データ パイプラインの特定の要件を満たすためにカスタム統合レイヤーを作成する必要がありますか? Go を使用して Kafka と OpenSearch でこれを行う方法を学びます。
スケーラブルなデータの取り込みは、OpenSearch のような大規模に分散された検索および分析エンジンの重要な側面です。リアルタイム データ インジェスト パイプラインを構築する方法の 1 つは、Apache Kafka を使用することです。これは、大量のデータ (および速度) を処理するように設計されたオープンソースのイベント ストリーミング プラットフォームで、リレーショナル データベースや NoSQL データベースなどのさまざまなソースと統合します。たとえば、標準的なユース ケースの 1 つは、異種システム (ソース コンポーネント) 間のデータのリアルタイム同期であり、OpenSearch インデックスが最新であることを保証し、分析に使用したり、ダッシュボードや視覚化を通じてダウンストリーム アプリケーションで使用したりできるようにします。
このブログ投稿では、Apache Kafka に書き込まれたデータが OpenSearch に取り込まれるデータ パイプラインを作成する方法について説明します。Amazon OpenSearch サーバーレスと Amazon Managed Streaming for Apache Kafka (Amazon MSK) サーバーレスを使用します。Kafka Connect はそのようなニーズに非常に適しています。OpenSearch および ElasticSearch 用のシンクコネクタを提供します (Amazon OpenSearch で ElasticSearch OSS エンジンを使用することを選択した場合に使用できます)。ただし、特定の要件や理由により、カスタム ソリューションが必要になる場合があります。
たとえば、Kafka Connect がサポートしていないデータ ソースを使用していて (まれですが、可能性はあります)、データ ソースを最初から作成したくない場合があります。あるいは、これは 1 回限りの統合であり、Kafka Connect をセットアップして構成する労力を費やす価値があるかどうか疑問に思っている場合もあります。もしかしたらライセンスなど他にも問題があるのかもしれません。
ありがたいことに、Kafka と OpenSearch はいくつかのプログラミング言語でクライアント ライブラリを提供しており、独自の統合レイヤーを作成できます。まさにこのブログで取り上げている内容です!カスタム Go アプリケーションを使用して、Kafka と OpenSearch の Go クライアントを通じてデータを取り込みます。
次のことを学びます:
- 必要な AWS サービスのセットアップ方法の概要: OpenSearch サーバーレス、MSK サーバーレス、AWS Cloud9、IAM ポリシーとセキュリティ構成
- アプリケーションの高度なウォークスルー
- データ取り込みパイプラインを稼働させます
- OpenSearch でデータをクエリする方法
本題に入る前に、OpenSearch サーバーレスと Amazon MSK サーバーレスの概要を簡単に説明しましょう。
Amazon OpenSearch サーバーレスと Amazon MSK サーバーレスの概要
OpenSearch は、ログ分析、リアルタイム監視、クリックストリーム分析のためのオープンソースの検索および分析エンジンです。Amazon OpenSearch Service は、AWS での OpenSearch クラスターのデプロイとスケーリングを簡素化するマネージド サービスです。
Amazon OpenSearch Service は、OpenSearch と Elasticsearch OSS の古いバージョン (ソフトウェアの最終オープンソース リリースである 7.10 まで) をサポートしています。クラスターを作成するときに、使用する検索エンジンを選択できます。
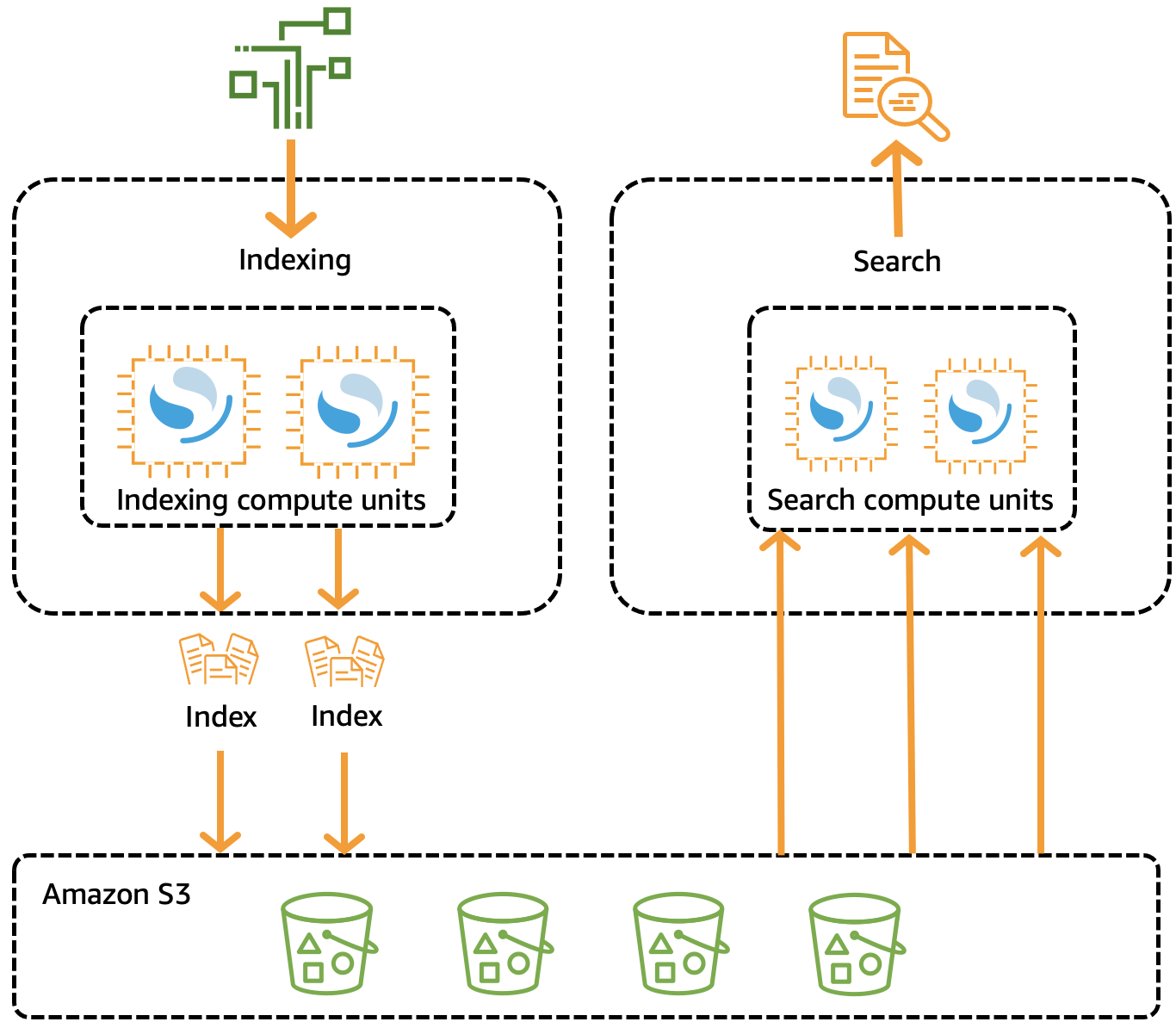
各 Amazon EC2 インスタンスがノードとして機能するクラスターを表す OpenSearch Service ドメイン (OpenSearch クラスターと同義) を作成できます。ただし、OpenSearch サーバーレスは、OpenSearch サービスにオンデマンドのサーバーレス構成を提供することで、運用の複雑さを解消します。インデックスのコレクションを使用して特定のワークロードをサポートし、インデックス作成と検索コンポーネントを従来のクラスターから分離し、Amazon S3 をインデックスのプライマリ ストレージとして使用します。このアーキテクチャは、検索機能とインデックス作成機能の独立したスケーリングをサポートしています。
詳細については、「OpenSearch サービスと OpenSearch サーバーレスの比較」を参照してください。
Amazon MSK (マネージド ストリーミング for Apache Kafka) は、Apache Kafka でストリーミング データを処理するためのフルマネージド サービスです。作成、更新、削除などのクラスター管理操作を処理します。標準の Apache Kafka データ操作を使用して、アプリケーションを変更せずにデータを生成および消費できます。オープンソースの Kafka リリースをサポートし、既存のツール、プラグイン、アプリケーションとの互換性を保証します。
MSK サーバーレスは、Amazon MSK のクラスターのタイプであり、クラスター容量を手動で管理および拡張する必要がなくなります。需要に基づいてリソースを自動的に構成および拡張し、トピック パーティションの管理を行います。従量課金制の料金設定では、使用した分だけお支払いいただきます。MSK サーバーレスは、柔軟な自動スケーリングのストリーミング容量を必要とするアプリケーションに最適です。
まず、高レベルのアプリケーション アーキテクチャについて説明し、次にアーキテクチャ上の考慮事項について説明します。
アプリケーションの概要とアーキテクチャ上の重要な考慮事項
これはアプリケーション アーキテクチャの簡略化されたバージョンであり、コンポーネントとコンポーネントが相互にどのように相互作用するかを概説しています。
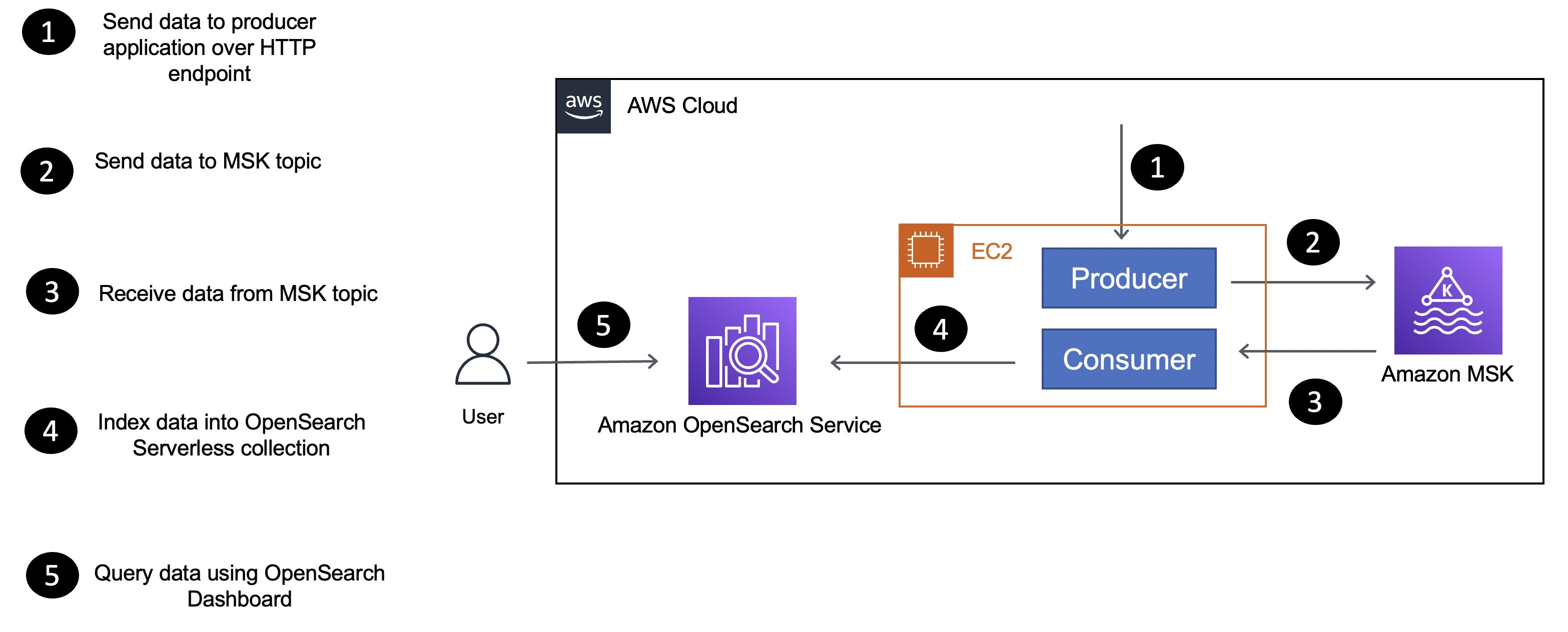
アプリケーションは、インスタンスにデプロイされる Go アプリケーションであるプロデューサー コンポーネントとコンシューマー コンポーネントで構成されますEC2。
- 名前が示すように、プロデューサーは MSK サーバーレス クラスターにデータを送信します。
- コンシューマ アプリケーションは
movieMSK サーバーレス トピックからデータ (メッセージ) を受信し、OpenSearch Go クライアントを使用してmoviesコレクション内のデータにインデックスを付けます。
シンプルさに重点を置く
このブログ投稿は簡潔さと理解しやすさを重視して最適化されているため、このソリューションは実稼働ワークロードを実行するように調整されていないことに注意してください。簡略化された点は次のとおりです。
- プロデューサー アプリケーションとコンシューマー アプリケーションは、同じコンピューティング プラットフォーム (EC2 インスタンス) 上で実行されます。
- MSK トピックからのデータを処理するコンシューマーアプリケーション インスタンスが 1 つあります。ただし、コンシューマ アプリケーションの複数のインスタンスを実行して、インスタンス間でデータがどのように分散されるかを確認することができます。
- Kafka CLI を使用してデータを生成する代わりに、Go でカスタム ジェネレーター アプリケーションと REST エンドポイントを作成してデータを送信します。これは、Go で Kafka プロデューサー アプリケーションを作成する方法を示し、Kafka CLI を模倣します。
- 使用するデータ量は少ないです。
- OpenSearch サーバーレス コレクションにはパブリックアクセス タイプがあります。
運用ワークロードの場合、次の点を考慮する必要があります。
データ量とスケーラビリティ要件に基づいて、コンシューマ アプリケーションに適切なコンピューティング プラットフォームを選択します。これについては、以下で詳しく説明します。
OpenSearch サーバーレス コレクションの VPC アクセス タイプを選択します。
Amazon OpenSearch Ingestion を使用してデータ パイプラインを作成することを検討してください。
MSK から OpenSearch へのデータ パイプラインを構築するためにカスタム アプリケーションをデプロイする必要がある場合、選択できるコンピューティング オプションの範囲は次のとおりです。 コンテナー: コンシューマー アプリケーションを Docker コンテナーとしてパッケージ化できます (Dockerfile は GitHub で入手できます
)リポジトリを取得) し、Amazon EKS または Amazon ECS にデプロイします。
アプリケーションを Amazon EKS にデプロイする場合は、KEDA を使用して、MSK トピック内のメッセージ数に基づいてコンシューマーアプリケーションを自動的にスケーリングすることも検討してください。
サーバーレス: MSK を AWS Lambda 関数のイベント ソースとして使用することもできます。コンシューマーアプリケーションを Lambda 関数として作成し、MSK イベントによってトリガーされるように構成したり、AWS Fargate で実行したりできます。
プロデューサー アプリケーションは REST API であるため、AWS App Runner にデプロイできます。
最後に、Amazon EC2 Auto Scaling グループを利用して、コンシューマ アプリケーションの EC2 フリートを自動的にスケーリングできます。
Java ベースの Kafka アプリケーションを使用して IAM 経由で MSK Serverless に接続する方法について説明する十分な資料があります。
Go がどのように動作するかを理解するために寄り道してみましょう。
Go クライアント アプリケーションは IAM を使用して MSK サーバーレスで認証するにはどうすればよいですか?
MSK サーバーレスでは、MSK クラスターの認証と認可を処理するために IAM アクセス制御が必要です。これは、MSK クライアント アプリケーション (この場合はプロデューサーとコンシューマー) が IAM を使用して MSK に対して認証する必要があり、これに基づいて特定の Apache Kafka 操作が許可または拒否されることを意味します。
良い点は、franz-goKafka クライアント ライブラリが IAM 認証をサポートしていることです。以下は、実際にどのように動作するかを示すコンシューマ アプリケーションのスニペットです。
func init() {
//......
cfg, err = config.LoadDefaultConfig(context.Background(), config.WithRegion("us-east-1"), config.WithCredentialsProvider(ec2rolecreds.New()))
creds, err = cfg.Credentials.Retrieve(context.Background())
//....
func initializeKafkaClient() {
opts := []kgo.Opt{
kgo.SeedBrokers(strings.Split(mskBroker, ",")...),
kgo.SASL(sasl_aws.ManagedStreamingIAM(func(ctx context.Context) (sasl_aws.Auth, error) {
return sasl_aws.Auth{
AccessKey: creds.AccessKeyID,
SecretKey: creds.SecretAccessKey,
SessionToken: creds.SessionToken,
UserAgent: "msk-ec2-consumer-app",
}, nil
})),
//.....
インフラストラクチャ設定
このセクションは、次のコンポーネントのセットアップに役立ちます。
- 必要な IAM ロール
- MSKサーバーレスクラスター
- OpenSearch サーバーレス コレクション
- アプリケーションを実行するための AWS Cloud9 EC2 環境
MSKサーバーレスクラスター
このドキュメントに従って、AWS コンソールを使用して MSK サーバーレス クラスターをセットアップできます。これを行った後、VPC、サブネット、セキュリティ グループ ([プロパティ] タブ)、およびクラスター エンドポイント ([クライアント情報の表示] をクリック) のクラスター情報をメモします。
アプリケーション IAM ロール
このチュートリアルには別の IAM ロールが必要です。
まず、次のステップを実行するための IAM ロールを作成し、「ステップ 1: アクセス許可を設定する (Amazon OpenSearch ドキュメント内)」のアクセス許可に従って OpenSearch サーバーレスを使用します。
MSK サーバーレス クラスターと対話し、OpenSearch Go クライアントを使用して OpenSearch サーバーレス コレクション内のデータのインデックスを作成する、クライアント アプリケーション用の別の IAM ロールを作成します。以下のようなインライン IAM ポリシーを作成します。必要な値を必ず置き換えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kafka-cluster:*"
],
"Resource": [
"<ARN of the MSK Serverless cluster>",
"arn:aws:kafka:us-east-1:<AWS_ACCOUNT_ID>:topic/<MSK_CLUSTER_NAME>/*",
"arn:aws:kafka:us-east-1:AWS_ACCOUNT_ID:group/<MSK_CLUSTER_NAME>/*"
]
},
{
"Effect": "Allow",
"Action": [
"aoss:APIAccessAll"
],
"Resource": "*"
}
]
}次の信頼ポリシーを使用します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}最後に、OpenSearch サーバーレス データ アクセス ポリシーをアタッチする別の IAM ロールがあります。これについては、次のステップで詳しく説明します。
OpenSearch サーバーレス コレクション
ドキュメントを使用して、OpenSearch サーバーレス コレクションを作成します。「ステップ 2: コレクションを作成する」のポイント 8 に従う場合は、必ず 2 つのデータ ポリシーを構成してください (つまり、前のセクションのステップ 2 と 3 で作成した IAM ロールごとに)。
注: このチュートリアルでは、パブリックアクセス タイプを選択します。VPC は実稼働ワークロードに推奨されます。
AWS Cloud9 EC2環境
このドキュメントを使用して、AWS Cloud9 EC2 開発環境を作成します。必ずMSK サーバーレス クラスターと同じ VPCを使用してください。
完了したら、次のことを行う必要があります: Cloud9 環境を開きます。[EC2 インスタンス]で、[EC2 インスタンスの管理]をクリックします。EC2 インスタンスで、[セキュリティ]に移動し、アタッチされているセキュリティ グループをメモします。
MSK サーバーレス クラスターに関連付けられたセキュリティ グループを開き、Cloud9 EC2 インスタンスの接続を許可する受信ルールを追加します。Cloud9 EC2 インスタンスのセキュリティ グループをソースとして選択し、ポートとして9098 を選択し、 TCPプロトコルを選択します。
これでアプリケーションを実行する準備が整いました。
Cloud9 環境を選択し、「Cloud9 で開く」を選択してIDE を起動します。ターミナル ウィンドウを開き、GitHub リポジトリのクローンを作成し、ディレクトリをそのフォルダーに変更します。
git clone https://github.com/build-on-aws/opensearch-using-kafka-golang
cd opensearch-using-kafka-golangプロデューサー アプリケーションを起動します。
cd msk-producer
export MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
go run main.goターミナルに次のログが表示されるはずです。
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
starting producer app
http server readyHTTPMSK サーバーレス クラスターにデータを送信するには、開始したアプリケーションによって公開されたエンドポイントを呼び出す bash スクリプトを使用し、movies.txt次の形式を使用してムービー データ (ファイルから) を送信します。JSONcurl
./send-data.shプロデューサ アプリケーションのターミナル ログに、次のような出力が表示されるはずです。
producing data to topic
payload {"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
record produced successfully to offset 2 in partition 0 of topic movies
producing data to topic
payload {"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
record produced successfully to offset 4 in partition 1 of topic movies
.....このチュートリアルの目的とシンプルさを保つために、データ量は意図的に 1500 レコードに制限されており、スクリプトは各レコードをプロデューサーに送信した後、意図的に 1 秒間スリープします。簡単にフォローできるはずです。
プロデューサー アプリケーションがmoviesトピックへのデータの送信で忙しい間、コンシューマー アプリケーションを起動して、MSK サーバーレス クラスターからのデータの処理を開始し、OpenSearch サーバーレス コレクションでインデックスを作成することができます。
cd msk-consumer
export MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
export OPENSEARCH_INDEX_NAME=movies-index
export OPENSEARCH_ENDPOINT_URL=<enter OpenSearch Serverless endpoint>
go run main.goターミナルに次の出力が表示されます。これは、MSK サーバーレス クラスターからのデータの受信と OpenSearch サーバーレス コレクションでのインデックス作成が実際に開始されたことを示します。
using default value for AWS_REGION - us-east-1
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
OPENSEARCH_INDEX_NAME movies-index
OPENSEARCH_ENDPOINT_URL <OpenSearch Serverless endpoint>
using credentials from: EC2RoleProvider
kafka consumer goroutine started. waiting for records
paritions ASSIGNED for topic movies [0 1 2]
got record from partition 1 key= val={"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
movie data indexed
committing offsets
got record from partition 2 key= val={"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
movie data indexed
committing offsets
.....プロセスが完了すると、OpenSearch Serverless コレクションに 1500 個の映画がインデックス付けされるはずです。ただし、完了するまで待つ必要はありません。数百のレコードを取得したら、OpenSearch ダッシュボードの開発者ツールに移動して、次のクエリを実行できます。
OpenSearch で映画データをクエリする
簡単なクエリを実行する
インデックス内のすべてのドキュメントをリストする簡単なクエリから始めましょう(パラメーターやフィルターは使用しません)。
GET movies-index/_search特定のフィールドのみのデータを取得する
デフォルトでは、検索リクエストは、ドキュメントのインデックス作成時に提供された JSON オブジェクト全体を取得します。この_sourceオプションを使用して、選択したフィールドからソースを取得します。たとえば、 および フィールドのみを取得するにはtitle、plot次genresのクエリを実行します。
GET movies-index/_search
{
"_source": {
"includes": [
"title",
"plot",
"genres"
]
}
}用語クエリの検索語に完全に一致するデータを取得します
これを実現するには、用語クエリを使用できます。たとえば、フィールドchristmasにその用語が含まれる映画を検索するにはtitle、次のクエリを実行します。
GET movies-index/_search
{
"query": {
"term": {
"title": {
"value": "christmas"
}
}
}
}** 選択フィールド選択と用語検索を組み合わせます。
このクエリを使用すると、特定のフィールドのみを取得できますが、特定の用語に関心があります。
GET movies-index/_search
{
"_source": {
"includes": [
"title",
"actors"
]
},
"query": {
"query_string": {
"default_field": "title",
"query": "harry"
}
}
}重合
集計を使用して、特定のフィールドのグループ値に基づいて集計値を計算します。たとえばratings、、、、、genreなどのフィールドを集計しyear、それらのフィールドの値に基づいて結果を検索できます。集計により、「各ジャンルに映画は何本ありますか?」などの質問に答えることができます。
GET movies-index/_search
{
"size":0,
"aggs": {
"genres": {
"terms":{"field": "genres.keyword"}
}
}
}結論は
要約すると、Kafka を使用してデータを OpenSearch Serverless に取り込み、それを別の方法でクエリするパイプラインをデプロイしました。その過程で、実稼働ワークロードで留意すべきアーキテクチャ上の考慮事項とコンピューティング オプション、Go ベースの Kafka アプリケーションと MSK IAM 認証の操作についても学びました。また、特に Go SDK を使用した OpenSearch オペレーションの実行を中心としたチュートリアルを探している場合は、「Go で Amazon OpenSearch 用の CRUD アプリケーションを構築する」という記事を読むことをお勧めします。