運河とは
アリババ B2B 企業は、事業の特性上、売り手は主に中国に集中し、買い手は主に海外に集中しているため、杭州と米国のコンピューター室を同期する需要が生じています。アリババを拠点とする企業は、データベースベースのログ分析を使用し、同期のための増分変更を取得し、増分サブスクリプションおよび消費型ビジネスを導き出そうと徐々に試みてきました。
Canal はデータベースの増分ログ解析に基づいて Java で開発され、増分データのサブスクリプションと消費のためのミドルウェアを提供します。現在、Canal は主に MySQL の Binlog の分析をサポートしており、分析が完了した後に取得された関連データを処理するために Canal Client が使用されます。(データベースの同期には、Canal をベースにした Ali の Otter ミドルウェアが必要です)。
MySQL バイログ
MySQL のバイナリ ログは、MySQL の最も重要なログと言えます。すべての DDL および DML (データ クエリ ステートメントを除く) ステートメントがイベントの形式で記録され、ステートメントの実行に費やされた時間も含まれます。MySQL のバイナリ ログはトランザクションです。安心タイプ。
一般に、バイナリ ログをオンにすると、約 1% のパフォーマンスの低下が発生します。バイナリには 2 つの最も重要な使用シナリオがあります。
1 つ目: MySQL レプリケーションはマスター側で Binlog を開き、マスターはそのバイナリ ログをスレーブに渡してマスターとスレーブのデータ整合性の目的を達成します。
2 番目: 当然、データは復元され、MySQL Binlog ツールを使用してデータが復元されます。
バイナリ ログには 2 種類のファイルが含まれます。バイナリ ログ インデックス ファイル (ファイル名サフィックス .index) はすべてのバイナリ ファイルを記録するために使用され、バイナリ ログ ファイル (ファイル名サフィックス . ステートメント) はステートメント イベントを記録します。
ビンログの分類
MySQL Binlog には STATEMENT、MIXED、ROW の 3 つの形式があります。構成ファイルで binlog_format= ステートメント|混合|行を構成することを選択できます。3 つの形式の違い:
1) ステートメント: ステートメント レベル、binlog は書き込み操作を実行するステートメントを毎回記録します。行モードと比較してスペースは節約されますが、「update tt set create_date=now()」などの不整合が発生する可能性があります。リカバリに binlog ログが使用される場合、実行時間の違いによりデータが異なる可能性があります。
利点: スペースを節約します。
短所: データの不整合が発生する可能性があります。
2) row: 行レベル。binlog は各操作後の各行レコードの変更を記録します。
利点: データの絶対的な一貫性を維持します。SQLが何であっても、どの関数が参照されても、実行後の効果のみを記録するためです。
短所: 多くのスペースを占有します。
3) 混合: アップグレードされたバージョンのステートメントは、何らかの状況によって引き起こされたステートメント モードの不一致を解決し、デフォルトはステートメントです。
場合によっては、ステートメントは ROW の方法で処理されます。次に例を示します。
1: 関数に UUID() が含まれる場合。
2: AUTO_INCREMENT フィールドを含むテーブルが更新されたとき。
3: INSERT DELAYED 文を実行する場合。
4: UDF を使用する場合。
利点: ある程度の一貫性を考慮しながら、スペースを節約します。
短所: まれに不一致が発生する場合があり、さらに、ステートメントと混合はバイナリログの監視が必要な状況では不便です。
上記の比較に基づいて、Canal は監視と分析を実行したいと考えており、行形式を選択することがより適切です。
運河の仕組み
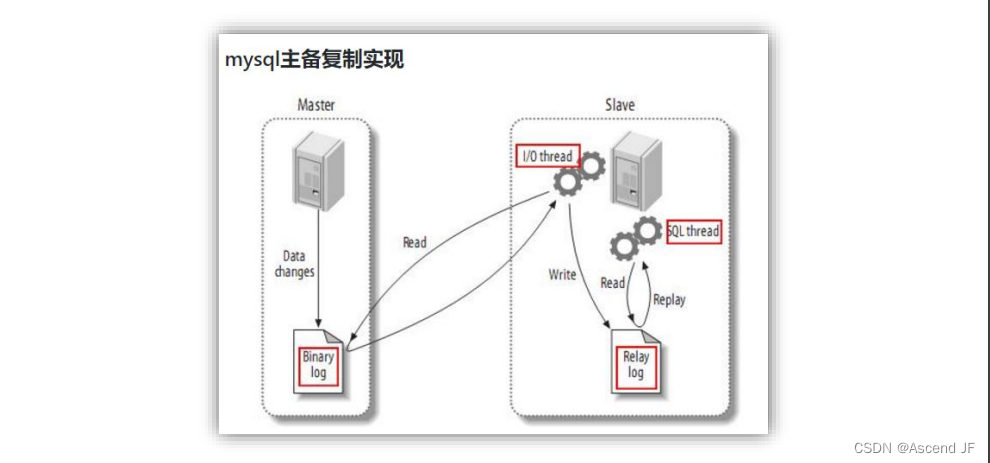
MySQL マスター/スレーブ レプリケーション プロセス
1) マスター メイン ライブラリはレコードを変更し、バイナリ ログ (バイナリ ログ) に書き込みます。
2) スレーブはライブラリから MySQL マスターにダンプ プロトコルを送信し、マスターのメイン ライブラリのバイナリ ログ イベントをリレー ログ (リレー ログ) にコピーします。
3) スレーブは、ライブラリからリレー ログ内のイベントを読み取ってやり直し、変更されたデータを自身のデータベースに同期します。
運河の仕組み
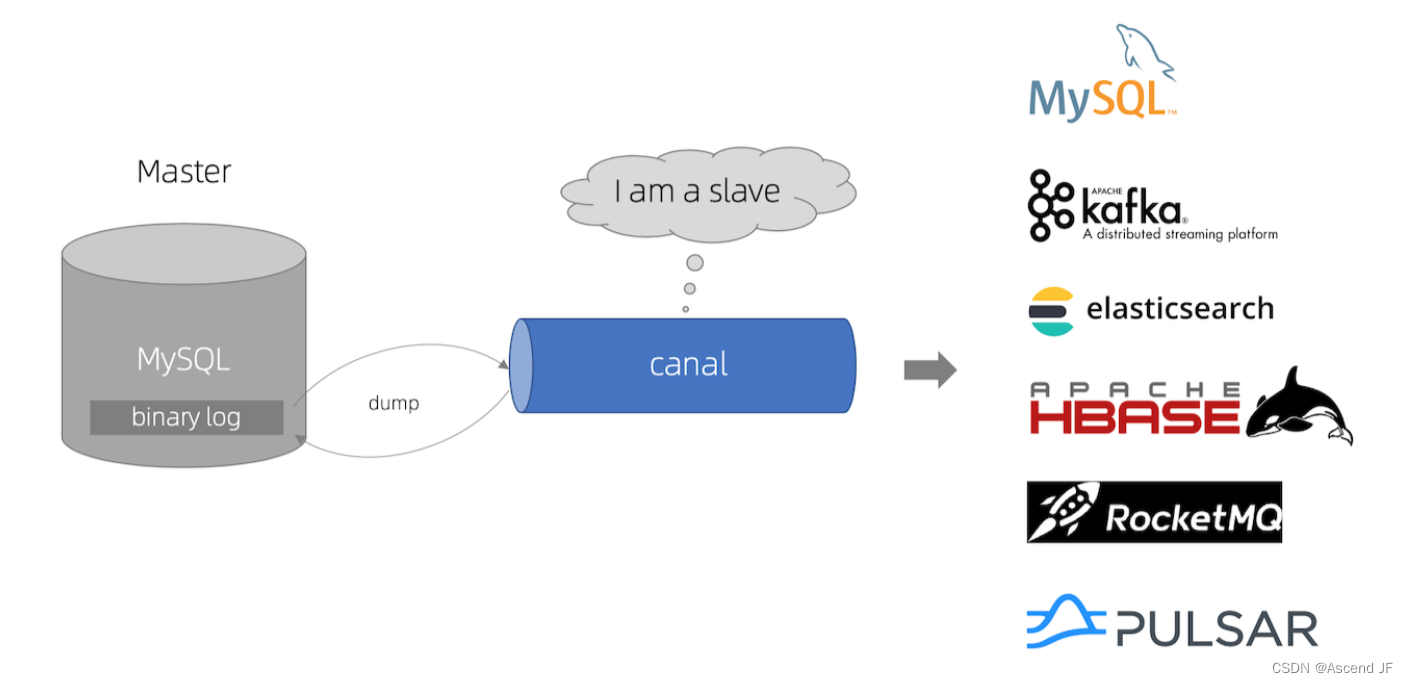
原理は比較的単純です。
-
canal は、mysql スレーブのインタラクティブ プロトコルをシミュレートし、mysql スレーブのふりをして、mysql マスターにダンプ プロトコルを送信します。
-
mysql マスターはダンプ リクエストを受信し、バイナリ ログをスレーブ (つまり運河) にプッシュし始めます。
-
canal はバイナリ ログ オブジェクト (元はバイト ストリーム) を解析します。
運河の利用シナリオ
1) 元のシナリオ: Ali の Otter ミドルウェアの一部 Otter はリモート データベース間の同期のための Ali のフレームワークであり、Canal はその一部です。
2) 一般的なシナリオ 1: キャッシュを更新する

3) 一般的なシナリオ 2: リアルタイム統計のためにビジネス テーブル内の新しいデータと変更されたデータを取得します。
運河使用実戦
Mysqlのbinlog機能が有効になっているか確認する
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.10 sec)表示ステータスが OFF の場合は、機能が有効になっていないことを意味します。binlog 機能を有効にして、mysql 設定ファイル my.ini を変更し、次の内容を追加します。
log-bin=mysql-bin #binlog文件名
binlog_format=ROW #选择row模式
server_id=1 #mysql实例id,不能和canal的slaveId重复service mysql restart mysql を再起動します。
MySQL スレーブを使用して MySQL アカウントを作成する
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
Canal サーバーをダウンロードしてインストールする
https://github.com/alibaba/canal/releases
- カナルアダプター(カナルクライアント)
canal に相当するクライアントは、canal-server (tcp モードで構成する必要がある) からデータを取得し、そのデータを MySQL、Elasticsearch、HBase などのストレージに同期できます。canal-server に付属する canal.serverMode と比較して、canal-adapter によって提供されるダウンストリーム データはより広く受け入れられています。
- 運河管理者
全体的な構成管理、ノードの運用と保守、その他の運用と保守を中心とした機能を提供し、より多くのユーザーが迅速かつ安全に操作できる比較的使いやすい WebUI 操作インターフェイスを提供します。
- canal-deployer(運河サーバー)
MySQL の binlog を直接監視し、MySQL スレーブ ライブラリに偽装して、データを処理せずにのみ受信することができます。MySQL バイナリログ データを受信した後、canal.serverMode: tcp、kafka、RocketMQ、RabbitMQ 接続を設定することで、対応するダウンストリームに送信できます。このうち、tcp メソッドは、カナル クライアントをカスタマイズしてデータを受け入れることができ、より柔軟です。
instance.properties 構成ファイルを変更します。
#需要改成数据源mysql数据库的信息
canal.instance.master.address=127.0.0.1:3306
#需要改成自己的数据库创建的从库用户名与密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
#需要改成同步的数据库表规则
canal.instance.filter.regex=.*\\..*
一般的な一致ルール:
すべてのテーブル: .* または .\…
canal データベースの下のすべてのテーブル: canal\…*
canal データベースの下の canal で始まるテーブル: canal.canal.*
canal データベースの下のテーブル: canal.test1
複数のルールの組み合わせ: canal\…*、mysql.test1、mysql.test2 (カンマ区切り)
複数の Mysql インスタンス構成を監視する
複数の Mysql インスタンスを監視する必要がある場合、前の運河アーキテクチャを通じて、運河サービス内に複数のインスタンスが存在する可能性があり、conf/ の下にある各例がインスタンスであり、各インスタンスの下に独立した構成ファイルがあることがわかります。デフォルトでは、インスタンスの例は 1 つだけです。異なる MySQL データを処理するために複数のインスタンスが必要な場合は、複数の例を直接コピーして名前を変更します。名前は構成ファイルで指定された名前と一致し、canal で canal を変更します。プロパティ。宛先=インスタンス 1、インスタンス 2、インスタンス 3。

Canalサーバーsh bin/startup.shを実行します(Win環境でstartup.batを実行します)。
Springboot は Canal クライアントを統合します
canal-clint SpringBoot プロジェクトを作成する
canal-clint モジュールで pom.xml を構成する
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.2</version>
</dependency>スタンドアロンの Canal クライアントを作成する SimpleCanalClientExampleTest
package com.canal.clint.clint;
/**
* <p>
* </p>
* @since 2023-03-30 17:13
*/
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
public class SimpleCanalClientExampleTest {
public static void main(String[] args) throws InvalidProtocolBufferException {
// 1.获取 canal 连接对象
CanalConnector canalConnector =
CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
while (true) {
// 2.获取连接
canalConnector.connect();
// 3.指定要监控的数据库,此处指定了要监听的库,会覆盖instance.properties配置的数据库表规则
canalConnector.subscribe("intl.*");
// 4.获取 Message
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println("没有数据,休息一会");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
// TODO 获取表名
String tableName = entry.getHeader().getTableName();
// TODO Entry 类型
CanalEntry.EntryType entryType = entry.getEntryType();
// TODO 判断 entryType 是否为 ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
// TODO 序列化数据
ByteString storeValue = entry.getStoreValue();
// TODO 反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
// TODO 获取事件类型
CanalEntry.EventType eventType = rowChange.getEventType();
// TODO 获取具体的数据
List<CanalEntry.RowData> rowDataList = rowChange.getRowDatasList();
// TODO 遍历并打印数据
for (CanalEntry.RowData rowData : rowDataList) {
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
JSONObject beforeData = new JSONObject();
for (CanalEntry.Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
System.out.println("TableName:" + tableName + ",EventType:" + eventType + ",After:"
+ beforeData + ",After:" + afterData);
}
}
}
}
}
}
}データベースユーザーテーブルの作成
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`remark` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;データを挿入する
INSERT INTO `intl`.`user`(`id`, `name`, `remark`) VALUES (1, '哈喽', 'Canal测试');
出力結果
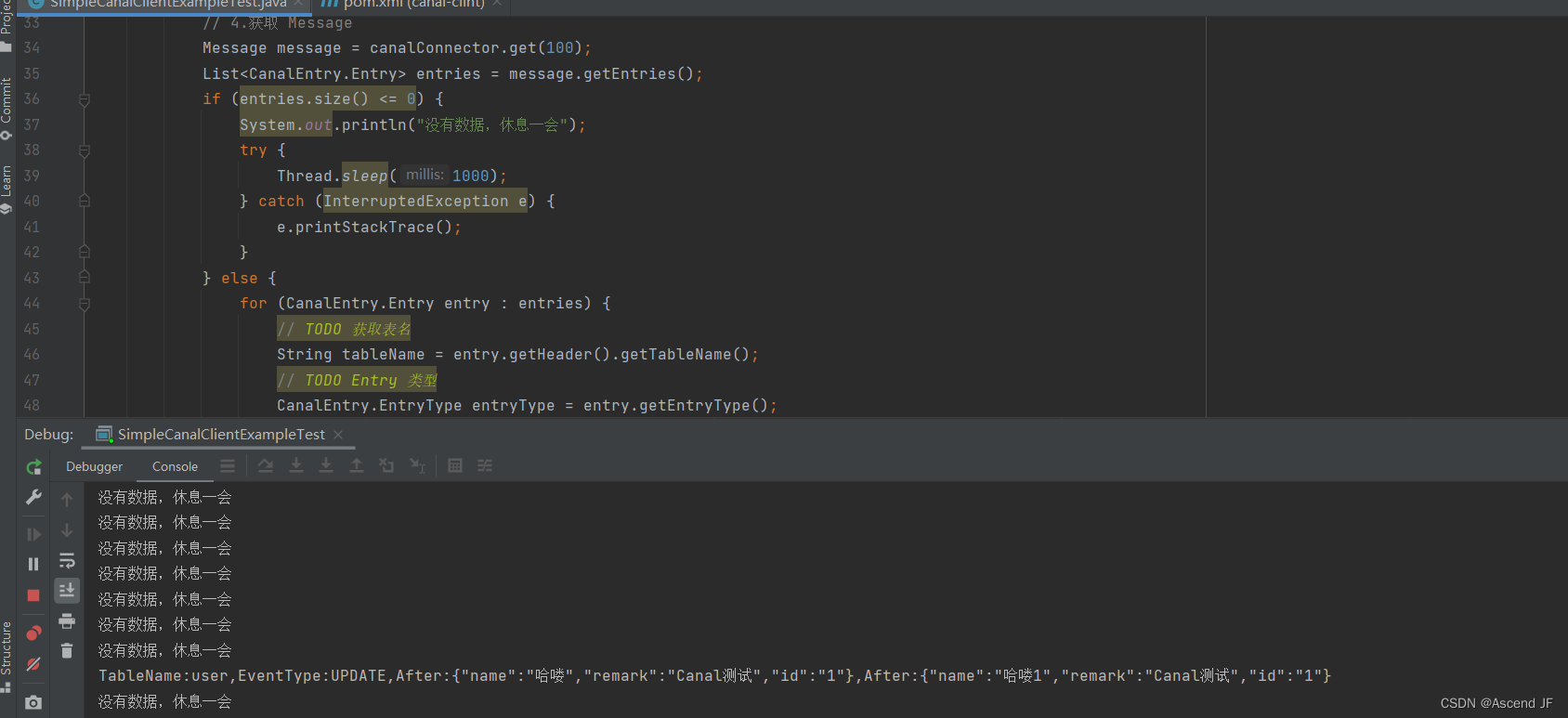
ピットに注意してください:
- Canal が Alibaba Cloud サーバーに基づいてインストールされている場合は、必ずポート 11111 (Canal のデフォルトのポート番号) を開いてください。
- クライアントが Connector.subscribe("intl.*") メソッドを呼び出し、監視するライブラリを指定すると、instance.properties によって構成されたデータベース テーブル ルールがオーバーライドされます。
- Mysql binlog ログ タイプが混合に設定されている場合、connector.subscribe("intl.*") メソッドが失敗し、Mysql インスタンス全体が監視される可能性があります。
Canal の展開ではクラスターもサポートされており、クラスター管理のために ZooKeeper と連携する必要があります。Canal には Web 管理インターフェイスもあります。