DataWhale 機械学習サマーキャンプ フェーズ II
DataWhale 機械学習サマーキャンプ フェーズ 3
-ユーザーの新しい予測チャレンジ
学習記録1(2023.08.18)
すでにベースラインを実行しているため、特徴オンライン スコアを追加せずに lightgbm ベースラインに変更します。0.52214ベース
ライン特徴を追加し、オンライン スコアを追加します0.78176。
特徴を激しく導出し、モデル パラメーターを微調整します。オンライン スコア0.86068
1. 質問の理解
競技データは約 620,000 のトレーニング セットと 200,000 のテスト セットで構成され、合計 13 のフィールドが含まれます。
- uuid はサンプルの一意の識別子です。
- eid はアクセス動作 ID、
- udmap は動作属性であり、key1 から key9 はプロジェクト名、プロジェクト ID、その他の関連フィールドなどのさまざまな動作属性を表します。
- common_ts はアプリケーション アクセス レコードの発生時刻 (ミリ秒のタイムスタンプ)、
- 残りのフィールド x1 ~ x8 はユーザー関連の属性であり、匿名処理フィールドです。
- 対象フィールドは予測対象、つまり新規ユーザかどうかです。
2. 欠損値分析
print('-----Missing Values-----')
print(train_data.isnull().sum())
print('\n')
print('-----Classes-------')
display(pd.merge(
train_data.target.value_counts().rename('count'),
train_data.target.value_counts(True).rename('%').mul(100),
left_index=True,
right_index=True
))
分析: データには欠損値がなく、533155 (85.943394%) の陰性サンプル、87201 (14.056606%) の陽性サンプルがあります。
不均一なデータ分散の処理:
- 閾値シフト
- サンプルの重みを設定する
weight_0 = 1.0 # 多数类样本的权重
weight_1 = 8.0 # 少数类样本的权重
dtrain = lgb.Dataset(X_train, label=y_train, weight=y_train.map({
0: weight_0, 1: weight_1}))
dval = lgb.Dataset(X_val, label=y_val, weight=y_val.map({
0: weight_0, 1: weight_1}))
3. 単純な特徴抽出
動作関連の機能: eid および udmap 関連の機能抽出
- udmap での値特徴抽出: ベースラインですでに指定されています
- udmap での主要な特徴の抽出
import json
def extract_keys_as_string(row):
if row == 'unknown':
return None
else:
parsed_data = json.loads(row)
keys = list(parsed_data.keys())
keys_string = '_'.join(keys) # 用下划线连接 key
return keys_string
train_df['udmap_key'] = train_df['udmap'].apply(extract_keys_as_string)
train_df['udmap_key'].value_counts()
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-PkbowYDJ-1692365546794) (C:\Users\ZYM\AppData\Roaming\Typora\) typora-user-images\ image-20230818195454065.png)]](https://img-blog.csdnimg.cn/37cfbfe15fa94d4aacc424487216af78.png)
eid と udmap_key の対応を確認します。
train_df.groupby('eid')['udmap_key'].unique()
![[外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-9zqnrzDe-1692365546795) (C:\Users\ZYM\AppData\Roaming\Typora\) typora-user-images\ image-20230818195553955.png)]](https://img-blog.csdnimg.cn/4e9d85d5b31b449f88a73604b1aa5d44.png)
分析: eid と key には強い相関関係がある、または相互に対応していることがわかり、動作関連の機能は eid、key、value を中心に構築できます。
4. データの視覚化
離散変数
個々の特性を表示します。
for i in train_data.columns:
if train_data[i].nunique() < 10:
print(f'{
i}, {
train_data[i].nunique()}: {
train_data[i].unique()}')
else:
print(f'{
i}, {
train_data[i].nunique()}: {
train_data[i].unique()[:10]}')
![[外部リンク画像の転送に失敗しました。ソース サイトには盗難防止リンク メカニズムがある可能性があります。画像を保存して直接アップロードすることをお勧めします (img-sPwmt4rl-1692365546795) (C:\Users\ZYM\AppData\Roaming\Typora) \typora-user-images\ image-20230818200557544.png)]](https://img-blog.csdnimg.cn/744e4773a01448e3b4c6f8212d3561db.png)
分析します:
-
['eid'、'x3'、'x4'、'x5'] は、より多くの値を持つカテゴリの特徴です
-
['x1', 'x2', 'x6','x7, 'x8'] は値が少ないカテゴリ特徴であり、x8 は基本的に性別特徴として決定されます
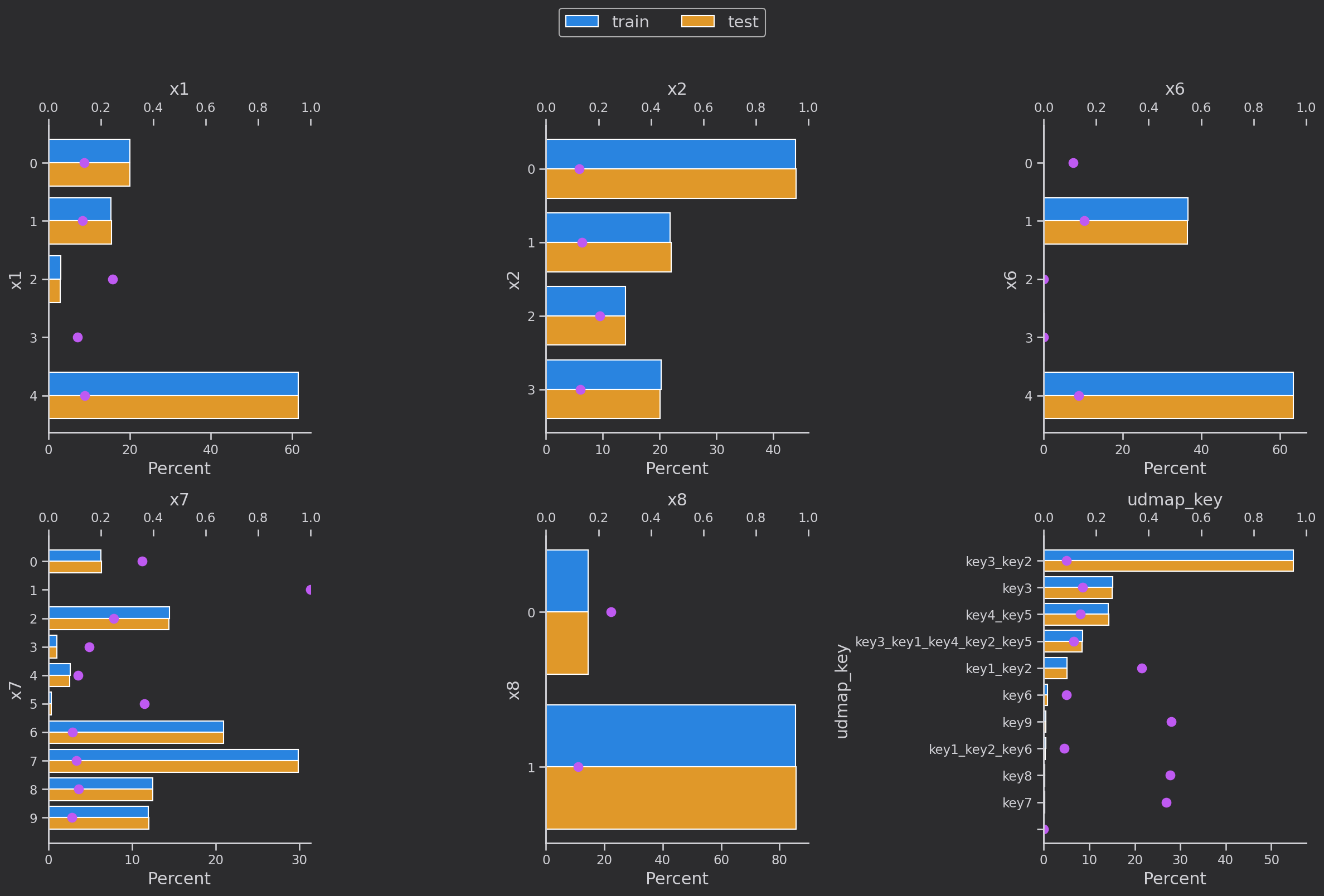
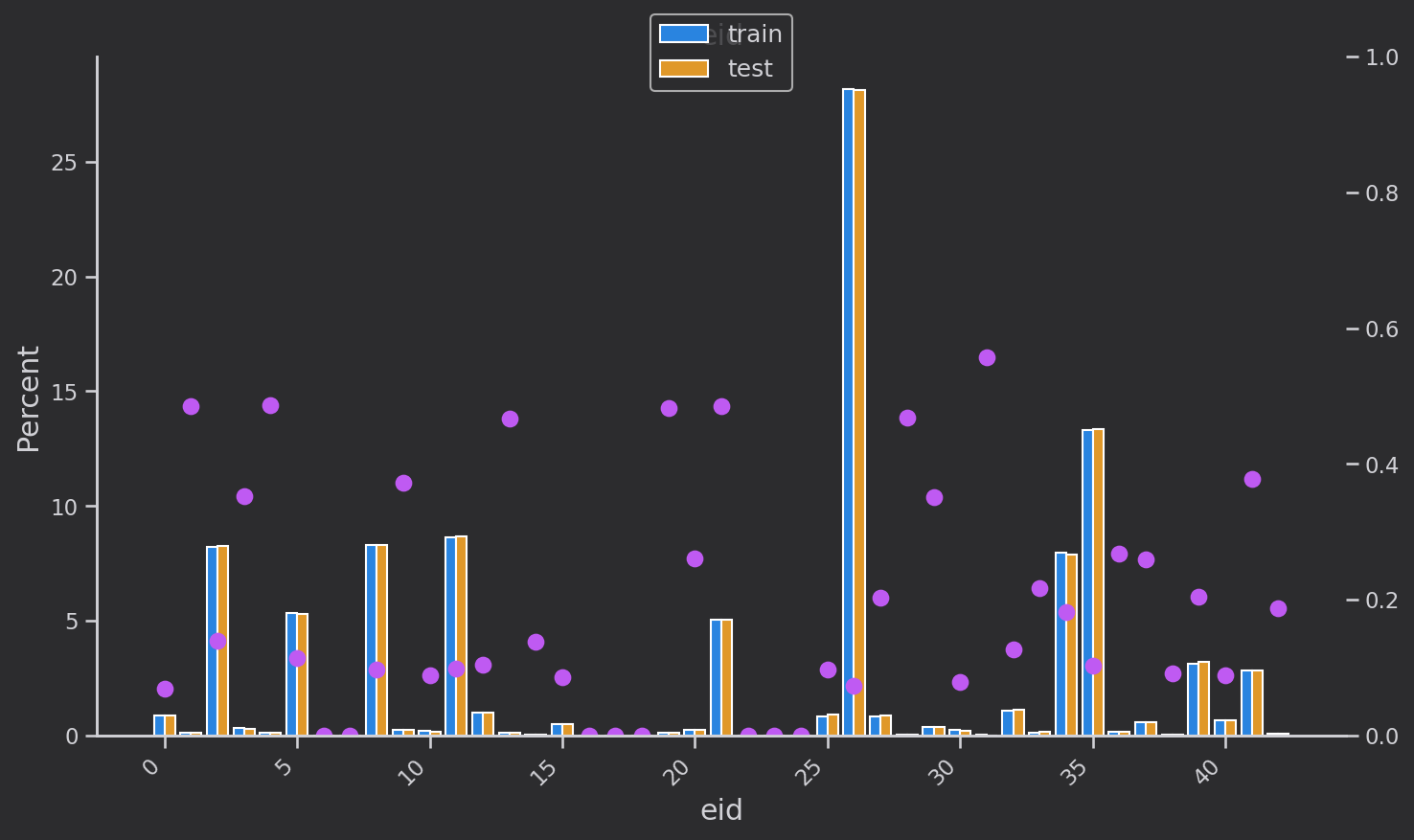
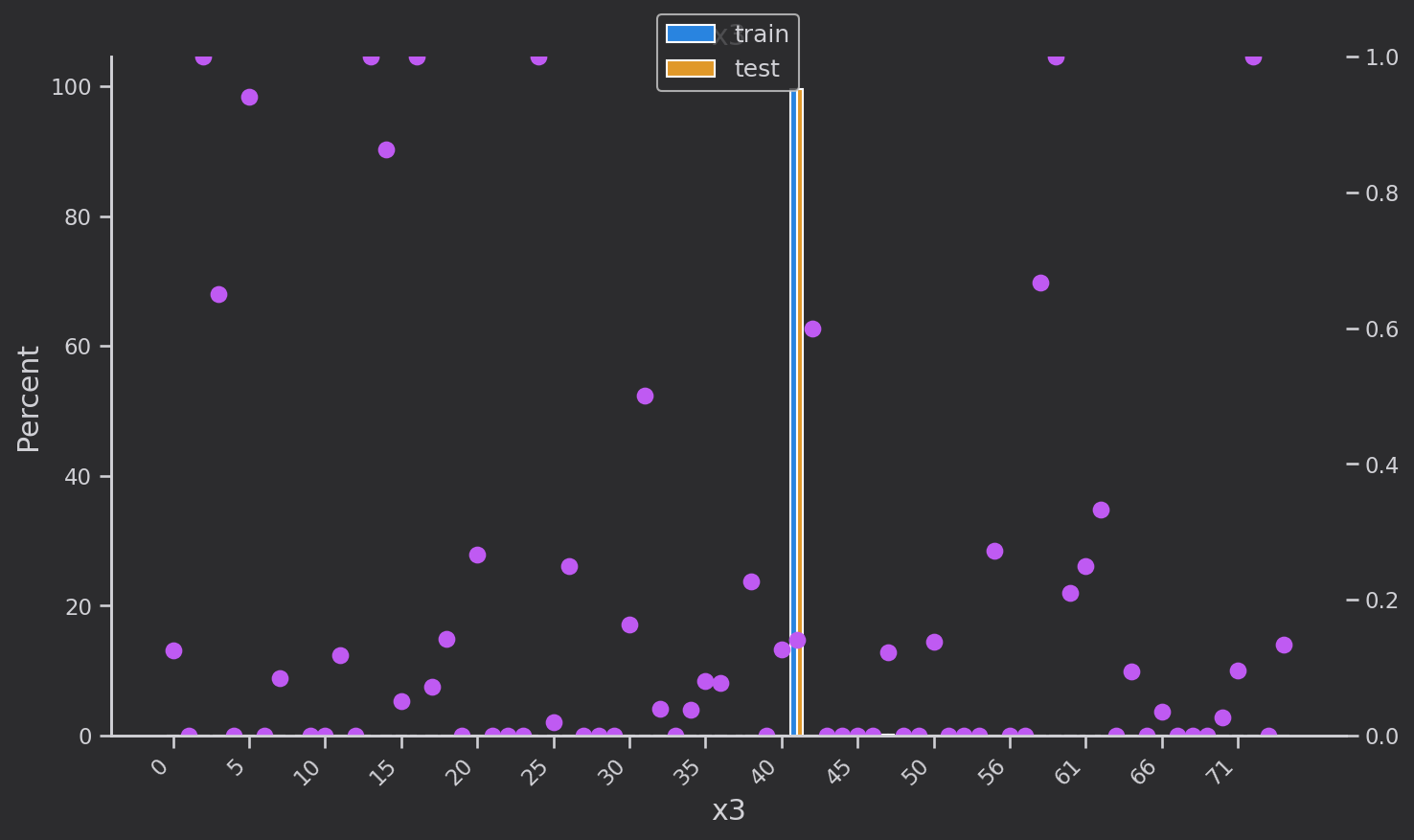
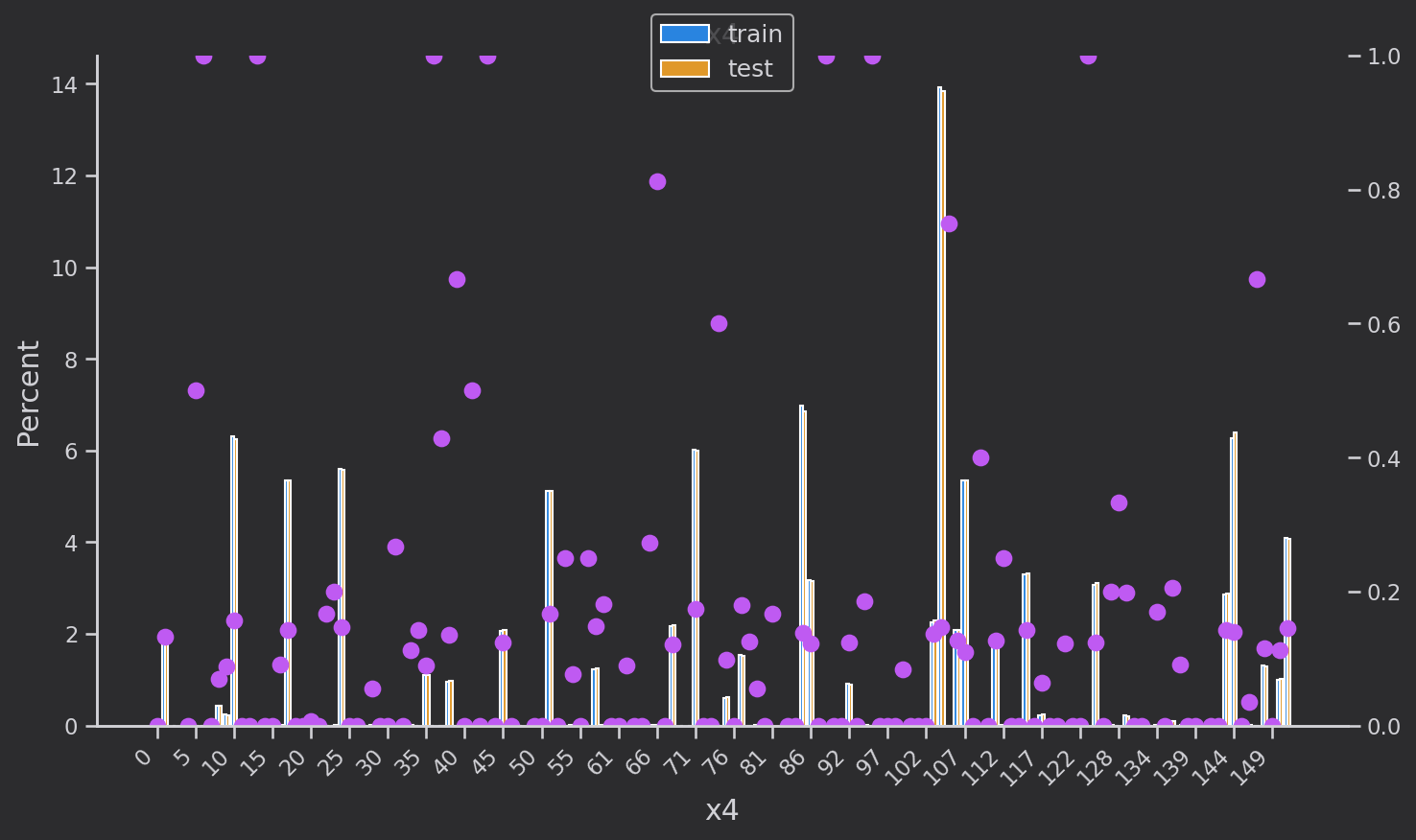
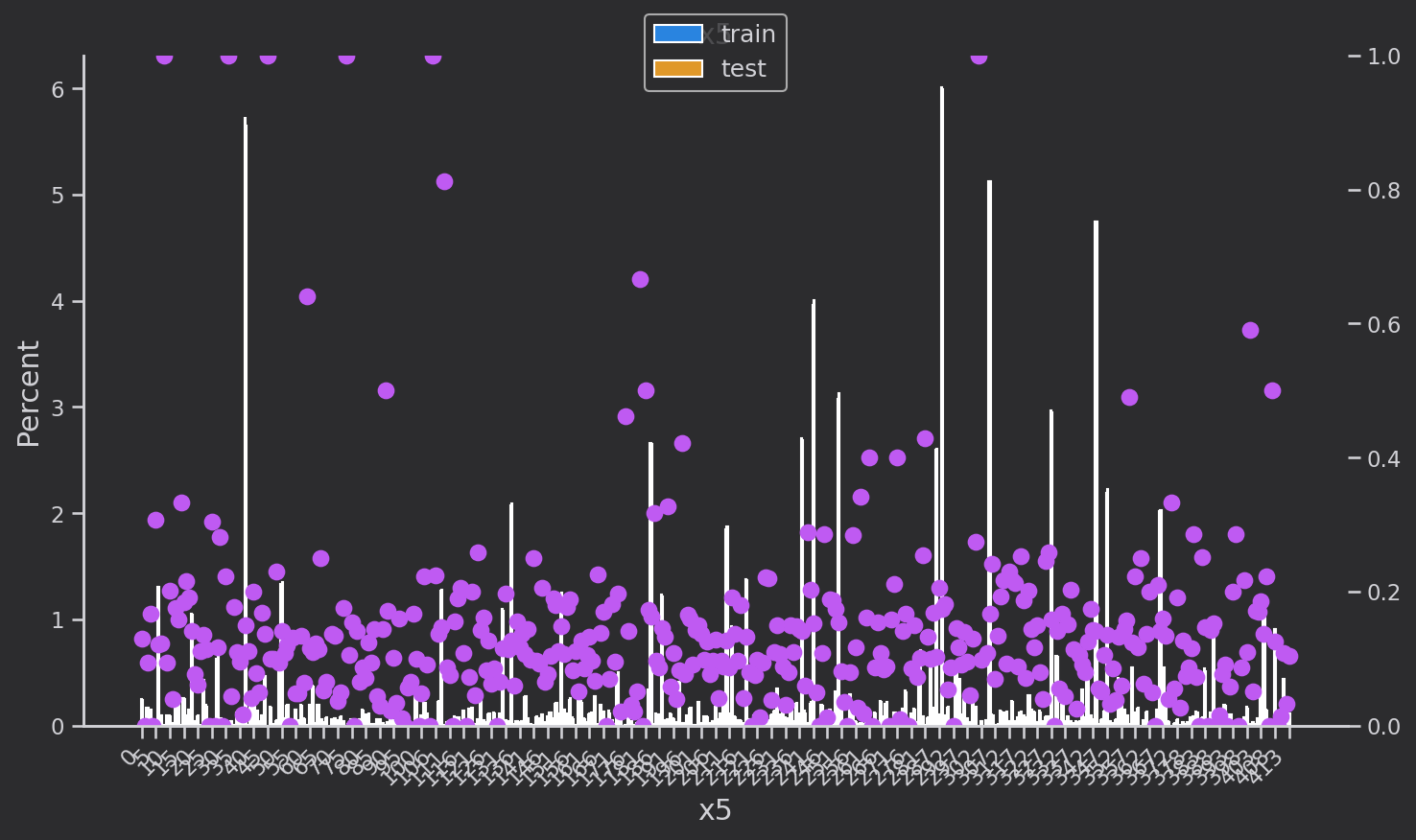
離散変数分布解析
離散変数の分布を調べます['eid', 'x3', 'x4', 'x5‘,'x1', 'x2', 'x6','x7', 'x8'']。青はトレーニング セット、黄色は検証セットで、分布は基本的に同じです。ピンクの点はトレーニング セットの各カテゴリの各
値のターゲットの平均値です。つまり、のtarget=1割合
描画コード:
def plot_cate_large(col):
data_to_plot = (
all_df.groupby('set')[col]
.value_counts(True)*100
)
fig, ax = plt.subplots(figsize=(10, 6))
sns.barplot(
data=data_to_plot.rename('Percent').reset_index(),
hue='set', x=col, y='Percent', ax=ax,
orient='v',
hue_order=['train', 'test']
)
x_ticklabels = [x.get_text() for x in ax.get_xticklabels()]
# Secondary axis to show mean of target
ax2 = ax.twinx()
scatter_data = all_df.groupby(col)['target'].mean()
scatter_data.index = scatter_data.index.astype(str)
ax2.plot(
x_ticklabels,
scatter_data.loc[x_ticklabels],
linestyle='', marker='.', color=colors[4],
markersize=15
)
ax2.set_ylim([0, 1])
# Set x-axis tick labels every 5th value
x_ticks_indices = range(0, len(x_ticklabels), 5)
ax.set_xticks(x_ticks_indices)
ax.set_xticklabels(x_ticklabels[::5], rotation=45, ha='right')
# titles
ax.set_title(f'{
col}')
ax.set_ylabel('Percent')
ax.set_xlabel(col)
# remove axes to show only one at the end
handles = []
labels = []
if ax.get_legend() is not None:
handles += ax.get_legend().legendHandles
labels += [x.get_text() for x in ax.get_legend().get_texts()]
else:
handles += ax.get_legend_handles_labels()[0]
labels += ax.get_legend_handles_labels()[1]
ax.legend().remove()
plt.legend(handles, labels, loc='upper center', bbox_to_anchor=(0.5, 1.08), fontsize=12)
plt.tight_layout()
plt.show()
次のステップは、データを分析して機能を構築することです。