Spring を初めて学んだとき、まだ XML ファイルを次々と書かなければならなかったのを今でも覚えています。当時は理由がわかりませんでした。インターネット上の手順に従って 1 つずつ設定していました。一致しないものがあると、 「長い間混乱してエラーを確認しました。最終的に実行できるようになるまで、ランダムに変更を加えただけです。これは本当に複雑です」と密かにため息をつきました。
その後 SpringBoot を使ってみると、XML の設定がかなり抜けているようで、密かに嬉しかったです。最初はデフォルト設定に従って正常に動作していましたが、後で変更が必要になったとき、どこから始めればよいのかわかりませんでした。
ほとんどの場合、ぼんやりと使用できますが、奇妙な問題が発生した場合は、Lao Li に助けを求めなければなりません。
その後 Spring Cloud というものがあることを知り、これからはマイクロサービスの時代が来るので、もうこのまま Spring Family Bucket を使うことはできないと思います。
フレームワークの本当の意味を理解しようと、SpringCloud の詳細なソースコードを一度にいろいろと突っ込んでみたのですが、結局うまくいかず落胆して帰ってきて、tmd って本当に複雑だなと改めて嘆きました。
この間、私は Spring の基本フレームワークに精通しておらず、多くのカプセル化ポイントを理解できていないことに気づきました。
結局のところ、SpringCloud は SpringBoot に基づいており、SpringBoot は Spring に基づいています。
そこで、Spring をもう一度学び直しました。さまざまな詳細に没頭するのではなく、戦略を変更しました。まず Spring を高次元の観点から概観し、核となる原則を理解し、その後、さまざまな分野を制覇しました。
それで私は、強くなりました。

実は、何を学ぶときも同じで、まず概要を掴んでから深堀りし、振り返ってからまとめる必要があります。
この記事では、Spring の核心 (考え方) を私なりの理解で説明したつもりです。私の個人的な表現力により、誤りや冗長な点があるかもしれません。ご容赦ください。間違いがあれば、ご指摘ください。 。
IOC と DI は脇に置いて、なぜ Spring が必要なのかを考えてみましょう
初めて Java を学ぶとき、私たちは自然に次のようなコードを書きます。
public class ServiceA {
private ServiceB serviceB = new ServiceB();
}
复制代码いくつかのロジックを にカプセル化します。これらのロジックを使用する必要があるServiceB 場合、それはの中にあります。ServiceAServiceAnew ServiceB
カプセル化されたロジックが非常に一般的な場合、それに依存する必要がある他のものServiceB が存在するため、コード内のあらゆる場所で新しいものが必要になることを意味します。このように、その構築方法が変更された場合、すべての場所でそのロジックを使用する必要があります。その場所に移動し、コードを変更します。ServiceCServiceFServiceB
たとえば、ServiceB インスタンス を作成する必要がある場合ServiceC 、コードを次のように変更する必要があります。
public class ServiceA {
private ServiceB serviceB = new ServiceB(new ServiceC());
}
复制代码確かにこの問題はあります。
しかし実際には、共通serviceロジックをカプセル化すれば、毎回新しいインスタンスを作成する必要はありません。つまり、インスタンスは 1 つだけで十分です。この問題を解決するには、システムがオブジェクトごとにnew1 つだけ必要とします。ServiceB
public class ServiceA {
private ServiceB serviceB = ServiceB.getInstance();
}
public class ServiceB {
private static ServiceB instance = new ServiceB(new ServiceC());
private ServiceB(){}
public static ServiceB getInstance(){
return instance;
}
}
复制代码問題は解決されたように見えますが、そうではありません。
大学の大規模な課題など、プロジェクトが比較的小規模な場合、上記の操作は実際には大きな問題にはなりませんが、エンタープライズレベルのアプリケーションとなると複雑になります。
多くのロジックが含まれるため、カプセル化されたサービス クラスも多く、コード内に 、ServiceB1...ServiceB2が存在したりServiceB100、相互に依存関係が存在したりするなど、依存関係も複雑です。
ServiceB依存関係を脇に置いて、単純なシングルトン ロジック コードを取り上げるだけで、繰り返しロジックを数百、数千のコピーで記述する必要がある場合があります。
また、拡張も容易ではなく、以前はServiceBの動作にトランザクションが必要なかったかもしれませんが、後からトランザクションが必要になるため、ServiceBトランザクション関連のロジックを組み込むためにコードを修正する必要があります。
その後すぐにServiceC、トランザクションも必要になり、トランザクションに関するまったく同じコードを ServiceC と D、E、F... で繰り返す必要がありました。
複数のServiceトランザクションは要件が異なりますし、トランザクションの入れ子の問題もあり、一言で言えば少々面倒です。
ここしばらくトランザクション要件を満たすために忙しく、オンラインにアクセスしましたが、コードを繰り返す悪夢からようやく解放され、ゆっくり休めると思いました。
オンラインの問題のトラブルシューティングが必要になることが多いため、トラブルシューティングを容易にするためにインターフェイスの入力パラメータをログに記録する必要があり、大幅な変更を一度に行う必要があります。
必要に応じて変更を加えるのは通常のことですが、各変更には多くの反復作業が必要であり、面倒で、技術的な内容がなく、見落としがちです。これは十分エレガントではありません。
そこで、このカップリングの泥沼から抜け出す方法を考え始めた人もいました。
エレベーションとストリッピング
人間の発明のほとんどは怠惰によるもので、人間は反復的な作業を嫌いますが、コンピュータは反復的な作業を好み、反復的な作業を行うのに最適です。
以前の開発では繰り返しの作業がたくさんあるので、そのような繰り返しの作業を支援する「もの」を作成してみてはいかがでしょうか?
昔と同じように、人間が一つ一つ手作業で製品を組み立て、製造していましたが、同じ作業を毎日何万回も繰り返すこともありましたが、その後、製品の製造を支援する全自動機械が開発され、人の手が解放され、製品の改良が行われました。生産効率。

このアイデアを改善した後、コーディング ロジックは、 ServiceA が特定の ServiceB に依存することを考えて記述し、 ServiceB がどのようにインスタンス化されるかについてコードを 1 文字ずつ入力することから、 ServiceB に依存する ServiceA のみを気にするように変更されました。 ServiceB がどのように生成されるかは関係ありません。その「もの」は、ServiceB の生成と ServiceA と ServiceB の関連付けに役立ちます。
public class ServiceA {
@注入
private ServiceB serviceB;
}
复制代码少し非現実的に聞こえるかもしれませんが、そうではありません。
もう一度機械の話に戻ります。私たちはこの機械を作ります。製品Aを作りたいなら、図面Aを描いて、その図面Aをこの機械に詰め込むだけです。機械は図面Aを認識し、設計に従って欲しいものを生産します。私たちの図面 A. 製品 A.
Spring はこのマシンであり、描画は Spring によって管理されるオブジェクト コードとそれらの XML ファイル (またはアノテーション付き@Configurationクラス) に依存します。
このときロジックが変わります。プログラマーはServiceAどちらに依存するかをServiceB知っていますが、コード内で ServiceB を作成する方法に関する完全なロジックを明示的に記述する必要はありません。構成ファイルを記述するだけでよく、Spring が特定の作成と関連付けを支援します。
続いて機械の例で言うと、図面(構成)を渡され、機械が製品を作るのServiceAを手伝ってくれます。ものづくりにはどのようなロジックが必要なのでしょServiceBうかServiceB?ServiceC
Spring でのデータベースの構成の描画例を探しています。

私たちの図面が非常に明確に書かれていることがわかります。作成するとき、2 つの属性の値を伝える必要があります。たとえば、最初の属性は でmybatis、値は です。MapperScannerConfigurersqlSessionFactoryBeanNamesqlSessionFactory
そしてそれはsqlSessionFactoryそれに依存しておりdataSource、dataSource設定する必要があるなどですdriverClassName。url
したがって、実際には製品(Bean)を作成するために何が必要かはよくわかっていますが、作成プロセスは Spring によって処理されるため、それを明確に伝えるだけで済みます。
ServiceAしたがって、Spring では特定の依存関係ServiceBやその依存関係がどのように正常に作成されるかを気にしなくなったという意味ではなくServiceB、これらのオブジェクトを組み立てるプロセスが Spring によって行われるということです。
Spring に伝えるために正しい描画を描画する必要があるため、オブジェクトがどのように作成されるかを明確に知る必要があります。
Spring は実際には、与えられた図面に基づいて使用する関連オブジェクトを自動的に作成するマシンであり、コード内に完全な作成コードを明示的に記述する必要はありません。
Spring によって作成されるこれらのオブジェクト インスタンスは Bean と呼ばれます。
これらの Bean を使用したい場合は、Spring から取得できます。Spring は、作成されたこれらのシングルトンBean をマップに配置し、名前またはタイプでこれらの Bean を取得できます。
これは IOC です。
これらの Bean は、コードの隅々で遅延して作成するのではなく、Spring マシンによって作成する必要があるため、この統一されたインターフェイスに基づいて多くのことを簡単に行うことができます。

たとえば、アノテーションServiceBが付けられている場合、Spring はこのアノテーションにトランザクションが必要であることを認識し、開始、コミット、ロールバック、その他のウーブン トランザクションの操作を行うことができます。@TransactionalServiceB
アノテーションが付けられたものはすべて@Transactional自動的にトランザクション ロジックを追加するため、反復的なコードが大幅に削減されます。トランザクションを必要とするメソッドまたはクラスにアノテーションを追加する限り、@TransactionalSpring がトランザクション機能を補完し、反復操作は Spring によって実行されます。春が完成しました。
別の例として、すべてのコントローラーのリクエスト入力パラメーターを記録する必要があります。これも非常に簡単です。xxx パス (コントローラー パッケージ パス) にあるクラスの各メソッドの入力パラメーターを Spring に伝える設定を記述するだけです。 ) をログに記録する必要があり、ログ出力ロジック コードも記述します。
Spring はこの設定を解析した後にこのコマンドを取得したので、後続の Bean を作成するときに、そのパッケージが上記の設定に準拠しているかどうかを確認し、準拠している場合はログ出力ロジックを追加し、元のロジックと織り合わせます。 。
このようにして、繰り返されるログ出力アクションの操作が構成に抽象化され、Spring マシンがその構成を認識した後、コマンドを実行してこれらの繰り返されるアクションを完了します。
これは AOP と呼ばれます。
ここまでで、Spring の成り立ちと中心となる概念についてはある程度理解できたと思いますが、上記の機能に基づいて実行できることは数多くあります。
Springのクローズ処理が統一されているため、設定ファイルの解析時、Beanの初期化の前後、Beanのインスタンス化の前後など、さまざまなタイミングで柔軟に多くの拡張ポイントを提供できます。
これらの拡張ポイントに基づいて、Bean の選択的ロード、プレースホルダーの置換、プロキシ クラス (トランザクションなど) の生成など、多くの機能を実装できます。
たとえば、SpringBoot Redisクライアントを選択すると、デフォルトで とlettuceのjedis2 つのクライアント構成がインポートされます。

構成順序に基づいて、レタスが最初にインポートされ、次に jedis がインポートされます。
@ConditionalOnMissingBean(RedisConnectionFactory.class)スキャンでレタスが見つかった場合は、レタスの RedisConnectionFactory を使用します。後で jedis をロードするときは、 jedis が注入されないことを確認するために基づいて、そうでない場合は注入されます。
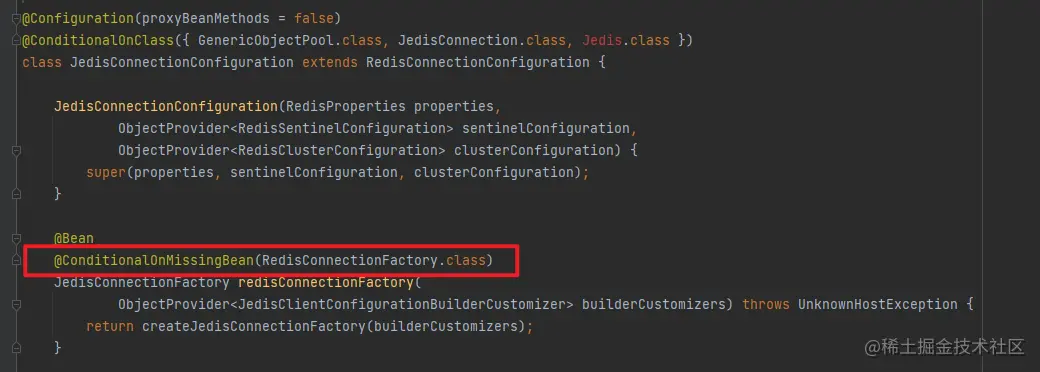
ps:@ConditionalOnMissingBean(xx.class) 現在 xx.class が存在しない場合、このアノテーションによって変更された Bean を生成できます。
上記の機能は、Spring が提供する拡張ポイントに基づいて実装されています。
使用されているコードを変更することなく、必要な Redis クライアントを置き換えることは非常に柔軟です。依存関係を変更するだけで済みます。たとえば、デフォルトのレタスから jedis に変更するには、Maven 設定を変更し、レタスを削除するだけです。依存関係を確認し、jedis を導入します。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
复制代码私が本当に言いたいのは、Spring Family Bucket が提供する拡張機能とカプセル化は多くのニーズに柔軟に対応でき、これらの柔軟性は Spring のコア IOC と AOP に基づいているということです。
やっと
最後に、段落を使用して Spring の原理を簡単に説明します。
Spring は、提供された構成クラスと XML 構成ファイルに従ってコンテンツを解析し、管理する必要がある Bean の情報とそれらの間の関係を取得します。また、Spring は、カスタマイズできる多くの拡張ポイントを公開します。これをBeanFactoryPostProcessor実装する必要がありますBeanPostProcessor。インターフェイスはいくつかのカスタマイズされた操作を実行できます。
Spring が Bean 情報を取得した後、リフレクションに基づいて Bean インスタンスを作成し、Bean 間の依存関係をアセンブルし、ネイティブまたは定義した依存関係を散在させて Bean を変換したり、一部の属性を置き換えたり、元の Bean ロジックをプロキシしたりしますPostProcessor。
最後に、構成要件を持つすべての Bean が作成された後、シングルトン Bean がマップに保管され、Bean を取得して使用するための BeanFactory が提供されます。
これにより、コーディング プロセス中に Bean がどのように作成されるかに注意を払う必要がなくなり、多くの反復的なコーディング アクションも節約されます。これらはすべて、私たちが作成したマシンである Spring によって行われます。
言いたいことはこれだけかもしれません。何度か読み返しましたが、表現したいことを明確に説明できているかわかりません。実際、最初はソース コード レベルでコアについて話しましたが、明確に説明するのが難しくなるのではないかと心配です。
最後に、Spring の IOC および DI コンセプトに関するインタビューの回答を以前に書きましたので、URL を参照してくださいhttps://yessimida.gitee.io/interview-of-legends/#/./docs/c-1Spring%E7%B2%BE%E9%80%89%E9%9D%A2%E8%AF%95%E9%A2%98%E8%A7%A3。
