1. ソートの概念とその応用

1.1 ソートの概念
並べ替え: いわゆる並べ替えは、1 つまたはいくつかのキーワードのサイズに従って、レコードの文字列を昇順または降順に配置する操作です。
安定性: ソートされるレコードのシーケンスに同じキーワードを持つ複数のレコードがあると仮定します。ソートされた場合、これらのレコードの相対的な順序は変更されません。つまり、元のシーケンスでは r[i]=r[j] になります。 、かつ r[i] が r[j] より前にあり、ソートされたシーケンス内で r[i] がまだ r[j] より前にある場合、ソート アルゴリズムは安定していると言われ、それ以外の場合は不安定と呼ばれます。
内部ソート: すべてのデータ要素がメモリ内に配置されるソート。
外部ソート: 同時にメモリに配置できるデータ要素が多すぎるため、ソート プロセスの要件に従って内部メモリと外部メモリ間でデータのソートを移動できません。
1.2 仕分けアプリケーション
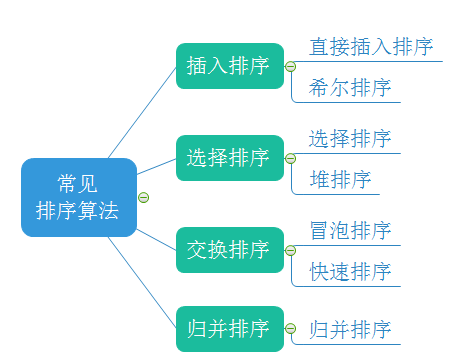
1.3 一般的な並べ替えアルゴリズム
// 排序实现的接口 // 插入排序 void InsertSort(int* a, int n); // 希尔排序 void ShellSort(int* a, int n); // 选择排序 void SelectSort(int* a, int n); // 堆排序 void AdjustDwon(int* a, int n, int root); void HeapSort(int* a, int n); // 冒泡排序 void BubbleSort(int* a, int n) // 快速排序递归实现 // 快速排序hoare版本 int PartSort1(int* a, int left, int right); // 快速排序挖坑法 int PartSort2(int* a, int left, int right); // 快速排序前后指针法 int PartSort3(int* a, int left, int right); void QuickSort(int* a, int left, int right); // 快速排序 非递归实现 void QuickSortNonR(int* a, int left, int right) // 归并排序递归实现 void MergeSort(int* a, int n) // 归并排序非递归实现 void MergeSortNonR(int* a, int n) // 计数排序 void CountSort(int* a, int n) // 测试排序的性能对比 void TestOP() { srand(time(0)); const int N = 100000; int* a1 = (int*)malloc(sizeof(int)*N); int* a2 = (int*)malloc(sizeof(int)*N); int* a3 = (int*)malloc(sizeof(int)*N); int* a4 = (int*)malloc(sizeof(int)*N); int* a5 = (int*)malloc(sizeof(int)*N); int* a6 = (int*)malloc(sizeof(int)*N); for (int i = 0; i < N; ++i) { a1[i] = rand(); a2[i] = a1[i]; a3[i] = a1[i]; a4[i] = a1[i]; a5[i] = a1[i]; a6[i] = a1[i]; } int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); int begin3 = clock(); SelectSort(a3, N); int end3 = clock(); int begin4 = clock(); HeapSort(a4, N); int end4 = clock(); int begin5 = clock(); QuickSort(a5, 0, N-1); int end5 = clock(); int begin6 = clock(); MergeSort(a6, N); int end6 = clock(); printf("InsertSort:%d\n", end1 - begin1); printf("ShellSort:%d\n", end2 - begin2); printf("SelectSort:%d\n", end3 - begin3); printf("HeapSort:%d\n", end4 - begin4); printf("QuickSort:%d\n", end5 - begin5); printf("MergeSort:%d\n", end6 - begin6); free(a1); free(a2); free(a3); free(a4); free(a5); free(a6); }OJ のソート (この OJ を実行するにはさまざまなソートを使用できます) OJ リンク
2. 一般的なソートアルゴリズムの実装
2.1 挿入ソート
2.1.1 基本的な考え方:
直接挿入ソートは単純な挿入ソート方法であり、その基本的な考え方は次のとおりです。
すべてのレコードが挿入され、新しいシーケンスが取得されるまで、キー値のサイズに従って、並べ替えるレコードを 1 つずつ並べ替えシーケンスに挿入します。
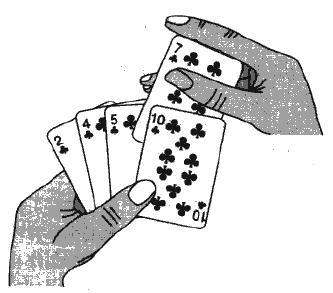
実際にポーカーをプレイするときは、挿入ソートの考え方を使用します。
2.1.2 直接挿入ソート:
i 番目 (i>=1) の要素を挿入するとき、前の array[0]、array[1]、...、array[i-1] はソートされており、このとき配列のソート コードを使用します。 [i]とArray[i-1]、array[i-2]、...はソートコードの順序を比較し、挿入位置を見つけてarray[i]を挿入し、元の位置の要素の順序を計算します。後方に移動されます
直接挿入ソートの特徴の概要:
- 要素セットの順序が近いほど、直接挿入ソート アルゴリズムの時間効率が高くなります。
- 時間計算量: O(N^2)
- 空間計算量: O(1)、安定した並べ替えアルゴリズムです
- 安定性: 安定
//插入排序 void InsertSort(int* a, int length) { for (int i = 1; i < length; i++) { int end = i - 1; int num = a[i]; while (end >= 0) { if (num < a[end]) { a[end + 1] = a[end];//挪动数组 end--; } else { break;//找到了要插入的点 } } a[end + 1] = num; } }2.1.3 ヒルソート (増分ソートの削減)
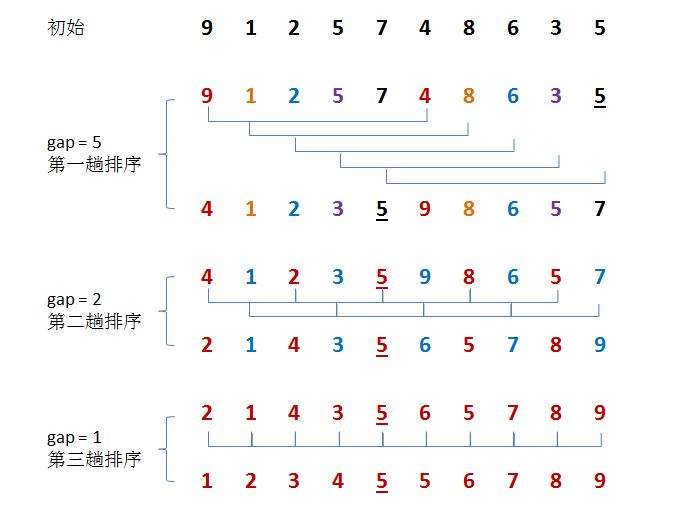
ヒル ソート法は、縮小増分法としても知られています。Hill ソート法の基本的な考え方は次のとおりです。まず整数を選択し、ソートするファイル内のすべてのレコードをグループに分割し、距離が 0 のすべてのレコードを同じグループにグループ化し、各グループ内のレコードをソートします。 。次に、上記のグループ化と並べ替えの作業を繰り返します。リーチ = 1 の場合、すべてのレコードは同じグループ内でソートされます。
//希尔排序 void ShellSort(int* a, int length) { //接近有序 int gap = length; while (gap > 1) { gap /= 2; for (int i = 0; i < length - gap; i++) { int end = i; int num = a[i + gap]; while (end >= 0) { if (a[end] > num) { a[end + gap] = a[end]; end -= gap; } else { break; } } a[end + gap] = num; } } }ヒルソートの特徴の概要:
ヒル ソートは直接挿入ソートを最適化したものです。
ギャップ > 1 の場合、事前に並べ替えられます。目的は、配列を順序に近づけることです。ギャップ == 1 の場合、配列はすでに順序に近いため、非常に高速になります。これにより、全体の最適化効果が得られる。実装した後は、パフォーマンス テストを比較できます。
ヒル ソートの時間計算量は、ギャップを評価する方法が多数あり、計算が困難であるため、計算が容易ではありません。したがって、多くのツリーで与えられるヒル ソートの時間計算量は固定されていません。
「データ構造 (C 言語編)」 — ヤン・ウェイミン

「データ構造 - オブジェクト指向手法と C++ 記述の使用」 - ying Renkun

私たちのギャップは Knuth によって提案された方法に従って評価され、Knuth は多数の実験統計を行っているため、一時的に次のようになります: O ( n 1.25 ) O(n^{1.25})O ( n1.25) 到 O ( 1.6 ∗ n 1.25 ) O(1.6*n^{1.25}) ○ (1.6∗n1.25)来算。
- 安定性: 不安定
2.2 選択ソート
2.2.1 基本的な考え方:
毎回、ソート対象のデータ要素から最小 (または最大) の要素を選択し、ソート対象のデータ要素がすべてなくなるまでシーケンスの先頭に格納します。
2.2.2 直接選択ソート:
要素セット array[i] – array[n-1] 内で最大 (最小) のキーを持つデータ要素を選択します
セット内の最後の (最初の) 要素ではない場合は、セット内の最後の (最初の) 要素と交換します。
残りの array[i]–array[n-2] (array[i+1]–array[n-1]) コレクションで、コレクションに 1 つの要素が残るまで上記の手順を繰り返します。
//选择排序 void SelectSort(int* a, int length) { int left = 0, right = length - 1; while (left < right) { int maxi = left, mini = left; for (int i = left + 1; i <= right; i++) { if (a[i] < a[mini]) { mini = i; } if (a[i] > a[maxi]) { maxi = i; } } Swap(&a[left], &a[mini]); if (left == maxi) maxi = mini; Swap(&a[right], &a[maxi]); left++; right--; } }直接選択ソートの機能の概要:
- 直接選択ソートの考え方は非常に分かりやすいですが、効率はあまり良くありません。実際にはほとんど使用されない
- 時間計算量: O(N^2)
- 空間の複雑さ: O(1)
- 安定性: 不安定
2.2.3 ヒープソート
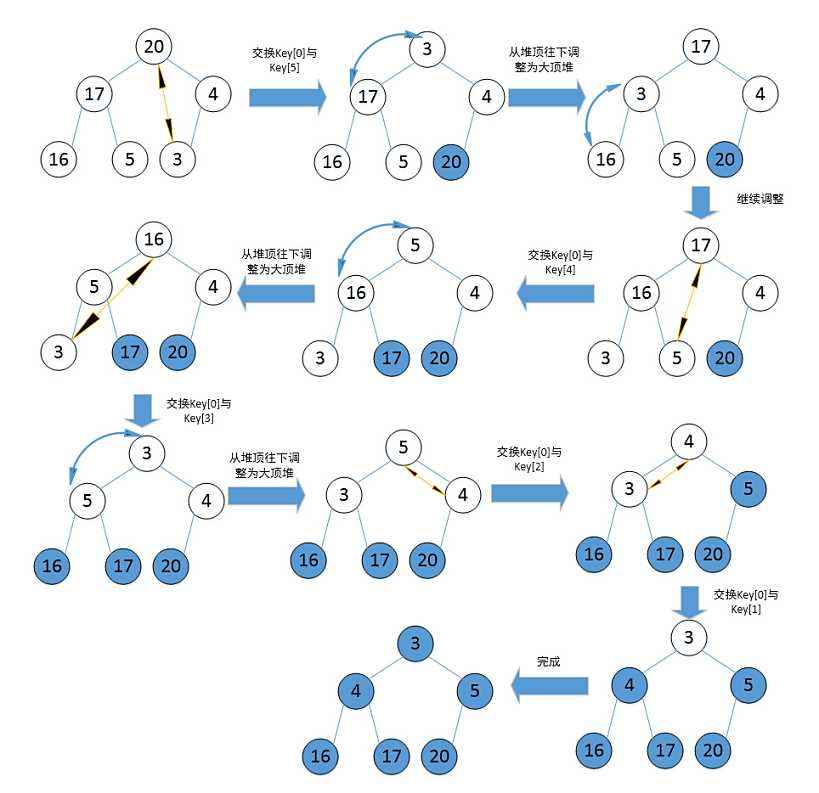
ヒープソート (Heapsort) は、選択ソートの一種である、積み重ねられたツリー (ヒープ) データ構造を使用して設計されたソート アルゴリズムを指します。ヒープを通じてデータを選択します。昇順の場合は大きなヒープを構築し、降順の場合は小さなヒープを構築する必要があることに注意してください。
//堆排序 void AdjustDown(int* a, int sz, int parent) { //调大堆 assert(a); int child = parent * 2 + 1; while (child < sz)//儿子节点要存在 { //找左右儿子中最大的那个 if (child + 1 < sz && a[child] < a[child + 1]) { child++;//找到了最大的那个 } if (a[child] > a[parent]) { Swap(&a[child], &a[parent]); parent = child; child = parent * 2 + 1; } else { break; } } } void SetHeap(int* a, int sz) { assert(a); for (int i = (sz - 1 - 1) / 2; i >= 0; i--) { AdjustDown(a, sz, i); } } void heap_sort(int* a, int sz) { int num = sz; SetHeap(a, sz); while (num) { Swap(&a[0], &a[num-1]); num--; AdjustDown(a, num, 0); } }直接選択ソートの機能の概要:
- ヒープ ソートはヒープを使用して数値を選択するため、はるかに効率的です。
- 時間計算量: O(N*logN)
- 空間の複雑さ: O(1)
- 安定性: 不安定
2.3 ソートの入れ替え
基本的な考え方: いわゆる交換とは、シーケンス内の 2 つのレコードのキー値の比較結果に従って、シーケンス内の 2 つのレコードの位置を交換することです。キー値が小さいレコードは、シーケンス内の 2 つのレコードの位置を交換します。シーケンスの先頭。
2.3.1 バブルソート
//冒泡排序 void BubbleSort(int* a, int n) { for (int i = 0; i < n - 1; i++) { bool exchange = false; for (int j = 0; j < n - i - 1; j++) { if (a[j] > a[j + 1]) { Swap(&a[j], &a[j + 1]); exchange = true; } } if (exchange == false) { break; } } }バブルソートの特徴をまとめると次のようになります。
- バブルソートはとてもわかりやすいソートです
- 時間計算量: O(N^2)
- 空間の複雑さ: O(1)
- 安定性: 安定
2.3.2 クイックソート
クイックソートは、1962 年に Hoare によって提案された 2 分木構造交換ソート手法です。その基本的な考え方は、ソートされる要素のシーケンス内の任意の要素が基準値とみなされ、ソートされる集合が基準値に従って 2 つの部分列に分割されるというものです。ソートコードに従って、左側のサブシーケンスのすべての要素が基準値より小さく、右側のサブシーケンスのすべての要素が基準値より大きく、その後、最も左のサブシーケンスがすべての要素が対応する位置に配置されるまでプロセスを繰り返します。
// 假设按照升序对array数组中[left, right)区间中的元素进行排序 void QuickSort(int array[], int left, int right) { if(right - left <= 1) return; // 按照基准值对array数组的 [left, right)区间中的元素进行划分 int div = partion(array, left, right); // 划分成功后以div为边界形成了左右两部分 [left, div) 和 [div+1, right) // 递归排[left, div) QuickSort(array, left, div); // 递归排[div+1, right) QuickSort(array, div+1, right); }上記は、クイックソートを再帰的に実現するための主要なフレームワークです。これは、バイナリ ツリーの事前順序トラバーサル ルールと非常によく似ていることがわかります。再帰フレームワークを作成するとき、学生は、バイナリ ツリーの事前順序トラバース ルールについて考えることができ、ポストオーダーは基準値をどのように追従するかを分析するだけでよく、データを区間内で分割する方法だけで十分です。
基本値に従って間隔を左半分と右半分に分割する一般的な方法は次のとおりです。
- ホアバージョン
//hoare版本 void QuickSort(int* a, int left,int right) { if (left >= right) return; int begin = left, end = right; int keyi = left; int mid = GetMid(a, left, right); Swap(&a[left], &a[mid]); while (left < right) { while (left < right && a[right] >= a[keyi]) { right--; } while (left < right && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[left], &a[keyi]); keyi = right; QuickSort(a, begin, keyi - 1); QuickSort(a, keyi + 1, end); }
- 穴掘り
//挖坑法 void QuickSort(int* a, int left, int right) { if (left >= right) return; int key = a[left]; int begin = left, end=right; while (left < right) { while (left < right && a[right] >= key) { right--; } a[left] = a[right]; while (left < right && a[left] <= key) { left++; } a[right] = a[left]; } a[left] = key; int keyi = left; QuickSort(a, begin, keyi - 1); QuickSort(a, keyi + 1, end); }
- 前後ポインタバージョン

//前后指针快速排序 void QuickSort(int* a, int left, int right) { if (left >= right) { return; } int cur = left + 1, prev = left; int keyi = left; while (cur <= right) { if (a[cur] < a[keyi] && cur > prev) { prev++; Swap(&a[cur], &a[prev]); } cur++; } Swap(&a[prev], &a[keyi]); int mid = prev; QuickSort(a, left, mid - 1); QuickSort(a, mid+1, right); }2.3.2 クイックソートの最適化
- 3 つの数字は中間の方法でキーを選択します
int GetMid(int* a,int left,int right) { int mid = left + right >> 1; if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else//a[left]>a[mid] { if (a[mid] > a[right]) { return mid; } else if (a[left] < a[mid]) { return left; } else { return right; } } }
- 小さな部分範囲に再帰する場合は、挿入ソートの使用を検討してください。
//小区间优化 void QuickSort(int* a, int left, int right) { if (left >= right) { return; } if ((right - left + 1) > 10) { int cur = left + 1, prev = left; int keyi = left; while (cur <= right) { if (a[cur] < a[keyi] && cur > prev) { prev++; Swap(&a[cur], &a[prev]); } cur++; } Swap(&a[prev], &a[keyi]); int mid = prev; QuickSort(a, left, mid - 1); QuickSort(a, mid + 1, right); } else { InsertSort(a + left, right - left + 1); } }2.3.2 非再帰的なクイックソート
void QuickSortNonR(int* a, int left, int right) { Stack st; StackInit(&st); StackPush(&st, left); StackPush(&st, right); while (StackEmpty(&st) != 0) { right = StackTop(&st); StackPop(&st); left = StackTop(&st); StackPop(&st); if(right - left <= 1) continue; int div = PartSort1(a, left, right); // 以基准值为分割点,形成左右两部分:[left, div) 和 [div+1, right) StackPush(&st, div+1); StackPush(&st, right); StackPush(&st, left); StackPush(&st, div); } StackDestroy(&s); }int OnceSort(int* a, int left, int right) { if (left > right) { return; } int key = a[left]; while (left < right) { //先算右边,右边找大 while (left<right&&a[right] >= key) { right--; } //找到了就交换 a[left] = a[right]; while (left<right&&a[left] <= key) { left++; } a[right] = a[left]; } a[left] = key;//将key放在正确的位置上 int meeti = left;//相遇的点 return meeti; } void QuickSort(int* a, int left, int right) { ST st;//创建一个栈来模拟递归的过程 STInit(&st); STPush(&st,right); STPush(&st,left); while (!STEmpty(&st)) { //左区间 int begin = STTop(&st); STPop(&st); int end = STTop(&st); STPop(&st); int mid = OnceSort(a, begin, end); if(end > mid + 1) { STPush(&st, end); STPush(&st, mid + 1); } //如果left>=mid-1说明左边已经排完序了 if(begin < mid - 1) { STPush(&st,mid - 1); STPush(&st, begin); } } STDestroy(&st); }なぜここでは判決文
ifの条件が採用されないのでしょうか=?等号を取ると次のようになります。
無駄な判定が多くなる beginとendが等しい場合要素は1つだけ 要素はソートする必要がないので番号を取る必要が
=ない数値が取得されない場合
=:
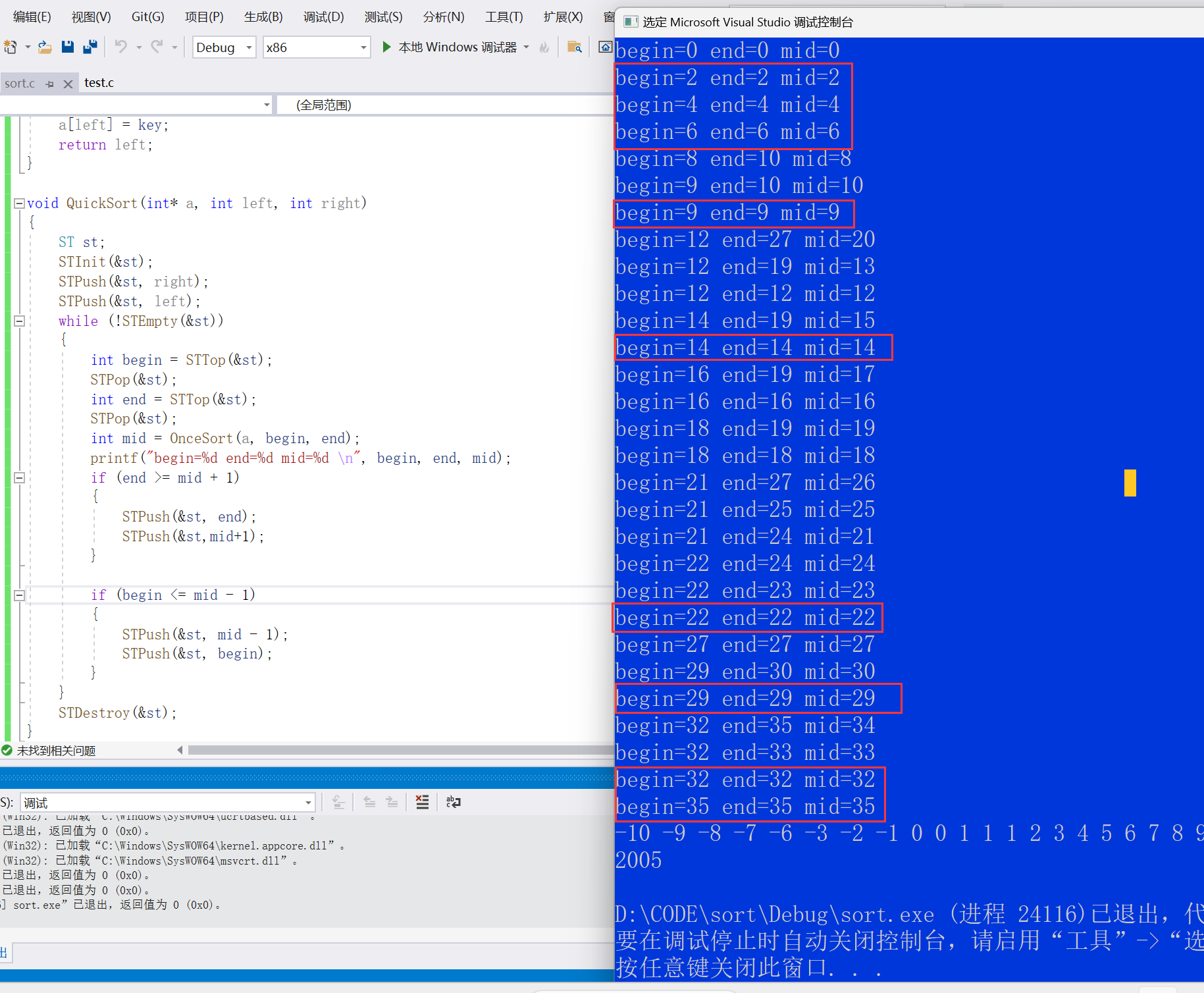

クイックソート機能の概要:
クイック ソートの全体的な総合的なパフォーマンスと使用シナリオは比較的良好であるため、あえてクイックソートと呼びます。
時間計算量: O(N*logN)
空間複雑度: O(logN)
安定性: 不安定
2.4 マージソート
基本的な考え方:
マージ ソート (MERGE-SORT) は、マージ操作に基づく効果的な並べ替えアルゴリズムであり、分割統治 (Divide and Conquer) の非常に典型的なアプリケーションです。順序付けられたサブシーケンスを結合して、完全に順序付けられたシーケンスを取得します。つまり、最初に各サブシーケンスを順番に作成し、次にサブシーケンス セグメントを順番に作成します。2 つのソート済みリストを 1 つのソート済みリストにマージすることを、双方向マージと呼びます。
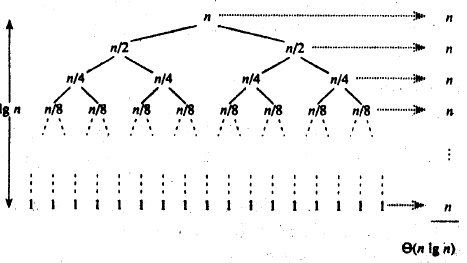
マージと並べ替えの中心的な手順: [外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-svQBGJGJ-1683775858015) (C:/Users/ 19735/デスクトップ/%E6%95% B0%E6%8D%AE%E7%BB%93%E6%9E%84%E5%88%9D%E9%98%B6V5-2021%E4%BF%AE%E8 %AE%A2/レッスン6–%E6 %8E%92%E5%BA%8F/12.jpg)]

//归并排序递归 void _MergeSort(int* a, int begin, int end, int* tmp) { if (begin >= end) { return; } int mid = begin + end >> 1; _MergeSort(a, begin, mid,tmp); _MergeSort(a, mid+1, end,tmp); int begin1 = begin, end1 = mid; int begin2 = mid + 1, end2 = end; int i = begin; while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[i++] = a[begin1++]; } else { tmp[i++] = a[begin2++]; } } //处理剩余的 while (begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1)); } void MergeSort(int* a, int sz) { int* tmp = (int*)malloc(sizeof(int) * sz); if (tmp == NULL) { perror("malloc fail"); exit(-1); } _MergeSort(a, 0, sz - 1, tmp); free(tmp); }
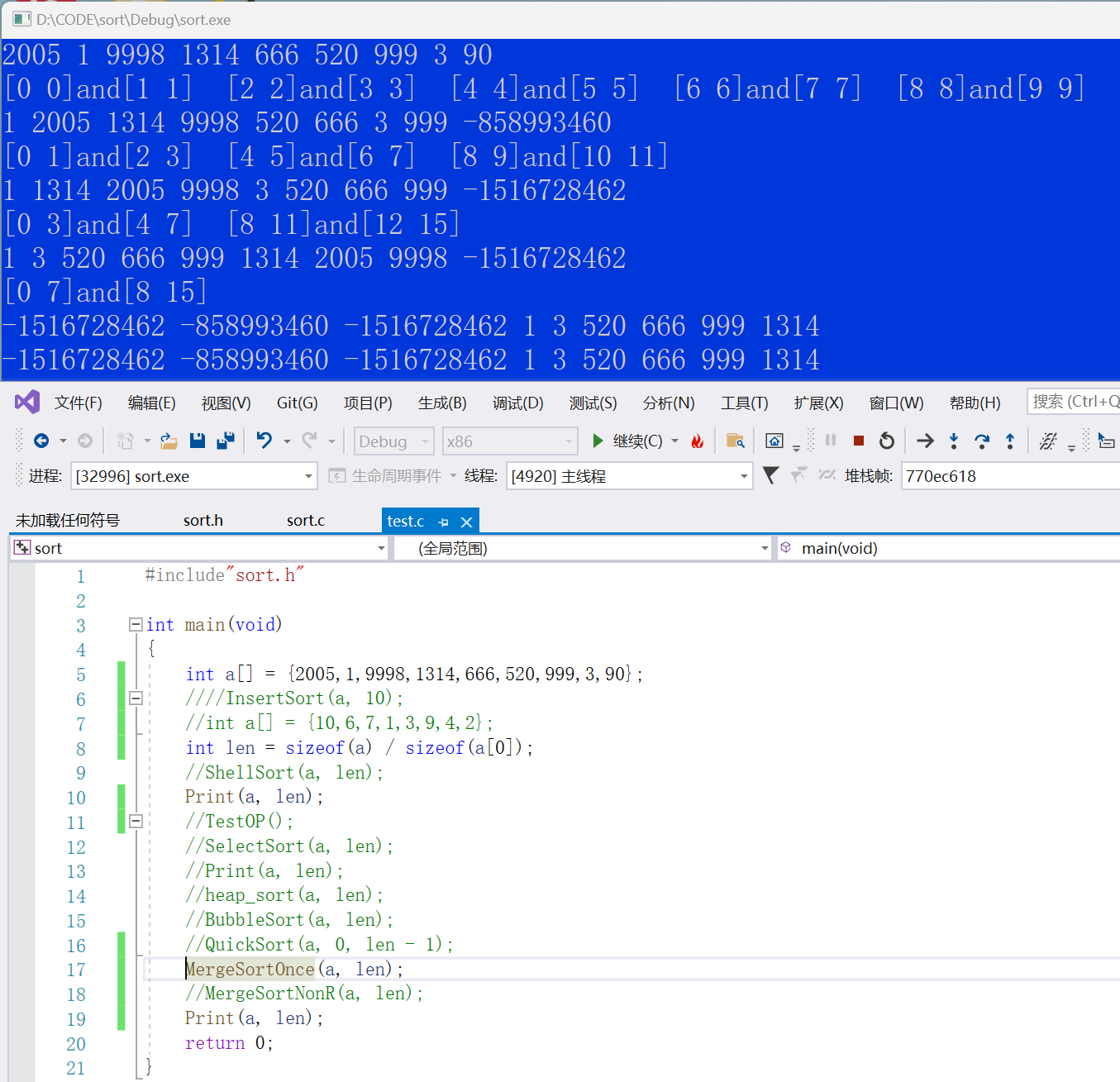
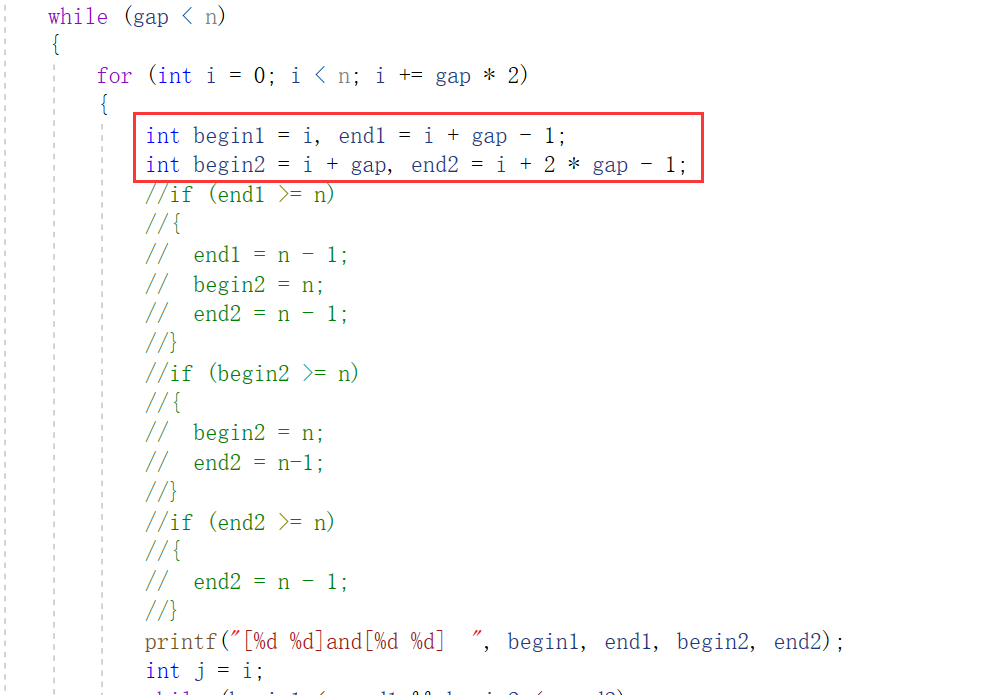
//归并排序非递归 void MergeSortNonR(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail"); exit(-1); } int gap = 1;//分组,组间距 while (gap < n) { for (int i = 0; i < n; i += gap * 2) { int begin1 = i, end1 = i + gap - 1; int begin2 = i + gap, end2 = i + 2 * gap - 1; int j = i; if (begin1>=n||end1 >= n || begin2 >= n) { break; } if (end2 >= n) { end2 = n - 1; } printf("[%d %d] [%d %d]\n", begin1, end1, begin2, end2); while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) { tmp[j++] = a[begin1++]; } else { tmp[j++] = a[begin2++]; } } while (begin1 <= end1) { tmp[j++] = a[begin1++]; } while (begin2 <= end2) { tmp[j++] = a[begin2++]; } memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1)); } gap *= 2; } free(tmp); }
間隔が修正されない場合:
元の配列は元々9要素しかなく、有効範囲が であることがわかりますが
[0,8]、上記の操作では明らかにこの範囲を超える範囲があるのですが、これはなぜでしょうか。
ギャップが大きい場合、ボックス内のコードは境界を越えますが、
begin2ギャップはまだ小さいため、end2プログラムは続行されます。コード実行プロセス:

マージソートの特徴の概要:
- マージの欠点は、O(N) のスペースの複雑さが必要なことであり、マージとソートの考え方は、ディスク内の外部ソートの問題を解決することを目的としています。
- 時間計算量: O(N*logN)
- 空間の複雑さ: O(N)
- 安定性: 安定
2.5 非比較ソート
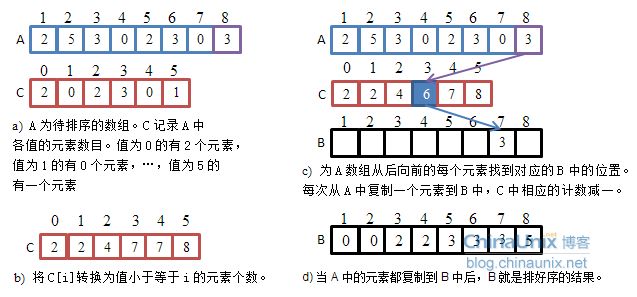
アイデア: 鳩の巣原理としても知られるカウンティング ソートは、ハッシュ ダイレクト アドレス指定方法を修正して応用したものです。
手順:
- 同じ要素の出現数を数える
- 統計結果に従ってシーケンスを元のシーケンスにリサイクルします
//计数排序 void CountSort(int* a, int n) { int max = a[0], min = a[0]; for (int i = 1; i < n; ++i) { if (a[i] > max) { max = a[i]; } if (a[i] < min) { min = a[i]; } } int range = max - min + 1; int* countA = (int*)malloc(sizeof(int) * range); if (countA == NULL) { perror("malloc fail\n"); return; } memset(countA, 0, sizeof(int) * range); // 计数 for (int i = 0; i < n; i++) { countA[a[i] - min]++; } // 排序 int j = 0; for (int i = 0; i < range; i++) { while (countA[i]--) { a[j++] = i + min; } } free(countA); }カウンティングソートの機能の概要:
- カウントソートはデータ範囲が集中している場合に非常に効率的ですが、適用範囲やシナリオが制限されます。
- 時間計算量: O(MAX(N,range))
- 空間複雑度: O(範囲)
- 安定性: 安定
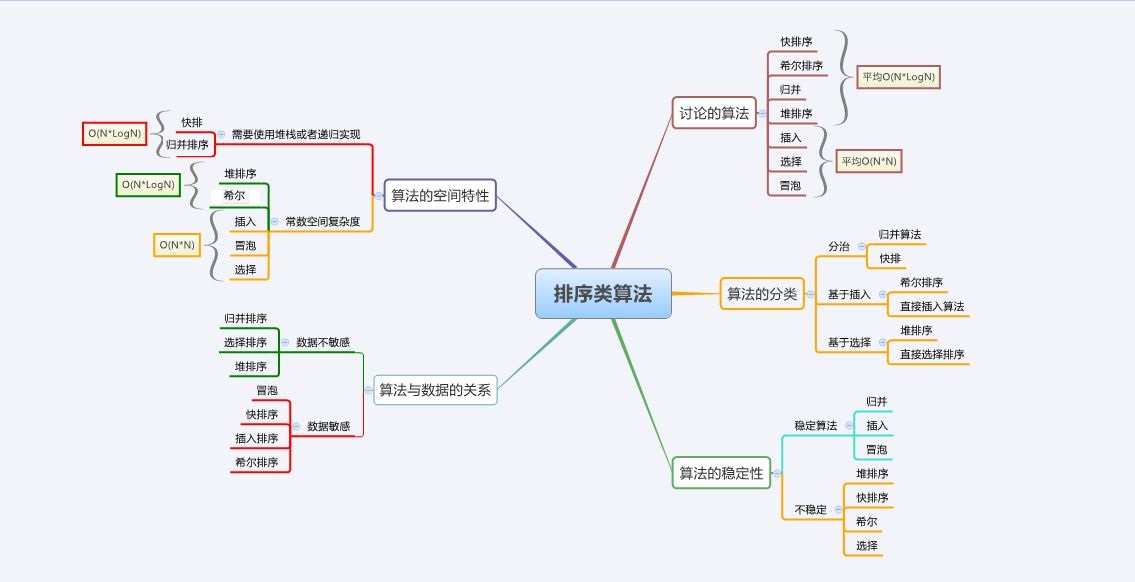
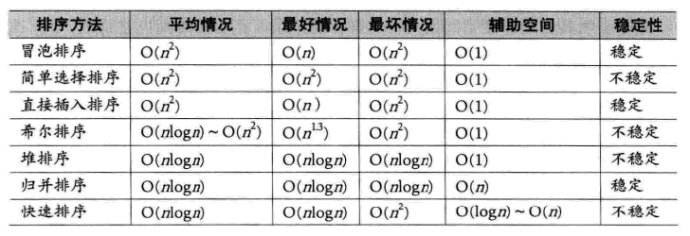
3. ソートアルゴリズムの複雑さと安定性の分析
4. 多肢選択の練習
1. 快速排序算法是基于( )的一个排序算法。 A 分治法 B 贪心法 C 递归法 D 动态规划法 2.对记录(54,38,96,23,15,72,60,45,83)进行从小到大的直接插入排序时,当把第8个记录45插入到有序表时,为找到插入位置需比较( )次?(采用从后往前比较) A 3 B 4 C 5 D 6 3.以下排序方式中占用O(n)辅助存储空间的是 A 选择排序 B 快速排序 C 堆排序 D 归并排序 4.下列排序算法中稳定且时间复杂度为O(n2)的是( ) A 快速排序 B 冒泡排序 C 直接选择排序 D 归并排序 5.关于排序,下面说法不正确的是 A 快排时间复杂度为O(N*logN),空间复杂度为O(logN) B 归并排序是一种稳定的排序,堆排序和快排均不稳定 C 序列基本有序时,快排退化成冒泡排序,直接插入排序最快 D 归并排序空间复杂度为O(N), 堆排序空间复杂度的为O(logN) 6.下列排序法中,最坏情况下时间复杂度最小的是( ) A 堆排序 B 快速排序 C 希尔排序 D 冒泡排序 7.设一组初始记录关键字序列为(65,56,72,99,86,25,34,66),则以第一个关键字65为基准而得到的一趟快速排序结果是() A 34,56,25,65,86,99,72,66 B 25,34,56,65,99,86,72,66 C 34,56,25,65,66,99,86,72 D 34,56,25,65,99,86,72,66答案: 1.A 2.C 3.D 4.B 5.D 6.A 7.A