
前回の記事では、ナレッジ ベースを構築する一般的なプロセスといくつかの最適化エクスペリエンスの詳細を紹介しましたが、より詳細な実践的なエクスペリエンスといくつかの関連ベンチマークを提供する特定のシナリオを組み合わせていませんでした。そのため、この記事では、議論のために特定のシナリオに切り込んでいきます。
対象シナリオ: PubMed の医学学術データの 1w 論文のナレッジ ベースを構築し、高速な挿入とクエリの速度を実現します。
主なディスカッションでは、OpenSearch クラスターのスケール設計、ナレッジ ベースのインデックス設計、および実験手順の詳細について説明します。
01
リソースの見積もり
一般に、OpenSearch クラスターの次の設計ガイドラインに従って OpenSearch のリソース構成を選択する必要があります。
検索のワークロードが部分的である場合は、10 ~ 30 GB のシャード サイズを使用する必要があります。部分的なログのワークロードが偏っている場合は、30 ~ 50 GB のノード サイズを使用する必要があります。
シャードの数をデータ ノードの数の偶数倍に設定するようにしてください。これにより、シャードがデータ ノードに均等に分散されます。
ノードあたりのシャード数は JVM ヒープ メモリに比例し、メモリ 1 GB あたりのシャード数は 25 を超えません。
5 つの vCPU はそれぞれ 1 つのシャードに対応できます。たとえば、8 つの vCPU は最大 6 つのシャードをサポートできます。
k-NN フィールドが有効な場合、メモリの見積もりについては次の表を参照してください。

現在の情報に基づくと、インデックスが作成される元のドキュメントの数のみがわかります。ドキュメントのセグメント化などの中間処理プロセスにより、特定のメモリ使用量とストレージ容量を見積もることは不可能であるため、テスト推論には実験データの小さなバッチを使用する必要があります。
小規模バッチ実験では、300 個のドキュメントにインデックスが付けられ、セグメント化を通じて約 203,000 個のレコードが生成され、ストレージ容量は 4.5 GB でした。次に、比例変換すると、10,000 個のドキュメントのインデックスを作成する必要がある場合、約 700 万件のレコードが生成され、150 GB のストレージが生成されます。以下に示すように:

検索ワークロードに属する知識クイズ チャットボット シナリオから始めて、検索パフォーマンスを向上させるには、シャードのサイズを 10 ~ 30 GB の範囲にする必要があります。シャードの数は通常、ノード数の倍数の原則に従い、2 ノードのクラスターの場合は [2、4、8、16 ...] になります。合計ストレージ容量 150 GB に基づいて、シャードは 8、10、12、14、および 16 になります。シャード数が 8 の場合、各シャードのストレージ容量は 18.75 GB となり、要件を満たします。
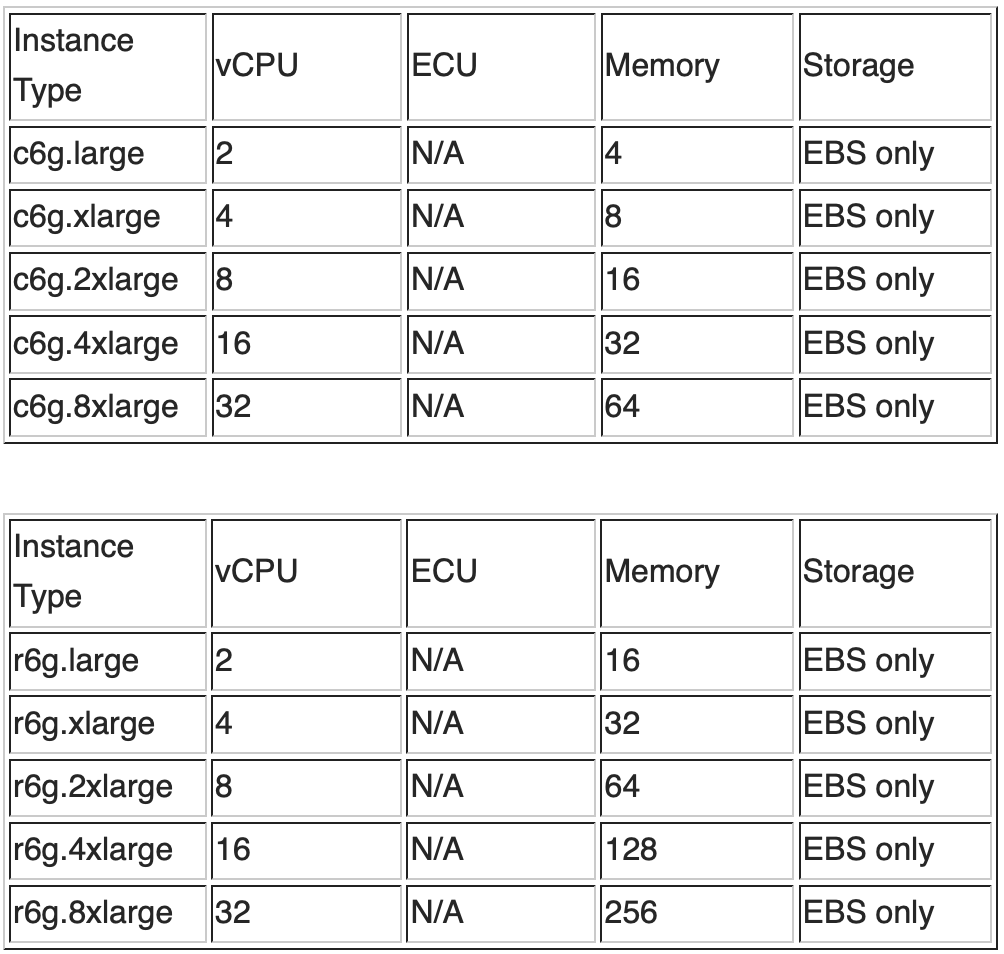
ベクトル検索に関しては、リコールとレイテンシーの両方を保証するために、HNSW アルゴリズムが使用されます。さらに、 のベンチマークの結論を参照してください。HNSW アルゴリズムの m の値は 16 に設定できます。メモリ計画の観点から、上の表の式に従ってメモリ使用量を計算します。

一般に、各ノードのオフヒープ メモリは 50% を占めますが、knn.memory.circuit_break.limit=70% のベスト プラクティス設定によれば、ノード メモリの 35% が KNN によって占有されるため、ノード全体は22.9GB / 35% = 65GB として計算される必要があります。
vCPU の計画に関しては、シャード数が 8 であると仮定し、1.5vCPU/シャードの係数を乗算すると、vCPU の数は少なくとも 12 以上である必要があります。次の C シリーズおよび R シリーズのインスタンス構成情報と価格情報を組み合わせ、メモリと vCPU の要件を考慮して、C シリーズの 2 ノード c6g.4xlarge または R-シリーズの 2 ノード r6g.2xlarge を選択します。シリーズ。
02
インデックス構築の実験
インデックスを構築する際に注意すべき主なポイントは次の 3 つです。
データの整合性により、すべての知識を照会でき、異常な取り込みによってデータが失われることがないことが保証されます。
構築速度とナレッジリコールには効果の調整が繰り返される可能性があり、繰り返し取り込む必要があるため、速度はフルリンクの開発と最適化の効率にとって非常に重要です。
パフォーマンスをクエリして、シーンでのリアルタイムのセッション エクスペリエンスを確保します。
取り込みプロセス全体は、基本的に、テキストのセグメント化、テキストのベクトル化、Amazon OpenSearch への取り込みの 3 つの段階に分けることができます。このうち、テキストのセグメンテーションとテキストのベクトル化の処理は一時的なワークロードであり、原則として同時グルージョブの数と Amazon SageMaker Endpoint の背後にあるノードの数を増やすことで、このワークロードの処理速度を直線的に向上させることができますが、OpenSearch はその処理速度を向上させます。事前に割り当てられたリソースに割り当てられます (注: 今年リリースされる OpenSearch Severless k-NN ベクトル データベースによってこれが変更されます)。後の 2 つの部分、つまりベクトル化と OpenSearch の取り込みがプロセス全体のボトルネックになる可能性があります。完全なプロセス テストを分解してパフォーマンスのボトルネックを分析するのは簡単ではないため、この実験ではこれら 2 つの部分を個別にテストします。
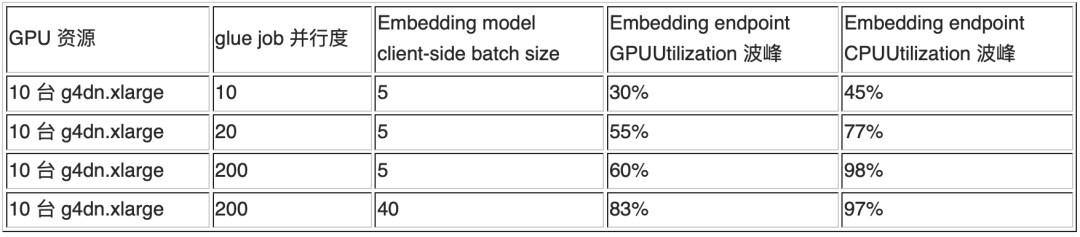
実験 1 – 埋め込みモデルのスループット テスト
paraphrase-multilingual-deploy.ipynb を使用してデプロイし、10 個の g4dn.xlarge モデルをデプロイします。
https://github.com/aws-samples/private-llm-qa-bot/blob/main/notebooks/embedding/paraphrase-multilingual-deploy.ipynb
OpenSearch ダウンストリームへの書き込みによって生じる影響をコメント アウトし、関連するコードを一時的にコメント アウトします。
https://github.com/aws-samples/private-llm-qa-bot/blob/main/code/aos_write_job.py
同時操作のために複数のグルー ジョブを開始するには、batch_upload_docs.py を使用します。
https://github.com/aws-samples/private-llm-qa-bot/blob/main/code/batch_upload_docs.py
処理フローのこの部分では、グルー ジョブの並列処理とクライアント側のバッチ サイズを調整することで、ベクトル化ステップのスループットを調整できます。GPU 使用率が不十分な場合、クライアント側のバッチ サイズを増やすと GPU 使用率が向上する可能性があります。簡単なテストの結果、この仮説は実際に証明できることがわかりました。具体的なデータについては、次の実験結果を参照してください。
ラボ 2 – Amazon OpenSearch 取り込みテスト
1. ベクトルをランダムに生成し、埋め込みモデル呼び出しを置き換えます。次のコードを参照してください。
import numpy as np
AOS_BENCHMARK_ENABLED=True
def get_embedding(smr_client, text_arrs, endpoint_name=EMB_MODEL_ENDPOINT):
if AOS_BENCHMARK_ENABLED:
text_len = len(text_arrs)
return [ np.random.rand(768).tolist() for i in range(text_len) ]
# call sagemaker endpoint to calculate embeddings
...
return embeddings左にスワイプするとさらに表示されます
2. OpenSearch クラスターとインデックスを構築し、設定を最適化します。
a. 対応するインデックスを構築する
ベクトル場に関係する 2 つのパラメーター ef_construction と m。ef_construction は k-NN グラフを構築する際の動的リストのサイズを指定し、値が大きいほどベクトルデータのグラフは正確になりますが、インデックスの応答が遅くなります。m は、k-NN の各ベクトルの二重リンク リストの数を指定します。数値が大きいほど、検索の精度は高くなりますが、対応するメモリ使用量が大幅に増加します。ブログのベンチマークの結論を参照してください<OpenSearch を使用した 10 億規模のユースケースのための k-NN アルゴリズムの選択> (https://aws.amazon.com/cn/blogs/big-data/choose-the-k- nn-algorithm-for-your-billion-scale-use-case-with-opensearch/)、現在のデータ スケールでは、パラメーター ef_construction: 128 および m: 16 で再現率を確保するのに十分です。インデックスを作成するときは、次の点に注意してください。
時間に応じた後続の情報の削除/更新を容易にするために、publish_date フィールドを追加します。
idx 整数フィールドを追加して、フルテキスト内の対応するセグメントの順序を記録し、呼び出し時に range_search に基づいて隣接するコンテキスト セグメントを呼び出します。
フィルタリングのみを実行し、キーワードの再呼び出しは実行しないフィールドはキーワード タイプに設定されるため、インデックス作成の速度が向上します。詳細については、次のコードを参照してください。
PUT chatbot-index
{
"settings" : {
"index":{
"number_of_shards" : 8,
"number_of_replicas" : 0,
"knn": "true",
"knn.algo_param.ef_search": 32,
"refresh_interval": "60s"
}
},
"mappings": {
"properties": {
"publish_date" : {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"idx" : {
"type": "integer"
},
"doc_type" : {
"type" : "keyword"
},
"doc": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"doc_title": {
"type": "keyword"
},
"doc_category": {
"type": "keyword"
},
"embedding": {
"type": "knn_vector",
"dimension": 768,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "nmslib",
"parameters": {
"ef_construction": 128,
"m": 16
}
}
}
}
}
}左にスワイプするとさらに表示されます
b. knn 関連パラメータを設定します。 「大規模言語モデルベースの知識質問応答アプリケーションの実践 - 知識ベースの構築 (オン)」を参照してください。
PUT /_cluster/settings
{
"transient": {
"knn.algo_param.index_thread_qty": 8,
"knn.memory.circuit_breaker.limit": "70%"
}
}左にスワイプするとさらに表示されます
c. 複数のグルー ジョブの同時取り込みを有効にするには、次のコードを参照します。
# 注意${Concurrent_num} 不能超过
# glue job->job detail->Advanced properties->Maximum concurrency 设置中最大限制
python batch_upload_docs.py \
--bucket "${bucket_name}" \
--aos_endpoint "${OpenSearch_Endpoint}" \
--emb_model_endpoint "${EmbeddingModel_Endpoint}" \
--concurrent_runs_quota ${Concurrent_num} \
--job_name "${Glue_jobname}"左にスワイプするとさらに表示されます
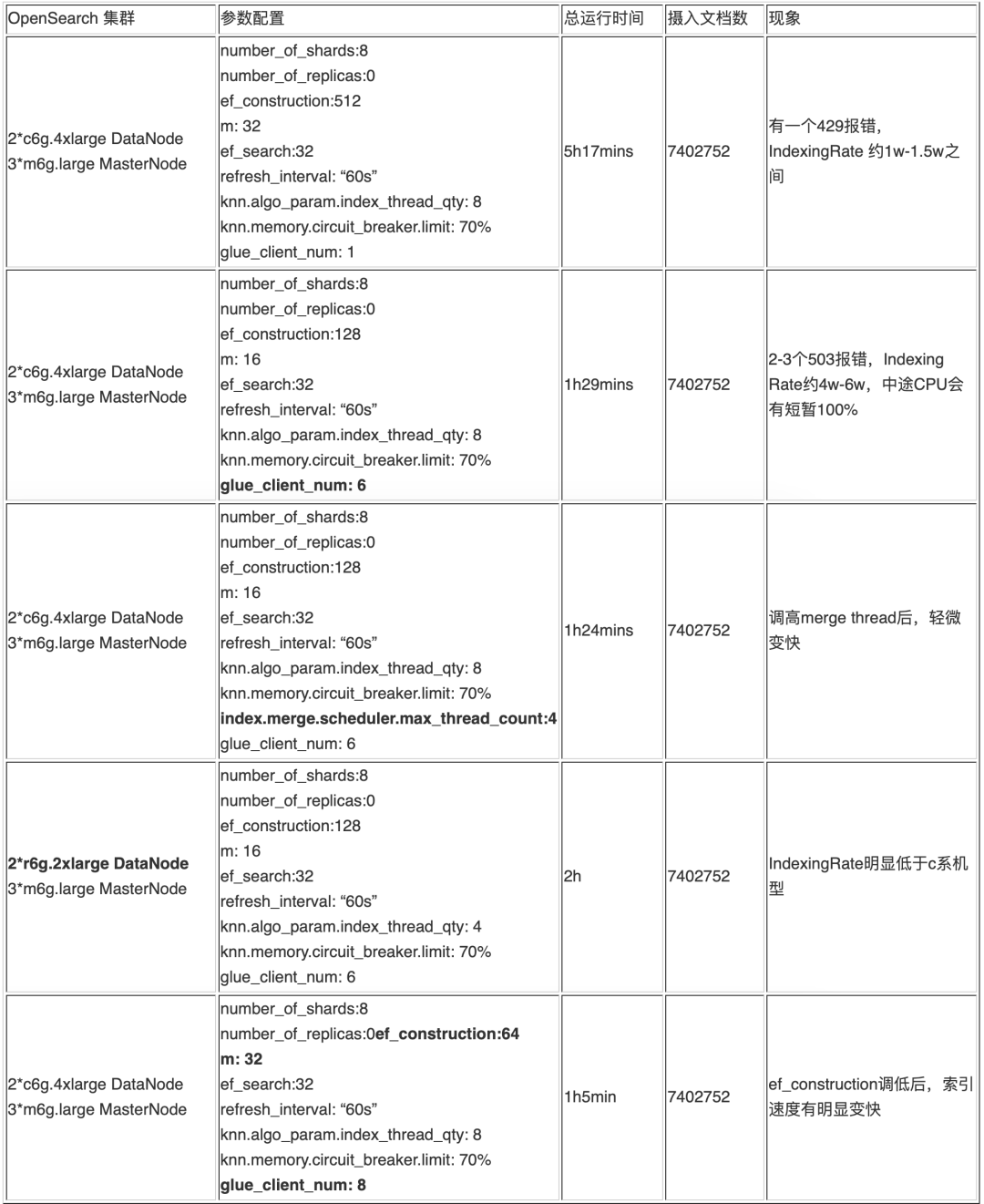
3. 実験結果の詳細
実験の各ラウンドでは、後続のデータ挿入でのパラメーター調整のガイドとして、調整されたパラメーターが太字でマークされています。
実験 3 – 全プロセス取り込みテスト
a. いくつかの実験記録の詳細
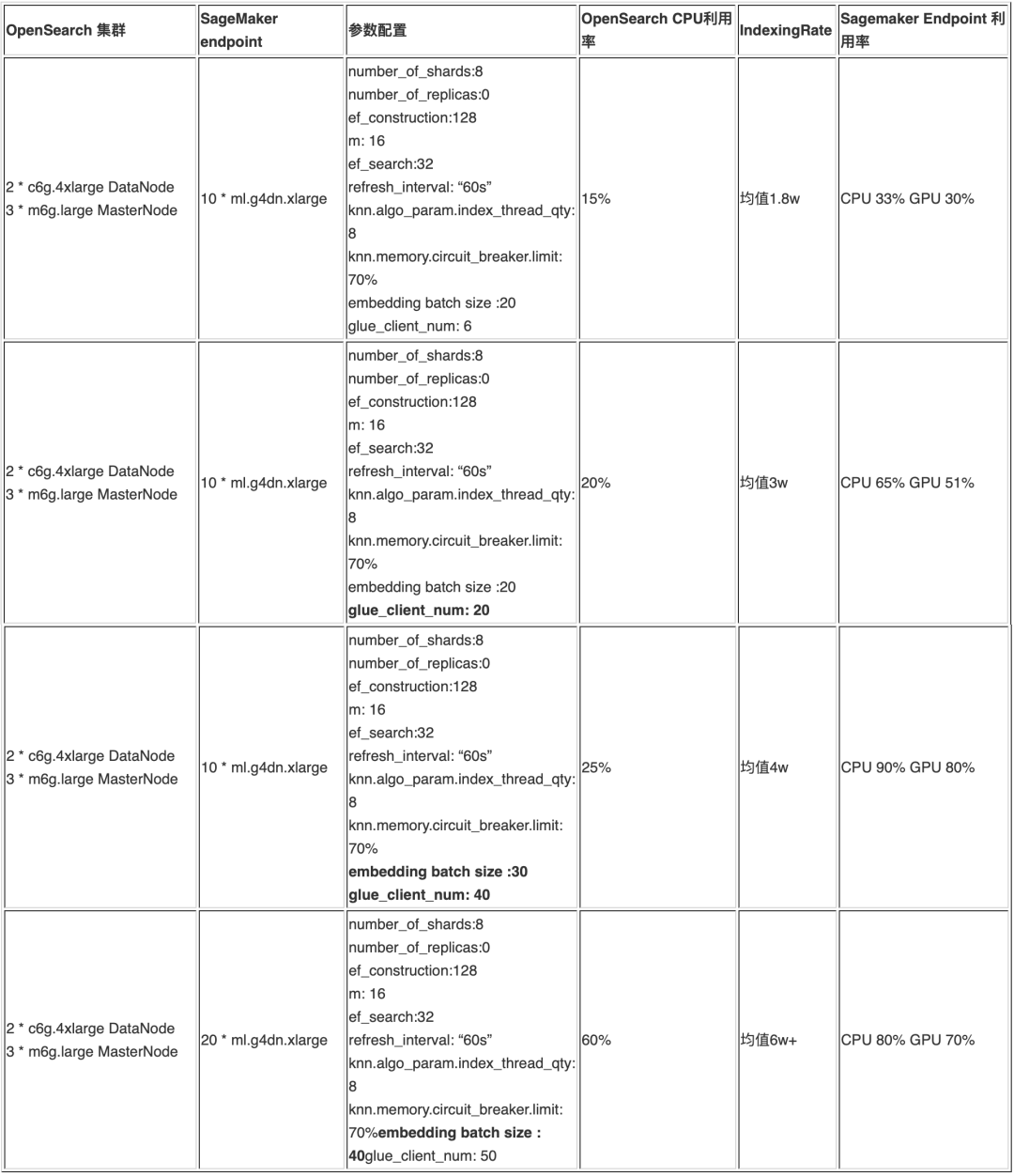
b. 予備的な実験結果
上記の実験記録を参照すると、10,000 個のドキュメントを 700 万個のベクトルに分割した後、クライアントの同時実行性を調整することで、推論エンドポイントのノード数と推論バッチ サイズを約 1 時間で取り込むことができることがわかります。整合性には問題ありません。大規模な知識構築の要件を満たすことができ、ドキュメントの量が増加し続ける場合は、OpenSearch ノードと SageMaker Endpoint ノードを拡張し続けることができます。
03
インデックス構築経験の概要
過去には、OpenSearch インジェストのベスト プラクティスの一部に knn が含まれていなかったため、knn インデックスの場合、以前の結論を完全に参照することができませんでした。上記の 3 つの異なる実験方法を通じて、複数の実験の過程で、この論文は参考までに、次の実際の経験と結論を取得しました。
a. CPU 使用率とパラメーター ef_construction は m と有意な正の相関関係があり、実験でより大きな ef_construction と m を使用すると、CPU は簡単に 100% に達します。実験では、他のパラメータが同じ場合、ef_construction が 512 の場合、CPU 使用率が 100% で長時間維持されますが、2 に変更すると、使用率は基本的に 20% を下回り、ピーク値になります。 30%を超えない。
b. クライアントの並列処理の量は、OpenSearch の取り込み速度および負荷と正の相関関係がありますが、直線的ではありません。マルチクライアントは取り込み速度を向上させることができますが、クライアントが多すぎると、(429、「429 Too Many Requests /_bulk」) や (503、「リクエストを処理できるサーバーがありません..」) などが大量に発生する可能性があります。間違い。
c. 指数バックオフ再試行メカニズムにより、取り込みの整合性と、クラスターの瞬間的な利用不能によって引き起こされる大規模な書き込みエラーを保証できます。opensearch-py パッケージには次の取り込み機能があります。同時クライアントが多すぎると、原因 CPU 使用率は常に 100% であり、max_retries のリトライ回数内では、毎回、initial_backoff * (attampt_idx ** 2) 時間待機します。initial_backoff 待ち時間を大きく設定することで、CPU の同時実行を回避できます。クライアント側 429エラーの広範囲の場合。また、クライアントの数が多すぎないように注意してください。大きすぎると、503 関連のエラーが多数発生する可能性が高くなります。時折発生する 503 エラーの場合は、Glue の再試行メカニズムを使用して書き込みの整合性を確保できます。
# chunk_size 为文档数 默认值为 500
# max_chunk_bytes 为写入的最大字节数,默认 100M 过大,可以改成 10-15M
# max_retries 重试次数
# initial_backoff 为第一次重试时 sleep 的秒数,再次重试会翻倍
# max_backoff 最大等待时间
response = helpers.bulk(client,
doc_generator,
max_retries=3,
initial_backoff=200, #默认值为 2,建议大幅提高
max_backoff=800,
max_chunk_bytes=10 * 1024 * 1024) #10M 社区建议值左にスワイプするとさらに表示されます
注:大規模なデータ取り込みの運用シナリオでは、LangChain が提供するベクター データベース インターフェイスを使用することはお勧めできません。そのソース コードを見ると、LangChain のデフォルトの実装が単一のクライアントであることがわかります。内部実装では指数バックオフ再試行メカニズムが使用されないため、取り込み速度と完全性は保証されません。
d. 書き込みが完了したら、書き込みの整合性を確保するためにドキュメントの重複排除量をクエリすることをお勧めします。OpenSearch ダッシュボードの開発ツールで次の DSL ステートメントを使用して、ドキュメントの総数をクエリできます。カーディナリティ統計は正確な統計ではないことに注意してください。精度を向上させるために precision_threshold パラメータ値を増やすことができます。
POST /{index_name}/_search
{
"size": 0,
"aggs": {
"distinct_count": {
"cardinality": {
"field": "{field_name}",
"precision_threshold": 20000
}
}
}
}
=> 10000左にスワイプするとさらに表示されます
同時に、対応するチャンクの数をドキュメント名に従ってカウントできるため、潜在的なドキュメント処理品質の問題を見つけるのに役立ちます。次のコードを参照してください。
GET /{index_name}/_search
{
"size": 0,
"aggs": {
"distinct_values": {
"terms": {
"field": "doc_title"
}
}
}
}
=>
...
"aggregations": {
"distinct_values": {
"buckets": [
{
"key": "ai-content/batch/PMC10000335.txt",
"doc_count": 42712
},
{
"key": "ai-content/batch/PMC10005506.txt",
"doc_count": 5279
},
...
{
"key": "ai-content/batch/PMC10008235.txt",
"doc_count": 9
},
{
"key": "ai-content/batch/PMC10001778.txt",
"doc_count": 1
}
]
}左にスワイプするとさらに表示されます
e. Refresh_interval が -1 に設定されている場合、他の関連パラメーターと同じ条件下では、503 エラーの数が大幅に増加します。60s に変更した後は状況は大幅に改善され、同様の問題が発生した場合は同様の調整が可能です。
04
検索パフォーマンスのチューニング
データが挿入された後は、直接クエリのパフォーマンスが非常に低下し、クエリの遅延が数秒、場合によっては 10 秒になる場合があります。いくつかの必要な最適化を行う必要があります。核心となるのは 2 つの主要なポイントです。
a. セグメントのマージ
セグメントは OpenSearch の最小の検索単位です。各シャードにセグメントが 1 つだけある場合、検索効率が最も高くなります。この目標を達成するには、リフレッシュ間隔を制御して小さなセグメントの生成速度を下げるか、セグメントのマージを手動で実行します。これにより、検索プロセス中のオーバーヘッドが軽減され、検索速度が向上します。
OpenSearch ダッシュボードの開発ツールで次の DSL を使用してマージを実行できます。マージ プロセス全体は比較的時間がかかります。実行前に、マージに使用される最大スレッド数を増やすことができ、これによりマージの速度が向上します。
# merge segments
POST /{index_name}/_forcemerge?max_num_segments=1?pretty
# increase max_thread_count for merge task
PUT {index_name}/_settings
{
"index.merge.scheduler.max_thread_count": 8
}左にスワイプするとさらに表示されます
マージの前後に次の DSL を実行して、現在のセグメントを確認できます。
GET _cat/segments/{index_name}?v&h=index,segment,shard,docs.count,docs.deleted,size左にスワイプするとさらに表示されます
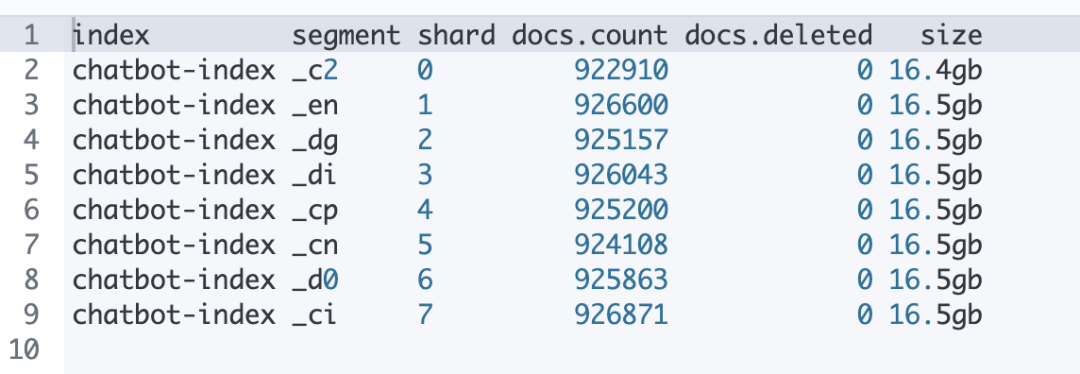
次の表は、セグメントのマージ後の状況を示しています。マージが完了すると、各シャードの下にセグメントが 1 つだけ存在し、データが均等に分散され、削除対象としてマークされたデータもクリーンアップされます。
b. k-NN インデックスのウォームアップ
k-NN インデックスのパフォーマンスは、インデックス データ構造がメモリにキャッシュされるかどうかに密接に関係しているため、提供できるキャッシュ コンテンツの容量はパフォーマンスに大きな影響を与えます。次の DSL コマンドを実行すると、k-NN インデックスをウォームアップできます。
GET /_plugins/_knn/warmup/{index_name}?pretty左にスワイプするとさらに表示されます
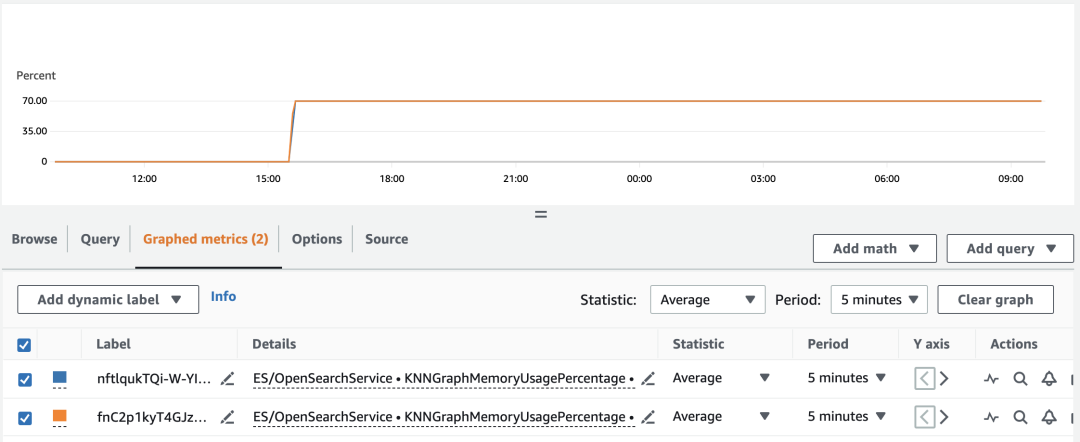
ウォームアップは非常に迅速に実行され、ウォームアップ完了後のパフォーマンスは大幅に向上します。図に示すように、CloudWatch に移動して OpenSearch ドメインの KNNGraphMemoryUsagePercentage インジケーターをチェックして、実行が完了したかどうかを確認できます。
05
エピローグ
このシリーズの前のブログに基づいて、この記事では、実際のデータ シナリオの実践を通じてさらに詳細に説明します。議論の焦点は、大規模なドキュメント向けのベクトル データ ベースのナレッジ ベースのより迅速かつ完全な構築にあります。 . 、金融、法律、医療などの一部の業界における業界知識ベースの構築にとって指導的な意味を持っています。
この記事の最初の部分では、Amazon OpenSearch のクラスター構成を選択するためのメソッドのリファレンスをいくつか示し、2 番目、3 番目、および 4 番目の部分では、データの取り込みと取得のパフォーマンスに関する予備的な経験の概要を示します。
このシリーズの詳細については、次のような関連ブログ投稿がいくつかあります。
「Amazon OpenSearch ベクトルデータベースのパフォーマンス評価と選択分析」では、ベクトルデータベースとしての Amazon OpenSearch に焦点を当て、その利点と位置付けについて説明し、インデックス作成とクエリに関するより詳細なベンチマークを提供し、より豊富な参考情報をユーザーに提供します。
「大規模言語モデルベースの知識質問応答アプリケーションの実践 - 知識想起の最適化」では、適用可能なさまざまな想起方法と実践的なスキルを含め、知識ベース構築の前提と背景の下で、対応する知識をより適切に想起する方法について説明します。さらに、この記事で説明されているコードの詳細は、サポート資料を参照できます。
コードリポジトリ aws-samples/private-llm-qa-bot
https://github.com/aws-samples/private-llm-qa-bot
ワークショップ <Amazon OpenSearch+Large Language Model に基づくインテリジェントな質問応答システム> (中国語版、英語版)
https://github.com/aws-samples/private-llm-qa-bot
参考文献:
1. OpenSearch を使用した 10 億規模のユースケース向けに k-NN アルゴリズムを選択する
https://aws.amazon.com/cn/blogs/big-data/choose-the-k-nn-algorithm-for-your-billion-scale-use-case-with-opensearch/
この記事の著者

李元波
Amazon クラウド テクノロジー分析および AI/ML ソリューション アーキテクト。AI/ML シナリオのエンドツーエンドのアーキテクチャ設計とビジネス最適化に重点を置き、データ分析の観点から Amazon Clean Rooms 製品サービスを担当します。インターネット業界で長年働いており、ユーザーのポートレート、洗練された運用、推奨システム、ビッグデータ処理に関して豊富な実務経験を持っています。

孫堅
Amazon クラウドテクノロジーのビッグデータソリューションアーキテクト。Amazon クラウドテクノロジーに基づくビッグデータソリューションのコンサルティングとアーキテクチャ設計を担当し、ビッグデータの研究と推進に尽力しています。彼は、ビッグ データの運用とメンテナンスのチューニング、コンテナ ソリューション、レイクとウェアハウスの統合、ビッグ データ エンタープライズ アプリケーションに豊富な経験を持っています。

唐世建
Amazon クラウド テクノロジー データ分析ソリューション アーキテクト。顧客のビッグデータ ソリューションのコンサルティングとアーキテクチャ設計を担当。

郭仁
Amazon クラウド テクノロジー AI および機械学習ディレクション ソリューション アーキテクト。Amazon クラウド テクノロジーに基づく機械学習ソリューション アーキテクチャのコンサルティングと設計を担当し、ゲーム、電子商取引、インターネット メディア、その他の業界での機械学習ソリューションの実装と推進に専念。Amazon Cloud Technology に入社する前は、データ インテリジェンス関連テクノロジーのオープンソースと標準化に従事し、豊富な設計と実務経験を持っています。


聞いたので、下の 4 つのボタンをクリックしてください
バグに遭遇することはありません!
