
この記事は8月17日のライブ配信の書き起こしをまとめたものです。ライブ配信のリプレイはWeChat公開アカウント「Alibaba Cloud Native」で視聴できます。記事の内容に加えて、実際のネットワークの問題に関する実践的なセッションも含まれています。
コンテナ ネットワークのジッター問題は、発生頻度が低く、短期間に発生するため、ネットワークの問題の中で特定して解決することが最も困難な問題の 1 つです。それだけでなく、Kubernetes クラスター内のネットワーク状態を毎日継続的に監視することも、クラスターの運用とメンテナンスの重要な部分です。
eBPF テクノロジーに基づいた KubeSkoop は、ポッド単位での粒度の高い、低オーバーヘッド、ホットスワップ可能なリアルタイム ネットワーク モニタリング機能を提供し、日常的なネットワーク モニタリングのニーズを満たすだけでなく、ネットワークの問題が発生した後に対応するプローブを迅速に有効にすることもできます。問題解決。KubeSkoop は、Prometheus ベースのインジケーターと Grafana ダッシュボードを提供するほか、コマンド ライン ベースおよび Loki ベースの例外イベント開示機能も提供し、問題箇所に関する詳細情報を提供します。
この共有には以下が含まれます。
- アプリケーションがパケットを受信/送信する方法
- ネットワーク問題のトラブルシューティングの難しさ、従来のネットワーク トラブルシューティング ツールや従来のツールの問題
- KubeSkoop とネットワーク監視部分 (つまり、KubeSkoop エクスポータ) の簡単な紹介
- カーネル内のさまざまなモジュールを組み合わせて、KubeSkoop エクスポーターのプローブ、インジケーター、イベントを詳細に導入します。
- 日常の監視と異常のトラブルシューティングで KubeSkoop エクスポーターを使用するための一般的なプロセス
- KubeSkoop エクスポータの今後の予定。
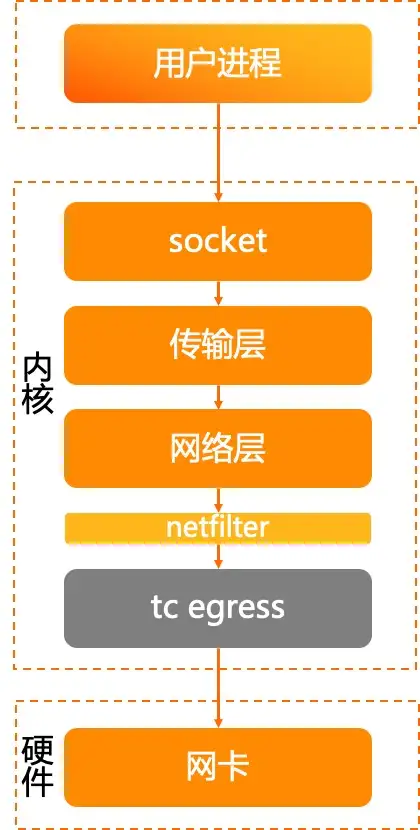
コンテナ内のアプリケーションはどのようにパケットを受信/送信しますか?
ネットワークでは、データはパケットで送信されます。Linux システムでは、アプリケーションがデータ パケットを正常に送受信できるようになる前に、カーネル内のさまざまなモジュールによってデータ パケットが層ごとに処理される必要があります。
まず受信プロセスを見てみましょう。
- ネットワーク パケットを受信した後、ネットワーク カード ドライバーは割り込みを開始します。
- カーネル ksoftirqd がスケジュールされた後、データを取得し、処理のためにプロトコル スタックに入ります。
- メッセージはネットワーク層に入り、ネットフィルターなどで処理された後、トランスポート層に入ります。
- トランスポート層はメッセージを処理した後、メッセージのペイロードをソケット受信キューに入れ、アプリケーション プロセスを起動し、CPU を解放します。
- アプリケーション プロセスがスケジュールされた後、収集されたデータはシステム コールを通じてユーザー モードで処理されます。
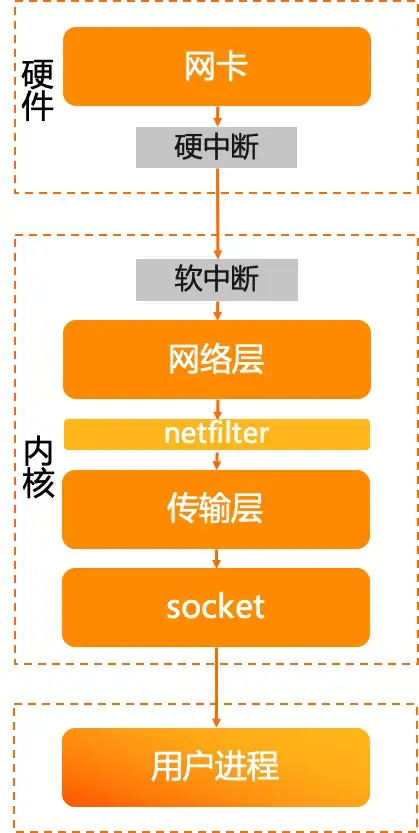
送信プロセスを見てみましょう。
- アプリケーションは、システム コールを通じてキュー書き込みデータをソケットに送信します。
- カーネル状態に入ると、ソケットはトランスポート層を呼び出してメッセージを送信します。
- トランスポート層はメッセージを組み立て、ネットワーク層を呼び出してメッセージを送信します。
- ネットワーク層が netfilter などで処理された後、tc egress に入ります。
- tc qdisc は、パケットを送信するためにネットワーク カード ドライバーを呼び出します。
インバウンド方向の tc の処理には注目していませんでしたが、アウトバウンド方向については強調して説明しましたが、これはリンク内で異常なパケット損失が発生する一般的な原因の 1 つでもあります。
上記の紹介からわかるように、パッケージは Linux カーネルで複雑な処理ステップを経る必要があります。カーネル ネットワーク サブシステムには多くのモジュールと大量かつ複雑なコードがあり、これがネットワーク問題のトラブルシューティングの難しさの 1 つであり、パケットの送受信に使用されるリンクが長いため、問題の特定が困難になります。同時に、ネットワーク関連システムは多くのパラメータと複雑な構成を持ち、特定の機能やパラメータの制限によって引き起こされるネットワークの問題は、その原因を特定するのに多くの時間を費やすと同時に、システムディスク、スケジューリング、ビジネスコードの欠陥などによって発生します。ネットワークの問題については、システムの状態を包括的に観察する必要があります。
一般的なネットワーク トラブルシューティング ツール
次に、Linux 環境における一般的なネットワーク問題のトラブルシューティング ツールと、その背後にある実装テクノロジを紹介します。
net-tools(netstat等)
net-tools が提供するツールを使用して、ネットワークの現在のステータス、異常な統計などを含むネットワーク統計を表示できます。
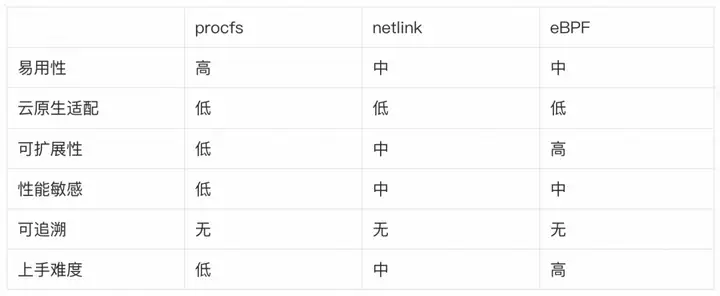
その原理は、procfs の /proc/snmp および /proc/netstat ファイルを通じて現在のネットワーク ステータスと例外数を取得することです。優れたパフォーマンスと低いオーバーヘッドが特徴ですが、提供される情報は比較的少なく、カスタマイズすることはできません。
procs は、Linux が提供する仮想ファイル システムの 1 つです。システム実行情報、プロセス情報、カウンタ情報を提供できます。ユーザー プロセスは、write() または read() システム コール関数 (/proc/net/netstat や /proc/<pid>/net/snmp など) を通じて procfs によって提供されるファイルにアクセスします。カーネル内の procfs 実装は、仮想ファイル システム vfs を通じてユーザーに情報を返します。
net-tools ツールキットと同様のコマンドには、nstat、sar、iostat などがあります。
iproute2(ip、ss 等)
iproute2 ツールキットの ip および ss ツールは、ネットワーク統計やネットワーク ステータスを表示するためのさまざまな実用的なツールも提供します。ただし、その原理は、netlink に基づいて情報を取得する netstat などのツールとは異なります。net-tools と比較すると、より包括的なネットワーク情報と優れたスケーラビリティを提供できますが、パフォーマンスは procfs よりも劣ります。
Netlink は Linux の特殊なソケット タイプであり、ユーザー プログラムは標準ソケット API を通じてカーネルと通信できます。ユーザプログラムはAF_NETLINKタイプのソケットを介してデータを送受信します。カーネルはソケット層を通じてユーザーリクエストを処理します。
同様のコマンドには、tc、conntrack、ipvsadm などがあります。
BCCツール
bcc-tools は、ネットワーク、ディスク、スケジューリングなどを含む、さまざまなカーネル状態観察ツールを提供します。そのコア実装は eBPF カウンティングに基づいており、非常に強力なスケーラビリティと優れたパフォーマンスを備えていますが、使用量のしきい値は上記のツールよりも高くなります。
eBPF は Linux では比較的新しいテクノロジであり、最近コミュニティでホットなトピックの 1 つです。eBPF はカーネル内の小さな仮想マシンで、ユーザーが作成したコードを動的にロードしてカーネル内で実行できます。同時に、カーネルはプログラムのセキュリティを検証して、カスタマイズされた eBPF コードによって問題が発生しないことを確認します。カーネルが異常に動作する。
eBPF プログラムがカーネルにロードされると、マップを通じてユーザー モード プログラムとデータを交換できます。ユーザー プロセスは、ユーザー モードの bpf() システム コールを通じてマップ内のデータを取得できます。また、eBPF プログラムは、カーネル内のカーネル API を使用してマップ データをアクティブに更新し、カーネルとユーザー間の通信を完了することもできます。プロセス。
bcc-tools で提供されるツールと同様に、bpftrace、systemtap などもあります。
クラウド ネイティブ シナリオにおける従来のツールの問題
上記のツールは、Linux のさまざまな機能を通じて豊富なステータス情報を提供し、システムで発生するネットワーク問題のトラブルシューティングに役立ちます。ただし、クラウド ネイティブ コンテナーの複雑なシナリオでは、従来のツールにもいくつかの制限があります。
- ほとんどのツールはローカル/ネットワーク名前空間ディメンションから監視するため、特定のコンテナーをターゲットにすることが困難になります。
- 複雑なトポロジを観察するには、カーネルの問題のトラブルシューティングに関する十分な経験がないと開始するのが難しい場合があります。
- 時々問題が発生する場合、リアルタイムで状況を把握してこれらのツールを使用することは困難です。
- これらのツールは大量の情報を提供しますが、情報間の相関関係は明らかではありません
- 一部の観察ツール自体もパフォーマンス上の問題を引き起こします。
キューブスクープ
Linux ネットワーク処理の上記の複雑なリンクに基づいて、クラウド ネイティブ コンテナーのシナリオにおける従来のツールの欠点がわかります。クラウド ネイティブ環境のネットワーク監視要件に基づいて、KubeSkoop プロジェクトが誕生しました。
KubeSkoop エクスポーターである KubeSkoop のネットワーク監視部分を紹介する前に、まず KubeSkoop プロジェクトの全体的な状況を確認しましょう。
KubeSkoop は、コンテナ ネットワークの問題の自動診断システムです。DNS 解決の例外やサービスへのアクセス不能など、ネットワークが引き続き利用できないシナリオに対してワンクリック診断機能を提供し、遅延の増加、時折のリセット、時折のパケット損失などのネットワーク ジッターの問題をリアルタイムで監視します。能力。KubeSkoop は、リンク全体のワンクリック診断、ネットワーク ステーションの遅延分析、ネットワーク異常イベントの識別とトレースバック機能を提供します。
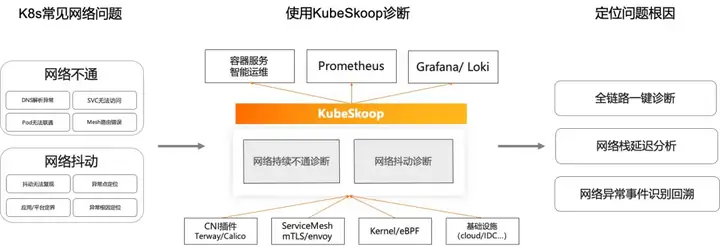
この共有では、KubeSkoop のネットワーク監視機能に焦点を当てます。
KubeSkoop エクスポーターは、eBPF、procfs、ネットリンク、その他のデータ ソースに基づいてコンテナ ネットワークの異常を監視します。ポッド レベルのネットワーク監視機能を提供し、ドライバー、ネットフィルター、TCP をカバーするネットワーク監視インジケーター、ネットワーク異常イベント レコード、およびリアルタイム イベント ストリームを提供できます。など。クラウド上の Prometheus や Loki などの監視可能なシステムに接続された、完全なプロトコル スタックと数十の異常シナリオ。
KubeSkoop エクスポーターは、カーネル内のさまざまな場所で情報を収集するためのプローブを提供し、プローブのホットプラグとオンデマンド読み込みをサポートします。有効なプローブは、収集された統計情報やネットワークの異常を、Prometheus インジケーターや異常なイベントの形で明らかにします。
プローブ、メトリクス、イベント
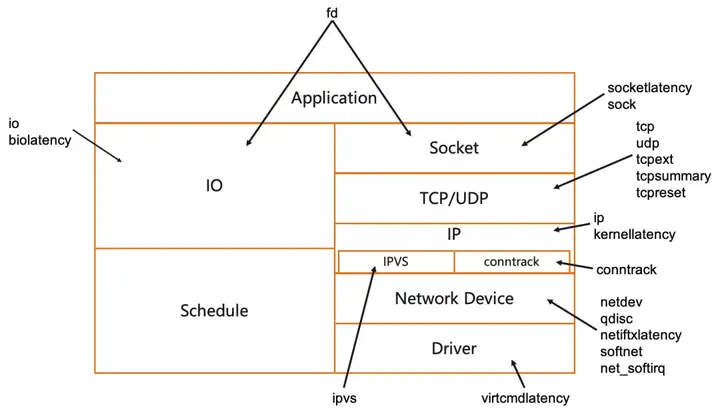
KubeSkoop エクスポータは、カーネル内のさまざまなモジュールに対して、さまざまな観察要件やさまざまなネットワーク問題シナリオに適したさまざまなプローブを提供します。
メトリクスは、接続数、再送信数など、ネットワーク内の主要な情報に関するポッド ディメンションに要約された統計データです。この情報は、時間の経過に伴うネットワーク ステータスの変化に関する情報をユーザーに提供し、ユーザーがコンテナ内の現在のネットワーク ステータスをよりよく理解するのに役立ちます。
パケットロス、TCPリセット、データ処理遅延などのネットワーク異常が発生した場合にイベントが発生します。インジケーターと比較して、イベントは、パケット損失の特定の場所、遅延の詳細な統計など、問題のサイトに関するより多くの情報を提供できます。イベントは、より詳細な観察と問題の特定を目的として、特定のネットワーク異常を対象とするためによく使用されます。
プローブリスト
以下では、KubeSkoop が現在提供しているプローブを紹介し、その機能、適用可能なシナリオ、コスト、提供するインジケーター/イベントについて説明します。
プローブ、インジケーター、イベントの説明については、KubeSkoop ドキュメント https://kubeskoop.ioにアクセスして 詳細を確認することもできます。
ソケット遅延
ソケット遅延プローブは、カーネル内のソケット関連およびアップストリームおよびダウンストリームのシンボルを追跡して、ソケット データの準備ができてからデータが読み取られるまで、およびソケットがデータを受信して TCP に渡すまでのユーザー モードの遅延を取得します。処理用のレイヤーです。このプローブは通常、ユーザー モード データがソケット層に到達したときの読み取りの遅延に焦点を当てています。プローブは、ソケットの読み取り/書き込み遅延に関連するインジケーターとイベントを提供します。
オーバーヘッド:高い
該当するシナリオ:スケジュール設定や処理の遅延などにより、プロセスのデータ読み取りが遅いと考えられます。
よくある質問:コンテナープロセスの CPU が制限を超えることによって引き起こされるネットワークジッター
靴下
sock プローブ データは、/proc/net/sockstat ファイルから取得されます。このファイルは、Pod 内のソケットの統計インジケーターを提供し、さまざまな TCP 状態 (inuse、orphan、tw) のソケット数とメモリ使用量を収集します。アプリケーション ロジックやシステム パラメーター構成などの問題が原因である可能性があり、ソケットと tcpmem の枯渇につながり、接続障害が発生し、同時実行パフォーマンスに影響を与える可能性があります。このプローブにはオーバーヘッドがほとんどないため、日常的な接続の一般的なステータスを観察するために使用することもできます。
オーバーヘッド:低い
適用可能なシナリオ:接続ステータス、ソケット リーク、再利用、過剰なソケット メモリ使用量などの毎日の観察。
一般的な問題:ソケット リークによりメモリ使用量が増加し続ける、接続確立の失敗/接続数が多すぎることによる時折の RST、再利用、tcpmem の枯渇など。
tcp/udp/tcpext
/proc/net/netstat および /proc/net/snmp の 2 つのファイルを通じて、新しい TCP 接続/正常に確立された接続の数、再送信されたメッセージの数、UDP プロトコルなどの TCP/UDP プロトコル層に関する基本情報を収集します。エラー、カウントなど tcpext は、RST パケットの送信に関する統計など、TCP のより詳細なインジケーターも提供します。このポインタは、TCP/UDP 接続に関連する異常な問題 (負荷の不均衡、接続確立の失敗、接続の異常終了など) などの重要な情報を提供します。同時に、情報を収集するための procfs に基づくプローブとしても使用できます。日常の交通状況の監視用です。
オーバーヘッド:低い
適用可能なシナリオ: TCP および UDP 関連のステータスを毎日監視します。TCPコネクション例外再送、コネクション確立失敗、リセットメッセージなどの情報収集 DNS解決失敗などの情報収集
よくある質問:アプリケーション接続の異常終了、再送信による遅延ジッター
tcpまとめ
tcpsummary プローブは、ネットリンク メッセージ (SOCK_DIAG_BY_FAMILY) を介してカーネルと通信することにより、ポッド内のすべての TCP 接続情報を取得し、TCP 接続ステータスと送受信キュー ステータスを集約してインジケーターを生成します。このプローブは、最終的な統計結果を取得するためにすべての接続情報を集約する必要があるため、多数の接続による同時実行性の高いシナリオでは、オーバーヘッドが大きくなる可能性があります。
オーバーヘッド:中
適用可能なシナリオ:時折の遅延や接続障害などのシナリオで TCP 接続ステータス情報を提供します。
よくある問題:ユーザー モード プロセスのハング、受信キューの蓄積によるパケット損失
tcプリセット
tcpreset プローブは、カーネル内の tcp_v4_send_reset および tcp_send_active_reset の呼び出しを追跡し、ソケット情報とステータスを記録し、TCP 接続で RST メッセージを送信するときにイベントを生成します。tcp_receive_reset が呼び出されたとき、つまり RST メッセージが受信されたとき、上記の情報も記録されます。プローブはカーネル内のコールド パスのトレースに基づいているため、オーバーヘッドが低くなります。このプローブはイベントのみを生成するため、TCP リセットの問題が発生した場合はオンにすることをお勧めします。
オーバーヘッド:低い
適用可能なシナリオ: TCP 接続が異常にリセットされた場合、カーネル内のリセット位置を追跡します。
よくある質問:クライアントとサーバーの両側のタイムアウト設定が原因で接続がリセットされる場合があります。
ip
ip プローブは、/proc/net/snmp ファイルから収集される IP 関連の情報インジケーターです。ルーティング先アドレスに到達できない場合と、データパケット長がIPヘッダに示されている長さよりも短い場合の2つの状況に応じたカウンタを搭載しており、上記2つの理由によるパケットロスを判定できます。プローブのオーバーヘッドは非常に小さいため、毎日の監視シナリオではプローブをオンにすることをお勧めします。
オーバーヘッド:低い
適用可能なシナリオ: IP 関連のステータスの毎日の観察。パケットロスなどの問題が発生した場合
よくある質問:ノードのルーティング設定が正しくなく、宛先に到達できないことによるパケット損失
カーネルレイテンシ
kernellatency は、メッセージの受信と送信のプロセス全体における複数の重要なポイントの時間を記録し、カーネル内のメッセージの処理遅延を計算します。ポインタは、パケット処理の送受信における遅延の指標を提供し、パケット 5 つ組とカーネル内のさまざまなポイントの間の処理時間などのイベントも提供します。このプローブには、すべてのパケットの時間統計と多数のマップ クエリ操作が含まれており、オーバーヘッドが高いため、関連する問題が発生した場合にのみこのプローブを有効にすることをお勧めします。
オーバーヘッド:高い
該当するシナリオ:接続タイムアウト、ネットワーク ジッターの問題
FAQ: iptables ルールが多すぎるため、カーネル処理の待ち時間が長くなります
ipvs
ipvs プローブは、/proc/net/ip_vs_stats ファイル内の情報を収集し、IPVS 関連の統計を提供します。IPVS はカーネルによって提供される 4 層の負荷分散機能であり、kube-proxy の IPVS モードで使用されます。プローブによって提供されるインジケーターには、主に、IPVS 接続の数、送受信データ パケット数、送受信データ バイト数が含まれます。このプローブは、日常監視における IPVS 統計情報の観察に適しており、サービス IP へのアクセス時のネットワーク ジッターや接続確立の失敗の補助参照としても機能します。
オーバーヘッド:低い
適用可能なシナリオ: IPVS 関連ステータスの毎日の監視
よくある質問:なし
接続する
conntrack プローブは、ネットリンク経由で conntrack モジュールを追跡するための統計を提供します。conntrack モジュールは、カーネルによって提供される netfilter フレームワークに基づいており、各接続の作成時間、メッセージ数、バイト数、その他のデータを含む、ネットワーク層上のデータ トラフィックの接続追跡を実行し、上位層のデータを提供します。情報の一致に基づく NAT などの操作。プローブのインジケーターは、現在の conntrack エントリの数と最大エントリ制限に加えて、現在の conntrack のさまざまな状態にあるエントリの統計的なカウントを提供します。プローブはすべての conntrack エントリを走査する必要があるため、同時実行性の高いシナリオでは大きなオーバーヘッドが発生します。
オーバーヘッド:高い
該当するシナリオ:接続確立の失敗、パケット損失、conntrack ストリーミングなど。
よくある質問: conntrack オーバーフローによる接続確立の失敗とパケット損失
ネット開発
netdev プローブは、/proc/net/dev ファイルを収集することにより、送受信バイト数、エラー数、データ パケット数、損失パケット数などの統計指標をネットワーク デバイス レベルで提供します。プローブは通常、マクロ レベルでネットワークの問題を検出するために使用され、時折 TCP ハンドシェイクが失敗するなどのシナリオで役立ちます。プローブのオーバーヘッドは非常に小さいため、毎日有効にすることをお勧めします。
オーバーヘッド:低い
適用可能なシナリオ:毎日の監視。ネットワークのジッター、デバイスの下部でのパケット損失など。
よくある質問:ネットワーク機器でのパケット損失によるネットワークのジッターまたは接続障害
qディスク
qdisc プローブは、qdisc のトラフィック統計や qdisc キュー ステータスの統計など、ネットリンクを通じて tc qidsc の統計インジケーターを提供します。tc qdisc は、ネットワーク デバイスのフローを制御するために使用される LInux カーネル内のモジュールで、スケジューリング ルールに従ってデータ パケットの送信を制御します。ネットワーク カードの qdisc ルールにより、パケットがドロップされたり、長い遅延が発生したりする可能性があります。プローブのオーバーヘッドは低いため、毎日有効にすることをお勧めします。
オーバーヘッド:低い
適用可能なシナリオ:毎日の監視。ネットワークジッター、パケットロスなど
よくある質問: qdisc キューのオーバーフローによるパケット損失によりネットワーク ジッターが発生する
netiftxlatency
主に、qdisc によるメッセージの処理時間と、基礎となるデバイスがメッセージを外部に送信する時間に焦点を当て、カーネルのネットワーク デバイス処理部分の主要なポイントでの遅延を追跡および計算します。両方の部分で特定のしきい値を超えると、メッセージ 5 重の情報を含む異常イベントが提供されます。プローブはすべてのパケットの遅延を計算するため、オーバーヘッドが大きいため、遅延の問題が発生する場合はオンにすることをお勧めします。
オーバーヘッド:高い
該当するシナリオ:接続タイムアウト、ネットワーク ジッターなど。
よくある質問:根本的なネットワークジッターにより遅延が増加する
ソフトネット
ソフトネット プローブのデータはカーネルの proc ファイルinterface/proc/net/softnet_stat から取得され、インジケーターはポッド レベルで集約されます。ソフトネット プローブは、CPU 方式に従ってネットワーク カードが受信したデータ パケットを統合し、ネットワーク カード デバイスから Linux カーネルのソフト割り込み処理プロセスに入るデータ パケットのステータスを表し、受信およびデータ パケットの外部概要データを提供します。データパケットを処理しています。プローブは、Love You ノード レベルでネットワークの問題が発生した場合に補助的な役割を果たすことができ、オーバーヘッドが非常に小さいため、有効にすることをお勧めします。
オーバーヘッド:低い
適用可能なシナリオ:毎日の監視。ノードレベルのネットワーク問題を支援する機能
よくある質問:なし
net_softirq
net_softirq プローブは、カーネル モード プログラムを通じて 2 つのネットワーク関連の割り込み (netif_tx、netif_rx) のスケジュールと実行時間を収集します。これには、ソフト割り込みの開始から実行の開始までの時間と、ソフト割り込みの開始からの時間も含まれます。実行完了までのソフト割り込み、および一定のしきい値を超えたメッセージは、インジケーターまたはイベントの形で統計的に開示されます。
オーバーヘッド:高い
該当するシナリオ:時折発生する遅延とネットワーク ジッター一般的な問題: CPU の競合によってソフト割り込みのスケジューリングが遅延し、ネットワーク ジッターが発生します。
virtcmdlatency
virtcmdlat プローブは、カーネル モードで仮想化指定のメソッド (virtnet_send_command) を呼び出す実行時間を計算して、仮想マシンが仮想化呼び出しを実行するのにかかる時間を取得し、遅延数のインジケーターとイベントを提供します。Virtio は一般的な仮想化ネットワーク ソリューションですが、準仮想化の特性により、基盤となる物理マシンのブロックにより、仮想マシンのネットワーク カード デバイス ドライバーの動作が遅延する可能性があります。プローブのオーバーヘッドが高いため、ネットワーク ジッターがホストによって引き起こされていると思われる場合は、プローブをオンにすることをお勧めします。
オーバーヘッド:高い
該当するシナリオ:時折発生する遅延とネットワークのジッター
よくある質問:基盤となる物理マシン リソースの競合によって引き起こされるネットワーク ジッター
fd
fd プローブは、単一の Pod 内のすべてのプロセスが保持するハンドルを収集し、Pod 内のプロセスによって開かれたファイル記述子の数とソケット タイプのファイル記述子を取得します。プローブはプロセスのすべての fd を走査する必要があるため、コストがかかります。
オーバーヘッド:高い
該当するシナリオ: fd リーク、ソケット リーク、その他の問題
一般的な問題:ソケットがユーザー モード プログラムによって閉じられていないため、リークが発生し、TCP OOM が発生し、ネットワーク ジッターが発生します。
イオ
io プローブのデータは、/proc/io によって提供されるファイル インターフェイスから取得され、単一の Pod によって実行されるファイル システム IO の速度と合計量を特徴付けるために使用されます。プローブによって提供されるメトリックには、ファイル システムの読み取りおよび書き込み操作の数とバイト数が含まれます。一部のネットワークの問題は、同じノード上の他のプロセスによって実行されている大量の IO によって引き起こされ、ユーザー プロセスの応答が遅くなる可能性があります。この場合、検証のために必要に応じてプローブをオンにすることができます。 Pod IO の毎日の監視に使用されます。
オーバーヘッド:低い
該当するシナリオ:ユーザー プロセスの応答の遅さと再送信の増加による遅延の増加
よくある質問:大量のファイルの読み書きによってネットワークのジッターが発生する
生体潜伏性
biolatency は、カーネル内のブロック デバイスの読み取りおよび書き込み呼び出しの実行時間を追跡し、しきい値を超える実行を例外イベントとして公開します。デバイスの IO 遅延の増加は、ユーザー プロセスのビジネス処理に影響を及ぼし、ネットワーク ジッターの問題を引き起こす可能性があります。このプローブは、ネットワーク異常が IO によって引き起こされていると疑われる場合にオンにできます。プローブはすべてのブロック デバイスの読み取りおよび書き込み操作に関する統計を収集する必要があり、中程度のオーバーヘッドがあるため、オンデマンドで有効にすることをお勧めします。
オーバーヘッド:中
該当するシナリオ: IO の読み取りと書き込みが遅いために発生するネットワーク ジッター、遅延の増加など
よくある質問:ブロック デバイスの読み取りおよび書き込み遅延によるネットワーク ジッター
KubeSkoopエクスポーターの使い方
KubeSkoop エクスポータは、日常的な監視や、ネットワークに異常な問題が発生した場合のトラブルシューティングに適しています。これら 2 つのシナリオでは、KubeSkoop エクスポーターをさまざまな方法で使用します。これについては、以下で簡単に紹介します。
毎日の監視

日常の監視では、Prometheus を使用して KubeSkoop エクスポータによって明らかにされたインジケータを収集し、オプションで Loki を使用して異常イベントのログを収集することをお勧めします。収集されたインジケーターとログは、Grafana ダッシュボードを通じて表示できます。KubeSkoo エクスポーターは、直接使用できる既製の Grafana ディスクも提供します。
インジケーターのコレクションとマーケットを構成した後、KubeSkoop エクスポーター自体でもいくつかの構成を実行する必要があります。日常の監視では、ビジネス トラフィックに影響を与えるために、porcfs に基づくほとんどのプローブや netlink および eBPF に基づく一部の低コスト プローブなど、いくつかの低コスト プローブを選択的に有効にすることができます。Loki を使用する場合は、Loki のサービス アドレスも設定して有効にする必要があります。これらの準備が完了すると、市場で有効なインジケーターとイベントを確認できるようになります。
日々の監視では、いくつかの敏感な指標の異常に注意を払う必要があります。たとえば、新しい接続の数が異常に突然増加したり、接続の確立に失敗した数が増加したり、リセット メッセージが増加したりするなどが考えられます。明らかに異常を表す可能性のあるこれらのインジケーターについては、異常が発生したときにトラブルシューティングと回復を行うために、より迅速に介入するようにアラームを構成することもできます。
例外のトラブルシューティング

日々の監視、ビジネス アラーム、エラー ログなどを通じてネットワーク異常の可能性を発見した場合、まず、TCP 接続障害、ネットワーク遅延ジッターなど、ネットワーク異常の種類を簡単に分類する必要があります。単純な分類により、トラブルシューティングの方向性を確立するのに役立ちます。
問題の種類に応じて、問題に該当するプローブをオンにすることができます。たとえば、ネットワーク遅延ジッターの問題が発生した場合、ソケットレイテンシーをオンにしてアプリケーションがソケットからデータを読み取る際の遅延に注意を払ったり、カーネルレイテンシーをオンにしてカーネルの遅延を追跡したりできます。
これらのプローブをオンにすると、構成された Grafana を通じてプローブによって公開されるインジケーターまたはイベントの結果を観察できます。同時に、異常なイベントは、Pod ログまたはエクスポーター コンテナーのインスペクター コマンドを通じて直接監視することもできます。今回開いたプローブの結果が異常ではない場合、または問題の根本原因について結論を導き出すことができない場合は、引き続き問題の特定を支援するために他のプローブを開くことを検討できます。
これらの取得された指標と異常イベントに基づいて、最終的に問題の根本原因を特定します。問題の根本原因は、システム内の特定のパラメータの調整に起因する場合もあれば、ユーザーのプログラムに発生する場合もあります。特定された根本原因に基づいて、これらのシステムパラメータを調整したり、プログラムコードを最適化したりできます。
これからの計画
KubeSkoop は先週、最初の正式バージョン 0.1.0をリリースしました。主な改善点は次のとおりです。
診断
- k3s クラスターをサポート
- サポートノードホストインターフェースの自動選択
- いくつかの診断エラーを修正しました
ネットワーク監視
- ほとんどの主流オペレーティング システムの btf 自動検出をサポート
- エクスポーターのパフォーマンスを最適化し、CPU オーバーヘッドを大幅に削減します。
- プローブのホットロードをサポート
- フローレベルインジケーター収集の暫定サポート
以下は、ここ数か月における当社の開発計画です。
- スケーラビリティと安定性を強化するための KubeSkoop エクスポータ コードのリファクタリング
- フローレベルのメトリクス表示を完全にサポートし、問題のある接続を迅速に特定します
- ローカル ファイル/ELK などへのイベント公開をサポートします。
- より使いやすい UI、クラスタ内のトラフィック トポロジの概要をサポート
結論
この共有は、KubeSkoop プロジェクトのネットワーク監視機能に焦点を当てた紹介です。主に、KubeSkoop エクスポータが所有するインジケーターと、日常の使用方法およびトラブルシューティングの一般的な方法を紹介します。このプロジェクトをより効果的に使用し、観察および監視するのに役立ちます。ネットワークを監視します。トラブルシューティング。
関連リンク:
[1] Githubプロジェクトのホームページ
https://github.com/ali baba/kubeskoop
著者: Xia Yu、Xi Heng
クリックして今すぐクラウド製品を無料で試し、クラウドでの実践的な取り組みを始めましょう!
この記事は Alibaba Cloud のオリジナル コンテンツであり、許可なく複製することはできません。
JetBrains が Rust IDE をリリース: RustRover Java 21 / JDK 21 (LTS) GA 中国には非常に多くの Java 開発者がいることから、エコロジーレベルのアプリケーション開発フレームワーク .NET 8 が誕生するはずであり、パフォーマンスは大幅に向上しており、 をはるかに上回っています。 NET 7. PostgreSQL 16 は、Rust チームの元メンバーによってリリースされました。大変遺憾ながら名前をキャンセルしていただきました。 昨日、フロントエンドの Nue JS の削除を完了しました。作者は、新しい Web エコシステムを作成すると言っています。 NetEase Fuxi、「バグにより人事部から脅迫された」従業員の死亡に対応 任正非氏:私たちは第4次産業革命を迎えようとしている、Appleはファーウェイの師であるVercelの新製品「v0」:UIインターフェースコードをベースに生成文章