シリーズ記事の目次
- 2024 Java インタビュー (1) – 春の章
- 2024 Java インタビュー (2) – 春の章
- 2024 Java インタビュー (3) – 春の章
- 2024 Java インタビュー (4) – 春の章
記事ディレクトリ
Redis パーティションのフォールト トレランス
1.redisデータパーティション
ハッシュ:(不安定)
クライアントシャーディング: ハッシュ + 剰余
ノードのスケーリング: データノードの関係が変化し、データ移行が発生する
移行の数は追加されたノードの数に関係します。容量を 2 倍にすることをお勧めします。
シンプルで直感的なアイデアは、ハッシュを使用して直接計算し、キーを使用してハッシュし、ノード数の剰余を取ることです。キーが十分に分散されている場合は均一性を達成できることがわかりますが、ノードが一度参加または離脱すると、元のすべてのノードが影響を受けるため、安定性は問題外になります。
一貫したハッシュ: (不均衡)
クライアントシャーディング: ハッシュ + 時計回り (最適化された剰余)
ノードのスケーリング: 隣接するノードにのみ影響しますが、データの移行は依然として発生します。
ダブルスケーリング: 最小限のデータ移行と負荷分散を確保
一貫性のあるハッシュは、安定性の問題を非常にうまく解決できます。すべてのストレージ ノードは、連続したハッシュ リング上に配置できます。ハッシュを計算した後、各キーは、最初に見つかったストレージ ノードのグループを時計回りに見つけて保存します。ノードの参加または脱退は、ハッシュ リング上で時計回りに隣接する後続のノードにのみ影響を与え、そのノードからデータを授受します。しかし、均一性の問題が発生し、たとえストレージノードを等間隔に配置できたとしても、ストレージノードの数が変わるとデータが不均一になってしまいます。
Codis ハッシュ スロット
Codis は、デフォルトですべてのキーを 1024 スロットに分割します。最初にクライアントから渡されたキーに対して crc32 操作を実行してハッシュ値を計算し、次にハッシュされた整数値 1024 をモジュロして剰余を取得します。この剰余は、に対応するスロットです。キー。
RedisCluster
Redis-cluster は、すべての物理ノードを [0-16383]スロットにマップします。crc16 アルゴリズムを使用して、キーのハッシュ値とモジュロ 16384 を取得します。基本的に、平均分散と連続分散を使用します。
2. マスタースレーブモード = シンプル
マスター スレーブ モードの最大の利点は、導入が簡単であることです。少なくとも2 つのノードでマスター スレーブ モードを構成でき、読み取りと書き込みを分離することで、読み取りと書き込みが同時に使用できなくなることを回避できます。ただし、マスター ノードに障害が発生すると、マスター ノードとスレーブ ノードは自動的に切り替わることができなくなり、SLA の低下に直接つながります。したがって、マスター/スレーブ モデルは一般に、ビジネス開発の初期段階、同時実行性が低く、運用と保守のコストが低い状況に適しています。
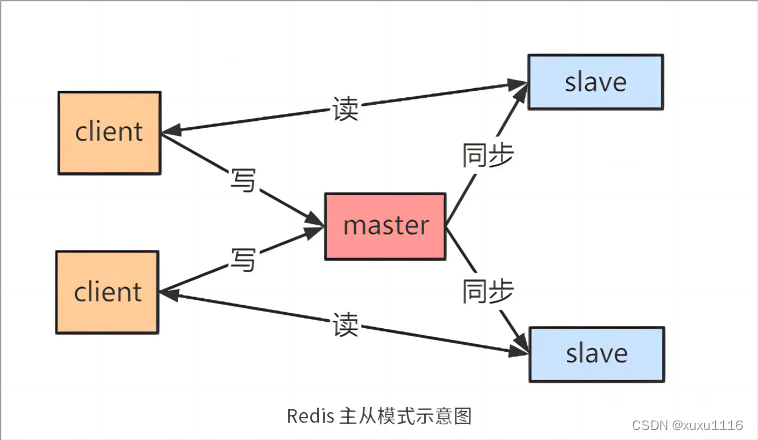
マスター/スレーブ レプリケーションの原理:
①スレーブサーバーからマスターサーバーへPSYNCコマンドを送信します。
② 初めて接続する場合は、フルコピーをトリガーします。このとき、マスターノードはバックグラウンドスレッドを開始し、RDBスナップショットファイルを生成します。
③マスターノードはこのRDBをスレーブノードに送信し、スレーブはまずローカルディスクに書き込み、その後ローカルディスクからメモリにロードします。
④マスターはこのプロセスの書き込みコマンドをキャッシュに書き込み、スレーブノードはこれらのデータをリアルタイムで同期します。
⑤ ネットワークが切断された場合、自動再接続後、マスターノードはコマンドを通じて欠落データの増分コピーをスレーブノードに伝播します。
欠点がある
スレーブ ノード データのすべてのレプリケーションと同期はマスター ノードによって処理されます。これにより、マスター ノードに過剰な負荷がかかります。これは、マスター/スレーブ構造を使用することで解決されます。redis4.0 での psync2 の導入により、この問題は解決されますつまり、スレーブの再起動後も増分同期を実行できます。
3. セントリーモード = 続きを読む
1 つ以上のセンチネル インスタンスで構成されるセンチネル クラスターは、1 つ以上のマスター サーバーと複数のスレーブ サーバーを監視できます。Sentinel モードは、フラッシュ セール システムでのアクティビティ情報のキャッシュなど、書き込みリクエストよりも読み取りリクエストの方がはるかに多いビジネス シナリオに適しています。書き込みリクエストが多く、クラスター内のスレーブ ノードの数が増加すると、マスター ノードに対するデータの同期のプレッシャーが非常に高くなります。
マスターサーバーがオフラインになった場合、sentinel はマスターサーバーの下のスレーブサーバーをアップグレードしてマスターサーバーにサービスを提供し続けることができるため、redis の高可用性が確保されます。
主観的なオフライン状態を検出する
Sentinel は、コマンド接続を確立しているすべてのインスタンス (マスター サーバー、スレーブ サーバー、および他の Sentinel) に 1 秒に 1 回 PING コマンドを送信します。
インスタンスが down-after-milliseconds ミリ秒以内に無効な応答を返した場合、Sentinel はインスタンスが主観的にオフライン ( SDown )であるとみなします。
目標のオフラインステータスを確認する
Sentinel がメイン サーバーが主観的にオフラインであると判断すると、Sentinel はメイン サーバーを監視している他のすべての Sentinel にホストのステータスを問い合わせるコマンドを送信します。
Sentinel 構成のクォーラム数に達したすべての Sentinel インスタンスがプライマリ サーバーが主観的にオフラインであると判断した場合、プライマリ サーバーは客観的にオフライン ( ODown )であると判断されます。
選挙リーダーセンチネル
マスター サーバーが客観的にオフラインであると判断されると、マスター サーバーを監視しているすべてのセンチネルは、選出アルゴリズム (raft) を通じてフェイルオーバー操作を実行するリーダー センチネルを選択します。
Raftアルゴリズム
Raft プロトコルは、分散システムの一貫性の問題を解決するために使用されるプロトコルです。Raft プロトコルで記述されるノードには、リーダー、フォロワー、候補の 3 つの状態があります。Raft プロトコルは時間を Term に分割します。Term は一種の「論理時間」と考えることができます。選挙プロセス:
①Raft はハートビート機構を利用してリーダー選出システムを起動し、システム起動後は全ノードがフォロワーに初期化され、期間は 0 となります。
② ノードが RequestVote または AppendEntries を受信した場合、そのノードはその Follower ID を維持します。
③ ノードが一定時間内に AppendEntries メッセージを受信せず、ノードのタイムアウト期間内にリーダーが見つからなかった場合、フォロワーは候補に変換され、リーダーに立候補し始めます。候補に変換されると、ノードはすぐに次のことを開始します: -- 独自の用語を追加し、新しいタイマーを開始します。 -- 自身に投票し、他のすべてのノードに RequestVote を送信し、他のノードからの応答を待ちます。
④ タイマーが切れる前に過半数のノードから承認票を獲得した場合、リーダーに変換されます。同時に、通知は AppendEntries を通じて他のノードに送信されます。
⑤各ノードは1期に1票しか投票できず、候補者は自身に投票し、フォロワーはRequestVoteを受け取った最初のノードに投票する先着順方式を採用しています。
⑥Raftプロトコルのタイマーはランダムタイムアウト(選挙の鍵)を採用しており、最初にCandidateに転換したノードが先に投票を開始し、過半数の票を獲得します。
プライマリサーバーの選択
リーダー センチネルが選出されると、リーダー センチネルは次のルールに従ってサーバーの中から新しいマスター サーバーを選択します。
① 主観的および客観的なオフラインノードをフィルタリングする
② 最もスレーブ優先度の高い構成のノードを選択し、存在する場合は「no」を返して選択を続けます。
③レプリケーション オフセットが大きいほどデータ レプリケーションがより完全になるため、レプリケーション オフセットが最も大きいシステム ノードを選択します。
④ run_id が小さいほど再起動回数が少なくなるため、run_id が最も小さいノードを選択します。
フェイルオーバー
Leader Sentinel が新しいマスター サーバーの選択を完了すると、Leader Sentinel はオフラインのマスター サーバー上でフェイルオーバー操作を実行します。主な手順は 3 つあります。
1. 障害が発生したマスターのスレーブの 1 つを新しいマスターにアップグレードし、障害が発生したマスターの他のスレーブを変更して新しいマスターをコピーします。
2. クライアントが障害が発生したマスターに接続しようとすると、クラスターは新しいマスターのアドレスをクライアントに返し、クラスターには現在の状態のマスターが 1 つだけ残ります。
3. マスターサーバーとスレーブサーバーが切り替わると、マスターの redis.conf、スレーブの redis.conf、および Sentinel.conf 設定ファイルの内容がそれに応じて変更されます。つまり、マスターの redis には、replicaof の余分な行が存在します。 conf設定ファイルの設定に応じて、sentinel.confの監視対象が変更されます。
4. クラスターモード = さらに書き込み
単一ノードの過剰な負荷による不安定性を回避するために、クラスター モードでは、一貫したハッシュ アルゴリズムまたはハッシュ スロット方式を使用して、各ノードに Key を配布します。その中で、各マスター ノードの後には、障害発生時のアクティブおよびバックアップの切り替えに使用される複数のスレーブ ノードが続きます。クライアントは任意のマスター ノードに接続でき、クラスターはさまざまな状況に応じてリクエストを異なるマスター ノードに転送します。クラスター モードはどのようにして高可用性を実現しますか
? それについてはどうですか? クラスター内のノードは定期的に互いの生存を検出します。ほとんどのノードがノードがダウンしていると判断すると、そのノードをクラスターから追い出し、障害が発生したマスター ノードを置き換えるノードをスレーブ ノードから選択します。全体の原理は基本的にセンチネル モードと同じで、
クラスター モードでは単一のマスター ノードの問題は回避されますが、クラスター内のデータを同期するときに一定量の帯域幅が占有されます。したがって、クラスター モードは大量の書き込み操作がある場合にのみ使用され、その他のほとんどの場合はセンチネル モードでニーズを満たすことができます。
5. 分散ロック
Watch を使用して Redis オプティミスティック ロックを実装する
オプティミスティック ロックは CAS (Compare And Swap) の比較と置換の考え方に基づいており、ロックの待機が発生せずリソースを消費することはありませんが、繰り返しのリトライが必要ですが、リトライ メカニズムのおかげで応答が速くなります。したがって、redis を使用して楽観的ロック (秒キル) を実装できます。具体的な考え方は以下のとおりです。
1. redisのwatch機能を利用してredisKeyのステータス値を監視する 2. redisKeyの値を取得し、redisトランザクションを作成し、キーの値に1を加算する 3. トランザクションを実行するキーの 1 が変更された場合は、キーをロールバックします。1 は追加しないでください。
setnx を使用して在庫の売れすぎを防止する分散ロックは、分散システム間の共有リソースへの同期アクセスを制御する方法です。Redis のシングルスレッド機能を使用して共有リソースをシリアル化する
// 获取锁推荐使用set的方式
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
String result = jedis.setnx(lockKey, requestId); //如线程死掉,其他线程无法获取到锁
// 释放锁,非原子操作,可能会释放其他线程刚加上的锁
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
// 推荐使用redis+lua脚本
String lua = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object result = jedis.eval(lua, Collections.singletonList(lockKey),
分散ロックの問題:
- クライアントが長時間ブロックされ、ロック失敗の問題が発生する
計算中に別のスレッドを非同期で起動してキーがタイムアウトしたかどうかを確認し、ロックタイムアウトが近づきロジックが完了していない場合はロックタイムアウトを延長します。
-
Redis サーバーのクロック ドリフトの問題により、同時にロックされている Redis の有効期限がシステム クロックに依存することが発生します。クロック ドリフトが大きすぎる場合、理論的には可能であり、有効期限の計算に影響を及ぼします。
-
単一ポイントのインスタンスに障害が発生し、ロックが時間内に同期されず、損失が発生します
RedLockアルゴリズム
1. 現在のタイムスタンプ T0 を取得し、クロック ドリフト エラー T1 を設定します。
2. すべての N/2+1 ロックを短時間で 1 つずつ取得し、時間 T2 で終了します。
3. 実際のロック処理時間は次のようになります: TTL - (T2 - T0) - T1。
このソリューションは、Redis の単一障害点を防ぐために複数のノードを使用します。効果は平均的なものであり、防ぐことはできません。
- マスター/スレーブ切り替えにより 2 つのクライアントが同時にロックを保持する
ほとんどの場合、その期間は非常に短く、切り替えの瞬間にノード ロックを取得するためにRedlockを使用する場合にも問題があります。それはすでに確率が非常に低い時期であり、避けることはできません。Redis 分散ロックはべき等トランザクションに適していますが、セキュリティを確保する必要がある場合はZookeeper や DBを使用するとよいですが、パフォーマンスが大幅に低下します。
飼育員分散ロックとの比較
- Redis 分散ロックでは、実際には常にロックの取得を試みる必要があり、パフォーマンスが消費されます。
- zk 分散ロックの場合、リスナーを登録するだけです。常に積極的にロックの取得を試みる必要はありません。ZK はロックした順にロックを取得するため、公平なロックです。パフォーマンスは mysql と似ていますが、 redisとは大きく異なります。
Redission 運用環境の分散ロック
Redisson は、NIO の Netty フレームワークに基づく Java In-Memory Data Grid (In-Memory Data Grid) 分散ロックのオープン ソース コンポーネントです。
ただし、ビジネスでデータの強い整合性が必要な場合、つまり、財務シナリオ (繰り返しの注文、繰り返しの転送) など、ロックの繰り返しの取得が許可されていない場合は、redis 分散ロックを使用しないでください。これは、 zookeeper や etcdなどの CP モデルを使用して実装できます。
| レディス | 動物園の飼育員 | etcd | |
|---|---|---|---|
| コンセンサスアルゴリズム | なし | パクソス (ZAB) | ラフト |
| キャップ | AP | CP | CP |
| 高可用性 | マスタースレーブクラスタ | n+1 | n+1 |
| 成し遂げる | setNX | ノードの作成 | 休息API |
6. Redis ハートビート検出
コマンド伝播フェーズ中、デフォルトでは、スレーブ サーバーは 1 秒に 1 回マスター サーバーに ACK コマンドを送信します。
1. マスターサーバーとスレーブサーバーの接続状態を検出します マスターサーバーとスレーブサーバーのネットワーク接続状態を検出します
ラグの値は 0 または 1 の間でジャンプする必要があります。スレーブが故障しています。
2. min-slave の実装を支援するために、安全でない状況でメイン サーバーが書き込みコマンドを実行しないように Redis を構成できます。
min-slaves-to-write 3 (min-replicas-to-write 3 )
min-slaves-max-lag 10 (min-replicas-max-lag 10)
上記の構成は、スレーブ サーバーの数が 3 台未満の場合、または 3 台のスレーブ サーバーの遅延 (ラグ) 値が 10 秒以上の場合、マスター サーバーは書き込みコマンドの実行を拒否することを意味します。
3. コマンド損失の検出と再送信メカニズムの
追加 マスターサーバーからスレーブサーバーに送信された書き込みコマンドがネットワーク障害により途中で失われた場合、スレーブサーバーが REPLCONF ACK コマンドをマスターサーバーに送信すると、マスターサーバーはサーバーはスレーブ サーバーの現在のレプリケーションを検出します。オフセットが自身のレプリケーション オフセットより小さい場合、マスター サーバーは、スレーブ サーバーによって送信されたレプリケーション オフセットに基づいて、レプリケーション バックログ バッファー内のスレーブ サーバーから欠落しているデータを見つけます。 、データをスレーブサーバーに再送信します。
1. Redis はなぜ速いのですか?
1) 完全にメモリに基づいており、ほとんどのリクエストは純粋なメモリ操作であり、非常に高速です。HashMap と同様に、データはメモリに保存されます。HashMap の利点は、検索と操作の時間計算量が O(1) であることです。
2) データ構造がシンプルでデータ操作もシンプル Redis のデータ構造は独自に設計されています
3) シングルスレッドを使用することで、不必要なコンテキストの切り替えや競合状態が回避される マルチプロセスやマルチスレッドによる CPU の消費による切り替えが発生しない ロックに関するさまざまな問題を考慮する必要がない ロック/リリースのロック操作が不要デッドロックの可能性によるパフォーマンスの低下
4) I/O 多重化モデル、ノンブロッキング IO を使用する
5) 基礎となるモデルが異なり、基礎となる実装方法とクライアントと通信するためのアプリケーション プロトコルが異なります。一般的なシステムがシステム関数を呼び出すと、処理に一定の時間がかかるため、Redis は独自の VM メカニズムを直接構築します。移動してリクエストしてください
2. Redis がシングルスレッドなのはなぜですか?
公式 FAQ には、Redis はメモリベースの操作であるため、CPU が Redis のボトルネックになるのではなく、Redis のボトルネックはマシンのメモリ サイズまたはネットワーク帯域幅である可能性が高いと記載されています。シングルスレッドは実装が簡単で、CPU がボトルネックにならないため、シングルスレッド ソリューションを採用するのが合理的であり、Redis はキュー テクノロジを使用して同時アクセスをシリアル アクセスに変換します。
1) リクエストの大部分は純粋なメモリ操作です
2) 単一スレッドを使用して不必要なコンテキストの切り替えと競合状態を回避する
3. Redis サーバーにはどれくらいのメモリが搭載されていますか?
構成ファイルで Redis メモリのパラメーターを設定します。
このパラメータが設定されていないか、0 に設定されている場合、redis のデフォルトのメモリ サイズは次のようになります。
デフォルトは 32 ビット モードの 3G です
64ビット以下では無制限
一般に、Redis はメモリを最大物理メモリの 4 分の 3、つまり 0.75 に設定することをお勧めします。
コマンド ライン設定 config set maxmemory <メモリ サイズ (バイト単位)> は、サーバーの再起動時に失敗します。
config get maxmemory は現在のメモリ サイズを取得します
永続的な場合は、maxmemory パラメータを設定する必要があります。maxmemory は bytes バイト型です。変換に注意してください。
4. Redis 操作がアトミックである理由とアトミック性を確保する方法は何ですか?
Redis の場合、コマンドのアトミック性は、操作を細分化することができず、操作が実行されるか実行されないかを意味します。
Redis の操作がアトミックである理由は、Redis がシングルスレッドであるためです。
Redis 自体が提供するすべての API はアトミック操作であり、Redis のトランザクションは実際にバッチ操作のアトミック性を保証します。
複数のコマンドは同時実行でアトミックですか?
必ずしも必要というわけではありませんが、get と set を 1 つのコマンド操作に変更してください。Redis トランザクションを使用するか、Redis+Lua== を使用します。
5. Redis データと MySQL データベース間の一貫性を実現する方法
1. 遅延二重削除戦略:
データベースへの書き込みの前後に redis.del(key) 操作を実行し、適切なタイムアウトを設定します。具体的な手順は次のとおりです。
1) 最初にキャッシュを削除します。
2) 次にデータベースに書き込みます。
3) 500 ミリ秒間スリープします (特定の業務時間に応じて)
4) キャッシュを再度削除します。
では、この 500 ミリ秒はどのように決定され、どのくらいの時間スリープする必要があるのでしょうか?
プロジェクトの時間のかかるデータ読み取りビジネス ロジックを評価する必要があります。この目的は、読み取りリクエストが確実に終了し、書き込みリクエストによって読み取りリクエストによって発生したキャッシュされたダーティ データを削除できるようにすることです。もちろん、この戦略では、Redis とデータベースのマスター/スレーブ間の時間のかかる同期も考慮されています。データ書き込みの最終スリープ時間: データの読み取りビジネス ロジックにかかる時間を基に、数百ミリ秒を追加するだけです。例: 1 秒間スリープします。
2. キャッシュの有効期限を設定する
理論的には、キャッシュの有効期限を設定することは、最終的な整合性を確保するための解決策です。すべての書き込み操作はデータベースの影響を受けます。キャッシュの有効期限に達している限り、後続の読み取りリクエストは自然にデータベースから新しい値を読み取り、二重削除戦略 + キャッシュ タイムアウト設定と組み合わせてキャッシュをバックフィルします
。最悪のシナリオは、タイムアウト期間内に内部データに不整合が発生し、書き込みリクエストの時間が増加することです。
3. データベースへの書き込み後にキャッシュを再度正常に削除するにはどうすればよいですか?
上記の解決策には、データベース操作後のキャッシュの削除がさまざまな理由で失敗し、その際にデータの不整合が発生する可能性があるという欠点があります。ここでは、確実に再試行するためのソリューションを提供する必要があります。
1. 計画 1 の具体的な処理
(1) データベースのデータを更新する;
(2) さまざまな問題によりキャッシュの削除に失敗する;
(3) 削除する必要があるキーをメッセージ キューに送信する;
(4) メッセージを自分で消費して取得する削除する必要があるキー
( 5) 成功するまで削除操作を再試行し続けます。
ただし、このソリューションには、基幹業務コードへの大量の侵入を引き起こすという欠点があります。2 番目のオプションでは、サブスクリプション プログラムを開始してデータベースのバイナリログをサブスクライブし、操作する必要のあるデータを取得します。アプリケーションで、新しいプログラムを起動して、このサブスクリプション プログラムから情報を取得し、キャッシュを削除します。
2. オプション 2 の具体的なプロセス
(1) データベース データを更新します;
(2) データベースは操作情報を binlog ログに書き込みます; (
3) サブスクリプション プログラムは必要なデータとキーを抽出します;
(4) 新しいセクションを開始しますビジネス以外のコードの情報を取得する;
(5) キャッシュ操作の削除を試行し、削除が失敗したことを確認する;
(6) 情報をメッセージ キューに送信する;
(7) メッセージ キューからデータを再取得し、操作を再試行してください。
6. 一般的に使用される電流制限アルゴリズム
カウンター アルゴリズム: Redis の setnx および有効期限のメカニズムを使用して実装
リーキー バケット アルゴリズム: 通常、メッセージ キューを使用して実装され、システムはキュー内のリクエストを一定の速度で処理し、キューがいっぱいになるとリクエストの拒否を開始します。
トークンバケットアルゴリズム: カウンタアルゴリズムもリーキーバケットアルゴリズムも、突然の大規模な同時実行を解決することはできません. トークンバケットアルゴリズムは、事前に一定数のトークンをバケットに入れておき、その後バケットがバケットになるまで一定の速度でトークンをバケットに入れます。フル。すべてのリクエストが必要です。システムにアクセスするにはトークンを取得する必要があります。
7. Redis ハッシュスロットの概念
Redis クラスターは一貫したハッシュを使用しませんが、ハッシュ スロットの概念を導入します。Redis クラスターには 16384 のハッシュ スロットがあります。各キーは CRC16 によってチェックされ、モジュロ 16384 はどのスロットを配置するかを決定するために使用されます。クラスターの各ノードは、次の部分を担当します。ハッシュスロット。
8. Redis に適したシナリオは何ですか?
(1) セッション キャッシュ
Redis を使用するために最も一般的に使用されるシナリオの 1 つはセッション キャッシュです。Redis を使用して他のストレージ (Memcached など) 上でセッションをキャッシュする利点は、Redis が永続性を提供することです。一貫性を厳密に必要としないキャッシュを維持する場合、ユーザーのショッピング カート情報がすべて失われると、ほとんどの人は不満を抱くでしょう。
幸いなことに、Redis は長年にわたって改良されてきたため、Redis を適切に使用してセッション ドキュメントをキャッシュする方法を見つけるのは簡単です。有名な商用プラットフォーム Magento でも Redis プラグインが提供されています。
(2) フル ページ キャッシュ (FPC)
基本的なセッション トークンに加えて、Redis は非常にシンプルな FPC プラットフォームも提供します。一貫性の問題に戻りますが、Redis インスタンスが再起動されても、ユーザーはディスクの永続性によりページの読み込み速度が低下することはありません。これは、PHP ローカル FPC と同様に、大きな改善です。
再び Magento を例に挙げると、Magento は Redis をフルページ キャッシュ バックエンドとして使用するためのプラグインを提供します。
さらに、WordPress ユーザー向けに、Pantheon には非常に優れたプラグイン wp-redis があり、閲覧したページをできるだけ早く読み込むのに役立ちます。
(3)
メモリ ストレージ エンジンの分野におけるキュー Redis の大きな利点の 1 つは、リストおよびセット操作を提供することで、Redis を優れたメッセージ キュー プラットフォームとして使用できるようになります。Redis によってキューとして使用される操作は、リストに対するローカル プログラミング言語 (Python など) のプッシュ/ポップ操作に似ています。
Google で "Redis キュー" を検索すると、すぐに多数のオープン ソース プロジェクトが見つかります。これらのプロジェクトの目的は、Redis を使用して、さまざまなキューのニーズを満たす非常に優れたバックエンド ツールを作成することです。たとえば、Celery には Redis をブローカーとして使用するバックエンドがあり、ここから確認できます。
(4) ランキングリスト/カウンター
Redis は、メモリ内の数値を増減する操作を非常によく実装しています。Sets と Sorted Sets を使用すると、これらの操作を非常に簡単に実行できます。Redis が提供するのは、これら 2 つのデータ構造だけです。したがって、ソートされたセットから上位 10 人のユーザーを取得するには、それらを「user_scores」と呼びます。次のようにするだけです。 もちろん、これはユーザーのスコアに基づいて実行していることを前提としています
。ユーザーとユーザーのスコアを返したい場合は、次のように実行する必要があります:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games は良い例で、Ruby で実装されており、そのランキングは Redis を使用してデータを保存しています。ここを参照してください。
(5) パブリッシュ/サブスクライブ
最後は (もちろん重要ですが)、Redis のパブリッシュ/サブスクライブ機能です。パブリッシュ/サブスクライブには実際に多くの使用例があります。人々がこれをソーシャル ネットワーク接続で使用したり、パブリッシュ/サブスクライブ ベースのスクリプトのトリガーとして使用したり、Redis のパブリッシュ/サブスクライブ機能を使用してチャット システムを構築したりしているのを見てきました。(いいえ、これは本当です。ぜひチェックしてみてください。)
9. プロジェクトにおける Redis の適用
一般に、Redis にはプロジェクト内にいくつかのアプリケーションがあります。
キャッシュとして、ホット データをキャッシュしてデータベースとの対話を減らし、システム効率を向上します
分散ロック ソリューションとして、キャッシュの故障などの問題を解決します
メッセージ キューとして、Redis のパブリッシュおよびサブスクライブ機能を使用してメッセージをパブリッシュおよびサブスクライブします。
特定の使用シナリオをプロジェクトと組み合わせる必要があります。たとえば、プロジェクト内のどのシナリオがキャッシュや分散ロックなどとして Redis を使用するかなどです。