分散スケジューリング エラスティックジョブ
1。概要
1.1 タスクのスケジューリングとは何ですか?
次のビジネス シナリオに対するソリューションを考えることができます。
- e コマース プラットフォームは、毎日午前 10 時、午後 3 時、午後 8 時に一連のクーポンを発行する必要があります。
- 特定の銀行システムでは、クレジット カードの返済期日の 3 日前に SMS リマインダーを送信する必要があります。
- 金融システムは毎日午前0時10分に前日の財務データを決済し、統計を集計する必要があります。
上記のシナリオは、タスク スケジューリングによって解決する必要がある問題です。
タスクのスケジュール設定は、特定のタスクを自動的に完了し、合意された特定の時間にタスクを実行するプロセスです。
Spring で提供されているスケジュールされたタスクのアノテーション @Scheduled をよく使用し、このアノテーションをビジネス クラスのメソッドに貼り付けます。
@Scheduled(cron = "0/20 * * * * ? ")
public void doWork(){
//doSomething
}
次に @EnableScheduling アノテーションをスタートアップ クラスに貼り付けます。
1.2 分散スケジューリングが必要な理由
Spring が提供するアノテーションでタスクのスケジューリング機能が完成するような気がしており、問題は完全に解決しているように思えますが、なぜまだ配布する必要があるのでしょうか。
主な理由は次のとおりです。
1. 単一マシンの処理制限: 当初は 1 分間に 10,000 件の注文を処理する必要がありましたが、現在は 1 分間に 100,000 件の注文を処理する必要があり、以前は統計に 1 時間かかっていましたが、現在は統計に 10 分かかります。ビジネス側がそれを計算します。マルチスレッドや単一マシンのマルチプロセス処理もできると言えるかもしれません。確かにマルチスレッドで並列処理を行うと単位時間あたりの処理効率は向上しますが、結局のところ1台のマシンの能力には限界があり(主にCPU、メモリ、ディスク)、1台のマシンでは処理しきれない状況が必ず発生します。
2. 高可用性: スタンドアロン版の固定タスクスケジューリングは 1 台のマシンでのみ動作するため、プログラムやシステムに異常が発生すると機能が利用できなくなります。スタンドアロンプログラムでは安定して実装できますが、プログラムに起因しない障害が発生する可能性が常にあり、これはシステムのコア機能としては許容できません。
3. 繰り返し実行を防止する: スタンドアロン モードでは、スケジュールされたタスクは問題ありません。しかし、複数のサービスをデプロイし、各サービスにスケジュールされたタスクがある場合、同時に合理的な制御がないと、スケジュールされたタスクは 1 つだけ実行され、このときスケジュールされた実行の結果は混乱や間違いが発生する可能性があります。
現時点では、分散タスク スケジューリングを実現する必要があります。
1.3 エラスティックジョブの紹介
Elastic-Job は、Dangdang によってオープンソース化された分散スケジューリング ソリューションです。Elastic-job-Lite と Elastic-Job-Cloud という 2 つの独立したサブプロジェクトで構成されています。Elastic-Job を使用すると、分散タスク スケジューリングを迅速に実装できます。
Elastic-Job アドレス: https://shardingsphere.apache.org/elasticjob/
機能リスト:
-
分散スケジューリング調整
- 分散環境では、指定されたスケジューリング ポリシーに従ってタスクを実行でき、同じタスクの複数のインスタンスが繰り返し実行されることを回避できます。
-
豊富なスケジュール戦略
- 成熟したスケジュールされたタスク ジョブ フレームワークの Quartz cron 式に基づいて、スケジュールされたタスクを実行します。
-
柔軟な伸縮
- インスタンスがクラスターに追加されるときは、タスクを実行するためにそのインスタンスを選択できる必要があります。クラスター内のインスタンスが削減されるときは、そのインスタンスが実行するタスクを他のインスタンスに転送して実行できます。
-
フェイルオーバー
- インスタンスがタスクの実行に失敗すると、タスクは別のインスタンスに転送されて実行されます。
-
実行ミスタスクの再トリガー
- 何らかの理由でジョブが実行されなかった場合、誤って実行されたジョブは自動的に記録され、次のジョブが完了した後に自動的にトリガーされます。
-
並列スケジューリングのサポート
- タスクのシャーディングをサポートします。タスクのシャーディングとは、タスクを複数の小さなタスクに分割し、複数のインスタンスで同時に実行することを指します。
-
ジョブシャーディングの一貫性
- タスクが複数の部分に分割されると、分散環境では同じ部分の実行インスタンスが 1 つだけ存在することが保証されます。
-
ジョブのライフサイクル操作のサポート
-
タスクは動的に開始および停止できます。
-
豊富な職種
-
シンプル、DataFlow、およびスクリプトの 3 つのジョブ タイプをサポートします。
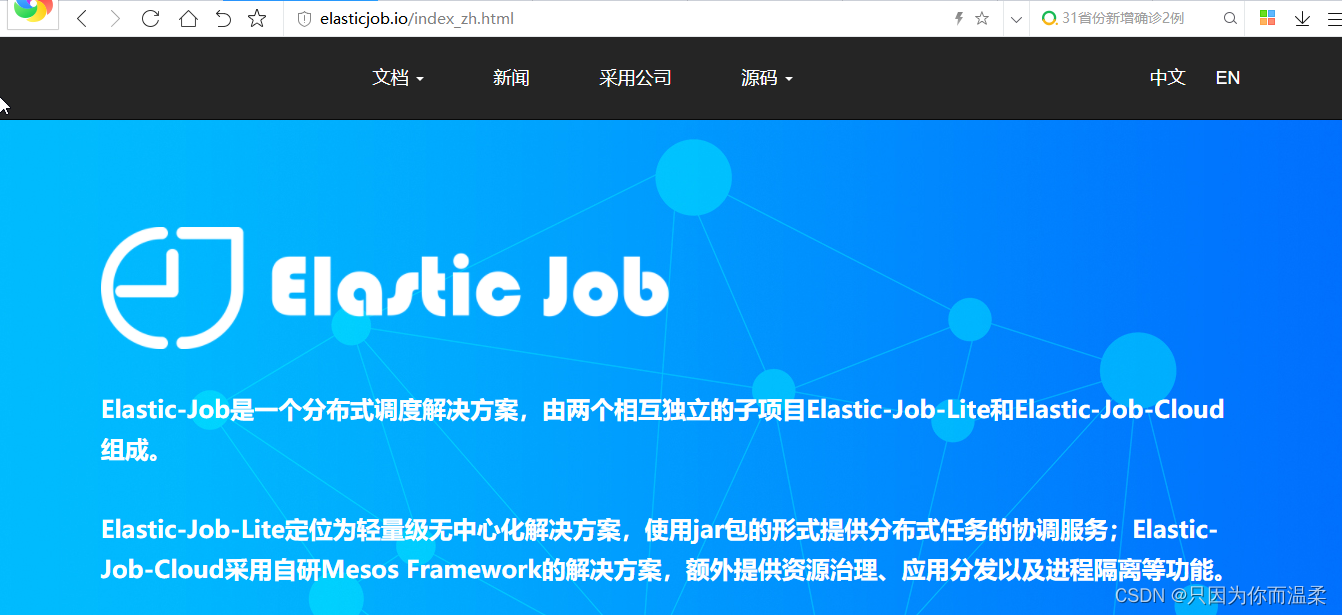
システム構成図
-
2.エラスティックジョブのクイックスタート
2.1 環境設定
2.1.1 バージョン 02. 要件
-
JDK にはバージョン 1.7 以降が必要です
-
Maven にはバージョン 3.0.4 以降が必要です
-
Zookeeper にはバージョン 3.4.6 以降が必要です
2.1.2 Zookeeper のインストールと操作
1. 解压zookeeper-3.4.11.tar.gz, 进入conf目录, 复制zoo_sample.cfg文件, 命名为:zoo.cfg
2. 进入bin目录, 运行zkServer.cmd就可以了.
3. 解压ZooInspector.zip, 运行jar文件
Zookeeper クライアント視覚化ツール
2.1.3 Maven プロジェクトの作成
次の依存関係を追加します
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
2.2 コードの実装
2.2.1 タスククラス
package com.xiaoge;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import java.util.Date;
public class MyElasticJob implements SimpleJob {
public void execute(ShardingContext shardingContext) {
System.out.println("定时任务开始====>" + new Date());
}
}
2.2.2 構成クラス
package com.xiaoge;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
public class JobDemo {
public static void main(String[] args) {
// JobScheduler(注册中心对象, 任务配置对象)
new JobScheduler(createRegistryCenter(), createJobConfiguration()).init();
}
// 注册中心
private static CoordinatorRegistryCenter createRegistryCenter() {
// 配置zk地址,调度任务的组名
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration("localhost:2181", "elastic-job-demo");
// 设置节点超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
// ZookeeperRegistryCenter("zookeeper地址", "项目名")
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
regCenter.init();
return regCenter;
}
// 定时任务配置
private static LiteJobConfiguration createJobConfiguration() {
// 定义作业核⼼配置 newBuilder("任务名称", "cron表达式", "分片数量")
JobCoreConfiguration simpleCoreConfig =
JobCoreConfiguration.newBuilder("myElasticJob", "0/10 * * * * ?", 1).build();
// 定义SIMPLE类型配置 MyElasticJob.class.getCanonicalName()--->获取这个类的权限定类名
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MyElasticJob.class.getCanonicalName());
// 定义Lite作业根配置 (overwrite(true) 表示zookeeper里面的配置可以覆盖, 如果为false, 设置了一次cron表达式, 第二次修改表达式是不生效的)
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).overwrite(true).build();
return simpleJobRootConfig;
}
}
2.2.3 テスト
-
単一プログラムを実行して、cron 式の内容に従ってタスクがスケジュールされているかどうかを確認します。
-
複数のプログラムを実行して、タスク スケジュールのインスタンスが 1 つだけになるかどうかを確認します。
-
複数のプログラムを実行した後、タスクをスケジュールしているプロセスをシャットダウンし、他のプロセスが引き続きタスクをスケジュールできるかどうかを確認します。
3.SpringBoot は Elastic-Job を統合します
3.1 Maven の依存関係を追加する
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xiaoge</groupId>
<artifactId>elastic-job-boot</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-spring</artifactId>
<version>2.1.5</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>
3.2 関連する構成
構成センターのアドレスは固定されていないため、このアドレス情報を構成ファイルで構成する必要があるため、構成ファイル application.yml に次の構成を追加します。
elasticjob:
url: localhost:2181
group-name: elastic-job-boot
zk 登録センター構成クラス:
@Bean
public CoordinatorRegistryCenter registryCenter(@Value("${elasticjob.url}") String zookeeperUrl, @Value("${elasticjob.group-name}") String groupName) {
// 配置zk地址,调度任务的组名
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(zookeeperUrl, groupName);
// 设置节点超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
// ZookeeperRegistryCenter("zookeeper地址", "项目名")
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
regCenter.init();
return regCenter;
}
タスクスケジューリング構成クラス:
/**
* todo 注意这个方法不能交给 spring 管理, 你要让它是个公共的方法,
* 传递不同的jobName(任务名称), cron(cron表达式), shardingTotalCount(分片数量) 生成不同的LiteJobConfiguration, 因为环境不同任务配置不同.
* 也有可能别的任务需要这个方法创建
* @return
*/
public LiteJobConfiguration createJobConfiguration(Class<?> clazz, String cron, Integer shardingTotalCount, String shardingParam) {
// 定义作业核⼼配置 newBuilder("任务名称", "cron表达式", "分片数量")
JobCoreConfiguration.Builder jobBuilder = JobCoreConfiguration.newBuilder(clazz.getSimpleName(), cron, shardingTotalCount);
if (!StringUtils.isEmpty(shardingParam)) {
// 分片参数
jobBuilder = jobBuilder.shardingItemParameters(shardingParam);
}
// SimpleJob配置
// 定义SIMPLE类型配置 MyElasticJob.class.getCanonicalName()--->获取这个类的权限定类名
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobBuilder.build(), clazz.getCanonicalName());
// 定义Lite作业根配置 (overwrite(true) 表示zookeeper里面的配置可以覆盖, 如果为false, 设置了一次cron表达式, 第二次修改表达式是不生效的)
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build();
return simpleJobRootConfig;
}
4. ケースの要件
要件: データベースにはいくつかのデータ列があり、これらのデータをバックアップする必要があります。バックアップが完了すると、データのステータスが変更され、バックアップ済みとしてマークされます。
4.1 初期化データ
elastic-job-demo.sql データをデータベースにインポートする
4.2 Druid&MyBatisの統合
4.2.1 依存関係の追加
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
4.2.2 設定の追加
spring:
datasource:
url: jdbc:mysql://localhost:3306/elastic-job-demo?serverTimezone=GMT%2B8
driverClassName: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
username: root
password: root
4.2.3 エンティティクラスの追加
package com.xiaoge.domain;
import lombok.Data;
@Data
public class FileCustom {
//唯⼀标识
private Long id;
//⽂件名
private String name;
//⽂件类型
private String type;
//⽂件内容
private String content;
//是否已备份
private Boolean backedUp = false;
public FileCustom() {
}
public FileCustom(Long id, String name, String type, String content) {
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
4.2.4 Mapper処理クラスの追加
package com.xiaoge.mapper;
import com.xiaoge.domain.FileCustom;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import java.util.List;
@Mapper
public interface FileCustomMapper {
@Select("select * from t_file_custom where backedUp = 0")
List<FileCustom> selectAll();
@Update("update t_file_custom set backedUp = #{state} where id = #{id}")
int changeState(@Param("id") Long id, @Param("state") int state);
}
4.3 ビジネス機能の実装
4.3.1 タスククラスの追加
package com.xiaoge.service;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.xiaoge.domain.FileCustom;
import com.xiaoge.mapper.FileCustomMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Slf4j
@Component
public class FileCustomElasticJob implements SimpleJob {
@Autowired
private FileCustomMapper fileCustomMapper;
@Override
public void execute(ShardingContext shardingContext) {
doWork();
}
private void doWork(){
List<FileCustom> fileList = fileCustomMapper.selectAll();
System.out.println("需要备份⽂件个数:"+fileList.size());
for(FileCustom fileCustom:fileList){
backUpFile(fileCustom);
}
}
private void backUpFile(FileCustom fileCustom){
try {
//模拟备份动作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("执⾏⽂件备份====>"+fileCustom);
fileCustomMapper.changeState(fileCustom.getId(),1);
}
}
4.3.2 タスクのスケジュール設定の追加
このBeanを構成クラスに追加します
/**
* todo 注意一个ElasticJob里面不管有多少实例, 只会有一个被调度, 那就是zookeeper选出来的leader
* @param myElasticJob
* @param regCenter
* @return
*/
@Bean(initMethod = "init")
public SpringJobScheduler initSpringScheduler(ElasticJob myElasticJob, CoordinatorRegistryCenter regCenter) {
LiteJobConfiguration simpleJobRootConfig = createJobConfiguration(myElasticJob.getClass(), "0/10 * * * * ?", 1);
return new SpringJobScheduler(myElasticJob, regCenter, simpleJobRootConfig);
}
4.4 テストと質問
高可用性を実現するために、このプロジェクトでクラスター操作を実行し、1 台のマシンがハングアップしても、もう 1 台のマシンが引き続き動作できるようにします。ただし、クラスターの場合、スケジュール タスクは 1 台のマシンでのみ実行されます。単一マシン タスクのスケジューリングは時間がかかり、リソースを消費します。このマシンの消費量は依然として比較的大きいですが、現時点では他のマシンはアイドル状態です。クラスタ内の他のマシンを適切に使用し、タスクをスムーズに実行する方法? より速く? このとき、Elastic-Jobはタスクのスケジューリングとシャーディングの機能を提供します。
5. シャーディングの概念
ジョブ シャーディングとは、タスクの分散実行を指します。タスクを複数の独立したタスク アイテムに分割し、1 つまたは複数の分散アイテムを分散アプリケーション インスタンスによって実行する必要があります。
たとえば、Elastic-Job Quick Start でのファイル バックアップの場合、2 つのサーバーがあり、それぞれがアプリケーション インスタンスを実行します。ジョブを迅速に実行するために、タスクを 4 つのスライスに分割し、各アプリケーション インスタンスが 2 つのスライスを実行することができます。ジョブ トラバーサル データ ロジックは次のようになります。インスタンス 1 はバックアップを実行するためにテキストおよびイメージ タイプのファイルを検索し、インスタンス 2 はバックアップを実行するためにラジオおよびビデオ タイプのファイルを検索します。サーバー容量の拡張によりアプリケーション インスタンスの数が 4 に増加した場合、ジョブ トラバーサル データのロジックは次のようになります。4 つのインスタンスがそれぞれテキスト、イメージ、ラジオ、およびビデオ タイプのファイルを処理します。
たとえば、Elastic-Job Quick Start でのファイル バックアップの場合、2 つのサーバーがあり、それぞれがアプリケーション インスタンスを実行します。ジョブを迅速に実行するために、タスクを 4 つのスライスに分割し、各アプリケーション インスタンスが 2 つのスライスを実行することができます。ジョブ トラバーサル データ ロジックは次のようになります。インスタンス 1 はバックアップを実行するためにテキストおよびイメージ タイプのファイルを検索し、インスタンス 2 はバックアップを実行するためにラジオおよびビデオ タイプのファイルを検索します。サーバー容量の拡張によりアプリケーション インスタンスの数が 4 に増加した場合、ジョブ トラバーサル データのロジックは次のようになります。4 つのインスタンスがそれぞれテキスト、イメージ、ラジオ、およびビデオ タイプのファイルを処理します。
シャーディング項目をビジネス処理から切り離す
Elastic-Job はデータ処理機能を直接提供するものではなく、フレームワークは実行中の各ジョブ サーバーにシャード アイテムを割り当てるだけであり、シャード アイテムと実データの対応付けは開発者自身で行う必要があります。
資源を最大限に活用
シャード アイテムをサーバーのデータより大きく、できればサーバーの倍数に設定すると、ジョブは分散リソースを適切に使用し、シャード アイテムを動的に割り当てます。
例: 3 台のサーバーが 10 個のシャードに分割されている場合、シャーディング項目の結果はサーバー A=0,1,2、サーバー B=3,4,5、サーバー C=6,7,8,9 になります。サーバー C がクラッシュした場合の場合、シャード アイテムの割り当て結果はサーバー A=0,1,2,3,4、サーバー B=5,6,7,8,9 になります。シャード アイテムを失うことなく、既存のシャード アイテムを最大限に活用します。改善するリソーススループット。
6. ケースをタスクのシャーディングに変換する
6.1 構成クラスの変更
シャードの数とシャードパラメータをタスク構成クラスに追加します。
@Bean(initMethod = "init")
public SpringJobScheduler initFileCustomElasticJob(FileCustomElasticJob
fileCustomElasticJob){
SpringJobScheduler springJobScheduler = new SpringJobScheduler(
fileCustomElasticJob,
registryCenter,
createJobConfiguration(FileCustomElasticJob.class,"0 0/1 * * *
?",4,"0=text,1=image,2=radio,3=vedio"));
return springJobScheduler;
}
6.2 ジョブシャーディングロジックの追加
package com.xiaoge.service;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.xiaoge.domain.FileCustom;
import com.xiaoge.mapper.FileCustomMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Slf4j
@Component
public class FileCustomElasticJob implements SimpleJob {
@Autowired
private FileCustomMapper fileCustomMapper;
@Override
public void execute(ShardingContext shardingContext) {
long threadId = Thread.currentThread().getId();
log.info("线程ID: {}, 任务的名称: {}, 任务参数: {}, 分片个数: {}, 分片索引号: {}, 分片参数: {}",
threadId,
shardingContext.getJobName(),
shardingContext.getJobParameter(),
shardingContext.getShardingTotalCount(),
shardingContext.getShardingItem(),
shardingContext.getShardingParameter()
);
doWork(shardingContext.getShardingParameter());
}
private void doWork(String shardingParameter) {
List<FileCustom> fileList = fileCustomMapper.selectFileCustomByType(shardingParameter);
log.info("需要备份⽂件个数{}: {}", shardingParameter, fileList.size());
for (FileCustom fileCustom : fileList) {
backUpFile(fileCustom);
}
}
private void backUpFile(FileCustom fileCustom) {
try {
//模拟备份动作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("执⾏⽂件备份====>" + fileCustom);
fileCustomMapper.changeState(fileCustom.getId(), 1);
}
}
6.3 マッパークラスの変更
package com.xiaoge.mapper;
import com.xiaoge.domain.FileCustom;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import java.util.List;
@Mapper
public interface FileCustomMapper {
@Select("select * from t_file_custom where backedUp = 0")
List<FileCustom> selectAll();
@Select("select * from t_file_custom where backedUp = 0 and type = #{type}")
List<FileCustom> selectFileCustomByType(@Param("type") String type);
@Update("update t_file_custom set backedUp = #{state} where id = #{id}")
int changeState(@Param("id") Long id, @Param("state") int state);
}
6.4 テスト
-
マシンが 1 台しかない場合、タスクのシャーディングはどのように実行されますか?
-
複数のマシンがある場合、タスクのシャーディングはどのように実行されますか?
7.データフロー型スケジューリングタスク
Dataflow タイプのスケジュールされたタスクは、Dataflowjob インターフェイスを実装する必要があります。このインターフェイスは、データのフェッチ (fetchData) と処理 (processData) に使用されるカバレッジ用の 2 つのメソッドを提供します。この例の変更を続けます。
Dataflow タイプのスケジュールされたタスクは、Dataflowjob インターフェイスを実装する必要があります。このインターフェイスは、データのフェッチ (fetchData) と処理 (processData) に使用されるカバレッジ用の 2 つのメソッドを提供します。この例の変更を続けます。
7.1 タスククラス
package com.xiaoge.service;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.xiaoge.domain.FileCustom;
import com.xiaoge.mapper.FileCustomMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* TODO 处理大数据量的时候用那个DataFlow这种方式
*
* @author <a href="mailto:[email protected]">Zhang Xiao</a>
* @since
*/
@Component
public class FileDataFlowJob implements DataflowJob<FileCustom> {
@Autowired
private FileCustomMapper fileCustomMapper;
// 抓取数据
@Override
public List<FileCustom> fetchData(ShardingContext shardingContext) {
System.out.println("开始抓取数据...........");
return fileCustomMapper.selectLimit(shardingContext.getShardingParameter(), 2);
}
// 处理数据
@Override
public void processData(ShardingContext shardingContext, List<FileCustom> fileCustomList) {
fileCustomList.forEach(fileCustom -> {
backUpFile(fileCustom);
});
}
private void backUpFile(FileCustom fileCustom) {
System.out.println("备份的方法名: " + fileCustom.getName() + "备份的类型: " + fileCustom.getType());
try {
//模拟备份动作
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("执⾏⽂件备份====>" + fileCustom);
fileCustomMapper.changeState(fileCustom.getId(), 1);
}
}
7.2 構成クラス
package com.xiaoge.config;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.JobTypeConfiguration;
import com.dangdang.ddframe.job.config.dataflow.DataflowJobConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.event.JobEventConfiguration;
import com.dangdang.ddframe.job.event.rdb.JobEventRdbConfiguration;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.lite.spring.api.SpringJobScheduler;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter;
import com.xiaoge.service.FileCustomElasticJob;
import com.xiaoge.service.FileDataFlowJob;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
/**
* TODO
*
* @author <a href="mailto:[email protected]">Zhang Xiao</a>
* @since
*/
@Configuration
public class ElasticJobConfig {
/**
* todo 注意一个ElasticJob里面不管有多少实例, 只会有一个被调度, 那就是zookeeper选出来的leader
* @param myElasticJob
* @param regCenter
* @return
*/
// @Bean(initMethod = "init")
// public SpringJobScheduler testScheduler(ElasticJob myElasticJob, CoordinatorRegistryCenter regCenter) {
// LiteJobConfiguration simpleJobRootConfig = createJobConfiguration(myElasticJob.getClass(), "0/10 * * * * ?", 1);
// return new SpringJobScheduler(myElasticJob, regCenter, simpleJobRootConfig);
// }
// @Bean(initMethod = "init")
// public SpringJobScheduler fileScheduler(FileCustomElasticJob fileCustomElasticJob, CoordinatorRegistryCenter regCenter){
// SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileCustomElasticJob,regCenter,createJobConfiguration(fileCustomElasticJob.getClass(),"0 0/1 * * * ?",4, "0=text,1=image,2=radio,3=vedio", false));
// return springJobScheduler;
// }
@Bean(initMethod = "init")
public SpringJobScheduler fileDataFlowScheduler(FileDataFlowJob fileDataFlowJob, CoordinatorRegistryCenter regCenter){
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileDataFlowJob,regCenter,createJobConfiguration(fileDataFlowJob.getClass(),"0 0/1 * * * ?",4, "0=text,1=image,2=radio,3=vedio", true));
return springJobScheduler;
}
// @Bean(initMethod = "init")
// public SpringJobScheduler test1Scheduler(ElasticJob myElasticJob1, CoordinDataRevisionatorRegistryCenter regCenter) {
// LiteJobConfiguration simpleJobRootConfig = createJobConfiguration(myElasticJob1.getClass(), "0/3 * * * * ?", 1);
// return new SpringJobScheduler(myElasticJob1, regCenter, simpleJobRootConfig);
// }
@Bean
public CoordinatorRegistryCenter registryCenter(@Value("${elasticjob.url}") String zookeeperUrl, @Value("${elasticjob.group-name}") String groupName) {
// 配置zk地址,调度任务的组名
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(zookeeperUrl, groupName);
// 设置节点超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
// ZookeeperRegistryCenter("zookeeper地址", "项目名")
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
regCenter.init();
return regCenter;
}
/**
* todo 注意这个方法不能交给 spring 管理, 你要让它是个公共的方法,
* 传递不同的jobName(任务名称), cron(cron表达式), shardingTotalCount(分片数量) 生成不同的LiteJobConfiguration, 因为环境不同任务配置不同.
* 也有可能别的任务需要这个方法创建
* @return
*/
public LiteJobConfiguration createJobConfiguration(Class<?> clazz, String cron, Integer shardingTotalCount, String shardingParam, boolean isDataFlow) {
// 定义作业核⼼配置 newBuilder("任务名称", "cron表达式", "分片数量")
JobCoreConfiguration.Builder jobBuilder = JobCoreConfiguration.newBuilder(clazz.getSimpleName(), cron, shardingTotalCount);
if (!StringUtils.isEmpty(shardingParam)) {
// 分片参数
jobBuilder = jobBuilder.shardingItemParameters(shardingParam);
}
JobTypeConfiguration jobConfiguration;
if (isDataFlow) {
// DataflowJob配置
jobConfiguration = new DataflowJobConfiguration(jobBuilder.build(), clazz.getCanonicalName(), true);
} else {
// SimpleJob配置
// 定义SIMPLE类型配置 MyElasticJob.class.getCanonicalName()--->获取这个类的权限定类名
jobConfiguration = new SimpleJobConfiguration(jobBuilder.build(), clazz.getCanonicalName());
}
// 定义Lite作业根配置 (overwrite(true) 表示zookeeper里面的配置可以覆盖, 如果为false, 设置了一次cron表达式, 第二次修改表达式是不生效的)
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(jobConfiguration).overwrite(true).build();
return simpleJobRootConfig;
}
}
7.3 テスト
8. 運営・保守管理
8.1 イベント追跡
Elastic-Job-Lite は、設定で JobEventConfiguration を提供し、データベース設定をサポートし、2 つのテーブル JOB_EXECUTION_LOG と JOB_STATUS_TRACE_LOG およびショートカット ジョブに関する情報を取得するためのさまざまなインデックスをデータベースに自動的に作成します。
8.1.1 Elastic-Job 構成クラスの変更
DataSource を ElasticJobConfig 構成クラスに挿入する
@Configuration
public class ElasticJobConfig {
@Autowired
private DataSource dataSource;
......
}
タスク構成にイベント追跡構成を追加する
@Bean(initMethod = "init")
public SpringJobScheduler fileDataFlowScheduler(FileDataFlowJob fileDataFlowJob, CoordinatorRegistryCenter regCenter){
// 日志监控, 它会自动在数据库生成两张表job_execution_log/job_status_trace_log
// 配置会在任务执行的时间将任务执行的情况存储到数据源中
JobEventConfiguration jobEventConfiguration = new JobEventRdbConfiguration(dataSource);
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileDataFlowJob,regCenter,createJobConfiguration(fileDataFlowJob.getClass(),"0 0/1 * * * ?",4, "0=text,1=image,2=radio,3=vedio", true), jobEventConfiguration);
return springJobScheduler;
}
8.1.2 ログ情報テーブル
起動後、次の 2 つのテーブルが elastic-job-demo データベースに追加されていることがわかります。
ジョブ実行ログ
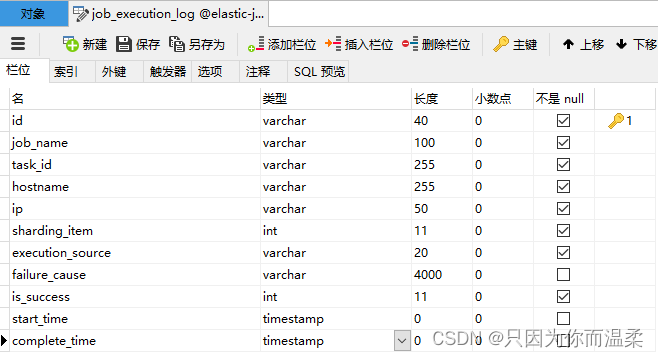
各ジョブの実行履歴の記録は、次の 2 つの手順に分かれています。
1. ジョブの実行開始時にデータベースにデータを挿入します。
2. ジョブの実行が完了したら、データベースのデータを更新し、is_success、complete_time、failure_cause (タスクの実行が失敗した場合) を更新します。
ジョブステータストレースログ
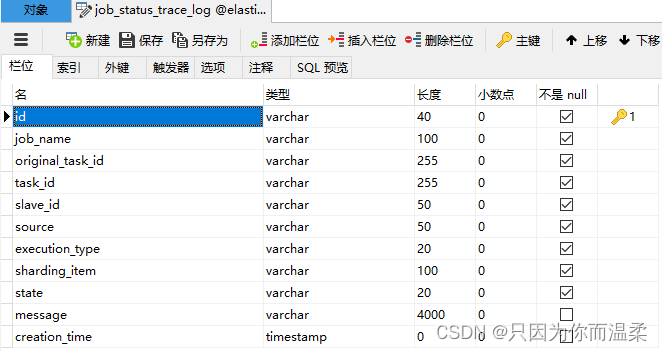
ジョブ ステータス変更トレース テーブルを記録すると、各ジョブ実行の task_id を通じてジョブ ステータス変更のライフ トラックと実行トラックをクエリできます。
8.2 運用保守コンソール
elastic-job-lite-console コンソールは elastic-job で提供されます
デザインのコンセプト
1. このコンソールは Elastic-Job とは直接関係なく、Elastic-Job の登録センターのデータを読み取ったり、登録センターのデータを更新してグローバル設定を変更したりすることでジョブの状態を表示します。
2. コンソールはタスク自体が実行されているかどうかのみ制御できますが、ジョブ プロセスの開始と停止は制御できません コンソールとジョブ サーバーは完全に分散されているため、コンソールはジョブ サーバーを制御できません。
主な機能:
1. ジョブとサーバーのステータスを確認する
2. ジョブ構成を迅速に変更および削除する
3. ジョブの有効化と無効化
4. 登録センター全体の求人を表示する
5. ジョブの実行トラックと実行ステータスを表示する
サポートされていない項目
1. ジョブを追加します。ジョブは初回実行時に自動的に追加されるため、コンソールを使用してジョブを追加する必要はなく、Elasitc-Job を含むジョブ プロセスをジョブ サーバー上で直接起動するだけです。
8.2.1 構築手順
-
elastic-job-lite-console-2.1.5.tar を解凍します。
-
bin ディレクトリに入り、次を実行します。
bin\start.bat -
ブラウザを開いて http://localhost:8899 にアクセスします。 ユーザー名: root パスワード: root を入力すると、インターフェイスは次のようになります。
ユーザーには管理者とゲストの2種類が用意されており、管理者はすべての操作権限を持ち、ゲストは閲覧権限のみを持ちます。デフォルトの管理者アカウントとパスワードは root/root、ゲスト ユーザー名とパスワードは guest/guest です。管理者とゲストのユーザー名とパスワードは、conf\auth.properties を通じて変更できます。
8.2.2 設定と使用方法
-
登録センターのアドレスを設定するには、まず Zookeeper を起動し、次に登録センターの設定インターフェイスに移動し、[追加] をクリックします。
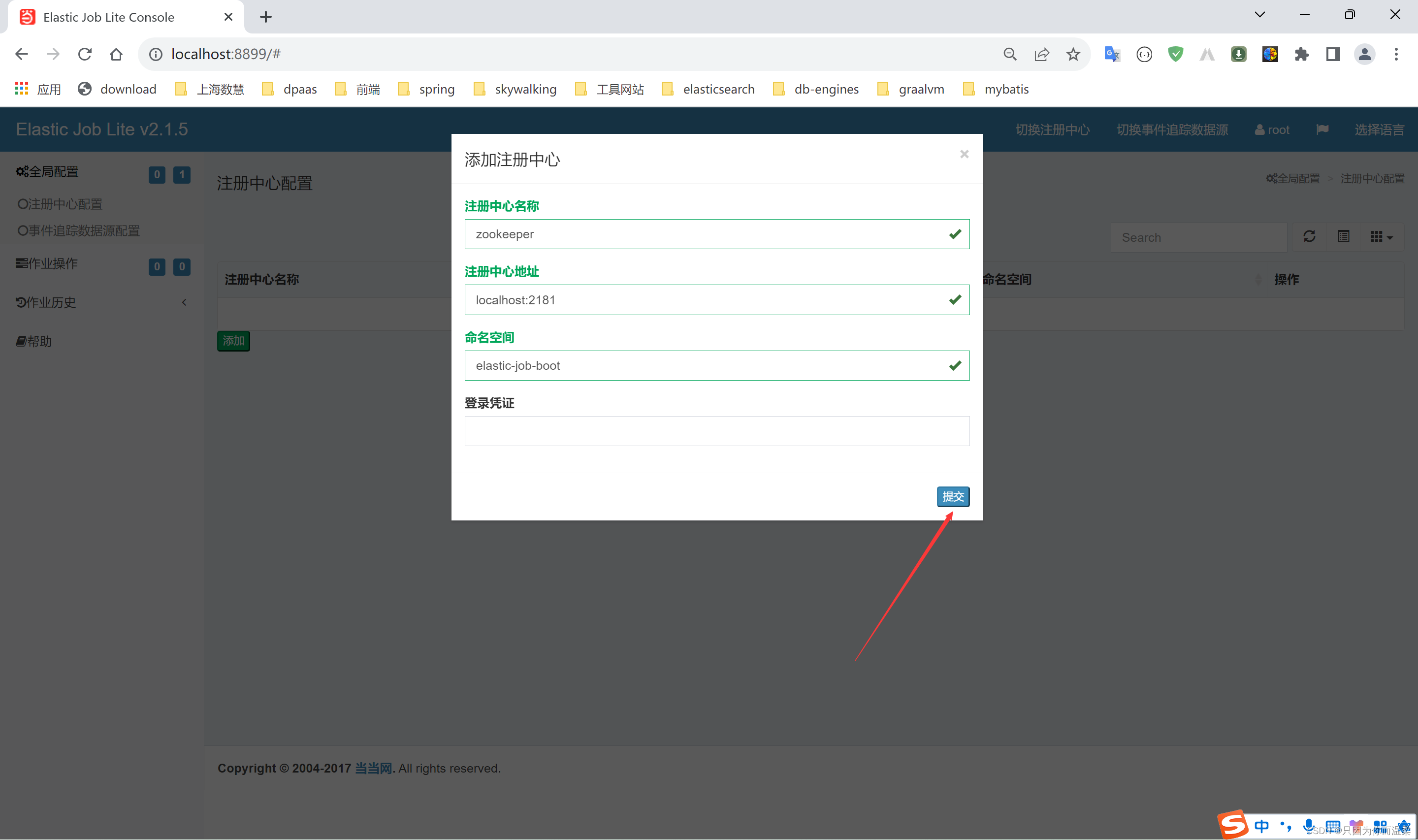
-
「送信」をクリックした後、「接続」をクリックします (zookeeper が起動状態である必要があります)。
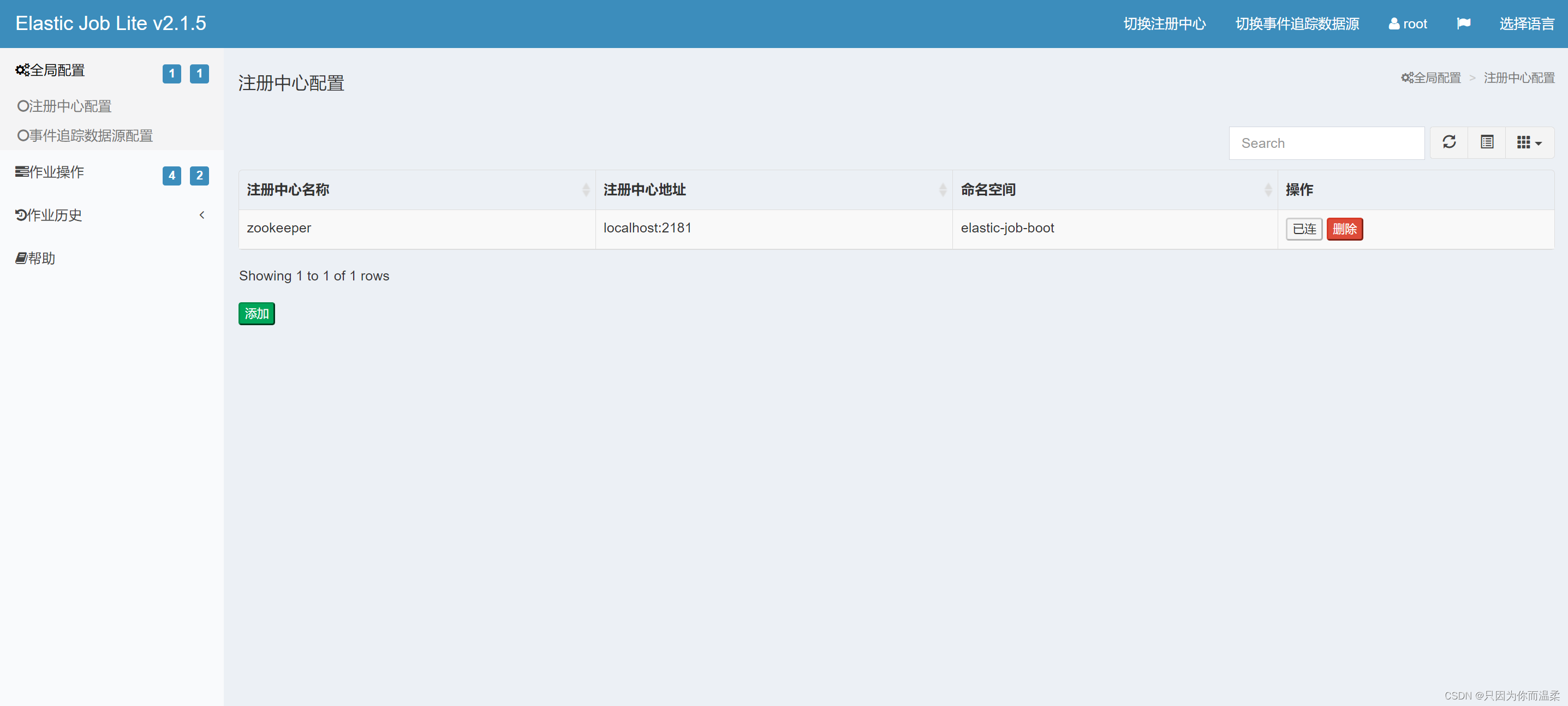
-
接続が成功すると、ジョブの緯度の下に、名前空間のジョブ名、シャードの数、ジョブの cron 式、サーバー IP、現在実行中のインスタンスの数、合計などの情報が表示されます。サーバー緯度で表示できるジョブの数。
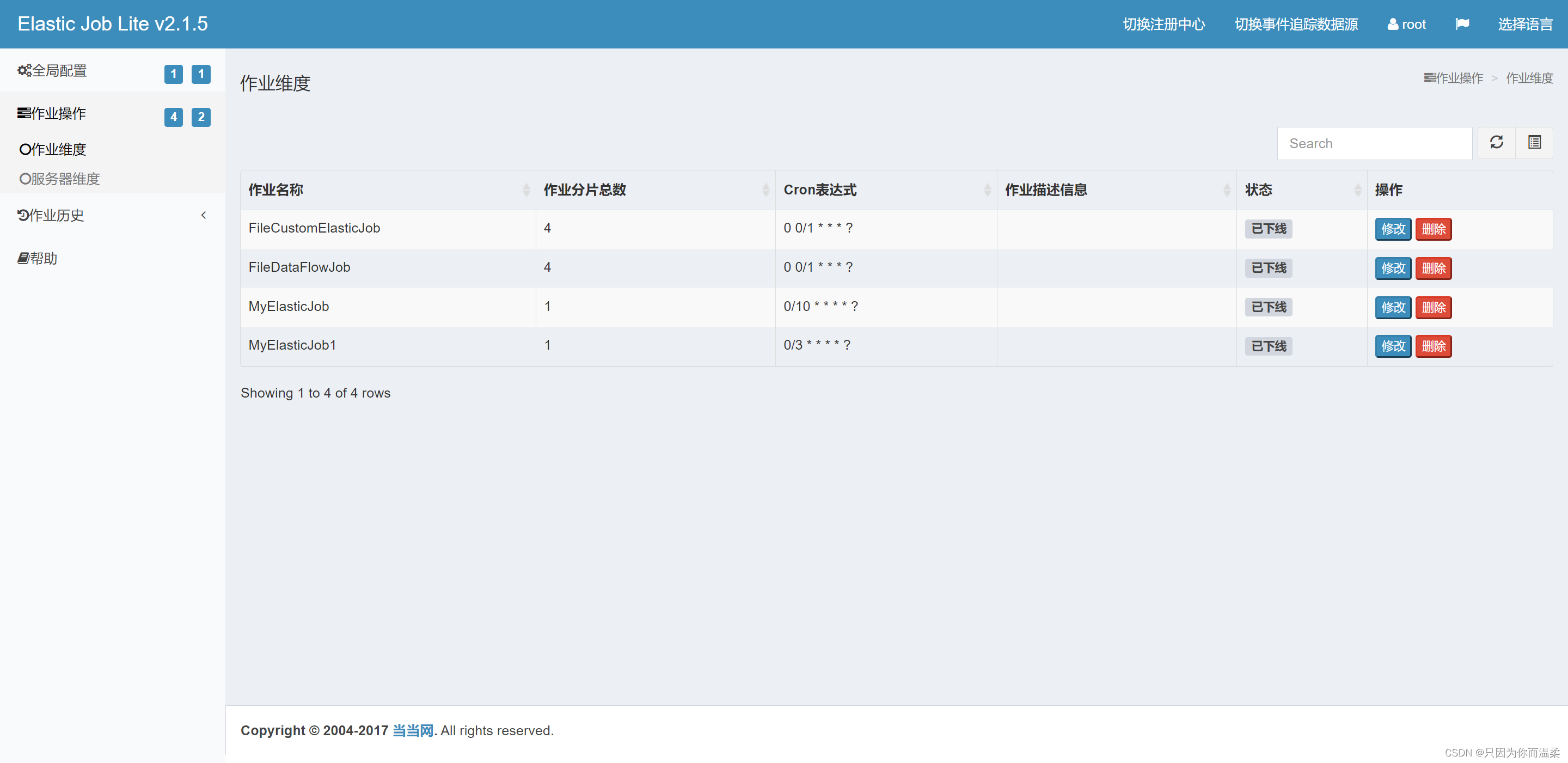
-
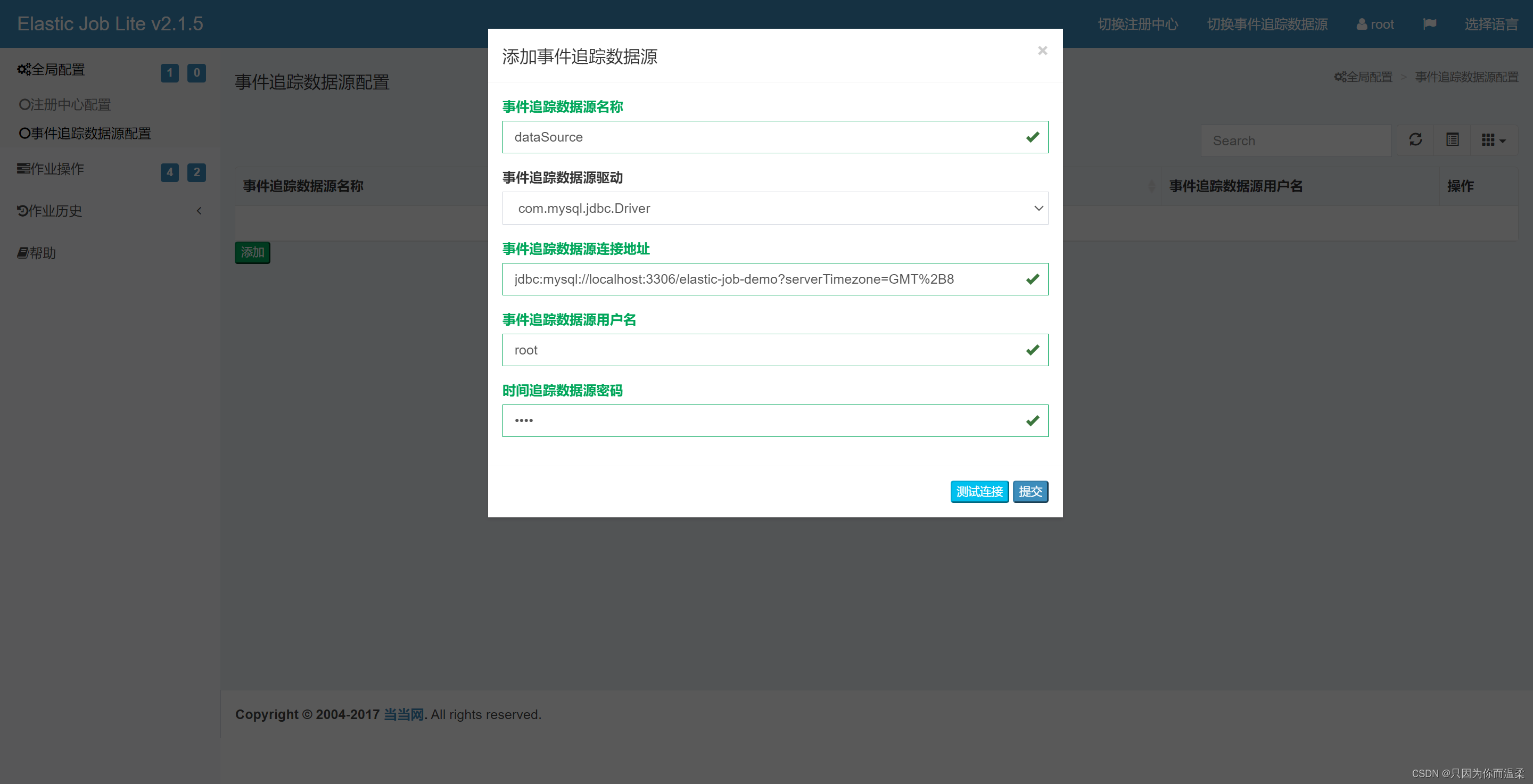
データベース接続を追加した後、タスクの実行結果を表示できます。
-
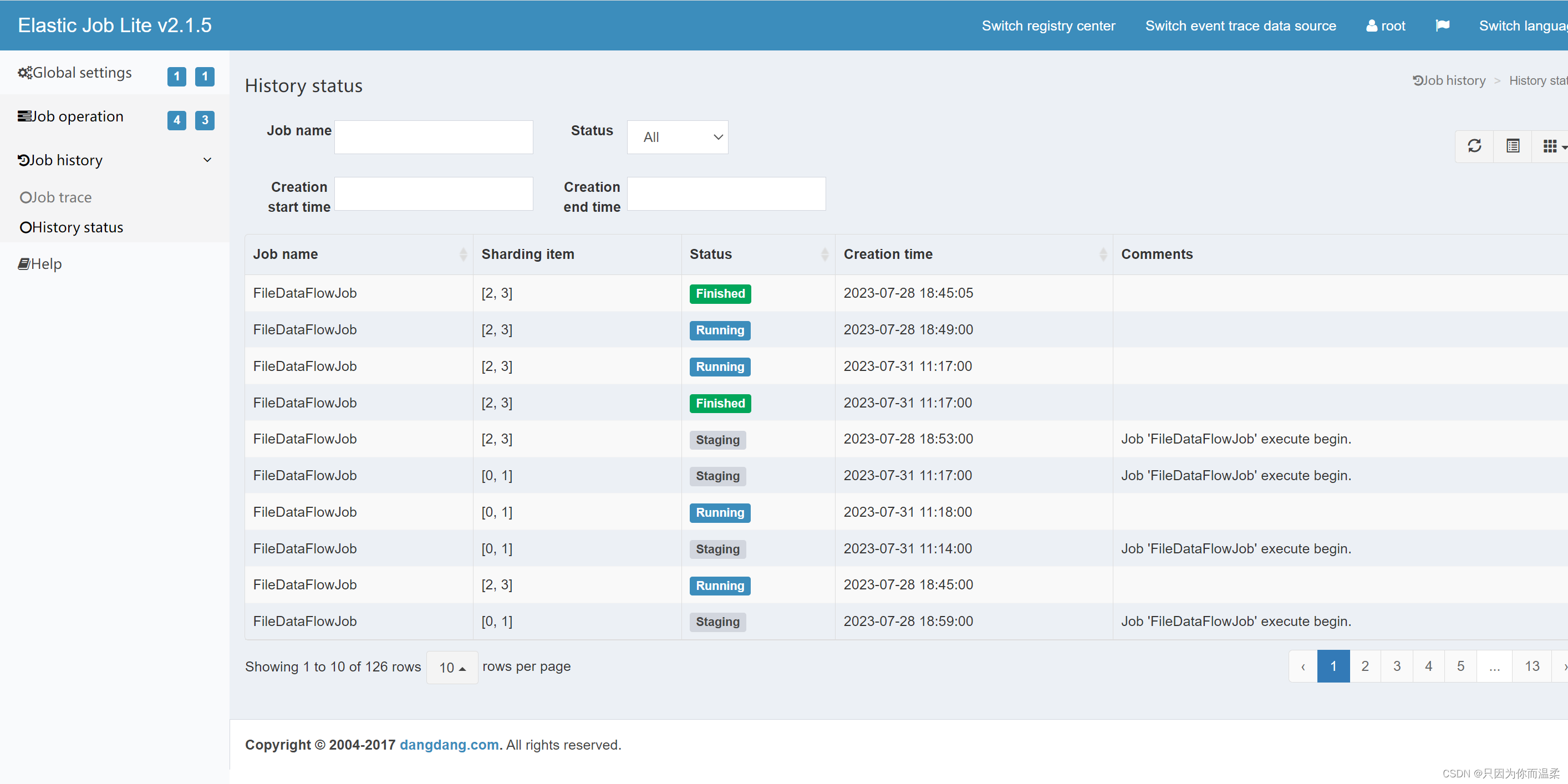
その後、ジョブ履歴でタスクの実行履歴を確認できます。
デモのダウンロード アドレス: https://download.csdn.net/download/zsx1314lovezyf/88282573