MirAIe ルール エンジンは、ユーザーが複数のアクティビティをグループ化して自動化できる、拡張可能なルール エンジン フレームワークです。
過去数年間にわたって MirAIe IoT プラットフォームを開発する中で、私たちは拡張性の高いルール エンジン フレームワークの必要性を認識しました。ルール エンジンを使用すると、さまざまなアクションをグループ化、管理、自動化でき、ホーム オートメーション、不正行為検出、リスク管理、ワークフロー自動化などのさまざまなアプリケーションで使用できます。パナソニックでは、モビリティ、インダストリー4.0、ビル管理、ホームオートメーションの分野でいくつかの取り組みに取り組んでいます。したがって、フレームワークはさまざまなアプリケーションに適応できる必要があります。この記事では、ルール エンジン フレームワークの高レベルの設計について説明します。
ルール分析
基本的にルールを使用すると、ユーザーは多数のタスクをグループ化して自動化できます。ユーザーが作成したルールの例としては、室温が 27 度を超えると寝室のエアコンをオンにする、毎晩午後 6 時にオフィスのロビーの照明をオンにする、バッテリーが切れたら電気自動車にプッシュ通知を送信するなどがあります。レベルが 30% を下回ると、近くに空きのある充電ステーションが見つかります。

ルールには、ルールがいつアクティブ化されるかを指定するトリガー条件があります。トリガーは、ユーザーの位置、センサーの状態、特定の瞬間、外部の気象条件、またはその他の要因によって異なる場合があります。ルールのトリガー条件を一緒に指定する 1 つ以上の論理演算子を使用して、複数のトリガーを結合できます。
ルールには、これらのトリガー条件が満たされたときにアクティブ化される 1 つ以上のアクションもあります。アクションは、ライトを点灯するなどの単純な場合もあれば、レポートを作成して複数のユーザーに添付ファイルとして送信するなどの複雑な場合もあります。
設計上の考慮事項
ルールのトリガー条件は複数の入力ソースに依存する場合があります。データ ソースには、数秒ごとに定期的にステータスを送信する研究室に設置されたセンサーなどの内部的なものと、データが頻繁に変更されないため毎日取得して保存する必要がある気象データなどの外部的なものがあります。課題は、複数の入力ソースを取り込んで単一の値を作成し、ルールをアクティブにするかどうかを決定することです。
私たちのフレームワークは幅広いアプリケーションをサポートする必要があるため、2 つの基本的な設計原則に焦点を当てることにしました。最初の原則は、さまざまな入力トリガーと出力操作をサポートするためにアーキテクチャが拡張可能である必要があるということです。ホーム オートメーションのユースケースでは、最も一般的なトリガーは、時間帯、デバイスのステータス、または外部の気象条件に依存する可能性があります。一方、スマート ファクトリーのユースケースでは、ユーザーのアクティビティや、機械の効率など、時間の経過とともに収集された集計データがトリガーとなる可能性があります。この目的は、スキーマにあまり変更を加えることなく、新しいトリガー タイプを追加できるようにすることです。同様に、ルールアクションも拡張可能です。一般的なアクションには、API の呼び出し、通知の送信、タスクの作成とタスク キューへのプッシュなどがあります。
この設計の 2 番目の基本原則は、柔軟性を優先し、各コンポーネントを独立して拡張できるようにすることでした。柔軟なシステムは、システム全体を拡張することなく変化するニーズに適応できるため、回復力とコスト効率が向上します。たとえば、夕方 6 時に多数のルールをトリガーする必要がある場合、システムはタイマー トリガー サービスとルール実行サービスを適切に拡張するだけで済み、他のサービスは元の規模で動作し続けます。この柔軟性を提供することにより、システムはさまざまなニーズに効率的かつ効果的に対応できます。
ルールエンジンコンポーネント
スケーラビリティを実現するために、ルール トリガー サービス、ルール処理エンジン、ルール実行サービスを分離しました。ルール トリガー サービスはマイクロサービスの集合であり、各マイクロサービスは特定の種類のルール トリガー ロジックを処理できます。ルール エンジンは、ルール定義に基づいてさまざまな起動状態を組み合わせて、ルールを起動するかどうかを決定します。最後に、ルール実行サービスは、ルールで指定された意図されたアクションを実行するアプリケーション固有のルール実行ロジックです。各コンポーネントは独立して開発されています。これらは明確に定義されたインターフェイスを実装しており、独立して拡張できます。

ルールトリガーサービス
ルールトリガーサービスは、ルールをトリガーするタイミングを決定するロジックを実装します。これはマイクロサービスのコレクションであり、それぞれが非常に特殊な種類のトリガーを処理できます。たとえば、ポイントインタイムのアクティブ化と期間ベースのトリガーのロジックは、タイマーでトリガーされるマイクロサービスによって処理されます。また、さまざまなサービスがデバイス状態トリガーまたは天候ベースのトリガーを処理します。
ルール定義のルール起動条件に応じて、ルールは最初に作成されたときに 1 つ以上のルール起動サービスに登録されます。各トリガー サービスは、ルールを登録、更新、登録解除するための 3 つの主要な API を提供します。登録されたトリガーの実際のペイロードはサービスごとに異なる場合がありますが、ルール作成/更新 API は、ルール管理サービスがトリガー タイプを迅速に識別し、トリガー条件の解析と解釈をサービスに委任できるように設計されています。適切なトリガーサービス。個々のトリガー タイプのエンドポイントは、構成変数または環境変数の一部として共有することも、標準のサービス検出パターンを使用して実行時に検出することもできます。
各トリガー タイプには、異なるアクティベーション サービス ロジックがあります。トリガーは、1 つ以上の入力ソースからデータをキャプチャし、それを処理し、必要に応じてキャッシュし、ルールを起動するかどうかを決定するときにイベントを発行できます。ルールトリガーサービスは、特定のルールがトリガー条件を満たす場合はブール値 true を出力し、それ以外の場合は false を出力します。
ルールには 1 つ以上のトリガーを含めることができ、各トリガーは、ルールを実行するために満たす必要がある特定の条件を確立します。たとえば、毎日午後 6 時に、または周囲の照明レベルが 100 ルクスを下回ったときにリビング ルームの照明をオンにするというルールを考えてみましょう。このルールは OR ロジックを使用して 2 つの条件を組み合わせます。1 つ目は時間ベースのトリガーで、2 つ目はデバイス (ALS センサー) ステータス トリガーです。複数のトリガーと論理演算子を組み合わせて、より複雑なルールを作成することもできます。

各トリガーの状態を管理するには、対応するトリガー サービスによって更新される永続キャッシュが使用されます。これにより、ルール処理エンジンは最新のトリガー状態を常に利用できるようになり、条件を評価して適切なアクションを呼び出すことができるようになります。上の図では、赤色のトリガー ステータスは現在のトリガー条件が満たされていないことを示し、緑色のステータスはトリガー条件が満たされていることを示します。ルールのトリガー ステータスが変化すると、対応するトリガー サービスが処理のためにルール ID をキューに追加し、ルール処理エンジンによって使用されます。
各ルール トリガー サービスは、登録されたルールの数に基づいて水平方向に拡張可能であり、他のシステム コンポーネントから独立するように設計されています。この分離により、アプリケーションの進化に応じて各トリガーのアクティブ化ロジックを独立して進化させることもできます。さらに、最小限の変更で新しいトリガー タイプをシステムに追加できます。
ルール処理エンジン
ルール処理エンジンは、保留中のルール キューからルールを処理し、トリガー ステータスに従ってルールを実行します。起動ロジックが 1 つ以上のルール トリガーの組み合わせである場合、処理エンジンは、ルール定義で指定された起動ロジックに従って各入力トリガーの状態を組み合わせて、最終的なブール値を計算します。ルールをトリガーする必要があると判断すると、ルール実行サービスを呼び出してルールを実行します。
トリガ状態には大きく分けて 2 種類あります。ポイントオブタイム トリガーは、午後 6 時にルールをアクティブにする、またはデバイスの状態変更をトリガーする (エアコンがオンになっているときにファンをオフにするなど) など、トリガーの状態が変化する場合にのみ有効です。他のすべてのトリガー条件も満たされている場合、このようなルールはイベントの直後にアクティブ化される必要があります。ルール処理エンジンは、ルールの処理直後にそのようなトリガーの値をリセットします。

2 番目のタイプのトリガーは、長期間にわたるエンティティの永続的な状態を表します。たとえば、午後 6 時から午前 6 時の間に動きが検出された場合にポーチのライトが点灯するというシナリオを考えてみましょう。タイマー トリガー サービスは、午後 6 時にトリガー値を true に設定し、午前 6 時に false に設定します。これらの状態はルール処理エンジンによってリセットされず、トリガー サービスによって明示的に変更されるまで変更されません。これにより、システムはエンティティの永続的な状態を維持し、その永続的な状態に基づいて意思決定を行うことができます。

ルール実行サービス
ルール実行サービスは、HTTP API の呼び出し、MQTT メッセージの送信、またはプッシュ通知のトリガーを行ってルールを実行できます。ルールが実行できるアクションのリストはアプリケーション固有であり、拡張可能です。ルール トリガー サービスと同様、ルール アクション サービスはコア ルール エンジンから切り離されており、独立して拡張できます。

ルール実行サービスを複数のルール アクション サービスから分離する 1 つの方法は、Kafka などのメッセージ キューを使用することです。操作の種類に応じて、ルール実行サービスはルール アクションを個々の Kafka トピックに公開でき、コンシューマーのグループがこれを利用して、関連するアクションを実行できます。ルール アクション ペイロードはアクション タイプに固有にすることができ、ルール定義の一部としてキャプチャされ、そのままタスク キューに渡されます。
拡張トリガーサービス
ルールによってトリガーされるサービスはステートフルになる可能性があるため、スケーリングが困難になる可能性があります。すべてのトリガー サービスを拡張する一般的な方法はありません。トリガー サービスの基礎となる実装は、トリガーの種類と依存する可能性のある外部サービスに応じて異なるためです。このセクションでは、2 つの重要なトリガー タイプに使用されるスケーリング方法について説明します。
デバイスステータストリガー
デバイス状態を使用してサービス登録ルールをトリガーするために、ルール管理サービスはデバイス識別子、デバイス プロパティ、およびそれらに対応するしきい値を提供します。デバイス状態トリガー サービスは、これらを共有キャッシュ (Redis など) に保存し、デバイス ID のみを使用してアクセスできるようにします。

指定された例では、デバイス状態の変更に関する通知が MQTT プロトコル経由で送信され、Kafka メッセージ キューに追加されます。デバイス状態を担当する Kafka コンシューマーは、各受信イベントを受信して処理します。ルール トリガー キャッシュをチェックして、デバイスに関連付けられているルールがあるかどうかを確認します。この情報に基づいて、コンシューマは、デバイスのトリガーの現在の状態を反映するために、対応するトリガー状態キャッシュを更新します。このメカニズムにより、トリガー状態キャッシュが最新のデバイス状態の変更と確実に同期され、システムが最新の情報に基づいてルールを正確に評価できるようになります。
当社のサービスはすべてコンテナ化されており、Kubernetes クラスターで実行されます。デバイス ステータス トリガー サービスは、アプリケーションの負荷分散と自動スケール グループを通じてスケールされる標準 API サービスです。デバイス状態コンシューマー グループは、受信するデバイス状態変更イベントの速度に基づいてスケールします。Kubernetes Event-Driven Autoscaling (KEDA) は、処理する必要があるイベントの数に基づいてデバイス状態コンシューマのスケーリングを推進できます。さらに、Kafka ワークロードを予測するツールもあり、これを使用してコンシューマーをより迅速にスケールし、パフォーマンスを向上させることができます。
タイマートリガー
タイマー トリガー サービスは、ポイントインタイム トリガーと期間トリガーを処理します。トリガー リクエストのペイロードは、特定の時間帯のように単純なものも、Unix cron ジョブの仕様のように詳細なものにすることもできます。ルールは数日または数か月にわたって起動されない可能性があるため、サービスは登録されているすべてのルール要求をメモリに保持する必要はありません。代わりに、ルール登録リクエストを受信すると、ルールを次に実行するタイミングを計算し、次回の実行時間とともにルールの詳細をデータベースに保存します。
サービスは一定の間隔で、後続の時間枠でアクティブ化する必要があるすべてのルールをフェッチしてメモリに取り込みます。これは、ルールの次回実行時フィールドでフィルタリングすることで実行できます。実行する必要があるルールをすべて識別すると、サービスはルールを起動時間によって並べ替え、それらを処理するために 1 つ以上の Kubernetes ポッドを生成します。各ポッドにはルールのサブセットのみが割り当てられます。さまざまなポッドに割り当てられたルールは、Zookeeper または Kubernetes カスタム リソース定義 (CRD) を通じて共有できます。
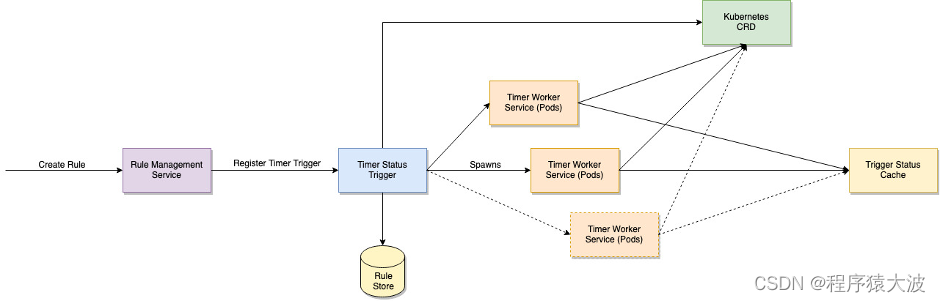
Kubernetes CRD を使用すると、特定のタスクを表すカスタム リソースを定義することで、データを共有し、複数のポッド間で作業を分散できます。タイマーでトリガーされるサービスは、次回の時間枠で処理する必要があるすべてのルールを個別のタスクに分割し、CRD に保存することでこの機能を使用します。次に、複数の作業単位が作成され、特定のタスクが割り当てられます。次に、各ポッドがルールを処理し、それに応じてトリガー状態キャッシュを更新します。
保守性と拡張性
ルール管理サービスとルール実行サービスはステートレス サービスであり、ロジックは非常に単純です。ルール管理は、ルールの作成、更新、削除のための標準 API を提供します。ルール実行サービスは、独立して動作してルール アクションを実行し、主にアプリケーション固有のアクションを呼び出します。
ルール管理サービスとトリガー サービス間の通信は非同期で実行できるため、サービス検出の必要がなくなります。たとえば、各トリガー サービスは、Kafka メッセージ ブローカー内に独自の専用キューを持つことができます。ルール管理サービスは、トリガー タイプに応じて、対応するキューにトリガー リクエストを追加できます。これは、トリガー タイプの Kafka コンシューマー (トリガー サービス) によって処理および消費されます。
すべての主要なコンポーネントが相互に分離されているため、新しいトリガー タイプと新しいアクション タイプのサポートを追加するのは簡単です。ルール管理サービスはプラグイン ベースの設計になっており、サポートされているトリガー タイプとアクション タイプごとにプラグインが追加され、ルール定義内の対応するトリガーとアクション ペイロードを検証します。ルール トリガーとアクション タイプの名前は、ルール管理サービスとトリガー サービスの間、およびルール処理サービスと実行サービスの間の通信のために、対応する Kafka キュー名に変換できます。
システムは複数のレベルでテストできます。単体テストで個々のサービスをカバーし、特定の機能に焦点を当てるのは比較的簡単です。分散環境でのデバッグとトラブルシューティングを容易にするには、分散ログとトレースのベスト プラクティスに従う必要があります。ログ記録とトレースのメカニズムを適切に実装すると、さまざまなサービス間のリクエストのフローを追跡し、問題を効果的に特定して診断できるようになります。これらのベスト プラクティスに従うことで、システムの動作をより深く理解し、デバッグ プロセスを簡素化できます。
信頼性
まず、発生する可能性のある潜在的な課題を特定しましょう。システム内のどのサービスでも計画外のダウンタイムが発生する可能性があり、システム負荷が効果的に拡張できる速度を超える速度で増大する可能性があり、一部のサービスやインフラストラクチャ コンポーネントが一時的に使用不能になる可能性があることを認識することが重要です。
通信に Kafka を使用すると、複数のレベルの信頼性を実現できます。Kafka は、メッセージの永続性、強力な耐久性の保証、フォールトトレラントなレプリケーション、コンシューマ グループ間の負荷分散、少なくとも 1 つの配信セマンティクスなど、メッセージ配信とコンシューマの信頼性を促進する機能を提供します。
最も直接的な信頼性のケースには、サービスのトリガーが含まれます。デバイス状態トリガーの場合、Kafka は状態変更イベントが失われないように、少なくとも 1 回の配信を保証するように構成されています。ただし、タイマーでトリガーされるサービスの信頼性を実現するには、追加の手順が必要です。ここでは、同時に処理する必要がある多数のイベントによって 1 人のワーカーが圧倒されないようにすることが重要です。
私たちのアプローチは、次回の時間枠で処理されるルールのリストを時系列に並べ、それらをラウンドロビン方式でワーカー サービス間で分散することです。さらに、ワーカー ポッドの数は、時間枠内のタイマー タスクの数と、任意の時点で実行されるタスクの最大数に比例します。これにより、潜在的に多数のタイマー タスクを同時に処理するのに十分な数のワーカー ノードが確保されます。また、作業単位がクラッシュしたときに自動的に再起動するように構成すると、手動介入なしで割り当てられたタスクを回復して完了できるようになり、作業単位を構成すると有益です。
さらに、Kubernetes には、サービスごとにリソース制限と最小要件を定義できるという利点もあります。これには、サービスが利用できる CPU または RAM リソースの最大量と、正常に開始するために必要な最小リソースの指定が含まれます。Kubernetes を使用すると、「ノイジーネイバー」問題 (1 つのポッドのリソースを大量に消費する動作が同じクラスター ノード上の他のポッドに影響を与える) などの問題に関する懸念を軽減できます。Kubernetes は、システム全体の安定性と信頼性の維持に役立つ分離機能とリソース管理機能を提供します。
要約する
MirAIe ルール エンジンは、ユーザーが複数のアクティビティをグループ化して自動化できる、拡張可能なルール エンジン フレームワークです。このフレームワークは、さまざまな内部または外部トリガーをサポートし、拡張性と柔軟性という 2 つの設計原則に重点を置いています。アーキテクチャは、さまざまな入力フリップフロップと出力操作をサポートし、あまり変更を加えずに新しいタイプを追加できるように拡張可能である必要がありました。また、このシステムは柔軟性を優先して各コンポーネントの独立したスケーリングを可能にし、回復力とコスト効率を高めます。