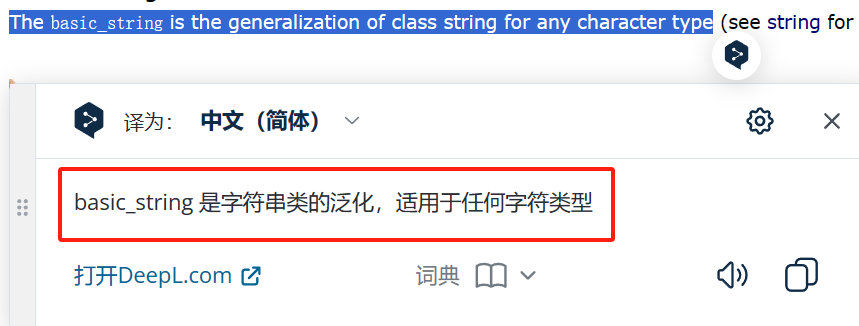
どうしても理解できなかったので翻訳ソフトを使ってみたら、一般論だったことが分かりました!!!一般化とは何ですかと尋ねますか?私のテンプレートブログをチェックしてください!!テンプレート初心者
したがって、通常使用する文字列は基本的には Basic_string<char> ですが、文字列は内部で typedefed されているため、自分で明示的にインスタンス化する必要はありません。
typedef Basic_string<char, char_traits, allocator> 文字列
3. 文字列の 3 つの構造 (コピー構造も構造)
String には多くのコンストラクターが用意されています。最も一般的に使用されるコンストラクターのみをマスターする必要があります。必要に応じて、残りについてドキュメントを問い合わせることができます: (最も一般的に使用されるのは 3 つです)
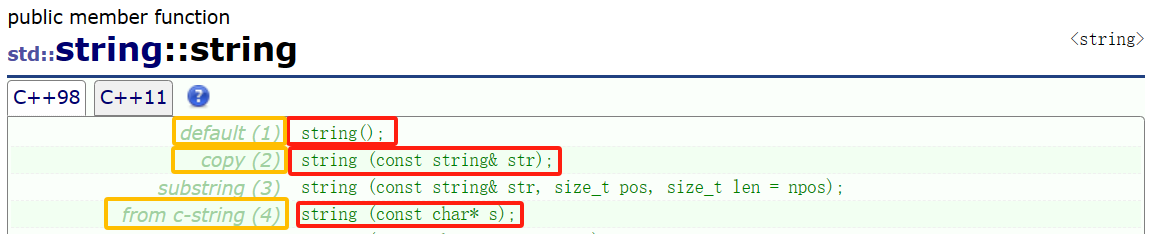
| (コンストラクター)関数名 | 機能の説明 |
| string() (強調) | 空の文字列クラス オブジェクト、つまり空の文字列を構築します。 |
| string(constchar*s) (強調) | C 文字列を使用して文字列クラス オブジェクトを構築する |
| 文字列(size_tn,charc) | 文字列クラス オブジェクトには n 個の文字が含まれています。 c |
| string(conststring&s) (強調) | コピーコンストラクター |

4. 3つの横行撹拌方法
4.1 [ ] + 添え字 (operator[ ] のオーバーロード関数)
[ ] の使用方法についてはここでは紹介しませんので、まずオーバーロードの実装と [ ] の利点について深く理解しましょう。
配列では、データ アクセスに [ ] を使用することもできますが、範囲外の読み取りと範囲外の書き込みの境界は非常に曖昧です。以下は、私たちが独自に作成した配列のオーバーロードされた角括弧関数です。
T& operator[](int index) {
// 使用assert检查越界
assert(index >= 0 && index < size);
return data[index];
}これにより、C++ 言語のカプセル化がさらに確実になり、より優れたものになります。文字列ライブラリでは、角括弧もオーバーロードされます。

文字列内の角括弧のオーバーロードは上記と同様です。つまり、assert のスコープを次のように変更します。
インデックス >= 0 && インデックス < data.size()
一般に、[ ] トラバーサル アクセスの使用方法は次のとおりです。
void test_string2()
{
string s1("1234");
//需求:让对象s1里面的每个字符都加1
//如果要让字符串的每个字符都加1,肯定离不开遍历,下面学习三种遍历string的方式。
//1.下标 + []
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++;//本质上
}
cout << s1 << endl;//GB2312兼容ascll编码,所以++后的结果为2345.
}
4.2 範囲ベースの for ループ (C++11 構文糖衣)
void test_string2()
{
//2.范围for
for (auto& ch : s1)//自动推导s1数组的每个元素后,用元素的引用作为迭代变量,通过引用达到修改s1数组元素的目的。
{
ch++;
}
cout << s1 << endl;
//在上面这种需求下,范围for看起来似乎更为方便
}
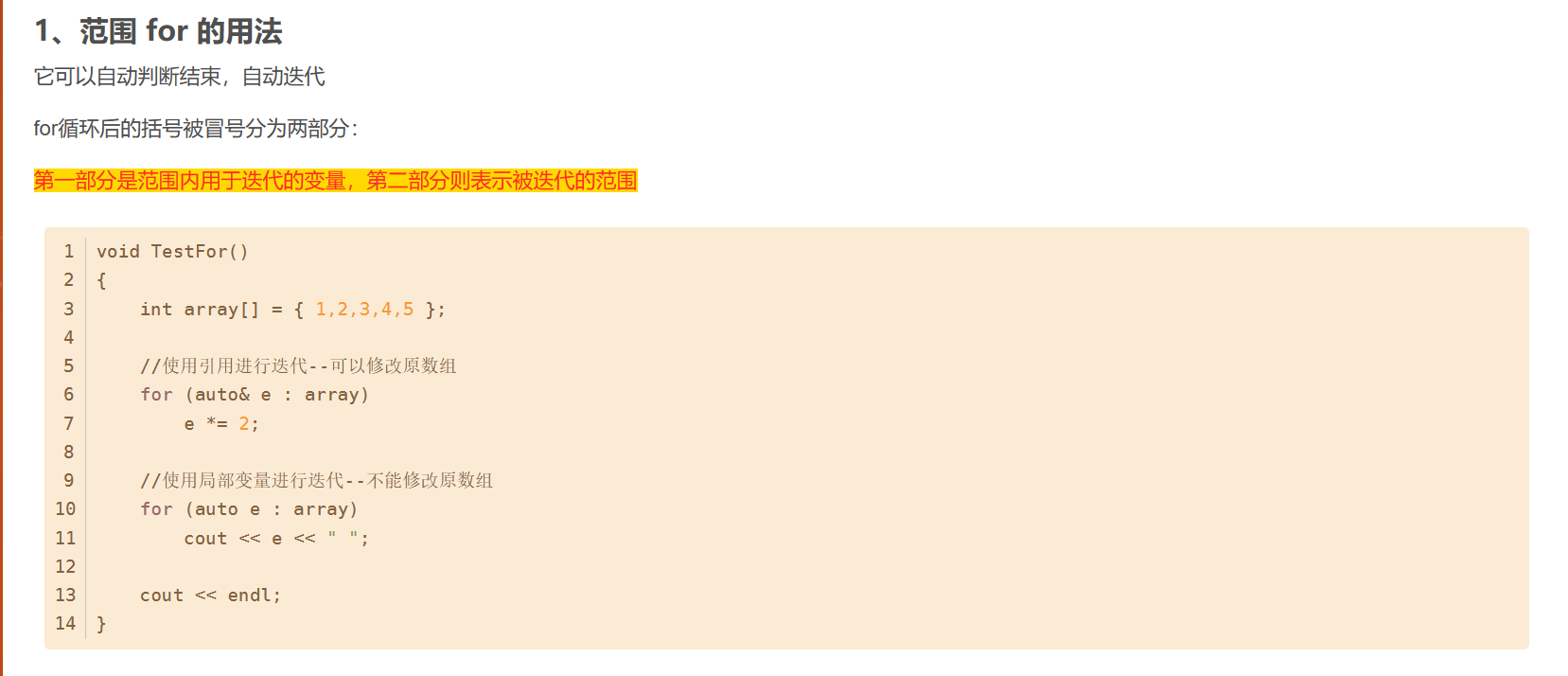

上の 2 つの図は、Xiaoyang C++ エントリ スコープの説明からの抜粋です。
4.3 イテレータのトラバーサル
[ ] これは単なる北朝鮮です。普遍的なものにしたいなら、私の反復子を参照する必要があります。
イテレータは、使用方法や動作の点ではポインタに似ていますが、それでもポインタとは異なります。定義する際にはクラスドメインを指定する必要があり、例えば以下のコードのit1の定義ではクラスドメインにイテレータの型を指定する必要があります。以下のコードからわかるように、it1 はオブジェクト s1 の内容にアクセスできるだけでなく、その内容を変更することもできます。そして、文字列に加えて、私たちの面倒なリストでは通常どおり iterator を使用することもできます。これにより、 iterator の汎用性も検証されます。
list<int> lt;
list<int>::iterator ltit = lt.begin();
while (ltit != lt.end())
{
cout << *ltit << " ";
ltit++;
}
cout << endl;したがって、文字列をトラバースするときは、begin インターフェイスと end インターフェイスを使用します。
int main()
{
string s1("i love gao_peng_yan");
string::iterator it1=s1.begin();
while(it1!=s1.end())
{
cout << *it1 ;
it1++;//别忘了迭代器++,要不然走不后去
}
return 0;
}イテレータのような重要な知識をトラバーサルのサブタイトルに入れるのはあまりにも不公平なので、ぜひ読んでください。!
5. 文字列イテレータ (イテレータはポインタをカプセル化し、ポインタの動作をシミュレートするクラスです)
イテレータは C++ のイテレータです。イテレータは普遍的で、ほとんどのコンテナに適用できます。ポインタとして理解できます。もちろん、すべてのイテレータが下部にポインタを使用して実装されているわけではありません。
typedef char* iterator; //简单理解string中的迭代器
実際のコードの書き方:
string::iterator it1=s1.begin();//(it1的类型是属于string类域当中的)
| 関数名 | 機能の説明 |
| 始める() | 文字列の最初の文字を指す反復子を返します。 |
| 終わり() | 文字列の最後の文字 ('\0') の次の位置を指す反復子を返します。 |
| rbegin() | 逆に開始して、文字列の最後の文字 ('\0') の次の位置を指す反復子を返します。 |
| レンド() | 逆に開始して、文字列の最初の文字を指す反復子を返します。 |
終了イテレータがどこにあるかについて誤解があるので、誰でもわかるように図を描きます。
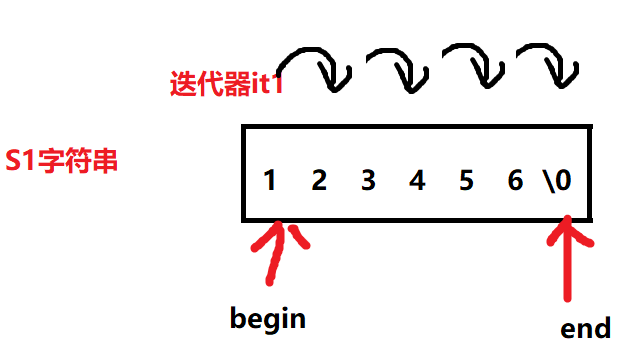
5.1開始インターフェイスと終了インターフェイス
トラバースするときは、インターフェースの begin と end を使用する必要がありますが、ドキュメントを参照すると、戻り値はすべてイテレータであることがわかります。begin() は最初の文字のイテレータを返し、end() は最後の文字 (通常は識別文字 \0) の次の位置のイテレータを返します。実際、これはポインタと同様に使用され、イテレータを逆参照することで対応する文字を取得し、その文字を操作できます。
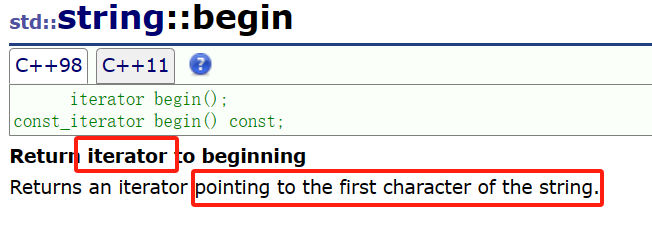
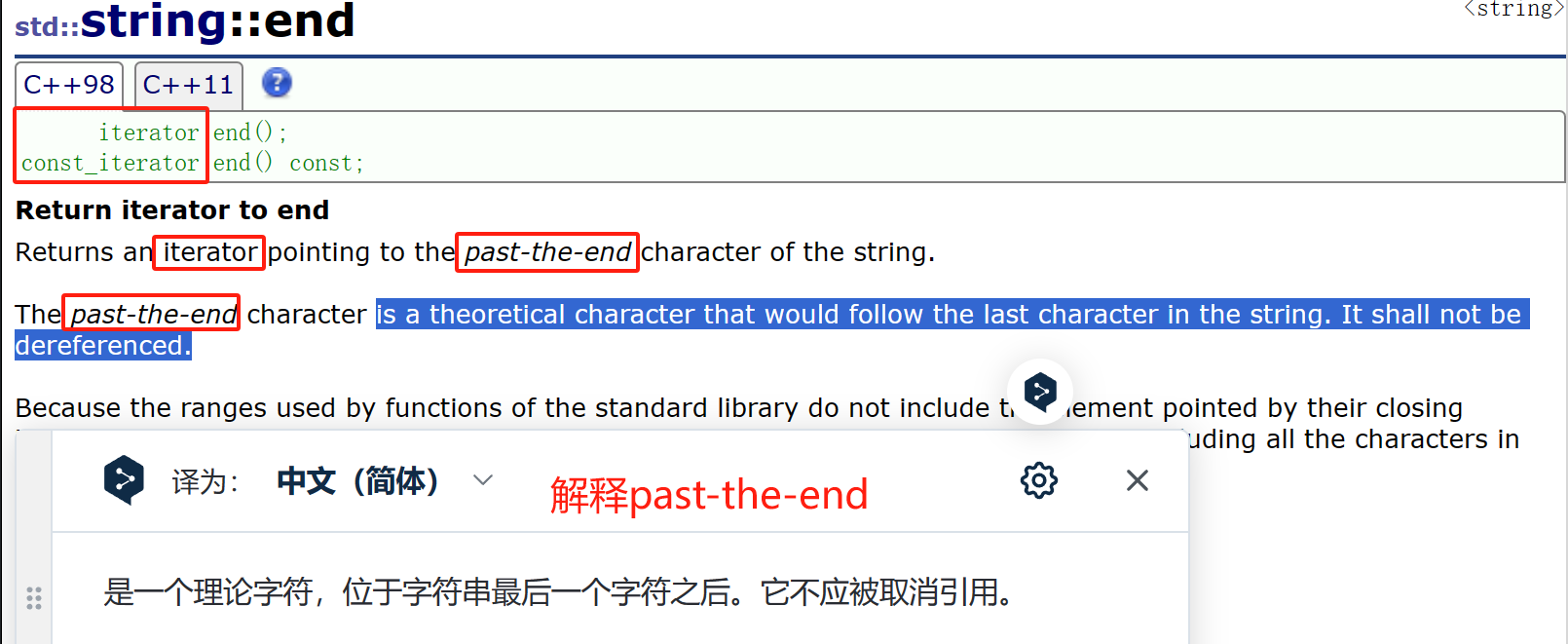
したがって、文字列をトラバースするときは、begin インターフェイスと end インターフェイスを使用します。
int main()
{
string s1("i love gao_peng_yan");
string::iterator it1=s1.begin();
while(it1!=s1.end())
{
cout << *it1 ;
it1++;//别忘了迭代器++,要不然走不后去
}
return 0;
}5.2定数反復子
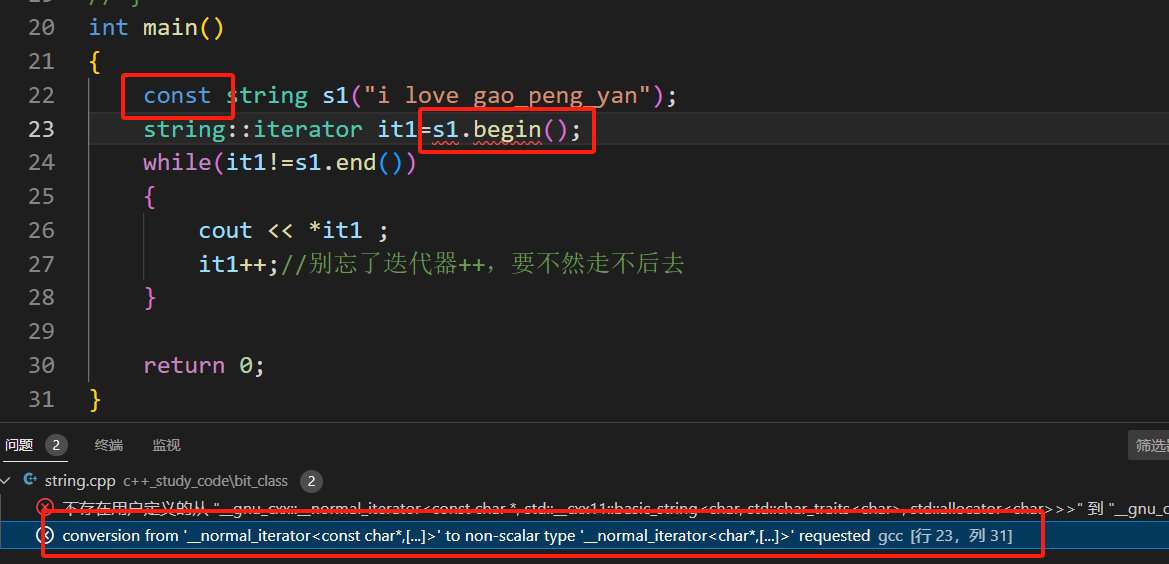
文字列の前に const を追加すると、見つかったコードは実際にエラーを報告しました。const オブジェクトは非 const オブジェクトのイテレータを使用していました。ドキュメントを確認したところ、確かに const イテレータがあることがわかりました。
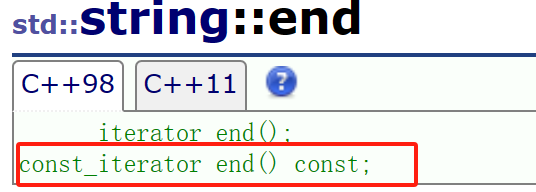
そこで、コードを変更します。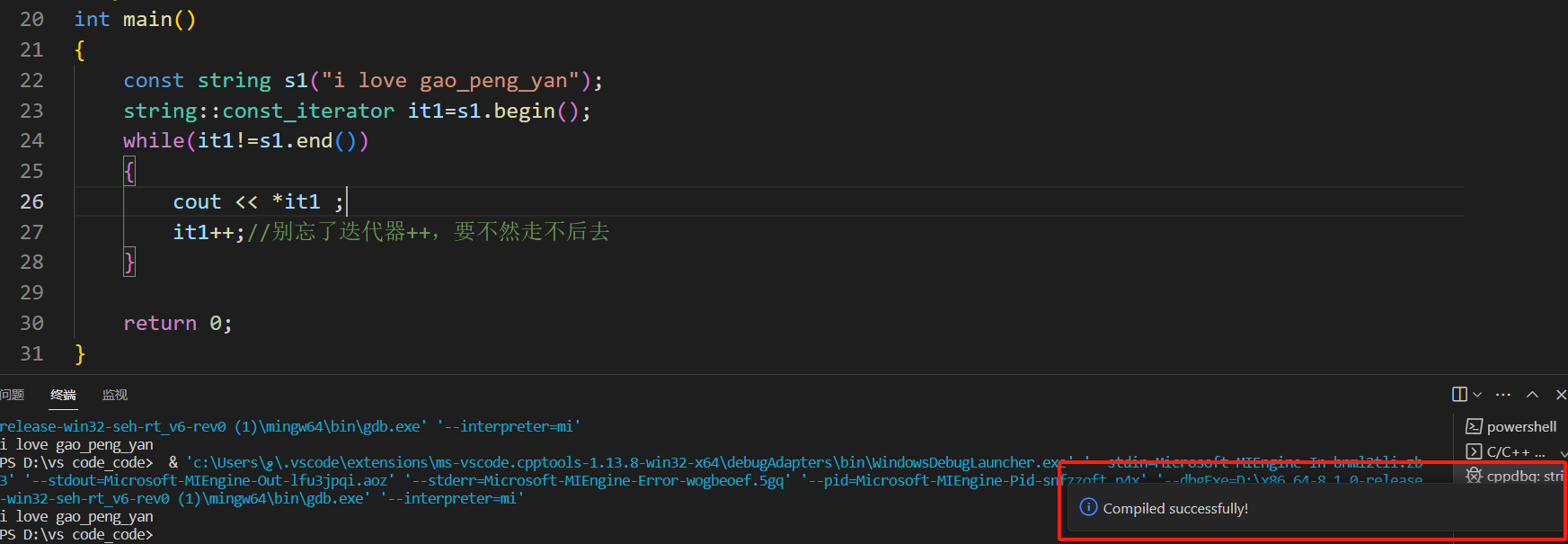
ああ、合格しました!!!
子羊のメモ:
const string::iterator it1=s1.begin();
string::const_iterator it1=s1.begin();
これら 2 つのまったく異なる書き方:
最初の反復子の場合、これは反復子のポインターを変更しないことを意味しますが、反復子は逆方向に進むことになっているため、通常はこのようには記述しません。
2 番目の反復子の場合、反復子によってアクセスされる要素の内容が変更されないことを意味します。

5.3 イテレータとポインタの違い
イテレータとポインタは 2 つの異なる概念であり、いくつかの点では類似点がありますが、異なるプログラミング コンテキストで使用され、異なる特性と用途があります。それらの主な違いは次のとおりです。
1. 目的:
- イテレータ: イテレータは抽象データ アクセス メソッドであり、通常、コレクション内の要素 (配列、リスト、マップなど) をトラバースするために使用されます。イテレータは、基礎となる要素を知らずにコレクションにアクセスするための一般的な方法を提供します。データ構造。
- ポインタ: ポインタは、メモリ内のオブジェクトのアドレスを格納する変数タイプです。ポインタは通常、メモリ アドレスへの直接アクセス、動的メモリ割り当てなどを含む、低レベル言語 (C や C++ など) でのメモリ操作に使用されます。2. 安全性:
- イテレータ: イテレータは通常、境界外アクセスやメモリ エラーを回避するための保護メカニズムを提供するため、コレクションを走査するためのより安全な方法として設計されています。異なるプログラミング言語のイテレーターは、異なる安全性特性を持つ場合があります。
- ポインター: ポインターが低レベル言語で使用されると、Null ポインター参照、範囲外アクセスなどのメモリー エラーが簡単に発生する可能性があります。したがって、ポインターの使用にはより注意が必要であり、プログラマーは安全性を確保する必要があります。3. 抽象化のレベル:
- イテレータ: イテレータは、基礎となるデータ構造の詳細を隠す、より高いレベルの抽象化を提供します。これにより、コードが読みやすく保守しやすくなり、プログラム内のエラーが減ります。
- ポインタ: ポインタはメモリ アドレスを直接操作する低レベルの抽象概念であり、プログラマはメモリ レイアウトとデータ構造の詳細を理解する必要があります。4. 言語の依存関係:
- イテレーター: イテレーターは、組み込みイテレーターまたはコレクション走査メカニズムを提供する高水準プログラミング言語 (Python、C#、Java など) でよく使用されます。
- ポインタ: ポインタは、メモリ操作を直接サポートする低レベル プログラミング言語 (C や C++ など) でより一般的であるため、プログラマはコンピュータ ハードウェアとメモリ管理についてより深い理解を必要とします。
6. 文字列の容量(サイズ変更、予約、クリア)
String は、容量を操作するいくつかの関数を提供します。

| 関数名 | 関数関数 |
|---|---|
| サイズ() | 文字列の長さを返します |
| 容量 | 文字列の容量を返します |
| 空の | 文字列が空かどうかを判断する |
注: サイズと容量は 2 つの完全に異なる機能インターフェイスです。

6.1サイズ変更(文字列を n 文字の長さに変更します)

サイズ変更機能は文字列のサイズを調整するために使用され、次の 3 つの状況に分けられます。

- n は元の文字列のサイズより小さいため、このときリサイズ関数は元の文字列のサイズを n に変更し、文字列の初期値も変更しますが、容量は変更しません。
- n は元の文字列のサイズより大きいですが、その容量よりは小さいです。このとき、サイズ変更関数は、size 以降のすべてのスペースを文字 c に設定します。
- n は元の文字列の容量より大きいです。このとき、サイズ変更関数は元の文字列を拡張し、size の後のすべてのスペースを文字 c に設定します。
状況 1 (切り捨てが発生する):

シナリオ 2 (拡張なし、ただし割り当ては可能):
文字列サイズを 13 に変更しましたが、拡張されませんでした

シナリオ 3 (拡張と割り当て):

6.2予約スペースの確保(通常は拡張に使用)(サイズは変更されません)

reserve は領域の拡張と予約に使用され、C 言語の realloc 関数に相当します。これは 2 つの状況に分けられます。
- n は元の文字列の容量より大きいため、このとき、reserve 関数により容量が n に拡張されます。
- n は元の文字列の容量以下です。標準では容量を削減するかどうかは指定されていません (VS では削減なし)。
string s1("xiao_yang");
cout << s1.size() <<endl;
cout << s1.capacity() << endl << endl;
s1.reserve(100);//预留100的空间
cout << "预留后的size与capacity" << endl;
cout << s1.size() << endl;
cout << s1.capacity() << endl;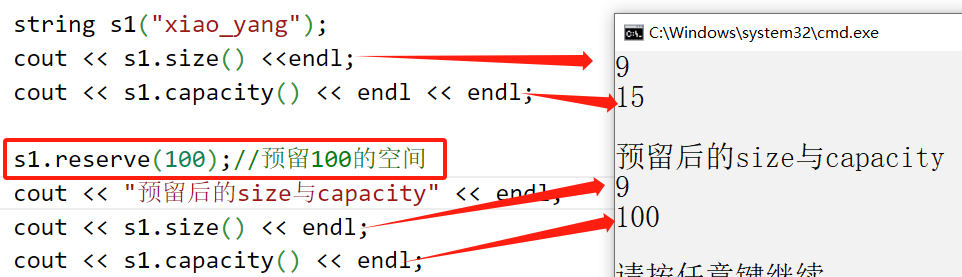
Xiaoyang のメモ: reserve 関数は元の文字列のサイズとデータを変更しません。
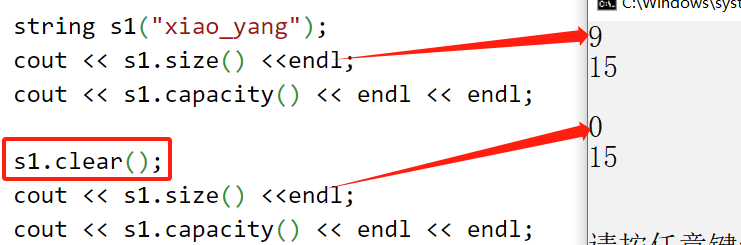
6.3clear(クリアストリング)
Clear 関数は、文字列をクリアする、つまりサイズを 0 に変更するために使用されます。容量が変更されるかどうかについては、標準では規定されていません。

7. 文字列の要素アクセス(要素アクセス)
string は、文字列内の個々の文字を取得するためのいくつかのインターフェイスを提供します。

Operator[ ] (上記の文字列トラバーサルで詳しく説明しました。ここでもう一度確認してみましょう)
演算子のオーバーロードの一種で、opetator[] を使用して文字列内の特定の添字文字を取得および変更できます。
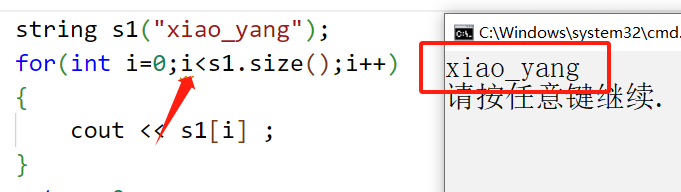
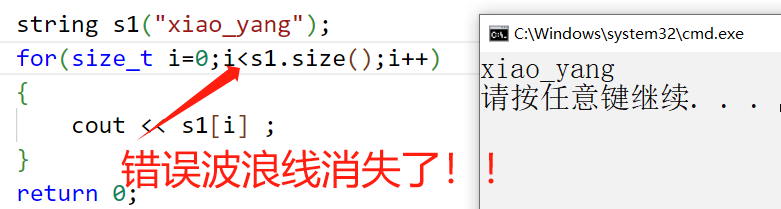
ここでの出力は正しいのに、なぜここにプロンプトが表示されるのでしょうか? ?
ドキュメントを見ると、[ ] のパラメータは size_t であり、unsigned int であることがわかります。したがって、ここに int を記述するのは不合理です。
8. 文字列の変更(+=、追加、挿入、消去、交換)
string は、文字列の内容を変更するための一連の関数を提供します。
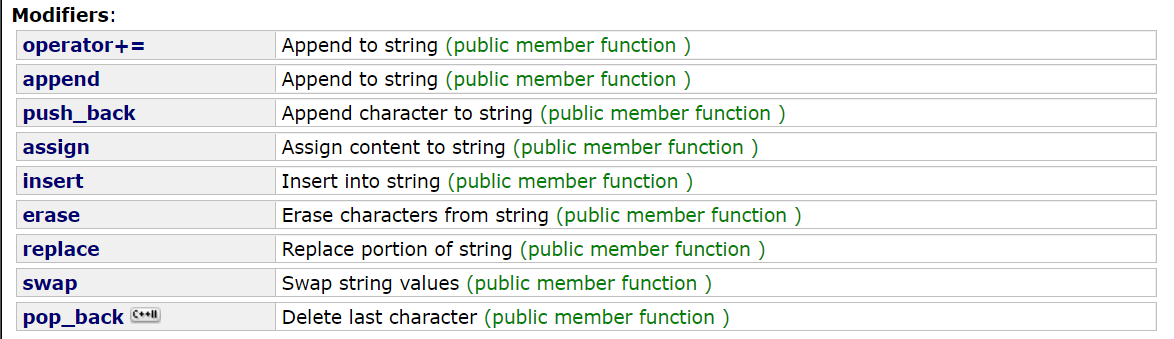
8.1演算子+= (最も素晴らしい末尾の挿入)
Operator+= は演算子のオーバーロードの一種で、文字列の末尾にデータを挿入するために使用されます。文字列の挿入、文字配列の挿入、末尾への文字の挿入をサポートしています。
string s1("xiao_yang");
string s2=" hehe ";
s1+=s2;cout << s1 << endl;
s1+="abcabc";cout << s1 << endl;
s1+='c';cout << s1 << endl;
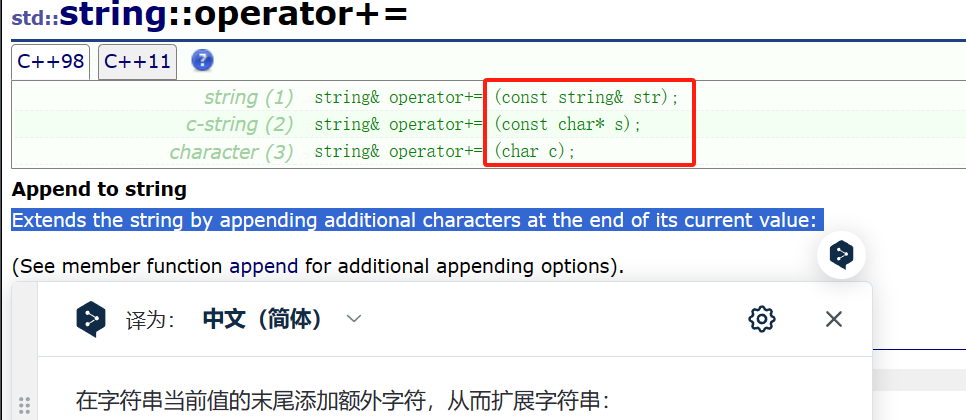
8.2append (最後にデータを追加しますが、+= はありません)
append の機能は、operator+= の機能と似ており、どちらも文字列の末尾にデータを追加します。
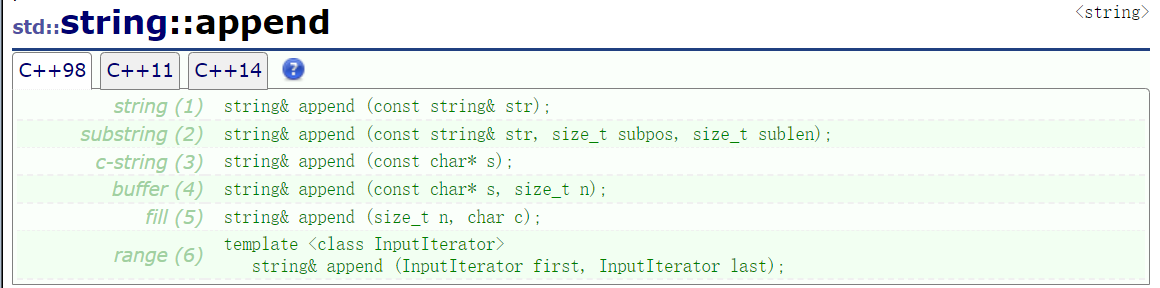

8.3insert (任意の位置に挿入) (通常は使用しません、時間の無駄です)
insert 関数は、文字列の pos にデータを挿入するために使用されます。

#include <iostream>
#include <string>
int main() {
std::string original_string = "Hello, world!";
// 在字符串的指定位置插入字符或子字符串
original_string.insert(7, "there, ");
std::cout << original_string << std::endl;
// 输出: "Hello, there, world!"
// 在字符串的末尾插入字符或子字符串
original_string.insert(original_string.length(), " How are you?");
std::cout << original_string << std::endl;
// 输出: "Hello, there, world! How are you?"
// 在字符串的开头插入字符或子字符串
original_string.insert(0, "Hi, ");
std::cout << original_string << std::endl;
// 输出: "Hi, Hello, there, world! How are you?"
return 0;
}
8.4erase(任意の位置を削除)
Erase は、位置 pos から開始して後方に len 文字を削除するために使用されます。
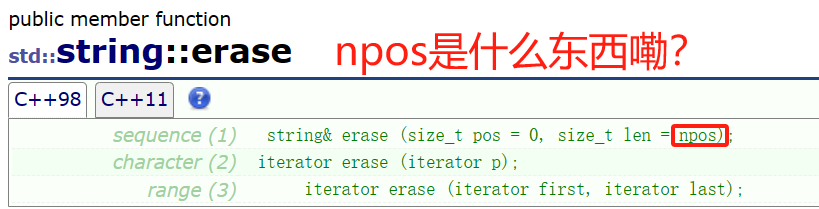
ここのNPOはとても特殊なんです!


npos は、型の値が単純な int ではなく size_t であるため、ここでは特別です。上記の Erase の最初のインターフェイス len の背後では、len のデフォルト値は npos です。npos の値は -1 ですが、npos は符号なしの数値です。したがって、nposは実際には符号なし整数の最大値です。したがって、len がわからない場合、消去関数は '\0' に到達するまで削除を続けます。
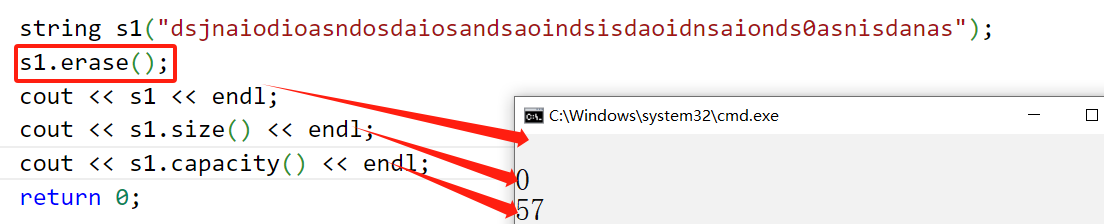
8.5 swap (パラメータであり、一般的なものとは異なります)
swap 関数は、指定された文字配列、有効なデータの数、容量などの 2 つの文字列の内容を交換するために使用されます。

string s1("dsjnaiodioasndosdaiosandsaoindsisdaoidnsaionds0asnisdanas");
string s2;
cout << "s1原来的size " << s1.size() << endl;
cout << "s1原来的capacity " << s1.capacity() << endl;
cout << "s2原来的size " << s2.size() << endl;
cout << "s2原来的capacity " << s2.capacity() << endl;
s1.swap(s2);
cout << endl << endl << endl;
cout << "s1交换后的size " << s1.size() << endl;
cout << "s1交换后的capacity " << s1.capacity() << endl;
cout << "s2交换后的size " << s2.size() << endl;
cout << "s2交换后的capacity " << s2.capacity() << endl;
9. 文字列演算演算関数(c_str、find、、substr)
string は、string を操作する一連の関数を提供します。

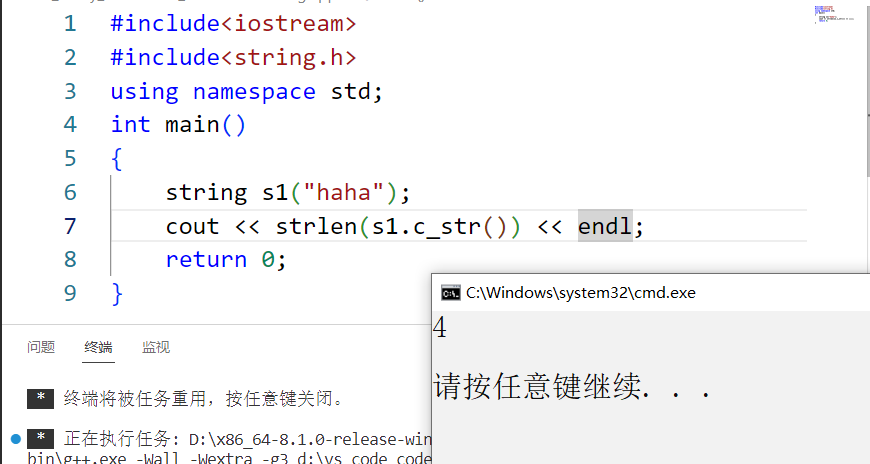
9.1c_str (C++とC言語間のインターフェースを作るため、大使館とみなされます)
一部のシナリオでは、ネットワーク送信や fopen などの C 形式の文字列、つまり文字配列に対する操作のみがサポートされていますが、C++ の文字列オブジェクトに対する操作はサポートされていません。 C 形式の文字列。
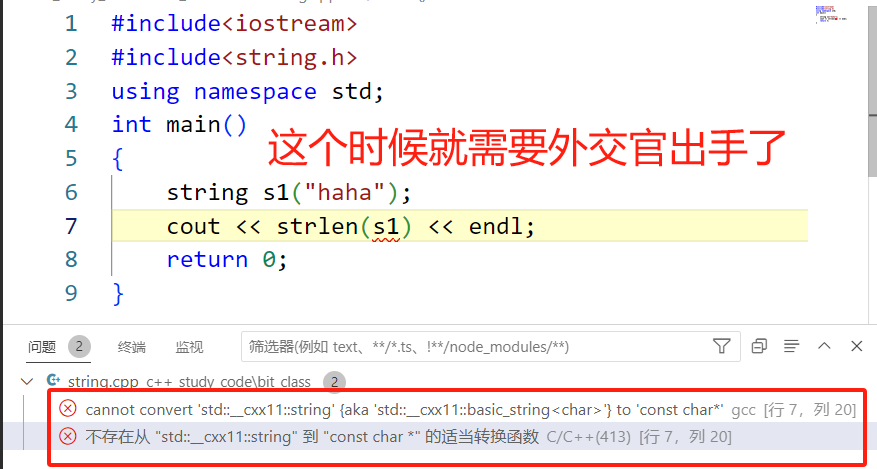
#include<iostream>
#include<string.h>
using namespace std;
int main()
{
string s1("haha");
cout << strlen(s1.c_str()) << endl;
return 0;
}
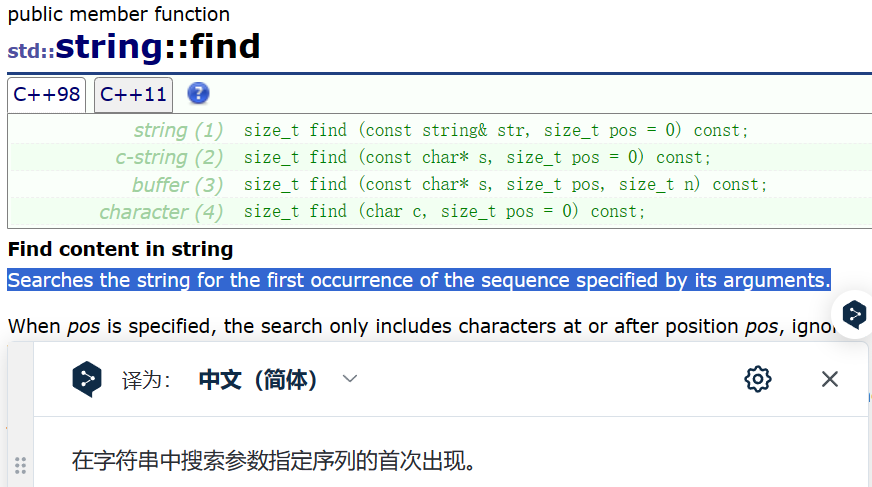
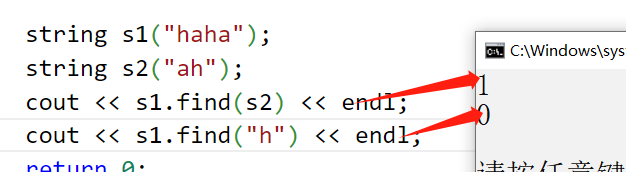
9.2find (検索文字列、npos も含む)
find は、文字、文字配列、または文字列オブジェクトが string 内で最初に出現する位置を返すために使用されます。それが見つからない場合は、npos が返されます。
#include<iostream>
using namespace std;
int main()
{
string s1("haha");
string s2("ah");
cout << s1.find(s2) << endl;
cout << s1.find("h") << endl;
cout << s1.max_size() << endl;
return 0;
}
9.3rfind (rfind はファイルの接尾辞を見つけるのに非常に快適です)
find 関数はデフォルトで開始位置から前から後ろに検索しますが、rfind 関数はデフォルトで後ろから前に検索します。

string s1("test.cpp");
string s2("hehe.c.zip");
cout << s1.find('.') << endl;
cout << s2.rfind(".") << endl;
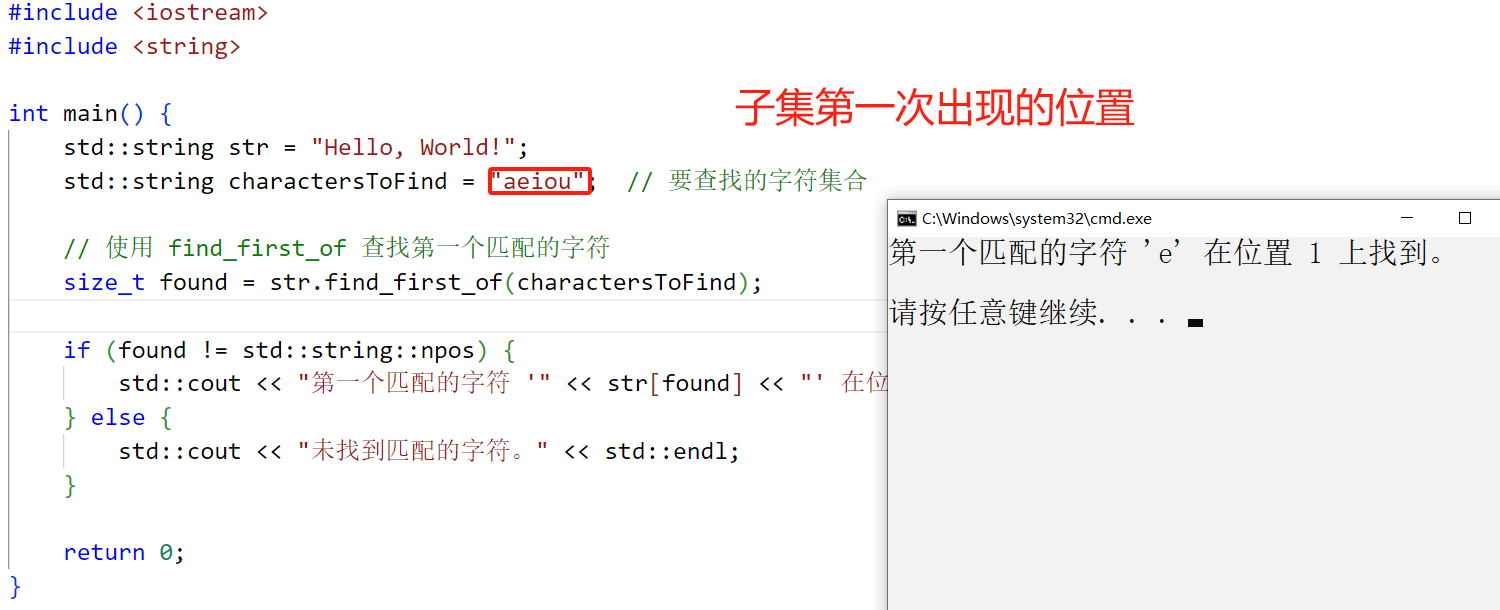
9.4find_first_of (文字サブセットの最初の出現を検索)
find_first_of 関数は、文字/文字配列/文字列内の任意の文字に一致する文字列内の要素の位置を返すために使用されます。

#include <iostream>
#include <string>
int main() {
std::string str = "Hello, World!";
std::string charactersToFind = "aeiou"; // 要查找的字符集合
// 使用 find_first_of 查找第一个匹配的字符
size_t found = str.find_first_of(charactersToFind);
if (found != std::string::npos) {
std::cout << "第一个匹配的字符 '" << str[found] << "' 在位置 " << found << " 上找到。" << std::endl;
} else {
std::cout << "未找到匹配的字符。" << std::endl;
}
return 0;
}
9.5substr (文字列を切り捨てて返す)

string s1("haha hehe heihei");
cout << s1.substr(0,s1.size()) << endl;
cout << s1.substr(5,10) << endl;//从5开始 弄10个
cout << s1.substr(10,10) << endl;
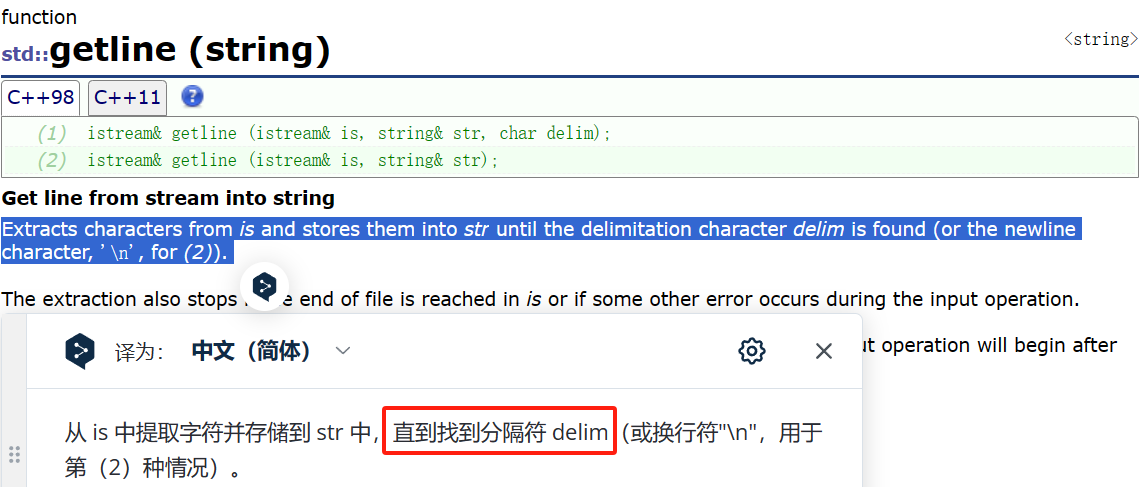
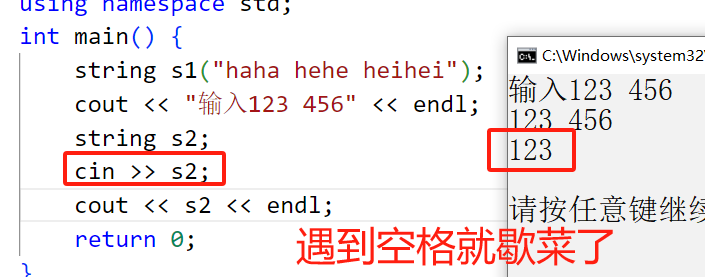
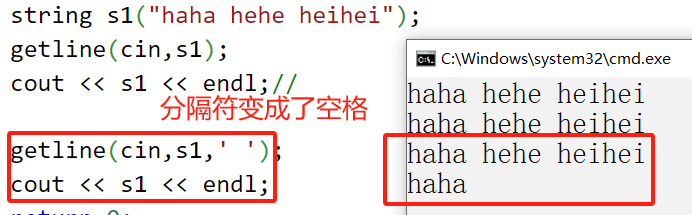
10. 非メンバー関数のオーバーロードされた関数 (getline)
getline は通常 OJ で有効です。これは、cin がスペースに遭遇すると停止するためです。
string s1("haha hehe heihei");
getline(cin,s1);
cout << s1 << endl;//
getline(cin,s1,' ');
cout << s1 << endl;
この記事があなたのお役に立てば幸いです! !
