シリーズ記事の目次
- 2024 Java インタビュー (1) – 春の章
- 2024 Java インタビュー (2) – 春の章
- 2024 Java インタビュー (3) – 春の章
- 2024 Java インタビュー (4) – 春の章
- 2024 Java インタビュー – コレクション
- 2024 年の Java インタビュー – redis(1)
- 2024 年の Java インタビュー – redis(2)
記事ディレクトリ
- シリーズ記事の目次
- MVCC
- クラスター化インデックスと非クラスター化インデックス (クラスター化インデックスとセカンダリ インデックス)
- ハッシュインデックス
- ハッシュ インデックスの代わりに B+ ツリー インデックスを使用するのはなぜですか?
- InnoDB が uuid の代わりに整数の自動インクリメント主キーを使用することを推奨するのはなぜですか?
- インデックス障害のシナリオは何ですか?
- 取引の4大特徴
- トランザクション分離レベル
- デフォルトの分離レベル - RR
- RR および RC の使用シナリオ
- 同時トランザクションはどのような問題を引き起こしますか?
- どうやって解決すればいいでしょうか?
- InnoDB でトランザクションの手動送信を有効にする方法は?
MVCC
正式名称は、Multi-Version Concurrency Control、マルチバージョン同時実行制御です。読み取りおよび書き込み操作で競合がないように、データの複数のバージョンを維持することを指します。スナップショット読み取りは、MySQL が MVCC を実装するためのノンブロッキング読み取り機能を提供します。MVCC の特定の実装では、データベース レコード、アンドゥ ログ、および readView の 3 つの暗黙的フィールドにも依存する必要があります。
3 つの暗黙フィールド:

元に戻すログ:
ロールバック ログ。データのロールバックを容易にするために挿入、更新、削除中に生成されるログ。
挿入時に生成される元に戻すログは、ロールバック中にのみ必要となり、トランザクションがコミットされた直後に削除できます。
更新および削除の場合、生成される Undo ログはロールバック時だけでなく、スナップショットの読み取り時にも必要となるため、すぐには削除されません。
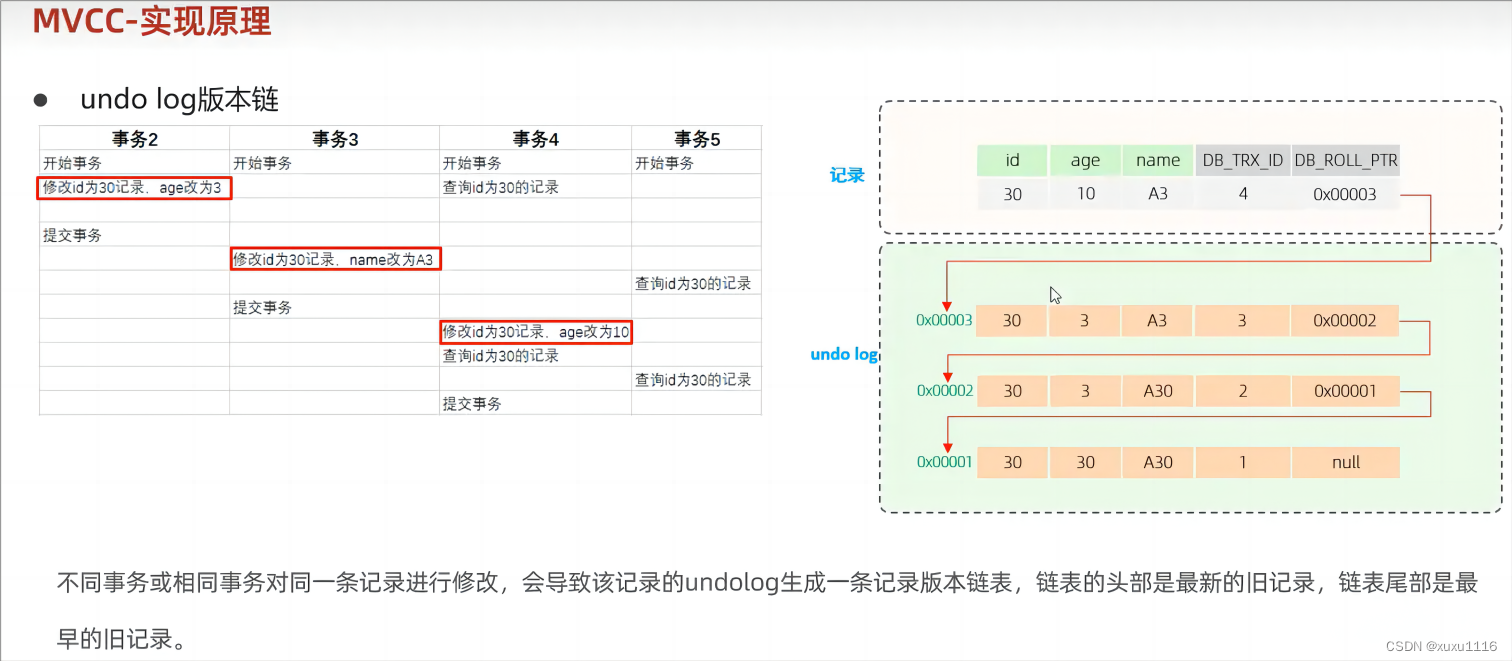
readView:
ReadView は、スナップショット読み取り SQL の実行時に MVCC がデータを抽出するための基盤であり、システムの現在アクティブな (コミットされていない) トランザクション ID を記録して維持します。
ReadView には 4 つのコア フィールドが含まれています。


分離レベルが異なると、ReadView を生成するタイミングも異なります。
READ COMMITTED : Readview は、トランザクションでスナップショット読み取りが実行されるたびに生成されます。
REPEATABLE READ : ReadView はトランザクションで初めてスナップショット読み取りが実行されるときにのみ生成され、その後 ReadView は再利用されます。
クラスター化インデックスと非クラスター化インデックス (クラスター化インデックスとセカンダリ インデックス)
クラスター化インデックス: データ ストレージとインデックスを組み合わせ、インデックス構造のリーフ ノードに行データ (主キー インデックス) を格納します。
非クラスター化インデックス: データとインデックスを別々に保存し、インデックス構造のリーフ ノードがデータの対応する場所を指します (補助インデックス)。
クラスター化インデックスのリーフ ノードはデータ ノードですが、非クラスター化インデックスのリーフ ノードはインデックス ノードのままですが、対応するデータ ブロックへのポインターを持ちます。
クラスター化インデックスの選択ルール:
- 主キーが存在する場合、主キー インデックスはクラスター化インデックスになります。
- 主キーが存在しない場合は、最初の一意 (UNIQUE) インデックスがクラスター化インデックスとして使用されます。
- テーブルに主キーまたは適切な一意のインデックスがない場合、InnoDB は ROWID を非表示のクラスター化インデックスとして自動的に生成します。
ハッシュインデックス
ハッシュ インデックスは、インデックス列の値を使用して値の hashCode を計算し、値が存在する行データの物理的な位置を hashCode の対応する位置に格納します。ハッシュ アルゴリズムが使用されるため、アクセスは速度は非常に速いですが、1 つの値は 1 つの hashCode にのみ対応し、ハッシュ分散方式であるため、ハッシュ インデックスは範囲検索とソート機能をサポートしていません。
ハッシュ インデックスの代わりに B+ ツリー インデックスを使用するのはなぜですか?
ハッシュ インデックスは、インデックス値のハッシュ値と物理ディスク アドレス間のマッピングを確立します。
(1) ハッシュの競合が多い場合、必ずしも B+ ツリーよりもパフォーマンスが向上するとは限りません。
(2) ハッシュ インデックスはレンジ クエリをサポートせず、ポイントツーポイント クエリのみをサポートしており、ハッシュ演算前のインデックス値とハッシュ演算後のハッシュ値の順序は必ずしも同じではありません。
(3) 一部のインデックスキーを使用してハッシュインデックスをクエリすることはできません。ハッシュインデックスのハッシュ値を計算する際、個別にハッシュ値を計算するのではなく、結合されたインデックスキーをマージしてからまとめてハッシュ値を計算します。 1 つまたは複数のインデックス キーをクエリする場合、ハッシュ インデックスは使用できません。
InnoDB が uuid の代わりに整数の自動インクリメント主キーを使用することを推奨するのはなぜですか?
(1) uuid はより多くのスペースを必要とします。uuid はランダムな文字列であり、より多くのスペースを占有し、整数ではありません。
(2) uuid のソートは整数ほど簡単ではありません。uuid は文字列であり、ノード内のインデックス値をソートする必要がありますが、明らかに整数ソートの方が簡単です。
(3) 整数自動インクリメント挿入により、頻繁なノード分割を回避できます。データを挿入するとき、自動増加する主キーは B+ ツリー構造にほとんど影響しません。増分であるため、後で追加するだけです。uuid はランダムであり、途中に挿入される場合があります。前のノードがいっぱいの場合は、ノード分割 (ページ分割)、ツリー構造の調整、その他のパフォーマンスを消費する大量の操作が発生します。
インデックス障害のシナリオは何ですか?
(1) 結合インデックスが左端の一致原則を満たさない場合、左端の優先順位を付けずに複数列のインデックスを作成するのと同じになり、結合クエリは無効になります (< または > の右側のインデックスが使用されている場合、これは無効となり、>= または < =通常の値に変更されます)
(2) クエリを実行する際、間違ったあいまいクエリを使用します(末尾あいまい一致のみの場合、インデックスは無効になりません。先頭あいまい一致の場合、インデックスは無効になります)。
(3) カラムに演算や関数を使用している場合、インデクスは無効になります。
(4) この列では型変換が使用されているため、インデックスも失敗します (たとえば、文字列型が引用符なしでクエリされている場合など)。
(5) is null を使用しない場合、インデックスは無効になります (現在のデータベース テーブルのデータ分布によっては固定されません)。テーブルにデータがある場合、またはデータが非常に少ない場合は、is null を使用してインデックスを使用します。インデックスを使用しない場合は、テーブル内のデータ量に基づいて決定します。量が多い場合は、グローバル スキャンを実行します)
(6) OR 接続: または の前の条件の列にインデックスがあり、後続の列にインデックスがない場合、関連するインデックスは使用されません。
取引の4大特徴
トランザクションの 4 つの主要な特性: 原子性、一貫性、分離性、耐久性
アトミック: トランザクションは最小の実行単位であり、分割は許可されません。トランザクションの原子性により、すべてのアクションが完了するか、何も実行されないかが保証されます。
一貫性: トランザクションの実行前後でデータの一貫性が保たれ、同じデータを読み取る複数のトランザクションの結果は同じになります。
分離: データベースに同時にアクセスする場合、ユーザーのトランザクションは他のトランザクションによって干渉されず、データベースは同時トランザクション間で独立します。
耐久性: トランザクションがコミットされた後。データベース内のデータに対する変更は永続的なものであり、データベースに障害が発生した場合でも影響はありません。
ビジネスはどのような保証に依存していますか:
-
原子性: アンドゥログ ログによって保証されます。アンドゥログ ログは、ロールバックが必要なログ情報を記録し、ロールバック中に実行された SQL を元に戻します。
-
一貫性: 他の 3 つの特性によって保証され、トランザクションの目的となります。
-
絶縁: MVCC によって保証
-
耐久性: redolog ログとメモリによって保証されており、mysql がデータを変更すると、メモリと redolog に操作が記録され、ダウンタイムが発生した場合には復元できます。
トランザクション分離レベル
Read uncommitted : 最も低い分離レベル。コミットされていないデータ変更の読み取りを許可します。これにより、ダーティ読み取り、ファントム読み取り、または反復不能読み取りが発生する可能性があります。
Read Committed : 同時トランザクションによってコミットされたデータの読み取りを許可します。これによりダーティ リードを防ぐことができますが、ファントム リードまたは反復不可能な読み取りが発生する可能性があります。
反復可能な読み取り: 独自のトランザクション自体によってデータが変更されない限り、同じフィールドの複数の読み取りの結果は一貫しています。これにより、ダーティ リード、反復不可能な読み取り、およびファントム リードを防ぐことができます。
シリアル化: ACID 分離レベルに完全に準拠した最高の分離レベル。すべてのトランザクションは 1 つずつ順番に実行されるため、トランザクション間の干渉の可能性はまったくありません。
| 分離レベル | 同時実行の問題 |
|---|---|
| コミットされていない読み取り | ダーティ読み取り、ファントム読み取り、または反復不可能な読み取りが発生する可能性があります |
| 送信済みを読む | ファントム読み取りまたは反復不可能な読み取りが発生する可能性があります |
| 反復可能な読み取り | ファントムリーディングが発生する可能性があります |
| シリアル化可能 | 干渉なし |
| 分離レベル | ダーティリード | 反復不可能な読み取り | 幻の読書 |
|---|---|---|---|
| コミットされていない読み取り | √ | √ | √ |
| コミットされた読み取り | × | √ | √ |
| 反復可能な読み取り | × | × | √ |
| シリアル化可能 | × | × | × |
1. ダーティ リード: ダーティ リードとは、トランザクションがデータにアクセスし、データを変更したが、その変更がデータベースにまだ送信されていないとき、この時点で別のトランザクションもデータにアクセスし、そのデータを使用することを意味します。
たとえば、Zhang San の給与は 5,000 で、トランザクション A では給与が 8,000 に変更されますが、トランザクション A はまだ送信されていません。同時に、トランザクション B は Zhang San の給与を読み取り、Zhang San の給与が 8,000 であることを読み取ります。その後、トランザクションAで例外が発生し、トランザクションはロールバックされました。張三さんの給料は5,000ドルに減額された。最後に、トランザクション B によって読み取られた Zhang San の給与 8,000 のデータはダーティ データであり、トランザクション B はダーティ リードを実行しました。
2. 反復不可能な読み取り: トランザクション内で同じデータを複数回読み取ることを指します。このトランザクションが終了する前に、別のトランザクションも同じデータにアクセスします。その後、最初のトランザクションの 2 回のデータ読み取りの間で、2 番目のトランザクションの変更により、最初のトランザクションで 2 回読み取られたデータが異なる可能性があります。このように、トランザクション内で 2 回読み取られるデータは異なるため、Non-Repeatable Read と呼ばれます。
例: トランザクション A では、Zhang San の給与が 5,000 であることが読み取られますが、操作は完了しておらず、トランザクションはまだ送信されていません。同時に、トランザクション B は Zhang San の給与を 8,000 に変更してトランザクションを送信しました。続いてトランザクション A で Zhang San の給与が再度読み取られ、この時点で給与は 8,000 になります。トランザクション内の 2 つの読み取りの結果に一貫性がなく、反復不可能な読み取りが発生します。
3. ファントムリード: トランザクションが独立して実行されない場合に発生する現象を指します。たとえば、最初のトランザクションでテーブル内のデータが変更され、この変更にはテーブル内のすべてのデータ行が含まれます。同時に、2 番目のトランザクションもこのテーブルのデータを変更し、この変更により新しいデータの行がテーブルに挿入されます。その後、最初のトランザクションを操作するユーザーは、あたかも幻覚が起こったかのように、テーブル内にまだ変更されていないデータ行が存在することに気づくでしょう。
例: 2 つの cmd ウィンドウがトランザクションを開き、最初のウィンドウで id=3 をクエリします。データはありません。このとき、id=3 が 2 番目のウィンドウに挿入され、id=3 が最初のウィンドウにも挿入されます。すでに存在していることを示していますが、id=3 をクエリするとまだデータがありません。
デフォルトの分離レベル - RR
デフォルトの分離レベル: 反復読み取り。
データがトランザクション自体によって変更されない限り、同じフィールドを複数回読み取った結果は一貫しています。
反復可能な読み取りによりファントム読み取りが発生する可能性があります。絶対的なセキュリティを確保したい場合は、分離レベルを SERIALIZABLE に設定することのみ可能です。この方法では、すべてのトランザクションは順次にのみ実行できます。当然、同時実行による影響はありませんが、パフォーマンスが大幅に低下します。
2 番目の方法は、MVCC を使用して、スナップショットのファントム読み取り (単純な選択など) の問題を解決することで、読み取られるのは最新のデータではありません。フィールドをバージョンとして管理し、一度に 1 人のユーザーだけがバージョンを更新できるようにします。
select id from table_xx where id = ? and version = V
update id from table_xx where id = ? and version = V+1
3 番目の方法は、最新のデータを読み取る必要がある場合、GapLock+Next-KeyLock を使用して、現在のファントム読み取りの問題を解決できます。
select id from table_xx where id > 100 for update;
select id from table_xx where id > 100 lock in share mode;
RR および RC の使用シナリオ
RC (読み取りコミット) と RR (反復読み取り) の 2 つのトランザクション分離レベルは、マルチバージョン同時実行制御 (MVCC) に基づいて実装されています。
| ラジコン | RR | |
|---|---|---|
| 成し遂げる | 複数のクエリ ステートメントは複数の異なる ReadView を作成します | ReadView の 1 つのバージョンのみが必要です |
| 粒度 | ステートメントレベルの読み取り一貫性 | トランザクションレベルの読み取り一貫性 |
| 正確さ | 各ステートメント実行時点のデータ | 最初のステートメントの実行時点のデータ |
同時トランザクションはどのような問題を引き起こしますか?
ダーティ リード: トランザクションがデータにアクセスしてデータを変更するが、その変更がまだデータベースにコミットされていない場合、別のトランザクションもデータにアクセスし、そのデータを使用します。このデータは送信されていないため、トランザクションによって読み取られるデータは「ダーティ データ」です。
変更の損失: 1 つのトランザクションがデータを変更すると、別のトランザクションもデータを読み取ります。最初のトランザクションがデータを変更すると、2 番目のトランザクションもそれを変更するため、最初のトランザクションの変更結果が失われるため、この名前が付けられます。失われた変更
Non-repeatable read : トランザクション内で同じトランザクションを複数回読み取ることを指します。このトランザクションが終了する前に、別のトランザクションもデータにアクセスします。そして、最初のトランザクションによる 2 回のデータ読み取りの間に、2 番目のトランザクションの変更により、1 回のトランザクションで 2 回読み取られるデータは同じではなくなるため、これをノンリピータブルリードと呼びます。
ファントム読み取り: ファントム読み取りは、反復不可能な読み取りに似ています。これは、1 つのトランザクション (T1) が数行のデータを読み取り、別の同時トランザクション (T2) がデータを挿入したときに発生します。後続のクエリでは、最初のトランザクション (T1) は、あたかもファントム ボリュームが発生したかのように、元々存在しなかったレコードをさらにいくつか検出するため、ファントム読み取りと呼ばれます。
どうやって解決すればいいでしょうか?
同時トランザクションは、ダーティ読み取り、反復不可能な読み取り、ファントム読み取りなどの問題を引き起こす可能性があります。これらの問題は、実際にはデータベースの読み取り一貫性の問題であり、特定のトランザクション分離メカニズムを提供するデータベースによって解決する必要があります。解決策は次のとおりです:
ロック: 他のトランザクションがデータを変更できないように、データを読み取る前にデータをロックします。たとえば、読み取り時に共有ロックを追加すると、他のものによる対応するデータの変更が防止され、書き込み時に排他的ロックを追加すると、他のものによる読み取りおよび書き込み操作が禁止されますが、このアプローチではパフォーマンスが低下します。パフォーマンスの考慮事項に基づいて、MySQL はマルチバージョン データベースとも呼ばれるデータ マルチバージョン同時実行制御 (MVCC) を提供します。ロックを追加することなく、データ要求時点の一貫したデータ スナップショット (スナップショット) が特定のメカニズムを通じて生成されます。このスナップショットは、特定のレベル (ステートメント レベルまたはトランザクション レベル) での一貫した読み取りを提供するために使用されます。ユーザーの観点からは、データベースが同じデータの複数のバージョンを提供できるように見えます。
ノンリピータブルリードとファントムリードの違いは次のとおりです。
非反復読み取りの焦点は変更です。たとえば、レコードを複数回読み取って特定の列の値が変更されていることがわかります。ファントム読み取りの焦点は追加または削除です。たとえば、レコードを複数回読み取ると、次のことがわかります。レコードの数が増加または減少しました。
InnoDB でトランザクションの手動送信を有効にする方法は?
InnoDB はデフォルトでトランザクションを自動的にコミットします。すべての SQL 操作 (非選択操作) は自動的にトランザクションを送信します。トランザクションを手動で有効にしたい場合は、set autocommit=0 を設定して自動トランザクション送信を無効にする必要があります。これは有効にすることと同じです。トランザクションの手動送信。
InnoDB で Autocommit=0 が設定されており、情報を追加した後に手動でコミット操作が行われていないのですが、この情報は見つかるでしょうか?
autocommit=0 は、自動トランザクション送信が禁止されていることを意味し、追加操作後に手動送信は実行されません。デフォルトでは、接続されている他のクライアントはこの新しいデータをクエリできません。