非線形活性化関数は深層学習ネットワークの重要な部分であり、近年の急速な発展に伴い、より多くの活性化関数が提案され、改良されています。適切な活性化関数を選択すると、モデルの最終結果が決まります。以下に、一般的な 13 個の活性化関数の計算方法とその対応画像をまとめます (この記事の計算方法は pytorch から引用しています)。
1.シグモイド
これは以前の活性化関数であり、その計算式は次のとおりです。
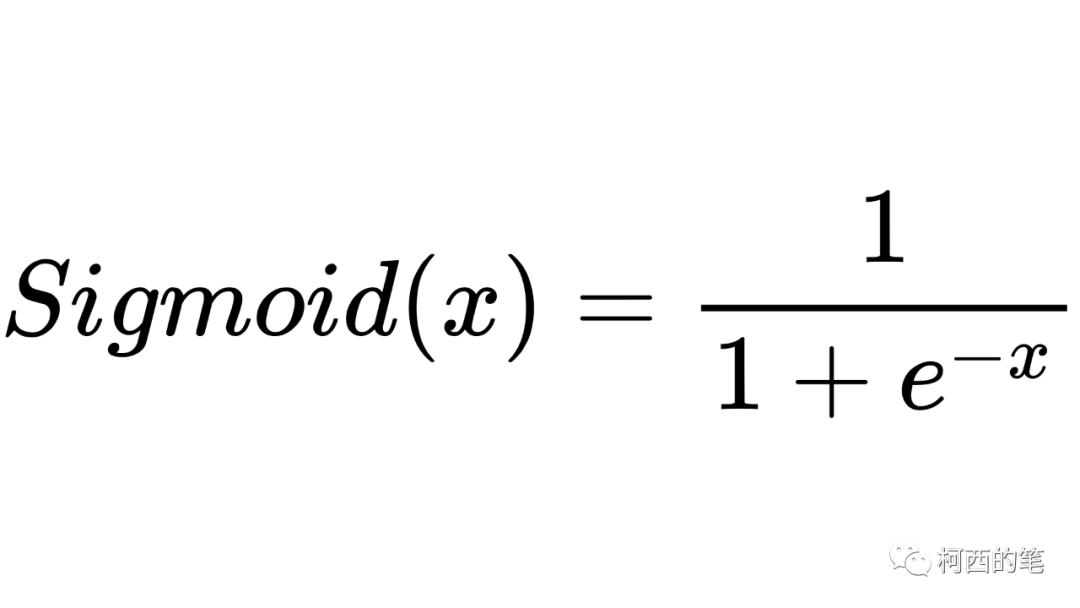
その図は次のとおりです。

アドバンテージ:
シグモイド関数の出力は (0,1) の間であり、出力範囲は制限されており、最適化は安定しており、出力層として使用できます。
連続関数、導関数を簡単に見つけることができます。
欠点:
べき乗が必要であり、計算コストが高くなります。
出力は平均 0 にならないため、収束率が低下します。
勾配の分散が起こりやすく、バックプロパゲーションの際、勾配が0に近い場合は基本的に重みが更新されないため、深いネットワークの学習が完了できません。
2.対数シグモイド
その計算式は次のとおりです。
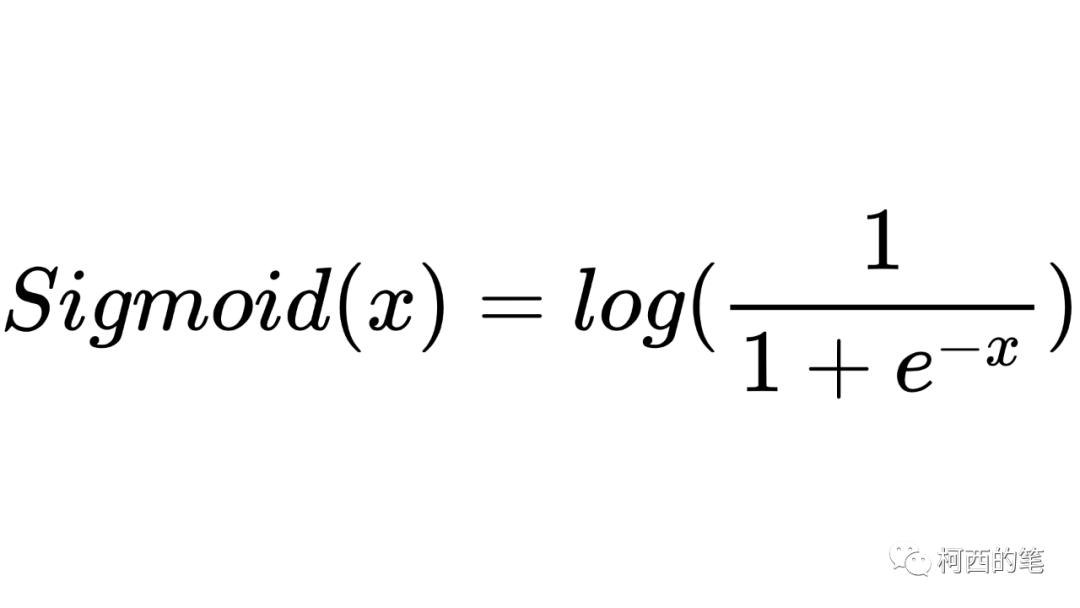
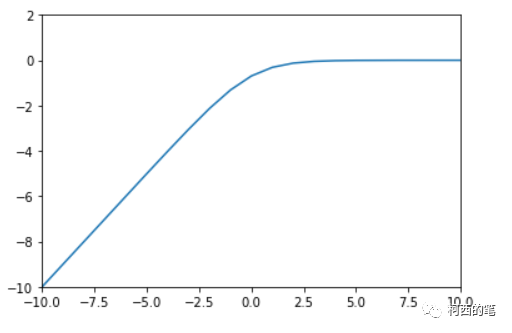
その図は次のとおりです。
3. リプレイ
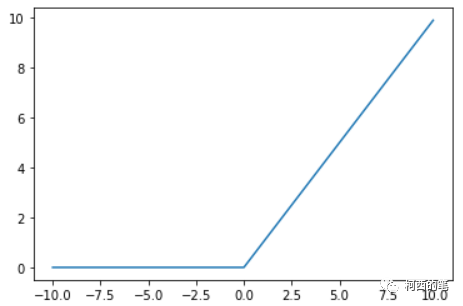
ディープ ニューラル ネットワークで最もよく使用される活性化関数の 1 つで、その計算式は次のとおりです。
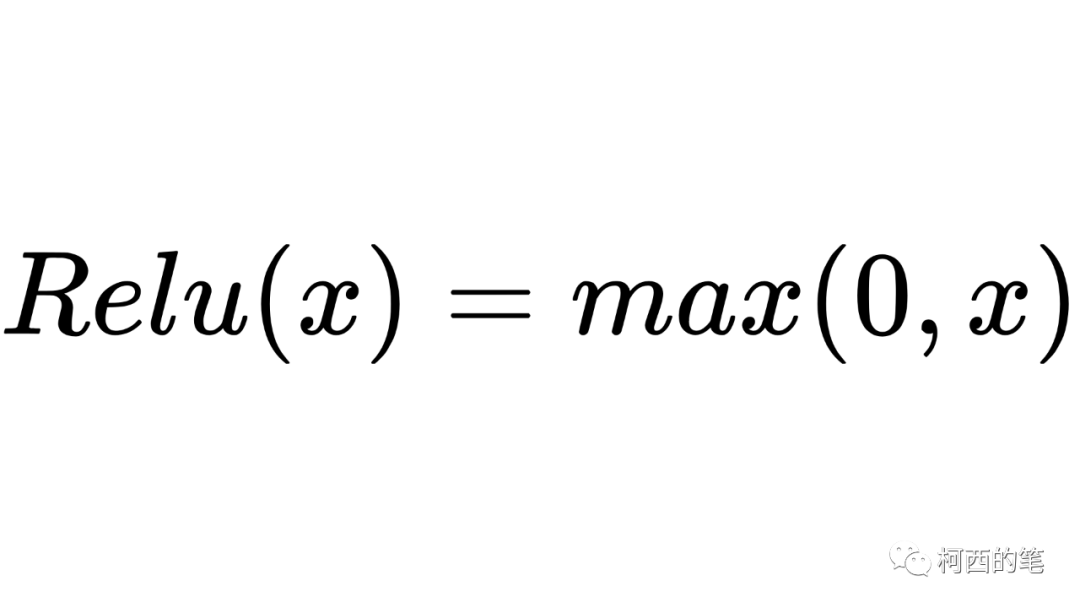
その図は次のとおりです。
アドバンテージ:
x>0 の領域では、勾配の飽和や勾配の消失の問題が発生せず、収束速度が速くなります。
指数演算が不要なため、演算速度が速く、複雑さが軽減されます。
欠点:
出力の平均はゼロではありません。
ニューロンの死があり、x<0 では勾配は 0 になります。このニューロンと後続のニューロンの勾配は常に 0 であり、どのデータにも応答しなくなるため、対応するパラメーターは更新されません。
4.リーキーレル
上記の Relu は x が 0 未満の場合に 0 を出力しますが、LeakyRelu は x が 0 未満の場合に 0 以外の値を出力することができ、その計算式は次のとおりです。
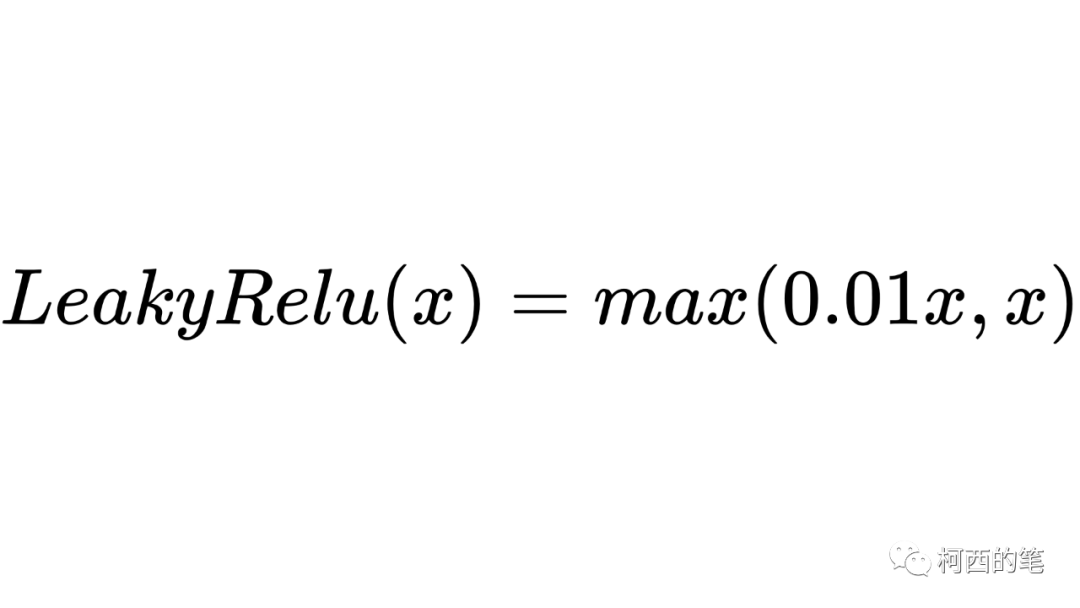
その図は次のとおりです。
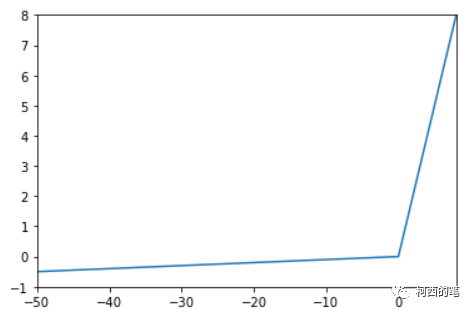
アドバンテージ:
Relu のニューロン死の問題を解決すると、負の領域に小さな正の傾きがあるため、負の入力値でも逆伝播できます。
Relu機能の利点があります。
欠点:
結果に一貫性がなく、正および負の入力値に対して一貫した関係予測を提供できない
5.高い
ReLUのマイナス部分の改良でもあり、ELU活性化関数は指数計算方式を採用し、xが0未満の場合を出力します。計算式は次のとおりです。
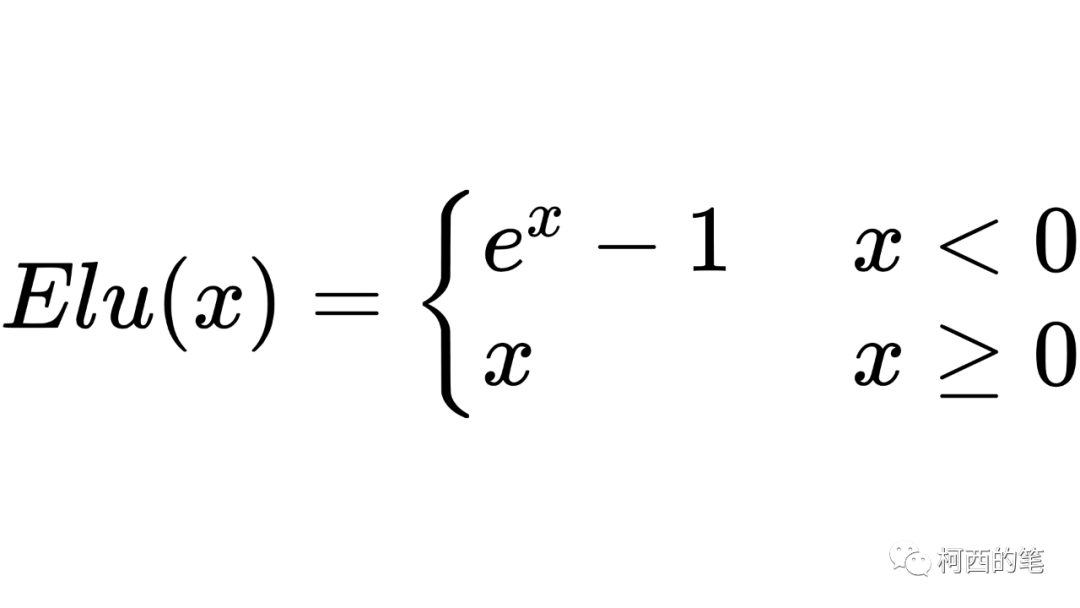
その図は次のとおりです。
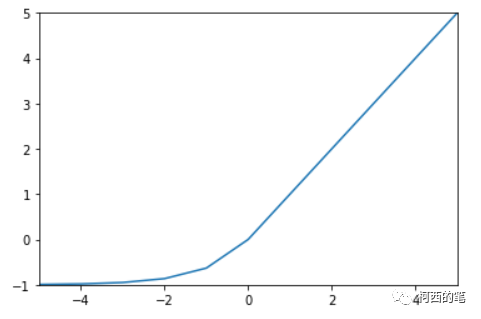
アドバンテージ:
はすべての点で連続微分可能です。
Relu やそのバリアントなど、他の線形非飽和活性化関数と比較してトレーニング時間が短縮されます。
ニューロン死の問題はありません。
非飽和活性化関数として、勾配の爆発または消滅の影響を受けず、精度が高くなります。
欠点:
べき乗が含まれるため、計算速度が遅くなります。
6. プレリュード
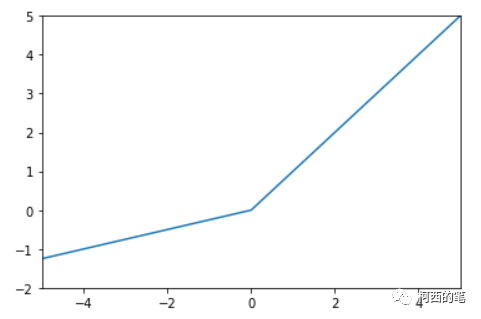
このうち、a は固定ではなく逆伝播によって学習されます。その計算式は次のとおりです。
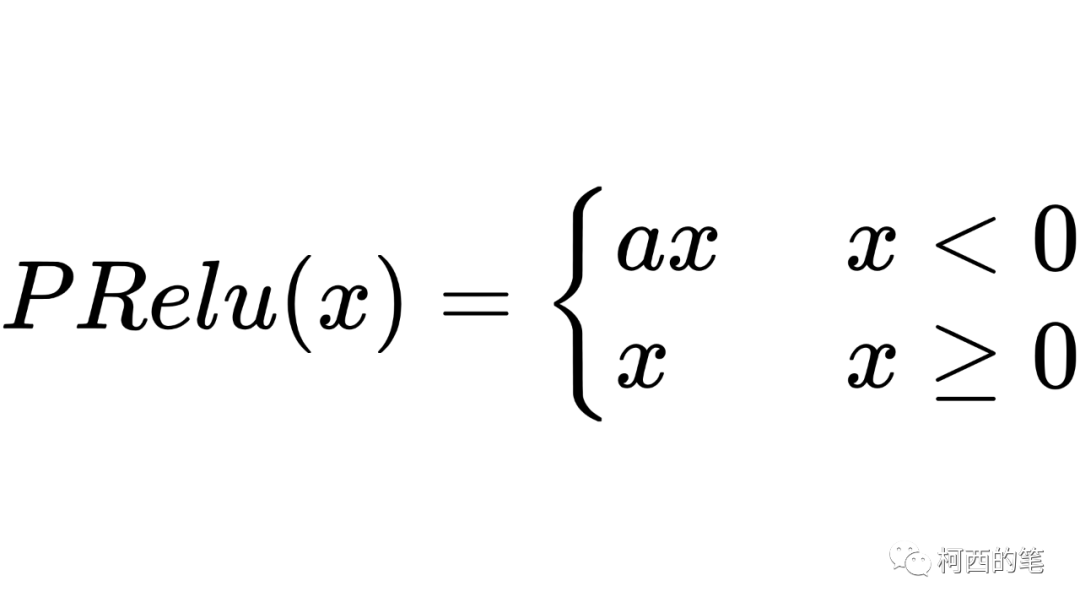
その図は次のとおりです。
7.レル6
Relu6 は Relu の出力を 6 までに制限しており、その計算式は次のとおりです。
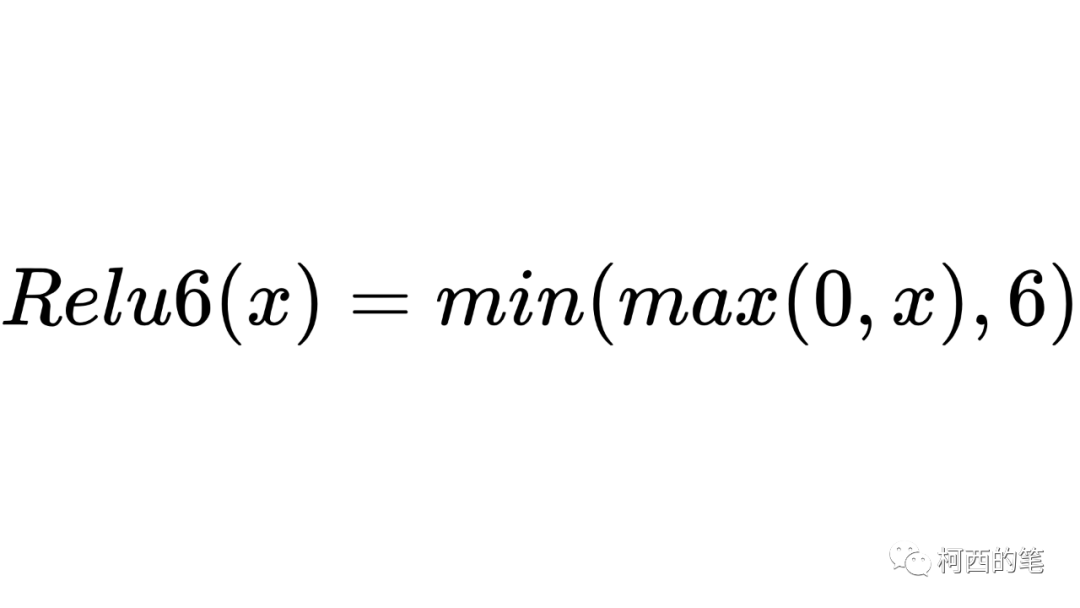
その図は次のとおりです。
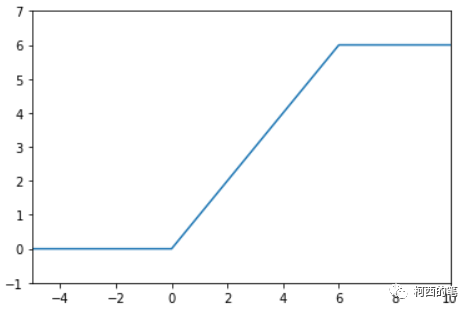
Relu は x>0 の領域で線形活性化に x を使用しますが、これにより活性化された値が大きすぎてモデルの安定性に影響を与える可能性があります。ReLU 活性化関数の線形成長部分を相殺するために、Relu6 は機能を使用することができます。
8.Rレル
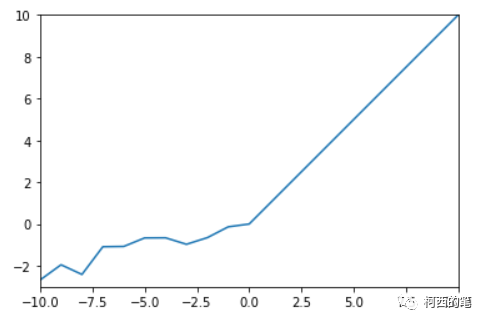
「Random Rectified Linear Unit」RRelu も LeakyRelu の亜種です。RRelu では、負の値の傾きはトレーニング中にランダムであり、その後のテスト中に固定されます。その計算式は次のとおりです。
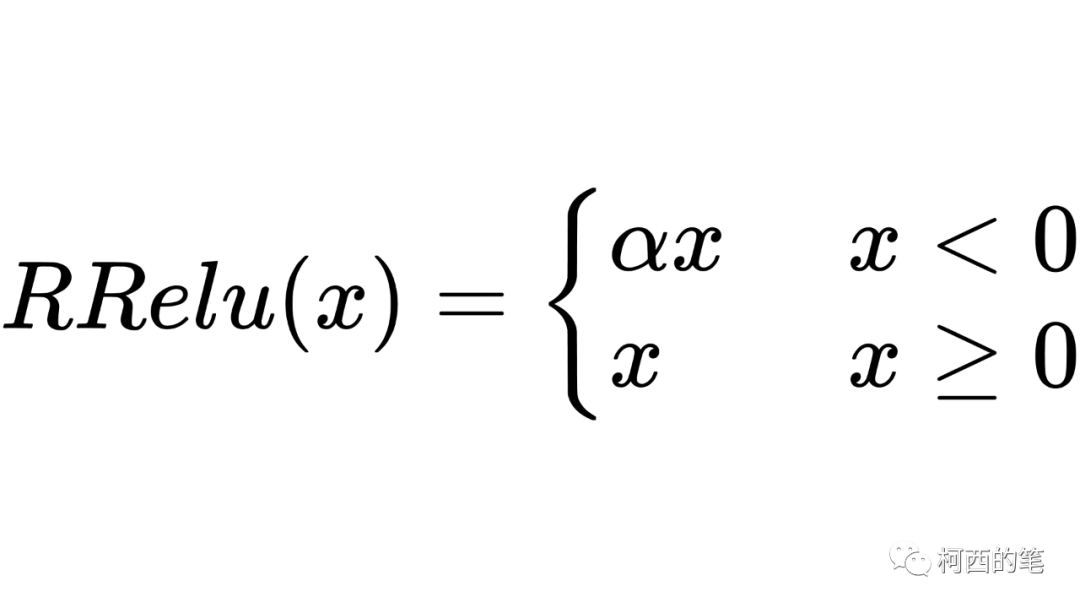
その図は次のとおりです。
9. セル
SElu と Elu の形式は似ていますが、もう 1 つスケール パラメーターがあります。その計算式は次のとおりです。
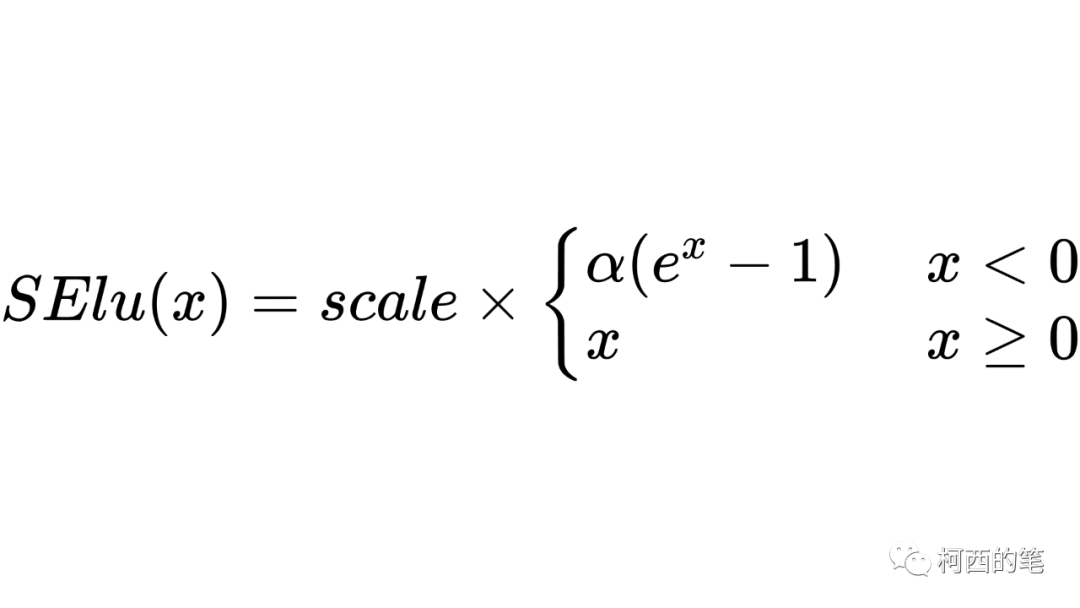
その図は次のとおりです。
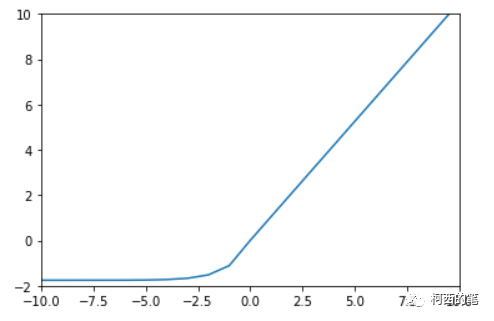
pytorch の acale=1.0507009873554804934193349852946。
10. 目的
CElu も上記の SElu と同様に、負の範囲は指数計算、整数範囲は線形計算として使用され、計算式は次のようになります。
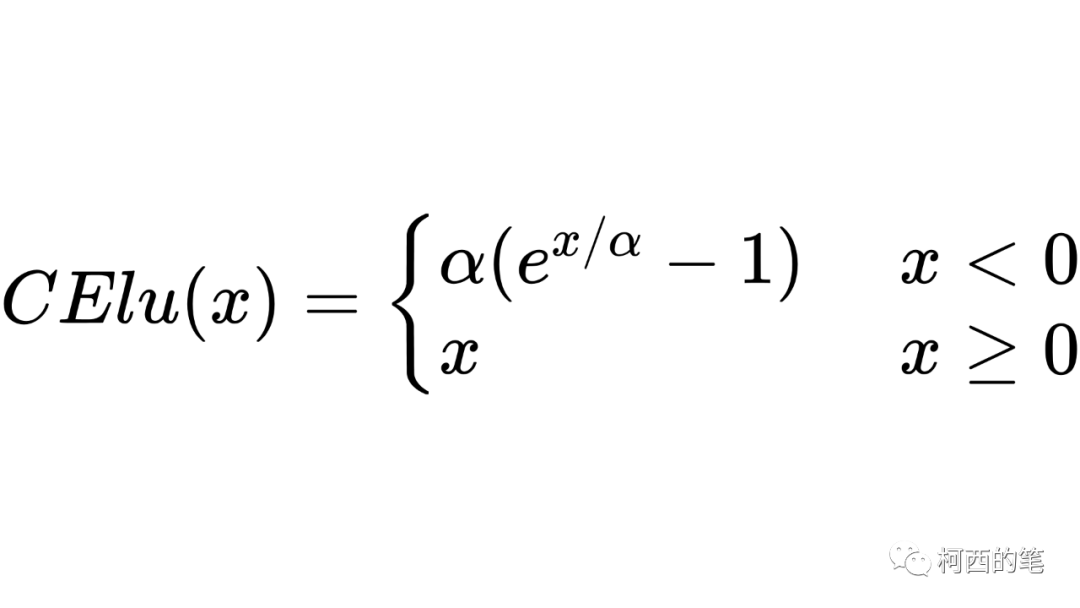
その図は次のとおりです。
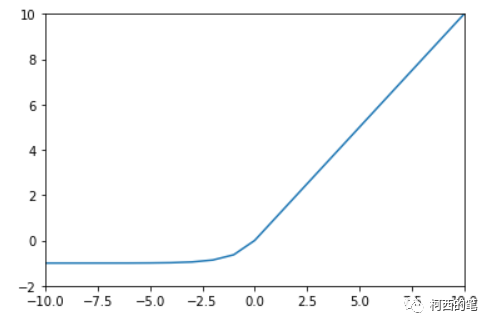
11. ゲル
活性化関数には正則化手法が追加されており、その計算式は次のようになります。
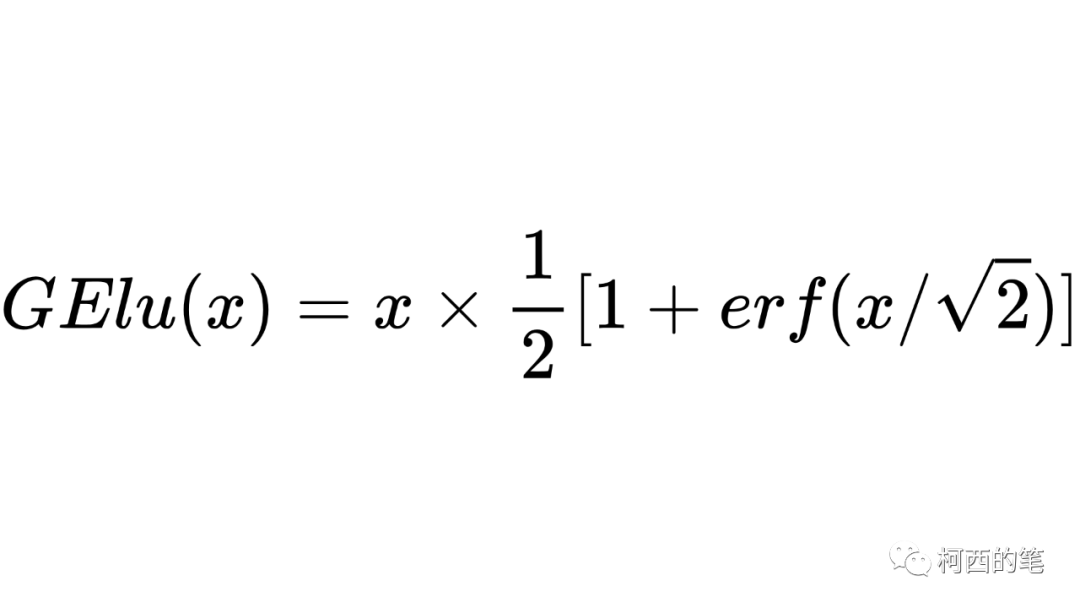
erf には解析的な表現がないため、元の論文では近似解が得られます。
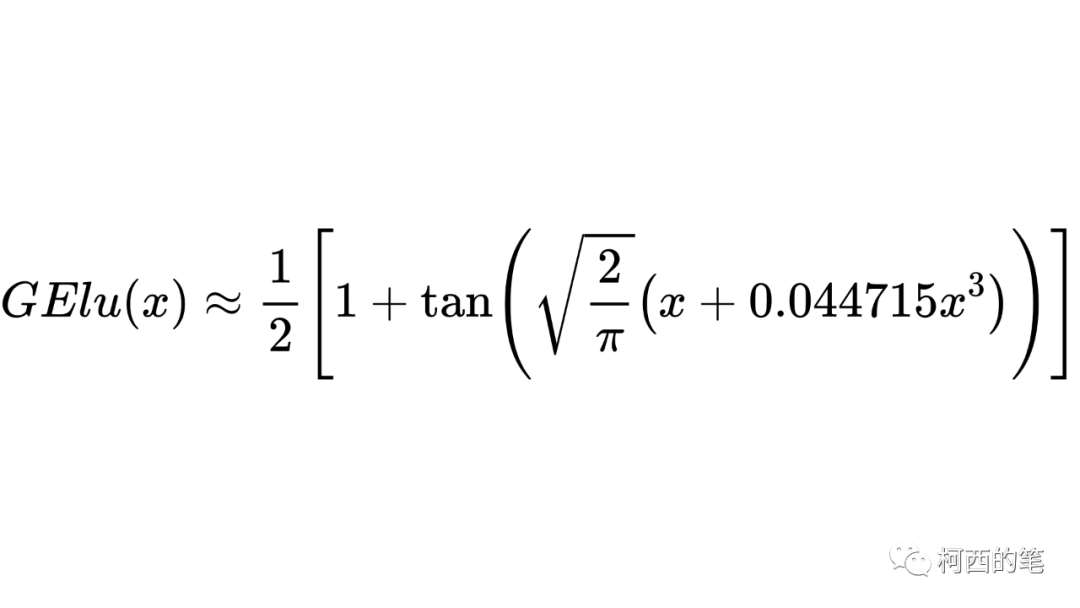
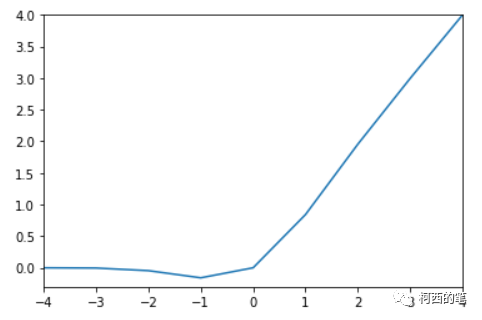
その図は次のとおりです。
12.唐
数学における双曲線正接関数 Tanh は、ニューラル ネットワーク、特に画像生成タスクの最終層で一般的に使用される活性化関数でもあり、その計算式は次のとおりです。
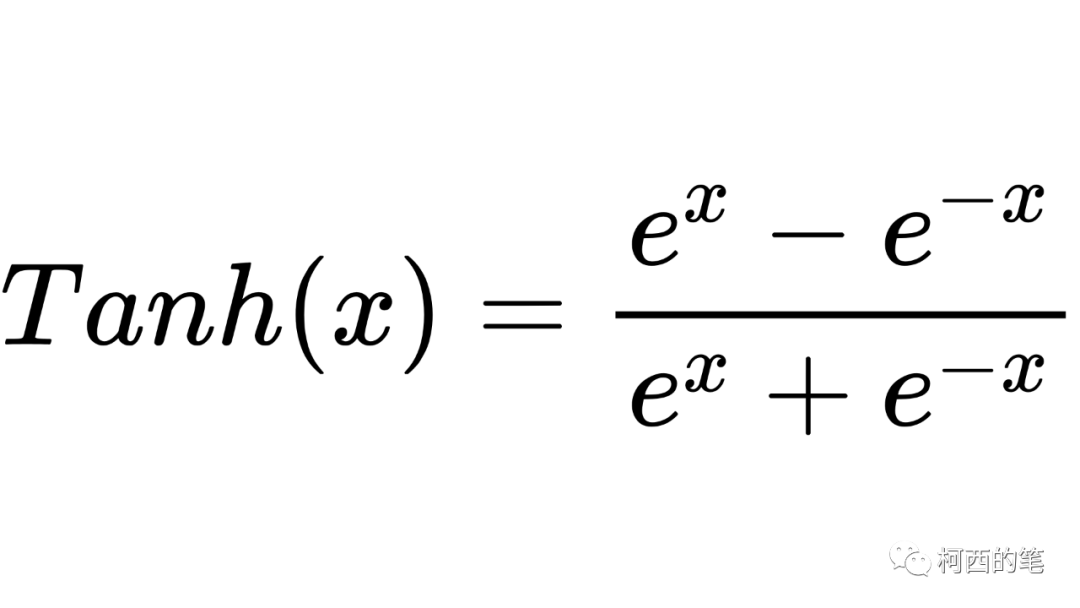
その図は次のとおりです。
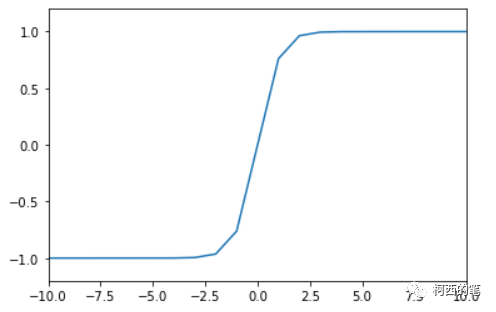
アドバンテージ:
出力平均値は 0 であるため、シグモイドよりも収束速度が速くなり、反復回数を減らすことができます。
欠点:
欠点は、べき乗が必要であり、計算コストが高いことです。
両側とも0に近づく場合もあるので、勾配消失もあります。
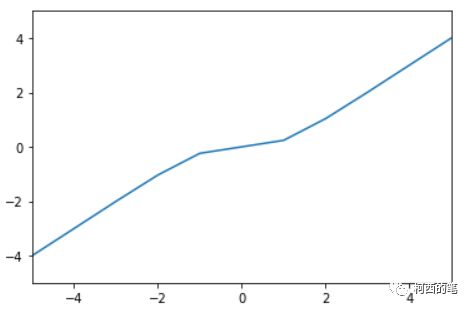
13.タンシュリンク
Tanhshrink は入力から双曲線正接の値を引いた値を直接使用し、その計算式は次のとおりです。
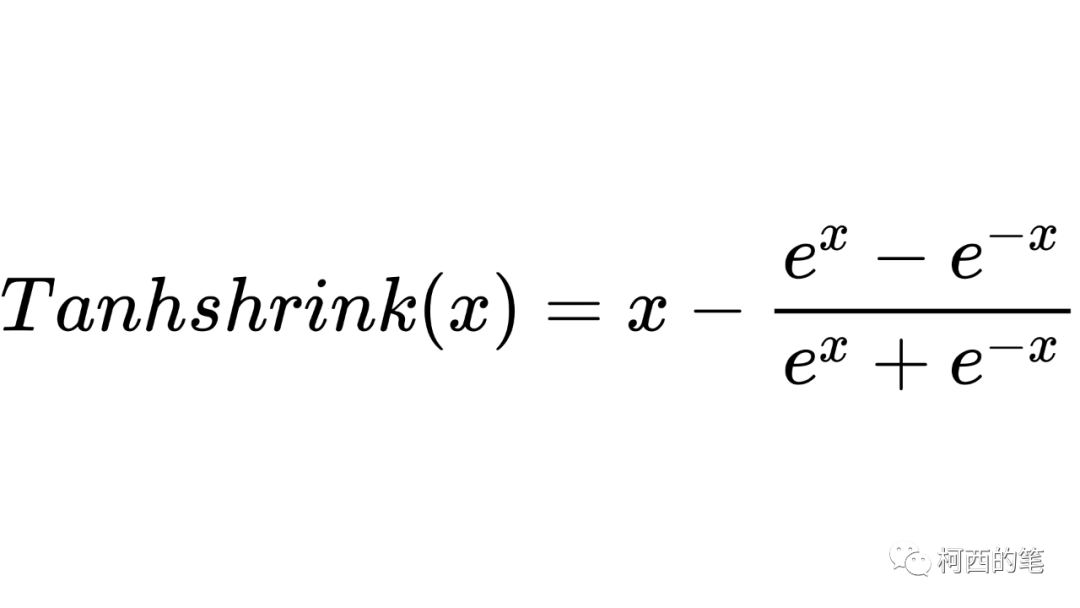
その図は次のとおりです。
要約:
最初に最も高速な ReLU を使用し、次にモデルのパフォーマンスを観察します。
ReLU 効果があまり良くない場合は、LeakyRelu などの亜種を試すことができます。
深さがそれほど深くない CNN では、一般に活性化関数の影響はそれほど大きくありません。