オーディオ空間分解によるリアルタイム ニューラル ラディアンス トーキング ポートレート合成
NeRF (Neural Radiance Field) は神経放射フィールドです
解決すべき主な問題:画像から 3D モデルを取得する
3Dモデルとは何ですか?
抽象的に言えば、3D モデルは主に形状と外観に分けられ、外観はマテリアルと照明に大別できます。これらの基本情報を取得した後は、特定のレンダリング アルゴリズムを通過するだけで、イメージを取得できます。モデルから画像へのこの順方向のプロセスはレンダリングと呼ばれ、画像からモデルを取得する逆のプロセスは逆レンダリングと呼ばれます。

形状表現:
主流の表現方法には、 メッシュ、点群、占有フィールド、および符号付き距離フィールド の4 つがあります。
もちろん、ボクセルやマルチビューなどの表現もいくつかありますが、ここではそれを列挙しますので、興味のある方はご自身で関連情報を確認してください。
NeRFで使用される形状表現方法はソフトシェイプと呼ばれるもので、何もない3次元空間から画像のニーズに基づいて徐々に3次元オブジェクトを作成します。NeRF は、次の図に示すように、レイ上の多くの点を分割します。
これは、多数のニューラル ネットワーク手法の中で NeRF が傑出している能力の鍵の 1 つでもあります。これまで、ニューラル ネットワークは 3D モデルを再構築するためにソフト ジオメトリではなくハード ジオメトリを使用することがよくありました。
ソフト方式を使用することには 2 つの大きな利点があります。
①オブジェクトセグメンテーションマスク(オブジェクトセグメンテーションマスク)を使用する必要がありません。
② 境界不連続問題がないため、微分レンダリングが容易
もちろん、レンダリングコストが高い、編集が難しいなどのデメリットもあります。
この方法に興味のある友人は、次の論文を自分で読むことができます。
Yu A 、Fridovich-Keil S 、Tancik M 、他 プレノセル: ニューラル ネットワークを使用しない放射フィールド[J]。2021年。
サン C 、サン M 、チェン HT 。直接ボクセル グリッド最適化: 放射フィールド再構築のための超高速収束[C]// 2021.

次に、NeRF のニューラル ネットワークに関する部分を紹介します。
ニューラル ネットワークを使用すると、色へのマッピング、占有へのマッピング、光密度 (密度) へのマッピングなど、各画像のさまざまなマッピング関係を関数に当てはめることができます。
しかし問題は、ニューラル ネットワークの表現に偏りがあり、ニューラル ネットワークを通じて高品質な結果が得られない可能性があることです。下図に示すように、滑らかな結果が得られる傾向にありますが、私たちが期待しているのは、鋭い(鋭い)結果が得られます。そこで、NeRF は画像を cos と sin で表されるフーリエ特徴 (フーリエ特徴) にマッピングできる関数を提案します。下の図からわかるように、以前と比較して結果は大幅に改善されました。
ニューラル ネットワークによって信号を表現するこの方法をニューラル フィールドと呼びます。この表現には3 つの大きな利点があります。
①各 3D モデルの表現に必要な容量は約 10MB だけなので、送信に便利です
②シーンを離散化する必要がない(離散化)
③より柔軟で最適化が容易:例えば、正則化がより便利で、汎化能力が強い

次に、下図に示すように、5 種類の NeRF の撮影シナリオを紹介します。
①物体が中心にあり、カメラは周囲を撮影し、被写体を再構成するためによく使用されます
②カメラの方向は固定されており、狭い範囲で動きます。
③パノラマ撮影と同様に、カメラが中央にあり全方向を撮影し、通常は背景を再構築するために使用されます。
④ランダムな方向への撮影と固定空間への配信
⑤は①と③を組み合わせたもので、オブジェクト本体だけでなく背景も再構築します。

NeRF が解決すべき主な問題は、空間で近くの景色を再構成するときに遠景がぼやけること、逆に遠方の景色を再構成するときに近くの景色がぼやけてしまうことであり、遠景の両方で鮮明な結果が得られることが期待されています。そして再建間近。
この問題を解決するために、NeRF++ メソッドは、NeRF を分解して結合し、 1 つの NeRF を使用して前景と背景を表し、最後にそれらを結合するという解決策を提案します。

前述の 5 番目の射撃シーンがここで使用されており、次の図に示すように、最終的な効果も非常に優れています。

特定の詳細に興味がある友人は、次の論文を読むことができます。
Zhang K 、 Riegler G 、 Snavely N 、他 NeRF++: 神経放射フィールドの分析と改善[J]。2020年。
次に、 NeRF のアンチエイリアシングの問題を紹介します。
アンチエイリアシング問題は、グラフィックスに関わる古典的な問題、つまりサンプリング レートの問題によって引き起こされる画像のエイリアシングの問題であるため、NeRF にもアンチエイリアシング処理が必要です。
ただし、従来の NeRF のように低解像度で結果をダウンサンプリングしてアンチエイリアスを行うことは望ましくありません。これにより、高解像度での画質に影響が生じ、PSNR が低下します。したがって、MipNeRF は、位置エンコーディングを使用して画像を sin と cos で表されるフーリエ特徴にマッピングします。以下に示すように:

同時に、低解像度でのスペクトルは非常に高いですが、サンプリング周波数がナイキストのサンプリング定理を満たすほど高くないため、 MipNeRF、つまりフーリエ関数用のローパス フィルター (ローパス フィルター)が導入されています。ローパス フィルター処理を実行します。このフィルターのサイズはピクセル サイズによって異なります。
詳細を知りたい場合は、次の論文を参照してください。
ジョナサン・T・バロン、ベン・ミルデンホール、マシュー・タンシク、ピーター・ヘドマン、リカルド・マーティン=ブルアラ、プラトゥール・P・スリニバサン。Mip-NeRF: アンチエイリアシング神経放射フィールドのマルチスケール表現。コンピュータ ビジョンに関する IEEE/CVF 国際会議 (ICCV) の議事録、2021 年 10 月。
次に、 NeRF の編集可能な問題を紹介します。
NeRF テクノロジーを使用して現実のオブジェクトをデジタル化できますが、VR/AR の分野などのデジタルの世界では、照明の編集、マテリアルの編集、さらにはスタイルやアートの編集など、3 次元オブジェクトをさらに編集する必要があることがよくあります。創造の皆さん、この問題は常に NeRF が解決する必要があるものです。ただし、前述したように、NeRF で使用されている 3 次元形状の表現方法は編集に適していないため、編集や修正が容易な Mesh に変換して表現することが期待されます。現在、IRON と呼ばれるニューラル インバース レンダリング パイプラインが提案されており、これはフォトメトリック画像上で実行でき、三角形メッシュとマテリアル テクスチャの形式で高品質の 3D コンテンツを出力でき、既存のグラフィックス パイプラインに展開できます。以下に示すように:

RION の最適化プロセスでは、ニューラル表現を使用して幾何学的形状と材質を表現し、3 次元オブジェクトをより柔軟かつコンパクトにします。同時に、IRON は SDF (有向距離場) を最適化します。まず、体積放射線場法が使用されます。その後、物理ベースのエッジ認識サーフェス レンダリングを使用してトポロジがさらに最適化され、ジオメトリの洗練とマテリアルと照明の分離が改善されます。
具体的な詳細については、arxiv の次の文書を参照してください。
IRON: フォトメトリック イメージからニューラル SDF とマテリアルを最適化することによる逆レンダリング。
外観表現:
以下の図に示すように、最も一般的な表現は間違いなくマテリアル テクスチャ マップ + アンビエント ライトであり、この方法は編集と修正が容易であり、レンダリング作業で広く使用されています。しかし、欠点は、この表現方法が非常に煩雑であり、テクスチャをマッピングするだけでなく、異なるサーフェス上で異なるライトを交差させる必要があることです。
次に、放射フィールドまたは表面ライト フィールドがあり、この方法では、各表面点 (x、y、z) での異なる観察角度 (θ、φ) の色 (r、g) が得られます。このようにして、オブジェクト表面の色、反射、影の効果を簡単に記述することができます。ただし、修正や編集が簡単ではないという欠点があります。
興味のある方は、次の文書を参照してください。
Wood DN、Azuma DI、Aldinger K、他。3D 写真用の表面ライト フィールド[C]// SIGGRAPH カンファレンス。2000年。
抽象的な
動的神経放射フィールド ( NeRF)) は、話すポートレートの高忠実度 3D モデリングで成功を収めていますが、トレーニングと推論の速度が遅いため、潜在的な使用法が大きく妨げられています。この論文では、グリッドベースの NeRF の最近の成功を活用して、話すポートレートのリアルタイム合成とより高速な収束を可能にする、効率的な NeRF ベースのフレームワークを提案します。私たちの重要な洞察は、本質的に高次元の話すポートレート表現を 3 つの低次元の特徴グリッドに分解することです。具体的には、分解オーディオ空間エンコーディング モジュールは、3D 空間グリッドと 2D オーディオ グリッドを使用してダイナミック ヘッドをモデル化します。胴体は、軽量の疑似 3D 変形可能モジュール内の別の 2D グリッドで処理されます。どちらのモジュールも、良好なレンダリング品質を前提とした効率に重点を置いています。
(動的神経放射場 (NeRF) は、話すポートレートの忠実度の高い 3D モデリングには成功していますが、その潜在的な使用は、トレーニングと推論の速度が遅いために大きく妨げられています。この論文では、NeRF ベースの効率的なフレームワークを提案します。メッシュベースの NeRF の最近の成功を活用して、リアルタイムで話すポートレートを合成し、収束を加速します。私たちの重要な洞察は、本質的に高次元の話すポートレート表現を 3 つの低次元の特徴グリッドに分解することです。具体的には、分解されたオーディオ空間エンコーディング モジュールです。 3D 空間メッシュと 2D オーディオ メッシュを使用して動的頭部をモデル化します。胴体は、軽量の疑似 3D 変形可能モジュール内の別の 2D メッシュによって処理されます。2 つのモジュールはどちらも、良好なレンダリング品質で効率を向上させることに焦点を当てています。広範な実験により、私たちの方法がリアルで音声同期されたトーキングポートレートビデオを生成できると同時に、以前の方法と比べて非常に効率的です。参照:)
まとめ
チャレンジ:
- グリッドベースの NeRF で空間情報と音声情報を効果的に表現する方法は未解決のままです。通常、オーディオは 64 次元ベクトルとしてエンコードされ、3D 空間座標を備えた MLP に供給されます。ただし、線形補間のためのグリッドベースの設定でオーディオに関係する追加の次元により、計算の複雑さが指数関数的に増加します。
- リアルなポートレートでは、それほど複雑ではないが同様に重要な胴体の部分を効果的にモデリングすることは簡単ではありません。これまでの実践では、別の完全な 3D 放射フィールド [22] を使用するか、絡み合った 3D 変形フィールド [32] を学習する必要がありましたが、これは過剰でコストがかかります。
仕事:
我々は、オーディオと空間表現を 2 つのグリッドに分解する、分解されたオーディオ空間コーディング モジュールを提案します。私たちは静的な 3 次元空間座標を維持しますが、オーディオは低次元の「座標」を動的にエンコードします。さらに、高次元特徴空間グリッドでオーディオと座標をクエリする代わりに、それらを 2 つの独立した低次元特徴グリッドに分割できることを示し、これにより補間のコストがさらに削減されます。この分解されたオーディオ空間エンコーディングにより、効率的な動的なヘッドショット モデリングが可能になります。
胴体部分については、計算コストの低減を追求し、その動作パターンを研究しています。観察された胴体の動きの少ないトポロジーの変化を考慮して、2D 特徴メッシュを使用した胴体の軽量の擬似 3D 変形モジュール モデルを提案します。これら 2 つのモジュールをさらにポートレート固有の NeRF アクセラレーション設計と組み合わせることで、私たちのアプローチは最新の GPU を使用してリアルタイム推論速度を達成できます。
貢献の概要:
- · 本質的に高次元のオーディオ駆動の顔のダイナミクスを 2 つの低次元の特徴グリッドで効率的にモデル化する、分解オーディオ空間エンコーディング モジュールを提案します。
- ・頭部の動きに同期した自然な体幹の動きの合成効率をさらに向上させる、軽量な擬似3D変形モジュールを提案します。
- · 私たちのフレームワークは、以前の作品よりも 500 倍高速に実行でき、より高品質でレンダリングでき、頭のポーズ、まばたき、背景画像など、話すポートレートのためのさまざまな明示的なコントロールもサポートしています。
図 1 に示すように。ネットワークアーキテクチャ。ヘッダーは、オーディオ空間分解エンコード モジュールを使用してモデル化されます。入力オーディオ信号は、最初にオーディオ特徴抽出器 (AFE) [22] によって処理され、次に低次元の空間依存オーディオ座標 xa \mathbf{x}_axa に圧縮されます。空間座標 x \ mathbf{x}x と音声座標 xa \mathbf{x}_axa を分離します。空間プロパティ f ff と g gg オーディオ プロパティは遅延で融合され、ヘッド カラー c cc と密度 σ \sigmaσ ボリューム レンダリングが生成されます。Pseudo - 3D 変形可能な胴体モデリング モジュール。ピクセル座標 xt x_txt ごとに胴体をサンプリングするだけで、変形フィールドが頭の姿勢 p \mathcal{p}p に依存する胴体ダイナミクス モデルを学習します。別のメッシュ エンコーダ E tosor 2 E_{\mathrm{tosor}}^{2}Etosor2 の胴体特徴学習 FT。これは胴体の色 ct と ααt 遅延に供給されます。
損失関数:
カラー : L color = ∑ C ∈ I ∣ ∣ C − C gt ∣ ∣ 2 2 ピクセルの透明度 : L エントロピー = − ∑ α ∈ I ( α log α + ( 1 − α ) log ( 1 − α ) )領域 : L ダイナミック = ∑ xa ∈ I ˉ 顔 ∣ xa ∣ 唇の微調整 : L 微調整 = ∑ C ∈ P ∣ ∣ C − C gl ∣ ∣ 2 2 + λ LPIPS ( P , P gt ) \ .text{Color}:\mathcal{L}_{\text{color}}=\sum_{\mathbf{C}\in\mathcal{I}}||\mathbf{C}-\mathbf{C}_ { \text{gt}}||_2^2\\ \text{ピクセルの透明度}:\mathcal{L}_{\text{エントロピー}}=-\sum_{\alpha\in\mathcal{I}}( \ alpha\log\alpha+(1-\alpha)\log(1-\alpha))\\ \text{顔の領域}:\mathcal{L}_{\mathrm{dynamic}}=\sum_{\mathbf{ x }_a\in\bar{\mathcal{I}}_{\mathrm{顔}}}|\mathbf{x}_a|\\ \text{唇の微調整}:\mathcal{L}_ { \text{微調整}}=\sum_{\mathbf{C}\in\mathcal{P}}||\mathbf{C}-\mathbf{C}_{\mathbb{gl}}||_2 ^ 2+\lambda\mathbf{LPIPS}(\mathcal{P},\mathcal{P}_{\mathbb{gt}})カラー:Lcolor = C∈I∑∣∣C−Cgt∣∣22 ピクセル透明度:レントロピー =−α∈I∑(αlogα+( 1−α)log(1−α))顔面領域:Ldynamic =xa ∈Iˉface ∑ ∣xa ∣唇の微調整:Lfine-tune =C∈P∑ ∣∣C-Cgl ∣∣22+λLPIPS(P,Pgt)
各ピクセルのカラー C の MSE 損失を使用してネットワークをトレーニングします。
エントロピー正則化項は、ピクセルの透明度を 0 または 1 にするために使用されます。ここで、α \alphaα は、画像 I \mathcal{I}I 内の各ピクセルの透明度です。
音声の状態は顔の部分にのみ影響を与える必要があります。動的モデリングを安定させるために、オーディオ座標に関する L 1 L1L1 正則化項も提案します。これにより、オーディオ座標 xa \mathbf{x}_axa が非顔領域「I face \mathcal{I}」に収まるようになります。 _{\mathrm {face}}Iface 」は 0 に近いため、顔の領域 (髪や耳など) 以外の意図しないジッターを回避できます。
合成ポートレートを自然に見せるためには、高品質の唇が不可欠です。実験の結果、唇の複雑な構造情報は、ピクセルごとの MSE 損失を通じてのみ学習するのは困難であることがわかりました。したがって、パッチタイプの構造損失を使用して唇領域を微調整することを提案します。記事では、顔のランドマークに基づいて唇が位置する画像パッチ P \mathcal{P}P をサンプリングします。次に、唇領域を微調整するために、 λ \lambdaλ によってバランスされた LPIPS 損失と MSE 損失の組み合わせを適用できます。
関連作業
音声によるトーキングポートレート合成:
- 音声駆動の発話ポートレート合成は、任意の入力音声音声から特定の人物を再現することを目的としています。リアルで同期性の高い会話ポートレートビデオを実現するために、さまざまな方法が提案されています。
- 方法 [6、7] では、音素と口の対応ルールのセットを定義し、縫合ベースの技術を使用して口の形状を変更します。ディープラーニングは、音声入力に対応する画像を合成することで画像ベースの手法を実装します。これらの方法の制限の 1 つは、固定解像度でのみ画像を生成でき、頭の姿勢を制御できないことです。
- もう 1 つの研究方向は、モデルベースの方法です。この方法では、顔のランドマークや 3D 変形可能な顔モデルなどの構造表現が、発話ポートレート合成を支援するために使用されます。ただし、これらの中間表現の推定では追加の誤差が生じる可能性があります。
最近、一部の作品 [19、22、32、46] では NeRF [36] を利用して、話すポートレートを合成しています。NeRF ベースの手法は、少ないトレーニング データであらゆる解像度でフォトリアリスティックなレンダリングを実現できますが、音声駆動の発話ポートレート合成に関する現在の研究は、トレーニングと推論の速度が遅いために依然として妨げられています。
ダイナミックモデリング:
- バニラ NeRF は静的シーンのモデル化しかできないため、動的シーンをモデル化するために多くの異なる方法が提案されています。
- 変形ベースの方法は、放射場に沿った変形場を学習することによって、すべての観測値を正準空間にマップし直すことを目的としています。変調ベースの方法では、時間や音声を表すことができる潜在コード上で NeRF を直接変調します。これらの方法は、位相変化を伴う複雑なダイナミクス モデリングに適しており、顔のダイナミクス モデリングにより適しています。
効率:
- レンダリングを高速化するために、最近の研究では、MLP のサイズを縮小するか、MLP を完全に削除し、3D シーンの特徴を明示的な 3D 特徴グリッド構造に保存することが提案されています。たとえば、DVGO [49] は高速化のために密な特徴グリッドを直接使用します。Instant-NGP [37] は、モデル サイズを制御するために多重解像度ハッシュ テーブルを採用しています。TensorRF [10] は、高密度の 3D 特徴グリッドをコンパクトな低ランクのテンソル コンポーネントに分解します。ただし、これらのグリッドベースの NeRF は静的なシーンにのみ適しています。
- 動作 [時間認識ニューラル ボクセルを備えた高速動的放射フィールド、
動的ビュー合成の高速最適化のためのニューラル変形可能ボクセル グリッド、Devrf: 動的シーン用の高速変形可能ボクセル放射フィールド、リアルタイムでの
動的放射輝度フィールド レンダリングのためのフーリエ プレノクツリー。
] これらの加速技術を動的 NeRF に適用しますが、変形に基づいているか、時間依存のダイナミクスのみをサポートしているため、オーディオ駆動のスピーキング ポートレート合成には適していません。対照的に、私たちのアプローチは、オーディオ主導の設定で音声とポートレートの合成を行うように設計されています。
方法
予選
動的シーンの新しいビュー合成に関しては、追加の条件が必要です (つまり、現在時刻 t が必要です)。従来のアプローチは通常、次の 2 つの方法で動的シーン モデリングを実行します。
- 変形ベースの手法は、各位置およびタイム ステップでの変形 Δ x \Delta\mathbf{x}Δx を学習します: G : x , t → Δ x , \mathcal{G}:\mathbf{x},t\rightarrow\ Delta \mathbf{x},G:x,t→Δx は、元の位置 x \mathbf{x}x に加算されます。
- 変調ベースの方法は、プレノプティック関数を時間内で直接調整します: F : x , d , t → σ , c . \mathcal{F}:\mathbf{x},\mathbf{d},t\rightarrow\sigma,\ mathbf {c}.F:x,d,t→σ,c..
変形ベースの方法は位相変化 (口の開閉など) が苦手なため、変形フィールド [39] の固有の連続性により頭部をモデル化する変調ベースの戦略を選択し、次のような変形を選択します。より単純な動作パターンで胴体の一部をモデル化するための戦略に基づいています。
トレーニング データは通常、同期されたオーディオ トラックを備えた静的カメラによって記録された 3 ~ 5 分のシーン固有のビデオです。各画像フレームには 3 つの主な前処理ステップがあります: (1) 頭、首、胴体、および背景の部分の意味解析; (2) 目や唇を含む 2D 顔のランドマークの抽出; (3) 頭部の部分的な姿勢を推定するための顔の追跡パラメーター。。音声処理の場合、自動音声認識 (ASR) モデルが適用され、音声トラックから音声特徴が抽出されます。NeRF は、頭のポーズと音声の状態に基づいて、頭のパーツを合成する方法を学習するために使用できます。胴体部分は頭部分と同じ座標系にないため、個別にモデル化する必要があります。
最近のグリッドベースの NeRF は 3D 特徴グリッド エンコーダ E spatial 3 : f = E spatial 3 ( x ) E_{\mathrm{spatial}}^{3}\colon\mathbf{f}=E_{\ mathrm{spatial }}^{3}(\mathbf{x})Espatial3 :f=Espatial3 (x)、ここで x ∈ R 3 \mathbf{x} \in R^3x∈R3 は空間座標、f ff はエンコーディングの空間的特徴。このフィーチャ グリッド エンコーダは、より安価な線形補間を使用して空間フィーチャをクエリするため、トレーニングと推論の効率が大幅に向上します。これにより、静的な 3D シーンのリアルタイム レンダリング速度が可能になります。私たちはこのインスピレーションを取り入れて拡張し、ダイナミックなスピーキングポートレート合成に必要な高次元のオーディオ空間情報をエンコードします。
分解されたオーディオ空間エンコーディング モジュール
従来の暗黙的な NeRF メソッドは通常、オーディオ信号を高次元のオーディオ特徴にエンコードし、それらを空間特徴と連結します。ただし、線形補間の複雑さは入力次元とともに指数関数的に増大するため、高次元の特徴をグリッドベースの NeRF と統合することは簡単ではありません。トレリス エンコーダでオーディオ空間特徴の高次元連結を直接使用すると、すぐに計算不可能になります。したがって、我々は、災害を軽減する次元で音声空間情報をモデル化するための 2 つの設計を提案します。
まず、高次元オーディオ特徴 a を低次元オーディオ座標 xa ∈ RD \mathbf{x}_a ∈ R^Dxa ∈RD に圧縮します。ここで、次元 D ∈ [1, 2, 3] D \in [1, 2, 3]D∈[1, 2, 3] は小さいです。これは、MLP を介して空間に依存する方法で実現されます: xa = MLP ( a , f ) \mathbf{x}_a = MLP (a, f) xa =MLP (a, f)。ここで、オーディオ座標が空間位置に明示的に依存するように、空間特徴 f ff を連結します。この操作により、オーディオ機能が空間情報を暗黙的に学習することから解放され、よりコンパクトなオーディオ座標が可能になります。オーディオ座標は、HyperNeRF の環境座標の変形可能なスライス サーフェス タイプからインスピレーションを得ていますが、高効率を実現するためにフィーチャー グリッド エンコーダーと統合されています。
2 番目に、代わりに高次元の g = E 3 + D ( x , xa ) を使用します。 g = E^{3+D} (\mathbf{x}, \mathbf{x}_a) g=E3 合成オーディオ空間トレリス エンコーダー+D(x, xa ) の場合、オーディオ座標と空間座標をそれぞれエンコードするために、より低い次元の 2 つのトレリス エンコーダーに分解します。 f = E spatial 3 ( x ) 、 g = E audio D ( xa ) \mathbf{f} =E_{\mathrm{空間}}^{3}(\mathbf{x}), \mathbf{g}=E_{\mathrm{音声}}^{ D}({\mathbf{x}}_{a })f=Espatial3 (x)、g=EaudioD (xa)。これにより、内挿コストが 2 3 + D 2^{3+D}23+D から 2 3 + 2 D (D ≥ 1) 2^3 + 2^D (D ≥ 1) 23+2D (D ≥ 1) にさらに削減されます。 1)。空間特徴 f ff と音声特徴 g gg は、補間を実行した後に連結できます。
目の動きも、自然な話し方のポートレート合成における重要な要素です。ただし、まばたきと音声信号の間には強い相関関係がないため、従来の方法では目の制御が無視されることが多く、速すぎるまばたきや半まばたきなどのアーチファクトが発生します。点滅を明示的に制御する方法を提供します。図 2 に示すように、2D 顔ランドマークに基づいて画像全体における目の領域の割合を計算し、この比率 (通常は 0% から 0.5% の範囲) を 1D 目の特徴 e として使用します。この目の特徴に基づいて NeRF ネットワークを調整し、単純な RGB 損失を伴う目のダイナミクスをモデルが学習するにはこの単純な変更で十分であることを示します。テスト中に、目の割合を簡単に調整してまばたきを制御できます。
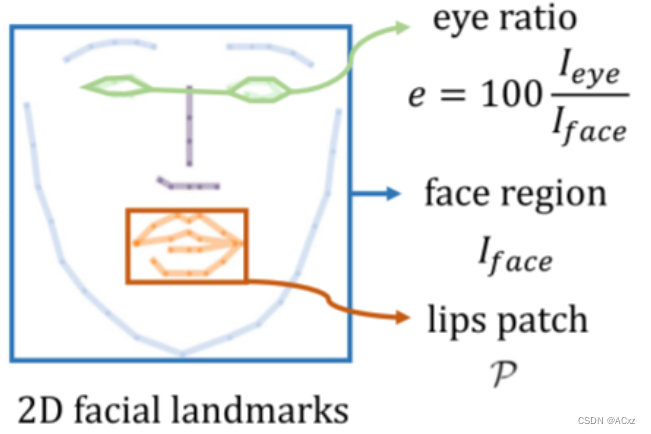
図 2. ランドマーク情報の例。予測された 2D 顔のランドマークに基づいて、トレーニングを支援する 3 つの特徴を抽出します。動的正則化のための顔領域 I face \mathcal{I}_{\mathrm{face}}Iface、アイ コントロール ee のためのアイ レシオ e、リップ パッチ P \mathcal{P}P 唇の微調整。
空間特徴 f ff、音声特徴 g gg、目の特徴 e ee を潜在的外観の埋め込み i ii に沿って接続し、小さな MLP を使用して密度と色を生成します。 c , σ = MLP ( f , g , e , i ) \
mathbf { c},\sigma=\mathbf{M}\mathbf{LP}(\mathbf{f},\mathbf{g},e,\mathbf{i})c,σ=MLP(f,g,e,私)
擬似3D変形モジュール
頭部と比較すると、胴体部分はほぼ静止しており、トポロジカルな変化はなくわずかな動きしか含まれていません。以前の方法では、別の完全に動的な NeRF を使用して胴体をモデル化するか [22]、頭部と一緒に絡み合った変形フィールドを学習します [32]。私たちはこれらの方法は冗長であると考え、図 1 の下部に示すように、より効率的な擬似 3D 変形可能モジュールを提案します。
私たちの方法は、変形ベースの動的 NeRF の 2D バージョンとみなすことができます。各カメラ光線に沿って一連の点をサンプリングする代わりに、画像空間からピクセル座標 X t ∈ R 2 X_t \in R^2Xt ∈R2 をサンプリングするだけで済みます。変形は頭の姿勢 p \mathcal{p}p に基づいて条件付けされるため、胴体の動きは頭の動きと同期します。MLP を使用して変形を予測します: Δ x = MLP ( X t , P ) \Delta \mathbf{x}=MLP(X_t,P)Δx=MLP(Xt ,P)。変形座標は 2D フィーチャ メッシュ エンコーダに供給されて、胴関数 ft = E torso 2 ( xt + Δ x ) を取得します。 \mathbf{f}_{t}=E_{\mathrm{torso}}^{2 } (\mathbf{x}_{t}+\Delta\mathbf{x}).ft =Etorso2 (xt +Δx).. 胴体の RGB カラーとアルファ値を生成するために別の MLP が使用されます:
ct , α t = MLP ( ft , it ) \mathbf{c}_t,\alpha_t=\mathbf{MLP}(\mathbf{f}_t,\mathbf { i}_t)ct ,αt =MLP(ft ,it )
ここで、 i_tit は、より多くのモデル容量を導入する潜在的な外観の埋め込みです。この変形ベースのモジュールが胴体のダイナミクスをうまくシミュレートし、自然な胴体の画像と一致する頭部を合成できることを示します。さらに重要なのは、2D フィーチャ メッシュによる擬似 3D 表現が非常に軽量で効率的であることです。個別にレンダリングされた頭と胴体の画像を、提供された背景画像とアルファ合成して、最終的な出力ポートレート画像を取得できます。
実験
![[外部リンクの画像転送に失敗しました。ソース サイトにはリーチ防止メカニズムが存在する可能性があります。画像を保存して直接アップロードすることをお勧めします (img-MbA1hvIh-1681375155843) (C:\Users\dell\AppData\Roaming\Typora\) typora-user-images\ image-20230413163735306.png)]](https://img-blog.csdnimg.cn/d18c109fd687446ba95f7f9be42930c7.png)