1。概要
顔認識に一般的に使用されるネットワークである Arcface は、特別に設計された損失関数を利用して、トレーニング中にモデルがクラス間の距離を増加させ、クラス内の距離を継続的に減少させることを可能にし、最終的にトレーニングされたバックボーンが顔の高度に識別できる特徴を取得できるようにします。認識。
この記事は、専門ブロガー Bubbliing によって提供されたウェアハウス コードによって実装されたアークフェイスに基づいています。主に、アークフェイス モデルの動的バッチ推論の Python および C++ コード実装を共有しています。トレーニングとテストについては、ウェアハウスの使用方法を参照してください。説明書。ウェアハウスのアドレスは次のとおりです: https://github.com/bubbliiiiing/arcface-pytorch
2. cuda版Python高速推論
このセクションには主に、Python を使用してアークフェイス モデルを onnx ユニバーサル プラットフォーム モデルに変換し、その後 TensorRT によってサポートされるアクセラレーション エンジンに変換するプロセス全体が含まれています。
2.1 円弧面モデルを ONNX モデルに変換する
ディープラーニングで学習させたモデルをONNXに変換するのが一般的なコードの利用方法です。対応するエクスポートにはtorch.onnx.export関数を使用します。ブロガーはテスト中に複数の画像の特徴マップを同時に計算することを考慮しているため、バッチは後で使用できるように動的に設定されます。
コードは次のように実装されます。
def export_onnx(model, img, onnx_path, opset, dynamic=False, simplify=True, batch_size=1):
torch.onnx.export(model, img, onnx_path, verbose=True, opset_version=opset,
export_params=True,
do_constant_folding=True,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {
0: 'batch_size'}, # shape(1,3,112,112)
'output': {
0: 'batch_size'} # shape(1,128)
} if dynamic else None)
# Checks
model_onnx = onnx.load(onnx_path) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
if simplify:
try:
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=dynamic,
test_input_shapes={
'images': list(img.shape)} if dynamic else None)
assert check, 'assert check failed'
onnx.save(model_onnx, onnx_path)
print('simplify onnx success')
except Exception as e:
print('simplify onnx failure')
具体的な利用プランは以下の通りです。
def convert2onnx_demo():
model_path = './model_data/arcface_mobilefacenet.pth'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Loading weights into state dict...')
net = arcface(backbone='mobilefacenet', mode="predict").eval()
net.load_state_dict(torch.load(model_path, map_location=device), strict=True)
net = net.to(device)
batch_size = 4
print('{} model loaded.'.format(model_path))
dummy_input = torch.randn(batch_size, 3, 112, 112).to(device)
onnx_path = './model_data/arcface_mobilefacenet.onnx'
opset = 10
export_onnx(net, dummy_input, onnx_path, opset, dynamic=True, simplify=True)
ort_session = ort.InferenceSession(onnx_path)
outputs = ort_session.run(None, {
'images': np.random.randn(batch_size, 3, 112, 112).astype(np.float32)})
print(outputs[0])
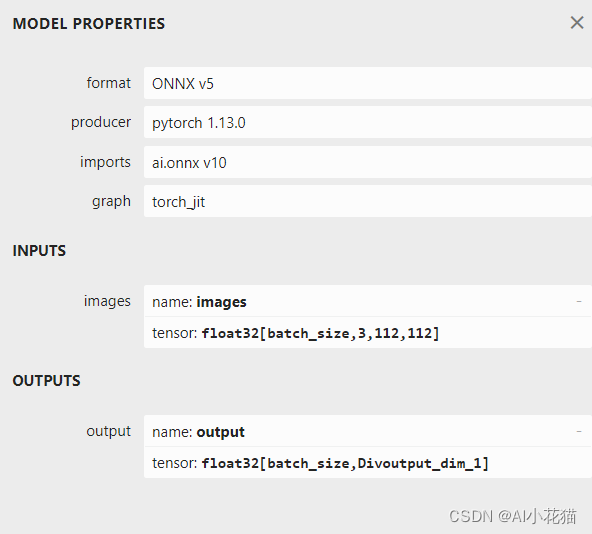
エクスポートされた onnx モデルの入力と出力は次のとおりです。 入力ディメンションのバッチが動的に変換されていることが明確にわかります。
2.2 アークフェイス ONNX モデルをエンジンに変換する
onnx をエンジンに変換するには多くの方法があります。trtexec.exe を使用して変換することも、Python を使用して対応するコードを作成して使用することもできます。ブロガーは Python を使用して、変換用の対応するスクリプトを作成します。具体的なコード変換は次のとおりです。以下に続きます:
def onnx2engine():
import tensorrt as trt
def export_engine(onnx_path, engine_path, half, workspace=4, verbose=False):
print('{} starting export with TensorRT {}...'.format(onnx_path, trt.__version__))
# assert img.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
if not os.path.exists(onnx_path):
print(f'failed to export ONNX file: {
onnx_path}')
logger = trt.Logger(trt.Logger.INFO)
if verbose:
logger.min_severity = trt.Logger.Severity.VERBOSE
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = workspace * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx_path)):
raise RuntimeError(f'failed to load ONNX file: {
onnx_path}')
## 支持动态batch使用必须
profile = builder.create_optimization_profile()
profile.set_shape("images", (1, 3, 112, 112), (8, 3, 112, 112), (16, 3, 112, 112))
config.add_optimization_profile(profile)
inputs = [network.get_input(i) for i in range(network.num_inputs)]
outputs = [network.get_output(i) for i in range(network.num_outputs)]
print('Network Description:')
for inp in inputs:
print('input {} with shape {} and dtype is {}\n'.format(inp.name, inp.shape, inp.dtype))
for out in outputs:
print('output {} with shape {} and dtype is {}\n'.format(out.name, out.shape, out.dtype))
half &= builder.platform_has_fast_fp16
print('building FP{} engine in {}'.format(16 if half else 32, engine_path))
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(engine_path, 'wb') as t:
t.write(engine.serialize())
print("max_batch_szie = {}".format(builder.max_batch_size))
print("flag= {}".format(flag))
print('export success, saved as {f} ({file_size(f):.1f} MB)')
onnx_path = './model_data/arcface_mobilefacenet.onnx'
engine_path = './model_data/arcface_mobilefacenet.engine'
half = True
verbose = True
export_engine(onnx_path, engine_path, half, verbose=verbose)
注意する必要があるのは、動的バッチを使用してエンジンの構築を完了するには、エンジンが最小推論バッチ、最適推論バッチ、最大推論バッチを認識できるようにプロファイルを適切に設定する必要があることです。
2.3 arcface TensorRT 高速推論
推論コードは比較的単純で、簡単な概要は次のとおりです。
- 画像は対応する推論バッチに結合されます
- TensorRT に必要なコンテキストを初期化する
- ホストとデバイス上のメモリ空間を動的入力バッチと出力結果に割り当てます。
- インターフェイスを呼び出して推論を完了します
- 関連する後処理コード
この記事の具体的なコードは次のとおりです。
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
LEN_ALL_RESULT = 128
def get_img_path_batches(batch_size, img_dir):
ret = []
batch = []
for root, dirs, files in os.walk(img_dir):
for name in files:
suffix = os.path.splitext(name)[-1]
if suffix in ['.jpg', '.png', '.JPG', '.jpeg']:
if len(batch) == batch_size:
ret.append(batch)
batch = []
batch.append(os.path.join(root, name))
if len(batch) > 0:
ret.append(batch)
return ret
class ArcFaceTRT(object):
"""
description: A arcface class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path, batch_size=1):
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
with open(engine_file_path, 'rb') as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
context.set_binding_shape(0, (batch_size, 3, 112, 112)) # 这句非常重要!!!定义batch为动态维度
#
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('binding: ', binding, engine.get_tensor_shape(binding))
## 动态 batch
dims = engine.get_tensor_shape(binding)
if dims[0] == -1:
dims[0] = batch_size
# size = trt.volume(engine.get_tensor_shape(binding)) * engine.max_batch_size
size = trt.volume(dims) * engine.max_batch_size
dtype = trt.nptype(engine.get_tensor_dtype(binding))
# allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# append the device buffer to device bindings
bindings.append(int(cuda_mem))
# append to the appropriate list
if engine.get_tensor_mode(binding).value == 1: ## 0 是NONE 1是INPUT 2是OUTPUT
# if engine.binding_is_input(binding):
self.input_w = engine.get_tensor_shape(binding)[-1]
self.input_h = engine.get_tensor_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = batch_size
# self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
# 组合为相应的batch进行处理
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
end = time.time()
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
features = []
for i in range(self.batch_size):
feature = output[i * LEN_ALL_RESULT:(i + 1) * LEN_ALL_RESULT]
features.append(feature)
print(feature.shape)
return batch_image_raw, end - start, features
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image(self, image_path_batch):
"""
description: Read an image from image path
"""
for img_path in image_path_batch:
yield cv2.imread(img_path)
def get_vedio_frame(self, cap):
for _ in range(self.batch_size):
yield cap.read()
def get_raw_image_zeros(self, image_path_batch=None):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (112, 112))
image = image.astype(np.float32)
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def img_infer(ArcFaceWraper, image_path_batch):
batch_image_raw, use_time, res = ArcFaceWraper.infer(ArcFaceWraper.get_raw_image(image_path_batch))
for i, feature in enumerate(res):
print('input->{}, time->{:.2f}ms, feature shape = {}'.format(image_path_batch[i], use_time * 1000, feature.shape))
def vedio_infer(ArcFaceWraper, cap):
batch_image_raw, use_time = ArcFaceWraper.infer(ArcFaceWraper.get_vedio_frame(cap))
print('input->{}, time->{:.2f}ms, saving into output/'.format(1, use_time * 1000))
cv2.namedWindow('vedio', cv2.WINDOW_NORMAL)
cv2.imshow('vedio', batch_image_raw[0])
cv2.waitKey(1)
def warmup(ArcFaceWraper):
batch_image_raw, use_time, _ = ArcFaceWraper.infer(ArcFaceWraper.get_raw_image_zeros())
print('warm_up->{}, time->{:.2f}ms'.format(batch_image_raw[0].shape, use_time * 1000))
if __name__ == '__main__':
from tqdm import tqdm
batch = 4
# engine_file_path = r"D:\personal\project\code\arcface-pytorch-main\model_data\arcface_mobilefacenet.engine"
engine_file_path = r"arcface\arcface_mobilefacenet.engine"
arcface_wrapper = ArcFaceTRT(engine_file_path, batch_size=batch)
try:
print('batch size is', batch)
image_dir = r"datasets"
# image_path_batches = get_img_path_batches(arcface_wrapper.batch_size, image_dir)
image_path_batches = get_img_path_batches(batch, image_dir)
# warmup
# for i in range(10):
# warmup(arcface_wrapper)
for batch in tqdm(image_path_batches):
img_infer(arcface_wrapper, batch)
finally:
# destroy the instance
arcface_wrapper.destroy()
1.コンテキストには
バッチの動的ディメンションが必要であり、これは動的バッチ推論の前提条件でもあります
2. 入力バインディングの場合、dim[0] をバッチ サイズに設定する必要があります。
2.4 試験結果
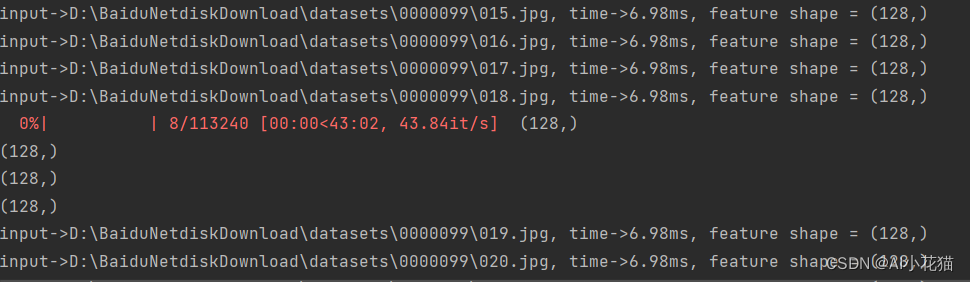
ここのブロガーは 4 つのバッチで推論を使用しており、推論速度はバッチごとに約 6.98 ミリ秒です。
バッチが 8 に設定されている場合、推論時間は次のようになります。
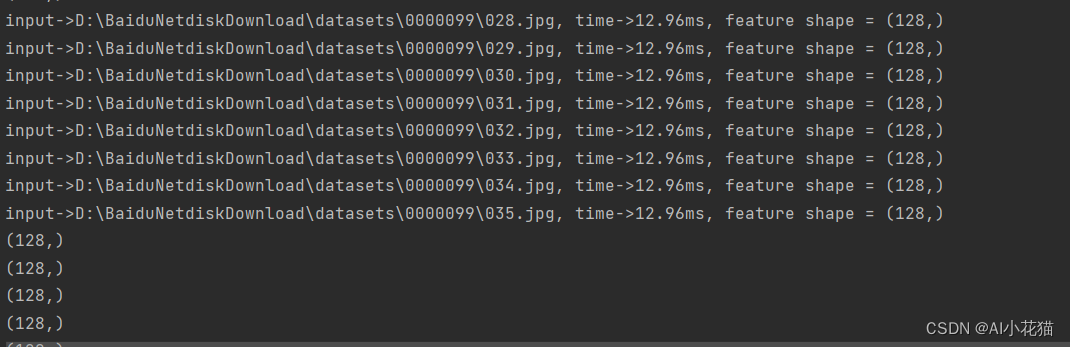
推論用に 1 ~ 16 の間の任意の値に設定することもできます。具体的な値の範囲は、エンジン生成時に設定された kmin と kmax に対応する形状に関係します。単一の推論速度と比較すると、部分的に改善されますが、それは十分ではありません。対応する割合。
3. CUDA版C++高速推論
このセクションには主に、C++ を使用してアークフェイス モデルを onnx ユニバーサル プラットフォーム モデルに変換し、その後 TensorRT によってサポートされるアクセラレーション エンジンに変換するプロセス全体が含まれます。
モデルの .pth モデルの ONNX モデルへの変換は前述のセクション 2.1 の内容と一致しているため、このセクションはモデルの ONNX モデルへの変換の成功から始まります。
3.1 アークフェイス ONNX モデルをエンジンに変換
エンジンへの変換方法は実はPythonの変換と似ており、主にC++のTensorRT対応APIを使って記述されています。
具体的な実装は以下の通りです。
void CreateEngine::trtFromOnnx(const std::string onnx_path,const std::string engine_out_path, unsigned int max_batch_size,size_t workspace ,bool half)
{
if (onnx_path.empty()) {
printf("failed to export ONNX file\n");
}
printf("***************start to create model engine********************\n");
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(static_cast<size_t>(workspace*1) << 30);
NetworkDefinitionCreationFlags flag = (1U << int(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
INetworkDefinition* network = builder->createNetworkV2(flag);
IParser* parser = createParser(*network, gLogger);
if (! parser->parseFromFile(onnx_path.c_str(), static_cast<int>(ILogger::Severity::kWARNING))) {
//wrong information
for (int32_t i = 0; i < parser->getNbErrors(); i++)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
}
std::cout << "******************successfully parse the onnx model*********************" << std::endl;
//danamic batch
auto profile = builder->createOptimizationProfile();
auto input_tensor = network->getInput(0);
auto input_dims = input_tensor->getDimensions();
// 配置最小:kMIN、最优:kOPT、最大范围:kMAX 指的是BatchSize
input_dims.d[0] = 1;
profile->setDimensions(input_tensor->getName(), OptProfileSelector::kMIN, input_dims);
profile->setDimensions(input_tensor->getName(), OptProfileSelector::kOPT, input_dims);
input_dims.d[0] = max_batch_size;
profile->setDimensions(input_tensor->getName(), OptProfileSelector::kMAX, input_dims);
//TensorRT – Using PreviewFeaturekFASTER_DYNAMIC_SHAPES_0805 can help improve performance and resolve potential functional issues
config->setPreviewFeature(PreviewFeature::kFASTER_DYNAMIC_SHAPES_0805, true);
config->addOptimizationProfile(profile);
//build engine
half &= builder->platformHasFastFp16();
if (half)
{
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
assert(engine != nullptr);
IHostMemory* serialized_engine = engine->serialize();
assert(serialized_engine != nullptr);
// save engine
std::ofstream p(engine_out_path, std::ios::binary);
if (!p) {
std::cerr << "could not open output engine path" << std::endl;
assert(false);
}
p.write(reinterpret_cast<const char*>(serialized_engine->data()), serialized_engine->size());
//release
network->destroy();
parser->destroy();
engine->destroy();
config->destroy();
serialized_engine->destroy();
builder->destroy();
std::cout << "**************successed transfer onnx to trt engine***************" << std::endl;
}
実装はPythonと同じで、主にプロファイルの追加と動的バッチの最大値、最小値、最適値の指定を行います。kFASTER_DYNAMIC_SHAPES_0805 はパフォーマンスを向上させることができるため、ここで使用する場合に追加しました。
3.2 arcface TensorRT 高速推論
推論の一般的なプロセスは次のとおりです。
- 画像を対応するバッチに組み立て、データの前処理を実行します。
- ホストとデバイスにそれぞれメモリを割り当てます
- cuda は推論を高速化して結果を取得します
- 結果のデコード + 類似度を計算するための後処理
- 対応するメモリを解放します
void ArcFaceInference::inference(std::vector<cv::Mat>& imgs, std::vector<cv::Mat>& res_batch)
{
int batch = imgs.size();
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
//input
int input_numel = batch * 3 * imgs[0].cols * imgs[0].rows;
float* cpu_input_buffer = nullptr;
float* gpu_input_buffer = nullptr;
CUDA_CHECK(cudaMallocHost((void**)(&cpu_input_buffer), input_numel * sizeof(float)));
CUDA_CHECK(cudaMalloc((void**)(&gpu_input_buffer), input_numel * sizeof(float)));
//output
auto output_dims = this->initEngine->engine->getBindingDimensions(1);
output_dims.d[0] = batch;
int output_numel = output_dims.d[0] * output_dims.d[1];
float* cpu_output_buffer = nullptr;
float* gpu_output_buffer = nullptr;
CUDA_CHECK(cudaMallocHost((void**)(&cpu_output_buffer), output_numel * sizeof(float)));
CUDA_CHECK(cudaMalloc((void**)(&gpu_output_buffer), output_numel * sizeof(float)));
// set input dim
auto input_dims = this->initEngine->engine->getBindingDimensions(0);
input_dims.d[0] = batch;
this->initEngine->context->setBindingDimensions(0, input_dims);
//batch process
batchPreprocess(imgs,cpu_input_buffer);
auto start = std::chrono::system_clock::now();
std::cout << "************start to inference batch imgs********************" << std::endl;
CUDA_CHECK(cudaMemcpyAsync(gpu_input_buffer, cpu_input_buffer, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream));
float* bindings[] = {
gpu_input_buffer,gpu_output_buffer };
bool success = this->initEngine->context->enqueueV2((void**)(bindings), stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(cpu_output_buffer, gpu_output_buffer, output_numel * sizeof(float), cudaMemcpyDeviceToHost, stream));
CUDA_CHECK(cudaStreamSynchronize(stream));
auto end = std::chrono::system_clock::now();
std::cout << "*************batch inference time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" <<"*********************" << std::endl;
//postprocess
for (int i = 0; i < batch; i++)
{
cv::Mat result = cv::Mat(1, output_dims.d[1], CV_32FC1, static_cast<float*>(&cpu_output_buffer[i * output_dims.d[1]]));
res_batch.emplace_back(result.clone());
// 计算相似度
float max_similarity = 0.0;
std::string name = "";
for (std::map<std::string, cv::Mat>::iterator iter = obsInfo.begin(); iter != obsInfo.end(); ++iter){
float similarity = getSimilarity(result.clone(), iter->second);
if (similarity>max_similarity)
{
max_similarity = similarity;
name = iter->first;
}
}
if (!GETVECTOR)
{
printf("第%i张图与%s的相似都最高,相似度为:%f\n", i + 1, name.c_str(), max_similarity);
}
}
//release
CUDA_CHECK(cudaStreamDestroy(stream));
CUDA_CHECK(cudaFreeHost(cpu_input_buffer));
CUDA_CHECK(cudaFreeHost(cpu_output_buffer));
CUDA_CHECK(cudaFree(gpu_input_buffer));
CUDA_CHECK(cudaFree(gpu_output_buffer));
}
3.3 テスト結果
テストでは顔検出に5つのカテゴリのデータを使用し、まずデータの一部を分割し、対応する平均的な特徴を抽出して保存し、推論テストの際には推論で得られた特徴を用いて既存の特徴との類似性を比較し、類似度を判定し、最も度合いが高いものが対応するカテゴリとなります。
具体的な結果は以下の通りです。
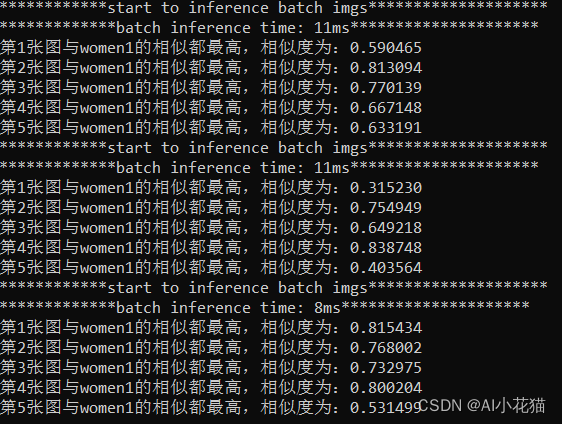
4 まとめ
Arcface の導入は実際には比較的単純ですが、難しいのは、マルチバッチ推論を迅速に実装する方法と、テーブルに新しい機能をより効果的に追加して動的拡張を実現する方法にあります。
この記事では、Arcface 動的バッチ推論の導入プロセスを実際のユースケースを通じて詳細に説明します。不足している点があれば、アドバイスをお願いします。
- -終わり - -