序文
いわゆるソートとは、データのセットを増加または減少の方法で配置して、このデータのセットを順序どおりにすることです。分別は生活の中で広く使われており、あらゆる分野で行われており、例えばネットで買い物をするとき、私たちはある分別方法に従ってものを選んでいます。したがって、並べ替えの実装を理解することが非常に重要です。
目次
1. ソートの概念
ソート: いわゆるソートとは、1 つまたはいくつかのキーワードのサイズに応じて、特定の規則に従ってレコードの文字列を増加または減少するシーケンスにすることです。
安定性: ソート対象のレコード シーケンスに同じキーワードを持つ複数のレコードがあると仮定します。これらのレコードの相対的な順序はソート後も変化していません。つまり、元のシーケンスでは r[i] = r[j] です。 r[i] が r[j] より前にあり、ソート後に r[i] が r[j] より前にある場合、このソート アルゴリズムは安定していると言われ、そうでない場合は不安定です。
内部ソート: すべてのデータ要素がメモリ内に配置されるソート。
外部ソート: データ要素が多すぎて同時にメモリに配置できない場合、データはソート プロセスの要件に従って内部メモリと外部メモリ間で移動できます。
2. 一般的な並べ替えアルゴリズム

3. 一般的なソートアルゴリズムの実装
3.1 挿入ソート
基本的な考え方: すべてのシーケンスが挿入され、新しい順序付きシーケンスが取得されるまで、キー値に従って、ソート対象のレコードを既にソート済みの順序付きシーケンスに 1 つずつ挿入します。
実際、ポーカーをプレイするときは、挿入ソートのアイデアを使用しました。

3.1.1 直接挿入ソート
i 番目の要素を挿入する時点で、前の array[0]、array[1]、...、array[i-1] は既にソートされており、このとき、arryy[i] と array[i] のソート コードは-1] が使用され、array[i-2]、array[i-3]、... ソート コード シーケンスを比較して、array[i] を挿入しようとしている挿入位置とその順序を見つけます。元の位置にある要素は後方に移動されます。
比較処理では、ソートが昇順の場合はまず現在値と比較し、現在値より小さい場合は現在の値の前の要素と比較し、大きい場合は前よりも比較します。現在の値の要素の場合、現在の値の前の要素の後に挿入されます。現在の値の前の要素より小さい場合は、挿入に適切な位置が見つかるまで前の要素との比較を続けます。が最小である場合は、それを配列の先頭に挿入します。図に示すように:

void InsertSort(int* a, int n)//升序排序
{
assert(a);
for (int i = 0; i < n - 1; ++i)
{
int end = i;
int tmp = a[end + 1];//保存数据,后面移动的时候数据会被覆盖
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];//将数据向后移动空出位置
--end;//迭代继续向前比较
}
else
{
break;//插入到
}
}
a[end + 1] = tmp;
}
}直接挿入ソートの機能の概要:
1. 時間計算量は O(N*2) です。
2. ソートされたシーケンスの順序が近いほど、時間の複雑さは低くなります。
3.安定性:安定しています。
4. 空間複雑度 O(1)、安定したソートです。
実装コード:
3.1.2 ヒルソート
ヒルソートは、減分増分ソート法とも呼ばれます。ヒル ソートの基本的な考え方は、まず整数を選択し、ソートするファイル内のレコードをグループに分割し、ギャップの距離を持つすべてのレコードを 1 つのグループに入れ、各グループ内のレコードをソートします。そして、上記のグループ化と並べ替え作業を繰り返します。ギャップ = 1 の場合、すべてのレコードは均一にソートされます。
率直に言うと、Hill ソートは直接挿入ソートからのブレークスルーを見つけます。直接挿入ソートの時間計算量は非常に高いですが、順序どおりまたは順序に近い場合、直接挿入ソートの効率は非常に優れています。注文にどれくらい近づいていますか?これには事前のソートが必要です。配列は事前ソートによって順序に近くなり、最後の直接挿入ソートは非常に高速になります。このように、Hill ソートは直接挿入ソートに対して適切に最適化されています。
ヒルのソートは 2 つのステップに分かれています。
1. 配列を事前に並べ替える
配列をギャップに応じて多数のグループに分割し、まずギャップのあるグループをギャップが順番になるように並べ替えてから、ギャップを減らします。上記のプロセスを繰り返します。
2. 直接挿入ソート
ギャップが 1 に等しい場合、これは直接挿入ソートと同等です。

図に示すように:
//希尔排序
void ShellSort(int* a, int n)
{
assert(a);//确保指针不为空
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//保证最后一次排序的间隔是1,进过计算gap按照三分之一减少是最优的
for (int i = 0; i < n - gap; ++i)//排升序
{
int end = i;
int tmp = a[end + gap];//防止数据被覆盖
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];//移动数组,继续在前面比较
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = tmp;//将数据插入到数组中
}
Print(a, 10);
printf(" gap = %d\n", gap);
printf("\n");
}
}ヒルソートの特徴まとめ
1. ヒル ソートは、直接挿入ソートを最適化したものです。
2. ギャップが 1 より大きい場合、配列をより近い順序にするために事前にソートされます。ギャップ == 1 の場合、配列はほぼ順序付けられているため、すばやく並べ替えることができます。これにより、全体の最適化効果が得られる。実装した後、パフォーマンス テストを比較できます。
3. ヒル ソートの時間計算量は、ギャップの値を取得する方法が多数あり、計算が困難であるため、計算が容易ではありません。そのため、多くの書籍では、ヒル ソートの時間計算量は固定されていません。

ここでのギャップはKnuthの方法に従って計算されているので、
とりあえずそれに従って計算します。

3.2 選択ソート
基本的な考え方: ソート対象のデータから毎回最小 (または最大の要素) を選択し、ソート対象の配列が終了するまでシーケンスの先頭にそれを格納します。
3.2.1 ヒープソート
参照:ヒープソート
3.2.2 直接選択ソート
昇順ソート:要素セットarray[i]~array[n-1]内で、キーコードが最大(最小)のデータ要素を選択します。
それがセット内の最後の (最初の) 要素でない場合は、セット内の最後の (最初の) 要素と交換します。
セットに 1 つの要素が残るまで、残りの array[i]--array[n -2](array[i+1] --array[n-1]) セットで上記の手順を繰り返します。
void SelectSort(int* a, int n)
{
assert(a);//确保a存在
//排升序
int left = 0;
int right = n - 1;
while (left < right)
{
int maxDex = right;
int minDex = left;
//遍历剩余的数组每次找出最大的和最小的将最大的换到n-1的位置,将最小的放到j位置
for (int i = left; i <= right; ++i)
{
if (a[maxDex] < a[i] )
{
maxDex = i;//记录最大值的下标
}
if (a[minDex] > a[i] )
{
minDex = i;//记录最小值的下标
}
}
Swap(&a[minDex], &a[left]);
if (left == maxDex)//说明最大值的下标在最左边,上一步的交换让最大值已经不是最左边,而是下标minDex
maxDex = minDex;
Swap(&a[maxDex], &a[right]);
left++;
right--;
}
}その時間計算量はO(n*n) です。
void SelectSort(int* a, int n)
{
assert(a);//确保a存在
//排升序
int left = 0;
int right = n - 1;
while (left < right)
{
int maxDex = right;
int minDex = left;
//遍历剩余的数组每次找出最大的和最小的将最大的换到n-1的位置,将最小的放到j位置
for (int i = left; i <= right; ++i)
{
if (a[maxDex] < a[i] )
{
maxDex = i;//记录最大值的下标
}
if (a[minDex] > a[i] )
{
minDex = i;//记录最小值的下标
}
}
Swap(&a[minDex], &a[left]);
if (left == maxDex)//说明最大值的下标在最左边,上一步的交换让最大值已经不是最左边,而是下标minDex
maxDex = minDex;
Swap(&a[maxDex], &a[right]);
left++;
right--;
}
}3.3 交換ソート
3.3.1 バブルソート
詳細についてはバブルソートを 参照してください
3.3.2 クイックソート
詳細については、クイックソートを 参照してください
クイックソートには再帰的な実装方法の他に、非再帰的な実装方法もありますが、ではどのようにして非再帰的なクイックソートを実現するのでしょうか?一緒に試してみましょう。クイック ソートを実装する再帰的方法は、関数を通じてスタック フレームを呼び出すことによって実装されることは誰もが知っています。実際、非再帰も、関数をシミュレートすることによってスタック フレームを呼び出すプロセスをシミュレートし、データ構造。
データ構造スタックとオペレーティング システム スタックは同じものではありませんが、それらのプロパティは同じです (後入れ先出し)。スタックを通じてそれをシミュレートするにはどうすればよいですか?
コード:
// 快速排序 非递归实现
void QuickSortNonR(int* a, int begin, int end)
{
//创建并初始化栈
Stack st;
StackInit(&st);
//将区间[left,right]入栈
StackPush(&st, end);
StackPush(&st, begin);
//通过栈来模拟快排递归时的调用
//数据结构实现的栈和操作系统的栈的特性是一样的
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);//如栈的时候先右后左,出栈的时候先左后右
int midi = PartSort1(a, left, right);//对子区间进行快速排序的单趟排序
//将左右子区间都入栈
if (midi + 1 < right)//右边区间至少存在一个数
{
StackPush(&st, right);
StackPush(&st, midi + 1);
}
if (left < midi - 1)//左边区间至少存在一个数
{
StackPush(&st, midi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}3.4 マージソート
3.4.1 マージソート
マージ ソートは、マージ操作に基づく効果的な並べ替えアルゴリズムです。このアルゴリズムは、分割統治法の典型的な応用です。すでに順序付けされたサブシーケンスをマージして、完全に順序付けされたシーケンスを取得します。つまり、最初に各サブシーケンスを作成します。すべて順番に並んでいます。サブシーケンスをマージすると、区間全体が順番に並びます。2 つの順序付きリストが 1 つの順序付きリストにマージされる場合、それは双方向マージと呼ばれます。マージ ソートの中心的な手順は次のとおりです。

コード:
//单趟归并排序
void _MergeSortSignal(int *a, int begin1, int end1, int begin2, int end2, int *tmp)//闭区间
{
int begin = begin1;//保存数组起始的位置方便拷贝
tmp = (int*)malloc(sizeof(int) * (10 + 1));
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//将剩下的一个数组尾插到tmp
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = begin ; j <= end2; ++j)
{
a[j] = tmp[j];
}
free(tmp);
}
// 归并排序递归实现
void _MergeSort(int* a, int left, int right, int * tmp)
{
if (left >= right)//区间只剩下一个数
{
return;
}
int midi = (left + right) / 2;
_MergeSort(a, left, midi, tmp);
_MergeSort(a, midi + 1, right, tmp);
//合并有序的小区间
_MergeSortSignal(a, left, midi, midi + 1, right, tmp);
}
void MergeSort(int* a, int n)
{
//int* tmp = (int*)malloc( sizeof(int) * n);
_MergeSort(a, 0, n - 1,NULL);//闭区间[left,right]
//free(tmp);
}
マージソートの非再帰的な方法:
スタックを使用して問題をシミュレートすると、問題はさらに複雑になりますが、上図から、マージソートは、ソート対象の範囲が整然とするまで、ソート対象の範囲を減らし続ける処理であることが容易にわかります。そうですね、区間内に数字が 1 つしかない場合、それは順番にあるはずであることを見つけるのは難しくありません。そこで、この考えを採用し、最初に隣接する連続する数字をマージします。ギャップは 1 です。次回、隣接する数値はマージされます。2 つの数値はすでに順序が決まっています。このとき、間隔長 2 の 2 つの隣接するサブ間隔は、順序付けられた間隔にマージされます。 、ギャップ = 2 など、ギャップを増やすだけです。いつ終了しますか? そうですね、ギャップが配列の長さ以上になるまで、配列は順序どおりになっている必要があります。現時点では合併する意味がありません。
注: マージのためにサブ区間を分割する場合、2 番目の区間の長さが最初の区間の長さより短いか、2 番目の区間が存在しない可能性があるため、境界の修正に注意する必要があります。 2 番目の間隔または 2 番目の間隔のみサブ間隔の場合、今回はマージソートの必要はありません。
//将两个有序小区间合并为一个
void _MergeSortSignal(int *a, int begin1, int end1, int begin2, int end2, int *tmp)//闭区间
{
int begin = begin1;//保存数组起始的位置方便拷贝
tmp = (int*)malloc(sizeof(int) * (10 + 1));
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//将剩下的一个数组尾插到tmp
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
for (int j = begin ; j <= end2; ++j)
{
a[j] = tmp[j];
}
free(tmp);
}
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
//实现思路:这里如果借助栈来模拟会将问题变得复杂起来,所以可以采取循环的方式
//直接归并,第一次是相邻的两个数归并,这时候gap为1,第二次gap为而就是区间[i,i+gap-1] 和区间[i+gap,i+2*gap -1]进行插入排序,依次类推
//直到gap不小于数组的长度就结束
int gap = 1;
while (gap < n)
{
//单趟归并排序
for (int i = 0; i < n;++i)
{
//采用闭区间
//[i,i+gap-1] 和[i+gap,i+2*gap]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//调用将两个数组合并成一个数组的函数
if (begin2 >= n)
{
break;//说明要排序第二组不存在,只有第一组,本次不需要再排
}
if (end2 >= n)
{
//需要修正第二组的边界
end2 = n - 1;
}
_MergeSortSignal(a, begin1, end1, begin2, end2, NULL);
}
gap *= 2;
}
}
3.4.2 マージソートアプリケーション - 外部ソート
マージ ソートは他のソートとは異なります。他のソートはメモリ内でのソートに適していますが、マージ ソートはメモリ内でのソートだけでなく、データが大量になるとメモリに収まらず、ファイルにのみ保存できます。今回は他のソートはあまり使いにくいですが、マージソートはデータをソートしてファイル内で行うことができるので、マージソートも外部ソートになります。
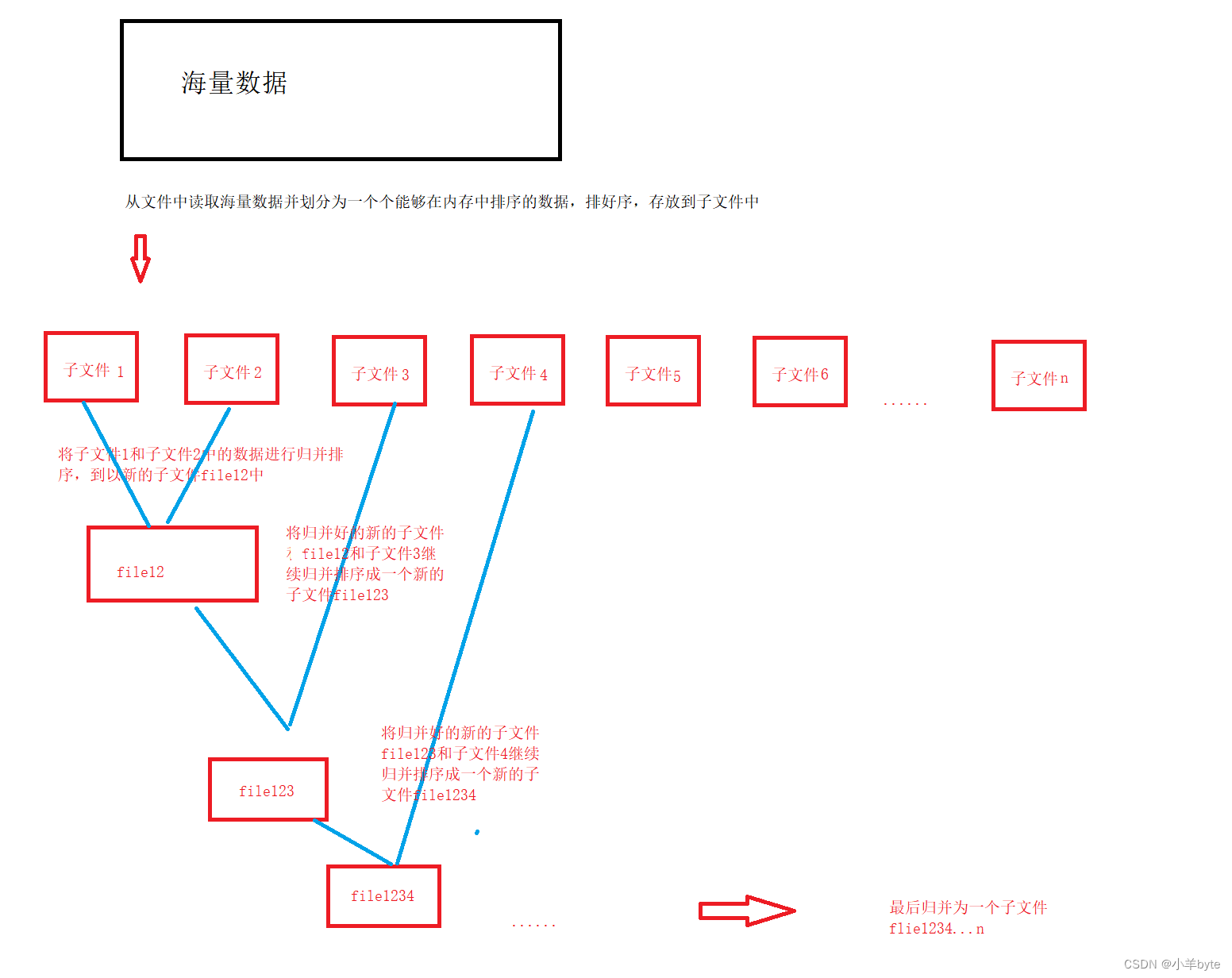
ここで、一度にメモリにロードできない大量のデータがあると想定してシナリオをシミュレーションし、データを並べ替えて結果をファイルに保存するプログラムを作成してください。
アイデアは次のとおりです。
1. まず、データを多くの部分に分割する必要がありますが、分割された各部分は一度にメモリにロードして並べ替えることができます。
2. 分割したデータをサブファイルに一括格納し、クイックソートでデータを整理します。
3. この時点で、マージ ソートの前提条件が満たされており、各サブシーケンスが整っています。この時点で必要なのは、2 つのファイルのデータを毎回読み取り、比較し、新しいファイルにマージすることだけです。最後に、すべての順序付けされたサブ間隔が 1 つのファイルにマージされるまで、同じ方法で続行します。この時点で、このファイル内のデータはすべて順序付けされています。
コード:
//将两个文件中的有序数据合并到一个文件中并且保持有序
void _MergeFile(const char* file1, const char* file2, const char* mfile)
{
FILE* fout1 = fopen(file1, "r");
if (fout1 == NULL)
{
printf("fout1打开文件失败\n");
exit(-1);
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("fout2打开文件失败\n");
exit(-1);
}
FILE* fin = fopen(mfile, "w");
if(fin == NULL)
{
printf("fin打开文件失败\n");
exit(-1);
}
int num1, num2;
int ret1 = fscanf(fout1, "%d\n", &num1);
int ret2 = fscanf(fout2, "%d\n", &num2);
//在文件中读数据进行归并排序
while (ret1 != EOF && ret2 != EOF)
{
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);
//再去fout1所指的文件中读取数据
ret1 = fscanf(fout1, "%d\n", &num1);
}
else
{
fprintf(fin, "%d\n", num2);
//再去fout2所指的文件中读取数据
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
while (ret1 != EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout2, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
void MergeSortFile(const char* file)//文件归并排序
{
//打开文件
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
int n = 10;
int a[10] = { 0 };
char subr[1024] ;
/*memset(subr, 0, 1024);
memset(a, 0, sizeof(int) * n);*/
int num = 0;
int i = 0;
int fileI = 1;
while (fscanf(fout, "%d\n",&num )!=EOF)
{
if (i < n - 1)
{
a[i++] = num;
}
else
{
a[i] = num;
QuickSort(a, 0, n - 1);//对内存中的数据进行排序
sprintf(subr, "%d", fileI++);
FILE* fin = fopen(subr, "w");
if (fin == NULL)
{
printf("打开文件失败\n");
exit(-1);
}
//写数据到文件中
for (int j = 0; j < n; ++j)
{
fprintf(fin, "%d\n", a[j]);
}
//关闭文件
i = 0;//置零对下一组数据进行操作
/*memset(subr, 0, 1024);
memset(a, 0, sizeof(int) * n);*/
fclose(fin);
}
}
//外排序
//利用互相归并到文件中,实现整体有序
char file1[100] = "1";
char file2[100];
char mfile[100] = "12";
for (int i = 2; i <= n; ++i)
{
sprintf(file2, "%d", i);
//读取FIle和file2,进行归并排序出mfile
_MergeFile(file1, file2, mfile);
strcpy(file1,mfile);
sprintf(mfile, "%s%d", mfile, i + 1);
}
fclose(fout);
return NULL;
}
3.5 非比較ソート
非比較ソートはその名のとおり、要素を比較せずにソートすることができますが、ここで紹介するのはカウントソートです。
鳩の巣原理としても知られるカウンティング ソートは、ハッシュ直接値手法を変形して応用したものです。手順:
1. 同じ要素の出現数を数える
2. 統計結果に基づいて配列を元の配列にリサイクルします。

コード:
// 计数排序
void CountSort(int* a, int n)
{
//先遍历数组,找出最大值和最小值用来确定范围
int max = a[0];
int min = a[0];
for (int i = 0; i < n; ++i)
{
if (max < a[i])
{
max = a[i];
}
if (min > a[i])
{
min = a[i];
}
}
//然后根据最大值和最小值的范围开辟空间
int range = max - min + 1;
int* CountArray = (int*)calloc(sizeof(int), range);
//统计原数组中每个数出现的次数
for (int i = 0; i < n; ++i)
{
CountArray[ a[i] - min ] ++ ;//利用相对位置来计算数据出现的个数
}
/*Print(CountArray, 9);
printf("\n");*/
//将临时数组中的数,覆盖到原数组中
int j = 0;
for (int i = 0; i < range; ++i)
{
while (CountArray[ i ]--)
{
a[j++ ] = i + min;//将每个数据从临时数组中拿出来加上相对数据min,然后对数组进行覆盖
}
}
//释放临时开辟的空间
free(CountArray);
}
カウンティングソートの機能の概要:
1. カウントソートはデータ範囲が集中している場合に非常に効率的ですが、適用範囲とシナリオが制限されます。
2. 時間計算量 O (max(N, range))
3. 空間複雑度 O(範囲)
4. ソートアルゴリズムの複雑さと安定性の分析

安定性とは何ですか?一般に、配列内の同じ要素の相対的な位置は、ソート後も変化しません。では、安定性または不安定性の影響は何でしょうか? これは、一部の特殊なシナリオに影響を与えます。たとえば、試験では、上位 3 名に賞が与えられる必要があります。上位 3 名を決定するにはどうすればよいですか? たとえば、上位 5 位のスコアは、99 98 97 97 97 です。これらの場合、3 位、4 位、5 位のスコアは同じであるため、上位 3 位を直接決定することは不可能であるため、別のルールが存在します。このとき このゲームは結果が同じ場合、タイムが短い方が前になるというルールです。したがって、この場合、上位 3 位は安定したソートによって決定でき、誰にとっても公平ですが、不安定なソートの場合、結果は不公平になります。
選択ソートが不安定で、一連のシーケンス内に同じ最大値が複数出現する場合、どれを選択するかが問題になる場合、または以下のようになります。
ヒープのソートも不安定です。ヒープを構築するとき、または数値を選択するときに、下方に調整する必要があります。下方に調整すると、図に示すように、同じ要素の相対的な順序が変わる可能性があります。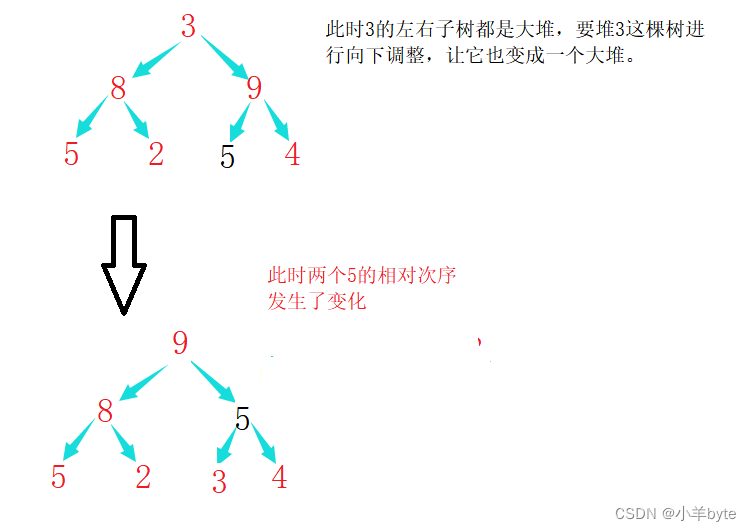
比較のためにベンチマークを選択すると相対的な順序が変わる可能性があるため、クイック ソートも不安定です。
ヒルソートも不安定です。事前ソート中に異なるグループに同じ番号が割り当てられる可能性があるため、相対的な順序を保証する方法がありません。カウントソートでは元の配列内の各要素の出現数がカウントされるため、同じ要素の相対位置を保証する方法はありません。