
長期的な視覚的 SLAM (同時位置特定とマッピング) の最も重要な要件の 1 つは、堅牢な位置認識です。探査期間の後、長期間観察されていない領域が再観察されると、標準のマッチング アルゴリズムは失敗します。
これらが確実に検出されると、ループ クロージャ検出によって正しいデータの関連付けが提供され、一貫したマップが取得されます。ループ検出に使用されるのと同じ方法を、突然の動き、深刻なオクルージョン、またはモーション ブラーなどによる軌道損失後のロボットの再位置推定に使用できます。
バッグオブワードの基本的な技術には、新しい画像が取得されたときに最も類似した画像を検索するために、ロボットによってオンラインで収集された画像からデータベースを構築することが含まれます。それらが十分に類似している場合、閉ループが検出されます。従来のテキスト分類では、主にバッグ オブ ワード モデルに基づく方法が使用されます。ただし、BoW モデルにはデータの疎性という重要な問題があります。
通常、テキストには多くの単語が含まれており、テキストには単語のほんの一部しか含まれていないため、BoW モデルによって構築された特徴ベクトルはほとんどがゼロ ベクトルであり、非常にまばらです。これにより、分類が不十分になり、計算効率が低下します。BoBW モデル (Binary Bag of Words) は、BoW モデルのスパース性の問題を克服します。BoW モデルのスパース性の問題を解決するために、研究者らはバイナリ特徴に基づいたバッグ オブ バイナリ ワード (BoBW) モデルを提案しました。BoBW メソッドは、高次元の単語頻度ベクトルの代わりに固定サイズのバイナリ コードを使用してテキストを表します。
このようにして、BoW モデルのスパース性の問題は克服されます。BoBW モデルは計算効率も向上させることができ、BoBW モデルは低次元のバイナリ特徴を使用するため、計算量とメモリ要件が大幅に削減されます。これにより、BoBW モデルは分類速度と効率において大きな利点をもたらします。
バイナリ バッグ オブ ワードは、テキスト内の単語を制限された長さのバイナリ ベクトルにマッピングする特徴表現方法です。具体的には: まず、テキストの語彙リストを設定し、テキスト内に出現するすべての固有の単語を語彙リストの単語として使用します。次に、特定のテキストについて、語彙内の各単語がそのテキスト内に出現するかどうかを確認します。存在する場合は 1、存在しない場合は 0。これにより、テキストを表す固定長のバイナリ ベクトルが構築されます。各要素は語彙内の単語に対応します。
バイナリフィーチャ表現では、FAST アルゴリズムを使用してコーナー ポイントを検出します。FAST アルゴリズムは、コーナー ポイントの周囲の半径 3 のブレゼンハム円のピクセル グレースケールを比較することによってコーナー ポイントを検出します。これにより、比較する画素数が少なくて済み、計算効率が高い。各 FAST コーナー ポイントの BRIEF 記述子を計算します。BRIEF 記述子はバイナリ ベクトルであり、各要素はコーナー ポイントの周囲のパッチ内の 2 つのピクセルの明るさを比較した結果です。簡単な記述子の式:
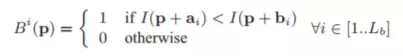
Bi(p) は記述子の i 番目の要素、I() はピクセルの明るさ、ai と bi はパッチの中心に対する 2 つの比較されたピクセルのオフセットです。パッチ サイズ S_b と要素数 L_b が与えられると、a_i と b_i はオフライン段階でランダムに選択されます。2 つの BRIEF 記述子間の距離は、ハミング距離を使用して計算されます。バイナリを使用して Bag of Words モデルを構築し、バイナリ クラスタリング (k メディアン) によってバイナリ記述部分空間をビジュアル ワードに離散化します。直接インデックス付けと逆インデックス付けが実装され、類似画像の検索と幾何学的検証のプロセスが高速化されます。以前の一致との一貫性を考慮することにより、意味的類似性の問題が効果的に処理されます。最終的なアルゴリズムの特徴抽出とセマンティック マッチングにはわずか 22 ミリ秒しかかかりません。これは、SURF などの特徴よりも桁違いに高速です。
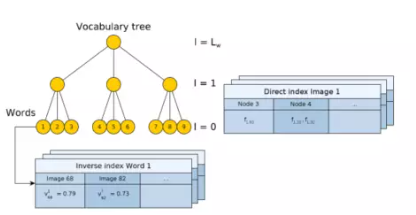
図1 : 画像データベースを構成する語彙ツリーと順方向インデックスと逆方向インデックスの例。語彙はツリーの葉ノードです。逆インデックスは、単語が出現する画像内の単語の重みを保存します。直接インデックス作成では、画像の特徴とそれに関連するノードが語彙ツリーのあるレベルに保存されます。
1. 画像データベースのモデリング
このセクションでは、Bag of Words モデルを使用して画像の特徴をスパース デジタル ベクトルに変換し、大量の画像の処理を容易にする方法を紹介します。語彙ツリーは、説明部分空間を W 個のビジュアルワードに離散化するために使用されます。他の特徴とは異なり、ここで離散的なものはバイナリ記述部分空間であり、モデリングはよりコンパクトです。セマンティック ツリーは、階層的な k メディアン クラスタリングによって構築されます。
まず、トレーニング サンプルに対して k メディアン クラスタリングを実行し、中心を取得します。次に、各クラスタリング ブランチに対して再帰的に繰り返して、最終的なビジュアル ワードとして W リーフ ノードを持つ Lw 層のセマンティック ツリーを構築します。各意味単語にはトレーニング コーパス内の頻度に応じて重みが付けられ、高頻度単語や識別度の低い単語は抑制されます。tf-idf 値を使用します。画像はバッグ オブ ワード ベクトル vt に変換され、そのバイナリ記述子はルートから開始してセマンティック ツリーをたどって、各層間のハミング距離が最小の中間ノードを選択し、最終的にリーフ ノードに到達します。2 つのバッグオブワード ベクトル v1 と v2 の類似性は次のように計算されます。
![]()
この記事では、バッグ オブ ワードと逆インデックスに加えて、直接インデックスを使用して各画像の単語とそれに対応する特徴を保存することも提案しています。直接インデックス付けは、対応する点を迅速に計算するために使用され、同じレベルに属する祖先ノードの特徴のみを比較します。
2. ループバック検出
1.データベースクエリ_
最新の画像を取得したら、それをバッグオブワードベクトル vt に変換します。データベースを検索すると、vt に最も類似した画像 <vt,vt1>、<vt,vt2>、... とそのスコア s(vt,vtj) が得られます。最も一致する画像との正規化された類似度を計算します。
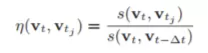
ここで、s(vt,vt-Δt) は前の画像のスコアであり、It の最高スコアを近似するために使用されます。
2.一致グループ化_
連続した画像間の競合を防ぐために、類似した連続した画像がグループ化されます。2 つの画像間の時間差が小さい場合、それらは同じグループに属します。グループのスコアを計算します。
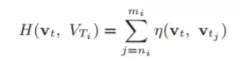
最も高いスコアを持つグループが最初の一致とみなされます。
3.時間的な一貫性
継続的なクエリの一貫性チェック。一致 <vt,VT'> は、以前の k 個の一致 <vt-Δt,VT1>,...,< vt-kΔt,VT"> と一致する必要があり、隣接するグループ間の時間間隔は短くなければなりません。最大の eta スコアを持つ <vt,vt'> が、ループ クロージャーの一致候補として保持されます。
4.効果的な幾何学的一貫性
一致する画像ペア <It, It'> が与えられた場合、最初に直接インデックスで It' をクエリします。直接インデックスを作成すると、各画像に関連付けられた単語とそれに対応する特徴が保存されます。同じ語彙ツリーレベル l に属する親ノードの特徴のみを比較します。
パラメータ l は、一致する点の数と時間コストを重み付けする係数です。l = 0 の場合、同じ単語に属する特徴のみが比較されます (最速) が、得られる対応点の数は少なくなります。l = Lw の場合、対応点の数は影響を受けませんが、時間は改善されません。十分な対応点が得られたら、RANSAC アルゴリズムを使用して基本行列を見つけます。一致を検証するために必要なのは基本行列のみですが、基本行列を計算した後は、追加コストなしで SLAM アルゴリズム用の画像間のデータ関連付けを提供できます。
3. 実験的テスト
評価には、屋内と屋外、静的環境と動的環境をカバーする 5 つの公開データ セットの使用が含まれます。一致する時間間隔を含むループバック グラウンド トゥルースを手動で作成します。精度と再現率を使用して正確さを測定します。さまざまなデータセットを使用してパラメーターを調整し、効果を評価して、アルゴリズムの堅牢性を証明します。
SURFと比較すると、BRIEFの効果はSURFの効果に近く、Bicocca25bに対するSURF64およびU-SURF128よりも優れていることが結果からわかります。BRIEF は高速ですが、スケールと回転の変更に敏感です。BRIEF は遠くのオブジェクトの一致に適しており、SURF は近距離での大きな変化に適しています。

図 2:幾何学的検査を行わずにトレーニング データ セットに対して BRIEF、SURF64、および U-SURF128 によって取得された適合率-再現率曲線。
次に、ループバックを検出するには、一定量の時間一貫性のある検出が必要です。k=3 の結果が最良であり、さまざまな周波数に対して安定しています。以下に示すように:
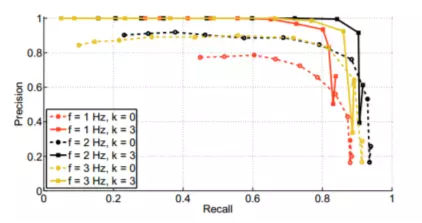
図3 類似度閾値α、時間一致一致数k、処理頻度f
消費時間の点では、アルゴリズム全体にかかる時間はわずか 22 ミリ秒で、これは SURF よりも 1 桁遅いです。特徴の抽出に最も時間がかかります。大きな語彙を使用すると変換に時間がかかりますが、クエリは高速になります。
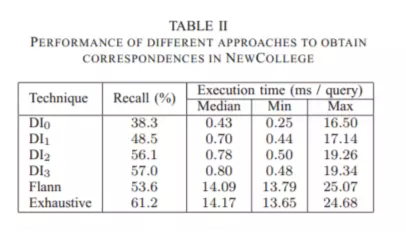

図4 BRIEF (左側のペア) と SURF64 記述子 (右側のペア) を使用して照合された単語の例
4. 結論
バイナリ特徴は、バッグオブワードアプローチにおいて非常に効果的であり、非常に効率的です。特に、結果は、FAST+BRIEF 機能が、移動ロボットで一般的な面内カメラ動作のループ検出問題を解決する上で、SURF (64 または 128 次元、回転不変なし) と同じくらい信頼できることを示しています。
特別なハードウェアを必要とせず、実行時間とメモリ要件は一桁小さくなります。パブリック データセットは、フロント カメラやサイド カメラを含む、屋内、屋外、静的および動的環境を記述します。これまでのほとんどの研究とは異なり、過剰調整を避けるために、評価データセットを覗くことなく、独立したデータセットから取得した同じ語彙とトレーニング データセットのセットから取得した同じパラメータ構成を使用してすべての結果を提示するように制限しました。
したがって、私たちのシステムは、追加の調整を行わなくても、現実世界の幅広い状況で堅牢で効率的なパフォーマンスを提供すると主張できます。この手法の主な制限は、回転とスケールの不変性が欠けているフィーチャを使用することです。