従来、同社のネットワーク制限により、一部のWebサイトではユーザー名とパスワードによるログインはできず、ブラウザからはWebサイトを開くことができましたが、ログインしていないユーザーはWebサイトを開くことができないという問題がありました。ブログのコードをコピーしますが、これは少し面倒でした。
幸いなことに、これらのコードは、Web ページのソース コードを表示することで入手できます。以下に示すように、csdn のコードが表示されます。
HTML要素の内容を取得する方法は次のとおりです。
1. F12 を開き、開発者のデバッグ インターフェイスに入ります。
2. 要素タブページに切り替えます。
3. マウスを使用してコード部分を選択します。
4. 要素をコピーします。
このコンテンツを解析する際には主にhtmlタグで囲まれているため、タグ部分を削除する必要があります。
HTMLタグには特徴があり、タグはペアで表示され、すべてのタグを削除するとコンテンツ部分だけが残ります。この考えを念頭に置いて、作業を開始できます。
ここでは、<div> または </div> に似たタグを削除するために、通常の置換を使用することを検討してください。通常の <.*> を直接渡すと、すべてが強制終了される可能性があります。<div>xxx</div> は実際には <.*> と一致するためです。両側の <div> と </div> を単に削除することはできません。
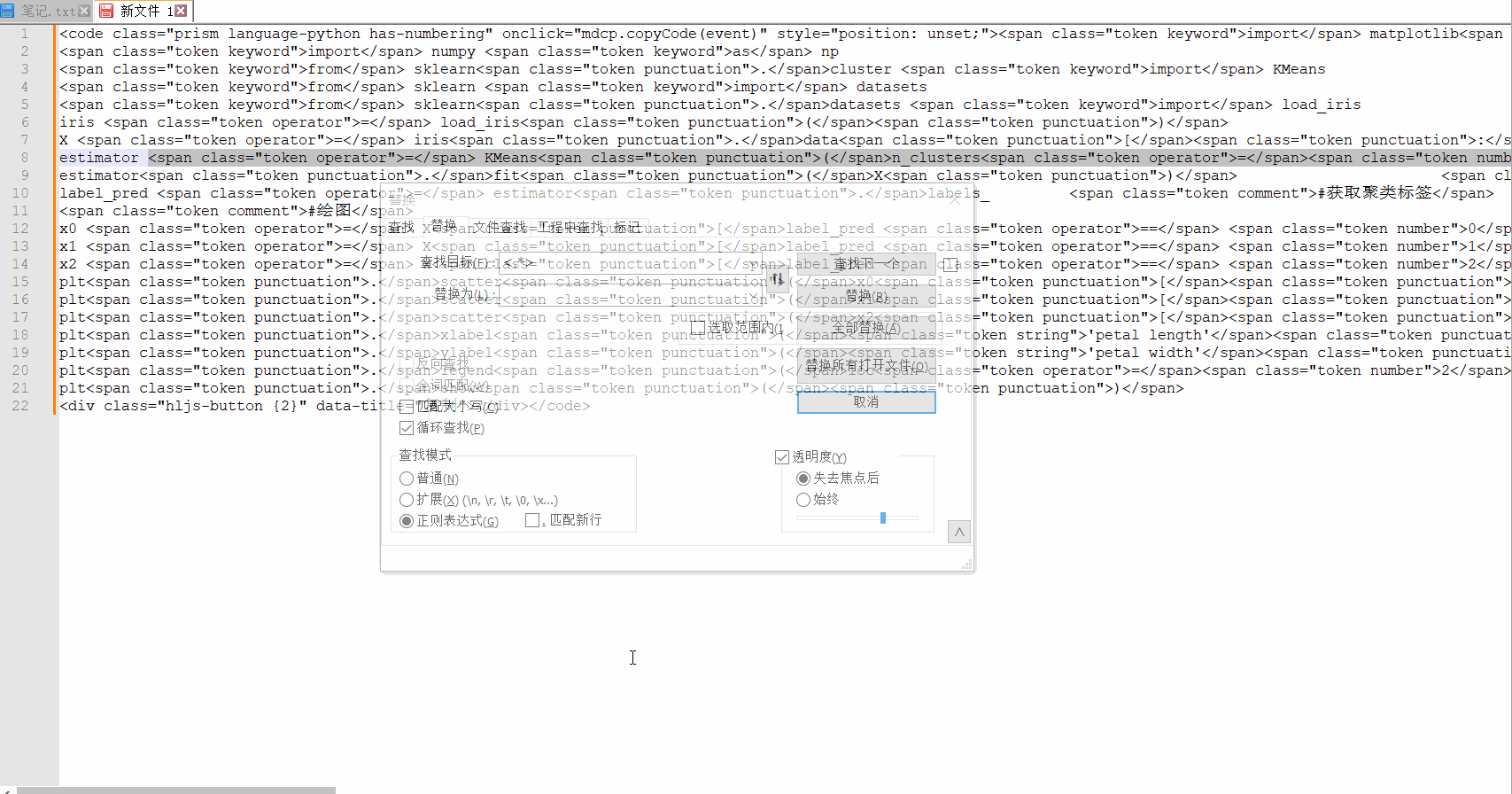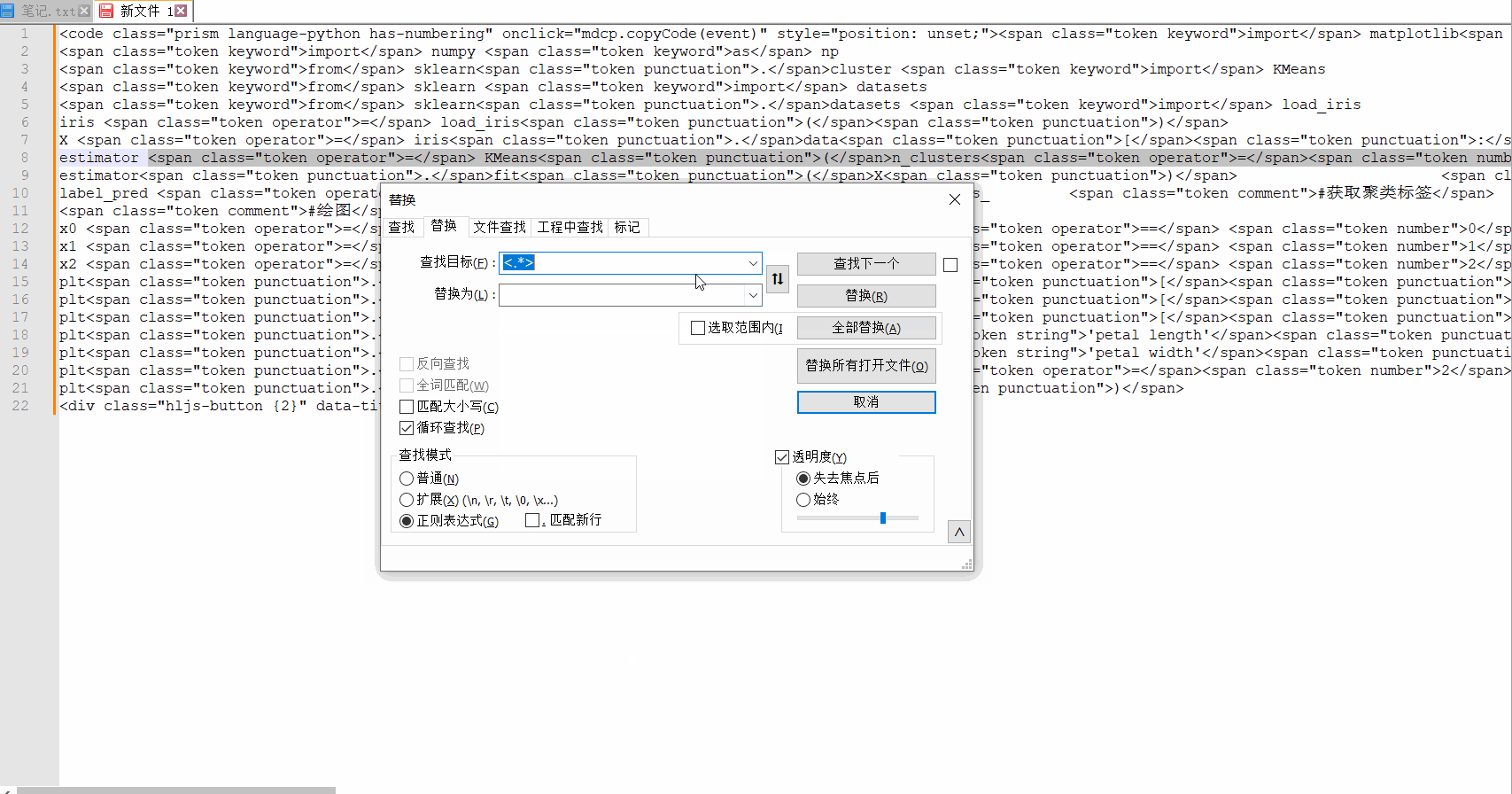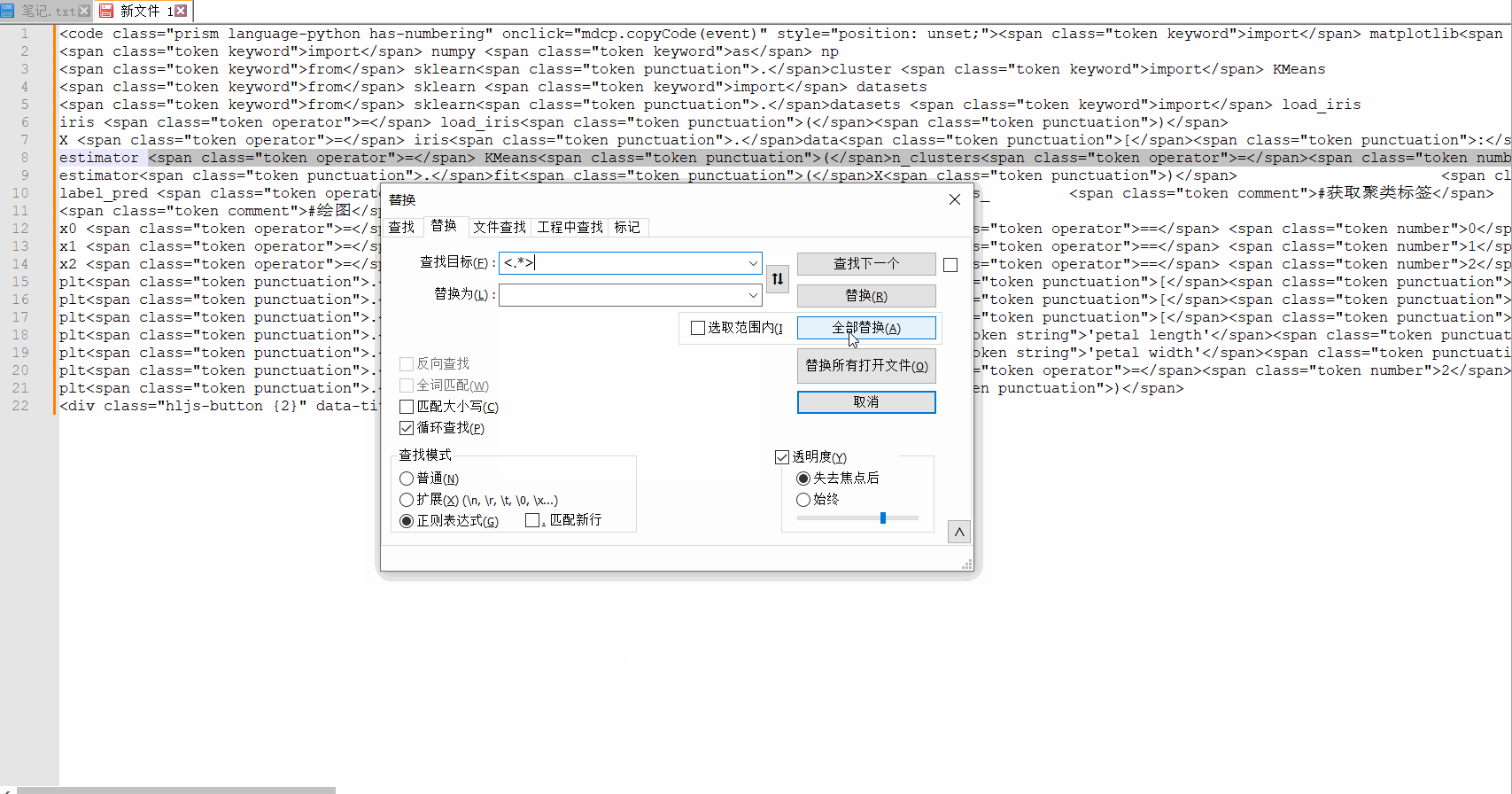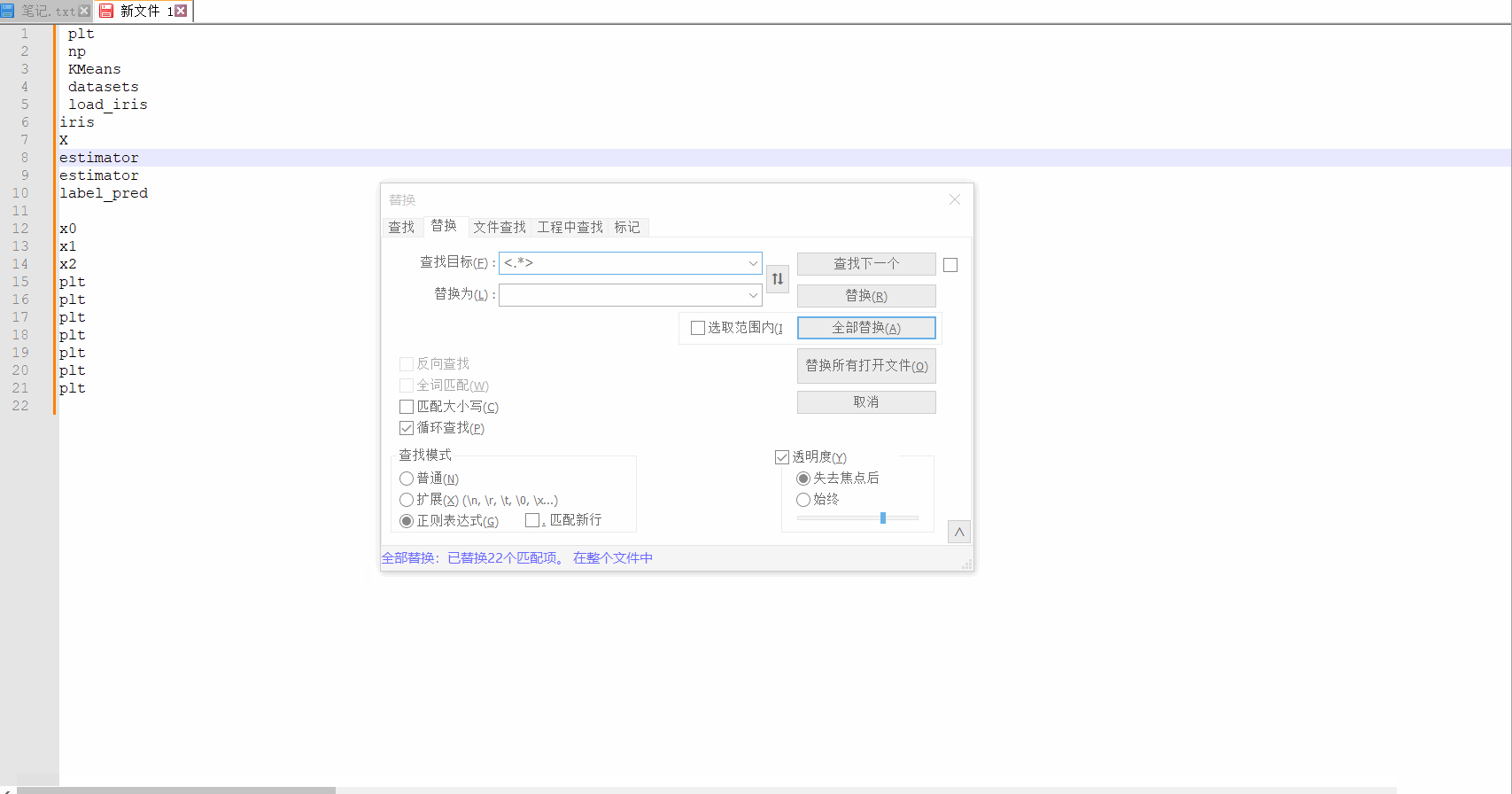
ここで考慮する必要があるのは、<> 内に終了タグ「>」を含めることはできないということです。これは少し理解するのが難しいようです。これは、開始タグ <div> であっても、終了タグ</div>。
この要件に応じて、正規表現 <[^>]+> が再度変更され、置換効果は次のようになります。
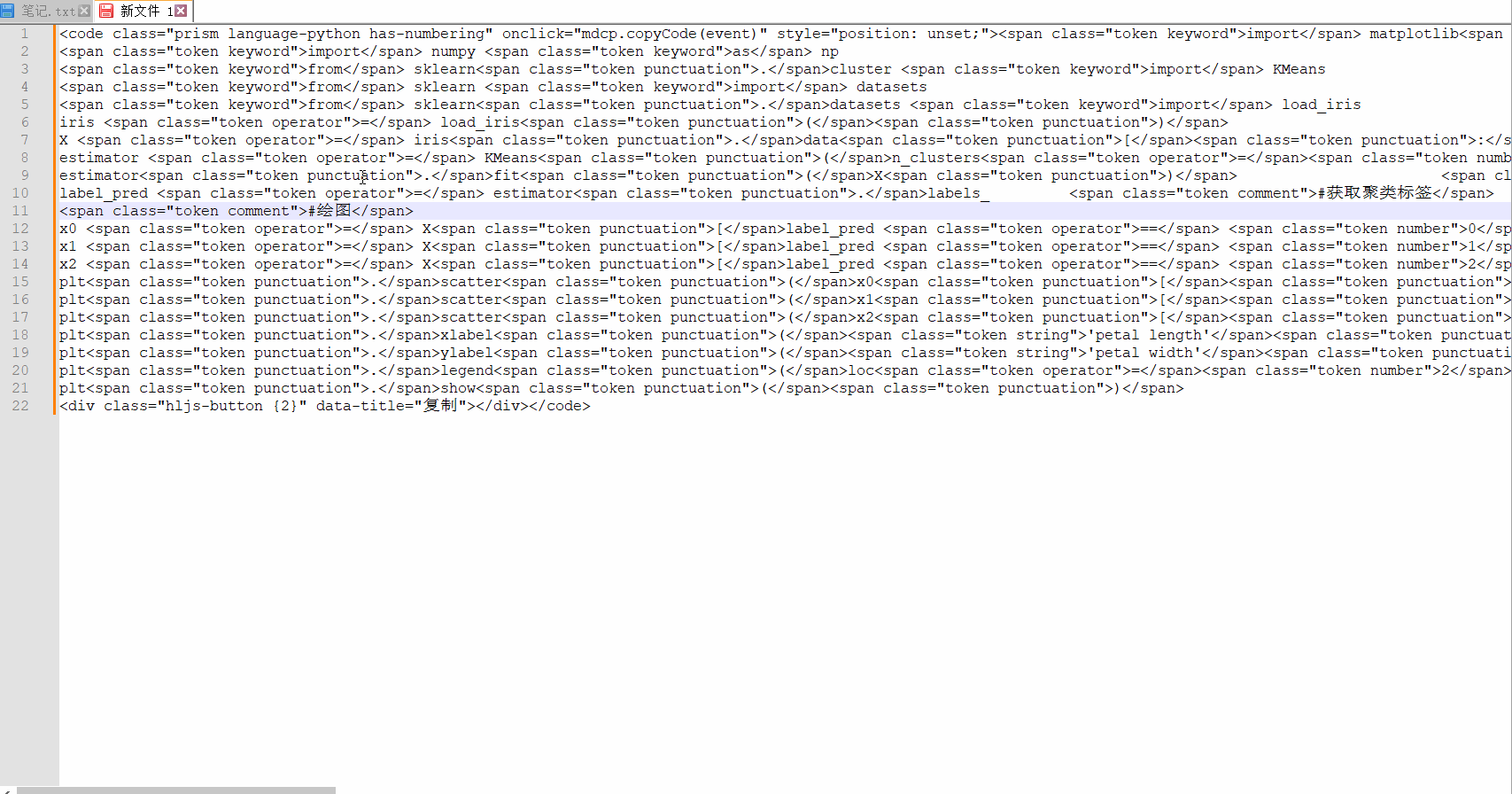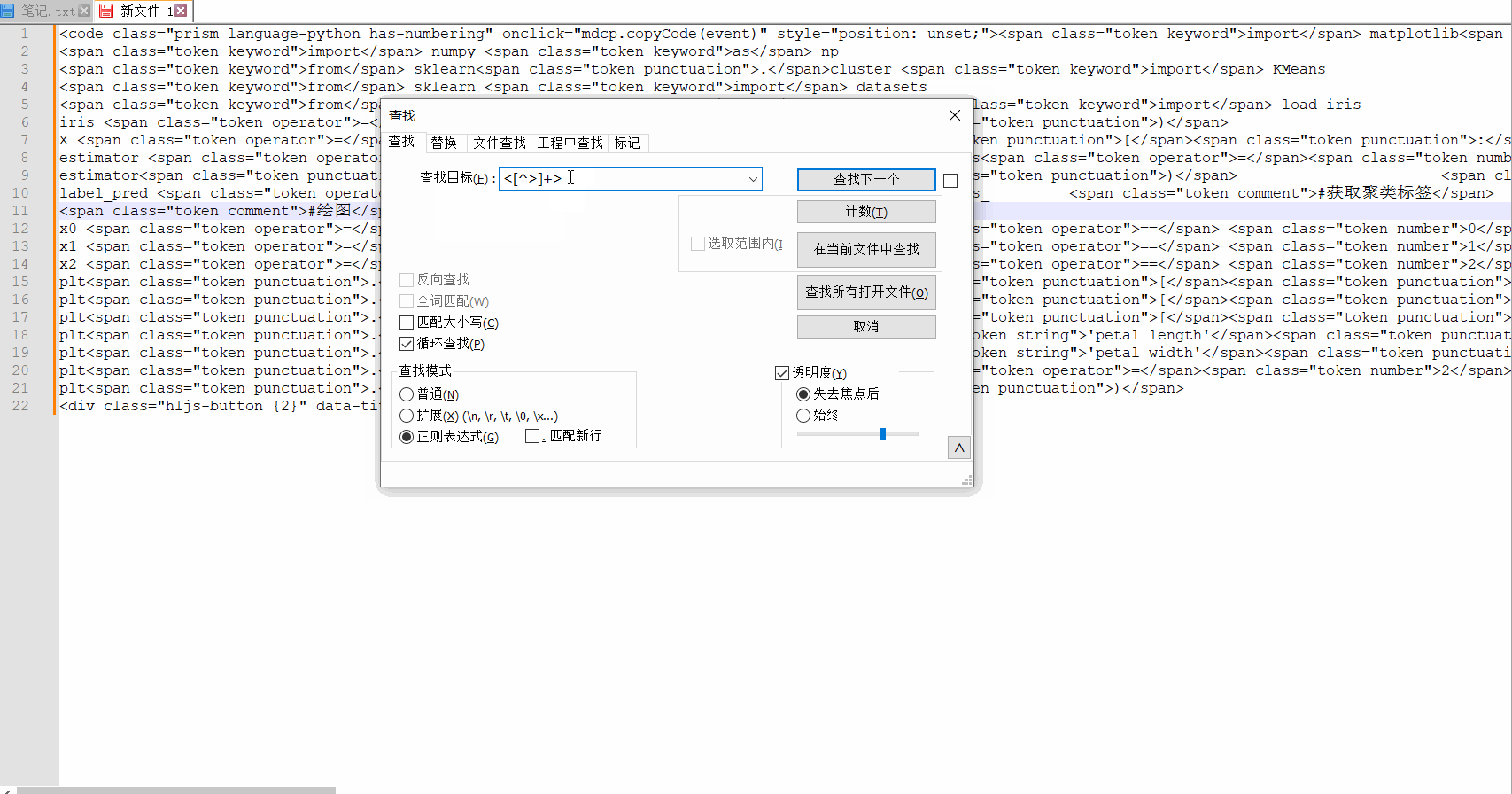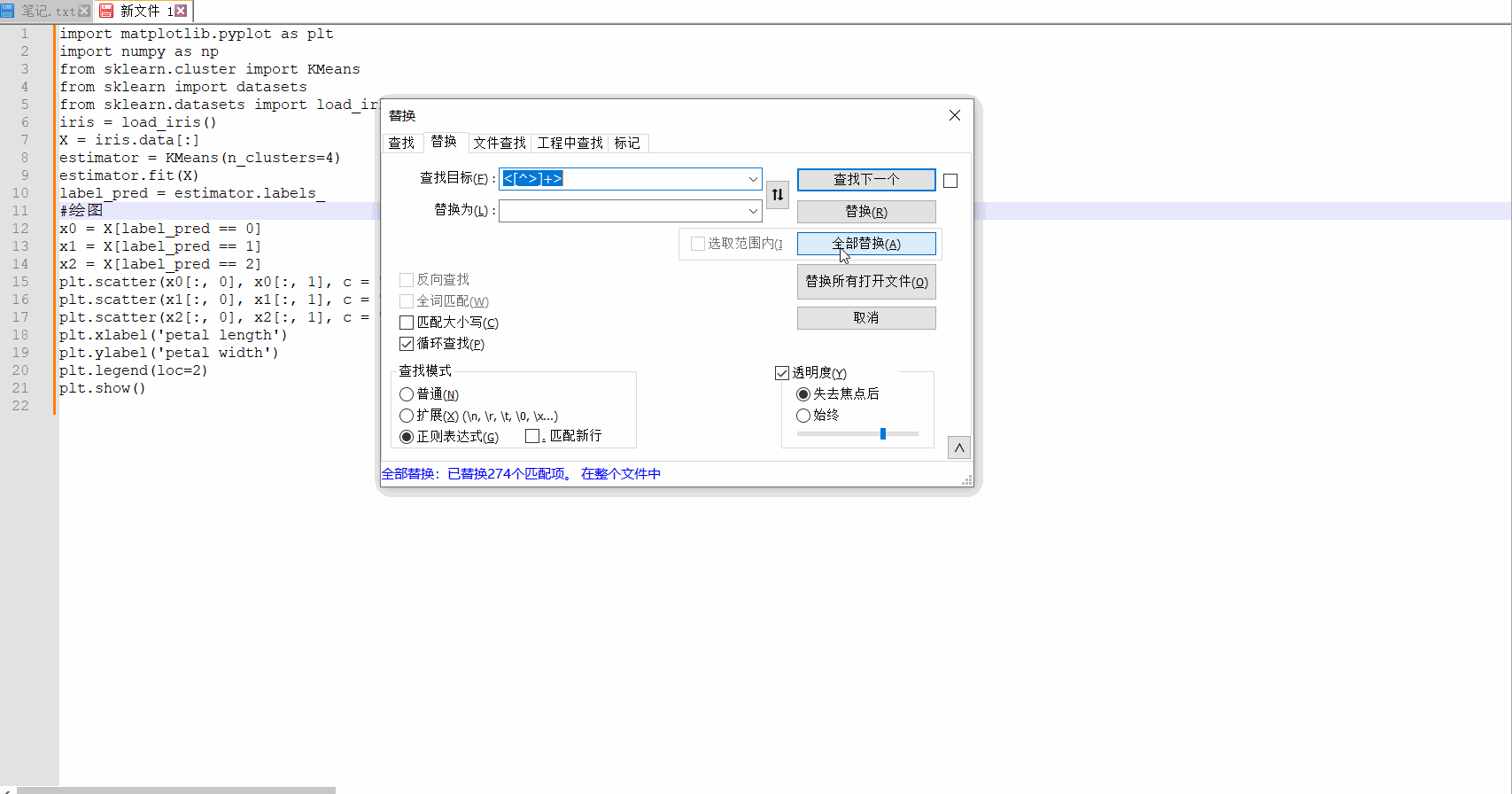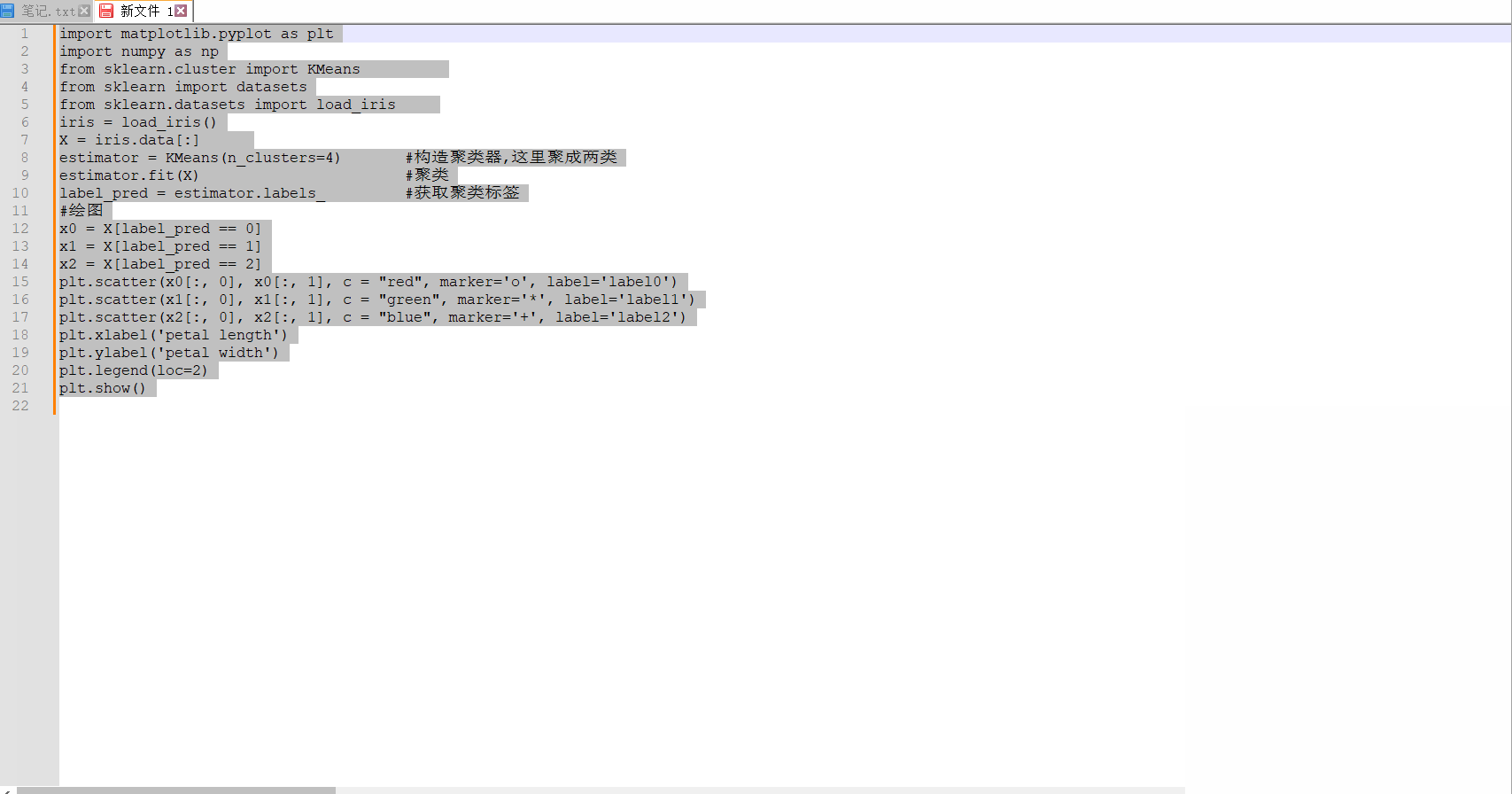
交換後はコード部分だけが残ります。必要なものだけを。
それについて少し話させてください。これは正規表現の書き込みをサポートする notepad++ を使用して行われるため、置換インターフェイスで次のような情報を確認できます。
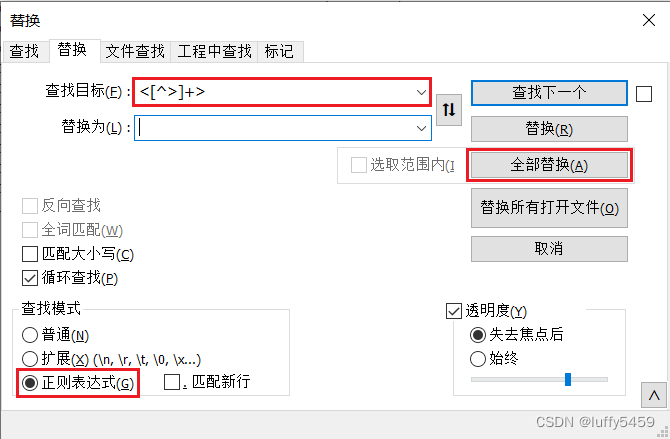
検索モードでは、これらのタグを削除し、一致するコンテンツを直接何も置き換えないため、正規表現に切り替える必要があります。そのため、「置換」に何も入力する必要はありません。最後に、「すべて置換」を選択します。
置換のもう 1 つの例です。ここでは Java コードを通じて実装します。
次のような文字列があるとします。
[{"name":"buejee","id":101,"email":[],"mobile":"15909062001"},{"name":"lucky","id":102,"email":["[email protected]"],"mobile":"15909062002"}]json形式ですが文字列として存在するのでメール部分を削除する必要があります。上の例には、それぞれ"email":[] と "email":["[email protected]"] という 2 つの電子メールがあります。それらをすべて削除するには、正規表現を次のように記述できます。
"email":\[[^\]]*\], このうち [^\]]* は [] の中に [] を含めることはできないことを意味します。ここでの * は、コンテンツに複数の文字を含めることも、何も含めることもできず、 [] と [ "[email protected]"] に一致することを意味します。また、「[」や「]」そのものが正規表現におけるキーワード記号となるため、ここでエスケープする必要があります。Java では、エスケープ記号は 2 つのバックスラッシュ\\です。
プログラムコードは次のとおりです。
package com.xxx.reg;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringReplace {
public static void main(String[] args) {
String str = "[{\"name\":\"buejee\",\"id\":101,\"email\":[],\"mobile\":\"15909062001\"},{\"name\":\"lucky\",\"id\":102,\"email\":[\"[email protected]\"],\"mobile\":\"15909062002\"}]";
Pattern pattern = Pattern.compile("\"email\":\\[[^\\]]*\\],");
Matcher matcher = pattern.matcher(str);
System.out.println(str);
String result = matcher.replaceAll("");
System.out.println(result);
}
}
操作結果:

印刷結果はメール部分を削除するだけです。
これら 2 つの例には同じ部分があります。つまり、削除されたコンテンツはフィルタリングする必要があり、貪欲に一致させることはできません。そうでない場合、効果は達成されません。特定のマークの出現を制限するには、通常の [^] 構文を使用します。