 1. アルゴリズムの複雑さの分析
1. アルゴリズムの複雑さの分析
なぜ複雑性分析を行うのでしょうか? それは、よりパフォーマンスの高いコードを書くためのガイドとなり、他の人が書いたコードの品質を判断できるからです。
(1) 時間計算量解析
時間計算量は、コードの実行時間を評価するために使用されます。

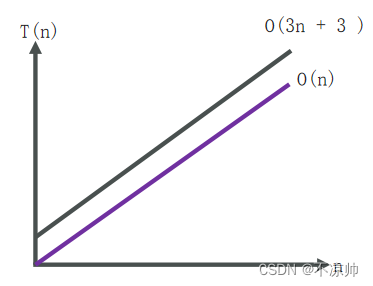
1. コードの各行の実行時間が同じ場合: 1ms
2. このコードが合計何行実行されるかを分析します。3n+3
3. コードにかかる合計時間: T(n) = (3n + 3) * 1ms
-
Big O 表記法: コードの実際の実行時間を具体的に表すものではありませんが、データ サイズの増加に伴うコード実行時間の変化傾向を表します。
-
T(n) はコードの実行回数に比例します (コードの行数が増えるほど、実行時間は長くなります)。
-
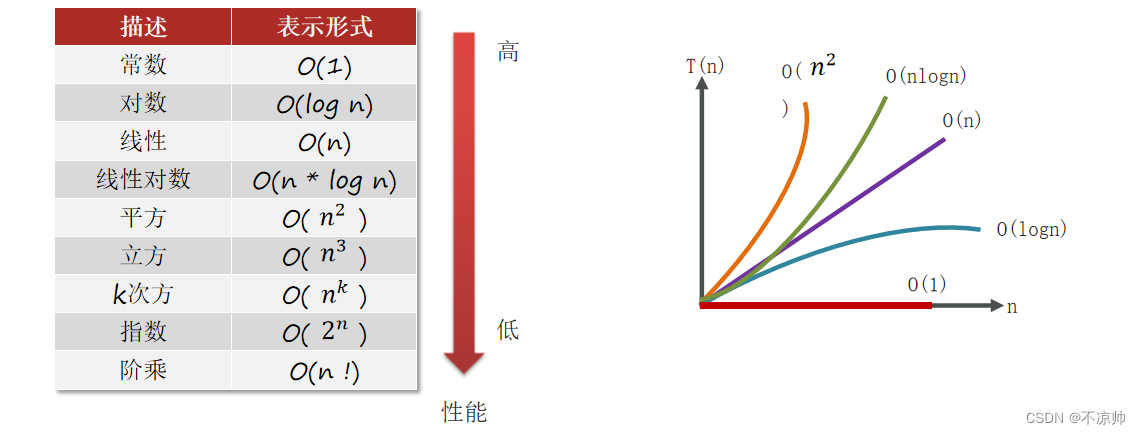
n が非常に大きい場合、式の下位、定数、および係数の部分はその増加傾向に影響を与えないため、無視できます。最大の大きさのみを記録する必要があります。
例:

上図の時間計算量: パラメーター n が増加してもコードの実行時間が増加しない限り、そのコードの計算量は O(1) です。
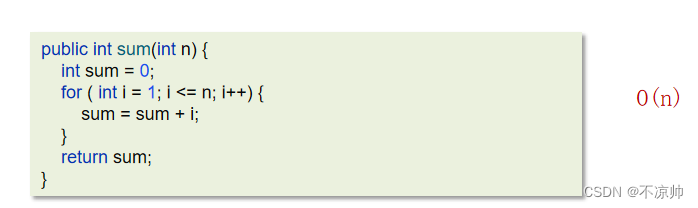


(2) 空間複雑性解析
空間複雑性の正式名称は漸近空間複雑性であり、アルゴリズムによって占有される追加の記憶域空間とデータのサイズとの間の増大する関係を

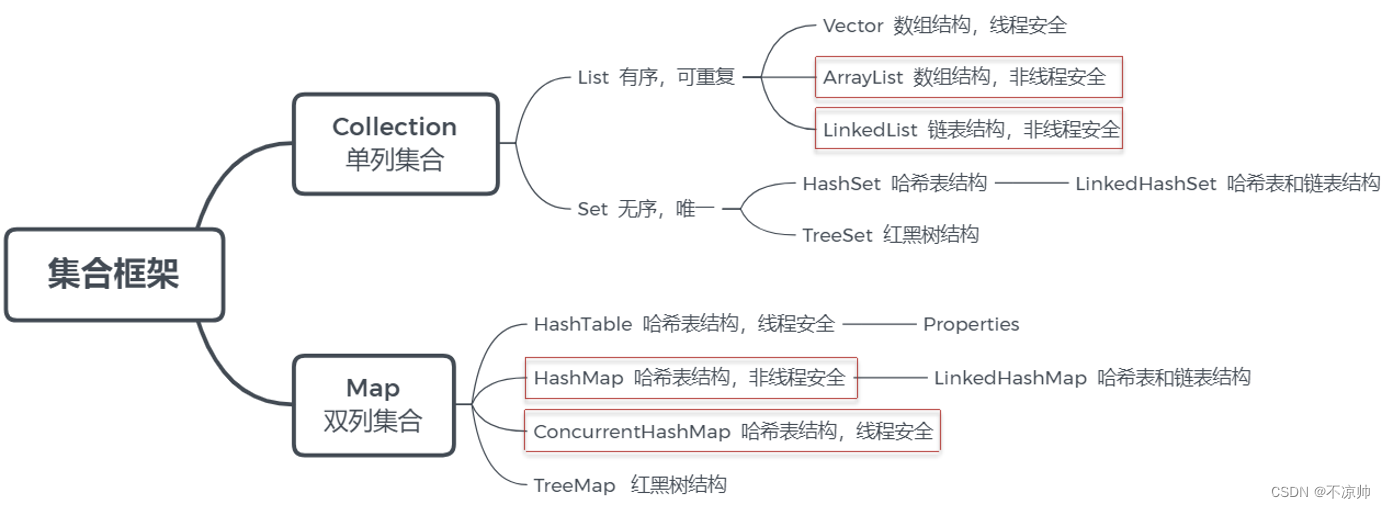
2. リスト分析
(1) アレイの最下層
配列は、連続メモリ空間を使用して同じデータ型のデータを格納する線形データ構造です。
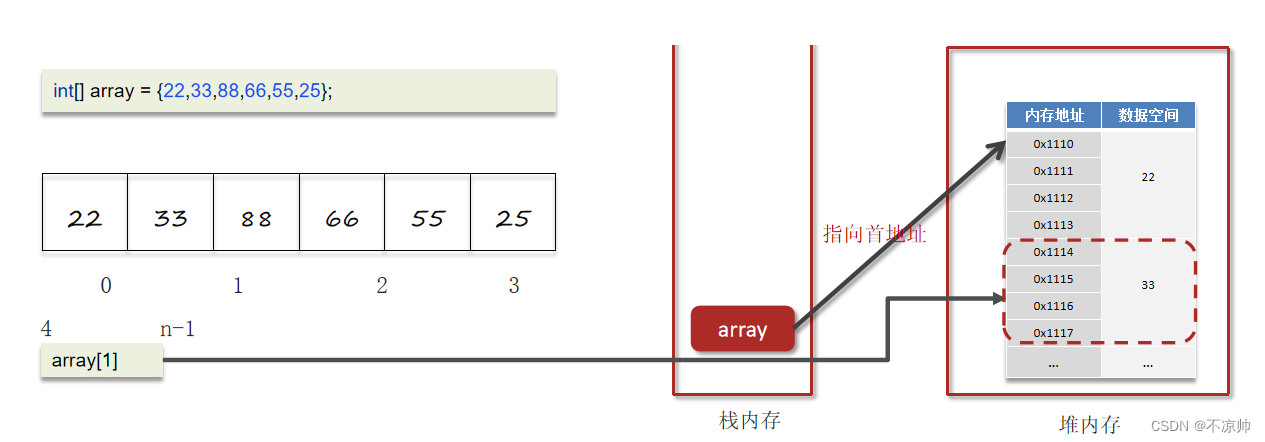
なぜ配列のインデックスは 0 から始まるのでしょうか? 1から始めたらどうなるでしょうか?

-
配列インデックスに従って要素を取得する場合、インデックスとアドレス指定式を使用して、メモリに対応する要素データを計算します (アドレス指定式は、配列の先頭アドレス + インデックス * 格納データの型サイズ)
-
配列のインデックスが 1 から始まる場合、アドレス指定式に減算演算を追加する必要があり、CPU にとっては 1 命令多くなり、パフォーマンスは高くありません。
配列を見つける時間計算量
1. ランダム クエリ (インデックスに基づくクエリ) 配列要素はインデックスを介してアクセスされ、コンピュータは配列の最初のアドレスとアドレス指定式を使用して、アクセスしたい要素をすぐに見つけることができます。
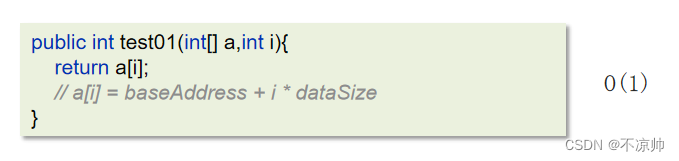
2. 不明なインデックスクエリ
ソートされた配列の要素を検索し、データ番号 55 を検索します。

配列への削除と挿入の時間計算量
配列は連続したメモリ空間であるため、配列の連続性を確保するには配列の挿入や削除の効率が非常に低くなります。
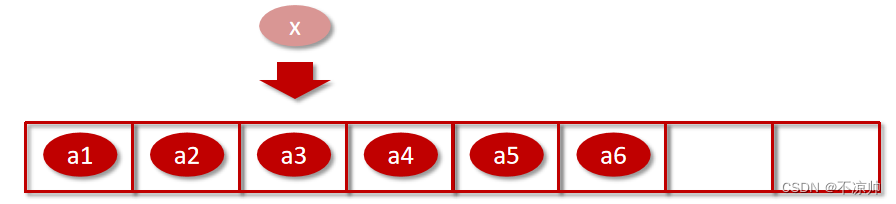
最良のケースは O(1)、最悪のケースは O(n)、平均時間計算量は O(n) です。
(2) ArrayListの解析
ソースコードを解析するにはどうすればよいですか? メンバー変数、コンストラクター、および主要なメソッドの観点から分析する必要があります。
1. 基礎となるデータ構造
ArrayList の最下層は動的配列を使用して実装されます
2. 初期容量
ArrayListの初期容量は 0 で、初めてデータを追加するときは 10 に初期化されます。
3. 拡張ロジック
ArrayList を展開すると、元の容量は1.5 倍になり、展開のたびに配列をコピーする必要があります。
4. ロジックを追加する
-
配列に次のデータを格納するのに十分な長さ (サイズ) プラス 1 があることを確認してください。
-
配列の容量を計算します。現在の配列の使用長 + 1 が現在の配列の長さより大きい場合は、grow メソッドを呼び出して容量を拡張します (元の 1.5 倍)。
-
新しいデータを保存する場所があることを確認したら、新しい要素を size の場所に追加します。
-
正常に追加されたブール値を返します。
(3) 配列とArrayListに関する問題
ArrayList list=new ArrayList(10) のリストは何倍に拡張されますか?

参考回答:このステートメントは ArrayList を宣言してインスタンス化するだけで、容量 10 を指定しており、容量を拡張しません。
配列とリストの間で変換するにはどうすればよいですか?

-
配列をリストに変換するには、JDK の java.util.Arrays ツール クラスの asList メソッドを使用します。
-
List を配列に変換するには、List の toArray メソッドを使用します。パラメーターのない toArray メソッドは、オブジェクト配列を返します。初期長の配列オブジェクトを渡し、オブジェクト配列を返します。
Arrays.asList を使用して List に変換した後、配列の内容が変更された場合、リストは影響を受けますか?
Arrays.asList がリストを変換した後、配列の内容が変更されると、最下層が Arrays クラスの内部クラス ArrayList を使用してコレクションを構築するため、リストは影響を受けます。このコレクションのコンストラクターでは、 in このコレクションはパッケージ化されただけで、最終的には同じメモリ アドレスを指します。
toArray を使用してリストを配列に変換した後、リストの内容が変更された場合、配列は影響を受けますか?
toArrayを使用してリストが配列に変換された後、リストの内容が変更されても、配列は影響を受けません。 toArray が呼び出されると、下部には配列のコピーが表示されます。元の要素なので、その後リストを変更しても配列には影響しません
(4) 一方向リンクリストと双方向リンクリスト
一方向リンク リスト: 各ノードには 2 つの部分が含まれます。1 つはデータ要素を格納するデータ フィールドで、もう 1 つは次のノードのアドレスを格納するポインタ フィールドです。次のノードのアドレスを記録するポインタを後続ポインタnextと呼びます。

リンクされたリストの各要素はノードと呼ばれ、物理ストレージ ユニット上の非連続かつ非順次のストレージ構造です。

二重リンク リスト: 名前が示すように、 2 方向をサポートします。各ノードには、後続ノードを指す後続ポインタ next と、前のノードを指す先行ポインタ prev が複数あります。


単一リンクリストを比較する:
-
二重リンク リストには、後続ノードと先行ノードのアドレスを格納するために 2 つの追加スペースが必要です。
-
双方向トラバーサルをサポートし、二重リンクリスト操作にも柔軟性をもたらします。
一方向リンクリストには一方向のみがあり、ノードには後続ポインタ next が 1 つだけあります。二重リンク リストは 2 つの方向をサポートしており、各ノードには後続ノードを指す後続ポインタ next と、前のノードを指す先行ポインタ prev が複数あります。
連結リスト演算データの時間計算量:
| クエリ、追加、削除 | |
|---|---|
| 一方向リンクリスト | 頭部 O(1)、その他 O(n) |
| 二重リンクリスト | 先頭と末尾 O(1)、その他は O(n)、与えられたノード O(1) |
(5) ArrayListとLinkedListの違い
1. 基礎となるデータ構造
-
ArrayList は動的配列のデータ構造実装です。
-
LinkedList は二重リンク リストのデータ構造実装です。
2. 運用データの効率化

-
添字クエリによる ArrayList の時間計算量は O(1) [メモリは連続的で、アドレス指定式: 配列の最初のアドレス + インデックス * 格納されたデータの型サイズ] に従うと、LinkedList は添字クエリをサポートしません。
-
検索 (不明なインデックス): ArrayList を走査する必要があり、リンクされたリストも走査する必要があり、時間計算量は O(n) です。
-
追加と削除:
ArrayList の末尾の挿入と削除の時間計算量は O(1) ですが、他の部分の追加と削除には配列の移動が必要で、時間計算量は O(n) です。
LinkedList の先頭ノードと末尾ノードの追加と削除の時間計算量は O(1) ですが、その他のノードはリンク リストを横断する必要があり、時間計算量は O(n) です。
3. 占有メモリ空間
-
ArrayList の最下層は配列であり、メモリは連続しているため、メモリが節約されます。
-
LinkedList は二重リンク リストであり、データと 2 つのポインターを保存する必要があるため、より多くのメモリを消費します。
4. スレッドの安全性
ArrayList も LinkedList もスレッドセーフではありません。スレッドの安全性を確保する必要がある場合、次の 2 つのオプションがあります。
-
メソッド内で使用される場合、ローカル変数はスレッドセーフです。
-
スレッドセーフな ArrayList と LinkedList の使用
List<Object> syncArrayList = Collections.synchronizedList(new ArrayList<>());
List<Object> syncLinkedList = Collections.synchronizedList(new LinkedList<>());3. データ構造
(1) 二分木
バイナリ ツリーは、その名前が示すように、各ノードに最大 2 つの「フォーク」、つまり 2 つの子ノード、つまり左側の子ノードと右側の子ノードがあります。ただし、バイナリ ツリーでは各ノードが 2 つの子ノードを持つ必要はなく、左側の子ノードのみを持つノードもあれば、右側の子ノードだけを持つノードもあります。二分木の各ノードの左部分木と右部分木も、それぞれ二分木の定義を満たします。
Java でバイナリ ツリーを実装するには、配列ストレージとチェーン ストレージの 2 つの方法があります。チェーン ストレージに基づくツリーのノードは次のように定義できます。
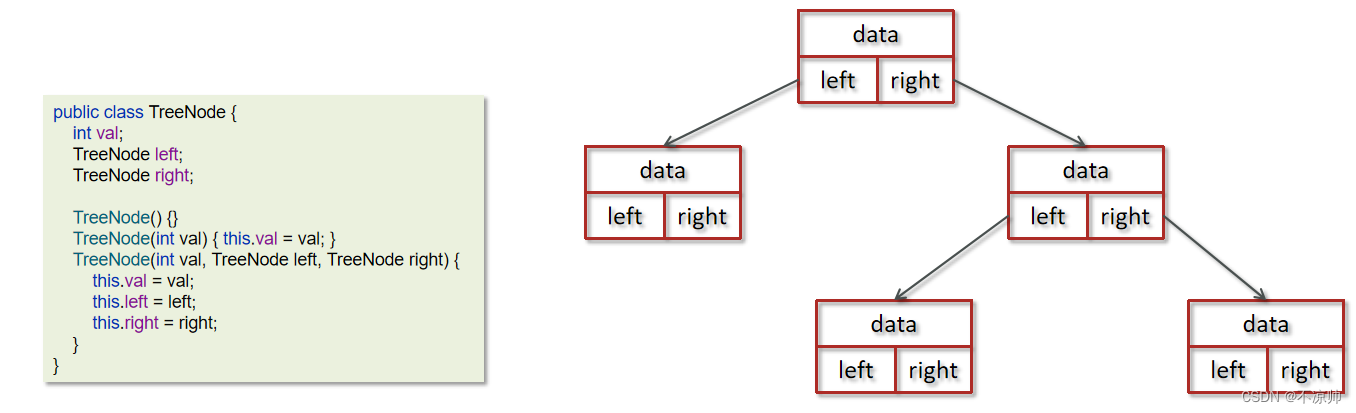
バイナリ ツリーの中で、より一般的なバイナリ ツリーは、完全バイナリ ツリー、完全バイナリ ツリー、二分探索、赤黒ツリーです。
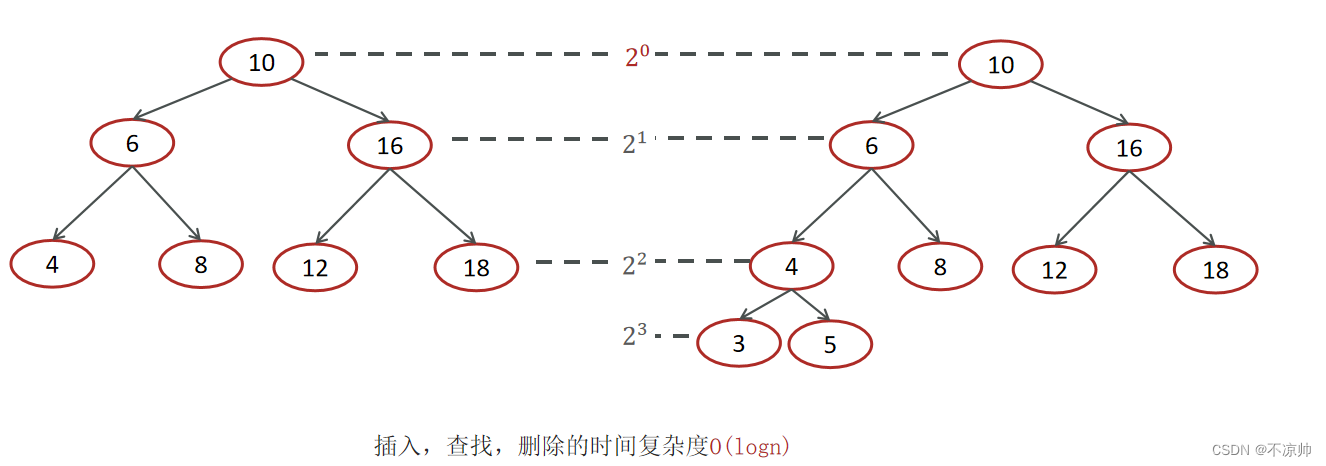
二分探索木(BST) は、二分探索木、順序付き二分木、または並べ替えられた二分木とも呼ばれ、一般的に使用されるタイプの二分木です。二分探索木では、ツリー内の任意のノードで、その左側の各ノードの値が必要です。サブツリー内の はこのノードの値より小さくなければならず、右側のサブツリー ノードの値はこのノードの値より大きくなければなりません (左側が小さく、右側が大きい)。

実際、二分探索ツリーの形状が異なるため、時間計算量も異なります。挿入、検索、削除の時間計算量を見てみましょう。

(2) 赤黒の木
Red Black Tree : これは、以前は対称バイナリ B ツリーと呼ばれていた自己平衡二分探索ツリー (BST) でもあります。
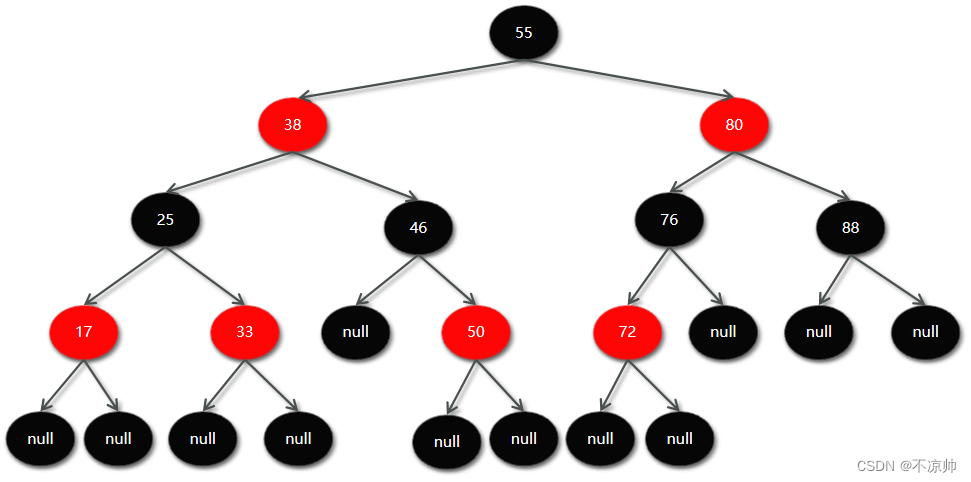
赤黒木の特徴:
-
ノードは赤または黒のいずれかです
-
ルートノードは黒です
-
リーフノードはすべて黒い空のノードです
-
赤黒ツリー内の赤いノードの子ノードはすべて黒です。
-
任意のノードからリーフ ノードまでのすべてのパスには、同じ数の黒いノードが含まれます。
バランスを確保: ノードを追加または削除するときに、これらのプロパティが満たされていない場合、すべてのプロパティを達成するために回転が発生します。
赤黒ツリーの時間計算量: 検索、追加、削除はすべて O(logn)
(3) ハッシュテーブル
ハッシュ テーブル(別名テーブル/ハッシュ テーブル) は、キー (Key) に基づいてメモリの格納場所の値 (Value) に直接アクセスするデータ構造です. データへのランダム アクセスの特性。

キーを配列の添字にマッピングする関数はハッシュ関数と呼ばれます。これは次のように表現できます: hashValue = hash(key)
ハッシュ関数の基本要件:
-
hashValue は配列の添字として使用する必要があるため、ハッシュ関数によって計算されるハッシュ値は 0 以上の正の整数である必要があります。
-
key1==key2 の場合、ハッシュ化後に取得されるハッシュ値も同じである必要があります: hash(key1) == hash(key2)
-
key1 != key2 の場合、ハッシュ化後に取得されるハッシュ値も異なる必要があります: hash(key1) != hash(key2)
ハッシュ衝突:
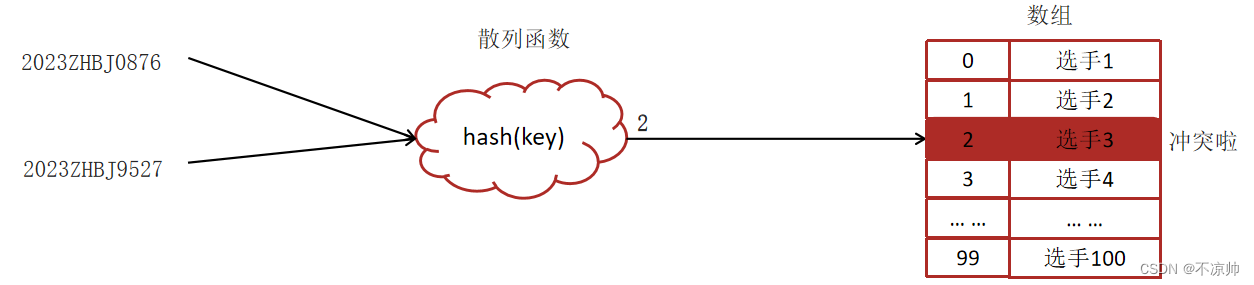
実際の状況では、異なるキーに対して異なるハッシュ値を計算できるハッシュ関数を見つけることはほとんど不可能であり、有名な MD5 や SHA などのハッシュ アルゴリズムでもこの状況を避けることはできません。これがハッシュ競合 (またはハッシュ競合、ハッシュの衝突、つまり複数のキーが同じ配列添字位置にマップされることを意味します)
ハッシュ テーブルでは、配列の各添字位置をバケットまたはスロットと呼ぶことができます。各バケット (スロット) はリンク リストに対応します。同じハッシュ値を持つすべての要素は、スロットに対応するリンク リスト内に同じに配置されます。 。

ハッシュ衝突 - リンクリスト方式(ジッパー)
-
配列の各添字位置はバケットまたはスロットと呼ばれます。
-
各バケット(スロット)はリンクされたリストに対応します
-
ハッシュ競合後の要素は、同じスロットに対応するリンク リストまたは赤黒ツリーに配置されます。
4. ハッシュマップ分析
(1) HashMapの実装原理
HashMap データ構造: 最下層はハッシュ テーブル データ構造、つまり配列とリンク リストまたは赤黒ツリーを使用します。
-
要素を HashMap に入れるとき、キーの hashCode を使用して再ハッシュし、配列内の現在のオブジェクトの要素の添字を計算します。
-
保存する際、同じハッシュ値を持つキーが存在する場合、2 つの状況が考えられます。
a. キーが同じ場合は、元の値を上書きします。
b. キーが異なる場合 (競合が発生した場合)、現在のキーと値をリンク リストまたは赤黒ツリーに配置します。
-
取得する際は、ハッシュ値に対応する添字を直接検索し、さらにキーが同一かどうかを判定して対応する値を検索します。
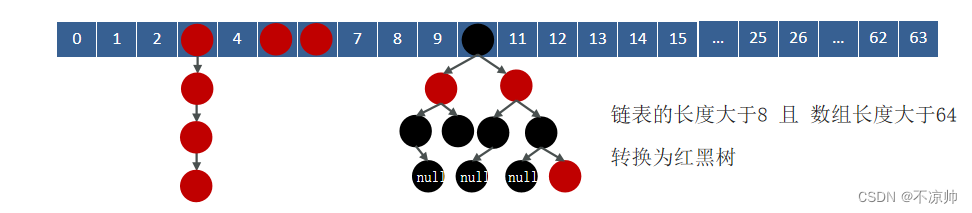
HashMapのjdk1.7とjdk1.8の違いは何ですか?
-
jdk1.8以前のジッパー方式、配列+リンクリスト
-
jdk1.8以降は、配列+リンクリスト+赤黒ツリーが使用されます。リンクリストの長さが8より大きく、配列の長さが64より大きい場合、リンクリストから赤黒ツリーに変換されます。 -黒い木。
(2) HashMapのputメソッドの具体的な処理
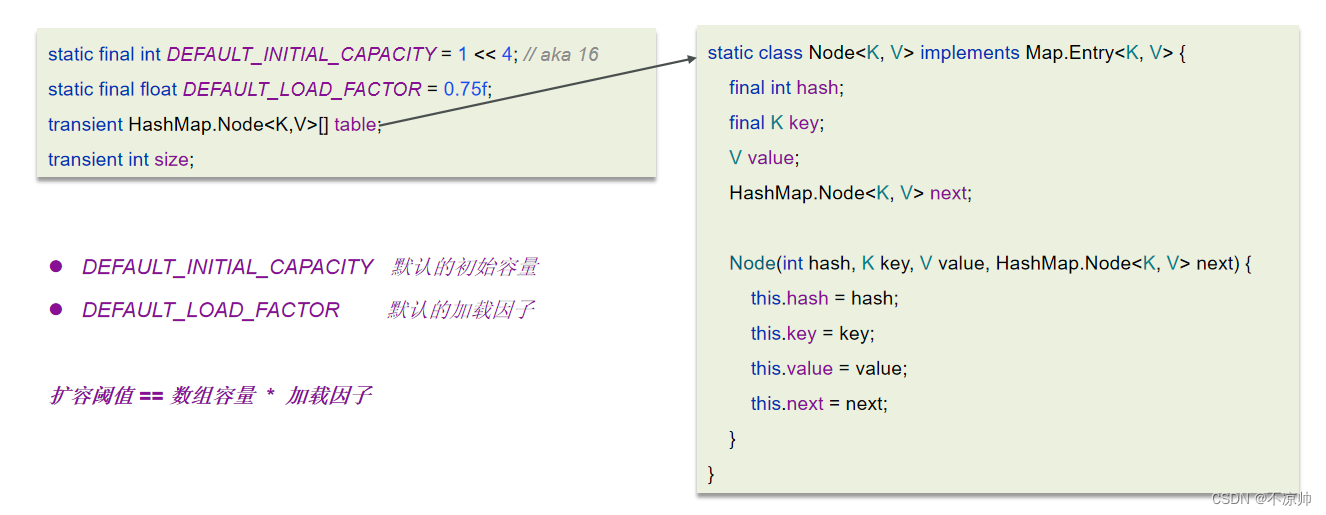
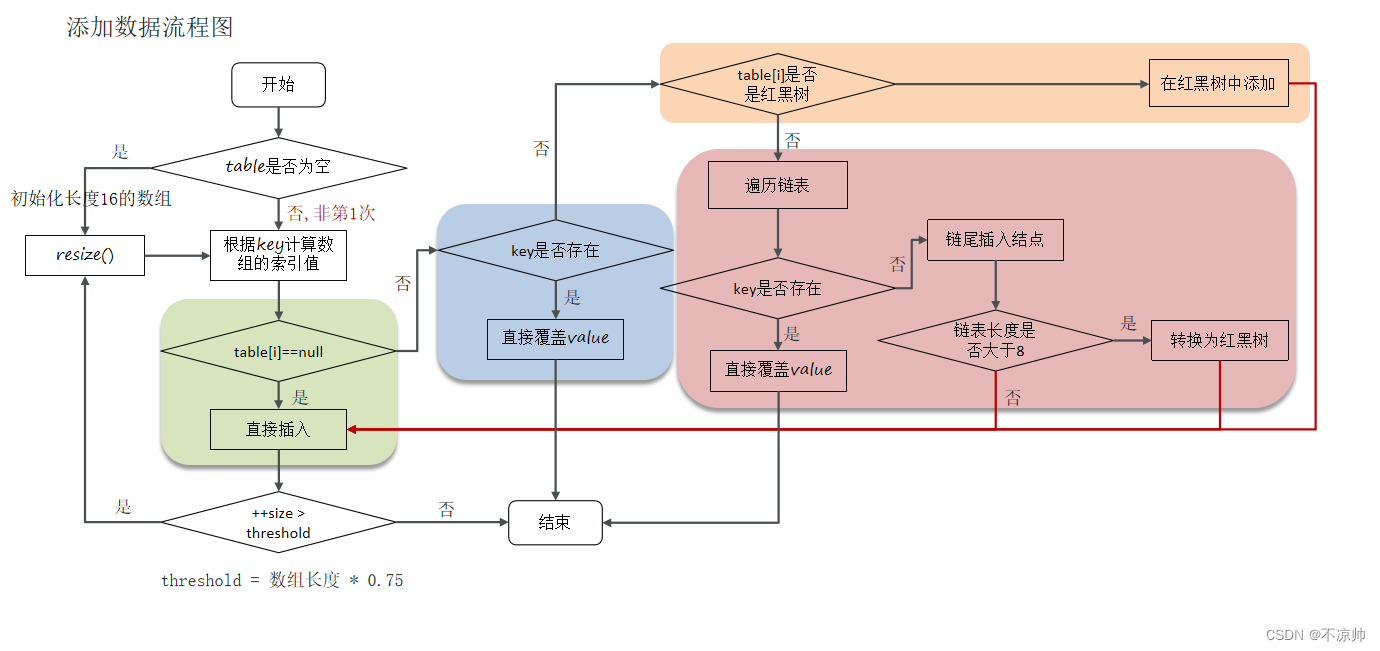
-
キーと値のペアの配列テーブルが空か null かを判断します。そうでない場合は、resize() を実行して展開 (初期化) します。
-
キー値に基づいてハッシュ値を計算し、配列のインデックスを取得します。
-
判定テーブル[i]==nullの場合は条件成立、直接新規ノードを作成して追加
-
table[i]==null の場合は true ではありません
4.1 table[i]の先頭要素がkeyと同じかどうかを判定し、同じであればvalueを直接上書きします。
4.2 table[i] がtreeNodeであるかどうか、つまり、table[i]が赤黒ツリーであるかどうかを判断し、赤黒ツリーの場合は、キーと値のペアをツリーに直接挿入します。
4.3 table[i] を走査し、リンク リストの最後にデータを挿入し、リンク リストの長さが 8 より大きいかどうかを判断します。8 より大きい場合は、リンク リストを赤黒ツリーに変換します。赤黒ツリーで挿入操作を実行します。トラバーサル プロセス中に、キーがすでに存在することが判明した場合は、値を直接オーバーライドします。
-
挿入成功後、実際のキーと値のペアのサイズが最大容量のしきい値(配列長 * 0.75)を超えているかどうかを判定し、超えている場合は容量を拡張します。
(3) HashMap アドレッシングアルゴリズム

HashMap の配列の長さは 2 の累乗でなければならないのはなぜですか?
-
インデックスを計算するときはより効率的です。インデックスが 2 の n 乗である場合は、モジュロの代わりにビットごとの AND 演算を使用できます。
-
展開時にインデックスを再計算するとより効率的です。ハッシュと oldCap == 0 を持つ要素は元の位置に残ります。それ以外の場合は、新しい位置 = 古い位置 + 古いキャップになります。
1.7のHashMapのマルチスレッド無限ループ問題
jdk7のデータ構造は配列+リンクリストです。配列を展開した場合、リンクリストは先頭挿入方式のため、データ移行処理中に無限ループが発生する可能性があります。

たとえば、現在 2 つのスレッドがあります
スレッド 1: 現在のハッシュマップ データを読み取ります。データ内にリンク リストがあります。拡張の準備中に、スレッド 2 が介入します。
スレッド 2: ハッシュマップも読み取り、容量を直接拡張します。先頭挿入なのでリンクリストの順序が逆になります。たとえば、元の順序は AB、拡張された順序は BA、スレッド 2 の実行は終了します。
スレッド 1: 実行を続けると無限ループが発生します。
スレッド 1 は最初に A を新しいリンク リストに移動し、次に B をリンク ヘッドに挿入します。別のスレッドにより、B の次のポイントは A となるため、B->A->B となり、ループが形成されます。もちろん、JDK 8 では展開アルゴリズムが調整され、リンク リストの先頭に要素が追加されなくなりました (ただし、展開前と同じ順序は維持されます)。末尾挿入メソッドにより、jdk7 での無限ループの問題が回避されます。
(4) HashMap展開機構
拡張プロセス:
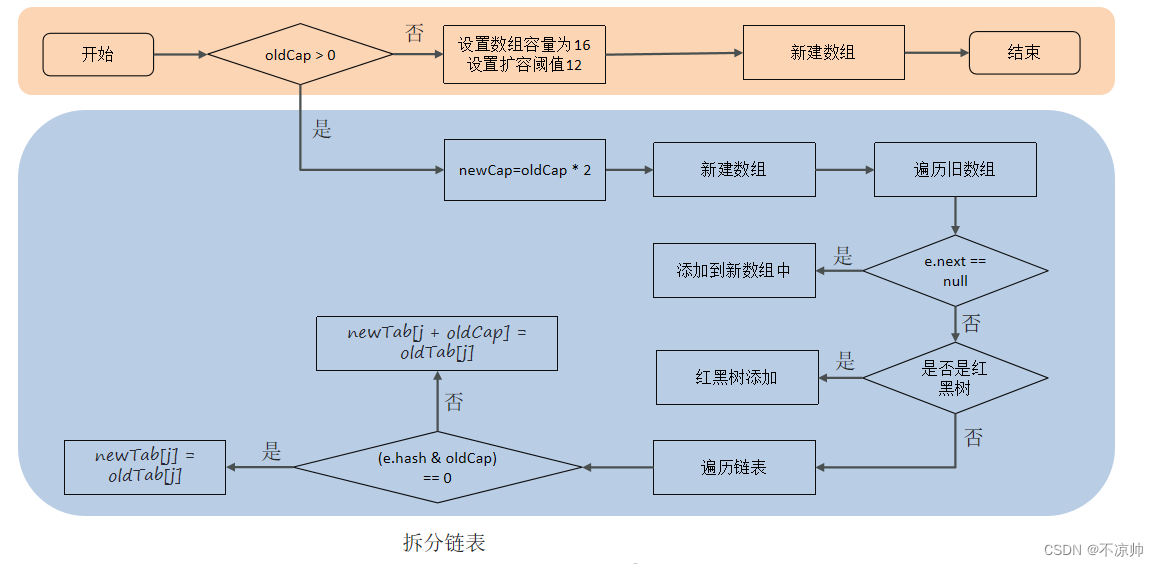
1. 要素の追加または初期化の際には、サイズ変更メソッドを呼び出して拡張する必要があります。初めてデータを追加するとき、初期配列の長さは 16 です。その後の各拡張では、拡張しきい値 (配列長 * 0.75) に達します。
2. 容量が拡張されるたびに、容量は拡張前の容量の2 倍になります。
3. 拡張後、新しい配列が作成され、古い配列のデータを新しい配列に移動する必要があります。
-
ハッシュの競合がないノードの場合は、 e.hash & (newCap - 1) を直接使用して、新しい配列のインデックス位置を計算します。
-
赤黒木の場合は赤黒木を追加
-
リンク リストの場合は、リンク リストを走査する必要があり、場合によってはリンク リストを分割し、(e.hash & oldCap) が 0 であるかどうかを判断する必要があります。要素の位置は元の位置に留まるか、または、元の位置 + 増加した配列サイズに移動します。
(5) HashMap、HashSet、HashTable の違い
HashMap、HashSet、HashTable はすべて Java コレクション フレームワークの一部であり、主に実装するインターフェイス、スレッド セーフ、実行効率、NULL 値の処理方法、要素の追加方法が異なります。
-
実装されたインターフェイス: HashMap および HashTable は Map インターフェイスの実装クラスであり、HashSet は Set インターフェイスの実装クラスです。
-
スレッド セーフ: HashTable のメソッドは同期されているため、スレッド セーフですが、HashMap は非同期であるため、格納されたオブジェクトはスレッド セーフではありません。HashSet の最下層は HashMap を使用して実装されるため、スレッドセーフではありません。
-
実行効率: HashTable は同期、HashMap は非同期であるため、HashMap の実行効率は HashTable よりも高くなります。3 つの実行効率は、高速から低速まで、HashMap>HashSet>HashTable となります。
-
null 値の処理: HashMap のキーと値は null にすることができますが、HashTable のキーと値は Null を格納できません。HashSet は値のみを格納できますが、その最下層はハッシュマップを使用するため、Null も格納できます。
-
要素の追加方法: HashMap は put メソッドを通じて要素を追加し、HashSet は add メソッドを通じて要素を追加します。
一般に、HashMap、HashSet、および HashTable にはそれぞれ独自の特性と使用シナリオがあり、使用するコレクション クラスの選択は主に特定のビジネス ニーズに依存します。