皆さんこんにちは、私の名前はニンイーです。
4週連続休みなしですが、最近は本業も副業も忙しさのピークで、夜11時に退社して夜中の2時まで授業を書いています。
ここ 1 か月以上、私の毎日の最大の願いは十分な睡眠を取ることです。
この段階はついに終わりました~SQL インタビューの質問を更新し続けましょう~
トピック 5:
175. 2 つのテーブルを結合する(単純)
これで 2 つのテーブルができました。
人物テーブル: PersonId、
姓と名に関する情報。
+----------+----------+-----------+| personId | lastName | firstName |+----------+----------+-----------+| 1 | Wang | Allen || 2 | Alice | Bob |+----------+----------+-----------+
住所テーブル: AddressId、PersonId、City、および State に関する情報が含まれます。
+-----------+----------+---------------+------------+| addressId | personId | city | state |+-----------+----------+---------------+------------+| 1 | 2 | New York City | New York || 2 | 3 | Leetcode | California |+-----------+----------+---------------+------------+
Person テーブル内の各人の姓、名、都市、および州をレポートする SQL クエリを作成します。personId のアドレスが Address テーブルにない場合は、null が報告されます。
結果の例:
+-----------+----------+---------------+----------+| firstName | lastName | city | state |+-----------+----------+---------------+----------+| Allen | Wang | Null | Null || Bob | Alice | New York City | New York |+-----------+----------+---------------+----------+
問題解決のアイデア:
この質問は非常に単純で、主なテストは、左結合を使用するか右結合を使用するかという JOIN 接続の知識点です。
タイトルの「personId のアドレスが Address テーブルにない場合、レポートは空の null になります」という文に注目してください。
Address テーブルには Null 値が表示されるため、左結合を使用して、Person テーブルを左側に、Address テーブルを右側に配置します。
SELECT firstName,lastName,city,stateFROM Person pLEFT JOIN Address aON p.personId = a.personId;
自分のコンピュータでローカルにテストしたい場合は、これを使用してデータ テーブル ステートメントをすばやく作成できます。
-- 创建表PersonCREATE TABLE Person(personId INT,LastName VARCHAR(10),FirstName VARCHAR(10));-- 插入语句INSERT INTO Person VALUES(1,'Wang','Allen'),(2,'Alice','Bob');CREATE TABLE Address(addressId INT,personId INT,City VARCHAR(20),state VARCHAR(20));-- 插入语句INSERT INTO Address VALUES(1,2,'New York City','New York'),(2,3,'Leetcode','California');
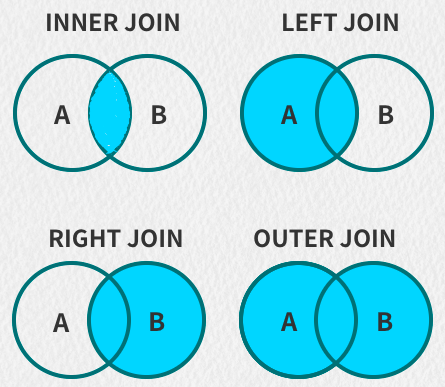
ナレッジポイント: 結合接続
複数のデータ テーブルの結合クエリには、JOIN 接続の使用が必要です。JOIN 接続にはいくつかの種類があります。
* INNER JOIN : 内部接続。JOIN とだけ書くこともできます。接続基準に一致するデータのみが、結合される 2 つのテーブルに保持されます。これは、2 つのテーブルの交差部分に相当します。前後で同じテーブルを結合する場合、自己結合とも呼ばれます。
* LEFT JOIN : 左結合。左外部結合とも呼ばれます。演算子の左側のテーブルにある WHERE 句に一致するすべてのレコードが返されます。演算子の右側のテーブルに ON 以降の結合条件に一致するレコードがない場合は、選択した値が返されます。右側のテーブルの列は NULL になります。
* RIGHT JOIN : 右結合。右外部結合とも呼ばれます。右側のテーブルの WHERE ステートメントに一致するすべてのレコードが返されます。左側の表で一致しないセグメント値は NULL に置き換えられます。
* FULL JOIN : 完全結合。WHERE ステートメントの条件を満たすすべてのテーブル内のすべてのレコードを返します。どのテーブルにも指定されたセグメントに適格な値がない場合は、代わりに NULL が使用されます。
トピック 6:
178. スコアランク(中)
スコア表があります: スコア
+----+-------+| id | score |+----+-------+| 1 | 3.50 || 2 | 3.65 || 3 | 4.00 || 4 | 3.85 || 5 | 4.00 || 6 | 3.65 |+----+-------+
スコアを高いものから低いものに並べ替える SQL クエリを作成します。2 つのスコアが等しい場合、両方のスコアは同じにランク付けされる必要があります。ランキングは途中に空の数字がなく連続している必要があります。
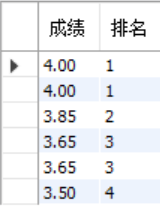
クエリ結果の形式は以下のとおりです。
+-------+------+| score | rank |+-------+------+| 4.00 | 1 || 4.00 | 1 || 3.85 | 2 || 3.65 | 3 || 3.65 | 3 || 3.50 | 4 |+-------+------+
問題解決のアイデア:
この質問は主に「相関サブクエリ」について調べます。相関サブクエリでは、メインクエリの各レコードレベルでサブクエリが順番に実行され、サブクエリはメインクエリに依存します。
この質問では、まずスコアを逆順に並べ替え、ランク列をサブクエリとして書き込み、現在の外部クエリ スコア以上の重複の数を計算します。この数値がランキングになります。
ステップ 1 : まずスコアを降順に並べ替えます。
SELECT a.Score AS '成绩'FROM Scores aORDER BY a.score DESC
ステップ 2 : select の後に「ランキング」列をサブクエリとして記述します。現在の外部クエリ スコア以上の重複の数を計算します。この数値がランキングになります。
SELECT a.Score AS '成绩',(SELECT COUNT(DISTINCT score)FROM ScoresWHERE score >= a.score) AS '排名'FROM Scores aORDER BY a.score DESC
自分のコンピュータでローカルにテストしたい場合は、これを使用してデータ テーブル ステートメントをすばやく作成できます。
-- 创建表CREATE TABLE Scores(Id INT,score DECIMAL(10,2));-- 插入语句INSERT INTO Scores VALUES(1,3.50),(2,3.65),(3,4.00),(4,3.85),(5,4.00),(6,3.65);
トピック 7:
183. 注文しないお客様(簡易)
Web サイトには、Customers テーブルと Orders テーブルという 2 つのテーブルが含まれています。SQL クエリを作成して、何も注文していない顧客をすべて検索します。
Customers 表:
+----+-------+| Id | Name |+----+-------+| 1 | Joe || 2 | Henry || 3 | Sam || 4 | Max |+----+-------+
注文テーブル:
+----+------------+| Id | CustomerId |+----+------------+| 1 | 3 || 2 | 1 |+----+------------+
たとえば、上記の表の場合、クエリは次を返す必要があります。
+-----------+| Customers |+-----------+| Henry || Max |+-----------+
問題解決のアイデア:
この質問はサブクエリを調べます。以前に注文したことのない顧客を調べたい場合は、まず Orders テーブルで既に注文した顧客を見つけて、これらの顧客を Customers テーブルから除外します。これは非常に簡単です。注文したことがない人がわかります。
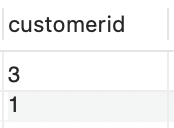
ステップ 1 : まず、注文テーブルですでに注文した顧客を見つけます。
SELECT customeridFROM orders
ステップ 2 : NOT IN を使用して、このリストにない顧客をクエリします。
SELECT name AS '未订购客户'FROM customersWHERE id NOT IN(SELECT customeridFROM orders);
自分のコンピュータでローカルにテストしたい場合は、これを使用してデータ テーブル ステートメントをすばやく作成できます。
-- 创建表CREATE TABLE Customers(Id INT,Name VARCHAR(10));-- 插入语句INSERT INTO Customers VALUES(1,'Joe'),(2,'Henry'),(3,'Sam'),(4,'Max');CREATE TABLE Orders(Id INT,CustomerId INT);-- 插入语句INSERT INTO Orders VALUES(1,3),(2,1);
トピック 8:
184. 部門内で最も給与の高い従業員(中)
これで、従業員情報テーブル Employee と部門テーブルDepartment の 2 つのテーブルができました。
SQL クエリを作成して、各部門の上位 3 人の有給従業員を検索します。結果のテーブルを任意の順序で返します。
従業員テーブル:
+-----+--------+----------+--------------+| id | name | salary | departmentId |+----+--------+--------+--------------+| 1 | Joe | 85000 | 1 || 2 | Henry | 80000 | 2 || 3 | Sam | 60000 | 2 || 4 | Max | 90000 | 1 || 5 | Janet | 69000 | 1 || 6 | Randy | 85000 | 1 || 7 | Will | 70000 | 1 |+----+---------+---------+------------+
Department 表:
+------+---------+| id | name |+------+---------+| 1 | IT || 2 | Sales |+------+---------+
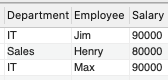
出力例:
+------------+----------+--------+| Department | Employee | Salary |+------------+----------+--------+| IT | Jim | 90000 || Sales | Henry | 80000 || IT | Max | 90000 |+------------+----------+--------+
問題解決のアイデア:
この質問では、テーブルの結合とサブクエリについて調べます。
まず部門をグループにグループ化し、各部門に対応する最高給与を調べます。次に、このクエリ結果を Where ステートメントの後に配置し、IN ステートメントと組み合わせて、部門名と給与の関係をクエリします。
部門には同時に最高給与の複数の従業員がいる可能性があるため、サブクエリに従業員名の情報を含めないでください。
ステップ 1 : まず、従業員テーブル Employee のDepartmentId フィールドをグループ化して、各部門の最大給与値を取得します。
SELECT DepartmentId, MAX( Salary )FROM EmployeeGROUP BY DepartmentId
ステップ 2 :
次に、DepartmentId フィールドを介して従業員テーブル Employee と部門テーブルDepartment を接続します。接続が完了したら、前の手順で見つけた部門 ID (DepartmentId) と対応する最大給与に基づいて、対応するすべての従業員の名前を検索します。
SELECTd.name AS 'Department',e.name AS 'Employee',SalaryFROM Employee eJOIN Department dON e.DepartmentId = d.IdWHERE (e.DepartmentId , Salary) IN(SELECT DepartmentId, MAX(Salary)FROM EmployeeGROUP BY DepartmentId);
自分のコンピュータでローカルにテストしたい場合は、これを使用してデータ テーブル ステートメントをすばやく作成できます。
-- 创建表CREATE TABLE Employee(id INT,name VARCHAR(10),salary INT,departmentId INT);-- 插入语句INSERT INTO Employee VALUES(1,'Joe',70000,1),(2,'Jim',90000,1),(3,'Henry',80000,2),(4,'Sam',60000,2),(5,'Max',90000,1);CREATE TABLE Department(id INT,name VARCHAR(20));-- 插入语句INSERT INTO Department VALUES(1,'IT'),(2,'Sales’);
知識ポイント:
(1) 集計機能:
集計関数は、その名前が示すように、データ レコードを集計する関数です。
たとえば、元のデータベースに 100 件のレコードがあり、この 100 件のレコードの最大値を集計関数を使用してクエリすると、最大値を持つレコードのみが出力されます。
一般的に使用される集計関数は次のとおりです。
MAX( ) 最大値
MIN( ) 最小値
SUM( ) 合計値
AVG( ) 平均
COUNT( ) レコード数
(2) サブクエリ:
SQL ステートメントはネストできますが、最も一般的なのはクエリ ステートメントのネストです。一般に、外側にネストされたステートメントをメイン クエリと呼び、内側にネストされたステートメントをサブクエリと呼びます。
(3) グループごとにグループ化:
GROUP BY 句は結果セットをグループ化するために使用され、通常は集計関数と組み合わせて使用されます。