ガイド
GPT-4 は、困難な数学的推論を含む自然言語処理 (NLP) タスクで顕著なパフォーマンスを実証しました。ただし、既存のオープンソース モデルのほとんどは、大規模なインターネット データで事前トレーニングされているだけであり、数学関連のコンテンツには最適化されていません。本稿では、「Evol-Instructフィードバックによる強化学習(RLEIF)」の手法を数学の分野に適用することで、Llama-2の数的推論能力を強化するWizardMathと呼ばれる手法を紹介します。このメソッドは 2 つの数学的推論ベンチマーク (GSM8k および MATH) で広範囲に実験されており、その実験では、WizardMath が他のすべてのオープンソース LLM よりも大きな利点があることが示されています。さらに、著者のモデルは、GSM8k 上の ChatGPT-3.5、Claude Instant-1、PaLM-2、および Minerva をも上回り、MATH 上でも Text-davinci-002、PaLM-1、および GPT-3 を上回っています。
導入
ChatGPT は大規模なインターネット データで広範囲に事前トレーニングされており、特定の命令データとメソッドでさらに微調整されているため、さまざまなベンチマークで優れたゼロショット機能を実現します。その後、Meta の一連の Llama モデルはオープンソース革命を引き起こし、特に MPT8、Falcon、StarCoder、Alpaca、Vicuna、WizardLM などのリリースを刺激しました。
ただし、これらのオープンソース モデルは、難しい数学的および科学的問題の解決など、複雑な複数ステップの定量的推論を必要とする状況では依然として困難に直面しています。「思考連鎖」(CoT) は、段階的な解決策を生成するためのより適切に設計されたヒントを提案し、パフォーマンスの向上につながります。「Self-Consistency」は、モデルから複数の可能な答えを生成し、多数決に基づいて正しい答えを選択する多くの推論ベンチマークでも顕著なパフォーマンスを達成しました。
最近の研究では、難しい数学的問題を解決するには、強化学習を使用したプロセス監視が結果監視よりも大幅に優れていることが示されています。
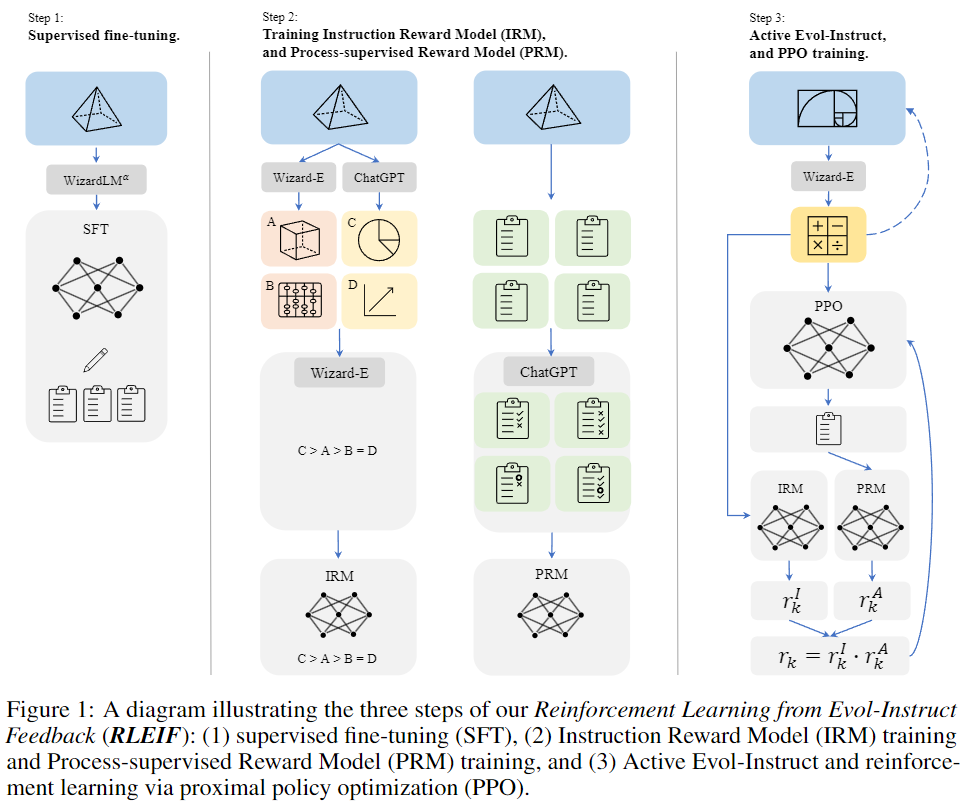
Evol-Instruct とプロセス教師あり強化学習に触発されたこの論文では、データからの論理推論における LLM の能力を向上させる、RLEIF「Evol-Instruct フィードバックからの強化学習 (RLEIF)」と呼ばれる新しい手法を紹介します。上の図 1 に示すように:
- このメソッドはまず、数学に特化した Evol-Instruct を通じてさまざまな数学命令データを生成します。
- 次に、命令報酬モデル IRM とプロセス監視報酬モデル PRM をトレーニングします。前者は進化的命令の品質を表し、後者はソリューションの各ステップにフィードバックを提供します。
- 最後に、IRM と PRM を通じて PPO 強化学習が実行されます。
数的論理的推論の能力を検証するために、著者は 2 つの数的推論ベンチマーク (GSM8k と MATH) で実験を行った結果、次のことがわかりました: この論文の WizardMath は、他のすべてのオープンソース LLM 上で良好なパフォーマンスを示し、SOTA レベルに達しています。
この論文の主な貢献は次のとおりです。
- WizardMath モデルを導入しました。これは、数学的推論におけるオープンソースの事前トレーニング済み大規模言語モデル Llama-2 の機能を強化します。
- 新しい手法である Reinforcement Learning from Evol-Instruct Feedback (RLEIF) は、Evol-Instruct と強化学習を組み合わせることによって LLM の推論パフォーマンスを向上させるために提案されています。
- GSM8k および MATH テスト ベンチマークでは、WizardMath は、Llama-2 70B、Llama-1 65B、Falcon-40B、MPT-30B8、Baichuan-13B Chat9、ChatGLM2 12B など、あらゆる面で他のすべてのオープンソース LLM を大幅に上回っています。
- GSM8k では、WizardMath は、GPT-3.5、Claude Instant、PaLM-2、PaLM-1、Minerva などのさまざまな主要なクローズドソース LLM を pass@1 で大幅に上回っています。
方法
この論文では、GSM8k と MATH データを進化させるための Evol-Instruct と強化プロセス監視手法を統合し、事前トレーニングされた LLama-2 モデルを進化したデータと報酬モデルで微調整する RLEIF と呼ばれる手法を提案します。
図 1 に示すように、この方法は 3 つのステップで構成されます。
教師ありファインチューニング(SFT)
InstructGPT のメソッドを継承し、まず教師付き命令と応答の命令ペアを使用して、以下を含む基本モデルを微調整します。
- GSM8k と MATH からの 15,000 の回答は、WizardLM 70B モデルのアルファ バージョンを使用して再生成され、プロセスごとの方法でソリューションを生成し、これらのデータを使用して基礎となる Llama モデルを微調整して正しい答えを見つけます。
- 多様な指示に従うモデルの能力を強化するために、この論文ではまた、WizardLM のトレーニング データから 1.5k のオープンドメイン対話をサンプリングし、それらを最終的な教師付き微調整トレーニング データとして上記の数学的コーパスとマージします。
Evol-Instruct の数学の原則
この研究は、WizardLM によって提案された Evol-Instruct メソッドと、WizardCoder でのその効果的な適用に触発され、異なる複雑さと多様性を持つ数学的命令を作成することで、事前トレーニングされた LLM を強化することを試みています。具体的には、Evol-Instruct を次の 2 つの進化ラインで構成される新しいパラダイムに適応させます。
- 下方進化: 問題を簡単にすることで指導が強化されます。たとえば、i) 難しい問題をそれほど難しくない問題に変更する、または ii) 別のトピックから新しい簡単な問題を生成する。
- Upward Evolution: オリジナルの Evol-Instruct メソッドから進化しました。i) 制約を追加する、ii) 具体化する、iii) 推論を追加するなどにより、より困難な問題を深めて生成します。
Evol-Instruct フィードバックからの強化学習 (RLEIF)
InstructGPT と PRM からインスピレーションを得て、著者は 2 つの報酬モデルをトレーニングして、それぞれ命令の品質と解答の各ステップの正しさを予測します。
-
命令報酬モデル (IRM): このモデルは、i) 定義、ii) 精度、および iii) 完全性の 3 つの側面から進化的命令の品質を判断することを目的としています。IRM のランキング リストのトレーニング データを命令ごとに生成するために、著者はまず ChatGPT と Wizard-E 4 を使用して 2 4 の進化した命令をそれぞれ生成します。次に、Wizard-E を使用して、これら 48 の命令の品質をランク付けします。
-
プロセス監視報酬モデル (PRM): この取り組み以前には、数学的推論のための強力なオープンソース LLM が存在しなかったため、高精度のプロセス監視をサポートする簡単な方法はありませんでした。したがって、著者らは ChatGPT を利用してプロセスを監視し、モデルによって生成されたソリューションの各ステップの正確性を評価するように依頼しています。
-
強化学習 PPO トレーニング。著者は、元の数学命令 (GSM8k + MATH) を 8 回進化させて、データ サイズを 15k から 96k に増加しました。IRM と PRM を使用して、命令報酬 (rI) と回答報酬 (rA) を生成します。これら 2 つの報酬は、最終的な報酬 r = rI · rA として乗算されます。
実験
この記事では主に、GSM8k と MATH の 2 つのベンチマークで WizardMath を評価します。GSM8k データセットには、約 7500 のトレーニング データと 1319 のテスト データが含まれており、主に小学校の算数の問題をカバーしています。各問題には基本的な算術演算 (加算、減算、乗算、除算) が含まれており、解くには通常 2 ~ 8 のステップが必要です。
MATH データセットは、AMC 10、AMC 12、AIME などの有名な数学コンテストからの数学問題を収集します。これには、初等代数、代数、数論、計数と確率、幾何学、中級代数、および微積分以前の 7 つの学術分野をカバーする 7500 のトレーニング データ セットと 5000 の難しいテスト データ セットが含まれています。また、問題の難易度は 5 段階に分類されており、「1」は比較的難易度が低く、「5」は最も高い難易度を示します。
指数評価
::: ブロック-1

GSM8k ベンチマーク テストの pass@1 評価指標では、この論文で提案した WizardMath モデルは現在トップ 5 に入っており、一部のクローズド ソース モデルよりわずかに優れており、すべてのオープンソース モデルを大幅に上回っています。
:::
::: ブロック-1


GSM8k と MATH での pass@1 の結果の比較。公正で一貫した評価を保証するために、このペーパーでは、貪欲なデコードと CoT 設定でのすべてのモデルのスコアを報告し、WizardMath と同様のパラメーター サイズを持つベースライン モデル間の改善を報告します。WizardMath ではより大きな B 数が使用され、効果が大幅に向上します WizardMath-70B モデルの精度は、一部の SOTA クローズドソース LLM に匹敵します。
:::
サンプル表示
以下の図は、同じ入力に対するさまざまなパラメーター レベルでの WizardMath モデルのさまざまな応答結果を示しています。
サンプル1



サンプル2


